1. Introduction
In medical research, the efficacy of new drugs or treatment protocols is established by controlled studies in which a treatment group is compared against a control group. A case series is one half of a controlled study consisting only of the treatment group. At the beginning of the COVID-19 pandemic, practicing medical doctors were confronted with having no treatment to offer to their patients that can prevent or minimize hospitalization and/or death. In response, some doctors were compelled to innovate and discover, on their own, treatment protocols using repurposed off-label medications. Most notable examples, amongst several others, include Didier Raoult [
1] in the IHU Méditerranée Infection hospital in Marseilles France, Vladimir Zelenko [
2] in upstate New York, George Fareed and Brian Tyson [
3] in California, Shankara Chetty [
4] in South Africa, Jackie Stone [
5] in Zimbabwe, and Paul Marik’s group [
6,
7], which was in the beginning based at the Eastern Virginia Medical School. Their efforts to treat patients generated case series of successfully treated patients that constitute real-world evidence [
8].
The goal of this paper is to present a statistical framework for rapidly analyzing systematic case series data of early treatment protocols with binary endpoints (e.g., hospitalization or death), and comparing them against our prior knowledge of the likelihood of adverse outcomes in the absence of treatment. Although the development of the proposed statistical technique was originally motivated by the need to assess available case series [
2,
9,
10,
11,
12,
13] of multidrug treatment protocols [
2,
14,
15,
16] for COVID-19, it can also play a very important role in the public health response to future pandemics or epidemics with no established treatment protocols. Furthermore, the potential scope of our methodology is very broad and it can be used to compare any treatment group case series, with binary endpoints, against our prior knowledge of the probability of adverse outcomes based on population-level historical controls. A limitation of the methodology is that it should be used only for treatment protocols that are based on repurposed medications [
17] with known acceptable safety. The main advantage of the technique is that it can be very good at rapidly validating and enabling the deployment of treatment protocols, based on repurposed medications, when there is a sufficiently strong signal of efficacy. When confronted with a mass casualty event, it is critically important to be able to rapidly leverage the direct clinical experience of medical doctors, towards formulating an evidence-based standard of care, while also being able to rigorously quantify the quality of the available evidence.
The closest concept to our approach is the idea of using a virtual control group [
18], in which the outcomes observed in a treatment group case series are compared against the predicted outcomes for the same patient cohort without treatment, using a trained statistical model, based on data accumulated before the discovery of the treatment in question. The virtual control group method aims to not only establish the existence of efficacy, but to also measure the corresponding treatment efficacy. Our idea is to abandon any attempt to obtain an unbiased measure of the treatment efficacy, and to focus on establishing, with sufficient confidence, the existence of some positive treatment efficacy. We do this by comparing the treatment group case series with a probability lower-bound for the expected negative outcomes without treatment. Such lower bounds can be easily extracted from available data, and can be facilitated by applying risk-stratification on the treatment group case series, when necessary. Thus, our aim is to establish, with sufficient confidence, a positive lower bound for treatment efficacy, quickly and without expending substantial resources, using real-world evidence that has been accumulated from the efforts of practicing physicians. In turn, this can be sufficient for a positive recommendation to adopt the corresponding treatment protocol.
Because case series are susceptible to selection bias, we define two cross-over thresholds for making a positive recommendation: an efficacy threshold, corresponding to a
preponderance of evidence standard, where we assume there is no selection bias, and a random selection bias threshold, corresponding to the
clear and convincing evidentiary standard, which controls for random selection bias in the case series. Following the recommendation of the American Statistical Association statement on statistical significance and
p-values [
19], the proposed approach combines use of the
p-value, which enables one to reject the null hypothesis, with a Bayesian factor analysis framework [
20,
21,
22,
23,
24] for controlling the false positive rate [
25] in the calculation of the efficacy threshold. Empirically, we have found that the frequentist
p-value framework has done a pretty good job on its own, at least for the analysis of the case series data considered in this paper. However, complementing it with Bayesian factor analysis is a reasonable precaution, because it can help raise the red flag when dealing with small sample sizes and/or weak signals.
We apply the proposed framework to the processing of available case series data [
2,
9,
10,
11,
12,
13] that support proposed early outpatient treatment protocols for COVID-19 patients, such as the original Zelenko triple-drug protocol [
2] and the more advanced McCullough protocol [
14,
15,
16]. The original Zelenko protocol was first announced on 23 March 2020 [
26]. The proposed approach was to risk stratify patients into two groups (low-risk vs. high-risk), provide supportive care to the low-risk group, and treat the high-risk group with a triple-drug protocol (hydroxychloroquine, azithromycin, zinc sulfate). Results were reported in an 28 April 2020 letter [
9] and a 14 June 2020 letter [
10], and the lab-confirmed subset of the April data was published in a formal case-control study [
2]. Zelenko’s letters have been attached to our
supplementary material document [
27].
The rationale for the triple-drug therapy was based on the following mechanisms of action: hydroxychloroquine prevents the virus from binding with the cells, and also acts as a zinc ionophore that brings the zinc ions inside the cells, which in turn inhibit the RDRP (RNA dependent RNA polymerase) enzyme used by the virus to replicate [
28,
29]. Azithromycin’s role is to guard against a secondary infection, but we have since learned that it also has its own anti-viral properties [
30,
31,
32], and a signal of the efficacy of adding azithromycin on top of hydroxychloroquine can be clearly discerned in a study of nursing home patients in Andorra, Spain [
33].
It is interesting that chloroquine was shown in vitro to have antiviral properties against the previous SARS-CoV-1 virus [
34], and that there is an anecdotal report from 1918 [
35] about the successful use of quinine dihydrochloride injections as an early treatment of the Spanish flu. In hindsight, it is now known that influenza viruses also use the RDRP protein to replicate [
36], which can be inhibited with intracellular zinc ions [
28,
29]. Consequently, there is a mechanism of action that can explain why we should anticipate the combination of zinc with a zinc ionophore (i.e., hydroxychloroquine, or quercetin [
37], or EGCG (Epigallocatechin Gallate) [
38]) to inhibit the replication of the influenza viruses. Other RNA viruses, including the respiratory syncytial virus (hereafter RSV) [
39] and the highly pathogenic Marburg and Ebola viruses [
40,
41], are also using the RDRP protein to replicate, raising the question of whether the zinc/zinc ionophore concept could also play a useful role against them.
Zelenko’s protocol was soon extended into a sequenced multidrug approach, known as the McCullough protocol [
14,
15,
16], which is based on the insight that COVID-19 is a tri-phasic illness that manifests in three phases: (1) an initial viral replication phase, in which the virus infects cells and uses them to replicate and make new viral particles, during which patients present with flu-like symptoms; (2) an inflammatory hyper-dysregulated immune-modulatory florid pneumonia, that presents with a cytokine storm, coughing, and shortness of breath, triggered by the toxicity of the spike protein [
42], when it is released, as viral particles are destroyed by the immune system, triggering release of interleukin-6 and a wave of cytokines; (3) a thromboembolic phase, during which microscopic blood clots develop in the lungs and the vascular system, causing oxygen desaturation, and very damaging complications that can include embolic stroke, deep vein thrombosis, pulmonary embolism, myocardial injury, heart attacks, and damage to other organs.
The rationale of the original Zelenko protocol was that early intervention to stop the initial viral replication phase could prevent the disease from progressing to the second and third phase, and, in doing so, prevent hospitalizations or death. The McCullough protocol [
14,
15,
16] extends the Zelenko protocol by using multiple drugs in combination sequentially to mitigate each of the three phases of the illness, depending on how they present for each individual patient. McCullough’s therapeutic recommendations for handling the cytokine injury phase and the thrombosis phase of the COVID-19 illness are, for the most part, standard on-label treatments for treating hyper-inflammation and preventing blood clots. The most noteworthy innovations to the antiviral part of the protocol are the addition of ivermectin [
43,
44,
45,
46,
47,
48], which has 20 known mechanisms of action against COVID-19 [
49], to be used as an alternative or in conjunction with hydroxychloroquine, the addition of a nutraceutical bundle [
50,
51,
52] combined with a zinc ionophore (quercetin [
37] or EGCG [
38]) for both low-risk and high-risk patients, and lowering the age threshold for high-risk patients to 50 years. The MATH+ protocol [
6,
7], developed for hospitalized patients by Marik’s group, follows the same principles of a sequenced multidrug treatment. A similar treatment protocol, based on similar insights, was independently discovered and published on May 2020 by Chetty [
4] in South Africa.
McCullough’s protocol [
14,
15,
16] was adopted by some treatment centers throughout the United States and overseas, but has not been endorsed by the United States public health agencies, ostensibly due to lack of support of the entire sequenced treatment algorithm by an RCT (Randomized Controlled Trial). In spite of the urgent need for safe and effective early outpatient treatment protocols for COVID-19, there has been no attempt to conduct any such trials of any comprehensive multidrug outpatient treatment protocols throughout the pandemic. Instead, the prevailing approach has been to try to build treatment protocols, one drug at a time, after validating each drug with an RCT. Because COVID-19 is a multifaceted tri-phasic illness, there is no a priori reason to expect that a single drug alone will work for all three phases of the disease. Consequently, the first priority should be to validate the efficacy of treatment protocols that use multiple drugs in combination, since this is what is actually going to be used in practice to treat patients. To that end we have analyzed the case series by Zelenko [
2,
9,
10], Procter [
11,
12], and Raoult [
13], where such multidrug outpatient treatment protocols have been used by practicing physicians.
The broader context in which the proposed statistical methodology is situated is as follows. Shortly before COVID-19 was declared a pandemic by the World Health Organization, an article [
53] was published on 23 February 2020 in the New England Journal of Medicine arguing that
“the replacement of randomized trials with non-randomized observational status is a false solution to the serious problem of ensuring that patients receive treatments that are both safe and effective.” The opposing viewpoint was published earlier in 2017 by Frieden [
54], highlighting the limitations of RCTs and the need to leverage and overcome the limitations of all available sources of evidence, including real-world evidence [
8], in order to make lifesaving public health decisions. In particular, Frieden [
54] stressed that the very high cost of RCTs and the long timelines needed for planning, recruiting patients, conducting the study, and publishing it, are limitations that
“affect the use of randomized controlled trials for urgent health issues, such as infectious disease outbreaks for which public health decisions must be made quickly on the basis of limited and imperfect data.”Deaton and Cartwright [
55] presented the conceptual framework that underlies RCTs and highlighted several limitations. Among them, they have stressed that randomization requires very large samples on both arms of the trial, otherwise, an RCT should not be presumed to be methodologically superior to a corresponding observational study. For example, the randomized controlled trial study of hydroxychloroquine by Dubee et al. [
56], was administratively stopped after recruiting 250 patients, with 124 in the treatment group and 123 in the control group. Although a two-fold mortality rate reduction was observed by day 28, the study failed to reach statistical significance, due to the small sample size. Even if statistical significance had been achieved via a stronger mortality rate reduction signal, the small sample size would have still prevented sufficient randomization. Consequently, although the study has gone through the motions of an RCT, it is not methodologically superior to a retrospective observational study. There are several other RCT studies of hydroxychloroquine with similar shortcomings [
57].
Furthermore, although a properly conducted RCT has internal validity, in that the inferences are applicable to the specific group of patients that participated in the trial, the external validity of the RCT outcomes needs to be justified conceptually on the basis of prior knowledge, which is either observational, or based on a deeper understanding of the underlying mechanisms of action. Because COVID-19 mortality risk in the absence of early treatment can span three orders of magnitude (from 0.01% to more than 10%) [
58,
59,
60,
61,
62,
63,
64], depending on age and comorbidities, trials using low-risk patient cohorts are not informative about expected outcomes on the high-risk patient cohorts and vice versa. Likewise, the timing of treatment and the medication dosage/duration of treatment will confound the results of an RCT. In general, better results are expected when treatment is initiated earlier rather than later, and negative results can be caused by inappropriate medication dosage (i.e., too much or too little). These are all relevant considerations for establishing the external validity of an RCT.
As was noted by Risch [
65], when interpreting evidence from RCTs, and more broadly from any study, we should bear in mind that results of efficacy or toxicity of a treatment regimen on hospitalized patients cannot be extrapolated to outpatients and vice versa. Likewise, Risch [
65] noted that evidence of efficacy or lack of efficacy of a single drug do not necessarily extrapolate to using several drugs in combination. This latter point is further amplified when there is an algorithmic overlay governing which drugs should be used and when, based on the individual patient’s medical history and ongoing response to treatment. Consequently, RCTs that compare a single drug monotherapy against supportive care are not always informative about whether the drug should be included in a multidrug protocol.
In addition to all that, we are also confronted with an ethical concern. If the available observational evidence are sufficiently convincing, then there is a crossover point where it is no longer ethical to justify randomly refusing treatment to a large number of patients in order to have a sufficiently large control group. The corresponding mathematical challenge is being able to quantify the quality of our observational evidence in order to determine whether or not we are already situated beyond this ethical crossover point.
Just as the quality of evidence provided by randomized controlled trials is fluid, with respect to successful randomization and external validity, the same is true about the quality of real-world evidence [
8] that will inevitably become available from the initial response to an emerging new pandemic. We envision that a successful pandemic response, in the area of early outpatient treatment, will proceed as follows: the first element of pandemic response is to assess and monitor the situation by prospectively collecting data, needed to construct predictive models of the probability of hospitalization and death, in the absence of treatments that have yet to be discovered, as a function of the patient’s medical profile/history. These models do not necessarily need to be sophisticated at the early stages of pandemic response. It could be sufficient to be able to predict good lower bounds for the hospitalization or mortality probabilities, as opposed to more precise estimates. These early data can be used to identify the predictive factors for hospitalization or death and risk stratify the patients into low-risk and high-risk categories. They can also be used as a historical control group that establishes our prior knowledge of expected outcomes, in the absence of treatment, that has yet to be discovered.
In parallel with gathering and analyzing data, which is the primary duty and responsibility of our public health and academic institutions, medical doctors have an ethical responsibility to use the emerging scientific understanding of the new disease and its mechanisms of actions to try to save the lives of as many patients as possible. Under article 37 of the 2013 Helsinki declaration [
66], it is ethically appropriate for physicians to
“use an unproven intervention, if in the physician’s judgment it offers hope of saving life, re-establishing health or alleviating suffering”, provided, there is informed consent from the patient, and
“where proven interventions do not exist, or other known interventions have been ineffective.”When this effort leads to the discovery of a treatment protocol, with an empirical signal of benefit and acceptable safety, and using the treatment protocol results in a case series of treated patients, then the confluence of the following conditions makes it possible to statistically establish the existence of treatment efficacy: First, the proposed treatment protocols should use repurposed drugs [
17] with known acceptable safety. When testing new drugs, we have no prior knowledge of the risks involved and a rigorous controlled study is required to determine the balance of risks and benefits. Second, we need data that give us prior knowledge of the probability risk of the relevant binary endpoints (i.e., hospitalization and/or death) in the absence of treatment, as a function of the relevant stratification parameters. Third, and most importantly, the case series corresponding to treated patients should exhibit a
very strong signal of benefit, relative to our prior experience with untreated patients, prior to the discovery of the respective treatment protocol.
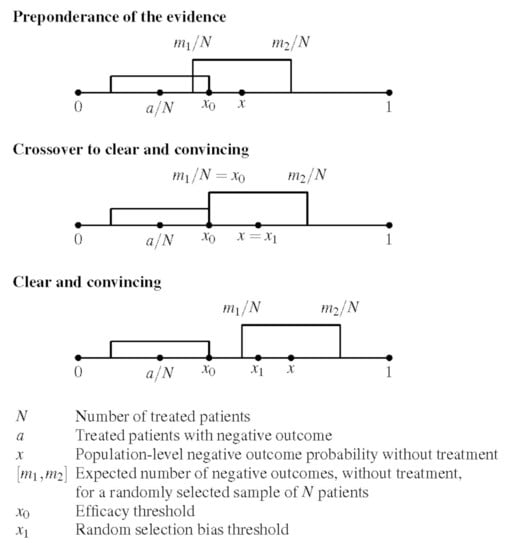
Under these conditions, the idea that is proposed in this paper works as follows. Our input is the number N of high-risk patients treated, the number of patients a with an adverse outcome (i.e., hospitalization or death) and selection criteria for extracting the high-risk cohort under consideration, from which we can deduce, based on prior knowledge, that the unknown probability x of an adverse outcome without treatment is bounded by . We also choose the desired level of p-value upper bound , which is typically (95% confidence), although we shall also consider and . The output is an efficacy threshold that gives us the following rigorous mathematical statement: if , then we have more than confidence that the treatment is effective relative to the standard of care. This statement has to be paired with the subjective assessment of our prior knowledge, based on which we need to show that . The upper bound is used by the Bayesian factor technique as part of finalizing the calculation of the efficacy threshold . Implicit in this argument is the assumption of no selection bias, allowing us to apply the probability x at the population level to our particular case series. From the sample size N and the finalized efficacy threshold , we also calculate a random selection bias threshold , higher than , that quantifies how large the gap between and needs to be, in order to mitigate with confidence, any possible random selection bias in the case-series sample .
As a result, we can assert the existence of treatment efficacy using two distinct standards of evidence. If we can establish
, then the
preponderance of evidence is in favor of the existence of treatment efficacy, and this can justify its provisional adoption on an emergency basis, in order to gather more evidence. If we can establish that
, then the evidence becomes
clear and convincing, and if these results are replicated by multiple treatment centers, then it becomes ethically questionable to deny patients access to the treatment protocol, for the purpose of conducting an RCT, or simply due to therapeutic nihilism by public health authorities. In
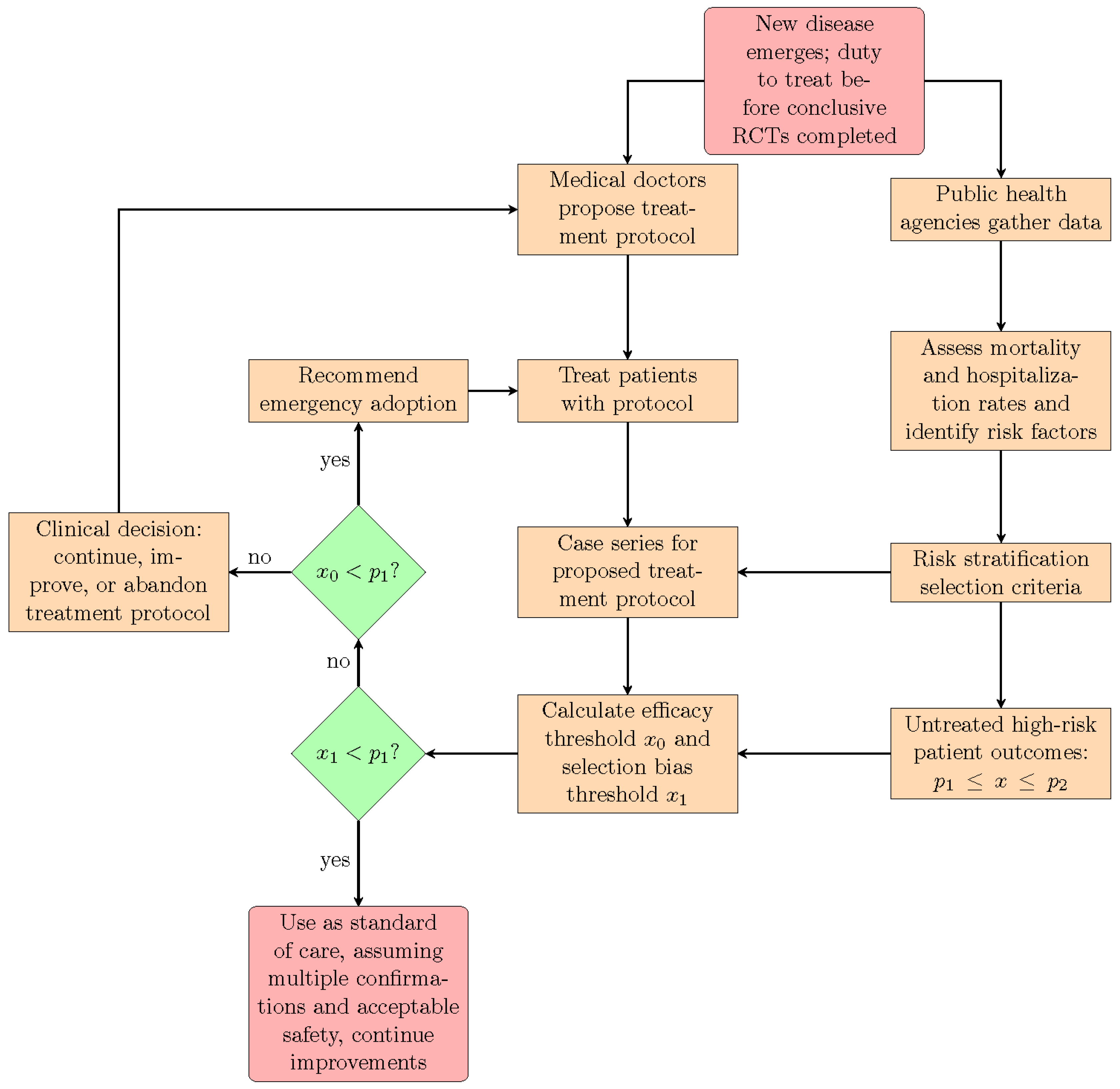
Figure 1, we show how the proposed statistical methodology can be integrated into an epidemic or pandemic response that leverages and deploys the direct experience of frontline medical doctors, resulting from their efforts to treat their patients. We stress again that this approach is appropriate only for treatment protocols using repurposed medications with known acceptable safety. When new medications, as opposed to repurposed drugs, are introduced into a pre-existing treatment protocol, then they should be rigorously tested both for safety and efficacy with prospective RCTs.
The paper is organized as follows. In
Section 2 we present the technique for calculating the efficacy threshold and the random selection bias threshold. We also explain the relationship of the proposed technique with the exact Fisher test and with the binomial proportion confidence interval problem. In
Section 3, we present a Bayesian technique for adjusting the efficacy thresholds in order to also control the corresponding false positive rate. In
Section 4, we illustrate an application of both techniques to the Zelenko case series [
2,
9,
10] as well as the Procter [
11,
12] and Raoult [
13] case series. Discussion and conclusions are given in
Section 5. With the exception of
Section 3, which is mainly relevant to a more careful analysis by biostatisticians, we have strived to make
Section 2 and
Section 4 of the paper relevant and accessible to both clinicians and biostatisticians by minimizing the mathematical details. Material that is relevant only to biostatisticians is relegated to the appendices. The computer code and the corresponding calculations are included in the
supplementary data document [
27].
5. Discussion and Conclusions
Our findings fully support risk stratification in the management of acute COVID-19, with the intent of reducing the intensity and duration of symptoms and by that mechanism, lower the risk of hospitalization and death. Although COVID-19 is generally known as a respiratory disease, there is an accumulation of evidence [
42,
97,
98] that it is also, if not primarily, a vascular disease, with endothelial injury having a major role in sustained permanent injuries, hospitalizations, and death. The spike protein has been shown to damage the vascular endothelial cells [
42] by downregulating ACE2, thereby inhibiting mitochondrial function, and by impairing the bioavailability of nitric oxide to endothelial cells. The spike protein also triggers immune dysregulation, triggering endothelial cells to transition to an activated immune response state, which causes both macrovascular and diffuse microvascular thrombosis, leading to myocardial injury and other organ damage [
97,
98]. Early outpatient treatment, using multiple drugs in combination, prevents these adverse outcomes by stopping viral replication at the first phase of the illness, and mitigating the injuries caused by the hyper inflammatory COVID-19 pneumonia phase and the subsequent thromboembolic phase.
One of the lessons learned during the COVID-19 pandemic is that some of the key discoveries for the successful treatment of a novel disease emerge from the experience of the frontline doctors that are directly confronted with the need to find a way to help their patients. A conceptual understanding of the biological mechanisms via which a disease agent infects and harms patients can be used to rapidly identify therapeutic strategies, based on repurposed drugs, that may counter the disease and its sequelae. In the absence of proven and effective treatment protocols, physicians have a
duty to treat, with informed consent from their patients, requiring an effort to innovate and/or adopt such novel therapeutic strategies, in order to immediately reduce hospitalizations and deaths and to alleviate suffering [
66]. Although the orthodox approach is to consider possible treatments as unproven until they are validated with an RCT, in real life, it is possible to be confronted with a situation where the real-world observational data that result from clinical practice are sufficiently strong to justify the immediate adoption of a newly discovered treatment protocol, and to raise the ethical concern of whether it is appropriate to even conduct the RCT, and deny treatment to a very large cohort of patients, in order to form a control group [
18]. Consequently, there is a need to be able to analyze the quality of observational data in a statistically rigorous way.
We have provided a hybrid statistical framework for assessing observational evidence that combines both frequentist and Bayesian methods; the frequentist methods aim to control the p-value for rejecting the null hypothesis, whereas the Bayesian methods aim to control the false positive rate. The two methods are complementary and not mutually exclusive. We have also proposed a formalism for assessing the signal of efficacy with respect to both random and systemic selection bias, and explain how it can be integrated with the proposed hybrid frequentist–Bayesian method. We stress that the method aims to answer only the question of whether we are confident that the proposed treatment protocol works, in order to facilitate the binary choice of whether or not it should be adopted. An exact measurement of the efficacy is not our primary concern; we only need to establish positive as opposed to null or negative efficacy.
The main weakness of the proposed statistical methodology is that it has to be limited only to the assessment of treatments that are based on repurposed medications [
17] with known acceptable safety. It would be highly inappropriate to use this approach on new medications, or other countermeasures, where the balance of risks and benefits is yet to be determined. Furthermore, the analysis of the treatment group case series needs to be compared with a model that can, at minimum, lower-bound the probability of adverse outcomes without treatment, based on our prior knowledge. On the other hand, the development of this model can be done independently from the analysis of the treatment group case series.
One way in which our approach deviates from the usual way of doing things is that we are using the proposed statistical methodology to assess the efficacy of the entire treatment algorithm against supportive care. Both the original Zelenko protocol [
2] and the more enhanced McCullough protocol [
14,
15,
16] are examples of sequenced multidrug treatment protocols. Furthermore, both protocols are algorithmic, in the sense that treatment is customized to the individual patient based on the patient’s medical history and the response to treatment. For the case of the Zelenko protocol [
2] this is done via the risk stratification of patients to low-risk and high-risk patients. For the case of the McCullough protocol [
14,
15,
16], this is done both by risk stratification and also by accounting for the progression of the illness through the three distinct stages and response to treatment. Consequently, the immediate goal is not to establish that any one particular drug is effective. The goal is to establish that the treatment algorithm itself is effective, so that it can be deployed rapidly on an emergency basis and be subsequently improved over time with further research.
A possible theoretical criticism is that the particular case series that we have analyzed may have selection bias. This is mitigated, to some extent, by having reported case series from three different treatment centers, two in the United States and one in France, with consistent mortality rates; this consistency is compelling statistical evidence against geographic selection bias. More importantly, for both of the Zelenko [
2,
9,
10] and Procter [
11,
12] case series, we have two consecutive reports over two consecutive time intervals replicating the hospitalization and mortality rate reduction outcomes, and these replications are additional statistical evidence against reporting selection bias. Furthermore, the treatment protocols have known biological mechanisms of action that have been reviewed in
Section 1. Finally, we have introduced the idea of random selection bias thresholds that can be used to account for random selection bias. For the Zelenko June 2020 [
10], Procter II [
12], and Raoult [
13] case series, we can have 95% confidence that random selection bias cannot be entirely responsible for the positive signal of benefit in mortality and hospitalization rate reduction. Furthermore, for the Raoult case series [
13], systemic selection bias that favors the selection of high-risk healthy patients by a factor of up to
(a conservative estimate) is not sufficient to overturn the positive signal of efficacy.
The case series that we have analyzed in this paper add up to a total of 3164 high-risk patients. It is currently estimated that the total number of high-risk patients that have been treated with early outpatient treatment protocols throughout the United States may exceed this number by one or two orders of magnitude [
99]. Unfortunately, no resources have been allocated to study this data by our public health agencies, but we can make some suggestions about how such an analysis could be carried out. One idea for quickly analyzing a very large data set is to extract the
and/or
part of the database, calculate the corresponding efficacy thresholds for hospitalization rate reduction and mortality rate reduction, and compare them with the CDC estimates [
62,
63,
64] for number of hospitalizations and deaths for these age groups over the total number of cases with symptomatic illness. Given a large enough data set, it would also be interesting to further risk stratify the
and/or
cohorts with respect to number of days between initial symptoms and initiation of treatment, and calculate the efficacy thresholds as a function of the delay in initiating treatment. This analysis would inadvertently not include younger patients that are high risk due to comorbidities or shortness of breath presentation, however, it has the advantage that it can be carried out quickly with limited resources.
Furthermore, it would be useful to break down the case series data in sequential time intervals corresponding to different waves and different variants of the SARS-CoV-2 (Severe Acute Respiratory Syndrome Coronavirus 2) virus. The case series considered in this paper are limited to 2020, before the vaccine roll out, during which natural immunity held up at preventing reinfection [
100] up until the emergence of the omicron variants near the end of 2021, which broke through natural immunity from previous variants, but also provided back immunity to the delta variant [
101]. Nevertheless, in terms of general methodology, it would also be useful to subject any results to sensitivity analysis with respect to host immunity (i.e., history of previous infection and or vaccination status), as needed. Analyzing the data from several more treatment centers that have adopted early outpatient treatment protocols for high-risk patients would further mitigate the potential for selection bias.
With substantial resources, a more detailed analysis, based on the virtual control group methodology [
18], is possible that can consider the entire data set and actually estimate the treatment efficacy. Given a case series of
N patients, one can input the medical history of each patient to the Cleveland Clinic calculator [
95] and use their mathematical model to predict the probability of hospitalization and death for each patient individually. Knowing the corresponding sequence of probabilities
for an adverse outcome (hospitalization or death) for all patients, the probability
of seeing
a adverse outcomes follows a Poisson binomial distribution [
102], and it can be substituted to Equation (
2) in order to calculate the
p-value for rejecting the null hypothesis of no treatment efficacy. Because the probability of an adverse outcome is known for each patient, note that there is no need to worry about selection bias or calculating any efficacy thresholds, and it is possible instead to directly calculate the
p-value for rejecting the null hypothesis. Furthermore, since the mean of the Poisson binomial distribution is the average
of the individual probabilities, one can calculate the risk ratio via the equation
. To conduct the corresponding Bayesian analysis, we can assume that the effect of the early outpatient treatment is to reduce the probabilities of adverse outcome by a numerical factor
x to
with
and use the Poisson binomial distribution
in Equation (29) and Equation (32) to calculate the corresponding integrals needed for the Bayesian factor. All other aspects of the Bayesian analysis would remain the same, except that the hypothesis being validated would not concern any efficacy thresholds, but would instead concern hypotheses about the actual efficacy
x of the early outpatient treatment protocol.
That said, we do not mean to imply that such a detailed analysis is necessary in order to greenlight the use of the investigated early outpatient treatment protocols for COVID-19. However, we wish to highlight that such a detailed analysis is indeed possible to carry out, using existing data and prior mathematical modeling, in order to validate the McCullough protocol. A limitation of the Cleveland Clinic calculator is that it should ideally be used in conjunction with case series over time intervals that are aligned with the data set used to train the calculator’s mathematical predictive model. Because the Cleveland Clinic calculator used data collected between 4 March 2020 and 14 July 2020 it can certainly be applied to case series up until July 2020. However, we believe that it can also be extended up until and including the delta variant, which became dominant towards the end of 2021, since all of these subsequent variants were just as hard to treat or harder than the initial waves in 2020.
Notwithstanding the hesitancy confronting the adoption of early treatment protocols for COVID-19 [
94,
103], everything that we have been through during the last two years vindicates the position of Frieden [
54] that there is an urgent need to leverage and overcome the limitations of real-world evidence data, in order to deploy a timely life-saving response to urgent health issues. Although case series real-world data is viewed as imperfect from an epidemiological viewpoint, this viewpoint is predicated on the goal being the
unbiased measurement of treatment efficacy. We have explained how case series data of high-risk patients for a treatment protocol based on repurposed medications, combined with our prior knowledge of population-level probabilities for adverse binary outcomes, can be used to answer the simpler question of whether or not the treatment protocol actually works (i.e., showing only the
existence of efficacy), in order to make the up or down decision about whether or not to adopt it. The proposed statistical framework also provides a rigorous technique for quantifying the quality of these data. This can help to make objective policies on the appropriate thresholds for adopting such treatments as a standard of care. There is still an opportunity to learn much by analyzing data from various treatment centers here in the United States that treated COVID-19 with early outpatient treatment protocols, as well as treatment centers from all around the world. It is also necessary to reflect on and develop policies and procedures for leveraging the direct experience of frontline doctors treating patients towards an agile and effective response to future epidemics and pandemics.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}