

An Exploratory Study of Tweets about the SARS-CoV-2 Omicron Variant: Insights from Sentiment Analysis, Language Interpretation, Source Tracking, Type Classification, and Embedded URL Detection


Abstract
1. Introduction
- Sharing of symptoms, information, and experiences as reported by frontline workers and people who were infected with the virus [65].
- Providing suggestions, opinions, and recommendations to reduce the spread of the virus [66].
- Communicating updates on vaccine development, clinical trials, and other forms of treatment [67].
- Sharing guidelines mandated by various policy-making bodies, such as mask mandate, social distancing, etc., that were required to be followed by members in specific geographic regions of the world under the authority of the associated policy-making bodies [68].
- Dissemination of misinformation such as the use of certain drugs or forms of treatment that have not been tested or have not undergone clinical trials [69].
- Creating and spreading conspiracy theories such as considering 5G technologies responsible for the spread of COVID-19, which eventually led to multiple 5G towers being burnt down in the United Kingdom [70].
- Studying public opposition to available vaccines in different parts of the world [71].
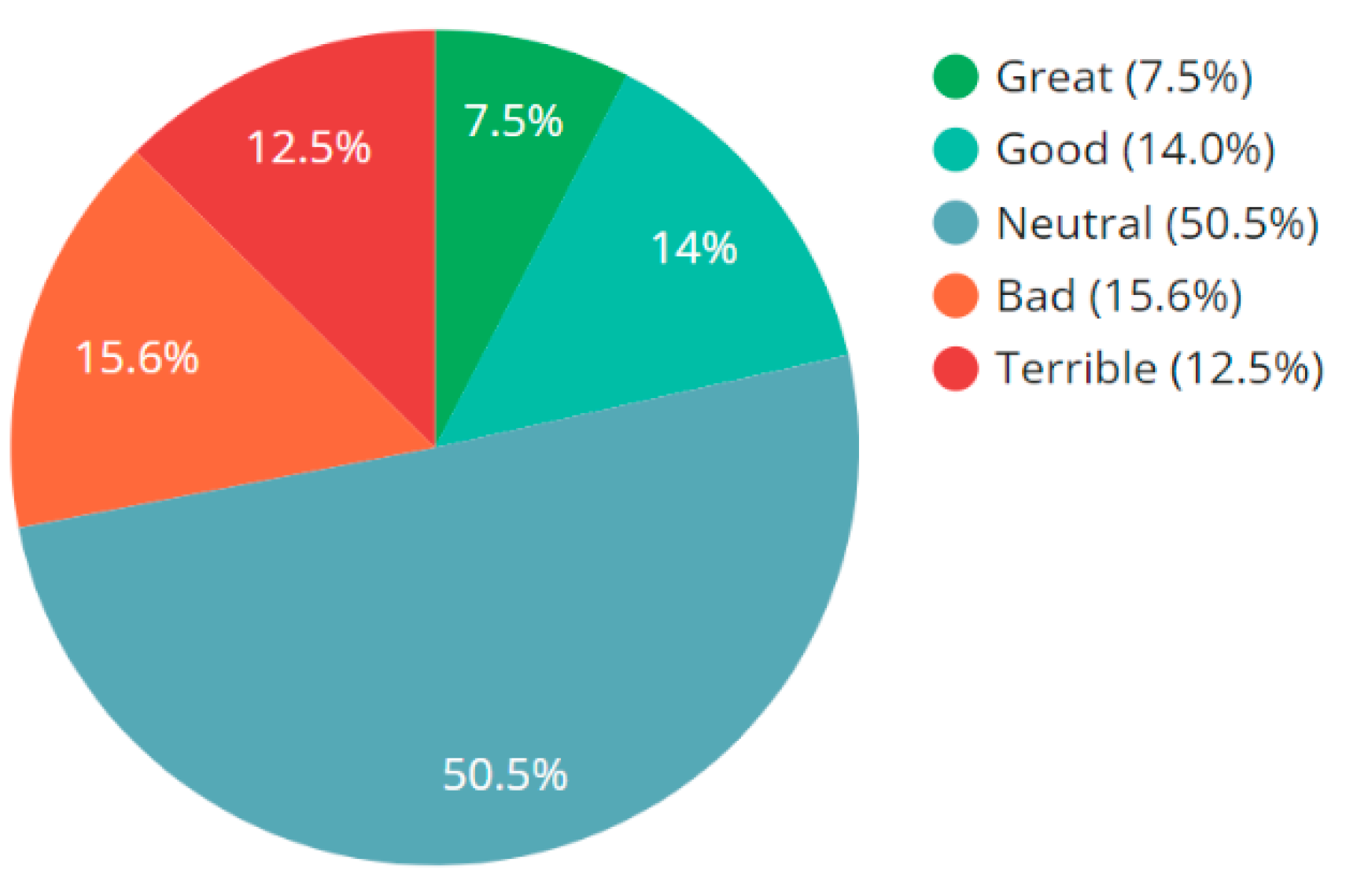
- The results from sentiment analysis showed that a majority of the tweets (50.5%) had a ‘neutral’ emotion, which was followed by the emotional states of ‘bad’, ‘good’, ‘terrible’, and ‘great’ that were found in 15.6%, 14.0%, 12.5%, and 7.5% of the tweets, respectively.
- The results from tweet source tracking showed that 35.2% of the Tweets were posted from an Android source, which was followed by the Twitter Web App, iPhone, iPad, TweetDeck, and other sources that accounted for 29.2%, 25.8%, 3.8%, 1.6%, and <1% of the tweets, respectively.
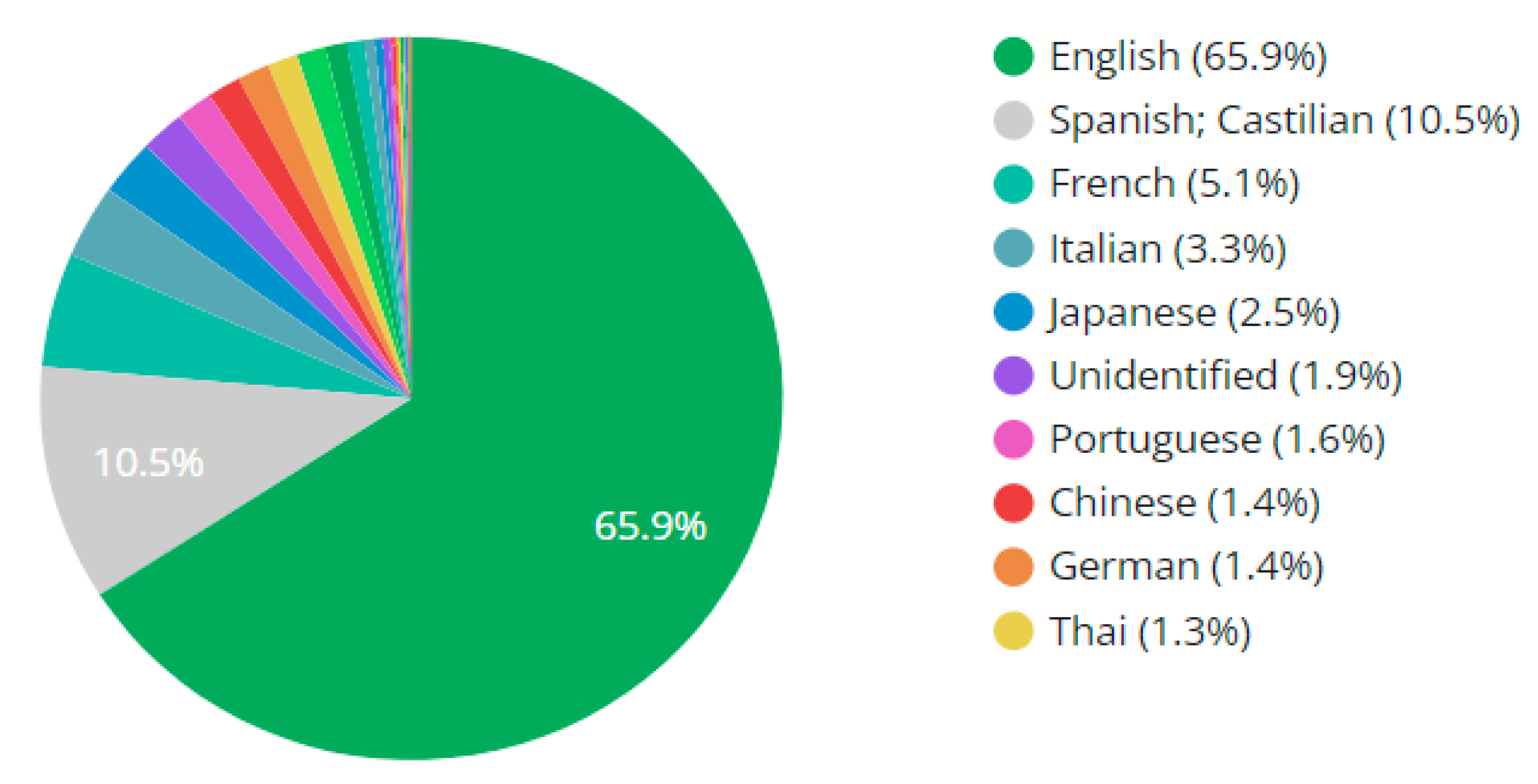
- The results from tweet language interpretation showed that 65.9% of the tweets were posted in English, which was followed by Spanish or Castillian (10.5%), French (5.1%), Italian (3.3%), Japanese (2.5%), and other languages that accounted for <2% of the tweets.
- The results from tweet type classification showed that the majority of the tweets (60.8%) were retweets which was followed by original tweets (19.8%) and replies (19.4%).
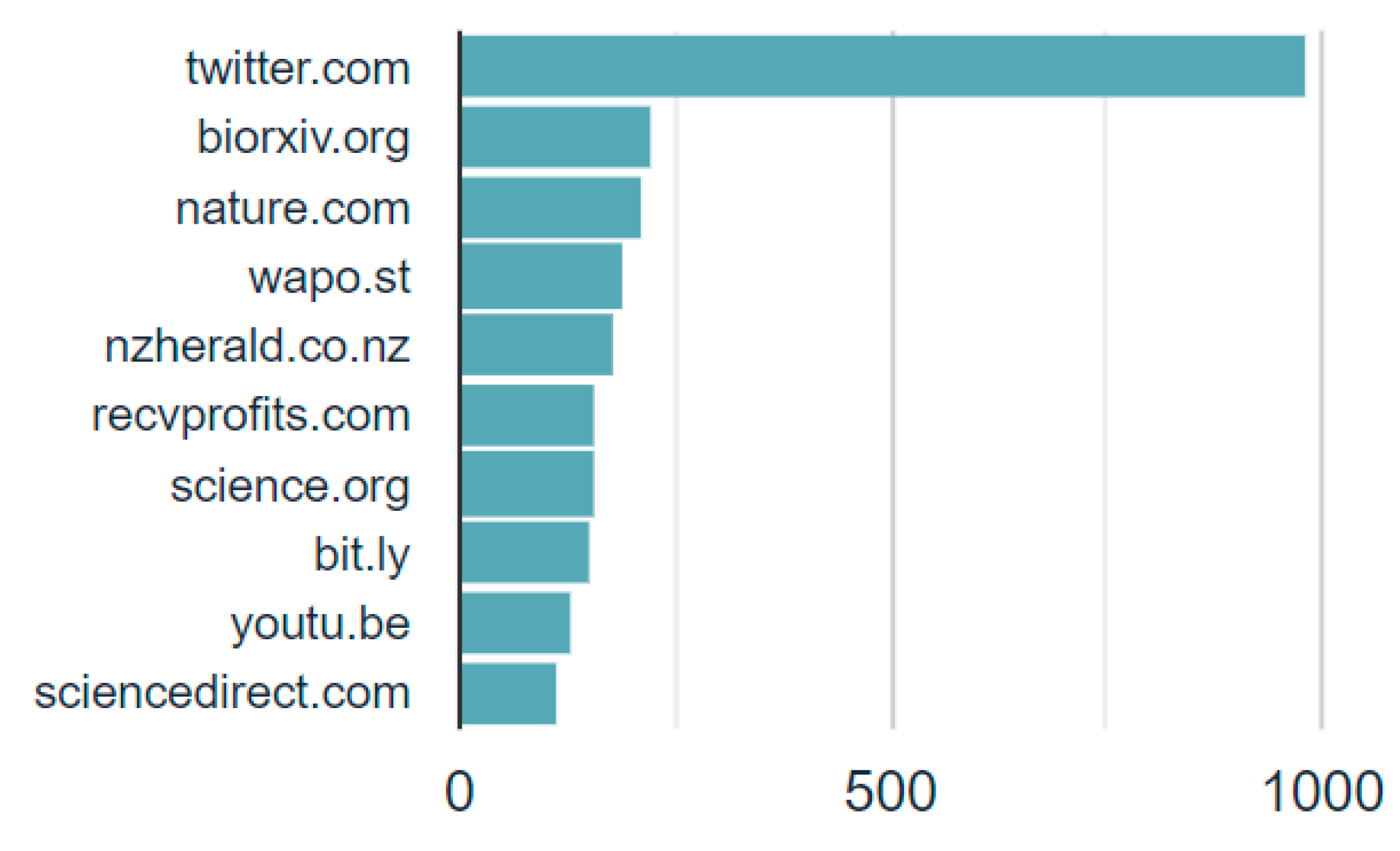
- The results from embedded URL analysis showed that the most common domain embedded in the tweets was twitter.com, which was followed by biorxiv.org, nature.com, wapo.st, nzherald.co.nz, recvprofits.com, science.org, and a few other domains.
2. Literature Review
- Most of these works used approaches to detect tweets that contained one or more keywords, hashtags, or phrases such as “COVID-19”, “coronavirus”, “SARS-CoV-2”, “covid”, “corona,” etc., but none of these works focused on including one or more keywords directly related to the SARS-CoV-2 Omicron variant to include the associated tweets. As the SARS-CoV-2 Omicron variant is now responsible for most of the COVID-19 cases globally, the need in this context is to filter tweets that contain one or more keywords, hashtags, or phrases related to this variant.
- The works on sentiment analysis [88,89] focused on the proposal of new approaches to detect the sentiment associated with tweets; however, the categories for classification of the associated sentiment were only ‘positive’, ‘negative’, and ‘neutral’. In a realistic scenario, there can be different kinds of ‘positive’ emotions, such as ‘good’ and ‘great’. Similarly, there can be different kinds of ‘negative’ emotions, such as ‘bad’ and ‘terrible’. The existing works cannot differentiate between these kinds of positive or negative emotions. Therefore, the need in this context is to expand the levels of sentiment classification to include the different kinds of positive and negative emotions.
- While there have been multiple innovations in this field of Twitter data analysis, such as detecting trending topics [90], anomaly events [91], public perceptions towards C.D.C. [92], and views towards not wearing masks [93], just to name a few, there has been minimal work related to quantifying and ranking the associated insights.
- The number of tweets that were included in previous studies (such as 4081 tweets in [102] and 4492 tweets in [100]) comprises a very small percentage of the total number of tweets that have been posted related to COVID-19 since the beginning of the outbreak. Therefore, the need in this context is to include more tweets in the studies.
3. Materials and Methods
3.1. Compliance with Twitter Policies
3.2. Overview of Social Bearing
- The traditional approach of searching tweets based on keyword search involves a series of steps, which include setting up a Twitter developer account, obtaining the GET oauth/authorizes code, obtaining the GET oauth/authenticate code, obtaining the Bearer Token, obtaining the Twitter API Access Token and Secret, and manually entering the same in a given application (such as a Python program) to connect with the Twitter API. As this research tool is already set up to work in accordance with the privacy policy, developer agreement, and developer policies of Twitter, therefore, the manual entry of all the above-mentioned codes and tokens is not required, and the process of connecting with the Twitter API to search tweets is simplified; it can be performed by just clicking the Twitter Sign-In button on the visual interface, and then the user is directed to sign into Twitter with an active Twitter account, thereafter, the tool is set up to work by searching tweets based on the keyword(s) or the hashtag(s).
- The tool uses the in-built JavaScript, text processing and text analysis libraries and algorithms to extract characteristics from the relevant tweets and displays the same on the visual interface in the form of results, thereby reducing the time and complexity of developing these algorithms and functions from scratch as well as for developing the approaches for visualizing the results.
- While displaying the results, the tool shows a list of users (with their Twitter usernames), who posted the tweets, in the “All Contributors” section. It allows removing one or more users from this list (if the usernames indicate that the Twitter profiles are bots) so that the new results are obtained based on the tweets posted by the rest of the users.
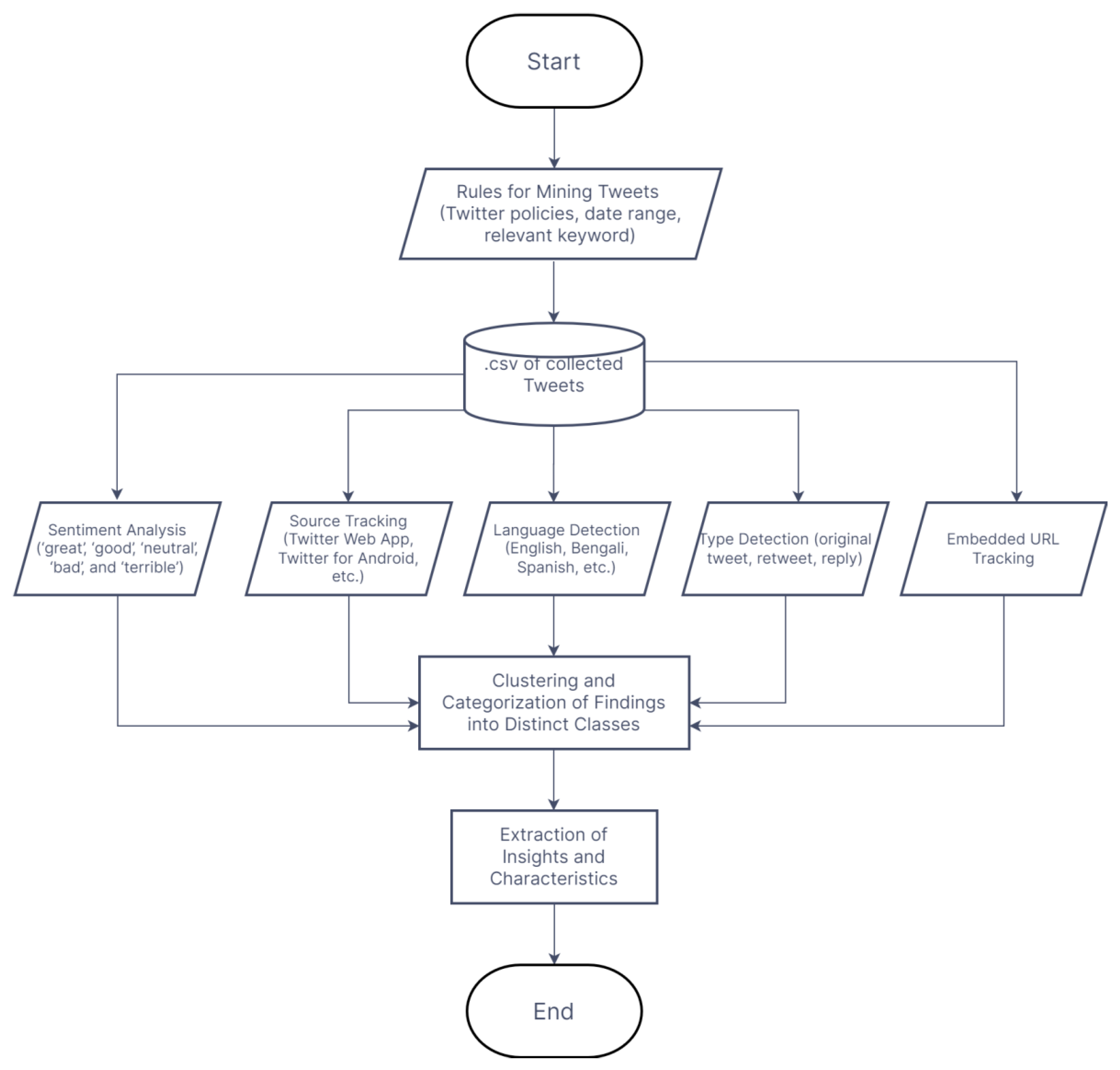
3.3. Methodology
3.4. Data Availability
3.4.1. Compliance with Guidelines for Twitter Content Redistribution
3.4.2. Compliance with FAIR
3.4.3. Data Description
3.4.4. Instructions for Using the Dataset
- Download and install the desktop version of the Hydrator app from https://github.com/DocNow/hydrator/releases (accessed on 14 May 2022).
- Click on the “Link Twitter Account” button on the Hydrator app to connect the app to an active Twitter account.
- Click on the “Add” button to upload one of the dataset files (such as Tweet IDs_November.txt). This process adds a dataset file to the Hydrator app.
- If the file upload is successful, the Hydrator app will show the total number of Tweet IDs present in the file. For instance, for the file—“TweetIDs_November.txt “, the app would show the number of Tweet IDs as 16,471.
- Provide details for the respective fields: Title, Creator, Publisher, and URL in the app, and click on “Add Dataset” to add this dataset to the app.
- The app will automatically redirect to the “Datasets” tab. Click on the “Start” button to start hydrating the Tweet IDs. During the hydration process, the progress indicator will increase, indicating the number of Tweet IDs that have been successfully hydrated and the number of Tweet IDs that are pending hydration.
- After the hydration process ends, a .jsonl file will be generated by the app that the user can choose to save on the local storage.
- The app would also display a “CSV” button in place of the “Start” button. Clicking on this “CSV” button would generate a .csv file with detailed information about the tweets, which would include the text of the tweet, User ID, username, retweet count, language, tweet URL, source, and other public information related to the tweet.
- Repeat steps 3–8 for hydrating all the files of this dataset.
4. Results and Discussions
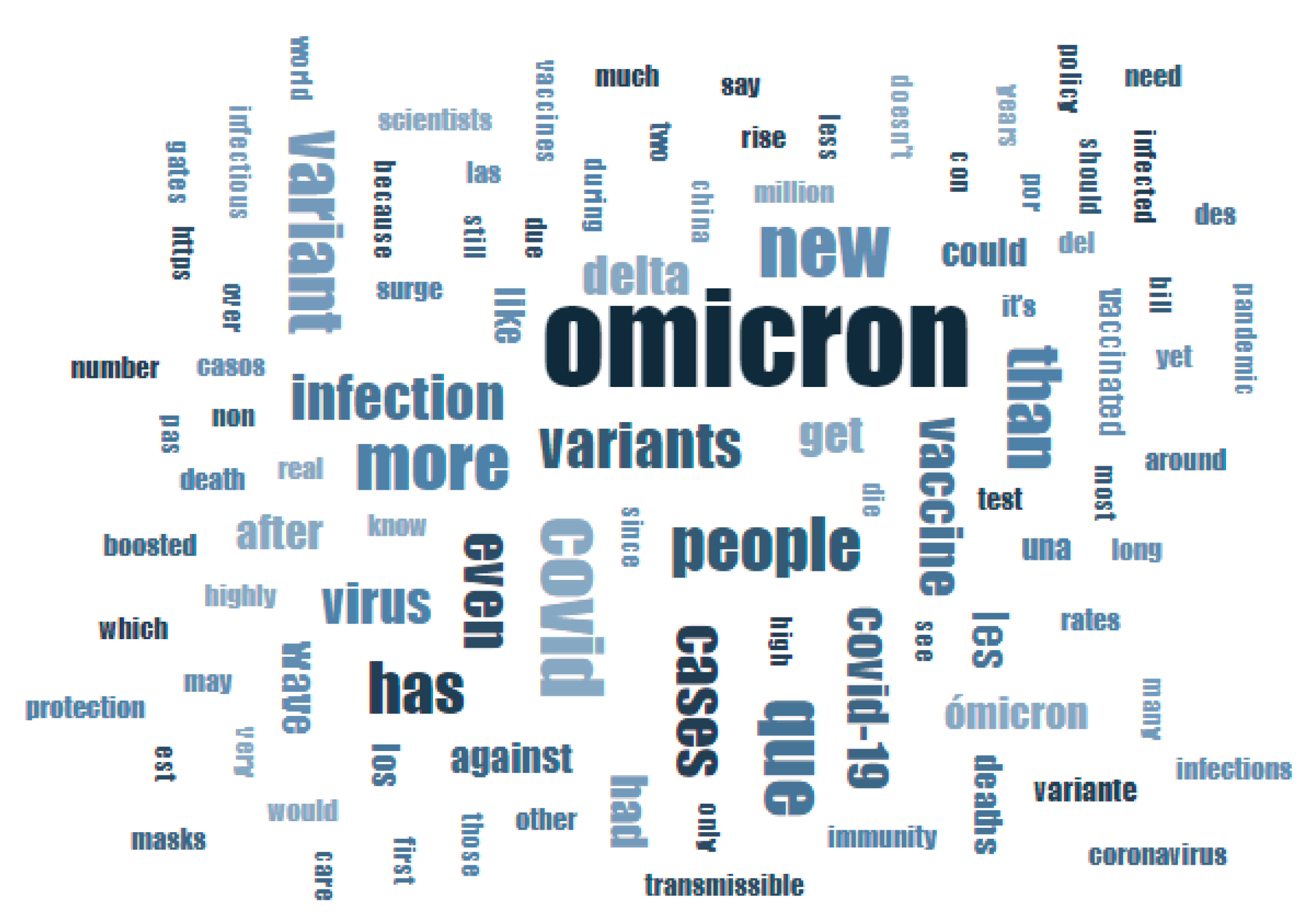
- The previous works in this field proposed approaches to filter tweets based on one or more keywords, hashtags, or phrases such as “COVID-19”, “coronavirus”, “SARS-CoV-2”, “covid”, “corona” but did not contain any keyword or phrase specifically related to the Omicron variant. Given this, those approaches for tweet searching or tweet filtering might not be applicable to collect the tweets posted about the Omicron variant unless the Twitter user specifically mentions something like “COVID-19 omicron variant” or “SARS-CoV-2 Omicron variant” in their tweets. As discussed in Section 3, there were multiple instances when the Twitter users did not use keywords, hashtags, or phrases such as “COVID-19”, “coronavirus”, “SARS-CoV-2”, “covid”, “corona” along with the keyword or hashtag “Omicron”. Thus, the need is to develop an approach to specifically mine tweets posted about the Omicron variant. This work addresses this need by proposing a methodology that searches tweets based on the presence of “Omicron” either as a keyword or as a hashtag. The effectiveness of this approach is justified by the word clouds presented in Figure 8 and Figure 9.
- The prior works [88,89] on sentiment analysis of tweets about COVID-19 focused on developing approaches for classifying the sentiment only into three classes—‘positive’, ‘negative’, and ‘neutral’. In a realistic scenario, there can be different kinds of ‘positive’ emotions, such as ‘good’ and ‘great’. Similarly, there can be different kinds of ‘negative’ emotions, such as ‘bad’ and ‘terrible’. The existing works cannot differentiate between these kinds of positive or negative emotions. To address the need in this context, associated with increasing the number of classes for classification of the sentiment of the tweet, this work proposes an approach that classifies tweets into five sentiment classes: ‘great’, ‘good’, ‘neutral’, ‘bad’, and ‘terrible’ (Figure 3).
- The emerging works in this field, for instance, related to detecting trending topics [90], anomaly events [91], public perceptions towards C.D.C. [92], and views towards not wearing masks [93], focused on the development of new frameworks and methodologies without focusing on quantifying the multimodal components of the characteristics of the tweets and ranking these characteristics to infer insights about social media activity on Twitter due to COVID-19. This work addresses this need. The results from sentiment analysis, type detection, source tracking, language interpretation, and embedded URL observation were categorized into distinct categories, and these categories were ranked in terms of the associated characteristics to infer meaningful and relevant insights about social media activity on Twitter related to tweets posted about the SARS-CoV-2 Omicron variant (Figure 3, Figure 4, Figure 5, Figure 6 and Figure 7). For instance, for tweet type analysis, the findings of this study show that “Twitter for Android” accounted for the most number of tweets (35.2% of the total tweets), which was followed by “Twitter Web App” (29.2% of the total tweets), “Twitter for iPhone” (25.8% of the total tweets), and other sources.
- The previous works centered around performing data analysis on tweets related to COVID-19, included a small corpus of tweets, such as 4081 tweets in [102] and 4492 tweets in [100]. In view of the number of active Twitter users and the number of tweets posted each day, there is a need to include more tweets in the data analysis process. This work addresses this need by considering a total of 12,028 relevant tweets that had a combined reach of 149,500,959, with 226,603,833 impressions, 1,053,869 retweets, and 3,427,976 favorites.
- The development of Twitter datasets has been of significant importance and interest to the scientific community in the areas of Big Data mining, Data Analysis, and Data Science. This is evident from the recent Twitter datasets on 2020 U.S. Presidential Elections [72], 2022 Russia–Ukraine war [73], climate change [74], natural hazards [75], European Migration Crisis [76], movies [77], toxic behavior amongst adolescents [78], music [79], civil unrest [80], drug safety [81], and Inflammatory Bowel Disease [82]. Twitter datasets help to serve as a data resource for a wide range of applications and use cases. For instance, the Twitter dataset on music [79] has helped in the development of a context-aware music recommendation system [137], next-track music recommendations as per user personalization [138], session-based music recommendation algorithms [139], music recommendation systems based on the use of affective hashtags [140], music chart predictions [141], user-curated playlists [142], sentiment analysis of music [143], listener engagement with popular songs [144], culture aware music recommendation systems [145], mining of user personalities [146], and several other applications. The works related to the development of Twitter datasets on COVID-19 [83,84,85,86,87] in the last few months did not focus on the development of a Twitter dataset comprising tweets about the Omicron variant of COVID-19 since the first detected case of this variant. To address this research gap, we developed a Twitter dataset (Section 3.4) that comprises 522,886 Tweet IDs of the same number of tweets about the Omicron variant of COVID-19 since the first detected case of this variant on 24 November 2021.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ksiazek, T.G.; Erdman, D.; Goldsmith, C.S.; Zaki, S.R.; Peret, T.; Emery, S.; Tong, S.; Urbani, C.; Comer, J.A.; Lim, W.; et al. A Novel Coronavirus Associated with Severe Acute Respiratory Syndrome. N. Engl. J. Med. 2003, 348, 1953–1966. [Google Scholar] [CrossRef] [PubMed]
- Fauci, A.S.; Lane, H.C.; Redfield, R.R. Covid-19—Navigating the Uncharted. N. Engl. J. Med. 2020, 382, 1268–1269. [Google Scholar] [CrossRef] [PubMed]
- Wilder-Smith, A.; Chiew, C.J.; Lee, V.J. Can we contain the COVID-19 outbreak with the same measures as for SARS? Lancet Infect. Dis. 2020, 20, e102–e107. [Google Scholar] [CrossRef]
- Cucinotta, D.; Vanelli, M. WHO declares COVID-19 a pandemic. Acta Biomed. 2020, 91, 157–160. [Google Scholar] [CrossRef]
- COVID Live—Coronavirus Statistics—Worldometer. Available online: https://www.worldometers.info/coronavirus/ (accessed on 14 May 2022).
- Huang, C.; Wang, Y.; Li, X.; Ren, L.; Zhao, J.; Hu, Y.; Zhang, L.; Fan, G.; Xu, J.; Gu, X.; et al. Clinical Features of Patients Infected with 2019 Novel Coronavirus in Wuhan, China. Lancet 2020, 395, 497–506. [Google Scholar] [CrossRef]
- Lauring, A.S.; Hodcroft, E.B. Genetic Variants of SARS-CoV-2—What Do They Mean? JAMA 2021, 325, 529–531. [Google Scholar] [CrossRef] [PubMed]
- Khare, S.; Gurry, C.; Freitas, L.; Schultz, M.B.; Bach, G.; Diallo, A.; Akite, N.; Ho, J.; Lee, R.T.; Yeo, W.; et al. GISAID’s Role in Pandemic Response. China CDC Wkly. 2021, 3, 1049–1051. [Google Scholar] [CrossRef]
- Global Initiative on Sharing All Influenza Data. GISAID—Initiative. Available online: https://www.gisaid.org/ (accessed on 14 May 2022).
- Centers for Disease Control and Prevention. SARS-CoV-2 Variant Classifications and Definitions. Available online: https://www.cdc.gov/coronavirus/2019-ncov/variants/variant-classifications.html (accessed on 14 May 2022).
- World Health Organization. Classification of Omicron (B.1.1.529): SARS-CoV-2 Variant of Concern. Available online: https://www.who.int/news/item/26-11-2021-classification-of-omicron-(b.1.1.529)-sars-cov-2-variant-of-concern (accessed on 14 May 2022).
- Gobeil, S.M.-C.; Henderson, R.; Stalls, V.; Janowska, K.; Huang, X.; May, A.; Speakman, M.; Beaudoin, E.; Manne, K.; Li, D.; et al. Structural diversity of the SARS-CoV-2 Omicron spike. Mol. Cell 2022, 82, 2050–2068.e6. [Google Scholar] [CrossRef]
- Schmidt, F.; Muecksch, F.; Weisblum, Y.; Da Silva, J.; Bednarski, E.; Cho, A.; Wang, Z.; Gaebler, C.; Caskey, M.; Nussenzweig, M.C.; et al. Plasma Neutralization of the SARS-CoV-2 Omicron Variant. N. Engl. J. Med. 2022, 386, 599–601. [Google Scholar] [CrossRef]
- Hoffmann, M.; Krüger, N.; Schulz, S.; Cossmann, A.; Rocha, C.; Kempf, A.; Nehlmeier, I.; Graichen, L.; Moldenhauer, A.-S.; Winkler, M.S.; et al. The Omicron variant is highly resistant against antibody-mediated neutralization: Implications for control of the COVID-19 pandemic. Cell 2022, 185, 447–456.e11. [Google Scholar] [CrossRef]
- Francis, A.I.; Ghany, S.; Gilkes, T.; Umakanthan, S. Review of COVID-19 vaccine subtypes, efficacy and geographical distributions. Postgrad. Med. J. 2022, 98, 389–394. [Google Scholar] [CrossRef] [PubMed]
- Gavriatopoulou, M.; Ntanasis-Stathopoulos, I.; Korompoki, E.; Fotiou, D.; Migkou, M.; Tzanninis, I.-G.; Psaltopoulou, T.; Kastritis, E.; Terpos, E.; Dimopoulos, M.A. Emerging treatment strategies for COVID-19 infection. Clin. Exp. Med. 2021, 21, 167–179. [Google Scholar] [CrossRef] [PubMed]
- World Health Organization. Weekly Epidemiological Update on COVID-19—22 March 2022. Available online: https://www.who.int/publications/m/item/weekly-epidemiological-update-on-covid-19---22-march-2022 (accessed on 14 May 2022).
- Feiner, L. WHO Says Omicron Cases Are “Off the Charts” as Global Infections Set New Records. Available online: https://www.cnbc.com/2022/01/12/who-says-omicron-cases-are-off-the-charts-as-global-infections-set-new-records.html (accessed on 14 May 2022).
- SARS-CoV-2 Omicron Variant Cases Worldwide 2022. Available online: https://www.statista.com/statistics/1279100/number-omicron-variant-worldwide-by-country/ (accessed on 14 May 2022).
- Katz, M.; Nandi, N. Social Media and Medical Education in the Context of the COVID-19 Pandemic: Scoping Review. JMIR Med. Educ. 2021, 7, e25892. [Google Scholar] [CrossRef]
- Sharma, M.; Yadav, K.; Yadav, N.; Ferdinand, K.C. Zika virus pandemic—analysis of Facebook as a social media health information platform. Am. J. Infect. Control 2017, 45, 301–302. [Google Scholar] [CrossRef]
- Wiederhold, B.K. Social Media and Social Organizing: From Pandemic to Protests. Cyberpsychol. Behav. Soc. Netw. 2020, 23, 579–580. [Google Scholar] [CrossRef]
- Fung, I.C.-H.; Duke, C.H.; Finch, K.C.; Snook, K.R.; Tseng, P.-L.; Hernandez, A.C.; Gambhir, M.; Fu, K.-W.; Tse, Z.T.H. Ebola virus disease and social media: A systematic review. Am. J. Infect. Control 2016, 44, 1660–1671. [Google Scholar] [CrossRef] [PubMed]
- Ding, H. Social Media and Participatory Risk Communication during the H1N1 Flu Epidemic: A Comparative Study of the United States and China. China Media Res. 2010, 6, 80–91. [Google Scholar]
- Longley, P.A.; Adnan, M.; Lansley, G. The Geotemporal Demographics of Twitter Usage. Environ. Plan. A 2015, 47, 465–484. [Google Scholar] [CrossRef]
- Data Reportal. Twitter Statistics and Trends. Available online: https://datareportal.com/essential-twitter-stats (accessed on 14 May 2022).
- Lazard, A.J.; Scheinfeld, E.; Bernhardt, J.M.; Wilcox, G.B.; Suran, M. Detecting themes of public concern: A text mining analysis of the Centers for Disease Control and Prevention’s Ebola live Twitter chat. Am. J. Infect. Control 2015, 43, 1109–1111. [Google Scholar] [CrossRef]
- Bolotova, Y.V.; Lou, J.; Safro, I. Detecting and Monitoring Foodborne Illness Outbreaks: Twitter Communications and the 2015 U.S. Salmonella Outbreak Linked to Imported Cucumbers. arXiv 2017, arXiv:1708.07534. [Google Scholar]
- Gomide, J.; Veloso, A.; Meira, W., Jr.; Almeida, V.; Benevenuto, F.; Ferraz, F.; Teixeira, M. Dengue Surveillance Based on a Computational Model of Spatio-Temporal Locality of Twitter. In Proceedings of the 3rd International Web Science Conference on—WebSci ’11, Koblenz Germany, 15–17 June 2011; ACM Press: New York, NY, USA, 2011. [Google Scholar]
- Tomaszewski, T.; Morales, A.; Lourentzou, I.; Caskey, R.; Liu, B.; Schwartz, A.; Chin, J. Identifying False Human Papillomavirus (HPV) Vaccine Information and Corresponding Risk Perceptions from Twitter: Advanced Predictive Models. J. Med. Internet Res. 2021, 23, e30451. [Google Scholar] [CrossRef] [PubMed]
- Do, H.J.; Lim, C.-G.; Kim, Y.J.; Choi, H.-J. Analyzing Emotions in Twitter during a Crisis: A Case Study of the 2015 Middle East Respiratory Syndrome Outbreak in Korea. In Proceedings of the 2016 International Conference on Big Data and Smart Computing (BigComp), Hong Kong, China, 18–20 June 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 415–418. [Google Scholar]
- Radzikowski, J.; Stefanidis, A.; Jacobsen, K.H.; Croitoru, A.; Crooks, A.; Delamater, P.L. The Measles Vaccination Narrative in Twitter: A Quantitative Analysis. JMIR Public Health Surveill. 2016, 2, e5059. [Google Scholar] [CrossRef] [PubMed]
- Fu, K.-W.; Liang, H.; Saroha, N.; Tse, Z.T.H.; Ip, P.; Fung, I.C.-H. How people react to Zika virus outbreaks on Twitter? A computational content analysis. Am. J. Infect. Control 2016, 44, 1700–1702. [Google Scholar] [CrossRef] [PubMed]
- Signorini, A.; Segre, A.M.; Polgreen, P.M. The Use of Twitter to Track Levels of Disease Activity and Public Concern in the U.S. during the Influenza a H1N1 Pandemic. PLoS ONE 2011, 6, e19467. [Google Scholar] [CrossRef] [PubMed]
- Gesualdo, F.; Stilo, G.; Agricola, E.; Gonfiantini, M.V.; Pandolfi, E.; Velardi, P.; Tozzi, A.E. Influenza-Like Illness Surveillance on Twitter through Automated Learning of Naïve Language. PLoS ONE 2013, 8, e82489. [Google Scholar] [CrossRef] [PubMed]
- Szomszor, M.; Kostkova, P.; de Quincey, E. #swineflu: Twitter Predicts Swine Flu Outbreak in 2009. In Lecture Notes of the Institute for Computer Sciences, Social Informatics and Telecommunications Engineering; Springer: Berlin/Heidelberg, Germany, 2011; pp. 18–26. ISBN 9783642236341. [Google Scholar]
- Alessa, A.; Faezipour, M. Flu Outbreak Prediction Using Twitter Posts Classification and Linear Regression with Historical Centers for Disease Control and Prevention Reports: Prediction Framework Study. JMIR Public Health. Surveill. 2019, 5, e12383. [Google Scholar] [CrossRef]
- Hirschfeld, D. Twitter data accurately tracked Haiti cholera outbreak. Nature 2012. [Google Scholar] [CrossRef]
- Van Der Vyver, A.G. The Listeriosis Outbreak in South Africa: A Twitter Analysis of Public Reaction. Available online: http://www.icmis.net/icmis18/ICMIS18CD/pdf/S198-final.pdf (accessed on 14 May 2022).
- Thackeray, R.; Burton, S.H.; Giraud-Carrier, C.; Rollins, S.; Draper, C.R. Using Twitter for breast cancer prevention: An analysis of breast cancer awareness month. BMC Cancer 2013, 13, 508. [Google Scholar] [CrossRef]
- Da, B.L.; Surana, P.; Schueler, S.A.; Jalaly, N.Y.; Kamal, N.; Taneja, S.; Vittal, A.; Gilman, C.L.; Heller, T.; Koh, C. Twitter as a Noninvasive Bio-Marker for Trends in Liver Disease. Hepatol. Commun. 2019, 3, 1271–1280. [Google Scholar] [CrossRef]
- Khan, A.; Silverman, A.; Rowe, A.; Rowe, S.; Tick, M.; Testa, S.; Dodds, K.; Alabbas, B.; Borum, M.L. Who Is Saying What about Inflammatory Bowel Disease on Twitter? In Proceedings of the G. W. Research Days 2016–2020, Washington, DC, USA; 2018. [Google Scholar]
- McLean, R.; Shirazian, S. Women and Kidney Disease: A Twitter Conversation for One and All. Kidney Int. Rep. 2018, 3, 767–768. [Google Scholar] [CrossRef]
- Stens, O.; Weisman, M.H.; Simard, J.; Reuter, K. Insights from Twitter Conversations on Lupus and Reproductive Health: Protocol for a Content Analysis. JMIR Res. Protoc. 2020, 9, e15623. [Google Scholar] [CrossRef] [PubMed]
- Cevik, F.; Kilimci, Z.H. Analysis of Parkinson’s Disease using Deep Learning and Word Embedding Models. Acad. Perspect. Procedia 2019, 2, 786–797. [Google Scholar] [CrossRef]
- Porat, T.; Garaizar, P.; Ferrero, M.; Jones, H.; Ashworth, M.; Vadillo, M.A. Content and Source Analysis of Popular Tweets Following a Recent Case of Diphtheria in Spain. Eur. J. Public Health 2019, 29, 117–122. [Google Scholar] [CrossRef] [PubMed]
- Sugumaran, R.; Voss, J. Real-Time Spatio-Temporal Analysis of West Nile Virus Using Twitter Data. In Proceedings of the 3rd International Conference on Computing for Geospatial Research and Applications—C.O.M.Geo ’12, Reston, VA, USA, 1–3 July 2012; ACM Press: New York, NY, USA, 2012. [Google Scholar]
- Kim, E.H.-J.; Jeong, Y.K.; Kim, Y.; Kang, K.Y.; Song, M. Topic-based content and sentiment analysis of Ebola virus on Twitter and in the news. J. Inf. Sci. 2016, 42, 763–781. [Google Scholar] [CrossRef]
- Tully, M.; Dalrymple, K.E.; Young, R. Contextualizing Nonprofits’ Use of Links on Twitter During the West African Ebola Virus Epidemic. Commun. Stud. 2019, 70, 313–331. [Google Scholar] [CrossRef]
- Odlum, M.; Yoon, S. What can we learn about the Ebola outbreak from tweets? Am. J. Infect. Control 2015, 43, 563–571. [Google Scholar] [CrossRef]
- Su, C.-J.; Yon, J.A.Q. Sentiment Analysis and Information Diffusion on Social Media: The Case of the Zika Virus. Int. J. Inf. Educ. Technol. 2018, 8, 685–692. [Google Scholar] [CrossRef][Green Version]
- Wood, M.J. Propagating and Debunking Conspiracy Theories on Twitter During the 2015–2016 Zika Virus Outbreak. Cyberpsychol. Behav. Soc. Netw. 2018, 21, 485–490. [Google Scholar] [CrossRef]
- Ghenai, A.; Mejova, Y. Catching Zika Fever: Application of Crowdsourcing and Machine Learning for Tracking Health Misinformation on Twitter. arXiv 2017, arXiv:1707.03778. [Google Scholar]
- Yang, J.-A.J. Spatial-Temporal Analysis of Information Diffusion Patterns with User-Generated Geo-Social Contents from Social Media. Ph.D. Thesis, San Diego State University, San Diego, CA, USA, 2017. [Google Scholar]
- Barata, G.; Shores, K.; Alperin, J.P. Local chatter or international buzz? Language differences on posts about Zika research on Twitter and Facebook. PLoS ONE 2018, 13, e0190482. [Google Scholar] [CrossRef]
- Maci, S.M.; Sala, M. Corpus Linguistics and Translation Tools for Digital Humanities: Research Methods and Applications; Maci, S.M., Sala, M., Eds.; Bloomsbury Academic: London, UK, 2022; ISBN 9781350275232. [Google Scholar]
- Alessa, A.; Faezipour, M. Tweet Classification Using Sentiment Analysis Features and TF-IDF Weighting for Improved Flu Trend Detection. In Machine Learning and Data Mining in Pattern Recognition; Springer International: Cham, Switzerland, 2018; pp. 174–186. ISBN 9783319961354. [Google Scholar]
- Lamb, A.; Paul, M.J.; Dredze, M. Separating Fact from Fear: Tracking Flu Infections on Twitter. Available online: https://aclanthology.org/N13-1097.pdf (accessed on 6 July 2022).
- Lee, K.; Mahmud, J.; Chen, J.; Zhou, M.; Nichols, J. Who Will Retweet This?: Automatically Identifying and Engaging Strangers on Twitter to Spread Information. In Proceedings of the 19th International Conference on Intelligent User Interfaces, New York, NY, USA, 24–27 February 2014; ACM: New York, NY, USA, 2014. [Google Scholar]
- Dai, X.; Bikdash, M.; Meyer, B. From Social Media to Public Health Surveillance: Word Embedding Based Clustering Method for Twitter Classification. In Proceedings of the SoutheastCon 2017, Concord, NC, USA, 20 March–2 April 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–7. [Google Scholar]
- Rahmanian, V.; Jahanbin, K. Using twitter and web news mining to predict COVID-19 outbreak. Asian Pac. J. Trop. Med. 2020, 13, 378. [Google Scholar] [CrossRef]
- Rosenberg, H.; Syed, S.; Rezaie, S. The Twitter pandemic: The critical role of Twitter in the dissemination of medical information and misinformation during the COVID-19 pandemic. Can. J. Emerg. Med. 2020, 22, 418–421. [Google Scholar] [CrossRef] [PubMed]
- Haman, M. The use of Twitter by state leaders and its impact on the public during the COVID-19 pandemic. Heliyon 2020, 6, e05540. [Google Scholar] [CrossRef] [PubMed]
- Alhayan, F.; Pennington, D.; Ayouni, S. Twitter Use by the Dementia Community during COVID-19: A User Classification and Social Network Analysis. Online Inf. Rev. 2022. ahead–of–print. [Google Scholar] [CrossRef]
- Guo, J.; Radloff, C.L.; Wawrzynski, S.E.; Cloyes, K.G. Mining twitter to explore the emergence of COVID-19 symptoms. Public Health Nurs. 2020, 37, 934–940. [Google Scholar] [CrossRef]
- Roy, S.; Ghosh, P. A Comparative Study on Distancing, Mask and Vaccine Adoption Rates from Global Twitter Trends. Healthcare 2021, 9, 488. [Google Scholar] [CrossRef]
- Yousefinaghani, S.; Dara, R.; Mubareka, S.; Papadopoulos, A.; Sharif, S. An analysis of COVID-19 vaccine sentiments and opinions on Twitter. Int. J. Infect. Dis. 2021, 108, 256–262. [Google Scholar] [CrossRef]
- Wang, S.; Schraagen, M.; Sang, E.T.K.; Dastani, M. Dutch General Public Reaction on Governmental COVID-19 Measures and Announcements in Twitter Data. arXiv 2020, arXiv:2006.07283. [Google Scholar]
- Krittanawong, C.; Narasimhan, B.; Virk, H.U.H.; Narasimhan, H.; Hahn, J.; Wang, Z.; Tang, W.W. Misinformation Dissemination in Twitter in the COVID-19 Era. Am. J. Med. 2020, 133, 1367–1369. [Google Scholar] [CrossRef]
- Ahmed, W.; Vidal-Alaball, J.; Downing, J.; Seguí, F.L. COVID-19 and the 5G Conspiracy Theory: Social Network Analysis of Twitter Data. J. Med. Internet Res. 2020, 22, e19458. [Google Scholar] [CrossRef]
- Bonnevie, E.; Gallegos-Jeffrey, A.; Goldbarg, J.; Byrd, B.; Smyser, J. Quantifying the rise of vaccine opposition on Twitter during the COVID-19 pandemic. J. Commun. Healthc. 2021, 14, 12–19. [Google Scholar] [CrossRef]
- Chen, E.; Deb, A.; Ferrara, E. #Election2020: The first public Twitter dataset on the 2020 US Presidential election. J. Comput. Soc. Sci. 2021, 5, 1–18. [Google Scholar] [CrossRef] [PubMed]
- Haq, E.-U.; Tyson, G.; Lee, L.-H.; Braud, T.; Hui, P. Twitter Dataset for 2022 Russo-Ukrainian Crisis. arXiv 2022, arXiv:2203.02955. [Google Scholar]
- Effrosynidis, D.; Karasakalidis, A.I.; Sylaios, G.; Arampatzis, A. The Climate Change Twitter Dataset. Expert Syst. Appl. 2022, 204, 117541. [Google Scholar] [CrossRef]
- Meng, L.; Dong, Z.S. Natural Hazards Twitter Dataset. arXiv 2020, arXiv:2004.14456. [Google Scholar]
- Urchs, S.; Wendlinger, L.; Mitrovic, J.; Granitzer, M. MMoveT15: A Twitter Dataset for Extracting and Analysing Migration-Movement Data of the European Migration Crisis 2015. In Proceedings of the 2019 IEEE 28th International Conference on Enabling Technologies: Infrastructure for Collaborative Enterprises (WETICE), Napoli, Italy, 12–14 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 146–149. [Google Scholar]
- Dooms, S.; De Pessemier, T.; Martens, L. MovieTweetings: A Movie Rating Dataset Collected from Twitter. In Proceedings of the Workshop on Crowdsourcing and Human Computation for Recommender Systems (CrowdRec 2013), Held in Conjunction with the 7th ACM Conference on Recommender Systems (RecSys 2013), Hong Kong, China, 12 October 2013. [Google Scholar]
- Wijesiriwardene, T.; Inan, H.; Kursuncu, U.; Gaur, M.; Shalin, V.L.; Thirunarayan, K.; Sheth, A.; Arpinar, I.B. ALONE: A Dataset for Toxic Behavior among Adolescents on Twitter. In Lecture Notes in Computer Science; Springer International: Cham, Switzerland, 2020; pp. 427–439. ISBN 9783030609740. [Google Scholar]
- Zangerle, E.; Pichl, M.; Gassler, W.; Specht, G. #nowplaying Music Dataset: Extracting Listening Behavior from Twitter. In Proceedings of the First International Workshop on Internet-Scale Multimedia Management—WISMM ’14, New York, NY, USA, 7 November 2014; ACM Press: New York, NY, USA, 2014. [Google Scholar]
- Sech, J.; DeLucia, A.; Buczak, A.L.; Dredze, M. Civil Unrest on Twitter (CUT): A Dataset of Tweets to Support Research on Civil Unrest. In Proceedings of the Sixth Workshop on Noisy User-Generated Text (W-NUT 2020), November 2020; Association for Computational Linguistics, Stroudsburg, PA, USA; 2020; pp. 215–221. [Google Scholar]
- Tekumalla, R.; Banda, J.M. A Large-Scale Twitter Dataset for Drug Safety Applications Mined from Publicly Existing Resources. arXiv 2020, arXiv:2003.13900. [Google Scholar]
- Stemmer, M.; Parmet, Y.; Ravid, G. What Are IBD Patients Talking about on Twitter? In ICT for Health, Accessibility and Wellbeing; Springer International: Cham, Switzerland, 2021; pp. 206–220. ISBN 9783030942083. [Google Scholar]
- Alqurashi, S.; Alhindi, A.; Alanazi, E. Large Arabic Twitter Dataset on COVID-19. arXiv 2020, arXiv:2004.04315. [Google Scholar]
- Hayawi, K.; Shahriar, S.; Serhani, M.; Taleb, I.; Mathew, S. ANTi-Vax: A novel Twitter dataset for COVID-19 vaccine misinformation detection. Public Health 2022, 203, 23–30. [Google Scholar] [CrossRef]
- Elhadad, M.K.; Li, K.F.; Gebali, F. COVID-19-FAKES: A Twitter (Arabic/English) Dataset for Detecting Misleading Information on COVID-19. In Advances in Intelligent Networking and Collaborative Systems; Springer International: Cham, Switzerland, 2021; pp. 256–268. ISBN 9783030577957. [Google Scholar]
- Haouari, F.; Hasanain, M.; Suwaileh, R.; Elsayed, T. ArCOV19-Rumors: Arabic COVID-19 Twitter Dataset for Misinformation Detection. arXiv 2020, arXiv:2010.08768. [Google Scholar]
- Cheng, M.; Wang, S.; Yan, X.; Yang, T.; Wang, W.; Huang, Z.; Xiao, X.; Nazarian, S.; Bogdan, P. A COVID-19 Rumor Dataset. Front. Psychol. 2021, 12, 644801. [Google Scholar] [CrossRef]
- Shamrat, F.M.J.M.; Chakraborty, S.; Imran, M.M.; Muna, J.N.; Billah, M.; Das, P.; Rahman, O. Sentiment analysis on twitter tweets about COVID-19 vaccines usi ng NLP and supervised KNN classification algorithm. Indones. J. Electr. Eng. Comput. Sci. 2021, 23, 463–470. [Google Scholar] [CrossRef]
- Sontayasara, T.; Jariyapongpaiboon, S.; Promjun, A.; Seelpipat, N.; Saengtabtim, K.; Tang, J.; Leelawat, N. Twitter Sentiment Analysis of Bangkok Tourism During COVID-19 Pandemic Using Support Vector Machine Algorithm. J. Disaster Res. 2021, 16, 24–30. [Google Scholar] [CrossRef]
- Asgari-Chenaghlu, M.; Nikzad-Khasmakhi, N.; Minaee, S. Covid-Transformer: Detecting COVID-19 Trending Topics on Twitter Using Universal Sentence Encoder. arXiv 2020, arXiv:2009.03947. [Google Scholar]
- Amen, B.; Faiz, S.; Do, T.-T. Big data directed acyclic graph model for real-time COVID-19 twitter stream detection. Pattern Recognit. 2022, 123, 108404. [Google Scholar] [CrossRef] [PubMed]
- Lyu, J.C.; Luli, G.K. Understanding the Public Discussion About the Centers for Disease Control and Prevention During the COVID-19 Pandemic Using Twitter Data: Text Mining Analysis Study. J. Med. Internet Res. 2021, 23, e25108. [Google Scholar] [CrossRef]
- Al-Ramahi, M.; Elnoshokaty, A.; El-Gayar, O.; Nasralah, T.; Wahbeh, A. Public Discourse Against Masks in the COVID-19 Era: Infodemiology Study of Twitter Data. JMIR Public Health Surveill. 2021, 7, e26780. [Google Scholar] [CrossRef]
- Jain, S.; Sinha, A. Identification of Influential Users on Twitter: A Novel Weighted Correlated Influence Measure for COVID-19. Chaos Solitons Fractals 2020, 139, 110037. [Google Scholar] [CrossRef]
- Madani, Y.; Erritali, M.; Bouikhalene, B. Using artificial intelligence techniques for detecting Covid-19 epidemic fake news in Moroccan tweets. Results Phys. 2021, 25, 104266. [Google Scholar] [CrossRef]
- Shokoohyar, S.; Berenji, H.R.; Dang, J. Exploring the heated debate over reopening for economy or continuing lockdown for public health safety concerns about COVID-19 in Twitter. Int. J. Bus. Syst. Res. 2021, 15, 650. [Google Scholar] [CrossRef]
- Chehal, D.; Gupta, P.; Gulati, P. COVID-19 pandemic lockdown: An emotional health perspective of Indians on Twitter. Int. J. Soc. Psychiatry 2021, 67, 64–72. [Google Scholar] [CrossRef]
- Glowacki, E.M.; Wilcox, G.B.; Glowacki, J.B. Identifying #addiction concerns on twitter during the COVID-19 pandemic: A text mining analysis. Subst. Abus. 2021, 42, 39–46. [Google Scholar] [CrossRef] [PubMed]
- Selman, L.E.; Chamberlain, C.; Sowden, R.; Chao, D.; Selman, D.; Taubert, M.; Braude, P. Sadness, despair and anger when a patient dies alone from COVID-19: A thematic content analysis of Twitter data from bereaved family members and friends. Palliat. Med. 2021, 35, 1267–1276. [Google Scholar] [CrossRef] [PubMed]
- Koh, J.X.; Liew, T.M. How loneliness is talked about in social media during COVID-19 pandemic: Text mining of 4,492 Twitter feeds. J. Psychiatr. Res. 2022, 145, 317–324. [Google Scholar] [CrossRef] [PubMed]
- Mackey, T.; Purushothaman, V.; Li, J.; Shah, N.; Nali, M.; Bardier, C.; Liang, B.; Cai, M.; Cuomo, R. Machine Learning to Detect Self-Reporting of Symptoms, Testing Access, and Recovery Associated with COVID-19 on Twitter: Retrospective Big Data Infoveillance Study. JMIR Public Health Surveill. 2020, 6, e19509. [Google Scholar] [CrossRef]
- Leung, J.; Chung, J.; Tisdale, C.; Chiu, V.; Lim, C.; Chan, G. Anxiety and Panic Buying Behaviour during COVID-19 Pandemic-A Qualitative Analysis of Toilet Paper Hoarding Contents on Twitter. Int. J. Environ. Res. Public Health 2021, 18, 1127. [Google Scholar] [CrossRef]
- Privacy Policy of Twitter. Available online: https://twitter.com/en/privacy/previous/version_15 (accessed on 15 May 2022).
- Twitter Developer Agreement and Policy. Available online: https://developer.twitter.com/en/developer-terms/agreement-and-policy (accessed on 15 May 2022).
- Social Bearing Research Tool. Available online: https://socialbearing.com/ (accessed on 15 May 2022).
- JQuery. JQuery UI 1.11.2. Available online: https://blog.jqueryui.com/2014/10/jquery-ui-1-11-2/ (accessed on 6 July 2022).
- Jquery-Tinysort-Min.Js. Available online: https://searchcode.com/codesearch/view/33978492/ (accessed on 6 July 2022).
- De Sandro, D. Masonry: Cascading Grid Layout Plugin. Available online: https://github.com/desandro/masonry (accessed on 6 July 2022).
- Npm. D3.Layout.Cloud. Available online: https://www.npmjs.com/package/d3.layout.cloud (accessed on 6 July 2022).
- Bostock, M. Data-Driven Documents. Available online: https://d3js.org/ (accessed on 6 July 2022).
- Analytics.Js 2.0 Source. Available online: https://segment.com/docs/connections/sources/catalog/libraries/website/javascript/ (accessed on 6 July 2022).
- Loader.Js. Available online: https://github.com/ember-cli/loader.js (accessed on 6 July 2022).
- Tunca, S.; Sezen, B.; Balcioğlu, Y.S. Twitter Analysis for Metaverse Literacy. In Proceedings of the New York Academic Research Congress, New York, NY, USA, 16 January 2022. [Google Scholar]
- Shaw, A. Preparing Your Social Media Data for a MANCOVA Test Using Social Bearing; SAGE: New York, NY, USA, 2022. [Google Scholar] [CrossRef]
- Shaw, A. Promoting Social Change—Assessing How Twitter Was Used to Reduce Drunk Driving Behaviours Over New Year’s Eve. J. Promot. Manag. 2021, 27, 441–463. [Google Scholar] [CrossRef]
- Maci, S. Discourse Strategies of Fake News in the Anti-Vax Campaign. Lang. Cult. Mediat. (LCM J.) 2019, 6, 15–43. [Google Scholar] [CrossRef]
- Neyazi, T.A. Digital propaganda, political bots and polarized politics in India. Asian J. Commun. 2020, 30, 39–57. [Google Scholar] [CrossRef]
- Saha, A.; Agarwal, N. Assessing Social Support and Stress in Autism-Focused Virtual Communities: Emerging Research and Opportunities; Information Science Reference: Hershey, PA, USA, 2018; ISBN 9781522540212. [Google Scholar]
- Záhorová, K. Propaganda on Social Media: The Case of Geert Wilders. Available online: https://dspace.cuni.cz/handle/20.500.11956/99767 (accessed on 9 June 2022).
- Almurayh, A.; Alahmadi, A. The Proliferation of Twitter Accounts in a Higher Education Institution, IAENG International Journal of Computer Science, 49:1. Available online: http://www.iaeng.org/IJCS/issues_v49/issue_1/IJCS_49_1_19.pdf (accessed on 9 June 2022).
- Forgues, B.; May, T. Message in a Bottle: Multiple Modes and Multiple Media in Market Identity Claims. In Research in the Sociology of Organizations; Emerald: West Yorkshire, UK, 2017; pp. 179–202. [Google Scholar]
- Chiauzzi, E.; Wicks, P. Digital Trespass: Ethical and Terms-of-Use Violations by Researchers Accessing Data from an Online Patient Community. J. Med. Internet Res. 2019, 21, e11985. [Google Scholar] [CrossRef]
- Search Tweets: Standard v1.1. Available online: https://developer.twitter.com/en/docs/twitter-api/v1/tweets/search/overview (accessed on 21 July 2022).
- How to Tweet. Available online: https://help.twitter.com/en/using-twitter/how-to-tweet (accessed on 15 May 2022).
- Twitter Official Website. Available online: https://twitter.com/ (accessed on 15 May 2022).
- Twitter Android Application. Available online: https://play.google.com/store/apps/details?id=com.twitter.android&hl=en_US&gl=US (accessed on 15 May 2022).
- Twitter for IPhone. Available online: https://apps.apple.com/in/app/twitter/id333903271 (accessed on 15 May 2022).
- Wikipedia Contributors TweetDeck. Available online: https://en.wikipedia.org/w/index.php?title=TweetDeck&oldid=1056092943 (accessed on 15 May 2022).
- Supported Languages on Twitter. Available online: https://developer.twitter.com/en/docs/twitter-for-websites/supported-languages (accessed on 15 May 2022).
- Standard Search API. Available online: https://developer.twitter.com/en/docs/twitter-api/v1/tweets/search/api-reference/get-search-tweets (accessed on 6 July 2022).
- How to Use Advanced Search. Available online: https://help.twitter.com/en/using-twitter/twitter-advanced-search (accessed on 6 July 2022).
- Wilkinson, M.D.; Dumontier, M.; Aalbersberg, I.J.; Appleton, G.; Axton, M.; Baak, A.; Blomberg, N.; Boiten, J.W.; da Silva Santos, L.B.; Bourne, P.E.; et al. The FAIR Guiding Principles for scientific data management and stewardship. Sci. Data 2016, 3, 160018. [Google Scholar] [CrossRef]
- Hydrator: Turn Tweet IDs into Twitter JSON & CSV from Your Desktop! Available online: https://github.com/DocNow/hydrator (accessed on 6 July 2022).
- Tekumalla, R.; Banda, J.M. Social Media Mining Toolkit (SMMT). Genom. Inform. 2020, 18, e16. [Google Scholar] [CrossRef]
- Twarc: A Command Line Tool (and Python Library) for Archiving Twitter JSON. Available online: https://github.com/DocNow/twarc (accessed on 6 July 2022).
- Vijay Karunamurthy Make Way for Youtu.Be Links. Available online: https://blog.youtube/news-and-events/make-way-for-youtube-links/ (accessed on 15 May 2022).
- Pichl, M.; Zangerle, E.; Specht, G. Towards a Context-Aware Music Recommendation Approach: What Is Hidden in the Playlist Name? In Proceedings of the 2015 IEEE International Conference on Data Mining Workshop (ICDMW), Atlantic City, NJ, USA, 14–17 November 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1360–1365. [Google Scholar]
- Jannach, D.; Kamehkhosh, I.; Lerche, L. Leveraging Multi-Dimensional User Models for Personalized next-Track Music Recommendation. In Proceedings of the Symposium on Applied Computing—SAC ’17, New York, NY, USA, 3–7 April 2017; ACM Press: New York, NY, USA, 2017. [Google Scholar]
- Ludewig, M.; Jannach, D. Evaluation of session-based recommendation algorithms. User Model. User-Adapted Interact. 2018, 28, 331–390. [Google Scholar] [CrossRef]
- Zangerle, E.; Chen, C.-M.; Tsai, M.-F.; Yang, Y.-H. Leveraging Affective Hashtags for Ranking Music Recommendations. IEEE Trans. Affect. Comput. 2021, 12, 78–91. [Google Scholar] [CrossRef]
- Zangerle, E.; Pichl, M.; Hupfauf, B.; Specht, G. Can Microblogs Predict Music Charts? An Analysis of the Relationship between #Nowplaying Tweets and Music Charts. Available online: http://m.mr-pc.org/ismir16/website/articles/039_Paper.pdf (accessed on 1 July 2022).
- Pichl, M.; Zangerle, E.; Specht, G. Understanding user-curated playlists on Spotify: A machine learning approach. Int. J. Multimed. Data Eng. Manag. 2017, 8, 44–59. [Google Scholar] [CrossRef]
- Abboud, R.; Tekli, J. Integration of nonparametric fuzzy classification with an evolutionary-developmental framework to perform music sentiment-based analysis and composition. Soft Comput. 2020, 24, 9875–9925. [Google Scholar] [CrossRef]
- Kaneshiro, B.; Ruan, F.; Baker, C.W.; Berger, J. Characterizing Listener Engagement with Popular Songs Using Large-Scale Music Discovery Data. Front. Psychol. 2017, 8, 416. [Google Scholar] [CrossRef] [PubMed]
- Zangerle, E.; Pichl, M.; Schedl, M. User Models for Culture-Aware Music Recommendation: Fusing Acoustic and Cultural Cues. Trans. Int. Soc. Music Inf. Retr. 2020, 3, 1–16. [Google Scholar] [CrossRef]
- Hridi, A.P. Mining User Personality from Music Listening Behavior in Online Platforms Using Audio Attributes; Clemson University: Clemson, SC, USA, 2021. [Google Scholar]
- Moderna Begins Next Phase of Omicron-Specific Booster Trial as Study Finds That Antibodies Remain Durable despite 6-Fold Drop over 6 Months. Available online: https://www.cnn.com/2022/01/26/health/moderna-omicron-antibodies-booster/index.html (accessed on 16 May 2022).
- Pfizer and BioNTech Initiate Study to Evaluate Omicron-Based COVID-19 Vaccine in Adults 18 to 55 Years of Age. Available online: https://www.pfizer.com/news/press-release/press-release-detail/pfizer-and-biontech-initiate-study-evaluate-omicron-based (accessed on 16 May 2022).
- Strasser, Z.; Hadavand, A.; Murphy, S.; Estiri, H. SARS-CoV-2 Omicron Variant Is as Deadly as Previous Waves after Adjusting for Vaccinations, Demographics, and Comorbidities. Res. Sq. 2022. [Google Scholar] [CrossRef]
- Bar-On, Y.M.; Goldberg, Y.; Mandel, M.; Bodenheimer, O.; Amir, O.; Freedman, L.; Alroy-Preis, S.; Ash, N.; Huppert, A.; Milo, R. Protection by a Fourth Dose of BNT162b2 against Omicron in Israel. N. Engl. J. Med. 2022, 386, 1712–1720. [Google Scholar] [CrossRef]
- Shukla, R.; Sinha, A.; Chaudhary, A. TweezBot: An AI-Driven Online Media Bot Identification Algorithm for Twitter Social Networks. Electronics 2022, 11, 743. [Google Scholar] [CrossRef]
- Martin-Gutierrez, D.; Hernandez-Penaloza, G.; Hernandez, A.B.; Lozano-Diez, A.; Alvarez, F. A Deep Learning Approach for Robust Detection of Bots in Twitter Using Transformers. IEEE Access 2021, 9, 54591–54601. [Google Scholar] [CrossRef]
- Pham, P.; Nguyen, L.T.; Vo, B.; Yun, U. Bot2Vec: A general approach of intra-community oriented representation learning for bot detection in different types of social networks. Inf. Syst. 2022, 103, 101771. [Google Scholar] [CrossRef]
- Pastor-Galindo, J.; Mármol, F.G.; Pérez, G.M. BOTTER: A Framework to Analyze Social Bots in Twitter. arXiv 2021, arXiv:2106.15543. [Google Scholar]
- Praveena, A.; Smys, S. Effective Spam Bot Detection Using Glow Worm-Based Generalized Regression Neural Network. In Mobile Computing and Sustainable Informatics; Springer: Singapore, 2022; pp. 469–487. ISBN 9789811618659. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
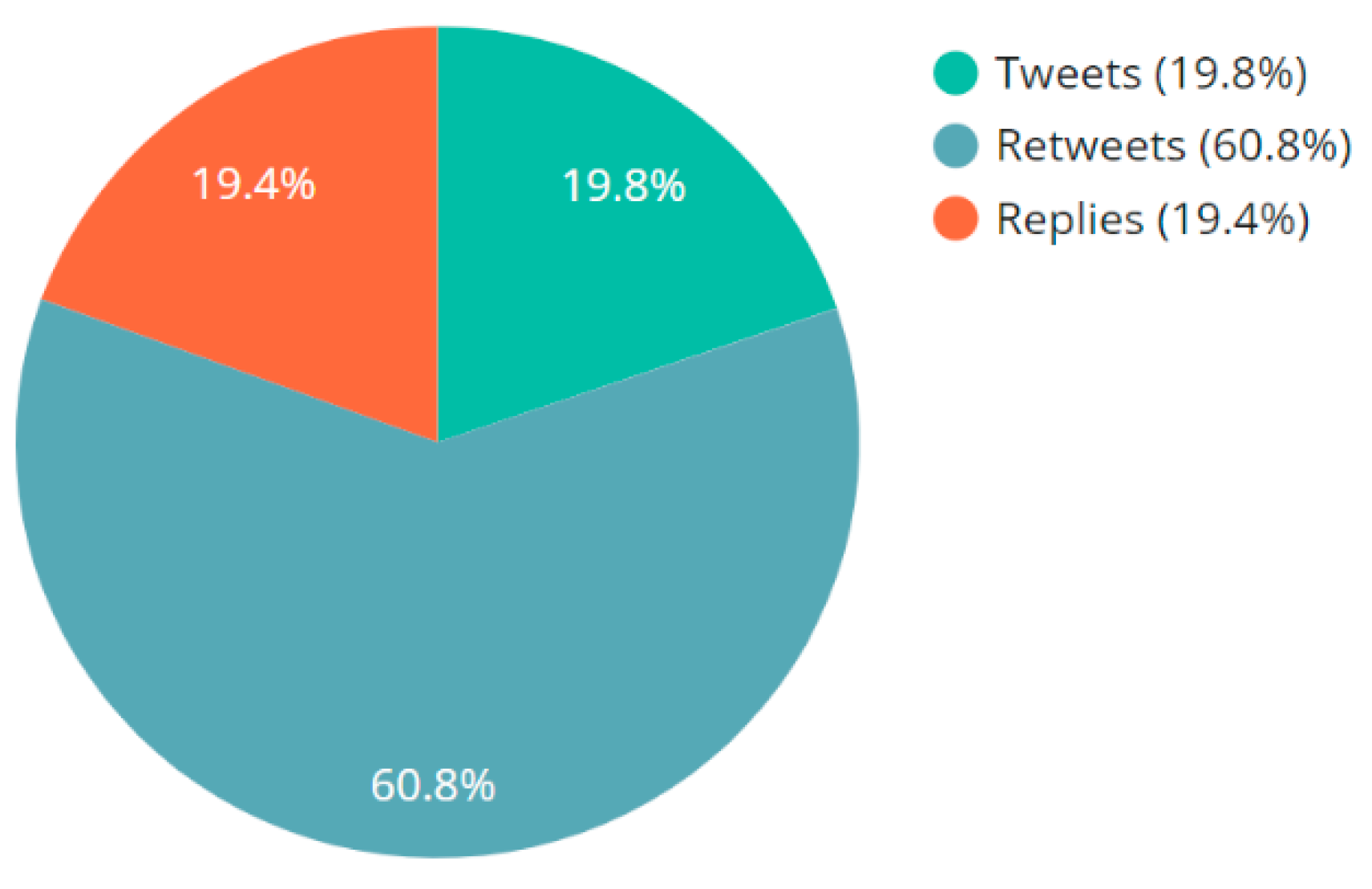{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tweet Source Label | Condition for Assignment |
|---|---|
| Twitter Web App | The tweet was posted by visiting the official website of Twitter [125] |
| Twitter for Android | The tweet was posted using the Twitter app for Android operating systems, which is available for free download on the Google Playstore [126] |
| Twitter for iPhone | The tweet was posted using the Twitter app for iPhone, which is available for free download on the App Store [127] |
| TweetDeck | The tweet was posted by using TweetDeck, a social media dashboard application for the management of Twitter accounts [128] |
| Filename | No. of Tweet IDs | Date Range of the Tweet IDs |
|---|---|---|
| TweetIDs_November.txt | 16471 | 24 November 2021 to 30 November 2021 |
| TweetIDs_December.txt | 99288 | 1 December 2021 to 31 December 2021 |
| TweetIDs_January.txt | 92860 | 1 January 2022 to 31 January 2022 |
| TweetIDs_February.txt | 89080 | 1 February 2022 to 28 February 2022 |
| TweetIDs_March.txt | 97844 | 1 March 2022 to 31 March 2022 |
| TweetIDs_April.txt | 91587 | 1 April 2022 to 20 April 2022 |
| TweetIDs_May.txt | 35756 | 1 May 2022 to 12 May 2022 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Thakur, N.; Han, C.Y. An Exploratory Study of Tweets about the SARS-CoV-2 Omicron Variant: Insights from Sentiment Analysis, Language Interpretation, Source Tracking, Type Classification, and Embedded URL Detection. COVID 2022, 2, 1026-1049. https://doi.org/10.3390/covid2080076
Thakur N, Han CY. An Exploratory Study of Tweets about the SARS-CoV-2 Omicron Variant: Insights from Sentiment Analysis, Language Interpretation, Source Tracking, Type Classification, and Embedded URL Detection. COVID. 2022; 2(8):1026-1049. https://doi.org/10.3390/covid2080076
Chicago/Turabian StyleThakur, Nirmalya, and Chia Y. Han. 2022. "An Exploratory Study of Tweets about the SARS-CoV-2 Omicron Variant: Insights from Sentiment Analysis, Language Interpretation, Source Tracking, Type Classification, and Embedded URL Detection" COVID 2, no. 8: 1026-1049. https://doi.org/10.3390/covid2080076
APA StyleThakur, N., & Han, C. Y. (2022). An Exploratory Study of Tweets about the SARS-CoV-2 Omicron Variant: Insights from Sentiment Analysis, Language Interpretation, Source Tracking, Type Classification, and Embedded URL Detection. COVID, 2(8), 1026-1049. https://doi.org/10.3390/covid2080076