1. Introduction
Urban mobility and transportation are critical aspects of cities’ functionality, which becomes even more complex in high-density urban areas. Paradoxically, cities with the highest density are predominantly located in the Global South, which is less developed. Cities such as Medan, Jakarta, Dhaka, and Manila have a density of well over 15,000 people/km
2, where millions of people move for work, education, and leisure using private vehicles. High use of private vehicles has negative consequences such as traffic jams, loss of productive life, increase risk of accidents, and increased pollutants and emissions. Empirical studies have also confirmed that vehicular emissions accounted for more than 90% of harmful gasses such as CO, VOC, NOX, and PM [
1]. The gold standard for urban mobility is a high use of public transport to ensure flows of people are synchronized and orchestrated sustainably [
2]. However, cities in the Global South face challenges in reaching this gold standard, as many parts of the cities develop in a sprawl with narrow streets unsuitable for buses, pavements occupied by informal street vendors, and lack resources to provide the much-needed transportation infrastructure.
Understanding current mobility patterns is important to ensure the provision of effective and efficient public transport with high usage. This includes understanding the process of gradually shifting towards public transportation, so citizens can travel more sustainably without much disruption. Mobility patterns can also inform the level and spread of emissions, as most emission models use secondary data [
3,
4,
5,
6,
7], but can hardly predict emission changes based on complex socioeconomic dynamics.
Alternative data sources are needed to enable efficient mapping of travel behavior [
8,
9]. Conventional journey mapping involves asking respondents about their daily movement. This can be time consuming and expensive [
10,
11]. The method also raises questions on the behavioral accuracy since it relies on the memory of travelers and is often biased due to underreported travel [
12]. Furthermore, most journey mapping reporting formats only show the modal split as an aggregated figure without providing specific details on how the modal share varies across various distance bands. If detailed data are available, the impact of interventions on the proportion of pedestrians (e.g., 1–3 km) or bicycle users (e.g., 1–5 km) can also be accurately estimated.
This paper discusses a survey using Google Location History (GLH)—a still underresearched innovative data source based on participatory mapping, to understand urban mobility in more detail in one of Indonesia’s growing metropolitan areas, Mebidang, an agglomeration of Medan, Binjai, and Deliserdang.
2. Literature Review
Data from participatory mapping are generally seen as a complimentary to large scale datasets, including data from statistics and origin-destination surveys to gain deeper understanding of citizens’ or the community’s mobility behavior. Participatory mapping is a collaborative process where communities and stakeholders contribute to making a map that reflects their knowledge, experience, and aspirations. Information from participatory mapping can support behavioral change and enable effective provision of transportation systems, and even urban design [
13,
14,
15]. For example, understanding safety concerns in using public transport and walking in certain areas, especially for women and children, can inform local governments to prioritize upgrading pedestrian infrastructure, lights, and security personnel to help citizens transition towards public transportation and active mobility when going to school [
16]. Understanding the different distance bands for each vehicle can help the promotion of shifting strategies for each distance band, reduce “car stickiness”—values attached to private vehicles—and provide better public transport for certain routes [
17]. The following section discusses current data sources and methods relating to participatory mapping, especially using mobile phone-based GIS tools.
2.1. Participatory Geographic Information Systems (PGISs) on Mobile Phones
PGISs emerged as a response to critiques of traditional GIS, aiming to empower marginalized groups in map-making. Applications under the general term of participatory geographical information systems (PGISs) or public participatory geographical information systems (PPGISs) have been helpful for decision-making in urban planning, environmental management, and disaster management, among other areas [
18]. With the development of new technology, there has been a push towards using new digital tools and methods for participatory mapping [
19,
20]. Examples of interactive mapping tools include Maptionnaire, Citizenlab, and ArcGIS Hub, which allow respondents to manually input spatial information on their usual routes to work or school and locate certain places of interest, using simple location tags or drawn lines. These interactive applications also have options where respondents can prioritize which initiatives should be developed first in which area.
The development of PGIS has also been largely facilitated by the development of mobile phone technology. Mobile applications can utilize built-in GPS and location detection features in smartphones. Some applications have been developed specifically for travel surveys, such as ATLAS, developed for iPhone users [
14], the Household Travel Survey (Tennessee), and Future Mobility Sensing (MIT). Respondents are required to download the application that tracks their movement for a certain amount of time, and then the collected data will be sent to the server. For each of the study, less than 10% of interested people sent their data. The low participation rate was linked to a technology familiarity gap, where non-tech-savvy people are not likely to install and operate the app on their mobile phone.
Over the years, mobile phone technology has advanced, with higher location precision. However, studies have also highlighted technical issues regarding travel data collected from mobile phones. Mobile phones require input data from GPS, which are enhanced by location triangulation from BTSs (base transceiver stations), WIFI, and other devices. Depending on the quality of signal, device specification and data traffic, the precision of the location varies [
21]. False nodes can be recorded if someone is stuck in a traffic jam; on the other hand, false trips can be recorded during idle time when the device location recording bounces off several WIFI routers or BTSs in the surrounding area. There is also still a possibility of human error, where respondents can forget to turn on the tracking app or run out of data.
Due to the limitation of data precision and granularity, there has also been a wide range of research focusing on mobile data analysis for transport modelling. For example, Coppola et al. [
22] used machine learning and clustering algorithms to identify mobility patterns based on travel purpose and travel mode, and to verify nodes and trips. Data analysis is also crucial for differentiating systematic and non-systematic trips. There has also been a greater push towards using AI to better identify patterns systematically, and decrease intervention based on the analyst’s judgement [
23]. For researchers, the range of data granularity and depth of data analysis depends on the purpose of the study.
For respondents, there are concerns over data protection; sharing a personal location, including house location, and daily routes through an installed app might be intimidating [
24,
25,
26]. While the apps developed for PGIS may fill in the gap for a more participative survey, developing and operating the app can be costly and it may not be universally available for researchers worldwide. The mentioned challenges also become the reason that despite smartphone-based travel surveys’ great potential, they are still seldom used on a large scale [
24]. From a humanistic standpoint, the academic discussion on PGIS also suggests future studies to improve technical, social, and political aspects in the process of data gathering and interpreting the maps.
2.2. Google Maps and Google Location History as a Mobility Survey Tool
Google Maps is a free mobile application ubiquitously installed on smartphones around the world, with an average 1.8 billion monthly users. Users utilize the app for navigation and search locations. The app also allows location tracking; when activated, the movement of the device is recorded and can be accessed through Google Location History. Due to its great potential as a free tool for mobility studies, several studies have tested and used Google Location History for research in areas of mobility, transport, and urban studies, as well as measuring the tool’s accuracy in recording place and time [
27,
28,
29,
30,
31,
32,
33]. The previous studies concluded the precision of time is 85% and location 90% at a 100 m radius, and precision of transport mode classification is more than 90% for private transport and active mobility, and 80% for public transport. The findings inform us that GLH has high accuracy at a 100 m radius, which may be more appropriate for city-wide studies rather than smaller-scale areas. However, the accuracy can be maintained with less than 50 m radius when recording slower-pace movements such as walking and cycling, using advanced location setting. Studies have also proven that data accuracy depends on network infrastructure as well as device brand and specification.
Several studies have used GLH as mobility survey tool. In a study by Walker et al. [
26], out of 60,000 recruitment letters sent, only 282 location data from participants were able to be used. Participants were required to send the JSON file from Google Takeout, which consists of entire trip journeys recorded on Google Maps. The study was able to produce detailed spatial and tabular data on number of trips, distance per mode, and heatmaps. Li et al. [
33] used a similar method but required participants to upload only seven days of data in the KML format, downloaded from the desktop version of Google Maps. The KML file is then uploaded to the Travel and Activity Internet Survey Interface (TRAISI) survey platform, where participants can validate their travel data, such as place, time, and mode. This study captured 956 weeklong travel data with a similar analysis method. Other studies rarely obtained more than 200 respondents [
25,
26,
28]. These empirical studies highlight consistently different results compared to conventional survey methods, with a higher number of trip legs and higher frequency of shorter distances, indicating that the GLH method recorded more trips. While evidently being more effective than conventional methods, survey participants require multiple devices and basic understanding of technology to participate, hence the low participation rate. Previous studies have provided evidence that GLH is a valuable tool for mobility surveys, but also has a deficiency in terms of ease of use and exclusion of certain participants. Tools used for analysis in previous studies were also universally accessible programs.
This study used GLH as a tool for a mobility survey with adjusted approaches in participant engagement and data analysis to make it more universal and inclusive, especially as the survey was conducted in Medan, Binjai, and Deli Serdang Cities, in North Sumatera, Indonesia—a developing country with lower infrastructure and technology adoption than the Global North. The survey seeks to gain more granular data of urban mobility, including the current level of usage of transportation modes at different distance bands and preferred routes tied to respondents’ demographic data. These types of data are useful for transport models, and support programs that focus on shifting private vehicle use towards public transportation and active mobility.
These data were compared to results from other studies in the area, mainly the Sustainable Urban Mobility Plan (SUMP) document published in 2022. It is currently considered the most comprehensive source of data. It brings together information from interviews, manual vehicle counts on major streets, and movement patterns supplied by a mobile telecommunication data provider. However, this conventional approach does not provide the modal share for each distance band and lacks detailed spatial data which can potentially help understand mobility patterns in first and last mile travel for more detailed transportation models.
3. Materials and Methods
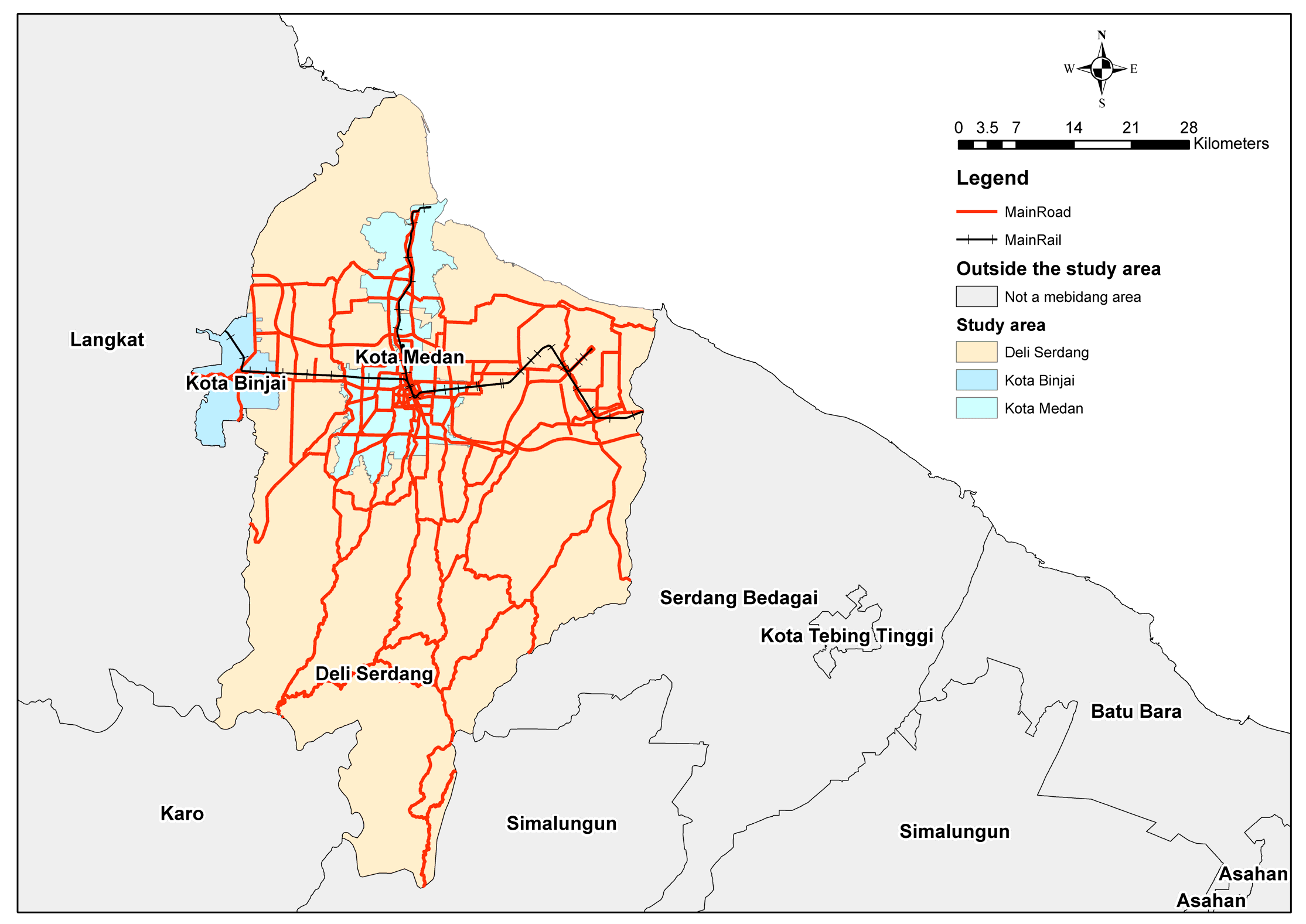
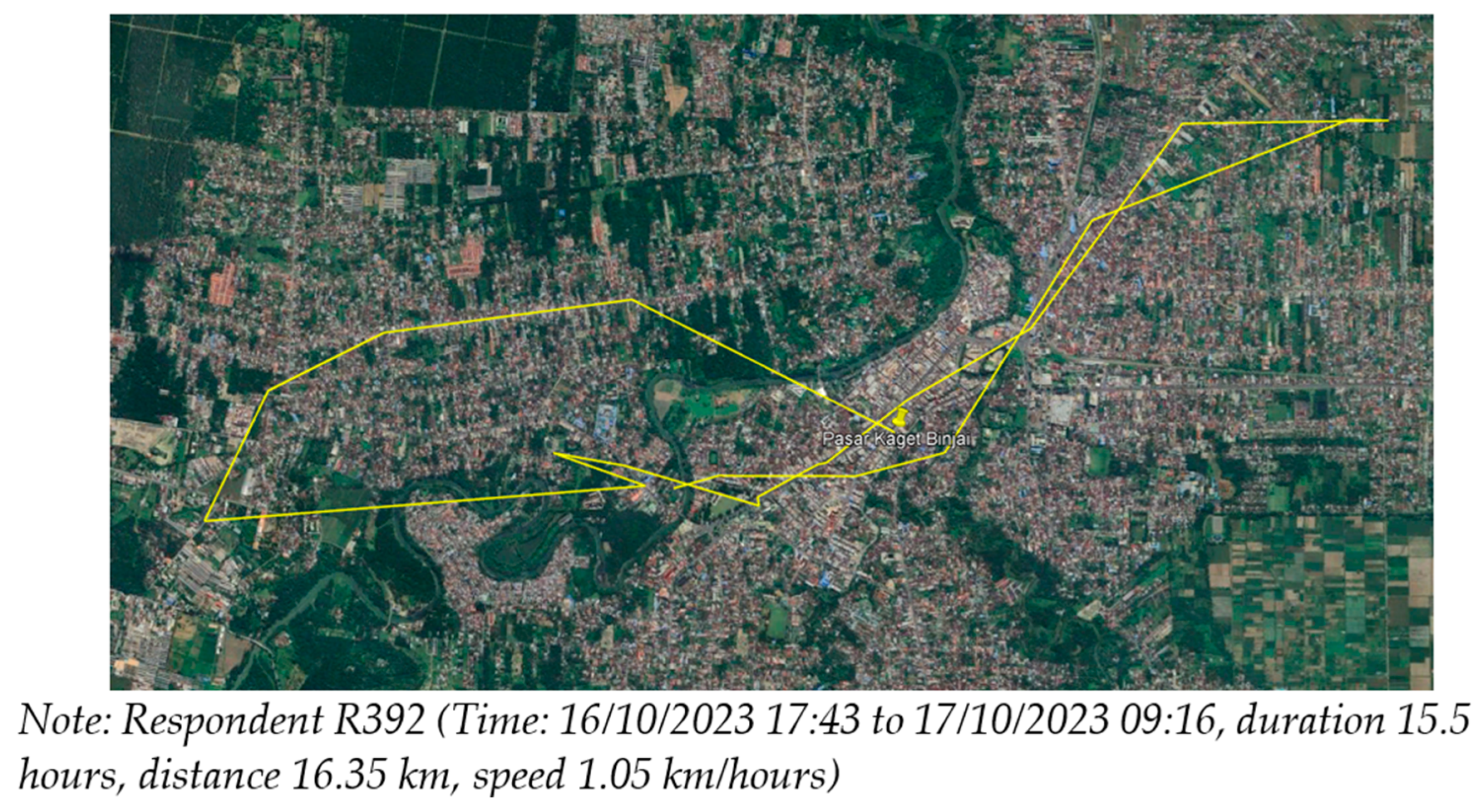
We undertook the mobility survey in the agglomeration area of Medan, Binjai, Deli Serdang (Mebidang), a growing metropolitan in North Sumatera, Indonesia, which urgently needs to develop public transportation (
Figure 1). The aim of the survey was to collect mobility data from smartphone GPS that could then be analyzed in terms of total and average trip distance, travel time, type of vehicle, and location of occurring visits; workplace, schools, and bus stops. To understand mobility based on characteristics, each type of the data above is needed including demographics; trip purpose, age, education, occupation, and similar factors.
Considering concerns over security in sharing personal location data, the technical practicality, and file size per participant, we decided that participants only needed to share 7 days of travel data in KML format. To obtain the KML data, respondents needed to download them from a PC or laptop by exporting a selected travel date from Google Maps, as the mobile app version did not have an export feature. A similar method was used by Li et al. [
33], who extracted KML data, whereas other publications on Google Location History (GLH) surveys required respondents to download JSON file (a simple text file used to store and share structured data) downloaded from Google Takeout, which is a record of all travel data recorded on Google Maps, and is significantly larger than KML files collected in this survey [
26]. The KML data were then uploaded to a Google Form, which was compiled and analyzed by the data collection team.
Clear information about the survey’s purpose and data collection was given to participants to ensure ethical considerations and privacy protection. Participants also received the option to opt out or decline participation. We took measures to ensure secure data storage and prevent disclosure to third parties without explicit participant consent. The University of York Ethics Board also approved the survey.
We carried out a pilot survey before the main survey to test the data collection process and assess data suitability for the research. The pilot survey took place in December 2023, with a target of 50 respondents. We disseminated survey information through local newspapers, radio, and social media. We held a session with students at Universitas Sumatera Utara (USU) to promote the survey. As an incentive, we entered participants into a prize draw for a new mobile phone. Respondents took part by completing a Google Form, which included sections for consent, demographic information, and uploading KML data. The form also provided a link to a step-by-step guide on how to record, download, and upload KML data from Google Maps. By the end of the pilot survey, data from 49 respondents had been collected.
The pilot survey highlighted several important lessons. First, the demographic spread was overly homogenous, with most respondents being university students, particularly from USU. Only 12.26% of respondents had learned about the program through the media used for promotion. This lack of diversity in respondents was not representative of the general population of Mebidang, limiting the survey’s ability to capture a broad range of mobility patterns. Despite using various channels to promote the survey, participation rates were low. The low participation in the pilot survey resembled that of previous surveys using GLH and other PGIS tools. Second, although we provided the survey information, including a step-by-step guide on the required data, 34.7% of submissions did not meet the criteria. Some participants uploaded less than seven days of travel data, while others submitted files in incorrect formats, such as screenshots of their travel history or corrupt files. These challenges underscored the need for improved communication and support to ensure accurate and complete data collection.
We adjusted the data collection process based on lessons from the pilot survey, then recruited surveyors to find respondents and collect their travel data in KML format, blending new survey tools with traditional face-to-face engagement. We split the Google Form in two to be inclusive and account for participants who might be less tech-savvy or had not enabled location recording on Google Maps. The first form was used to collect personal data- age, sex, education, occupation, main purpose of travel, and perception of comfort and safety of the daily travel, while the second form was used to upload the KML data. By using this approach, it was possible for surveyors to find participants who would take part, and ask them to turn on their location recording, then collect data in the next week. Surveyors had an active role in maintaining communication with the participant. By using surveyors, participants who did not have access to a personal computer/laptop to export their KML data could be paired with survey facilitators equipped with laptops.
3.1. Data Collection
We employed stratified random sampling. Key considerations for grouping included ensuring a proportional distribution of respondents across the cities of Medan, Binjai, and Deli Serdang (Mebidang) and including vulnerable groups, in alignment with gender equality and social inclusion (GESI) principles. The target sample size was set at 400 respondents, calculated based on Cochran’s sampling formula with a 5% margin of error. This sample size ensures robust statistical analysis. In comparison, other surveys involved sample sizes with less than 200 respondent data, with only Li et al. [
33] successfully achieving more than 500 respondents. This study used a respondent distribution of 60% from Medan, 20% from Binjai, and 20% from Deli Serdang, with vulnerable groups comprising at least 15% of the total sample.
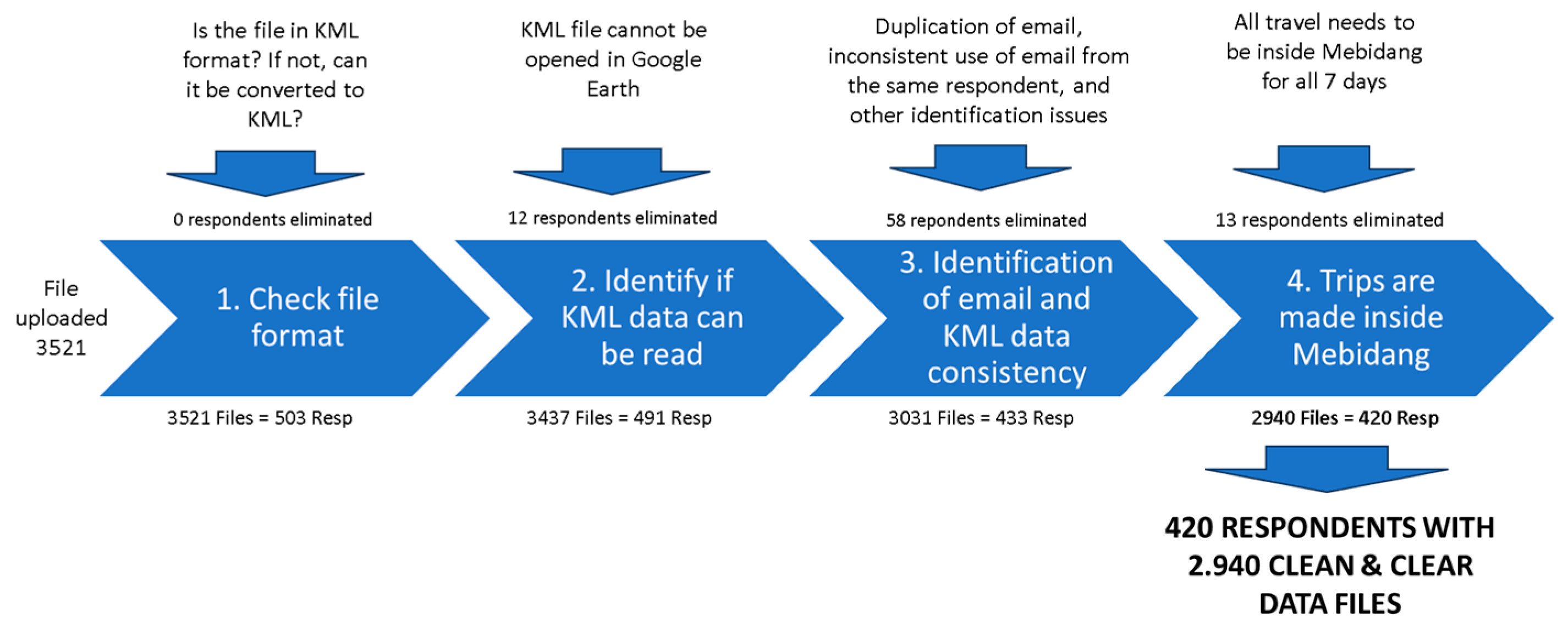
We conducted the survey between 1 August 2023 and 30 October 2023, successfully collecting 420 valid weeklong travel data, exceeding the minimum target of 400. There were four steps of initial data cleaning involved, as shown in
Figure 2. The first was to check the correct file format, and all 503 respondents’ data were valid. The process was continued by individually checking the KML files were readable, eliminating email duplication or other identification issues due to wrong uploading process, and finally eliminating trips made outside Mebidang. At the end of the cleaning process, 420 valid travel data were ready to be analyzed.
We divided the analysis into two components: descriptive statistical analysis and modelling, based on KML files capturing respondents’ journeys over one week’s travel within the Mebidang area. The dataset included 62% of respondents from Medan City, 15% from Binjai City, and 23% from the Deli Serdang region. Sixteen percent of respondents represented vulnerable groups, ensuring inclusivity in line with the study’s objectives. There were 2940 KML files collected, comprising 9918 lines and 16,573 nodes. To comply with ethical and confidentiality guidelines, respondent email data were removed during data cleaning prior to analysis. This ensured the protection of participant information while enabling robust data analysis.
This study used Power BI to extract data from KML files; alternatively, this process can also be conducted in MS Excel. Prior to analysis, the data required cleaning to address errors resulting from issues such as low internet connectivity, poor GPS accuracy of mobile devices, and the nature of how the devices interacted with surrounding WIFI, telecommunication towers, and other devices, as mentioned in previous studies [
21,
22,
24,
27,
32]. These errors led to the following challenges:
- a.
Inaccuracies in the recorded spatial and temporal data for nodes and travel;
- b.
Difficulty in accurately predicting the mode of travel based on the spatial data provided.
Because of these factors, raw KML data from GLH required additional cleaning. Examples include trips labelled solely as “moving”, with no assigned transport mode, and instances where trips were recorded despite the respondent remaining stationary. The latter issue was identifiable when data showed respondents moving at very low speeds in a pattern circulating around nearby points. Sometimes, data showed respondents returning to their usual starting point but being recorded as continuously moving around that point from night until morning. Such anomalies required resolution through academic assumptions and expert judgement. Previous studies have used predefined criteria for what is considered a node or place, depending on the context and scope of the study; for example, continuous movement in a 1 km radius can be considered a node.
Figure 3 outlines the data cleaning steps in this study, including assumptions for determining travel modes based on average speed and distance patterns observed in the dataset. Trips labelled “movement” in between two trips with the same transport mode were labelled the same. For example, in a series of trips labelled motorcycle “movement”, a motorcycle was assumed to be fully made by motorcycle. The data cleaning process was followed by the extraction of demographic and travel-related variables for analysis.
3.2. Method for Analysis
Power BI application was used to transform the data from KML files into tabular format, and to extract the following information (see
Table 1):
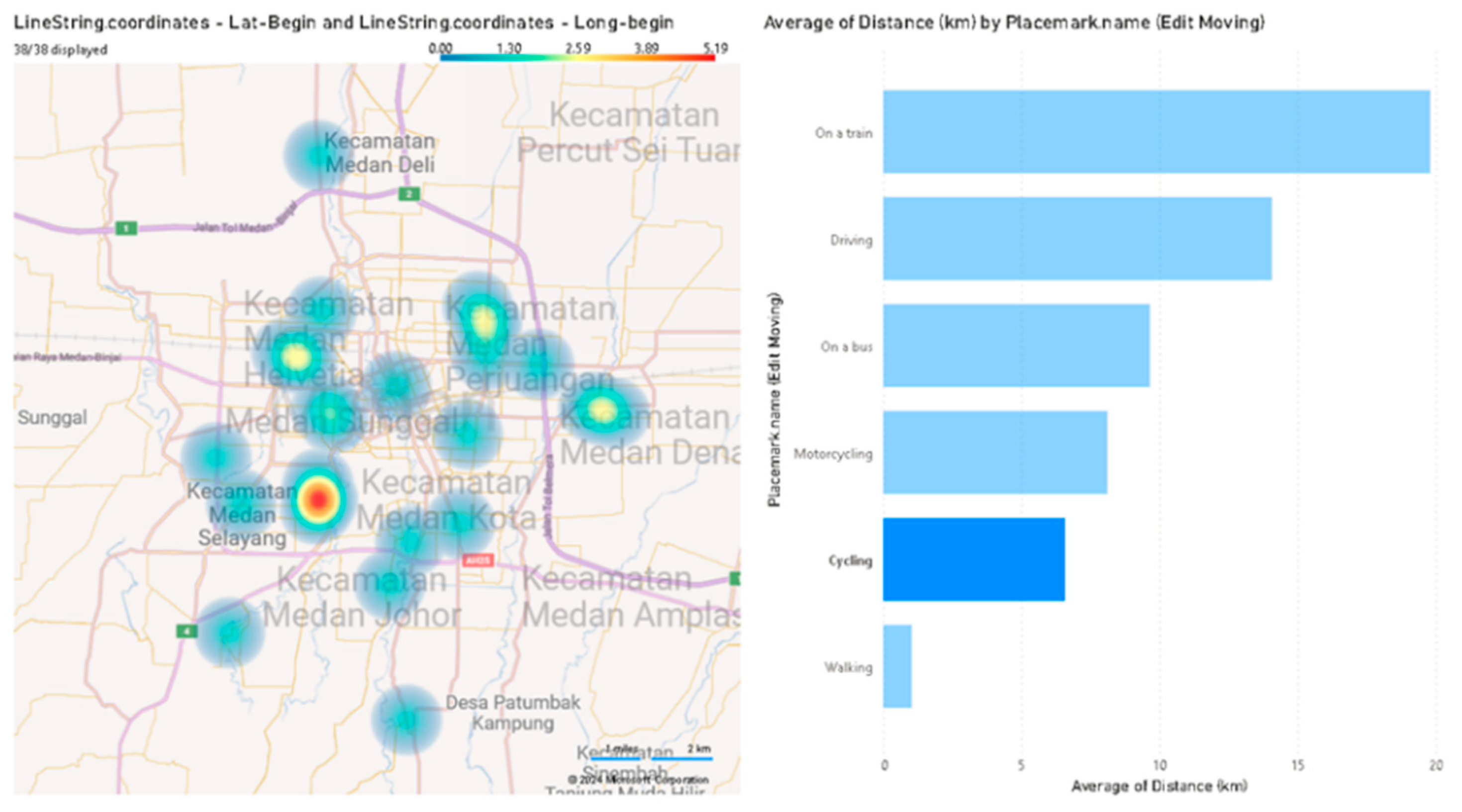
We then integrated the tabular data with the personal data collected through Form 1, which contained respondent characteristics. We analyzed this combined dataset using pivot tables to explore mobility patterns. Demographic data were essential for describing the travel behavior of different groups or clusters, such as the movement patterns of students on weekdays. The Power BI dashboard facilitated the visualization of heatmaps and movement patterns, enabling the overlay of travel routes for further analysis.
6. Conclusions
This study demonstrates the potential of GLH as an innovative and cost-effective tool for mobility surveys. By using the widely available Google Maps application, this method eliminates the need for bespoke survey software and additional downloads, making it more accessible for participants while reducing costs.
However, GLH presents technical challenges that require attention. These include inaccuracies in identifying travel modes and false short trips caused by Wi-Fi and telecommunications network interference [
27,
28,
29,
39]. While these issues were manageable for this survey’s dataset of 420 respondents, larger datasets may require automated cleaning processes to maintain data quality. Developing a mobile application capable of direct data export could streamline the reliance on two devices—a smartphone for data collection and a computer for exporting KML files. Privacy concerns remain critical; strong measures to protect confidentiality and assure participants of data security are essential to encourage participation and ensure reliable data collection.
This survey showed GLH’s ability to provide deeper insights into mobility patterns compared to conventional surveys conducted in Mebidang. By recording detailed trips tied to respondent characteristics and travel modes, GLH offers rich data that can inform transport planning and analysis. For instance, GLH data revealed discrepancies between public transport trips self-reported by participants and those recorded by the system, highlighting its potential to reduce reporting bias. GLH data supports transport modelling by identifying linked spatial mobility patterns and travel modes at different distance bands, which can better inform policies, regulations, and infrastructure development.
While this study contributes valuable insights, future research should explore GLH data further through advanced data science techniques, such as demographic modelling and automated processing. Changes in Google’s data storage policies should also be monitored, as local storage and direct data export capabilities could enhance practicality.
In conclusion, GLH offers a promising, cost-effective solution for mobility research, with significant potential to advance urban planning, emissions analysis, and sustainable transport strategies. Continued development to address its technical and privacy challenges will further strengthen its utility and application.

 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}