1. Introduction
The driving cycle is a speed–time profile that represents vehicle driving characteristics [
1,
2,
3,
4,
5,
6,
7,
8], which can be used to study vehicle parameter matching, control strategy optimization, fuel economy, and other aspects. In the development and testing of vehicles, engineers often adopt driving cycles. Because of differences in city size, geographical characteristics, road types, road topology, vehicle ownership, and other factors, the characteristics of the driving cycle in different cities and regions are different [
9]. Therefore, when purchasing the urban bus, the relevant departments can select the most suitable bus for the city by referring to the fuel economy and other evaluation indicators of the vehicle tested under the representative driving cycle of the city [
10]. Hence, it is important to select the appropriate method to accurately construct the driving cycle with different regional driving characteristics [
11]. At present, many researchers have used different methods to construct the driving cycles of many regions. Some select micro-trip-based methods [
12,
13], some select the Markov chain method [
9,
14], and some combine several methods to construct driving cycles [
15,
16]. They all verified the feasibility of the methods they selected, but their conclusions are based on their data. The advantages of different methods are not comparable. Therefore, based on the same driving data, this paper adopts different methods to construct the driving conditions of the same route, and finds out the advantages and disadvantages of different methods through comparison, to provide references for the selection of methods to construct the working conditions.
The route intensity method is used to select representative routes. The bus route is made up of bus stations. The more frequently the bus station appears across all bus routes, the higher utilization the bus station has, and the more representative it is. The route intensity is shown in (1), where
μi is the route intensity of the
ith bus route,
λj is the occurrence number of the
jth bus station of the
ith bus route among all bus routes, and
n is the total number of bus stations on the
ith bus route.
After analysis of the route intensity of all Xi’an bus lines and consultation with the Xi’an bus company, Bus Route No. 2 was selected among more than 200 bus routes. There are 33 bus stops, the origin station is in the southwest corner of the Second Ring Road in Xi’an, and the terminal station is in the northeast corner of the Second Ring Road. It generally runs from east to west, covers the First Ring Road and the Second Ring Road, and passes through the urban main road. The selected route can reflect the traffic conditions in urban areas in Xi’an.
In an actual situation, when the bus is in an idling condition, the speed collected by the GPS and CAN bus equipment is not necessarily zero, which will reduce the authenticity of the collection data and thus reduce the accuracy of the driving cycle. Therefore, idling calibration is required. Referring to relevant papers and considering the actual situation of the vehicle, we defined the data with a speed less than 1.5 km/h as idle speed data and assigned it to zero.
Due to various factors, such as bad weather and building obstruction, there will be a lot of noise in data collected by the GPS. Moreover, when the equipment is disturbed, the collected data may have an abnormal value, which will cause the vehicle acceleration to be greater than the true value. By consulting the bus driver and combining this with the actual situation, we know that the maximum acceleration of the bus will not be greater than 3 m/s2 and the maximum deceleration will not be greater than −4 m/s2. The data exceeding the limit point is regarded as cusp data, and linear interpolation is carried out several times until the cusp data is within the limit point.
The data collected by GPS and CAN bus equipment is continuous. However, there are some specific situations, such as waiting for departure and driving between the bus terminal and the bus company. These data are invalid for driving cycle construction, which will affect the accuracy of driving cycle construction. By investigating the record of the bus company dispatching station, the actual following car timing, and the monitoring platform track verification, these data are stripped from the continuous data to ensure the validity of the collected data.
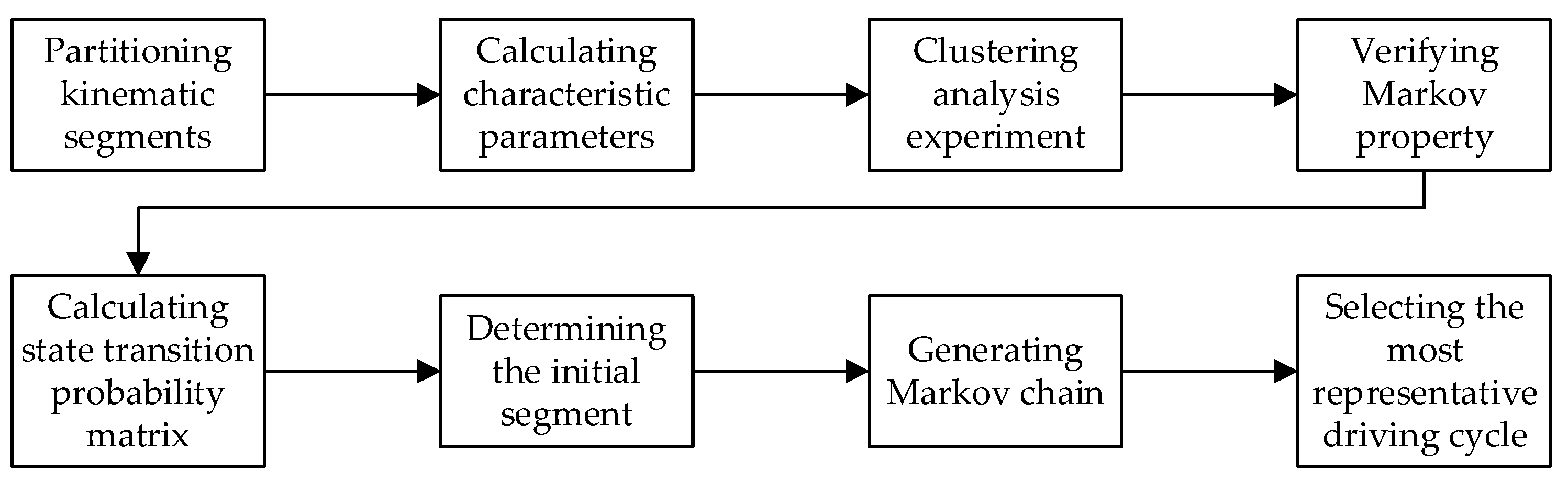
4. Combined Micro-Trip and Markov Chain Method
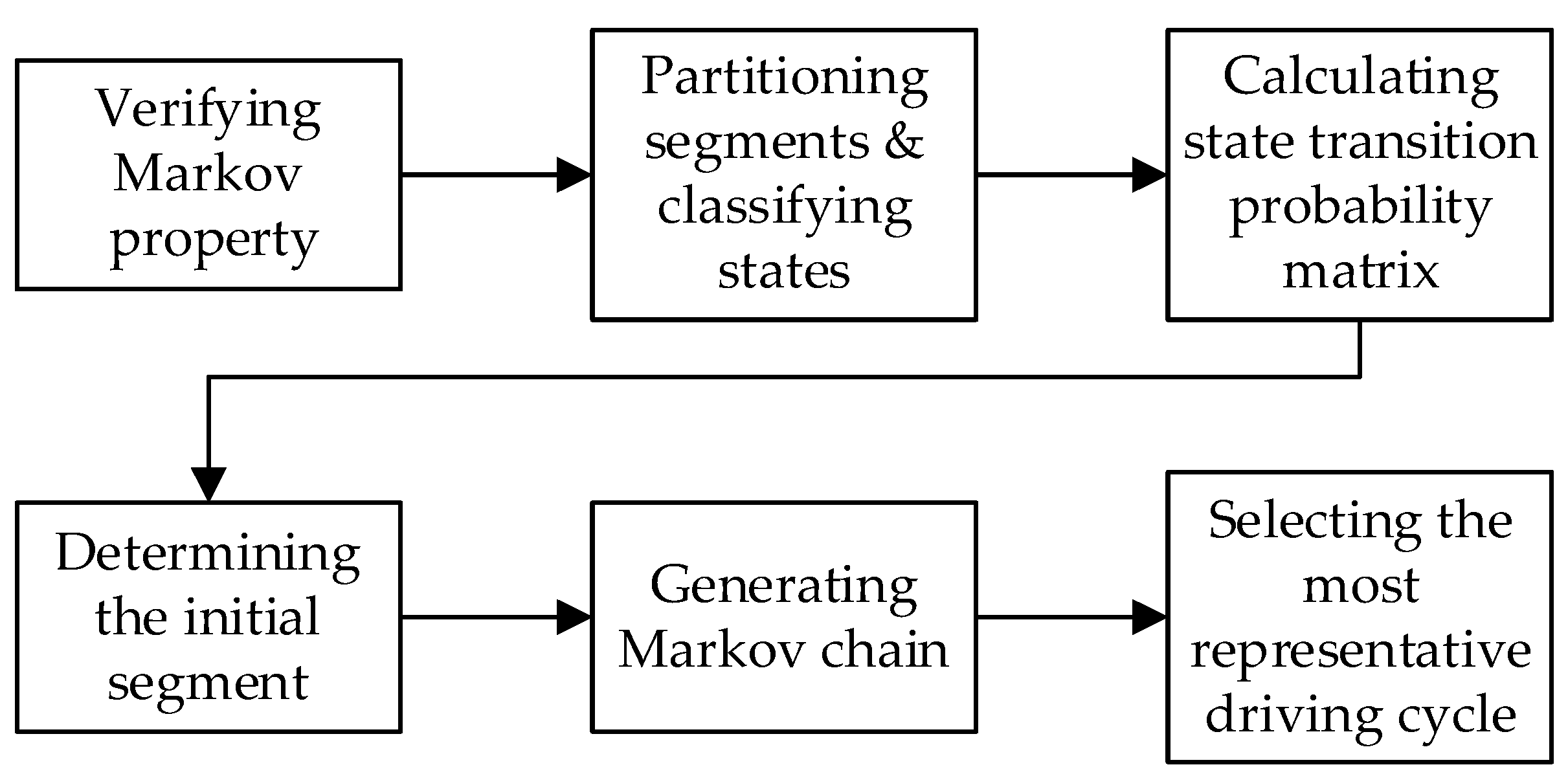
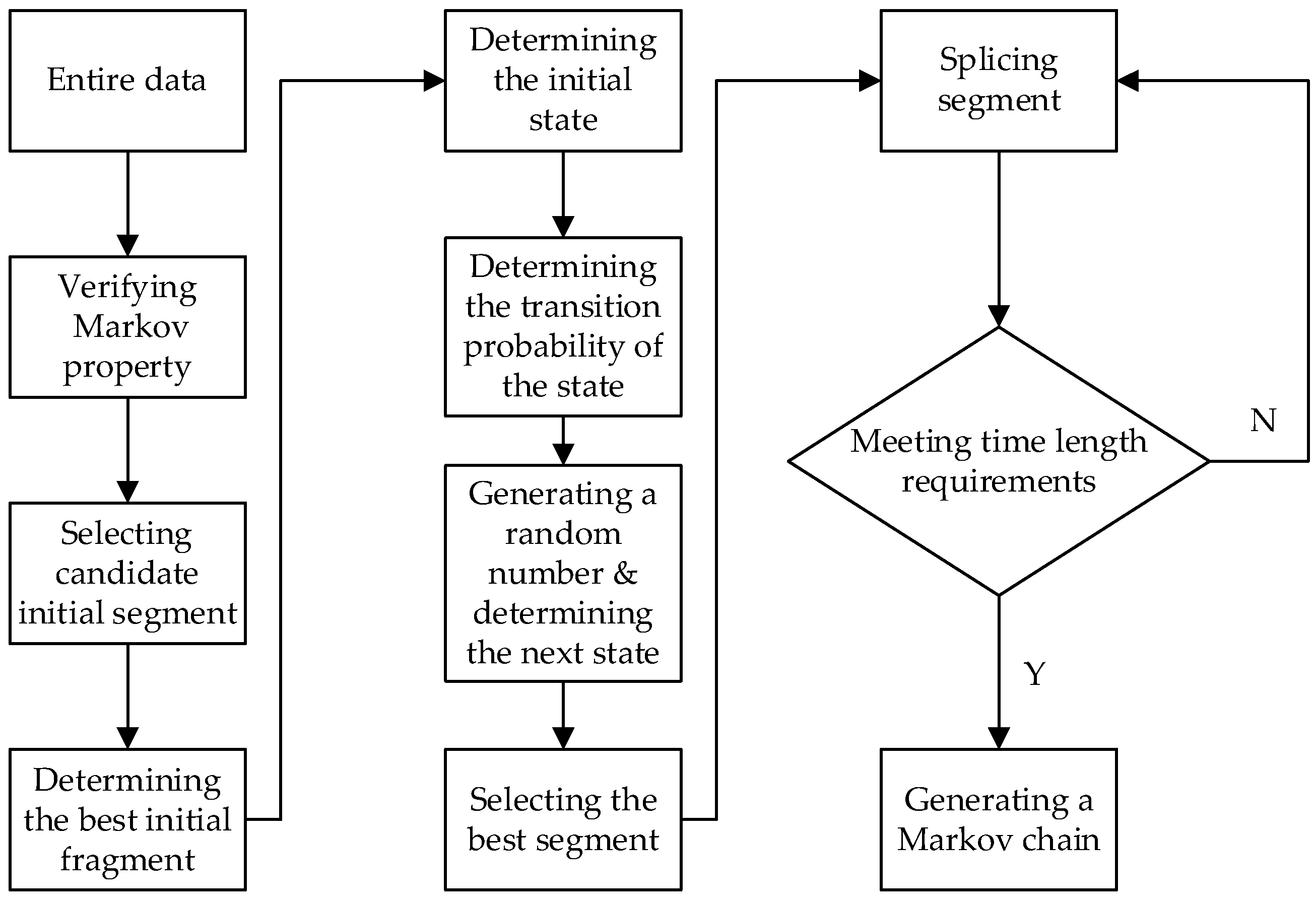
The flow diagram for constructing the Xi’an No.2 bus driving cycle by the combined micro-trip and Markov chain method is shown in
Figure 11.
4.1. Clustering Analysis Experiment and Calculating State Transition Probability Matrix
The partitioning of micro-trips, the definitions of characteristic parameters, and the standardization of characteristic parameters are the same as in the clustering analysis method above.
The combined micro-trip and Markov chain method takes different clusters from clustering analysis as different states and then generates a Markov chain based on the Markov chain method. If the number of micro-trips belonging to a certain cluster is too small, the probability of transition to this cluster will be extremely small, which in turn leads to a small probability of selecting a micro-trip belonging to this cluster during the driving cycle construction. This is equivalent to reducing the amount of data. Therefore, the characteristic parameters should be reasonably selected for clustering analysis to avoid the above phenomenon.
To determine appropriate characteristic parameters, 30 different combinations of characteristic parameters were selected. SPSS software was used to conduct a k-means clustering analysis experiment on 2565 micro-trips, and the number of clusters was 3. After analyzing the clustering results, the four characteristic parameters of maximum speed, the standard deviation of speed, maximum acceleration, and maximum deceleration were selected as the best combination of characteristic parameters for clustering analysis, which is the most in line with the actual driving cycle of the bus.
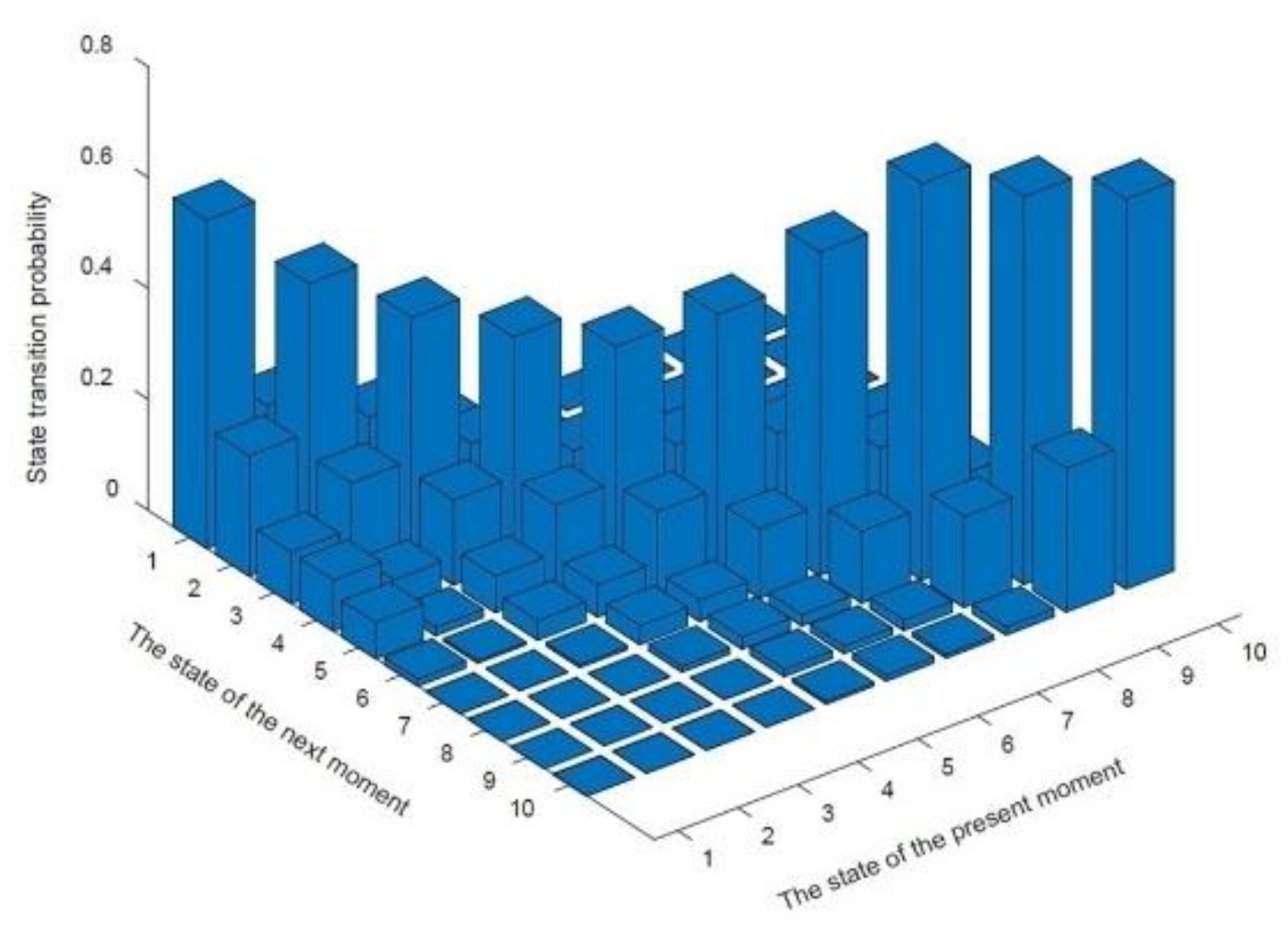
The Markov property verification is the same as in the Markov chain method above, and the calculation results for the state transition probability matrix are shown in (11).
4.2. Generating Markov Chains and Constructing Driving Cycles
The process of generating a Markov chain is like the Markov chain method above. We determine the state of the initial segment based on the cluster it belongs to. The state of the next unit segment is then determined according to the state transition matrix, each unit segment in the corresponding state segment set is selected for long-segment splicing, and the similarity between the V-A matrix of the current long segment and the V-A matrix for the overall data is calculated respectively. We select the unit segment with the maximum similarity in the corresponding state segment set, and each unit segment can only be selected once.
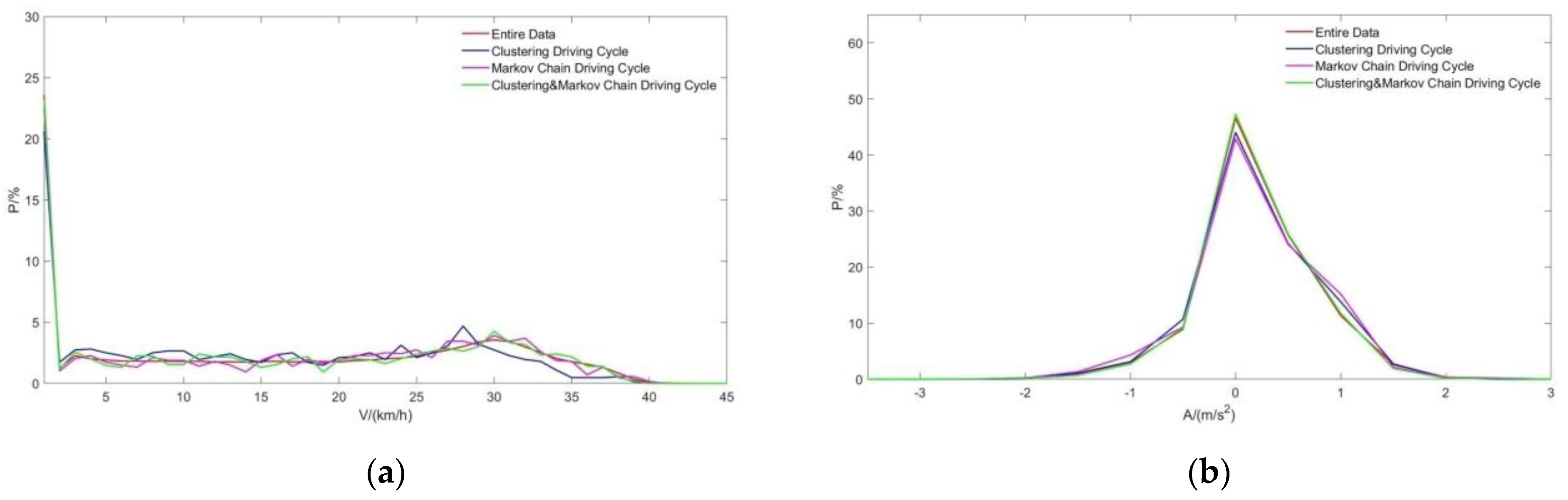
This step is repeated until the time length of the current long segment is appropriate. After each step, the similarity between the V-A matrix of the current long segment and the V-A matrix of the overall data is calculated according to (4). In this way, a candidate driving cycle is constructed. The above steps are repeated to construct a total of 50 candidate driving cycles. The candidate driving cycle with the minimum average deviation is selected as the final representative driving cycle according to (6) and (7) [
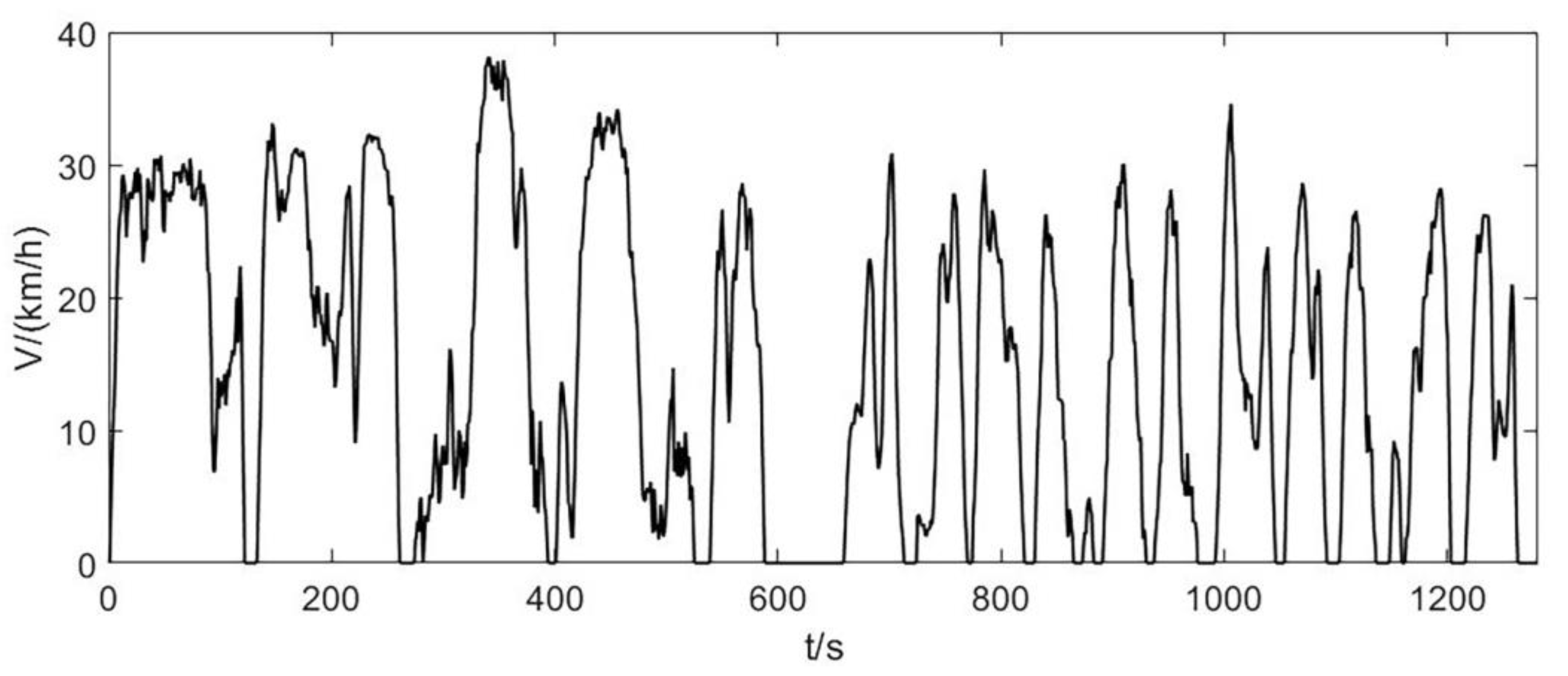
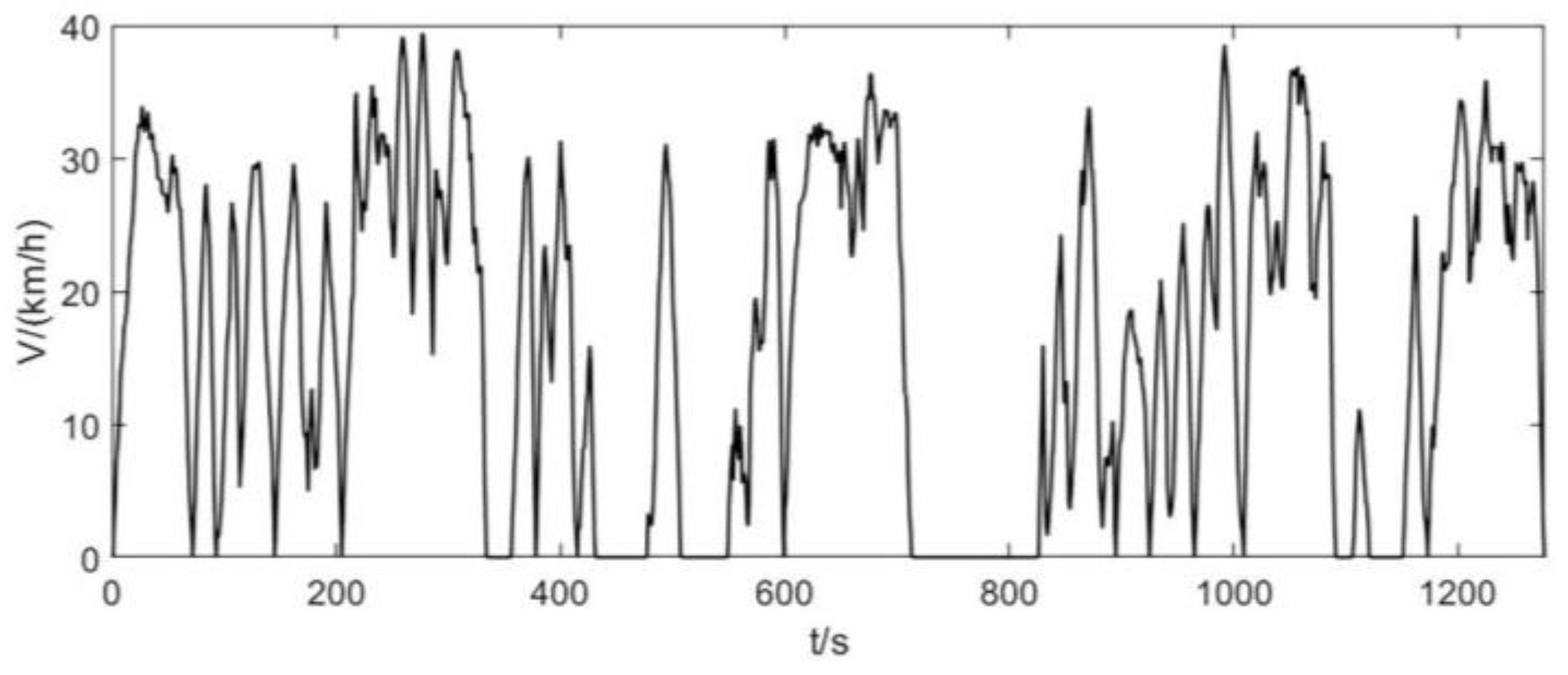
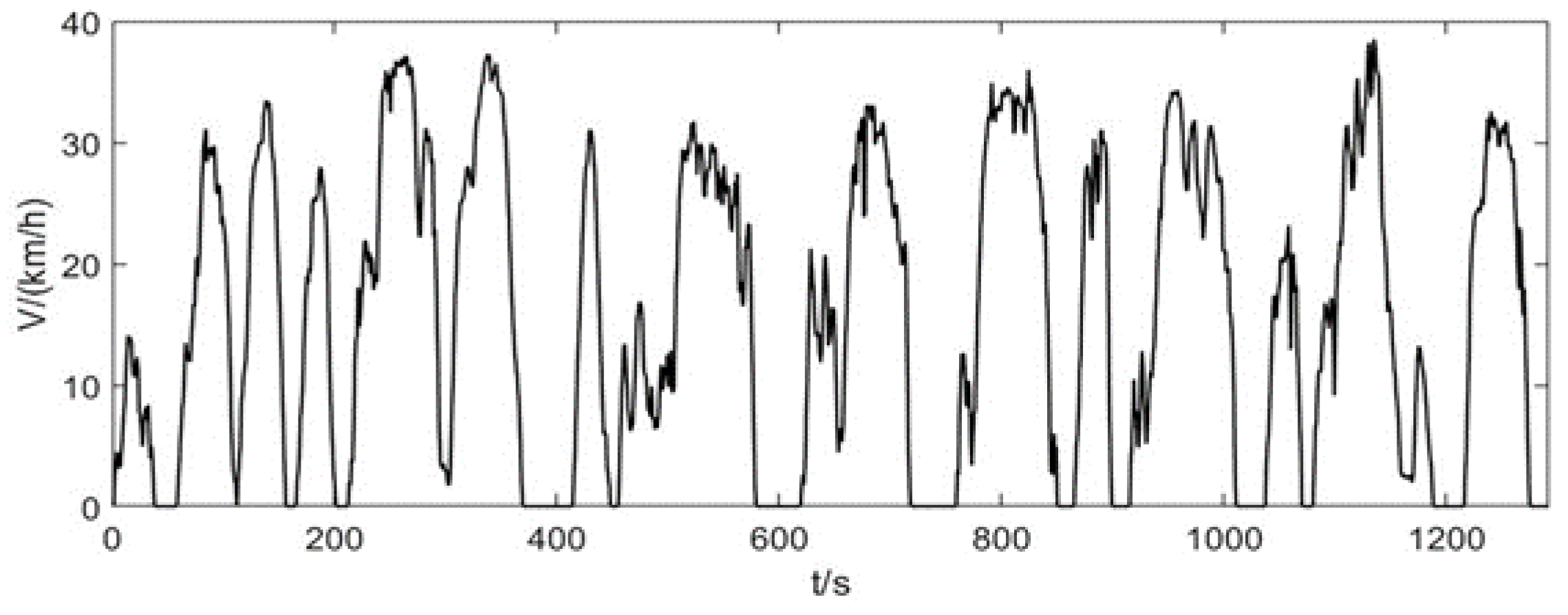
23]. The representative driving cycle is shown in
Figure 12. The running time is 1292 s, the running distance is 5.64 km, the maximum speed is 38.48 km/h, the maximum acceleration is 2.44 m/s
2, and the maximum deceleration is −2.78 m/s
2.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}