
Analysis of the Performance of Machine Learning Models in Predicting the Severity Level of Large-Truck Crashes



Abstract
1. Introduction
2. Literature Review
2.1. Crash Severity Prediction Models
2.2. Data Balancing Techniques in Crash Severity Prediction Modeling
3. Study Data
3.1. Data Source
3.2. Variables Selection and Setting
4. Methodology
4.1. Crash Severity Modeling Methods
4.1.1. Random Forest (RF)
4.1.2. Adaptive Boosting (AdaBoost)
4.1.3. Gradient Boosting Decision Tree (GBDT)
4.1.4. Extreme Gradient Boosting (XGBoost)
4.1.5. Support Vector Machine (SVM)
4.1.6. k-Nearest Neighbor (k-NN)
4.2. Data-Balancing Techniques
- SMOTE: Using k-Nearest Neighbors, this method aims to create synthetic instances for minority classes [29]. Depending upon the amount of over-sampling required, neighbors from the k nearest neighbors are randomly chosen.
- RUS: Aims to balance the class distribution by randomly eliminating the number of instances of the majority class until the dataset is balanced [3]. The major disadvantage of RUS is that it can delete instances that could be important for data analysis.
- The Mixed technique: This method combines both SMOTE and RUS techniques. In this method, the instance number of the minority class is increased while the instance number of the majority class is discarded until the classes are balanced, while the dataset size remains the same as the original dataset size [16].
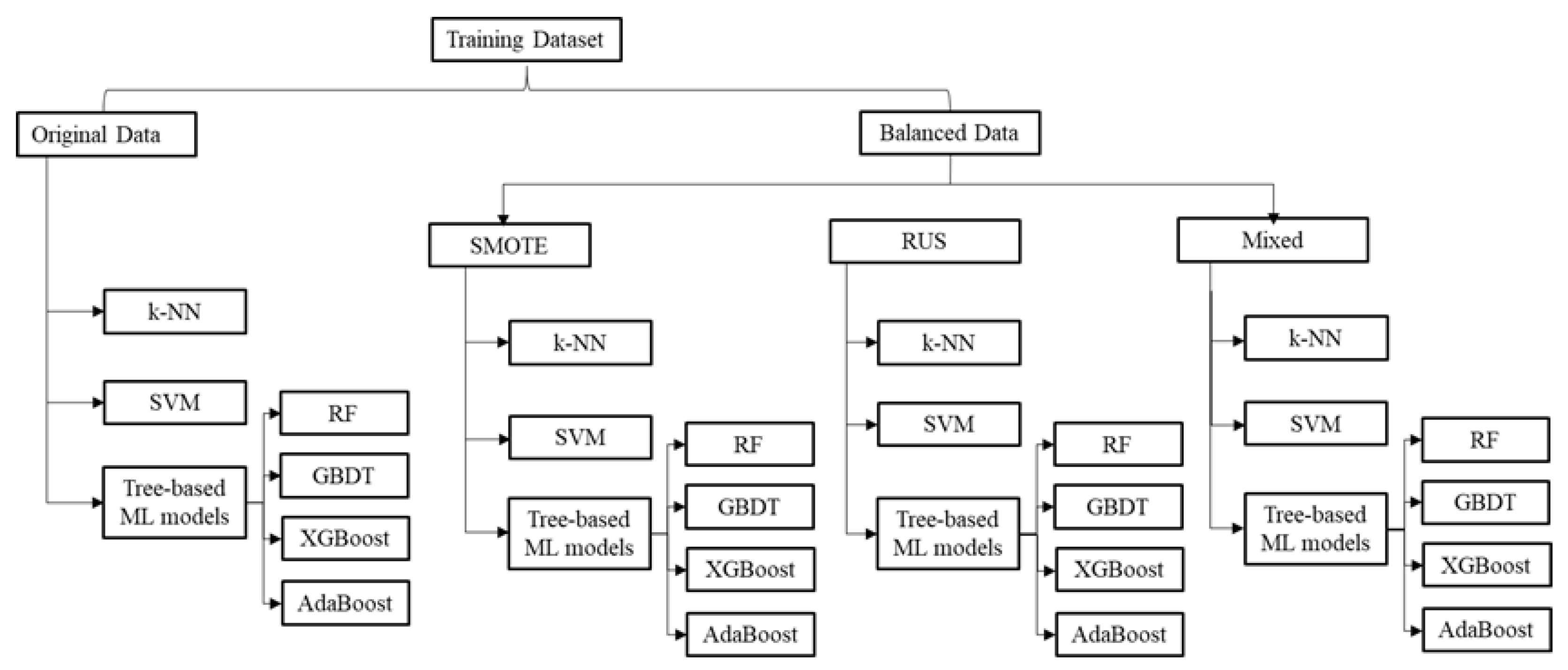
4.3. Study Design
4.4. Prediction Evaluation Measures
5. Results and Analysis
5.1. Imbalanced versus Balanced Training Datasets
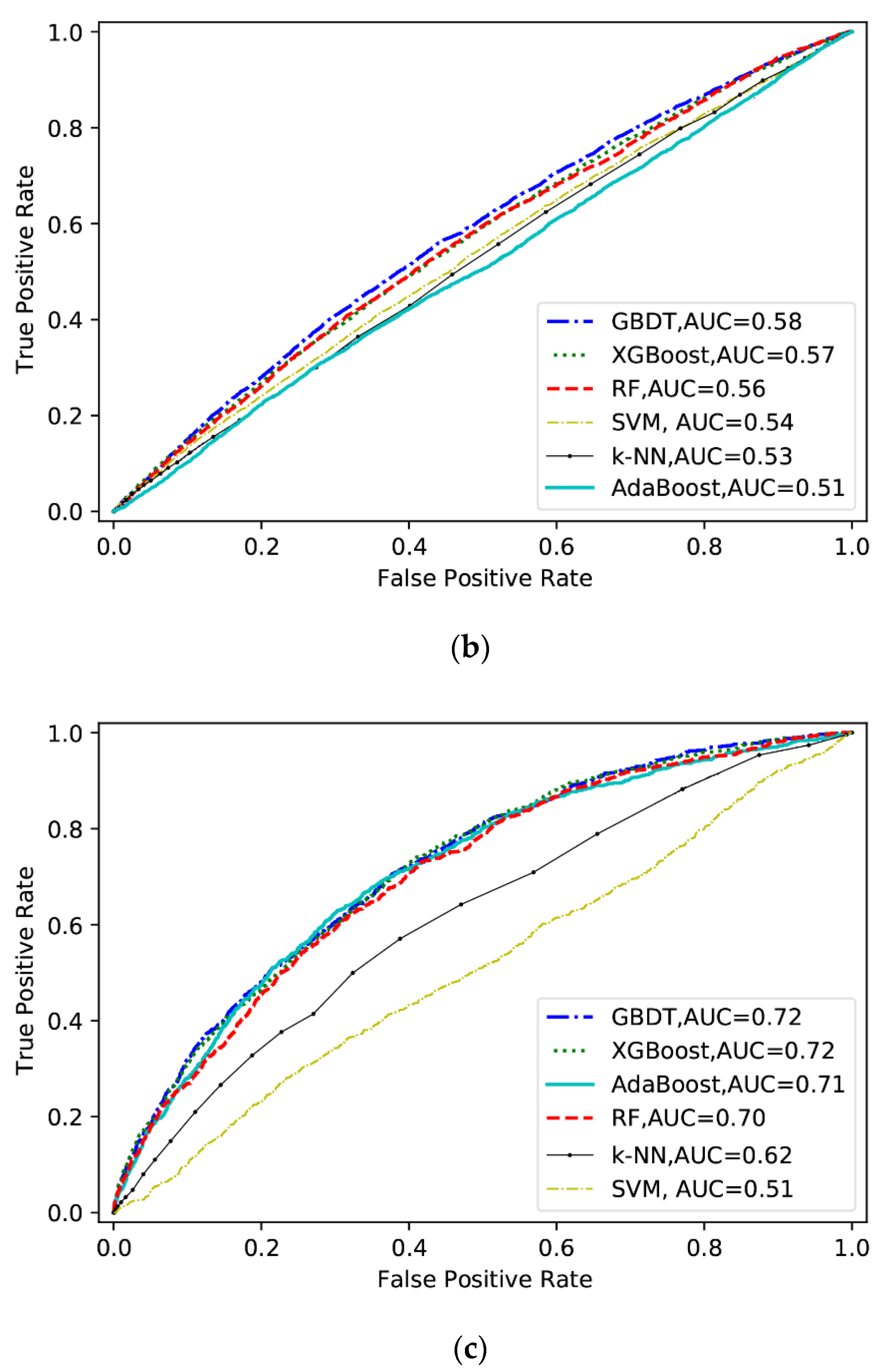
5.2. Prediction Performance of Machine Learning Models
6. Conclusions and Recommendations
- For XGBoost, GBDT, RF, AdaBoost, k-NN, and SVM tested in this study, using an imbalanced training dataset did not affect the model performance. In fact, the original dataset works better in predicting all three levels of severity when compared to the balanced datasets. Therefore, we would recommend using the training dataset that has a similar distribution as the prediction distribution to train the selected ML-based models.
- Classification tree-based ML models (XGBoost, AdaBoost, RF, and GBDT) perform relatively better than the non-tree-based ML models (SVM and k-NN) at all three severity levels. Among them, the GBDT model performs best.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Fiorentini, N.; Losa, M. Handling imbalanced data in road crash severity prediction by machine learning algorithms. Infrastructures 2020, 5, 61. [Google Scholar] [CrossRef]
- Su, X.; Zhou, T.; Yan, X.; Fan, J.; Yang, S. Interaction trees with censored survival data. Int. J. Biostat. 2008, 4, 1–26. [Google Scholar] [CrossRef]
- Kotsiantis, S.; Kanellopoulos, D.; Pintelas, P. Handling imbalanced datasets: A review. GESTS Int. Trans. Comput. Sci. Eng. 2006, 30, 25–36. [Google Scholar]
- Oommen, T.; Baise, L.G.; Vogel, R.M. Sampling bias and class imbalance in maximum-likelihood logistic regression. Math. Geosci. 2011, 43, 99–120. [Google Scholar] [CrossRef]
- Wei, F.; Cai, Z.; Wang, Z.; Guo, Y.; Li, X.; Wu, X. Investigating Rural Single-Vehicle Crash Severity by Vehicle Types Using Full Bayesian Spatial Random Parameters Logit Model. Appl. Sci. 2021, 11, 7819. [Google Scholar] [CrossRef]
- Guo, Y.; Osama, A.; Sayed, T. A cross-comparison of different techniques for modeling macro-level cyclist crashes. Accid. Anal. Prev. 2018, 113, 38–46. [Google Scholar] [CrossRef]
- Cai, Z.; Wei, F.; Wang, Z.; Guo, Y.; Chen, L.; Li, X. Modeling of Low Visibility-Related Rural Single-Vehicle Crashes considering Unobserved Heterogeneity and Spatial Correlation. Sustainability 2021, 13, 7438. [Google Scholar] [CrossRef]
- Li, Z.; Liu, P.; Wang, W.; Xu, C. Using support vector machine models for crash injury severity analysis. Accid. Anal. Prev. 2012, 45, 478–486. [Google Scholar] [CrossRef]
- Pineda-Jaramillo, J.; Barrera-Jiménez, H.; Mesa-Arango, R. Unveiling the relevance of traffic enforcement cameras on the severity of vehicle–pedestrian collisions in an urban environment with machine learning models. J. Saf. Res. 2022, 81, 225–238. [Google Scholar] [CrossRef]
- Chang, L.-Y.; Chien, J.-T. Analysis of driver injury severity in truck-involved accidents using a non-parametric classification tree model. Saf. Sci. 2013, 51, 17–22. [Google Scholar] [CrossRef]
- Yu, R.; Abdel-Aty, M. Utilizing support vector machine in real-time crash risk evaluation. Accid. Anal. Prev. 2013, 51, 252–259. [Google Scholar] [CrossRef]
- Iranitalab, A.; Khattak, A. Comparison of four statistical and machine learning methods for crash severity prediction. Accid. Anal. Prev. 2017, 108, 27–36. [Google Scholar] [CrossRef] [PubMed]
- Tang, J.; Liang, J.; Han, C.; Li, Z.; Huang, H. Crash injury severity analysis using a two-layer Stacking framework. Accid. Anal. Prev. 2019, 122, 226–238. [Google Scholar] [CrossRef] [PubMed]
- Schlögl, M.; Stütz, R.; Laaha, G.; Melcher, M. A comparison of statistical learning methods for deriving determining factors of accident occurrence from an imbalanced high resolution dataset. Accid. Anal. Prev. 2019, 127, 134–149. [Google Scholar] [CrossRef] [PubMed]
- Thammasiri, D.; Delen, D.; Meesad, P.; Kasap, N. A critical assessment of imbalanced class distribution problem: The case of predicting freshmen student attrition. Expert Syst. Appl. 2014, 41, 321–330. [Google Scholar] [CrossRef]
- Mujalli, R.O.; López, G.; Garach, L. Bayes classifiers for imbalanced traffic accidents datasets. Accid. Anal. Prev. 2016, 88, 37–51. [Google Scholar] [CrossRef]
- Rivera, G.; Florencia, R.; García, V.; Ruiz, A.; Sánchez-Solís, J.P. News classification for identifying traffic incident points in a Spanish-speaking country: A real-world case study of class imbalance learning. Appl. Sci. 2020, 10, 6253. [Google Scholar] [CrossRef]
- Abou Elassad, Z.E.; Mousannif, H.; Al Moatassime, H. A proactive decision support system for predicting traffic crash events: A critical analysis of imbalanced class distribution. Knowl.-Based Syst. 2020, 205, 106314. [Google Scholar] [CrossRef]
- Fernández, A.; García, S.; del Jesus, M.J.; Herrera, F. A study of the behaviour of linguistic fuzzy rule based classification systems in the framework of imbalanced data-sets. Fuzzy Sets Syst. 2008, 159, 2378–2398. [Google Scholar] [CrossRef]
- Greene, W.H. Econometric Analysis, 4th ed.; International Edition; Prentice Hall: Hoboken, NJ, USA, 2000. [Google Scholar]
- Duncan, G.J.; Magnuson, K.A.; Ludwig, J. The endogeneity problem in developmental studies. Res. Hum. Dev. 2004, 1, 59–80. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Chen, S.-H.; Pan, J.-S.; Lu, K. Driving Behavior Analysis Based on Vehicle OBD Information and Adaboost Algorithms. In Proceedings of the International Multiconference of Engineers and Computer Scientists, Hong Kong, China, 18–20 March 2015; pp. 18–20. [Google Scholar]
- Li, J.; Liu, J.; Liu, P.; Qi, Y. Analysis of factors contributing to the severity of large truck crashes. Entropy 2020, 22, 1191. [Google Scholar] [CrossRef] [PubMed]
- Fan, J.; Wang, X.; Wu, L.; Zhou, H.; Zhang, F.; Yu, X.; Lu, X.; Xiang, Y. Comparison of Support Vector Machine and Extreme Gradient Boosting for predicting daily global solar radiation using temperature and precipitation in humid subtropical climates: A case study in China. Energy Convers. Manag. Sci. 2018, 164, 102–111. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Fransico, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer Science & Business Media: Berlin, Germany, 1999. [Google Scholar]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Fernández, A.; García, S.; Galar, M.; Prati, R.C.; Krawczyk, B.; Herrera, F. Learning from Imbalanced Data Sets; Springer: Berlin, Germany, 2018; Volume 10. [Google Scholar]
- Wei, F.; Cai, Z.; Guo, Y.; Liu, P.; Wang, Z.; Li, Z. Analysis of roadside accident severity on rural and urban roadways. Intell. Autom. Soft Comput. 2021, 28, 753–767. [Google Scholar] [CrossRef]
- Liu, X.; Zhou, Z. Ensemble methods for class imbalance learning. In Imbalanced Learning: Foundations, Algorithms, and Applications; Wiley: Hoboken, NJ, USA, 2013. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Traffic Control | Weather Characteristics | ||
|---|---|---|---|
| none | 1 for no traffic control, 0 otherwise (baseline) | clr | 1 for clear weather condition, 0 otherwise (baseline) |
| st_sign | 1 for traffic control is stop sign, 0 otherwise | rain | 1 for raining weather condition, 0 otherwise |
| sig_light | 1 for signal light controlled, 0 otherwise | snw | 1 for snowing weather condition, 0 otherwise |
| yld_sign | 1 for yield sign controlled, 0 otherwise | blowing | 1 for blowing sand weather condition, 0 otherwise |
| flash_light | 1 for flashing light controlled, 0 otherwise | fog | 1 for fog weather condition, 0 otherwise |
| mk_lane | 1 for markedlane controlled, 0 otherwise | sleet | 1 for sleet weather condition, 0 otherwise |
| sig_camera | 1 for signal camera controlled, 0 otherwise | sv_crosswinds | 1 for severe crosswinds weather condition, 0 otherwise |
| Light characteristics | Median type | ||
| day_light | 1 for crash during daylight, 0 otherwise (baseline) | median_none | 1 lane with no median, 0 otherwise (baseline) |
| dawn | 1 for crash during dark yet not lighted, 0 otherwise | unprotected | 1 lane with unprotected, 0 otherwise |
| dk_no_light | 1 for crash during dawn, 0 otherwise | posi_barrier | 1 lane with positive barrier, 0 otherwise |
| dk_light | 1 for crash during dark yet lighted, 0 otherwise | one_way_pair | 1 lane with one-way pair, 0 otherwise |
| dusk | 1 for crash during dusk, 0 otherwise | curbed | 1 lane with curbed, 0 otherwise |
| Roadway functional system | Road alignment | ||
| r_int_hwy | 1 crashes in rural interstate highway, 0 otherwise (baseline) | stgt_evel | 1 for straight level road alignment, 0 otherwise (baseline) |
| u_int_hwy | 1 crash in urban interstate highway, 0 otherwise | stgt_grade | 1 for straight grade road alignment, 0 otherwise |
| r_ppl_a | 1 crash in rural principle arterial, 0 otherwise | stgt_hillcrest | 1 for straight hillcrest road alignment, 0 otherwise |
| u_oth_ppl_a | 1 crash in urban other principle arterial, 0 otherwise | curve_level | 1 for curve level road alignment, 0 otherwise |
| u_minor_a | 1 crash in urban minor arterial, 0 otherwise | curve_grade | 1 for curve grade road alignment, 0 otherwise |
| r_minor_a | 1 crash in rural minor arterial, 0 otherwise | curve_hillcrest | 1 for curve hillcrest road alignment, 0 otherwise |
| Location of first harmful event | Base type | ||
| on_rd | 1 for crash occurred on road, 0 otherwise (baseline) | soil | 1 for soil road, 0 otherwise (baseline) |
| on_shlder | 1 for crash occurred on shoulder, 0 otherwise | granular | 1 for granular road, 0 otherwise |
| on_median | 1 for crash occurred on median, 0 otherwise | asph | 1 for asphalt road, 0 otherwise |
| off_rd | 1 for crash occurred off road, 0 otherwise | concr | 1 for concrete road, 0 otherwise |
| Shoulder type left | Curb type left | ||
| shldr_lt_none | 1 for no left shoulder, 0 otherwise (baseline) | curb_lt_none | 1 for no left curb, 0 otherwise (baseline) |
| shldr_lt | 1 if left shoulder exists, 0 otherwise | curb_lt | 1 if left curb exists, 0 otherwise |
| Shoulder type right | Curb type right | ||
| shldr_rt_none | 1 for no right shoulder, 0 otherwise (baseline) | curb_rt_none | 1 for no right curb, 0 otherwise (baseline) |
| shldr_rt | 1 if right shoulder exists, 0 otherwise | curb_rt | 1 if right curb exists, 0 otherwise |
| Road type | Crash contributing factors | ||
| 2lane_ 2way | 1 for road type that is 2 lanes, 2 way, 0 otherwise (baseline) | fatigue | 1 for driver under influence of fatigue, 0 otherwise |
| 4ormore_div | 1 for road type that is 4 or more, divided, 0 otherwise | drug | 1 for driver under influence of drug, 0 otherwise |
| 4ormore_undiv | 1 for road type that is 4 or more, undivided, 0 otherwise | alcohol | 1 for driver under influence of alcohol, 0 otherwise |
| Lane width and shoulder width | Numerical variables | ||
| lane_wid | width of lanes in feet | adt_adj_curnt_amt | adjusted average daily traffic for the current year for crashes located on the road |
| shldr_width_left | width of left shoulder in feet | crash_spd_lim | speed limit of the lane |
| shldr_width_right | width of right shoulder in feet | trk_aadt_pct | adjusted average daily traffic percent |
| nbr_of_lane | number of lanes | ||
| Variable | Crash Injury Severity | Total | Percent | Variable | Crash Injury Severity | Total | Percent | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| PDO | SLIG | KSEV | PDO | SLIG | KSEV | ||||||
| Traffic Control | Weather Characteristics | ||||||||||
| none | 6587 | 1819 | 275 | 8681 | 10.44% | clr | 43,087 | 13,219 | 2764 | 59,070 | 71.04% |
| st_sign | 2679 | 915 | 273 | 3867 | 4.65% | rain | 6333 | 1978 | 332 | 8643 | 10.39% |
| sig_light | 7271 | 2081 | 253 | 9605 | 11.55% | snw | 133 | 26 | 5 | 164 | 0.20% |
| yld_sign | 938 | 262 | 28 | 1228 | 1.48% | blowing | 36 | 13 | 8 | 57 | 0.07% |
| flash_light | 283 | 96 | 32 | 411 | 0.49% | fog | 422 | 188 | 90 | 700 | 0.84% |
| mk_lane | 31,653 | 10,224 | 1872 | 43,749 | 52.62% | sleet | 153 | 35 | 9 | 197 | 0.24% |
| sig_camera | 116 | 33 | 5 | 154 | 0.19% | sv_crosswinds | 159 | 40 | 11 | 210 | 0.25% |
| Light Characteristics | Median Type | ||||||||||
| day_light | 45,662 | 13,980 | 2326 | 61,968 | 74.53% | median_none | 17,147 | 5482 | 1639 | 24,268 | 29.19% |
| dawn | 828 | 276 | 84 | 1188 | 1.43% | unprotected | 5882 | 1818 | 368 | 8068 | 9.70% |
| dk_no_light | 6667 | 2249 | 894 | 9810 | 11.80% | posi_barrier | 11,128 | 3634 | 720 | 15,482 | 18.62% |
| dk_light | 6534 | 2150 | 480 | 9164 | 11.02% | one_way_pair | 103 | 18 | 1 | 122 | 0.15% |
| dusk | 448 | 139 | 39 | 626 | 0.75% | curbed | 675 | 220 | 27 | 922 | 1.11% |
| Roadway Functional System | Road Alignment | ||||||||||
| r_int_hwy | 21,967 | 6639 | 829 | 29,435 | 35.40% | stgt_evel | 46,507 | 14,148 | 2729 | 63,384 | 76.23% |
| u_int_hwy | 5766 | 1958 | 733 | 8457 | 10.17% | stgt_grade | 6265 | 2161 | 516 | 8942 | 10.75% |
| r_ppl_a | 17,158 | 5611 | 769 | 23,538 | 28.31% | stgt_hillcrest | 1799 | 741 | 150 | 2690 | 3.24% |
| u_oth_ppl_a | 2348 | 680 | 139 | 3167 | 3.81% | curve_level | 3304 | 999 | 265 | 4568 | 5.49% |
| u_minor_a | 2853 | 963 | 438 | 4254 | 5.12% | curve_grade | 1947 | 652 | 152 | 2751 | 3.31% |
| r_minor_a | 6567 | 1769 | 538 | 8874 | 10.67% | curve_hillcrest | 449 | 121 | 26 | 596 | 0.72% |
| Location of First Harmful Event | Base Type | ||||||||||
| on_rd | 52,128 | 16,415 | 3226 | 71,769 | 86.31% | soil | 372 | 133 | 42 | 547 | 0.66% |
| on_shlder | 764 | 190 | 130 | 1084 | 1.30% | granular | 34,451 | 10,964 | 2561 | 47,976 | 57.70% |
| on_median | 1873 | 641 | 115 | 2629 | 3.16% | asph | 788 | 223 | 50 | 1061 | 1.28% |
| off_rd | 5653 | 1608 | 373 | 7634 | 9.18% | concr | 24,821 | 7534 | 1191 | 33,546 | 40.34% |
| Shoulder Type Left | Curb Type Left | ||||||||||
| shldr_lt_none | 4725 | 1254 | 586 | 6565 | 8.39% | curb_lt_none | 3211 | 1162 | 197 | 4570 | 27.43% |
| shldr_lt | 51,941 | 16,290 | 3459 | 71,690 | 91.61% | curb_lt | 9225 | 2518 | 348 | 12,091 | 72.57% |
| Shoulder Type Right | Curb Type Right | ||||||||||
| shldr_rt_none | 5813 | 1964 | 755 | 8532 | 10.19% | curb_rt_none | 3754 | 1239 | 234 | 5227 | 29.12% |
| shldr_rt | 54,458 | 17,180 | 3573 | 75,211 | 89.81% | curb_rt | 9721 | 2636 | 368 | 12,725 | 70.88% |
| Road Type | Crash Contributing Factors | ||||||||||
| 2lane_2way | 9890 | 3310 | 1185 | 14,385 | 17.30% | fatigue | 804 | 386 | 129 | 1319 | 1.59% |
| 4ormore_div | 43,114 | 13,338 | 2202 | 58,654 | 70.54% | drug | 100 | 84 | 88 | 272 | 0.33% |
| 4ormore_undiv | 7355 | 2189 | 454 | 9998 | 12.02% | alcohol | 348 | 235 | 167 | 750 | 0.90% |
| Datasets | Total | PDO | SLIG | KSEV | |
|---|---|---|---|---|---|
| Original dataset | 61,983 | 44,905 | 14,159 | 2919 | |
| Balanced datasets | SMOTE | 134,715 | 44,905 | 44,905 | 44,905 |
| RUS | 8757 | 2919 | 2919 | 2919 | |
| Mixed | 61,983 | 20,661 | 20,661 | 20,661 | |
| Severity Levels | Datasets | Crash Severity Prediction Models | |||||
|---|---|---|---|---|---|---|---|
| XGBoost | GBDT | RF | AdaBoost | k-NN | SVM | ||
| PDO | Original | 0.59 | 0.60 | 0.58 | 0.58 | 0.53 | 0.53 |
| SMOTE | 0.57 | 0.57 | 0.57 | 0.55 | 0.55 | 0.51 | |
| RUS | 0.57 | 0.58 | 0.55 | 0.57 | 0.51 | 0.53 | |
| Mixed | 0.53 | 0.53 | 0.55 | 0.53 | 0.52 | 0.50 | |
| SLIG | Original | 0.57 | 0.58 | 0.56 | 0.51 | 0.53 | 0.54 |
| SMOTE | 0.55 | 0.55 | 0.52 | 0.51 | 0.52 | 0.51 | |
| RUS | 0.50 | 0.51 | 0.51 | 0.50 | 0.51 | 0.52 | |
| Mixed | 0.52 | 052 | 0.53 | 0.49 | 0.50 | 0.50 | |
| KSEV | Original | 0.72 | 0.72 | 0.70 | 0.71 | 0.62 | 0.51 |
| SMOTE | 0.70 | 0.69 | 0.70 | 0.67 | 0.61 | 0.50 | |
| RUS | 0.71 | 0.72 | 0.70 | 0.71 | 0.62 | 0.51 | |
| Mixed | 0.63 | 0.62 | 0.67 | 0.63 | 0.57 | 0.55 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, J.; Qi, Y.; Tao, J.; Tao, T. Analysis of the Performance of Machine Learning Models in Predicting the Severity Level of Large-Truck Crashes. Future Transp. 2022, 2, 939-955. https://doi.org/10.3390/futuretransp2040052
Liu J, Qi Y, Tao J, Tao T. Analysis of the Performance of Machine Learning Models in Predicting the Severity Level of Large-Truck Crashes. Future Transportation. 2022; 2(4):939-955. https://doi.org/10.3390/futuretransp2040052
Chicago/Turabian StyleLiu, Jinli, Yi Qi, Jueqiang Tao, and Tao Tao. 2022. "Analysis of the Performance of Machine Learning Models in Predicting the Severity Level of Large-Truck Crashes" Future Transportation 2, no. 4: 939-955. https://doi.org/10.3390/futuretransp2040052
APA StyleLiu, J., Qi, Y., Tao, J., & Tao, T. (2022). Analysis of the Performance of Machine Learning Models in Predicting the Severity Level of Large-Truck Crashes. Future Transportation, 2(4), 939-955. https://doi.org/10.3390/futuretransp2040052