
Deep Learning Architectures for Skateboarder–Pedestrian Surrogate Safety Measures




Abstract
:1. Introduction
2. Selection of the Physical Study Area
3. Data Distribution
4. Object Detection Models
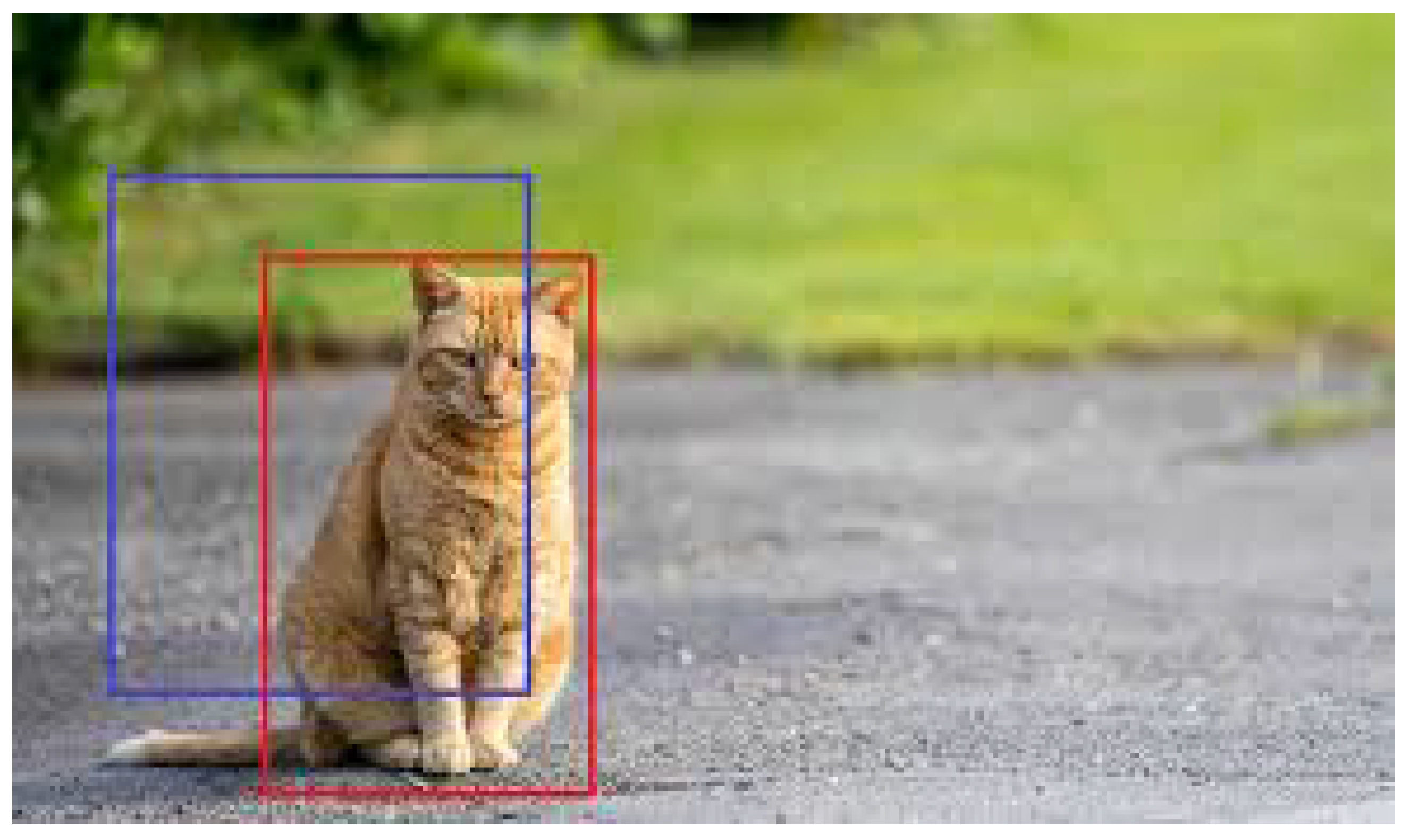
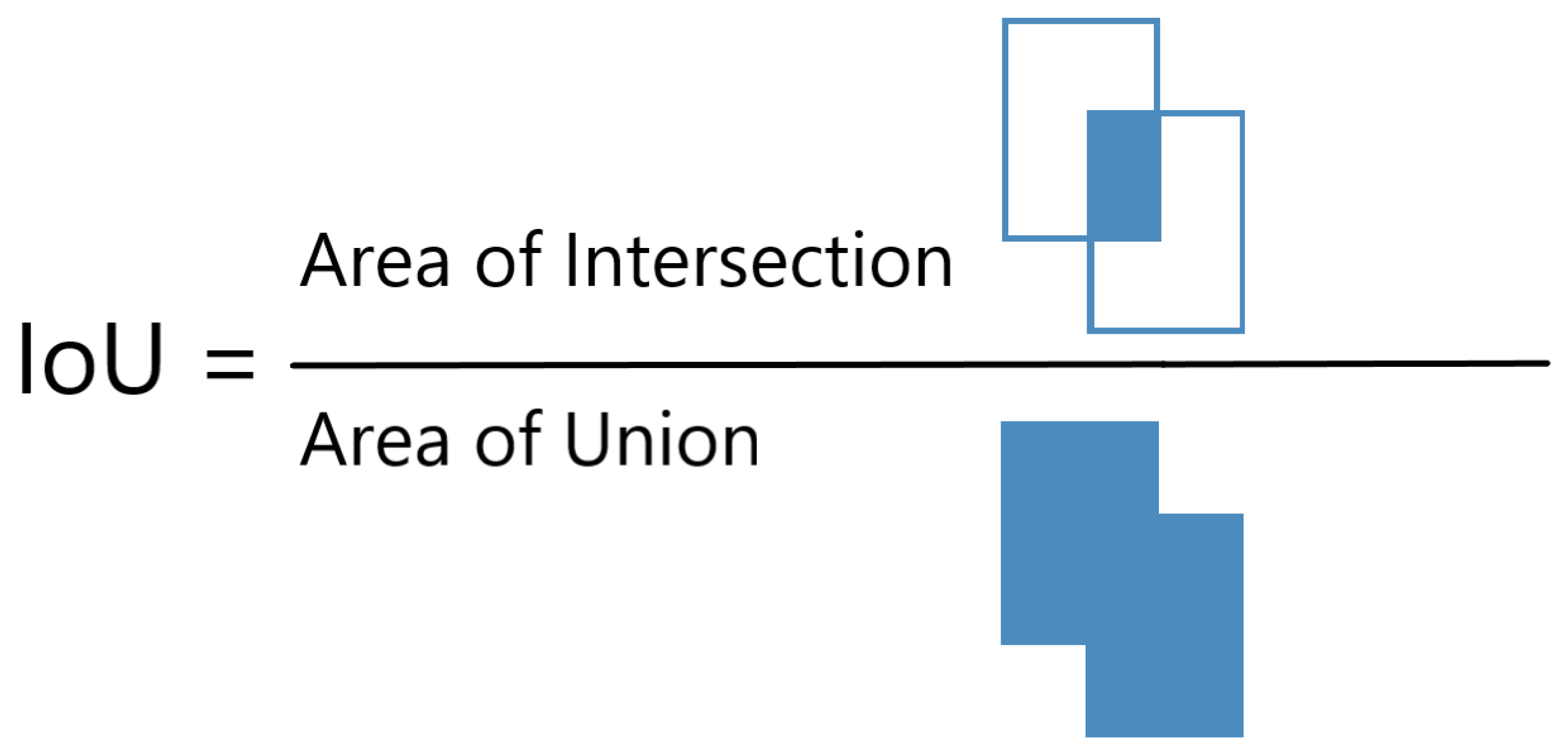
5. Performance Metric of Object Detection Models
6. Results
6.1. Model Input Size
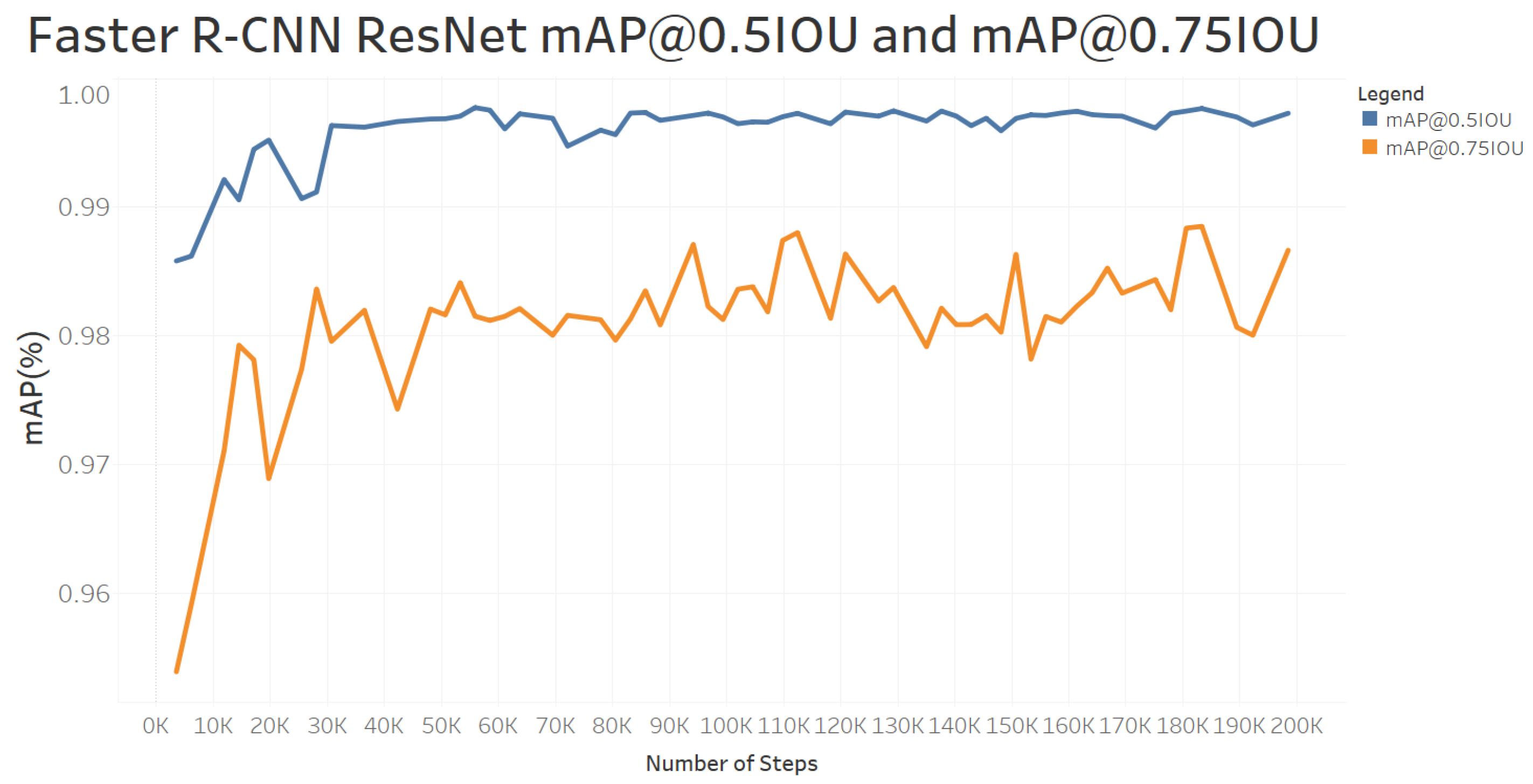
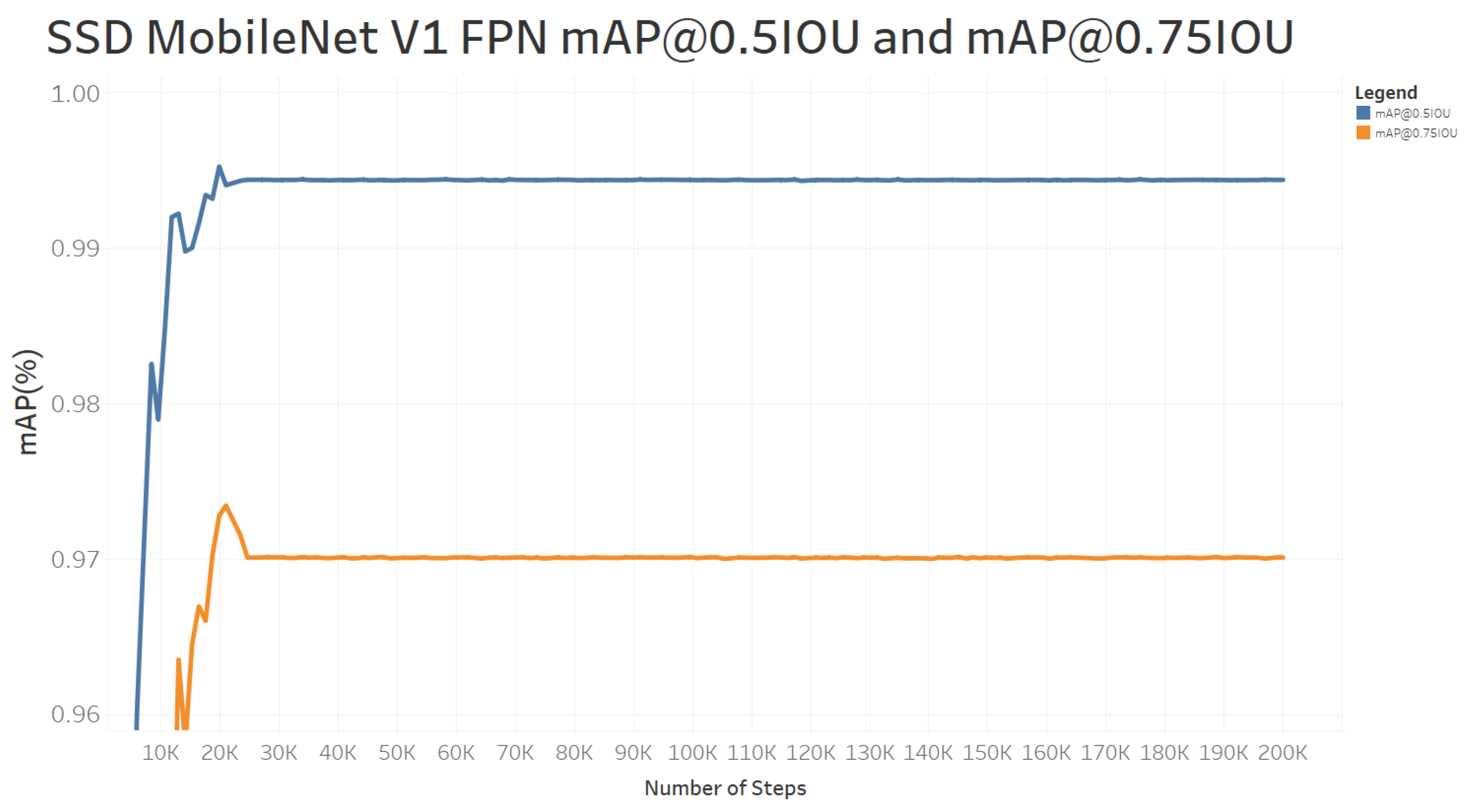
6.2. Model Mean Average Precision
6.3. Hardware and Model Frame Rates
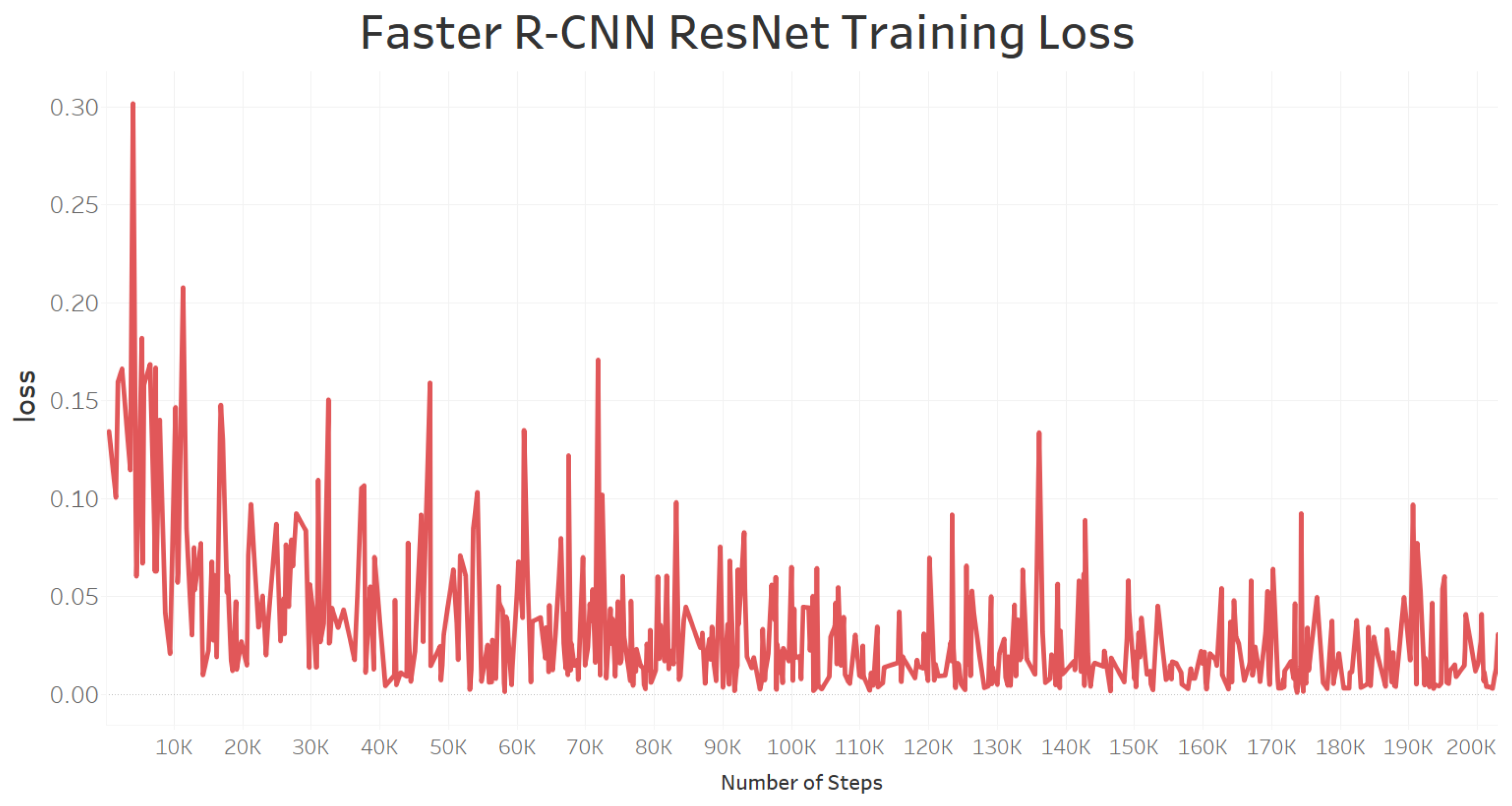
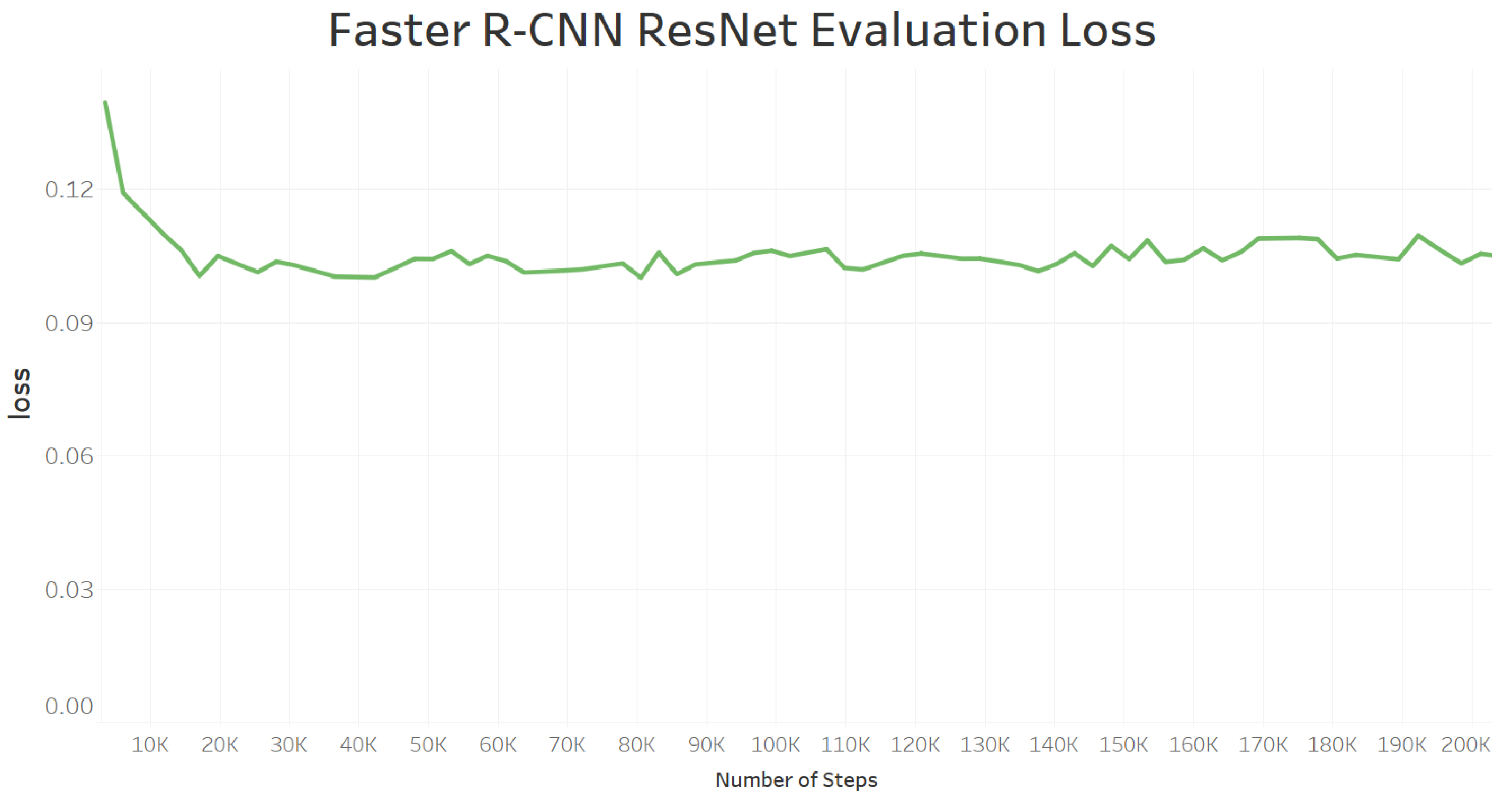
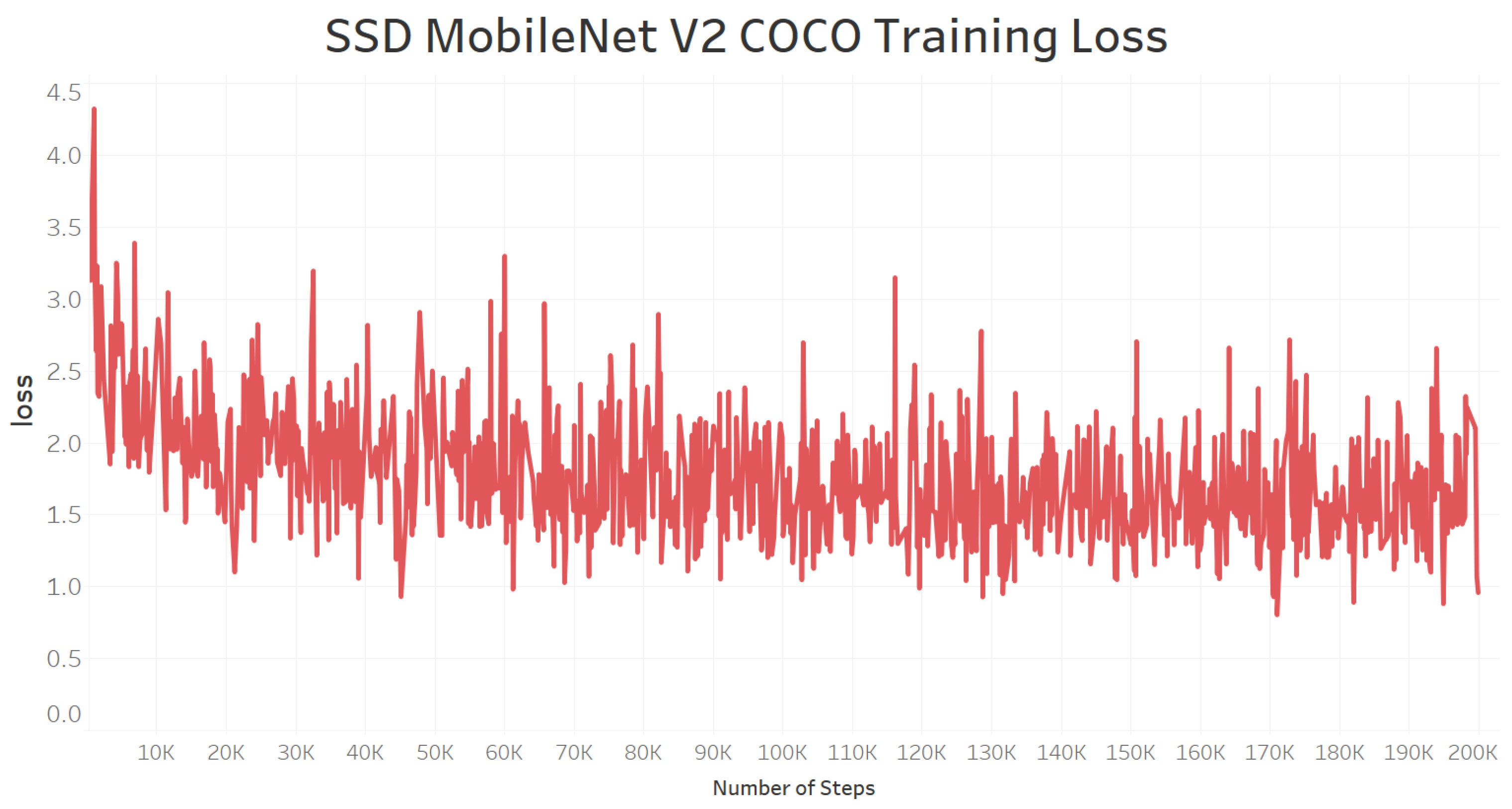
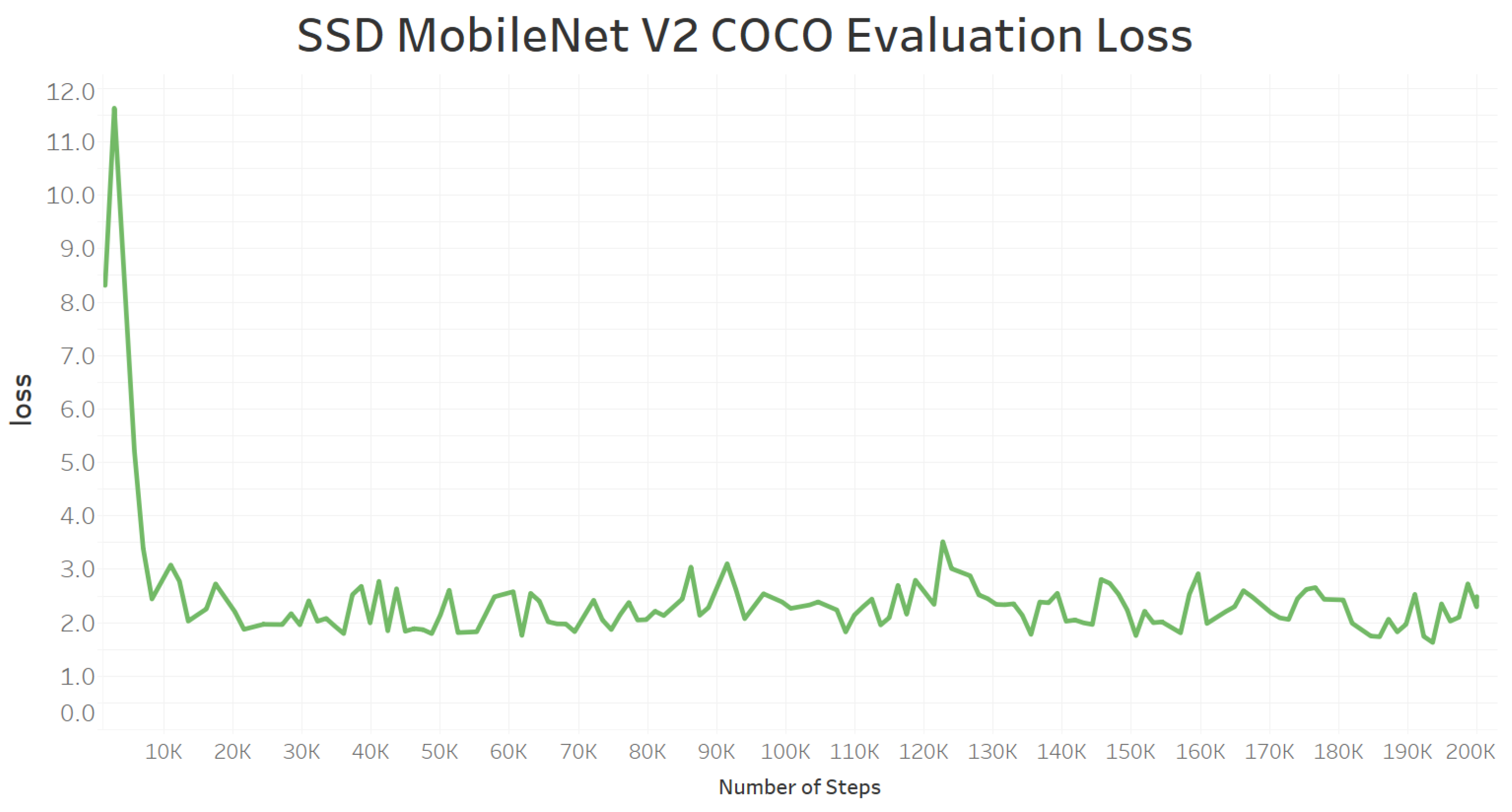
6.4. Model Training Loss and Evaluation Loss
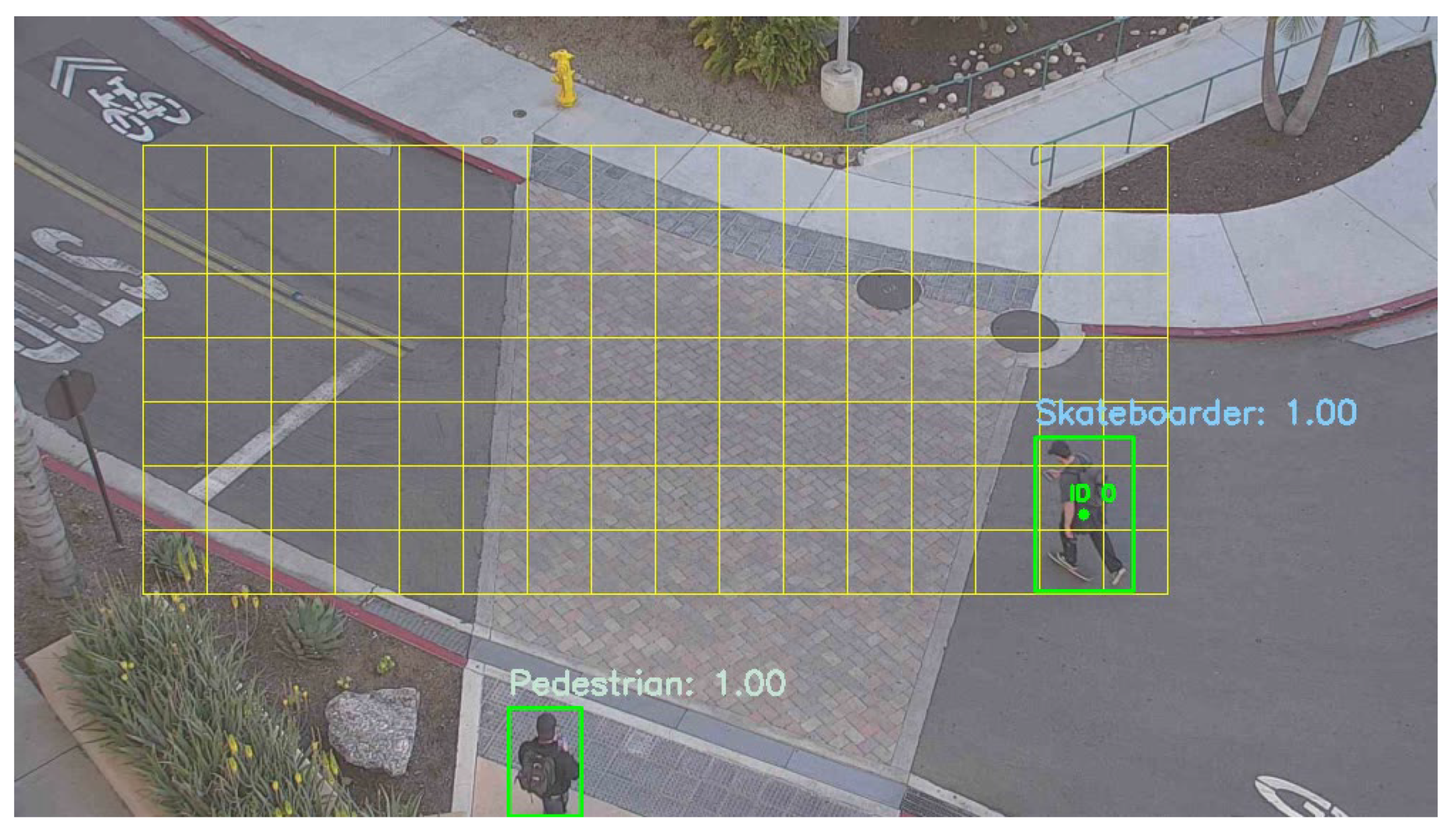
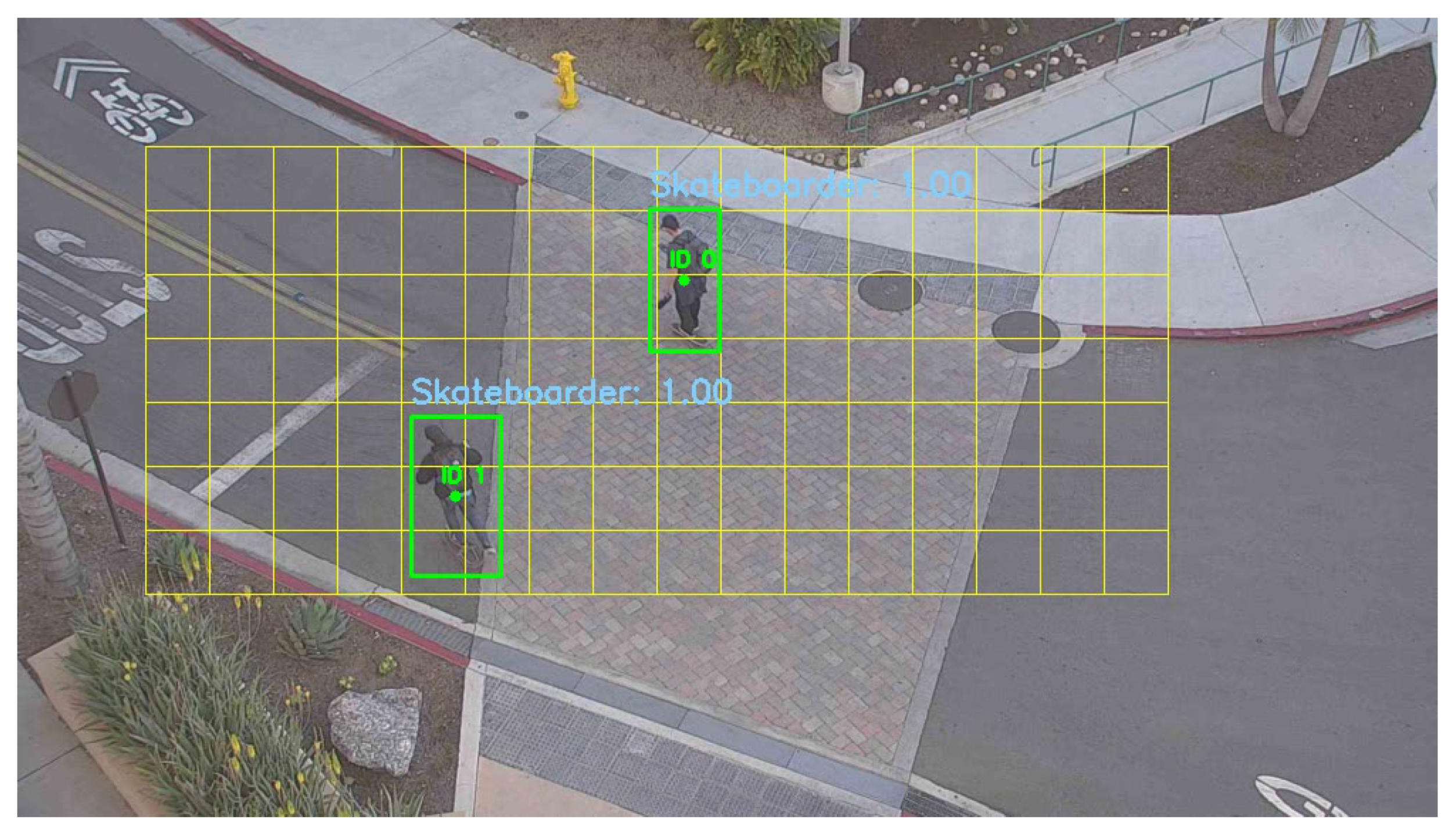
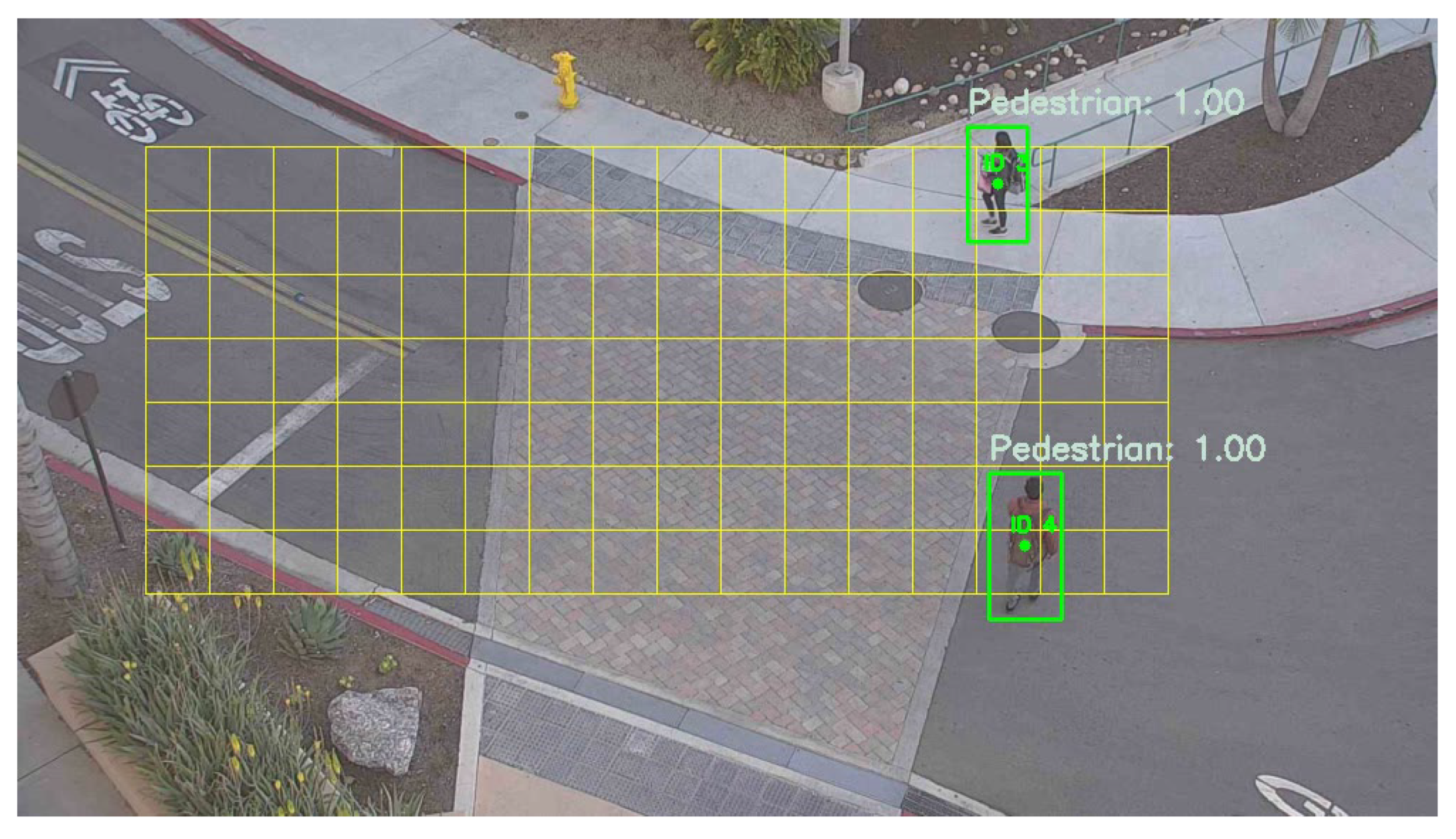
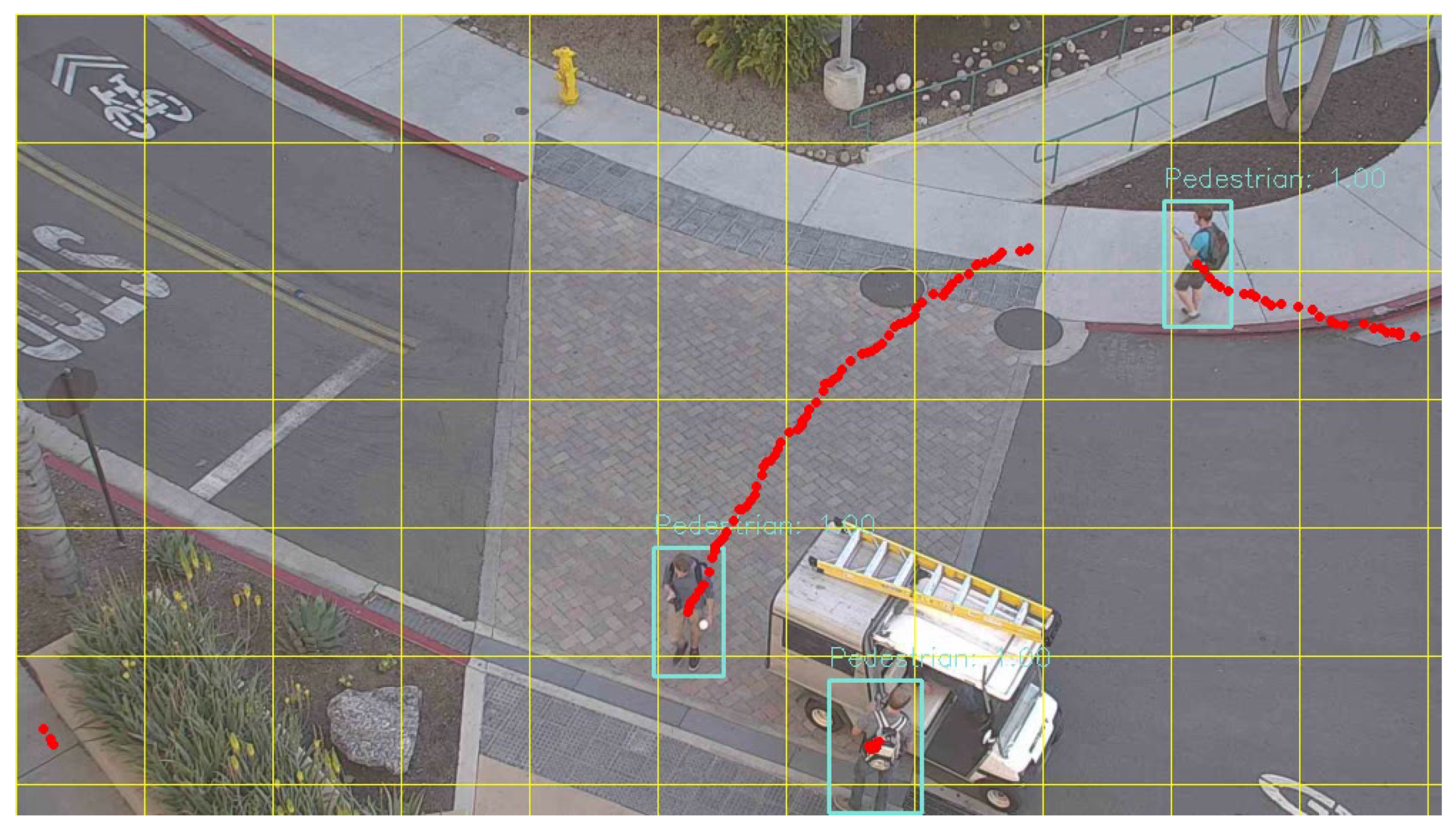
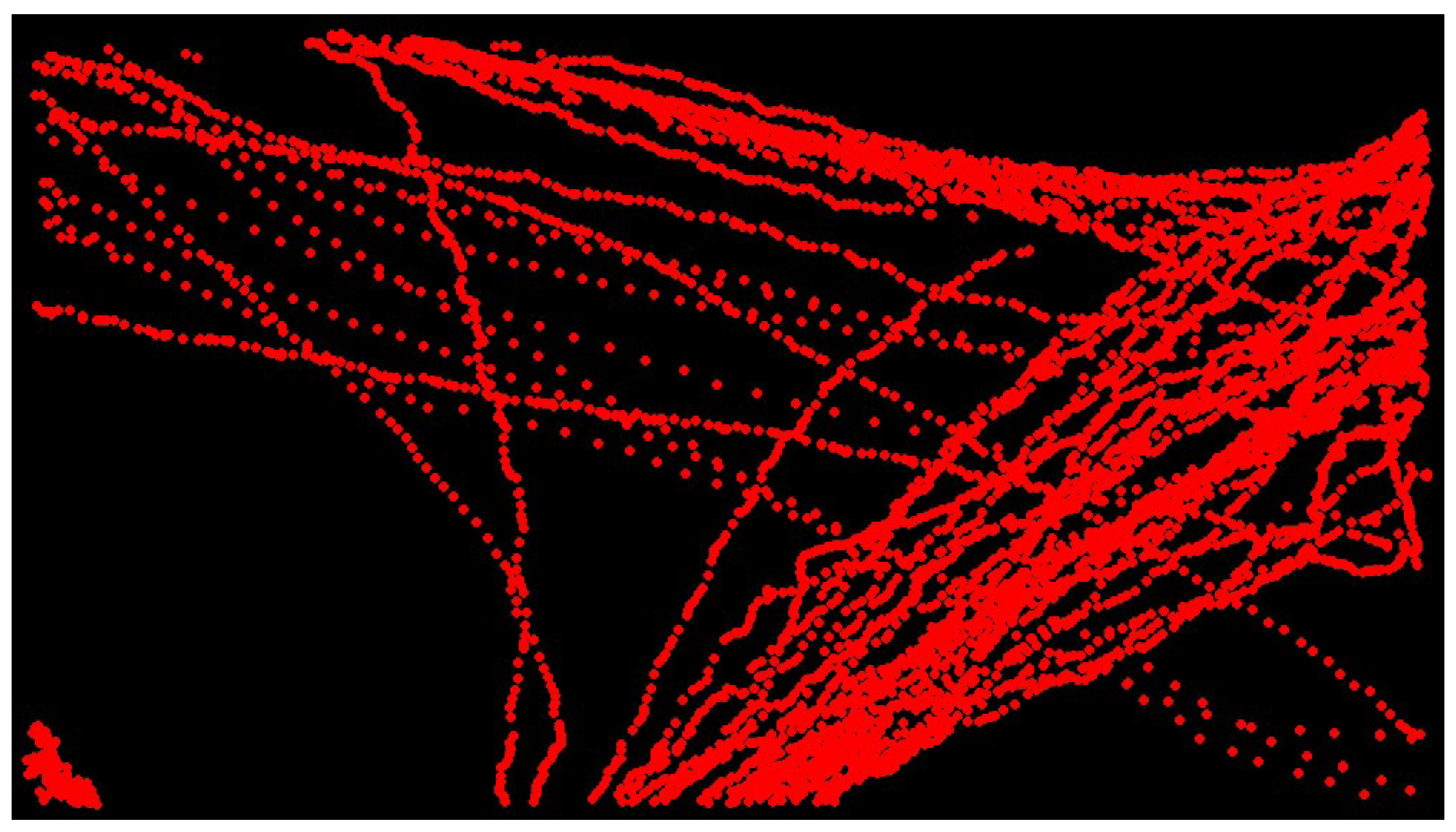
6.5. Model Prediction Evaluation
6.6. Critical Findings Summarized
7. Model Selection and Application
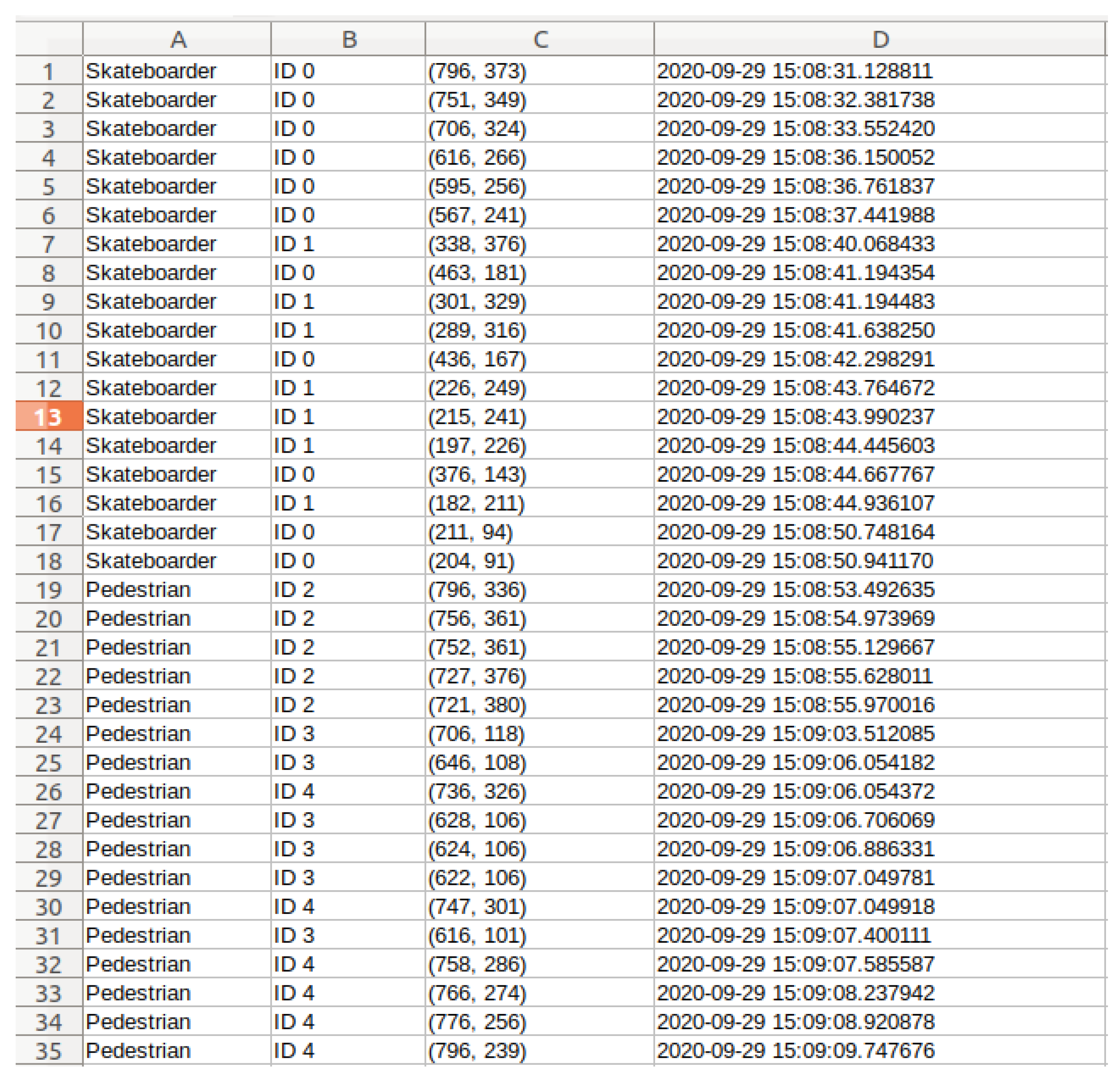
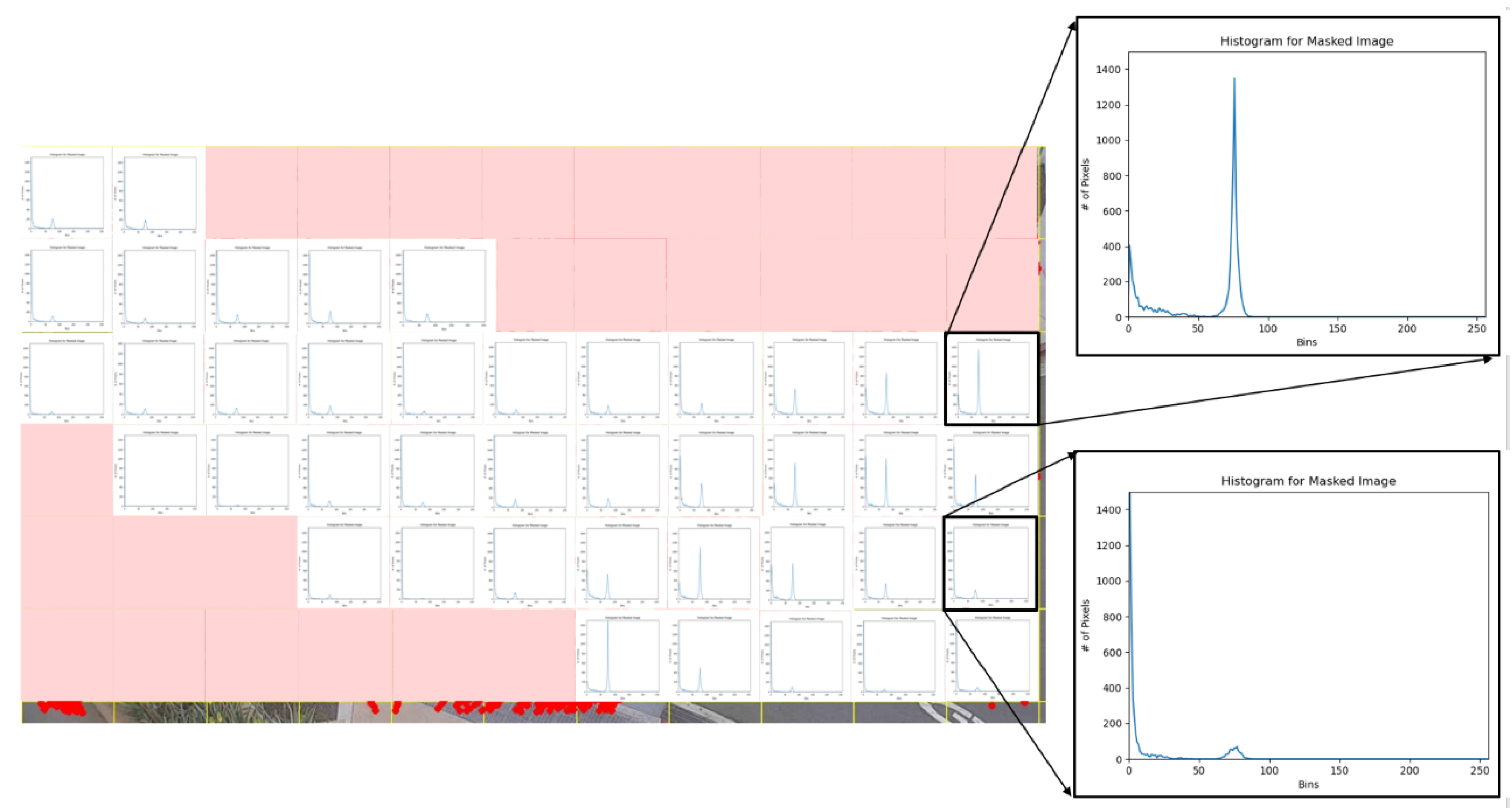
7.1. Automated PET Calculation
7.2. Real-Time Hazardous Conflict Zone Determination
8. Conclusions
- The perspective of the camera used in this study was not equivalent to the perspective of a surveillance camera mounted on a traffic mast. Cameras affixed to traffic masts directly face oncoming traffic. Therefore, the images of pedestrians and skateboarders captured in this study are taken at different pan (), tilt (), and zoom (r) values than the spherical coordinate configuration of a camera mounted on the mast at a city intersection.
- The confidence scores of our models were higher when detecting objects in images containing no shadows. Pedestrians and skateboarders on overcast days or during illuminated nighttime periods had a higher chance of being detected and properly classified.
9. Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| MDPI | Multidisciplinary Digital Publishing Institute |
| DOAJ | Directory of open access journals |
| TLA | Three letter acronym |
| LD | Linear dichroism |
References
- IOC Approves Five New Sports for Olympic Games Tokyo 2020. Available online: https://olympics.com/ioc/news/ioc-approves-five-new-sports-for-olympic-games-tokyo-2020 (accessed on 24 August 2021).
- McKenzie, L.B.; Fletcher, E.; Nelson, N.G.; Roberts, K.J.; Klein, E.G. Epidemiology of skateboarding-related injuries sustained by children and adolescents 5–19 years of age and treated in US emergency departments: 1990 through 2008. Inj. Epidemiol. 2016, 3, 10. [Google Scholar] [CrossRef] [Green Version]
- Fountain, J.L.; Meyers, M.C. Skateboarding injuries. Sport. Med. 1996, 22, 360–366, ISSN 1179-2035. [Google Scholar] [CrossRef]
- Kyle, S.B.; Nance, M.L.; Rutherford, G.W.; Winston, F.K. Skateboard-associated injuries: Participation-based estimates and injury characteristics. J. Trauma 2002, 53, 686–690, ISSN 2163-0763. [Google Scholar] [CrossRef]
- Forsman, L.; Eriksson, A. Skateboarding injuries of today. Br. J. Sport. Med. 2001, 35, 325–328, ISSN 1473-0480. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Panda, N.; Majhi, S.K. How effective is the salp swarm algorithm in data classification. In Computational Intelligence in Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2020; pp. 579–588. ISBN 978-3-319-89628-1. [Google Scholar]
- Dulebenets, M.A. A novel memetic algorithm with a deterministic parameter control for efficient berth scheduling at marine container terminals. Marit. Bus. Rev. 2017, 2, 302–330, ISSN 2397-3757. [Google Scholar] [CrossRef] [Green Version]
- D’Angelo, G.; Pilla, R.; Tascini, C.; Rampone, S. A proposal for distinguishing between bacterial and viral meningitis using genetic programming and decision trees. Soft Comput. 2019, 23, 11775–11791, ISSN 1432-7643. [Google Scholar] [CrossRef]
- Liu, Z.Z.; Wang, Y.; Huang, P.Q. AnD: A many-objective evolutionary algorithm with angle-based selection and shift-based density estimation. Inf. Sci. 2020, 509, 400–419, ISSN 0020-0255. [Google Scholar] [CrossRef] [Green Version]
- Pasha, J.; Dulebenets, M.A.; Kavoosi, M.; Abioye, O.F.; Wang, H.; Guo, W. An optimization model and solution algorithms for the vehicle routing problem with a “factory-in-a-box”. IEEE Access 2020, 8, 134743–134763, ISSN 2169-3536. [Google Scholar] [CrossRef]
- Behbahani, H.; Nadimi, N. A Framework for Applying Surrogate Safety Measures for Sideswipe Conflicts. Int. J. Traffic Transp. Eng. 2015, 5, 371–383, ISSN 2217-544X. [Google Scholar] [CrossRef] [Green Version]
- Peesapati, L.N.; Hunter, M.P.; Rodgers, M.O. Evaluation of Postencroachment Time as Surrogate for Opposing Left-Turn Crashes. Transp. Res. Rec. 2013, 2386, 42–51. [Google Scholar] [CrossRef] [Green Version]
- Zheng, L.; Ismail, K.; Meng, X. Traffic conflict techniques for road safety analysis: Open questions and some insights. Can. J. Civ. Eng. 2014, 41, 633–641. [Google Scholar] [CrossRef]
- Ozbay, K.; Yang, H.; Bartin, B.; Mudigonda, S. Derivation and Validation of New Simulation-Based Surrogate Safety Measure. Transp. Res. Rec. 2008, 2083, 105–113. [Google Scholar] [CrossRef] [Green Version]
- Hayward, J.C. Near miss determination through use of a scale of danger. Highw. Res. Rec. 1972, 384, 24–34, ISSN 0073-2206. [Google Scholar]
- Saffarzadeh, M.; Nadimi, N.; Naseralavi, S.; Mamdoohi, A.R. A general formulation for time-to-collision safety indicator. Proc. Inst. Civ. Eng. Transp. 2013, 166, 294–304. [Google Scholar] [CrossRef]
- Peesapati, L.N.; Hunter, M.P.; Rodgers, M.O. Can post encroachment time substitute intersection characteristics in crash prediction models? J. Saf. Res. 2018, 66, 205–211. [Google Scholar] [CrossRef]
- Graw, M.; König, H.G. Fatal pedestrian—Bicycle collisions. Forensic Sci. Int. 2002, 126, 241–247, ISSN 0379-0738. [Google Scholar] [CrossRef]
- Tuckel, P.; Milczarski, W.; Maisel, R. Pedestrian injuries due to collisions with bicycles in New York and California. J. Saf. Res. 2014, 51, 7–13, ISSN 0022-4375. [Google Scholar] [CrossRef] [PubMed]
- Fontaine, H.; Gourlet, Y. Fatal pedestrian accidents in France: A typological analysis. Accid. Anal. Prev. 1997, 29, 303–312, ISSN 0001-4575. [Google Scholar] [CrossRef]
- Choueiri, E.M.; Lamm, R.; Choueiri, G.; Choueiri, B. Pedestrian accidents: A 15-year survey from the United States and Western Europe. ITE J. 1993, 63, 36–42, ISSN 0162-8178. [Google Scholar]
- Robi, J. The 10 Most Dangerous Pedestrian Intersections in San Diego County. Available online: https://www.neighborhoods.com/blog/the-10-most-dangerous-pedestrian-intersections-in-san-diego-county (accessed on 24 August 2021).
- Shourov, E.C.; Paolini, C. Laying the Groundwork for Automated Computation of Surrogate Safety Measures (SSM) for Skateboarders and Pedestrians using Artificial Intelligence. In Proceedings of the 2020 Third International Conference on Artificial Intelligence for Industries (AI4I), Irvine, CA, USA, 21–23 September 2020; pp. 19–22. [Google Scholar] [CrossRef]
- Dutta, A.; Zisserman, A. The VIA Annotation Software for Images, Audio and Video. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; ACM: New York, NY, USA, 2019. ISBN 978-1-4503-6889-6. [Google Scholar] [CrossRef] [Green Version]
- Dutta, A.; Gupta, A.; Zissermann, A. VGG Image Annotator (VIA). 2016. Available online: https://www.robots.ox.ac.uk/~vgg/software/via/ (accessed on 25 August 2021).
- San Diego State University Internet of Things Laboratory (IoTLab). Available online: http://iotlab.sdsu.edu/ (accessed on 25 August 2021).
- Bappy, J.H.; Roy-Chowdhury, A.K. CNN based region proposals for efficient object detection. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3658–3662, ISSN 15224880. [Google Scholar]
- Purkait, P.; Zhao, C.; Zach, C. SPP-Net: Deep absolute pose regression with synthetic views. arXiv 2017, arXiv:1712.03452. ISSN 2331-8422. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448, ISBN 0-8186-7042-8. ISSN 1063-6919. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. arXiv 2015, arXiv:1506.01497. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969, ISSN 1063-6919. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125, ISSN 1063-6919. [Google Scholar]
- Pramanik, A.; Pal, S.K.; Maiti, J.; Mitra, P. Granulated RCNN and multi-class deep sort for multi-object detection and tracking. IEEE Trans. Emerg. Top. Comput. Intell. 2021, 1–11, ISSN 2471-285X. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788, ISSN 1063-6919. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37, ISBN 978-3-319-46448-0. [Google Scholar]
- Li, Y.; Ren, F. Light-weight retinanet for object detection. arXiv 2019, arXiv:1905.10011. ISSN 2331-8422. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. ISSN 2331-8422. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. ISSN 2331-8422. [Google Scholar]
- Wang, C.Y.; Yeh, I.H.; Liao, H.Y.M. You Only Learn One Representation: Unified Network for Multiple Tasks. arXiv 2021, arXiv:2105.04206. ISSN 2331-8422. [Google Scholar]
- Coral EdgeTPU Dev Board: A Development Board to Quickly Prototype on-Device ML Products. Available online: https://coral.ai/products/dev-board/ (accessed on 24 August 2021).
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. Tensorflow: A system for large-scale machine learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16), Savannah, GA, USA, 2–4 November 2016; pp. 265–283, ISBN 978-1-880446-39-3. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 658–666, ISBN 0-8186-7822-4. [Google Scholar]
- Henderson, P.; Ferrari, V. End-to-end training of object class detectors for mean average precision. In Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 198–213, ISBN 978-3-030-69525-5. [Google Scholar]
- Rakshit, S. Intersection Over Union. Available online: https://medium.com/koderunners/intersection-over-union-516a3950269c (accessed on 24 August 2021).
- Rockikz, A. How to Perform YOLO Object Detection using OpenCV and PyTorch in Python. Available online: https://www.thepythoncode.com/article/yolo-object-detection-with-opencv-and-pytorch-in-python (accessed on 24 August 2021).
- Gettman, D.; Head, L. Surrogate safety measures from traffic simulation models. Transp. Res. Rec. 2003, 1840, 104–115. [Google Scholar] [CrossRef] [Green Version]
- Shourov, C.E.; Paolini, C. Skateboarder and Pedestrian Conflict Zone Detection Dataset. Available online: http://dx.doi.org/10.17605/OSF.IO/NYHF7 (accessed on 24 August 2021).
- Wang, Y. Real-time moving vehicle detection with cast shadow removal in video based on conditional random field. IEEE Trans. Circuits Syst. Video Technol. 2009, 19, 437–441, ISSN 1558-2205. [Google Scholar] [CrossRef]
- Jung, C.R. Efficient background subtraction and shadow removal for monochromatic video sequences. IEEE Trans. Multimed. 2009, 11, 571–577, ISSN 1941-0077. [Google Scholar] [CrossRef]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Perspective | Pan (Degrees) | Tilt (Degrees) |
|---|---|---|
| 1 | 84.21 | 1.04 |
| 2 | 84.21 | −0.55 |
| 3 | 85.71 | −3.49 |
| 4 | 85.71 | −5.26 |
| 5 | 92.23 | −8.05 |
| 6 | 97.79 | −22.78 |
| 7 | 110.48 | −28.75 |
| 8 | 122.28 | −33.62 |
| 9 | 139.75 | −35.95 |
| 10 | 174.22 | −36.54 |
| 11 | 179.71 | −36.54 |
| 12 | 234 | −36.54 |
| 13 | 249.27 | −25.79 |
| 14 | 245.85 | −25 |
| 15 | 249.04 | −21.87 |
| 16 | 255.57 | −10.74 |
| 17 | 253.77 | −8.17 |
| 18 | 255.97 | −5.6 |
| Model | Elapsed Time | fps |
|---|---|---|
| Faster R-CNN | 0.08 | ≈35 |
| SSDV2 | 0.02 | ≈54 |
| SSDV1lite | 0.03 | ≈102 |
| Model | mAP@0.5IOU | mAP@0.75IOU | Evaluation Loss | fps |
|---|---|---|---|---|
| Faster R-CNN | 99.5 | 98.0 | 0.1 | ≈35 |
| SSDV2 | 98 | 92.0 | 1.8 | ≈54 |
| SSDV1lite | 99.5 | 97.0 | 0.2 | ≈102 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shourov, C.E.; Sarkar, M.; Jahangiri, A.; Paolini, C. Deep Learning Architectures for Skateboarder–Pedestrian Surrogate Safety Measures. Future Transp. 2021, 1, 387-413. https://doi.org/10.3390/futuretransp1020022
Shourov CE, Sarkar M, Jahangiri A, Paolini C. Deep Learning Architectures for Skateboarder–Pedestrian Surrogate Safety Measures. Future Transportation. 2021; 1(2):387-413. https://doi.org/10.3390/futuretransp1020022
Chicago/Turabian StyleShourov, Chowdhury Erfan, Mahasweta Sarkar, Arash Jahangiri, and Christopher Paolini. 2021. "Deep Learning Architectures for Skateboarder–Pedestrian Surrogate Safety Measures" Future Transportation 1, no. 2: 387-413. https://doi.org/10.3390/futuretransp1020022
APA StyleShourov, C. E., Sarkar, M., Jahangiri, A., & Paolini, C. (2021). Deep Learning Architectures for Skateboarder–Pedestrian Surrogate Safety Measures. Future Transportation, 1(2), 387-413. https://doi.org/10.3390/futuretransp1020022