Abstract
Objective: The interpretation of time series data collected in free-living has gained importance in chronic disease management. Some data are collected objectively from sensors and some are estimated and entered by the individual. In type 1 diabetes (T1D), blood glucose concentration (BGC) data measured by continuous glucose monitoring (CGM) systems and insulin doses administered can be used to detect the occurrences of meals and physical activities and generate the personal daily living patterns for use in automated insulin delivery (AID). Methods: Two challenges in time-series data collected in daily living are addressed: data quality improvement and the detection of unannounced disturbances of BGC. CGM data have missing values for varying periods of time and outliers. People may neglect reporting their meal and physical activity information. In this work, novel methods for preprocessing real-world data collected from people with T1D and the detection of meal and exercise events are presented. Four recurrent neural network (RNN) models are investigated to detect the occurrences of meals and physical activities disjointly or concurrently. Results: RNNs with long short-term memory (LSTM) with 1D convolution layers and bidirectional LSTM with 1D convolution layers have average accuracy scores of 92.32% and 92.29%, and outperform other RNN models. The F1 scores for each individual range from 96.06% to 91.41% for these two RNNs. Conclusions: RNNs with LSTM and 1D convolution layers and bidirectional LSTM with 1D convolution layers provide accurate personalized information about the daily routines of individuals. Significance: Capturing daily behavior patterns enables more accurate future BGC predictions in AID systems and improves BGC regulation.
1. Introduction
Time series data are widely used in many fields, and various data-driven modeling techniques are developed to represent the dynamic characteristics of systems and forecast the future behavior. The growing research in artificial intelligence has provided powerful machine learning (ML) techniques to contribute to data-driven model development. Real-world data provide several challenges to modeling and forecasting, such as missing values and outliers. Such imperfections in data can reduce the accuracy of ML and the models developed. This necessitates data preprocessing for the imputation of missing values, down- and up-sampling, and data reconciliation. Data preprocessing is a laborious and time-consuming effort since big data are usually stacked on a large scale [1]. When models are used for forecasting, the accuracy of forecasts improve if the effects of future possible disturbances based on behavior patterns extracted from historical data are incorporated in the forecasts. This paper focuses on these two problems and investigates the benefits of preprocessing the real-world data and the performance of different recurrent neural network (RNN) models for detecting various events that affect blood glucose concentration (BGC) in people with type 1 diabetes (T1D). The behavior patterns detected are used for more accurate predictions of future BGC variations, which can be used for warnings and for increasing the effectiveness of automated insulin delivery (AID) systems.
Time series data captured in daily living of people with chronic conditions have many of these challenges to modeling, detection, and forecasting. Focusing on people with T1D, the medical objective is to forecast the BGC of a person with T1D and prevent the excursion of BGC outside a “desired range” (70–180 mg/dL) to reduce the probability of hypo- and hyperglycemia events. In recent years, the number of people with diabetes has grown rapidly around the world, reaching pandemic levels [2,3]. Advances in continuous glucose monitoring (CGM) systems, insulin pump and insulin pen technologies, and in novel insulin formulations has enabled many powerful treatment options [4,5,6,7,8,9]. The current treatment options available to people with T1D range from manual insulin injections to AID. Manual injection (insulin bolus) doses are computed based on the person’s characteristics and the properties of the meal consumed. Current AID systems necessitate the manual entry of meal information to give insulin boluses for mitigating the effects of meal on the BGC. A manual adjustment of the basal insulin dose and increasing the BGC target level and/or consumption of snacks are the options to mitigate the effects of physical activity. Some people may forget to make these manual entries and a system that can nudge them to provide appropriate information can reduce the extreme excursions in BGC. Commercially available AID systems are hybrid closed-loop systems, and they require these manual entries by the user. AID systems, also called artificial pancreas (AP), consist of a CGM, an insulin pump, and a closed-loop control algorithm that manipulates the insulin infusion rate delivered by the pump based on the recent CGM values reported [10,11,12,13,14,15,16,17,18,19,20,21,22,23]. More advanced AID systems that use a multivariable approach [10,24,25,26] use additional inputs from wearable devices (such as wristbands) to automatically detect the occurrence of physical activity and incorporate this information to the automated control algorithms for a fully automated AID system [27]. Most AID systems use model predictive control techniques that predict future BGC values in making their insulin dosing decisions. Knowing the habits of the individual AID user improves the control decisions since the prediction accuracy of the future BGC trajectories can explicitly incorporate the future potential disturbances to the BGC, such as meals and physical activities, that will occur with high likelihood during the future BGC prediction window [24,26]. Consequently, the detection of meal and physical activity events from historical free-living data of a person with T1D will provide useful information for decision making by both the individual and by the AID system.
CGM systems report subcutaneous glucose concentration to infer BGC with a sampling rate of 5 min. Self-reported meal and physical activity data are often based on diary entries. Physical activity data can also be captured by wearable devices. The variables reported by wearable devices may have artifacts, noise, missing values, and outliers. The data used in this work include only CGM values, insulin dosing information, and diary entries of meals and physical activities.
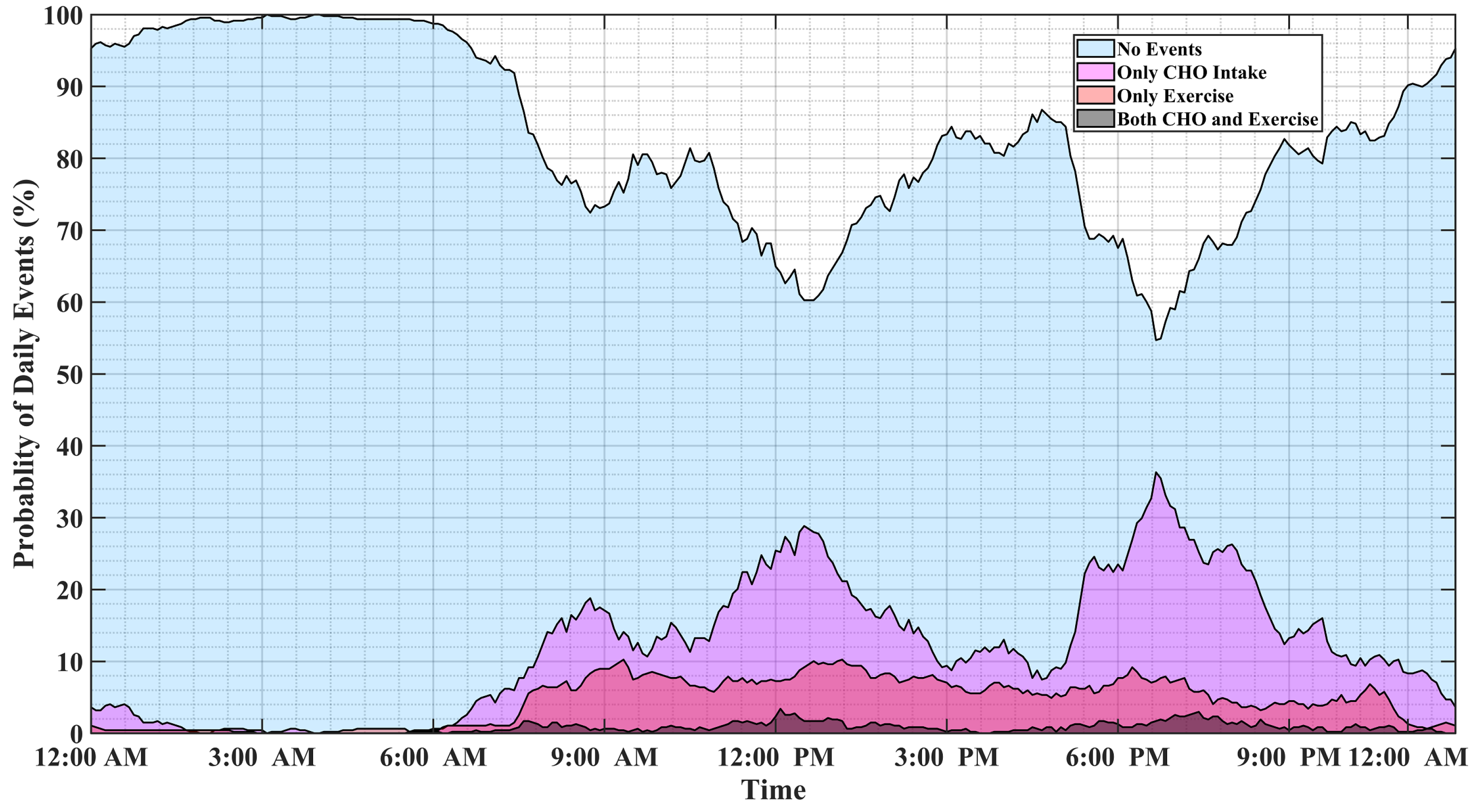
Analyzing long-term data of people with T1D indicates that individuals tend to repeat daily habitual behaviors. Figure 1 illustrates the probability of physical activity and meal (indicated as carbohydrate intake) events, either simultaneously or disjointly, for 15 months of self-reported CGM, meal, insulin pump, and physical activity data of individuals with T1D. Major factors affecting BGC variations usually occur at specific time windows and conditions, and some combinations of events are mutually exclusive. For example, insulin-bolusing and physical activity are less likely to occur simultaneously or during hypoglycemia episodes, since people do not exercise when their BGC is low. People may have different patterns of behavior during the work week versus weekends or holidays. Predicting the probabilities of exercise, meal consumption, and their concurrent occurrence based on historical data using ML can provide important information on the behavior patterns for making medical therapy decisions in diabetes.
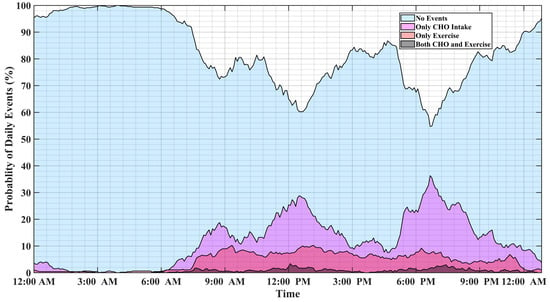
Figure 1.
The probabilities of meal and physical activity events during one day obtained by analyzing 15 months of the pump–CGM sensor, meal, and physical activity data collected from a randomly selected person with T1D.
Motivated by the above considerations, this work develops a framework for predicting the probabilities of meal and physical activity events, including their independent and simultaneous occurrences. A framework is built to handle the inconsistencies and complexities of real-world data, including missing data, outlier removal, feature extraction, and data augmentation. Four different recurrent neural network (RNN) models are developed and evaluated for estimating the probability of events causing large variations in BGC. The advent of deep neural networks (NNs) and their advances have paved the way for processing and analyzing various types of information, namely: time-series, spatial, and time-series–spatial data. Long short-term memory (LSTM) NN models are specific sub-categories of recurrent NNs introduced to reduce the computational burden of storing information over extended time intervals [28,29]. LSTMs take advantage of nonlinear dynamic modeling without knowing time-dependency information in the data. Moreover, their multi-step-ahead prediction capability makes them an appropriate choice for detecting upcoming events and disturbances that can deteriorate the accuracy of model predictions.
The main contributions of this work are the development of NN models capable of estimating the occurrences of meals and physical activities without requiring additional bio-signals from wearable devices, and the integration of convolution layers with LSTM that enable the NN to accurately estimate the output from glucose–insulin input data. The proposed RNN models can be integrated with the control algorithm of an AID system to enhance its performance by readjusting the conservativeness and aggressiveness of the AID system.
The remainder of this paper is organized as follows: the next section provides a short description of the data collected from people with T1D. The preprocessing step, including outlier removal, data imputation, and feature extraction is presented in Section 3. Section 4 presents various RNN configurations used in this study. A case study with real-world data and a discussion of the results are presented in Section 5 and Section 6, respectively. Finally, Section 6 provides the conclusions.
2. Free-Living, Self-Reported Dataset of People with T1D
A total of 300 self-collected T1D datasets were made available for research, and each dataset represents a unique individual. Among all of the datasets, 50 T1D datasets include CGM-sensor–insulin-pump recordings and exercise information such as the time, type, and duration of physical activity recorded from either open or closed-loop insulin-pump–sensor data. Meal information is reported as the amount of carbohydrates (CHO) consumed in the meal as estimated by the subject. An over or underestimation of CHO in meals is common.
The subjects with T1D selected for this study used insulin-pump–CGM-sensor therapy for up to two years, and some of them have lived with diabetes for more than fifty years. Table 1 and Table 2 summarize the demographic information of the selected subjects and the definition of the variables collected, respectively. Separate RNN models were developed for each person in order to capture personalized patterns of meal consumption and physical activity.

Table 1.
The general demographic information of 11 subjects with T1D and the durations of recorded samples.
Table 2.
The name and the definition of measured variables.
3. Data Preprocessing
This is a computational study for the development of detection and classification of infrequent events (eating, exercising) that affect the main variable of interest in people with diabetes: their blood glucose concentrations. It is based on data collected from patients in free living; hence, it contains many windows of data with missing values and outliers. Using real-world data for developing models usually has numerous challenges: (i) the datasets can be noisy and incomplete; (ii) there may be duplicate CGM samples in some of the datasets; (iii) inconsistencies exist in the sampling rate of CGM and insulin values; (iv) gaps in the time and date can be found due to insulin pump or CGM sensor disconnection. Therefore, the datasets need to be preprocessed before using them for model development.
3.1. Sample Imputation
Estimating missing data is an important step before analyzing the data [30]. Missing data are substituted with reasonable estimates (imputation) [31]. In dealing with time-series data such as CGM, observations are sorted according to their chronological order. Therefore, the variable “Time”, described in Table 2, is converted to “Unix time-stamp”, samples are sorted in ascending order of “Unix time-stamp”, and gaps without observations are filled with pump–sensor samples labeled as “missing values”.
Administered basal insulin is a piecewise constant variable and its amount is calculated by the AID system or by predefined insulin injection scenarios. Applying a simple forward or backward imputation for basal insulin with gaps in duration lasting a maximum of two hours gives reasonable reconstructed values for the missing observations. Gaps lasting more than two hours in missing recordings are imputed with basal insulin values recorded in the previous day at the same time, knowing that insulin injection scenarios usually follow a daily pattern [32].
The variable “Bolus” is a sparse variable (usually nonzero only at times of meals) and its missing samples were imputed with the median imputation approach, considering that the bolus injection policy is infrequently altered. Similarly, missing recordings of variables “Nutrition.carbohydrate”, “Smbg”, “Duration”, “Activity.duration”, and “Distance.value” were imputed with the median strategy. A multivariate strategy that uses CGM, total injected insulin, “Nutrition.carbohydrate”, the “Energy.value”, and “Activity.duration” was employed to impute missing CGM values.
This choice of variables has to do with the dynamic relationship between CGM and the amount of carbohydrate intake, the duration and the intensity of physical activity, and the total injected insulin. Estimates of missing CGM samples were obtained by performing probabilistic principal component analysis (PPCA) on the lagged matrices of the CGM data. PPCA is an extension of principal component analysis, where the Gaussian conditional distribution of the latent variables is assumed [33]. This formulation of the PPCA facilitates tackling the problem of missing values in the data through the maximum likelihood estimation of the mean and variance of the original data. Before performing PPCA on the feature variables, the lagged array of each feature variable, , at the jth sampling index was constructed from the past two hours of observations as:
For an observed set of feature variables , let be its q-dimensional () Gaussian latent transform [34] such that
where and represent the ith row of the loading matrix and mean value of the data. is also the measurement noise with the probability distribution
Based on the Gaussian distribution assumption of and the Gaussian probability distribution of , one can deduce that
The joint probability distribution can be derived from (4) and Bayes’ joint probability rule as
Define the set . The log-likelihood of the joint multivariate Gaussian probability distribution of (5) is calculated over all available observations as
where the log-likelihood (6) is defined for all available observations . By applying the expectation operation with respect to the posterior probability distribution over all latent variables , where , (6) becomes
Parameters , , and in (8) are updated recursively until they converge to their final values. The final estimation of missing CGM samples is obtained by performing a diagonal averaging of the reconstructed lagged matrix over rows/columns filled with CGM values. Long gaps in CGM recordings might exist in the data, and imputing their values causes problems in accuracy and reliability. Therefore, CGM gaps of no more than twenty-five consecutive missing samples (approximately two hours) are imputed by PPCA.
3.2. Outlier Removal
Signal reconciliation and outlier removal are necessary to avoid misleading interpretation of data and biased results, and to improve the quality of CGM observations. As a simple outlier removal approach for a variable with Gaussian distribution, observations outside standard deviations from the mean, known as inner Tukey fences, can be labeled as outliers and extreme values [35]. The probability distribution of the CGM data shows a skewed distribution compared to the Gaussian probability distribution. Thus, labeling samples as outliers only based on their probability of occurrence is not the proper way of removing extreme values from the CGM data since it can cause a loss of useful CGM information, specifically during hypoglycemia ( mg/dL) and hyperglycemia ( mg/dL) events. As another alternative, extreme values and spikes in the CGM data can be labeled from the prior knowledge and by utilizing other feature variables, namely: “Smbg”, “Nutrition.carbohydrate”, “Bolus”, and “Activity.duration”. Algorithm 1 is proposed to remove outliers from CGM values. Usually, BGC is slightly different from the recordings of the CGM signal because of the delay between BGC and the subcutaneous glucose concentration measured by the CGM device and sensor noise. The noisy signal can deteriorate the performance of data-driven models. Therefore, Algorithm 2, which is based on eigendecomposition of the Hankel matrix of CGM values, is used to reduce the noise in the CGM recordings.
| Algorithm 1: Outlier rejection from CGM readings |
|
| Algorithm 2: Smoothing CGM recordings |
|
3.3. Feature Extraction
Converting raw data into informative feature variables or extracting new features is an essential step of data preprocessing. In this study, four groups of feature variables, including frequency domain, statistical domain, nonlinear domain, and model-based features, were calculated and added to each dataset to enhance the prediction power of models. The summarized description of each group of features and the number of past samples required for their calculation are listed in Table 3.
Table 3.
The type and definition of the extracted feature variables and the length of time window required for their calculations.
A qualitative trend analysis of variables can extract different patterns caused by external factors within a specified time [36,37]. A pairwise multiplication of the sign and magnitude of the first and second derivatives of CGM values indicates the carbohydrate intake [38,39], exogenous insulin injection, and physical activity. Therefore, the first and second derivatives of CGM values, calculated by the fourth-order backward difference method, were added as feature variables. The sign and magnitude product of the first and second derivatives of CGM, their covariance, Pearson correlation coefficient, and Gaussian kernel similarity were extracted. Statistical feature variables, e.g., mean, standard deviation, variance, skewness, etc., were obtained from the specified time window of CGM values. Similar to the first and second derivatives of CGM values, a set of feature variables, including covariance and correlation coefficients, from pairs of CGM values and derivatives was extracted and augmented to the data.
As a result of the daily repetition in the trends of CGM and glycemic events and the longer time window of CGM values, samples collected during the last twenty-four hours were used for frequency-domain feature extraction. Therefore, magnitudes and frequencies of the top three dominant peaks in the power spectrum of CGM values, conveying past long-term variation of the BGC, were included in the set of feature maps.
The plasma insulin concentration (PIC) is another feature variable that informs about the carbohydrate intake information and exogenous insulin administration. PIC accounts for the accumulation of subcutaneously injected insulin within the bloodstream, which is gradually consumed by the body to enable the absorption of carbohydrates released from the gastrointestinal track to various cells and tissues. Usually, dynamic physiological models are used to describe and model the glucose and insulin concentration dynamics in diabetes. The main idea of estimating PIC from physiological models stems from predicting the intermediate state variables of physiological models by designing a state observer and utilizing the total infused insulin and carbohydrate intake as model inputs, and CGM values as the output of the model [40,41,42]. In this work, the estimation of the PIC and glucose appearance rate were obtained from a physiological model known as Hovorka’s model [43]. Equation (9) presents this nonlinear physiological (compartment) model:
Model (9) comprises four sub-models, describing the action of insulin on glucose dynamics, the insulin absorption dynamics, plasma–interstitial-tissue glucose concentration dynamics, and the blood glucose dynamics.The state variables of (9), the nominal values of the parameters, and their units are listed in Table 4 [43].
Table 4.
The description of variables and parameters and the nominal values of parameters in Hovorka’s model [43].
Body weight has a significant effect on the variations in the PIC and other state variables as it is used for determining the amount of exogenous insulin to be infused. Although estimating body weight as an augmented state variable of the insulin-CGM model is an effective strategy to cope with the problem of unavailable demographic information, estimating body weight from the total amount of daily administered insulin is a more reliable approach. As reported in various studies, the total daily injected insulin can have a range of 0.4–1.0 units kg day[44,45,46]. A fair estimation of body weight can be obtained by calculating the most common amount of injected basal/bolus insulin for each subject and using a conversion factor of 0.5 units kg day as a rule of thumb to estimate the body weight.
The insulin–glucose dynamics (9) in discrete-time format are given by
where denotes the extended state variables and is the total injected exogenous insulin. Symbols and denote zero-mean Gaussian random process and measurement noises (respectively), representing any other uncertainty and model mismatch that are not taken into account. Further, and represent the positive definite system uncertainty and measurement noise covariance matrices, respectively.
Tracking the dynamics of the internal state variables of the model (10) is feasible by using a class of sequential Monte Carlo algorithms known as particle filters. A generic form of the particle filter algorithm proposed by [47] with an efficient adaptive Metropolis–Hastings resampling strategy developed in [48] was employed to predict the trajectory of the PIC and other state variables. In order to avoid any misleading state estimations, each state variable was subjected to a constraint to maintain all estimations within meaningful intervals [41].
3.4. Feature Selection and Dimensionality Reduction
Reducing the number of redundant feature variables lowers the computational burden of their extraction and hinders over-parameterized modeling. In this work, a two-step feature selection procedure was used to obtain the optimal subset of feature variables that boost the efficiency of the classifier the most. In the first step, the deviance statistic test was performed to filter out features with low significance (p-value > 0.05). In the second step, the training split of all datasets was used in the wrapper feature selection strategy to maximize the accuracy of the classifier in estimating the glycemic events. A sequential floating forward selection (SFFS) approach [49] was applied on a random forest estimator with thirty decision tree classifiers with a maximum depth of six layers to sort out features with the most predictive power in descending order. Consequently, the top twenty feature variables with the highest contribution to the classification accuracy enhancement were used for model development.
4. Detection and Classification Methods
Detecting the occurrence of events causing large glycemic variations requires solving a supervised classification problem. Hence, all samples required labeling using the information provided in the datasets, specifically using variables “Activity.duration” and “Nutrition.carbohydrate”. In order to determine the index sets of each class, let N be the total number of samples and be the sample duration of physical activity at each sampling time k. Define sets of sample indexes as:
The label indexes defined by (11) corresponds to classes “Meal and Exercise”, “no Meal but Exercise”, “no Exercise but Meal”, “neither Meal nor Exercise”, respectively.
Four different configurations of the RNN models were studied to assess the accuracy and performance of each in estimating the joint probability of the carbohydrate intake and physical activity. All four models used 24 past samples of the selected feature variables, and event estimations were performed one sample backward. Estimating the co-occurrences of the external disturbances should be performed at least one step backward as the effect of disturbance variables needs to be seen first, before parameter adjustment and event prediction can be made.
Since the imputation of gaps with a high number of consecutive missing values adversely affects the prediction of meal–exercise classes, all remaining samples with missing values after the data imputation step were excluded from parameter optimization. Excluding missing values inside the input tensor can be carried out either by using a placeholder for missing samples and filtering samples through masking layer or by manually removing incomplete samples.
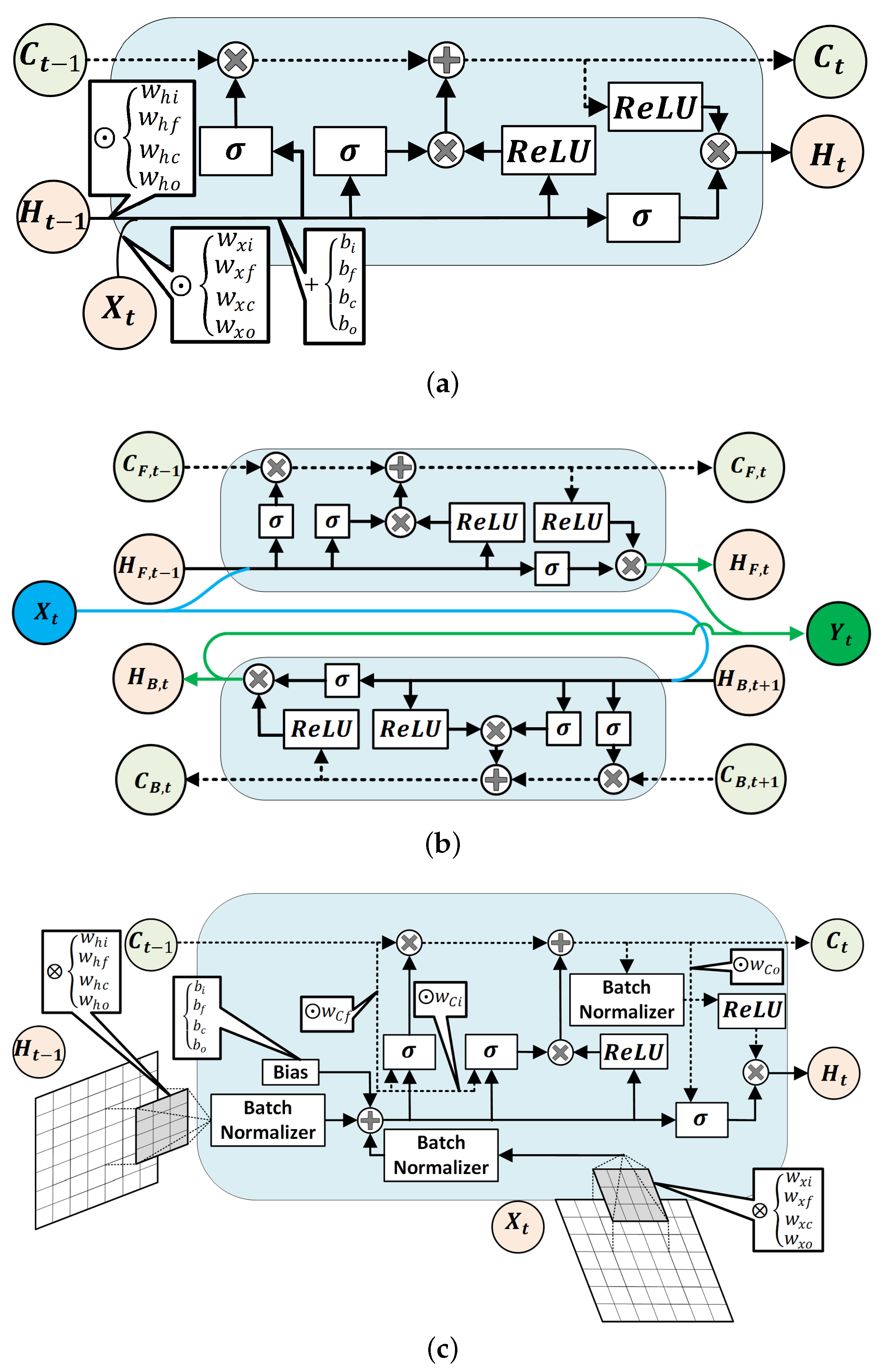
Each recurrent NN models used in this study encompasses a type of LSTM units [50] (see Figure 2) to capture the time-dependent patterns in the data. The first NN model consists of a masking layer to filter out unimputed samples, followed by a LSTM layer, two dense layers, and a softmax layer to estimate the probability of each class. The LSTM and dense layers undergo training with dropout and parameter regularization strategies to avoid the drastic growth of hyperparameters. Additionally, the recurrent information stream in the LSTM layer was randomly ignored in the calculation at each run. At each layer of the network, the magnitude of both weights and intercept coefficients was penalized by adding a regularizer term to the loss function. The rectified linear unit (ReLu) activation function was chosen as a nonlinear component in all layers. The input variables of the regular LSTM network will have the shape of , which denotes the size of samples, the size of lagged samples, and the number of feature variables, respectively.
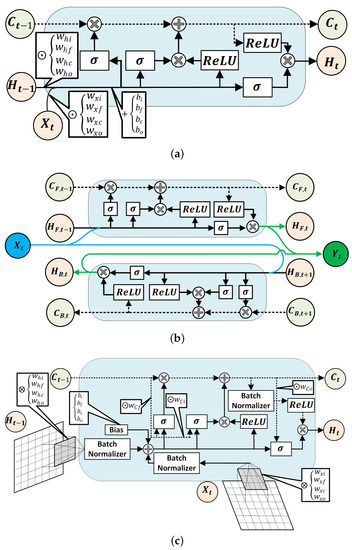
Figure 2.
Structures of a regular LSTM unit (a), a Bi-LSTM unit (b), and schematic demonstration of a 2D ConvLSTM cell (c) [50].
The second model encompasses a series of two 1D convolution layers, each one followed by a max pool layer for downsampling feature maps. The output of the second max pool layer was flattened to achieve a time-series extracted feature to feed to to the LSTM layer. A dense layer after LSTM was added to the model and the joint probability of events was estimated by calculating the output of the softmax layer. Like the first RNN model, the ReLU activation function was employed in all layers to capture the nonlinearity in the data. A regularization method was applied to all hyperparameters of the model. Adding convolution layers with repeated operations to an RNN model paves the way for extracting features for the sequence regression or classification problem. This approach has shown a breakthrough in visual time-series prediction from the sequence of images or videos for various problems, such as activity recognition, textual description, and audio and word sequence prediction [51,52]. Time-distributed convolution layers scan and elicit features from each block of the sequence of the data [53]. Therefore, each sample was reshaped into , with blocks at each sample.
The third classifier has a 2D convolutional LSTM (ConvLSTM) layer, one dropout layer, two dense layers, and a softmax layer for the probability estimation of each class from the sequences of data. A two-dimensional ConvLSTM structure was designed to capture both temporal and spatial correlation in the data, moving pictures in particular, by employing a convolution operation in both input-to-state and state-to-state transitions [50]. In comparison to a regular LSTM cell, ConvLSTMs perform the convolution operation by an internal multiplication of inputs and hidden states into kernel filter matrices (Figure 2c). Similar to previously discussed models, the regularization constraint and ReLU activation function were considered in constructing the ConvLSTM model. A two-dimensional ConvLSTM import sample of spatiotemporal data in the format of , where and , stands for the size of the rows and columns of each tensor, and is the number of channels/features on the data [54].
Finally, the last model comprises two 1D convolution layers, two max pooling layers, a flatten layer, a bidirectional LSTM (Bi-LSTM) layer, a dense layer, and a soft max layer to predict classes. Bi-LSTM units capture the dependency in the sequence of the data in two directions. Hence, as a comparison to a regular LSTM memory unit, Bi-LSTM requires reversely duplicating the same LSTM unit and employing a merging strategy to calculate the output of the cell [55]. The use of this approach was primarily observed in speech recognition tasks, where, instead of real-time interpretation, the whole sequence of the data was analyzed and its superior performance over the regular LSTM was justified [56]. The joint estimation of glycemic events was made one step backward. Therefore, the whole sequence of features were recorded first, and the use of an RNN model with Bi-LSTM units for the detection of unannounced disturbances was quite justifiable. The tensor of input data is similar to LSTM with 1D convolutional layers. Figure 2 is the schematic diagram of a regular LSTM, a Bi-LSTM, and a ConvLSTM unit.
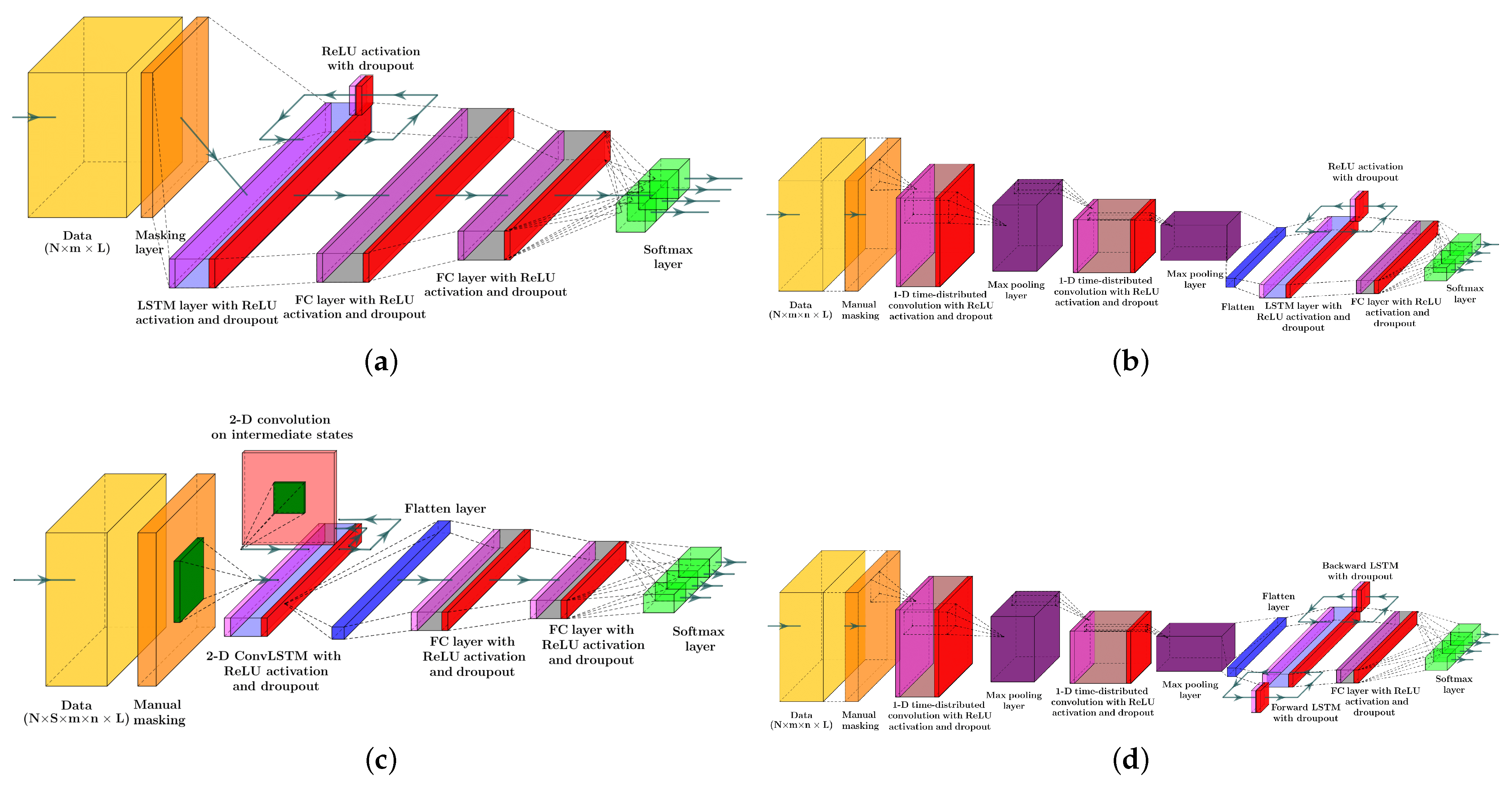
Figure 3 depicts the structure of the four RNN models to estimate the probability of meal consumption, physical activity, and their concurrent occurrence. The main difference between models (a) and (b) in Figure 3 is the convolution and max-pooling layers added before the LSTM layer to extract features map from time series data. Although adding convolutional blocks to an RNN model increases the number of learnable parameters, including weights, biases, and kernel filters, calculating temporal feature maps from input data better discriminates the target classes.
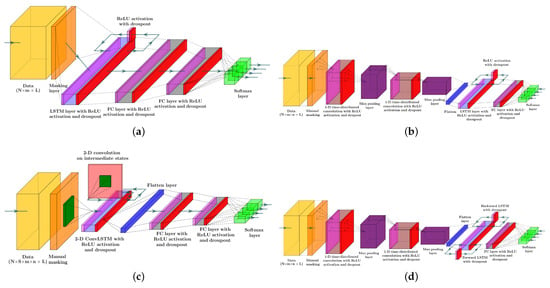
Figure 3.
Systematic structures of the different RNN models included in the study: (a) LSTM NN model, (b) LSTM with 1D convolutional layers, (c) 2D ConvLSTM NN model, and (d) Bi-LSTM with 1D convolutional layers. Color dictionary: Yellow: tensor of data, Orange: Masking to exclude missing samples, Magenta: Relu activation, Light blue: LSTM layer, Red: dropout, Grey: dense layer, Green: softmax activation, Blue: flatten layer, Purple: max pool layer, Dark green: kernel filter, Light red: the matrix of intermediate states.
5. Case Study
Eleven datasets containing CGM-sensor–insulin-pump, physical activity, and carbohydrate intake information were selected randomly from subject records for a case study. Data imputation and reconciliation, RNN training, and an evaluation of the results were conducted individually for each subject. Hence, the RNN models were personalized, using only that person’s data. All datasets were preprocessed by the procedure elaborated on in the data preprocessing section and feature variables were rescaled to have zero-mean and unit variance. Stratified six-fold cross-validation was applied to 87.5% of samples of each dataset to reduce the variance of predictions. Weight values proportional to the inversion of class sizes were assigned to the corresponding samples to avoid biased predictions caused by imbalanced samples in each class. In order to better assess the performance of each model and to avoid the effects of randomization in the initialization step of the back propagation algorithm, each model was trained five times with different random seeds. Hyperparameters of all models were obtained through an adaptive moment estimation (Adam) optimization algorithm, and 2% of the training sample size was chosen as the size of the training batches. In model training with different random seeds, the number of adjustable parameters, including weights, biases, the size and number of filter kernels, and the learning rate remained constant.
One difficulty associated with convolution layers in models (b) and (d) is the optimization of the hyperparameters of the convolutional layers. Usually, RNN models with convolution layers require a relatively high computation time. As a solution, learning rates with small values are preferred for networks with convolutional layers since they lead to a more optimal solution compared to large learning weights, which may result in non-optimality and instability.
The data preprocessing part of the work was conducted in a Matlab 2019a environment, and Keras/Keras-gpu 2.3.1 were used to construct and train all RNN models. Keras is a high-class API library with Tensorflow as the backend; all are available in the Python environment. We used two computational resources for data preparations and model training. Table 5 provides the details of hardware resources.
Table 5.
Hardware specifications.
6. Discussion of Results
Each classifier was evaluated by testing a 12.5% split of all sensor and insulin pump recordings for each subject, corresponding to 3–12 weeks of data for a subject. The average and the standard deviation of performance indexes are reported in Table 6. The lowest performance indexes were achieved by 2D ConvLSTM models. Bi-LSTM with 1D convolution layer RNN models achieve the highest accuracy for six subjects out of eleven, and LSTM with 1D convolution RNN for three subjects. Bi-LSTM with 1D convolution layer RNN models outperformed other models for four subjects, with weighted F1 scores ranging from 91.41–96.26%. Similarly, LSTM models with 1D convolution layers achieved the highest weighted F1 score for another four subjects, with score values within 93.65–96.06%. Glycemic events for the rest of the three subjects showed to be better predicted by regular LSTM models, with a weighted F1 score between 93.31–95.18%. This indicates that 1D convolution improves both the accuracy and F1 scores for most of the subjects. Based on the number of adjustable parameters for the four different RNN models used for a specific subject, LSTMs are the most computational demanding blocks in the model. To assess the computational load of developing the various RNN models, we compared the number of learnable parameters (details provided in Supplementary Materials). These values can be highly informative, as the number of dropouts in each model and the number of learnable parameters at each epoch (iteration) are invariant.
Table 6.
The average performance indexes of LSTM, LSTM with 1D convolution layers, 2D ConvLSTM, and Bi-LSTM with 1D convolution layers RNN models for the event detection problem. Standard deviations are given in parentheses and values with bold notation denote the highest performance indexes.
A comparison between 1D conv-LSTM and 1D-Bi-LSTM for one randomly selected subject shows that the number of learnable parameters increases by at least 54%, mainly stemming from an extra embedded LSTM in the bidirectional layer (Table S1). While comparing adjustable parameters may not be the most accurate way of determining the computational loads for training the models, they provide a good reference to compare the computational burden of different RNN models.
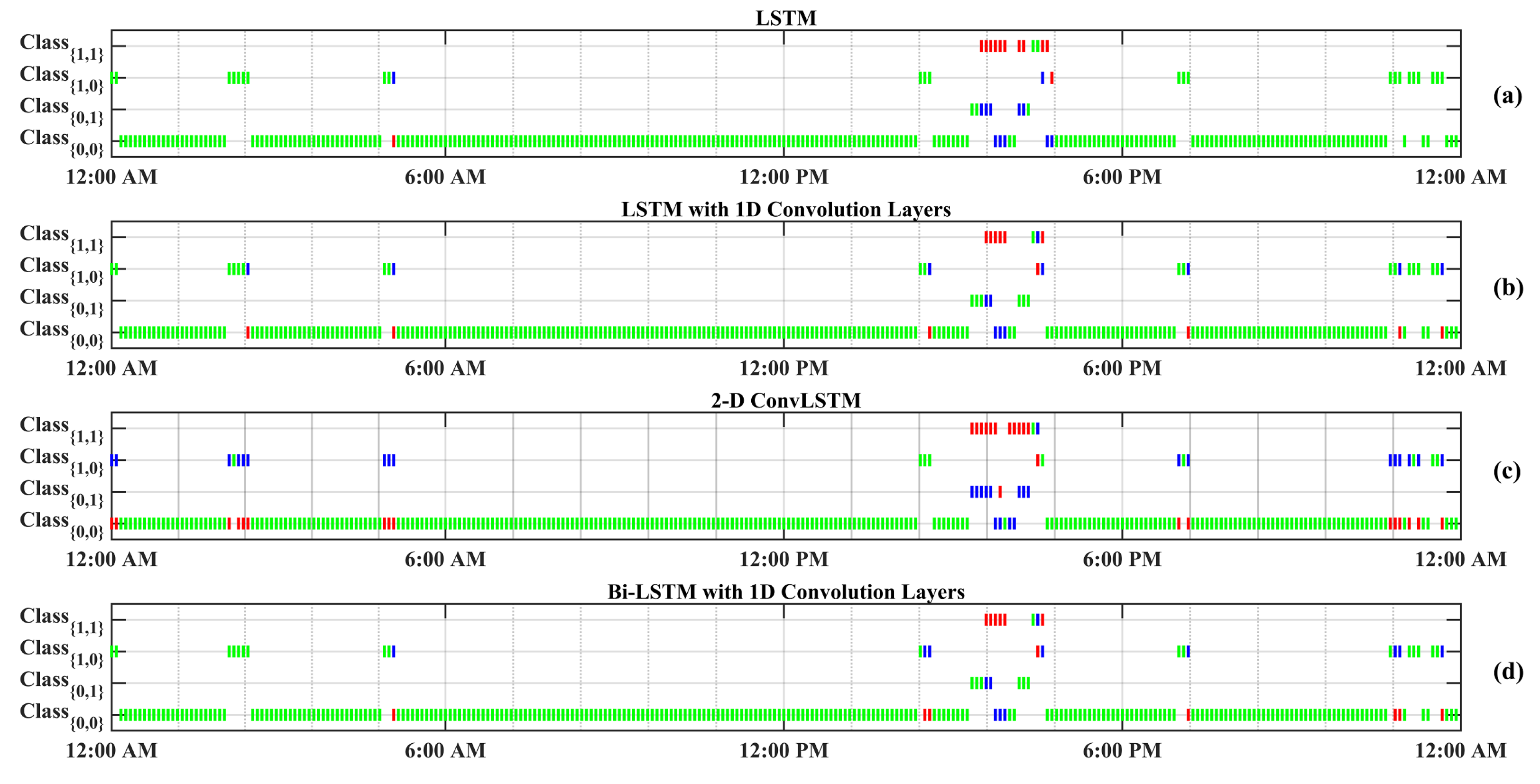
Figure 4 displays a random day selected from the test data to compare the effectiveness of each RNN model in detecting meal and exercise disturbances. Among four possible realizations for the occurrence of events, detecting joint events, , is more challenging as it usually shows overlaps with and . Another reason for the lower detection is the lack of enough information on , knowing that people would usually rather have a small snack before and after exercise sessions over having a rescue carbohydrate during physical activity. Furthermore, the AID systems used by subjects automatically record only CGM and insulin infusion values, and meal and physical activity sessions need to be manually entered to the device, which is, at times, an action that may be forgotten by the subject. Meal consumption and physical activity are two prominent disturbances that disrupt BGC regulation, but their opposite effect on BGC makes the prediction of less critical than each of meal intake or only physical activity classes.
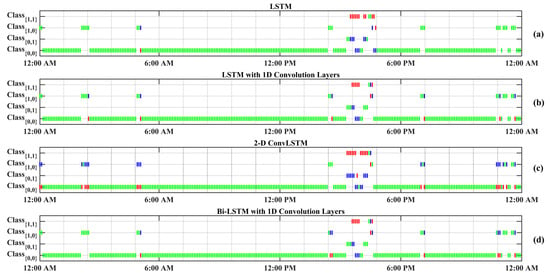
Figure 4.
One-step-backward predicted Meal and Exercise events for one randomly selected dataset (Subject 2).Vertical green bars represent correctly predicted classes. Vertical red bars denote incorrectly predicted classes, and their actual labels are shown by blue bars. Class Dictionary: : “neither Meal nor Exercise”, : “only Exercise”, : “only Meal”, : “Meal and Exercise”.
The confusion matrices of the classification results for one of the subjects (No. 2) are summarized in Table 7. As can be observed from Figure 4 and Table 7, detecting (physical activity) is more challenging in comparison to the carbohydrate intake () and (no meal or exercise). One reason for this difficulty is the lack of biosignal information, such as 3D accelerometer, blood volume pulse, and heart rate data. Some erroneous detections, such as confusing meals and exercise, are dangerous, since meals necessitate an insulin bolus while exercise lowers BGC, and the elimination of insulin infusion and/or increase in target BGC are needed. RNNs with LSTM and 1D convolution layers provide the best overall performance in minimizing such confusions: two meals events are classified as exercise (0.003%) and eight exercise events are classified as meals (0.125%).
Table 7.
Confusion matrices calculated from the predicted and actual classes of testing samples collected from Subject 2.
Two limitations of the study are the quality and accuracy of data collected in free living and the variables that are measured. As stated in the Introduction and Data Preprocessing sections, the missing data in the time series of CGM readings is one limitation that we addressed by developing data preprocessing techniques. The second limitation is the number of variables that are measured. In this data set, there are only CGM and insulin pump data and the voluntary information provided by the patients about meal consumption and exercising. This information is usually incomplete (sometimes people may forget or have no time to enter this information). These events can be captured objectively by other measurements from wearable devices. Such data were not available in this data set and limited the accuracy of the results, especially when the meal and exercise occurred concurrently.
The proportion of correctly detected exercise and meal events to all actual exercise and meal events for all subjects reveals that a series of convolution–max-pooling layers could elicit informative feature maps for classification efficiently. Although augmented features, such as the first and second derivatives of CGM and PIC, enhance the prediction power of the NN models, the secondary feature maps, extracted from all primary features, show to be a better fit for this classification problem. In addition, repeated 1D kernel filters in convolution layers better suit the time-series nature of the data, as opposed to extracting feature maps by utilizing 2D convolution filters on the data.
7. Conclusions
This work focuses on developing RNN models for detection and classification tasks using time series data containing missing and erroneous values. The first modeling issue arose from the quality of the recorded data in free living. An outlier rejection algorithm was developed based on multivariable statistical analysis and signal denoising by decomposition of the Hankel matrix of CGM recordings. A multivariate approach based on PPCA for CGM sample imputation was used to keep the harmony and relationship among the variables. The second issue addressed is the detection of events that affect the behavior of dynamic systems and the classification of these events. Four different RNN models were developed to detect meal and exercise events in the daily lives of individuals with T1D. The results indicate that models with 1D convolution layers can classify events better than regular LSTM RNN and 2D ConvLSTM RNN models, with very low confusion between the events that may cause dangerous situations by prompting erroneous interventions, such as giving insulin boluses during exercise.
Supplementary Materials
The following supporting information can be downloaded at: https://www.mdpi.com/article/10.3390/biomedinformatics2020019/s1, File S1: Assessing the computational load of training the RNN models.
Author Contributions
M.R.A., M.R., X.S., M.S., A.S., K.K. and A.C. conceived the research. M.R.A. and M.R. developed the theory, and M.R.A. performed the computations. M.R.A., M.R. and A.C. wrote the manuscript. All authors discussed the results and contributed to the final manuscript. A.C. supervised the project. All authors have read and agreed to the published version of the manuscript.
Funding
Financial support from JDRF under Grant No. 1-SRA-2019-S-B, NIH under Grant No. K25 HL141634 and the Hyosung S. R. Cho Endowed Chair to Ali Cinar at Illinois Institute of Technology are gratefully acknowledged.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Cai, L.; Zhu, Y. The challenges of data quality and data quality assessment in the big data era. Data Sci. J. 2015, 14, 2. [Google Scholar] [CrossRef]
- Centers for Disease Control and Prevention. National Diabetes Statistics Report, 2020; Centers for Disease Control and Prevention, US Department of Health and Human Services: Atlanta, GA, USA, 2020. [Google Scholar]
- Roglic, G. WHO Global report on diabetes: A summary. Int. J. Noncommun. Dis. 2016, 1, 3. [Google Scholar] [CrossRef]
- Horowitz, M.E.; Kaye, W.A.; Pepper, G.M.; Reynolds, K.E.; Patel, S.R.; Knudson, K.C.; Kale, G.K.; Gutierrez, M.E.; Cotto, L.A.; Horowitz, B.S. An analysis of Medtronic MiniMed 670G insulin pump use in clinical practice and the impact on glycemic control, quality of life, and compliance. Diabetes Res. Clin. Pract. 2021, 177, 108876. [Google Scholar] [CrossRef]
- Berget, C.; Lange, S.; Messer, L.; Forlenza, G.P. A clinical review of the t:slim X2 insulin pump. Expert Opin. Drug Deliv. 2020, 17, 1675–1687. [Google Scholar] [CrossRef]
- Cobry, E.C.; Berget, C.; Messer, L.H.; Forlenza, G.P. Review of the Omnipod® 5 Automated Glucose Control System Powered by HorizonTM for the treatment of Type 1 diabetes. Ther. Deliv. 2020, 11, 507–519. [Google Scholar] [CrossRef]
- Sangave, N.A.; Aungst, T.D.; Patel, D.K. Smart Connected Insulin Pens, Caps, and Attachments: A Review of the Future of Diabetes Technology. Diabetes Spectr. 2019, 32, 378–384. [Google Scholar] [CrossRef]
- Hoskins, M. New Diabetes Technology Expected in 2022. Available online: https://www.healthline.com/diabetesmine/new-diabetes-technology-in-2022 (accessed on 20 May 2022).
- Tanzi, M.G. FDA approves first interchangeable biosimilar insulin product for treatment of diabetes. Pharmacy Today 2021, 27, 21. [Google Scholar]
- Sevil, M.; Rashid, M.; Hajizadeh, I.; Askari, M.R.; Hobbs, N.; Brandt, R.; Park, M.; Quinn, L.; Cinar, A. Automated insulin delivery systems for people with type 1 diabetes. In Drug Delivery Devices and Therapeutic Systems; Chappel, E., Ed.; Developments in Biomedical Engineering and Bioelectronics, Academic Press: Cambridge, MA, USA, 2021; Chapter 9; pp. 181–198. [Google Scholar]
- Boughton, C.K.; Hovorka, R. New closed-loop insulin systems. Diabetologia 2021, 64, 1007–1015. [Google Scholar] [CrossRef]
- Brown, S.A.; Kovatchev, B.P.; Raghinaru, D.; Lum, J.W.; Buckingham, B.A.; Kudva, Y.C.; Laffel, L.M.; Levy, C.J.; Pinsker, J.E.; Wadwa, R.P.; et al. Six-Month Randomized, Multicenter Trial of Closed-Loop Control in Type 1 Diabetes. N. Engl. J. Med. 2019, 381, 1707–1717. [Google Scholar] [CrossRef]
- Forlenza, G.P.; Buckingham, B.A.; Brown, S.A.; Bode, B.W.; Levy, C.J.; Criego, A.B.; Wadwa, R.P.; Cobry, E.C.; Slover, R.J.; Messer, L.H.; et al. First Outpatient Evaluation of a Tubeless Automated Insulin Delivery System with Customizable Glucose Targets in Children and Adults with Type 1 Diabetes. Diabetes Technol. Ther. 2021, 23, 410–424. [Google Scholar] [CrossRef]
- Ware, J.; Hovorka, R. Recent advances in closed-loop insulin delivery. Metab.-Clin. Exp. 2022, 127, 154953. [Google Scholar] [CrossRef] [PubMed]
- Garcia-Tirado, J.; Lv, D.; Corbett, J.P.; Colmegna, P.; Breton, M.D. Advanced hybrid artificial pancreas system improves on unannounced meal response—In silico comparison to currently available system. Comput. Methods Programs Biomed. 2021, 211, 106401. [Google Scholar] [CrossRef]
- Haidar, A.; Legault, L.; Raffray, M.; Gouchie-Provencher, N.; Jacobs, P.G.; El-Fathi, A.; Rutkowski, J.; Messier, V.; Rabasa-Lhoret, R. Comparison Between Closed-Loop Insulin Delivery System (the Artificial Pancreas) and Sensor-Augmented Pump Therapy: A Randomized-Controlled Crossover Trial. Diabetes Technol. Ther. 2021, 23, 168–174. [Google Scholar] [CrossRef] [PubMed]
- Paldus, B.; Lee, M.H.; Morrison, D.; Zaharieva, D.P.; Jones, H.; Obeyesekere, V.; Lu, J.; Vogrin, S.; LaGerche, A.; McAuley, S.A.; et al. First Randomized Controlled Trial of Hybrid Closed Loop Versus Multiple Daily Injections or Insulin Pump Using Self-Monitoring of Blood Glucose in Free-Living Adults with Type 1 Diabetes Undertaking Exercise. J. Diabetes Sci. Technol. 2021, 15, 1399–1401. [Google Scholar] [CrossRef] [PubMed]
- Ekhlaspour, L.; Forlenza, G.P.; Chernavvsky, D.; Maahs, D.M.; Wadwa, R.P.; Deboer, M.D.; Messer, L.H.; Town, M.; Pinnata, J.; Kruse, G.; et al. Closed loop control in adolescents and children during winter sports: Use of the Tandem Control-IQ AP system. Pediatr. Diabetes 2019, 20, 759–768. [Google Scholar] [CrossRef]
- Deshpande, S.; Pinsker, J.E.; Church, M.M.; Piper, M.; Andre, C.; Massa, J.; Doyle, F.J., III; Eisenberg, D.M.; Dassau, E. Randomized Crossover Comparison of Automated Insulin Delivery Versus Conventional Therapy Using an Unlocked Smartphone with Scheduled Pasta and Rice Meal Challenges in the Outpatient Setting. Diabetes Technol. Ther. 2020, 22, 865–874. [Google Scholar] [CrossRef]
- Wilson, L.M.; Jacobs, P.G.; Riddell, M.C.; Zaharieva, D.P.; Castle, J.R. Opportunities and challenges in closed-loop systems in type 1 diabetes. Lancet Diabetes Endocrinol. 2022, 10, 6–8. [Google Scholar] [CrossRef]
- Franc, S.; Benhamou, P.Y.; Borot, S.; Chaillous, L.; Delemer, B.; Doron, M.; Guerci, B.; Hanaire, H.; Huneker, E.; Jeandidier, N.; et al. No more hypoglycaemia on days with physical activity and unrestricted diet when using a closed-loop system for 12 weeks: A post hoc secondary analysis of the multicentre, randomized controlled Diabeloop WP7 trial. Diabetes Obes. Metab. 2021, 23, 2170–2176. [Google Scholar] [CrossRef]
- Jeyaventhan, R.; Gallen, G.; Choudhary, P.; Hussain, S. A real-world study of user characteristics, safety and efficacy of open-source closed-loop systems and Medtronic 670G. Diabetes Obes. Metab. 2021, 23, 1989–1994. [Google Scholar] [CrossRef]
- Jennings, P.; Hussain, S. Do-it-yourself artificial pancreas systems: A review of the emerging evidence and insights for healthcare professionals. J. Diabetes Sci. Technol. 2020, 14, 868–877. [Google Scholar] [CrossRef]
- Hajizadeh, I.; Askari, M.R.; Kumar, R.; Zavala, V.M.; Cinar, A. Integrating MPC with Learning-Based and Adaptive Methods to Enhance Safety, Performance and Reliability in Automated Insulin Delivery. IFAC-PapersOnLine 2020, 53, 16149–16154. [Google Scholar] [CrossRef]
- Hajizadeh, I.; Askari, M.R.; Sevil, M.; Hobbs, N.; Brandt, R.; Rashid, M.; Cinar, A. Adaptive control of artificial pancreas systems for treatment of type 1 diabetes. In Control Theory in Biomedical Engineering; Boubaker, O., Ed.; Academic Press: Cambridge, MA, USA, 2020; Chapter 3; pp. 63–81. [Google Scholar]
- Askari, M.R.; Hajizadeh, I.; Rashid, M.; Hobbs, N.; Zavala, V.M.; Cinar, A. Adaptive-learning model predictive control for complex physiological systems: Automated insulin delivery in diabetes. Annu. Rev. Control. 2020, 50, 1–12. [Google Scholar] [CrossRef]
- Garcia-Tirado, J.; Brown, S.A.; Laichuthai, N.; Colmegna, P.; Koravi, C.L.; Ozaslan, B.; Corbett, J.P.; Barnett, C.L.; Pajewski, M.; Oliveri, M.C.; et al. Anticipation of Historical Exercise Patterns by a Novel Artificial Pancreas System Reduces Hypoglycemia During and After Moderate-Intensity Physical Activity in People with Type 1 Diabetes. Diabetes Technol. Ther. 2021, 23, 277–285. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Yu, Y.; Si, X.; Hu, C.; Zhang, J. A Review of Recurrent Neural Networks: LSTM Cells and Network Architectures. Neural Comput. 2019, 31, 1235–1270. [Google Scholar] [CrossRef]
- Efron, B. Missing data, imputation, and the bootstrap. J. Am. Stat. Assoc. 1994, 89, 463–475. [Google Scholar] [CrossRef]
- Moritz, S.; Bartz-Beielstein, T. imputeTS: Time series missing value imputation in R. R J. 2017, 9, 207. [Google Scholar] [CrossRef] [Green Version]
- Ahola, A.J.; Mutter, S.; Forsblom, C.; Harjutsalo, V.; Groop, P.H. Meal timing, meal frequency, and breakfast skipping in adult individuals with type 1 diabetes–associations with glycaemic control. Sci. Rep. 2019, 9, 1–10. [Google Scholar] [CrossRef]
- Tipping, M.E.; Bishop, C.M. Probabilistic principal component analysis. J. R. Stat. Soc. Ser. Stat. Methodol. 1999, 61, 611–622. [Google Scholar] [CrossRef]
- Ilin, A.; Raiko, T. Practical approaches to principal component analysis in the presence of missing values. J. Mach. Learn. Res. 2010, 11, 1957–2000. [Google Scholar]
- Hoaglin, D.C.; John, W. Tukey and Data Analysis. Stat. Sci. 2003, 18, 311–318. [Google Scholar] [CrossRef]
- Bakshi, B.; Stephanopoulos, G. Representation of process trends-III. Multiscale extraction of trends from process data. Comput. Chem. Eng. 1994, 18, 267–302. [Google Scholar] [CrossRef]
- Cheung, J.Y.; Stephanopoulos, G. Representation of process trends-Part I. A formal representation framework. Comput. Chem. Eng. 1990, 14, 495–510. [Google Scholar] [CrossRef]
- Samadi, S.; Turksoy, K.; Hajizadeh, I.; Feng, J.; Sevil, M.; Cinar, A. Meal Detection and Carbohydrate Estimation Using Continuous Glucose Sensor Data. IEEE J. Biomed. Health Inf. 2017, 21, 619–627. [Google Scholar] [CrossRef] [PubMed]
- Samadi, S.; Rashid, M.; Turksoy, K.; Feng, J.; Hajizadeh, I.; Hobbs, N.; Lazaro, C.; Sevil, M.; Littlejohn, E.; Cinar, A. Automatic Detection and Estimation of Unannounced Meals for Multivariable Artificial Pancreas System. Diabetes Technol. Ther. 2018, 20, 235–246. [Google Scholar] [CrossRef] [PubMed]
- Eberle, C.; Ament, C. The Unscented Kalman Filter estimates the plasma insulin from glucose measurement. Biosystems 2011, 103, 67–72. [Google Scholar] [CrossRef]
- Hajizadeh, I.; Rashid, M.; Turksoy, K.; Samadi, S.; Feng, J.; Frantz, N.; Sevil, M.; Cengiz, E.; Cinar, A. Plasma insulin estimation in people with type 1 diabetes mellitus. Ind. Eng. Chem. Res. 2017, 56, 9846–9857. [Google Scholar] [CrossRef]
- Hajizadeh, I.; Rashid, M.; Samadi, S.; Feng, J.; Sevil, M.; Hobbs, N.; Lazaro, C.; Maloney, Z.; Brandt, R.; Yu, X.; et al. Adaptive and Personalized Plasma Insulin Concentration Estimation for Artificial Pancreas Systems. J. Diabetes Sci. Technol. 2018, 12, 639–649. [Google Scholar] [CrossRef] [Green Version]
- Hovorka, R.; Canonico, V.; Chassin, L.J.; Haueter, U.; Massi-Benedetti, M.; Federici, M.O.; Pieber, T.R.; Schaller, H.C.; Schaupp, L.; Vering, T.; et al. Nonlinear model predictive control of glucose concentration in subjects with type 1 diabetes. Physiol. Meas. 2004, 25, 905–920. [Google Scholar] [CrossRef] [Green Version]
- Ivers, N.M.; Jiang, M.; Alloo, J.; Singer, A.; Ngui, D.; Casey, C.G.; Catherine, H.Y. Diabetes Canada 2018 clinical practice guidelines: Key messages for family physicians caring for patients living with type 2 diabetes. Can. Fam. Physician 2019, 65, 14–24. [Google Scholar]
- Care, F. Standards of Medical Care in Diabetes 2019. Diabetes Care 2019, 42, S124–S138. [Google Scholar]
- NICE. Type 1 Diabetes in Adults: Diagnosis and Management; National Institute for Health and Care Excellence (NICE): London, UK, 2015; pp. 1–87. [Google Scholar]
- Arulampalam, M.; Maskell, S.; Gordon, N.; Clapp, T. A tutorial on particle filters for online nonlinear/non-Gaussian Bayesian tracking. IEEE Trans. Signal Process. 2002, 50, 174–188. [Google Scholar] [CrossRef] [Green Version]
- Pitt, M.; Silva, R.; Giordani, P.; Kohn, R. Auxiliary particle filtering within adaptive Metropolis-Hastings sampling. arXiv 2010, arXiv:1006.1914. [Google Scholar]
- Pudil, P.; Novovičová, J.; Kittler, J. Floating search methods in feature selection. Pattern Recognit. Lett. 1994, 15, 1119–1125. [Google Scholar] [CrossRef]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.Y.; Wong, W.K.; Woo, W.c. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. Adv. Neural Inf. Process. Syst. 2015, 28, 802–810. [Google Scholar]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: A neural image caption generator. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3156–3164. [Google Scholar]
- Donahue, J.; Anne Hendricks, L.; Guadarrama, S.; Rohrbach, M.; Venugopalan, S.; Saenko, K.; Darrell, T. Long-term recurrent convolutional networks for visual recognition and description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2625–2634. [Google Scholar]
- Géron, A. Hands-on Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems; O’Reilly Media: Newton, MA, USA, 2019. [Google Scholar]
- Brownlee, J. Deep Learning for Time Series Forecasting: Predict the Future with MLPs, CNNs and LSTMs in Python; Machine Learning Mastery. 2018. Available online: https://machinelearningmastery.com/deep-learning-for-time-series-forecasting/ (accessed on 20 May 2022).
- Schuster, M.; Paliwal, K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef] [Green Version]
- Graves, A.; Schmidhuber, J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures. Neural Netw. 2005, 18, 602–610. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).