Abstract
This paper introduces a novel approach to pavement material crack detection, classification, and segmentation using advanced deep learning techniques, including multi-scale feature aggregation and transformer-based attention mechanisms. The proposed methodology significantly enhances the model’s ability to handle varying crack sizes, shapes, and complex pavement textures. Trained on a dataset of 10,000 images, the model achieved substantial performance improvements across all tasks after integrating transformer-based attention. Detection precision increased from 88.7% to 94.3%, and IoU improved from 78.8% to 93.2%. In classification, precision rose from 88.3% to 94.8%, and recall improved from 86.8% to 94.2%. For segmentation, the Dice Coefficient increased from 80.3% to 94.7%, and IoU for segmentation advanced from 74.2% to 92.3%. These results underscore the model’s robustness and accuracy in identifying pavement cracks in challenging real-world scenarios. This framework not only advances automated pavement maintenance but also provides a foundation for future research focused on optimizing real-time processing and extending the model’s applicability to more diverse pavement conditions.
1. Introduction
Pavement maintenance is a critical aspect of infrastructure management, ensuring that roads, highways, and other paved surfaces remain safe and operational. The structural integrity of pavement material is frequently compromised by the formation of cracks, which can deteriorate rapidly under the influence of traffic loads, environmental conditions, and time. Effective and timely crack detection is essential to prevent minor issues from escalating into significant structural failures, which could result in costly repairs and potential hazards to public safety [1].
The detection of cracks in pavement material is a foundational element of preventive maintenance strategies. Pavement cracks, if not identified and addressed early, can lead to extensive damage, including potholes, rutting, and other forms of surface deformation. These issues not only degrade the quality of the pavement but also pose serious risks to vehicles and pedestrians [2], eventually affecting both structural and functional performance. For instance, unnoticed cracks can evolve into potholes, which are particularly hazardous, causing accidents and damage to vehicles. Moreover, the presence of cracks allows water to seep into the sublayers of the pavement, weakening the structural base and accelerating deterioration. The economic implications of neglected pavement cracks are also significant. Repair costs increase exponentially as cracks grow larger and more widespread, requiring more extensive interventions such as resurfacing or even full-depth repairs. In contrast, early detection allows for less invasive maintenance techniques, such as crack sealing or patching, which are cost-effective and extend the pavement’s lifespan [3].
In this context, accurate and efficient crack detection is crucial for optimizing pavement maintenance strategies. Traditionally, crack detection has relied on manual inspections, which are labor-intensive, time-consuming, and prone to human error [4]. As the scale of road networks expands, these conventional methods are increasingly insufficient, prompting the need for automated, precise, and scalable solutions. The detection of pavement cracks presents several challenges, particularly in terms of the variability in crack sizes, shapes, and the surrounding environmental conditions. Cracks can range from fine hairline fissures to wide, deep crevices, each requiring different detection techniques. Fine cracks are especially difficult to detect, as they can blend into the pavement texture, while larger cracks, although more apparent, may exhibit complex patterns that complicate their identification and classification [5].
Another significant challenge lies in the diversity of pavement materials and surface conditions. Asphalt, concrete, and composite pavements each have distinct visual characteristics, and cracks can manifest differently across these surfaces. Additionally, environmental factors such as shadows, lighting variations, and weather conditions further complicate crack detection [6,7]. For instance, wet surfaces can obscure cracks, while shadows cast by surrounding structures or vegetation can create false positives. Moreover, cracks do not always follow a predictable pattern; they may branch out, form irregular networks, or exhibit varying degrees of severity along their length. This irregularity poses a challenge to conventional image-processing techniques, which often rely on predefined patterns or features for crack detection. As a result, existing methods may struggle to accurately detect and classify cracks, particularly in complex scenarios [8].
To address these challenges, recent advancements in deep learning have opened new avenues for more effective crack detection methodologies [9,10]. Among these, the integration of multi-scale feature aggregation and transformer-based attention mechanisms represents a promising approach. Multi-scale feature aggregation is a technique that allows the detection model to capture features at different levels of detail. This is particularly useful for crack detection, where cracks of various sizes coexist within the same pavement surface. By aggregating features from multiple scales, the model can detect both fine details, such as hairline cracks, and broader features, such as large structural fissures. This approach ensures that the model is sensitive to cracks of all sizes, improving overall detection accuracy. Transformer-based attention mechanisms, on the other hand, enhance the model’s ability to focus on the most relevant parts of the image. Traditional convolutional neural networks (CNNs) process images in a fixed grid, often leading to the dilution of important details in complex images [11]. Transformers, however, employ self-attention mechanisms that allow the model to weigh the importance of different regions of the image dynamically. This means that the model can prioritize areas that are more likely to contain cracks, while de-emphasizing irrelevant or less important regions. This capability is particularly beneficial in complex environments where cracks may be partially obscured or where the surrounding texture might otherwise confuse the detection model [12].
By combining these two techniques—multi-scale feature aggregation and transformer-based attention mechanisms—a more robust and accurate model for pavement crack detection can be developed. This hybrid approach leverages the strengths of both methods: the ability to detect features on multiple scales ensures that cracks of all sizes are identified, while the attention mechanism enhances the model’s focus on relevant image regions, improving detection accuracy and reducing false positives.
This research addresses the limitations of conventional and existing deep-learning-based crack detection methods by developing an advanced, unified deep learning model tailored for automated pavement inspection. The model integrates detection, classification, and segmentation tasks into a single, comprehensive framework, allowing for more efficient and accurate processing of pavement crack images. By employing multi-scale feature aggregation and transformer-based attention mechanisms, the model enhances its ability to detect and classify various crack types—specifically alligator, longitudinal, and transverse cracks—across diverse pavement surfaces and environmental conditions. Additionally, precise segmentation maps are generated to enable more targeted maintenance interventions. The proposed solution aims to provide a scalable and robust method for crack detection, addressing key challenges in infrastructure management and contributing to improved road safety. This paper makes several key contributions to the field of pavement crack detection through the development and application of advanced deep learning techniques:
- Multi-Scale Feature Aggregation for Comprehensive Detection: We introduce a multi-scale feature aggregation approach that enables the model to effectively detect cracks of varying sizes, from fine hairline fissures to large structural cracks. By integrating features from multiple scales, the model achieves a higher level of detail and accuracy in crack detection.
- Transformer-Based Attention Mechanisms for Enhanced Focus: We incorporate transformer-based attention mechanisms into the crack detection model, allowing it to dynamically focus on the most relevant regions of the pavement images. This reduces the likelihood of false positives and improves the model’s ability to detect cracks in complex environments.
- Unified Model for Detection, Classification, and Segmentation: The proposed methodology integrates detection, classification, and segmentation into a single, unified model. This holistic approach not only identifies the presence of cracks but also categorizes them by type and provides precise segmentation maps, which are essential for targeted maintenance actions.
2. Related Work
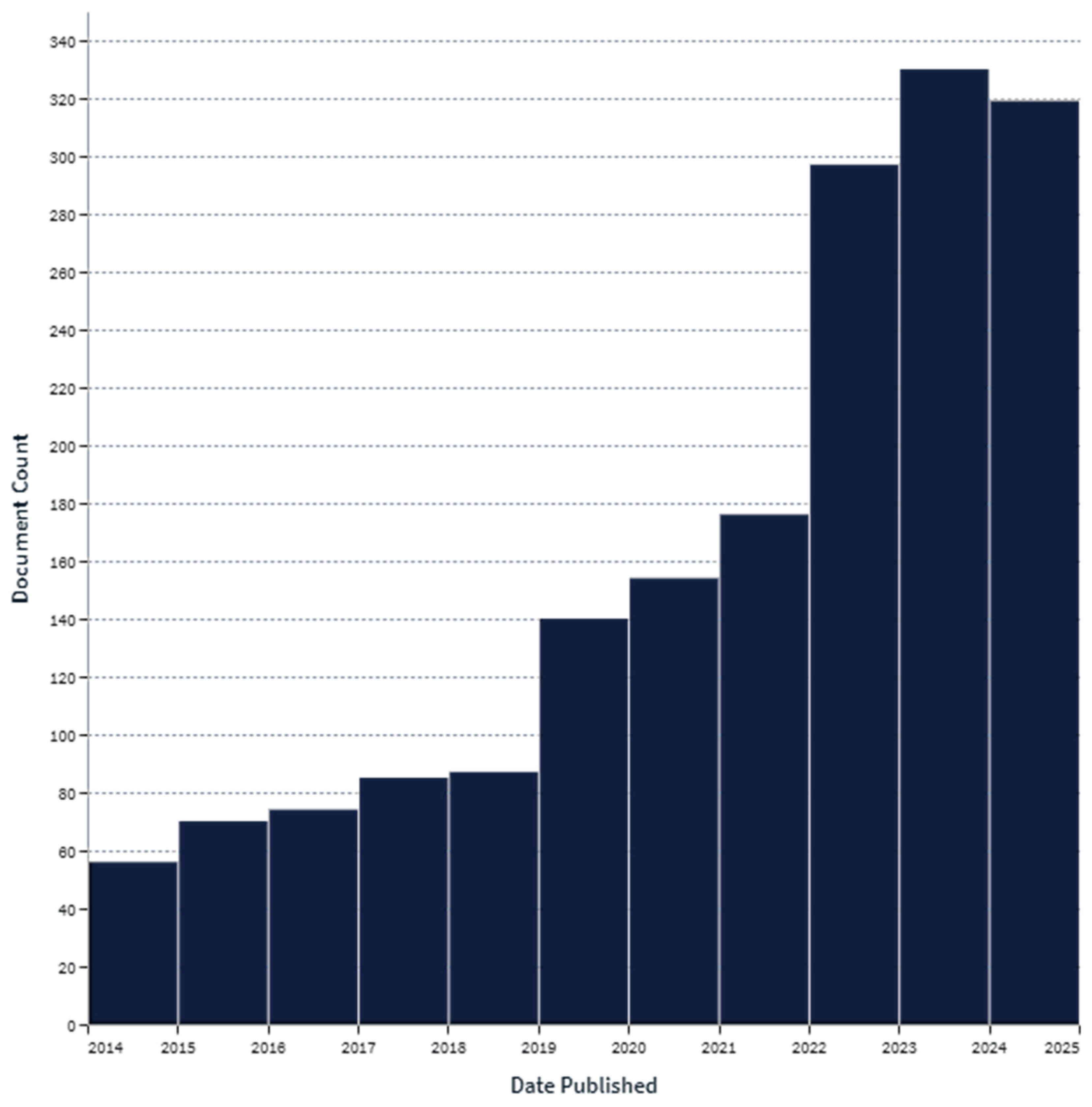
The detection, classification, and segmentation of pavement cracks have been active areas of research within the field of civil engineering and computer vision for quite a long time now, as shown in Figure 1 from lens.org [13]. The evolution of these methods reflects the ongoing pursuit of more accurate, efficient, and scalable solutions for infrastructure maintenance. This section provides an overview of the existing methods of crack detection, classification, and segmentation, followed by a discussion of their limitations, particularly in handling multi-scale features and focusing on relevant image regions.
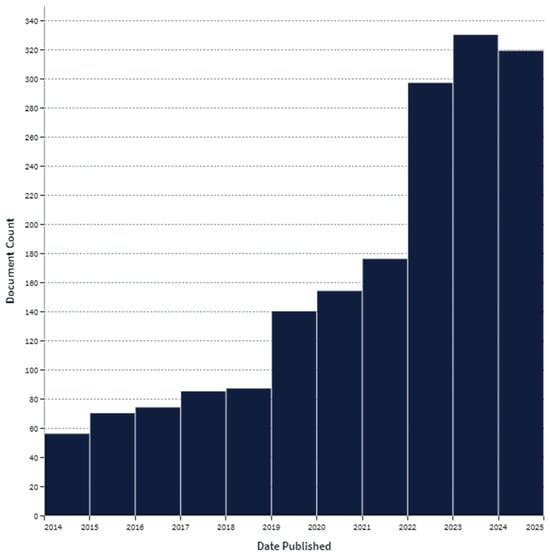
Figure 1.
Trends in pavement crack detection, classification, and segmentation.
2.1. Overview of Existing Methods in Crack Detection, Classification, and Segmentation
Historically, pavement crack detection relied heavily on manual inspections, where engineers and technicians visually assessed road surfaces to identify and categorize cracks. While effective in certain contexts, this approach is labor-intensive, subjective, and impractical for large-scale assessments, leading to the development of automated techniques.
- i.
- Image-Processing Techniques
Early automated methods predominantly relied on traditional image-processing techniques. Edge detection algorithms, such as the Canny edge detector, Sobel operator, and Laplacian of Gaussian, were among the first tools employed to identify cracks. These methods work by detecting intensity discontinuities in images, which are often indicative of cracks. Morphological operations, such as dilation and erosion, were then applied to refine the detected edges and reduce noise.
Histogram equalization is a widely employed technique in image preprocessing, primarily used to enhance image contrast by redistributing the intensity values. This adjustment results in improved clarity, especially in images with low-light conditions [14]. Another common preprocessing step is cropping, which involves trimming away unwanted outer regions of an image. Cropping is often used to remove unnecessary background elements, enhance composition, adjust perspective, or focus on specific areas or subjects within the image. This process can lead to variations in image size due to the removal of different sections [15,16].
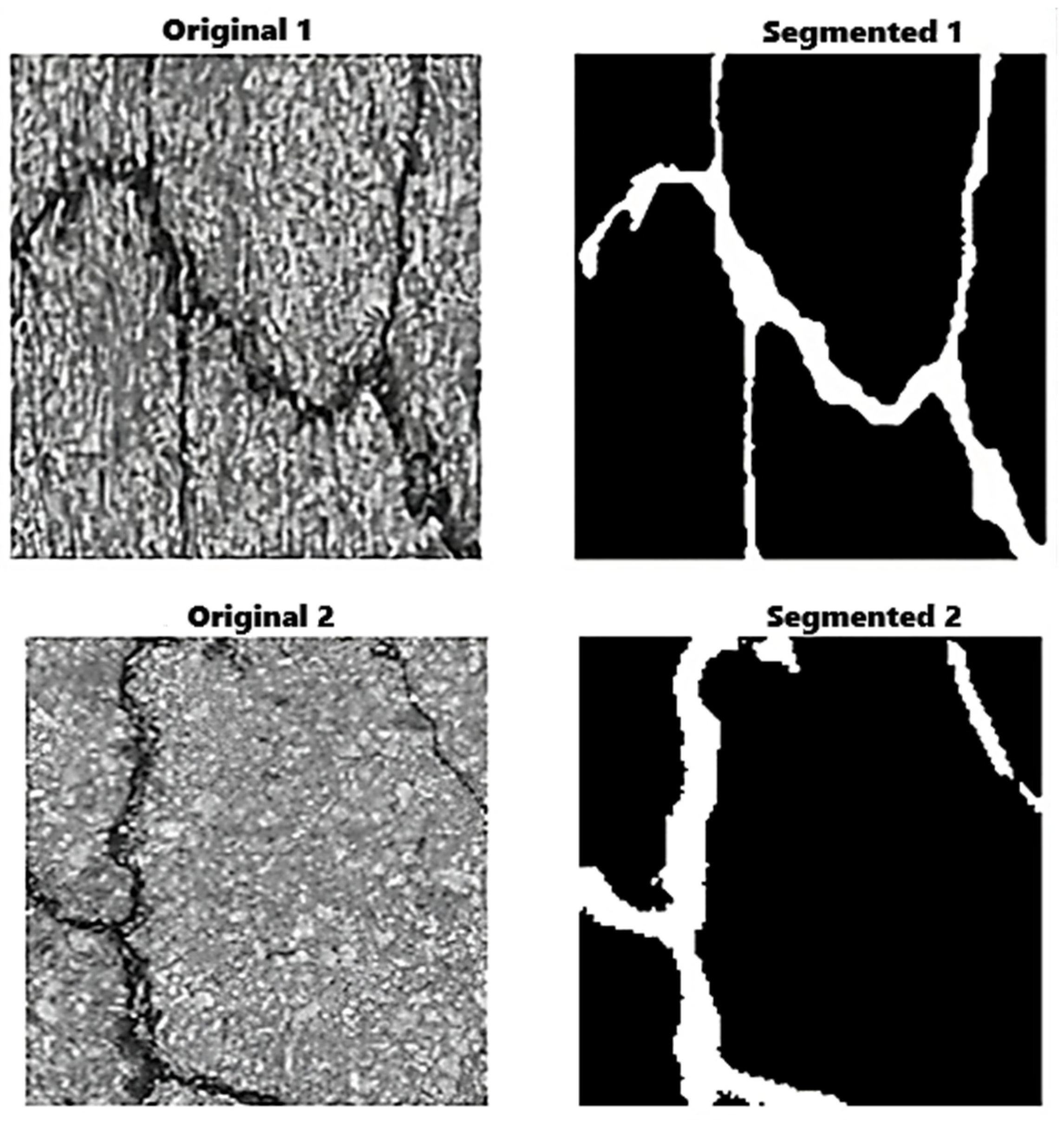
Image segmentation is a fundamental task in image processing that involves partitioning an image into multiple regions or segments. This technique is extensively applied in object detection and boundary identification across various domains, including medical imaging, autonomous driving, and satellite imagery. During segmentation, each pixel in the image is assigned a label or class to indicate the object or region it belongs to [17]. This process provides more detailed and specific information about the image compared to other image-processing methods, as demonstrated in Figure 2.
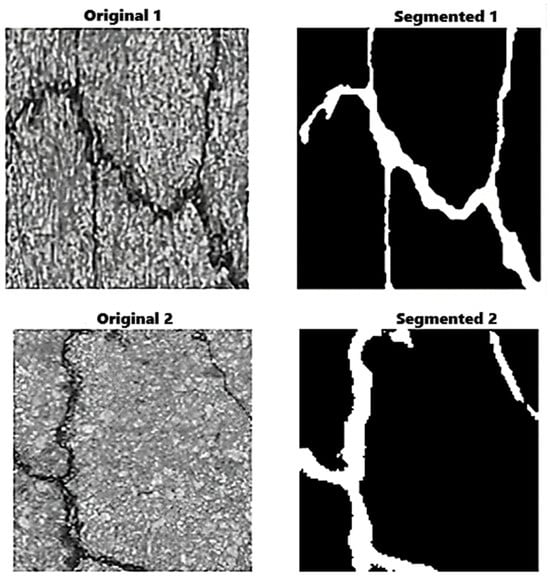
Figure 2.
Crack image segmentation.
While these techniques provide a foundational approach to automated crack detection, they exhibit significant limitations. Specifically, edge detection algorithms are highly sensitive to noise and lighting variations, often leading to false positives or missed cracks. Additionally, these methods struggle with detecting cracks that do not conform to simple geometric shapes, as they rely on predefined filters that are inadequate for capturing complex crack patterns.
- ii.
- Machine Learning Approaches
With the advent of machine learning, more sophisticated methods for crack detection and classification emerged. Machine learning algorithms, such as Support Vector Machines (SVMs), Random Forest, and K-Nearest Neighbor (KNN), were employed to classify image patches as containing cracks or not. These approaches typically involve extracting handcrafted features, such as texture descriptors (e.g., Local Binary Patterns, Gabor filters) or histogram-based features, which are then used as inputs to the classifiers.
In [18], the development of DeepCrack, a deep convolutional neural network, marks a significant advance in the field of crack detection. This method addresses the common issues of poor continuity and low contrast in pavement cracks, which typically hinder detection using low-level features. By employing a strategy that leverages high-level feature learning, DeepCrack facilitates more effective identification of line structures. The network utilizes multi-scale convolutional features that are learned at hierarchical stages and then fused to enhance both detailed and holistic representations of cracks. Built on the encoder–decoder architecture of SegNet, DeepCrack strategically fuses features on equivalent scales from both the encoder and decoder networks. Trained on a specific dataset and evaluated on three others, DeepCrack has demonstrated superior performance, achieving an average F-measure of over 0.87. Similarly, another innovative approach involves a pothole detection system using a commercial black-box camera, which demonstrates the potential of integrating existing infrastructure with advanced image-processing technologies for road maintenance [19].
Recent advancements in machine learning have significantly enhanced the accuracy and efficiency of road surface damage analysis. These algorithms, with their ability to learn complex patterns from extensive datasets, have become a pivotal component in the evolution of automated pavement inspection systems. A comprehensive review by Decker [20] focused on the treatment of cracks in asphalt pavements, with particular attention to minimizing water intrusion and preventing structural failures. This study involved an extensive analysis of the existing literature, surveys conducted with agencies and contractors, and the development of best practice guidelines. It provides a thorough examination of current techniques for crack sealing and filling, offering valuable insights into the latest methods for maintaining the integrity of pavements.
Building on these advancements, Prah and Okine [21] proposed a sophisticated programming methodology for detecting asphalt cracks. Their approach begins with the preprocessing of crack images, where the surface is smoothed, and existing cracks are enhanced to improve visibility. Subsequently, each non-overlapping square of the image is analyzed using a Support Vector Machine (SVM), a supervised learning technique that generates support vectors to identify and classify cracks. This method exemplifies the growing application of machine learning in improving the precision of crack detection and highlights the potential of SVMs in processing complex pavement images.
Although machine learning methods offer improved accuracy over traditional image-processing techniques, they still face challenges. The reliance on handcrafted features limits their ability to generalize across different pavement types and environmental conditions. Moreover, these models often struggle with detecting fine cracks or distinguishing between cracks and other pavement surface irregularities, such as shadows or lane markings.
- iii.
- Deep Learning Techniques
The introduction of deep learning, particularly Convolutional Neural Networks (CNNs), revolutionized crack detection, classification, and segmentation. Unlike traditional machine learning methods, CNNs automatically learn hierarchical feature representations directly from raw image data, enabling them to capture more complex patterns and structures. Various CNN architectures have been proposed for crack detection. For instance, ref. [22] developed a deep CNN model for crack detection, demonstrating significant improvements in accuracy and robustness over traditional methods. Similarly, ref. [23] proposed a CNN-based approach for crack classification, which was further enhanced by incorporating data augmentation techniques to improve generalization. In addition to detection and classification, deep learning has also been applied to crack segmentation. Fully Convolutional Networks (FCNs), U-Net, and SegNet are among the popular architectures used for pixel-level crack segmentation. These models generate segmentation maps that precisely outline crack regions, facilitating more targeted maintenance actions [24].
One such approach is the use of an improved deep learning fusion model that combines deep CNN fusion with the U-Net architecture [25]. This model focuses on optimizing hyperparameters specifically for crack classification. The researchers developed a custom dataset to test their model, which is capable of calculating crack lengths through pixel labeling and scanning, providing detailed and precise measurements essential for effective pavement maintenance. Another innovative method leverages deep neural networks to detect road damage using images captured through a smartphone [23]. This system was trained and tested on a large dataset of 163,664 images, collected in partnership with local governments in Japan. The success of this method highlights how deep learning can be applied to real-world scenarios, efficiently handling large volumes of data while maintaining high accuracy.
Additionally, a feature pyramid and hierarchical boosting network have been used for pavement crack detection [26]. This approach utilizes deep supervision learning to enhance low-level features, making crack detection faster and more efficient. The reduced recognition time makes this model particularly useful for applications that require quick and reliable pavement assessments. Zou et al. [18] introduced a model designed to segment asphalt images into cracks and the surrounding pavement using an encoder–decoder architecture. This method effectively isolates cracks from the background, providing clear and accurate segmentation that is essential for detailed pavement analysis and maintenance planning. Further contributing to this field, Wang et al. [27] developed a network topology that incorporates four convolutional layers with max pooling as an encoder, followed by a series of decoding modules. This design aims to focus on crack features while filtering out irrelevant components, enhancing the precision of crack segmentation.
However, despite the success of deep learning models, they are not without limitations. Standard CNNs and FCNs typically process images on a single scale, which can be problematic when dealing with cracks of varying sizes. Smaller cracks may be overlooked, while larger cracks might dominate the learned features, leading to suboptimal performance. Additionally, CNNs have a fixed receptive field, which limits their ability to capture long-range dependencies within an image, a critical factor in accurately segmenting irregular crack patterns.
2.2. Limitations of Current Approaches in Handling Multi-Scale Features and Focusing on Relevant Image Regions
One of the primary limitations of the current crack detection methods, including those based on deep learning, is their ability to handle multi-scale features. Cracks in pavement surfaces exhibit a wide range of sizes and shapes, from tiny hairline fractures to large, branching fissures. A model that processes images on a single scale may fail to capture the full spectrum of crack features, leading to incomplete or inaccurate detections.
- Multi-Scale Feature Handling
To address this, some researchers have explored multi-scale approaches within the context of deep learning. For example, Feature Pyramid Networks (FPNs) have been integrated with CNNs to capture features on multiple scales by combining information from different layers of the network [28]. This approach has been effective in improving the detection of cracks across various sizes. However, while multi-scale feature aggregation enhances the model’s ability to detect cracks of different sizes, it also increases the model’s complexity and computational requirements, which can be a limitation in real-time applications.
- Focus on Relevant Image Regions
Another significant challenge is the ability of models to focus on the most relevant regions of an image. Pavement images often contain a mix of relevant (cracks) and irrelevant (noise, shadows, lane markings) features. Standard CNNs process the entire image uniformly, without distinguishing between important and unimportant regions. This can lead to false positives or missed detections, particularly in complex environments where cracks may be partially obscured or when the pavement surface exhibits significant texture variations.
To mitigate this, some approaches have incorporated attention mechanisms into CNNs [29]. Attention mechanisms allow the model to dynamically focus on different parts of the image, emphasizing areas that are more likely to contain cracks. However, traditional attention mechanisms in CNNs are often limited in scope, focusing on small, localized regions rather than capturing long-range dependencies within the image. This limitation hampers their effectiveness in dealing with complex crack patterns that span large portions of the pavement surface.
3. Materials and Methods
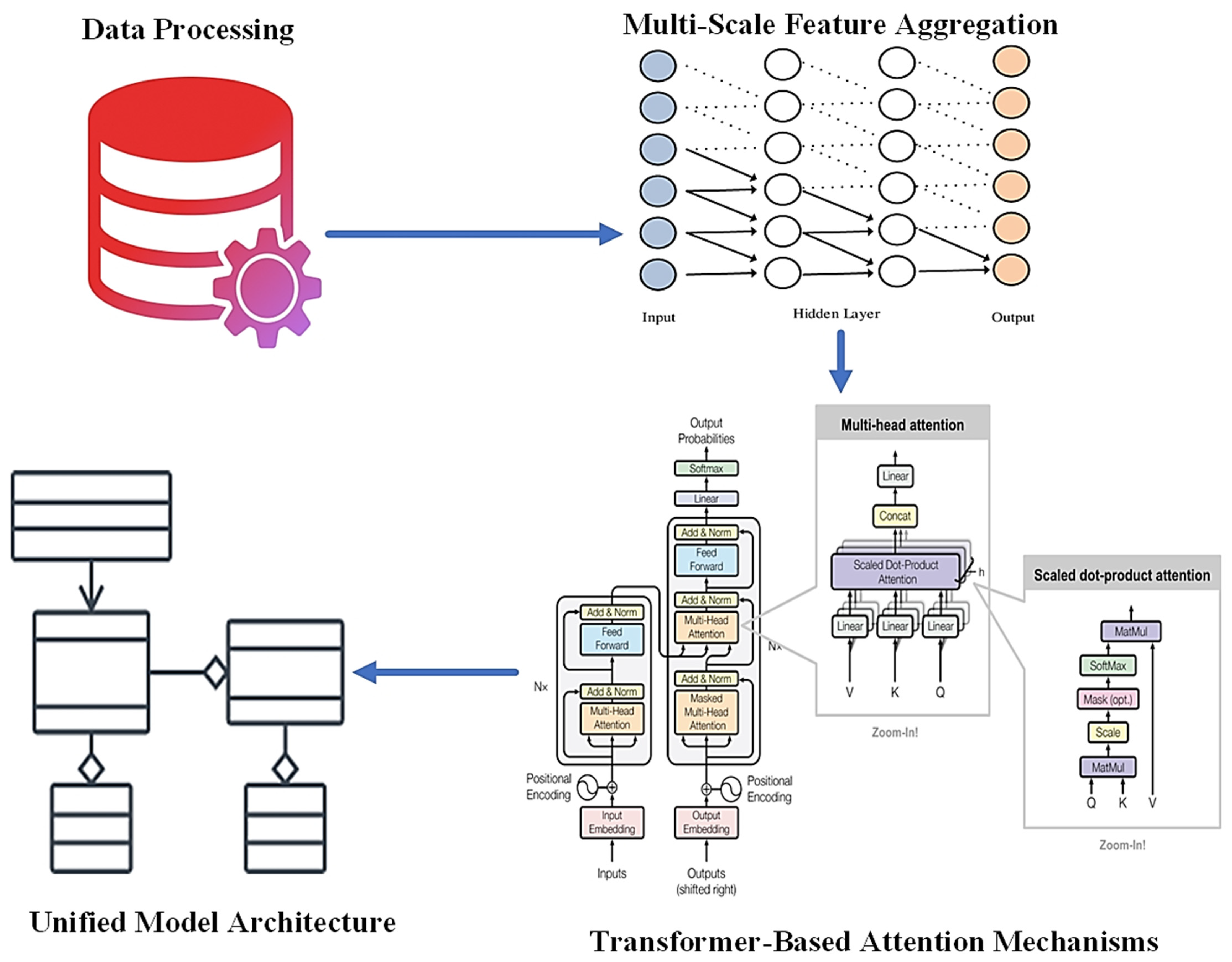
The proposed methodology leverages a combination of advanced deep learning techniques, including multi-scale feature aggregation, transformer-based attention mechanisms, and a unified model architecture, to address the complex challenge of pavement crack detection, classification, and segmentation, as shown in Figure 3. This section provides a comprehensive explanation of the algorithms and mathematical foundations that underpin each component of the methodology, offering a detailed understanding of how these techniques interact to improve overall model performance.
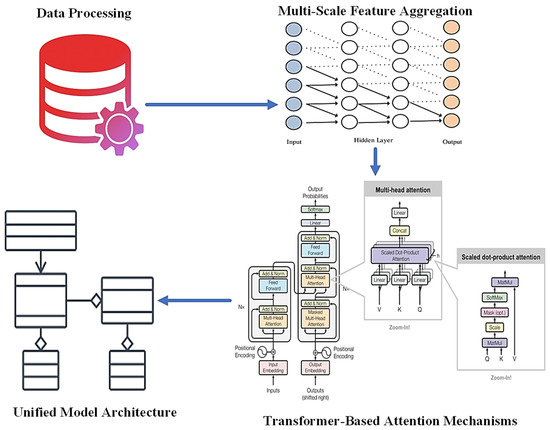
Figure 3.
Research methodology.
3.1. Data Preprocessing
For this study, we used two main sources of data: the RCD-IIUM dataset, which was developed specifically for this research, and additional publicly available datasets. These datasets together provide a broad view of different pavement conditions and crack types, helping to ensure that our model can perform well in various real-world scenarios.
- RCD-IIUM dataset: The RCD-IIUM dataset is a collection of high-resolution images of pavement surfaces from different roads in Malaysia. The images have been labeled to identify three main types of cracks: alligator, longitudinal, and transverse. The labeling was conducted carefully to make sure the data were accurate and useful for training the model.
- Online available data: To add more variety to the training data and improve the model’s ability to generalize, we also included images from publicly available datasets. These images come from different locations and cover a wide range of pavement surfaces and conditions. By using these additional data, we aimed to make the model more adaptable to different lighting conditions, surface textures, and crack appearances.
Table 1 presents the data description, including the names of the datasets used, the number of original images obtained from each dataset, and their respective citations. The majority of the images come from the RCD-IIUM Pavement Crack Dataset, supplemented by the RDD2020 and CRACK500 datasets to ensure a diverse and comprehensive collection of pavement crack images for analysis.

Table 1.
Dataset Description.
The dataset was subjected to several augmentation techniques to enhance its diversity and reduce the risk of overfitting. These techniques include the following:
- Rotation and scaling: Images are randomly rotated and scaled to simulate different perspectives and distances, ensuring that the model learns to recognize cracks from various angles and sizes. Special attention is given to images containing longitudinal and transverse cracks. Careless rotation could alter the orientation of these specific crack types, potentially mislabeling them during training. Therefore, when rotating such images, a controlled rotation angle is applied to preserve their structural integrity and ensure that longitudinal and transverse cracks remain correctly classified. Mathematically, if I(x, y) represents the pixel intensity at coordinates (x, y), then the rotation operation can be represented as Equation (1):where θ is the rotation angle.I′(x′, y′) = I(cos(θ) x + sin(θ)·y, −sin(θ)·x + cos(θ)·y)
- Random cropping: This technique involves selecting random subregions of the image to focus on specific areas of the pavement, which makes the model more sensitive to cracks of different sizes and shapes. If I(x, y) represents the original image, then cropping can be defined as selecting a submatrix I′[x1:x2, y1:y2] where x1, x2, y1, and y2 are the cropping boundaries.
- Noise injection: Gaussian noise is added to the images to increase the model’s robustness against real-world imperfections, such as dirt or shadows. Mathematically, if I(x, y) is the original image and N(x, y) is Gaussian noise with mean μ and variance σ2, then the noisy image I′(x, y) is represented as Equation (2):where N (x, y)∼N(μ, σ2).I′(x, y) = I(x, y) + N(x, y)
- Contrast adjustment: This involves modifying the contrast of the images to ensure that the model can handle various lighting conditions. The contrast adjustment can be mathematically represented by Equation (3):where α is the contrast factor.I′(x, y) = α (I(x, y) − 128) + 128
These augmentation techniques are crucial for training a model that can perform well under varied and unpredictable real-world conditions. The combined dataset includes images of three main types of cracks: alligator, longitudinal, and transverse. Table 2 shows how the data are distributed across these crack types.
Table 2.
Distribution of Images Across Crack Types in the Combined Dataset after Image Processing.
3.2. Multi-Scale Feature Aggregation
The core of our methodology lies in multi-scale feature aggregation, which is designed to capture features on different scales within the image, making the model more sensitive to cracks of varying sizes.
- CNN architecture: We use a deep Convolutional Neural Network (CNN) as the backbone of our model. Networks like ResNet or EfficientNet are employed for their ability to extract rich, hierarchical features from images. The input image I(x, y) is processed through multiple convolutional layers, where each layer l applies a filter fl to produce feature maps Fl(x, y), represented as Equation (4):
Here, Wij is the filter weights, bl is the bias, and σ is a non-linear activation function such as ReLU.
- Feature Pyramid Network (FPN): The FPN is integrated into the CNN architecture to aggregate features from different layers. The FPN enhances the model’s ability to detect both fine details and broader patterns. Mathematically, if Fl represents the feature map from the l-th layer, then the FPN combines these maps, represented as Equation (5):where αl is the learnable weight that determines the contribution of each layer’s features.
- Feature fusion strategy: The features extracted by the FPN are fused using a weighted averaging technique. This strategy combines features across scales, ensuring a comprehensive representation of the pavement surface. The final fused feature map can be expressed as Equation (6):where ws is the weight assigned to features on different scales s.
3.3. Transformer-Based Attention Mechanisms
To further improve the model’s ability to focus on relevant regions of the image, especially in complex environments, we integrate Vision Transformers (ViTs) into the architecture.
- Integration with aggregated features: The aggregated multi-scale features from the FPN are passed through the Vision Transformer. The transformer treats the image as a sequence of non-overlapping patches Pi, where each patch is embedded into a vector space. The embedding for each patch is given by Equation (7):where We is the embedding matrix and be is the bias. The transformer applies self-attention across these patches to capture long-range dependencies.
- Self-attention mechanisms: The self-attention mechanism computes the relevance of each patch with respect to all others. For each patch i, its attention score with patch j is computed as Equation (8):where Qi and Kj are the query and key vectors for patches i and j, and is the dimension of the key vectors. The final output for each patch is represented as Equation (9):where is the value vector for patch j. The output Oi is then passed through the remaining layers of the transformer to produce the final attention-enhanced feature map.
3.4. Unified Model Architecture
The unified model architecture integrates the tasks of detection, classification, and segmentation using a combination of the RetinaNet, ResNet, and U-Net models. The algorithm for a unified model architecture with an attention mechanism for crack detection, classification, and segmentation is presented in Table 3. This integration ensures that the tasks benefit from shared feature representations and joint optimization.
Table 3.
Step-by-Step Algorithm for the Unified Model Architecture with Attention Mechanism Integration.
- (a)
- Detection Branch: RetinaNet
For the detection branch, RetinaNet was employed, which is particularly effective for handling class imbalance, a common challenge in crack detection where small cracks may be underrepresented.
- Backbone: ResNet-50 is used as the backbone network within RetinaNet for feature extraction. This provides a deep representation of the input images, capturing both low-level and high-level features.
- Focal loss: RetinaNet uses focal loss to address the issue of class imbalance by down-weighting the loss assigned to well-classified examples. The focal loss is defined as Equation (10):where pt is the predicted probability for the correct class, αt is a balancing factor, and γ is a focusing parameter, typically set to 2.0.
- Anchor boxes: The model uses a predefined set of anchor boxes that are adapted to the typical sizes and aspect ratios of pavement cracks, ensuring that the detection network is well-tuned to identify cracks of varying shapes and sizes.
- (b)
- Classification Branch: ResNet
For the classification branch, ResNet-34 was used to categorize the detected cracks based on their type or severity.
- Feature extraction: ResNet-34, a variant with fewer layers than deeper models, is chosen for its balance between computational efficiency and feature extraction capability. The network extracts hierarchical features from the input images, which are then used to classify the cracks into different categories.
- Cross-entropy loss: The classification branch employs cross-entropy loss, which is effective for multi-class classification tasks and represented as Equation (11):where C is the number of classes, yc is the true label, and y^c is the predicted probability for class c.
- (c)
- Segmentation Branch: U-Net
For the segmentation branch, U-Net architecture was utilized, which is well-suited for pixel-level classification tasks and has proven effective in medical image segmentation and other applications requiring precise delineation of boundaries.
- Encoder–decoder structure: U-Net’s encoder–decoder structure allows for capturing context on multiple scales, making it ideal for segmenting cracks of various sizes and shapes. The encoder is based on a modified ResNet architecture, while the decoder up-samples the features to match the input resolution.
- Skip connections: U-Net employs skip connections that directly connect corresponding layers in the encoder and decoder, preserving spatial information that is crucial for accurate segmentation.
- Dice loss: The segmentation branch uses Dice loss, which is particularly effective for imbalanced segmentation tasks where the target (cracks) occupies only a small portion of the image, represented as Equation (12):where P represents the predicted segmentation, and G represents the ground truth segmentation.
- (d)
- Joint Optimization
The unified model is trained using a joint optimization strategy, where all three branches—detection, classification, and segmentation—are optimized simultaneously. This is achieved by combining their respective loss functions into a single objective, represented as Equation (13):
Here, λ1, λ2, and λ3 are hyperparameters that balance the contributions of each task. This approach ensures that the model learns to perform all tasks effectively, benefiting from shared features and improving overall performance in crack detection, classification, and segmentation.
4. Results
4.1. Experimental Setup
This section outlines the setup used for evaluating the proposed methodology, including the training environment, the selection of hyperparameters, and the evaluation metrics utilized to measure the model’s performance across different tasks.
- Training environment: The training process for the model was conducted in a high-performance computing environment tailored to handle the computational intensity of deep learning tasks. The hardware and software setup used is detailed in Table 4.
Table 4. Hardware and Software Setup.
- Hyperparameters: The model’s hyperparameters were selected based on prior research and iterative experimentation. These hyperparameters were fine-tuned to optimize the model’s performance while ensuring stability during training. The key hyperparameters used are presented in Table 5.
Table 5. Tuned Hyperparameters.
These hyperparameters were chosen to balance the trade-offs between training speed, model accuracy, and the ability to generalize unseen data.
- Evaluation metrics: To comprehensively evaluate the performance of the model across detection, classification, and segmentation tasks, the following metrics were employed, as shown in Table 6.
Table 6. Evaluation Metrics for Each Task.
4.2. Detection Performance
The detection task aims to accurately identify and localize cracks within pavement images. Table 7 summarizes the performance metrics for the detection task across three types of cracks: alligator, longitudinal, and transverse.
Table 7.
Detection Performance Metrics.
Analysis:
- Precision and recall: The model achieved high precision and recall scores across all crack types, indicating its effectiveness in correctly identifying and localizing cracks with minimal false positives and false negatives.
- F1-score: The F1-scores, which balance precision and recall, were consistently strong across all crack types, confirming the robustness of the detection process.
- IoU and mAP: The Intersection over Union (IoU) and mean average precision (mAP) metrics further demonstrate the model’s ability to accurately delineate crack boundaries, with longitudinal cracks showing the best overall performance.
4.3. Classification Performance
The classification task involves categorizing the detected cracks into specific types. Table 8 presents the classification accuracy and related metrics for each crack type.
Table 8.
Classification Accuracy Metrics.
Analysis:
- Classification accuracy: The model demonstrated high accuracy across all crack types, with the highest performance observed for longitudinal cracks. This indicates the model’s strong ability to distinguish between different types of cracks.
- Precision and recall: The close alignment of precision and recall metrics across all crack types suggests that the model is consistent in correctly identifying and categorizing cracks without overfitting to any particular class.
- F1-Score: The F1-scores confirm that the model maintains a good balance between precision and recall, ensuring reliable classification performance.
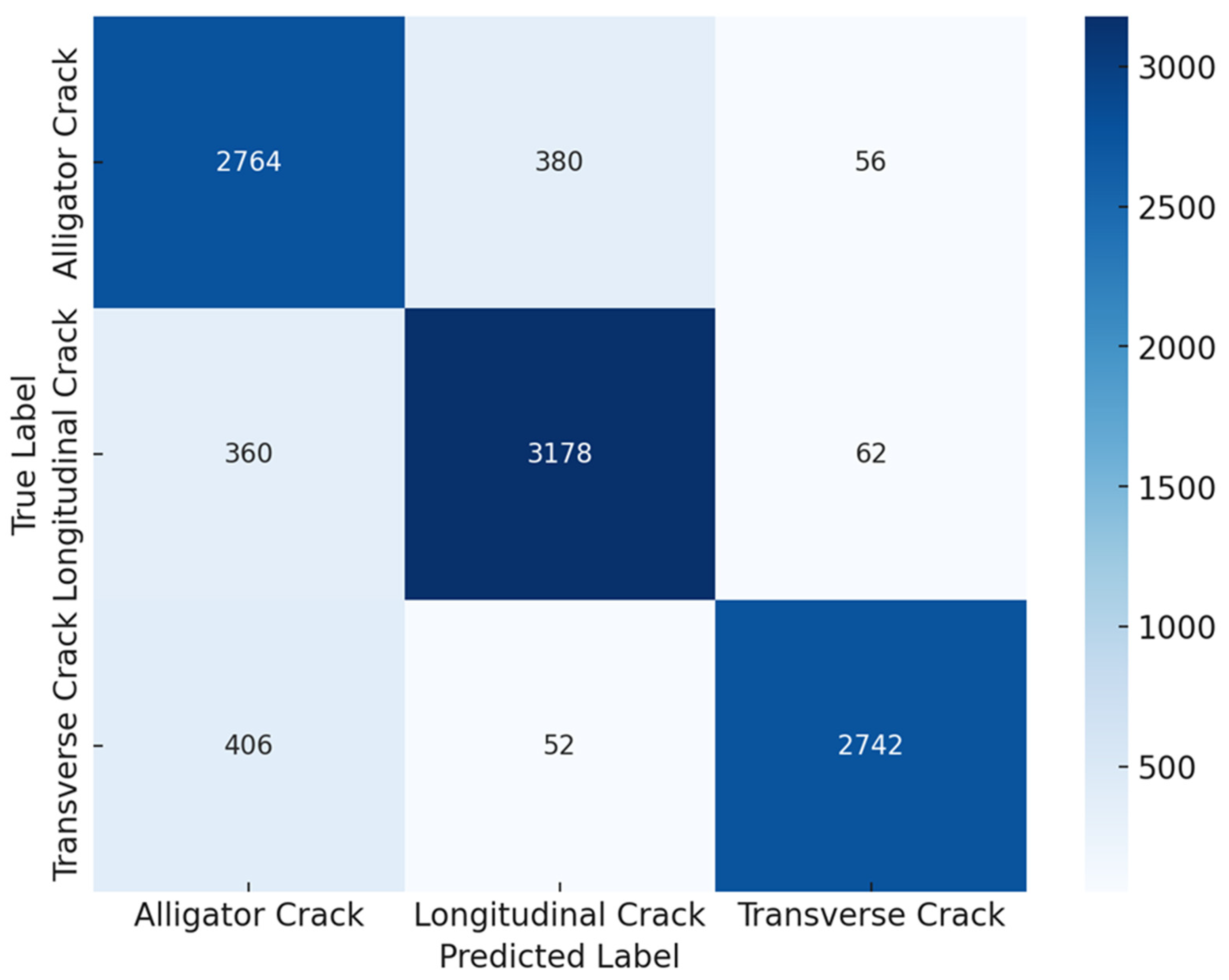
The confusion matrix presented in Figure 4 provides a detailed overview of the model’s classification performance for the three crack types: alligator, longitudinal, and transverse cracks.
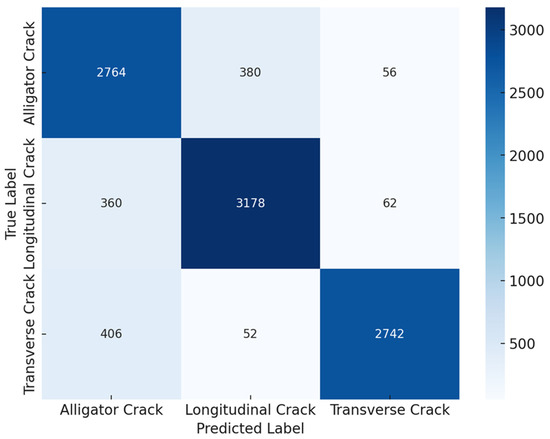
Figure 4.
Confusion Matrix Analysis for Crack Classification before Transformer-Based Attention.
The model’s performance across different crack types showed varying levels of accuracy and misclassification. For alligator cracks, the model correctly classified 2764 instances, but 380 were misclassified as longitudinal cracks and 56 as transverse cracks. This indicates some confusion, likely due to visual similarities between these crack types. For longitudinal cracks, out of 3600 samples, 3178 were correctly identified, while 360 were misclassified as alligator cracks and 62 as transverse cracks. Although the model generally performed well, the overlap in features between longitudinal and other crack types led to these misclassifications. In the case of transverse cracks, the model correctly classified 2742 instances, with 406 misclassified as alligator cracks and 52 as longitudinal cracks.
4.4. Segmentation Performance
The segmentation task focuses on delineating the exact boundaries of cracks within the detected regions. The performance of the segmentation task is evaluated using Dice Coefficient and IoU metrics, as summarized in Table 9.
Table 9.
Segmentation Performance Metrics.
Analysis:
- Dice Coefficient and IoU: The model’s ability to accurately segment cracks is reflected in the Dice Coefficient and IoU metrics, which measure the overlap between the predicted and actual crack boundaries. Longitudinal cracks achieved the highest segmentation accuracy, while transverse cracks, with more irregular shapes, were more challenging to segment.
- Pixel accuracy: The pixel accuracy values indicate that the model correctly classified the majority of pixels in the images, further confirming its effectiveness in crack segmentation.
- Precision and recall: The segmentation precision and recall metrics highlight the model’s capability to not only identify the correct pixels but also ensure that most of the relevant pixels are captured, minimizing false negatives.
4.5. Comparison of Model Performance before and after Transformer-Based Attention Mechanisms
To evaluate the impact of transformer-based attention mechanisms, the model’s performance was compared before and after their integration. The results are shown in Table 10.
Table 10.
Comparison of Model Performance Before and After Transformer-Based Attention Mechanisms.
Analysis:
- Impact on detection: The integration of attention mechanisms significantly enhanced detection precision and recall, resulting in a more accurate localization of cracks. The IoU improvements further indicate a more precise alignment of detected crack regions with ground truth data.
- Classification gains: The classification metrics saw substantial gains, particularly in recall and F1-score, highlighting the model’s improved ability to differentiate between crack types after applying attention mechanisms.
- Segmentation enhancement: The most notable improvements were observed in the segmentation task, where the IoU and Dice Coefficient metrics showed dramatic increases. This suggests that attention mechanisms allowed the model to better focus on the critical areas of the image, resulting in more accurate crack boundary delineation.
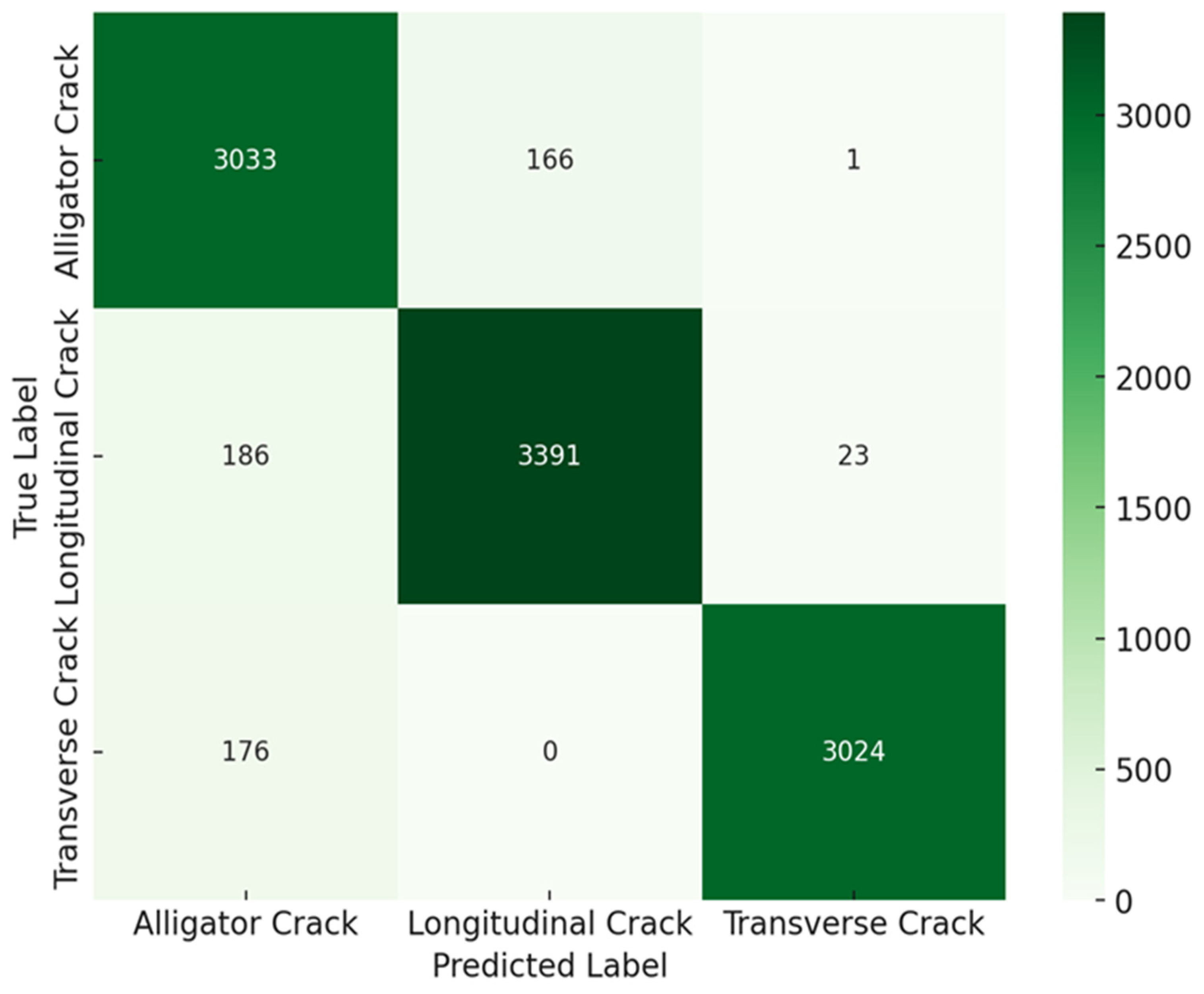
After applying transformer-based attention mechanisms, the model showed significant improvements in classifying all crack types, as shown in Figure 5. For alligator cracks, the model correctly classified 3033 instances, with 166 misclassified as longitudinal cracks and just 1 as a transverse cracks, indicating a marked reduction in misclassifications and highlighting the enhanced ability to differentiate between visually similar crack types. In the case of longitudinal cracks, out of 3600 samples, 3391 were accurately identified, with 186 misclassified as alligator cracks and 23 as transverse cracks. This improvement suggests that the model now better discriminates longitudinal cracks from other types, reducing overlap in features. For transverse cracks, the model correctly classified 3024 instances, with 176 misclassified as alligator cracks and none as longitudinal cracks. The reduced confusion between transverse and other crack types reflects the model’s increased accuracy in handling complex scenarios, further validating the effectiveness of transformer-based attention mechanisms in improving classification performance.
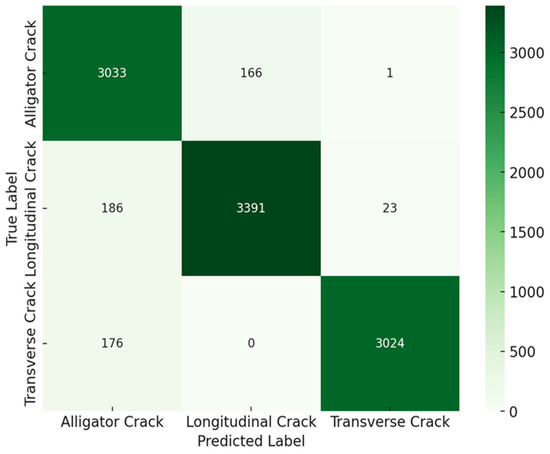
Figure 5.
Confusion matrix analysis for crack classification after transformer-based attention.
4.6. Time Efficiency Metrics
To assess the computational impact of adding transformer-based attention mechanisms, the time efficiency of the model was evaluated before and after their integration, as presented in Table 11.
Table 11.
Time Efficiency Metrics.
Analysis:
- Inference time increase: The addition of attention mechanisms resulted in a modest increase in inference time, which is expected due to the increased computational complexity.
- Efficiency trade-offs: While there is a slight increase in processing time, the significant improvements in detection, classification, and segmentation accuracy make this trade-off worthwhile, especially in applications where precision is critical.
4.7. Overall Model Performance Summary
Table 12 provides a summary of the overall model performance, combining the key metrics for detection, classification, and segmentation after the integration of attention mechanisms. Also, Figure 6 presents a visual representation of the model’s output, progressing from the original image to the final processed result.
Table 12.
Overall Model Performance Summary.

Figure 6.
Visual representation of the model’s output, showing the detection, classification, and segmentation of pavement cracks.
5. Conclusions
This study highlighted the significant impact of integrating advanced deep learning techniques, particularly multi-scale feature aggregation and transformer-based attention mechanisms, on the detection, classification, and segmentation of pavement cracks. The quantitative results demonstrated that after applying transformer-based attention, the model achieved a precision of 94.8% and a recall of 94.2% for crack classification, a significant improvement over the pre-transformer performance, where precision and recall were 88.3% and 86.8%, respectively. The segmentation task also benefited, with the Dice Coefficient increasing from 80.3% to 94.7%, reflecting the model’s enhanced capability to accurately delineate crack boundaries. These findings confirm the model’s robustness and reliability, making it a valuable tool for automated pavement maintenance, capable of delivering high-precision results even in complex scenarios.
The contributions of this research to the field of pavement maintenance for both structural and functional performance are substantial [31,32], providing a framework that significantly improves the accuracy and efficiency of crack analysis. The model’s enhanced performance not only facilitates more accurate infrastructure monitoring but also paves the way for further advancements. Future work could focus on optimizing the model’s architecture to reduce computational costs, improving real-time processing capabilities, or expanding the dataset to include more diverse pavement conditions and environmental factors. These efforts would further refine the model’s performance, making automated crack detection and classification an even more integral part of modern infrastructure management systems [33,34].
Author Contributions
Conceptualization, A.A. and A.S.; methodology, A.A. and A.A.B.; software, A.A.; validation, A.A., A.S. and A.A.B.; formal analysis, A.S. and A.A.B.; investigation, A.A.; resources, A.S. and A.A.B.; data curation, A.A.; writing—original draft preparation, A.A.; writing—review and editing, A.A., A.S. and A.A.B.; visualization, A.A.; supervision, A.A.B. and A.S.; project administration, A.A.B. and A.S.; funding acquisition, A.A.B. All authors have read and agreed to the published version of the manuscript.
Funding
The authors sincerely thank the Kulliyyah of Engineering at the International Islamic University Malaysia for granting the IIUM Engineering Merit Scholarship to the first author- Arselan Ashraf and for fostering a supportive and conducive environment for their research endeavors. The Authors would like to extend sincere thanks to Technical University of Munich. The authors would also like to extend their appreciation to the Malaysian Ministry of Higher Education (MOHE) for their support provided through the Fundamental Research Grant Scheme (FRGS), under the project FRGS/1/2021/TK02IUIAM/02/4.
Data Availability Statement
The RCD-IIUM dataset, developed and utilized in this research, is publicly available on GitHub for researchers and professionals in road maintenance and infrastructure management. Proper citation of the relevant publications is required when using this dataset. The dataset can be accessed at the following GitHub link: https://github.com/ArselanAshraf/RCD-IIUM-Road-Crack-Detection-Dataset-.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Ashraf, A.; Sophian, A.; Shafie, A.A.; Gunawan, T.S.; Ismail, N.N.; Bawono, A.A. Efficient Pavement Crack Detection and Classification Using Custom YOLOv7 Model. Indones. J. Electr. Eng. Inform. 2023, 11, 119–132. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, B.; Wang, J.; Li, J.; Sun, X. APLCNet: Automatic Pixel-Level Crack Detection Network Based on Instance Segmentation. IEEE Access 2020, 8, 199159–199170. [Google Scholar] [CrossRef]
- Mandal, V.; Uong, L.; Adu-Gyamfi, Y. Automated Road Crack Detection Using Deep Convolutional Neural Networks. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 5212–5215. [Google Scholar]
- Ashraf, A.; Sophian, A.; Shafie, A.A.; Gunawan, T.S.; Ismail, N.N. Machine Learning-Based Pavement Crack Detection, Classification, and Characterization: A Review. Bull. Electr. Eng. Inform. 2023, 12, 3601–3619. [Google Scholar] [CrossRef]
- Hassan, S.A.; Han, S.H.; Shin, S.Y. Real-Time Road Cracks Detection Based on Improved Deep Convolutional Neural Network. In Proceedings of the 2020 IEEE Canadian Conference on Electrical and Computer Engineering (CCECE), London, ON, Canada, 30 August–2 September 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–4. [Google Scholar]
- Jing, P.; Yu, H.; Hua, Z.; Xie, S.; Song, C. Road Crack Detection Using Deep Neural Network Based on Attention Mechanism and Residual Structure. IEEE Access 2023, 11, 919–929. [Google Scholar] [CrossRef]
- Liu, H.; Yang, C.; Li, A.; Huang, S.; Feng, X.; Ruan, Z.; Ge, Y. Deep Domain Adaptation for Pavement Crack Detection. IEEE Trans. Intell. Transp. Syst. 2022, 24, 1669–1681. [Google Scholar] [CrossRef]
- Ashraf, A.; Sophian, A.; Shafie, A.A.; Gunawan, T.S.; Ismail, N.N.; Bawono, A.A. Detection of Road Cracks Using Convolutional Neural Networks and Threshold Segmentation. J. Integr. Adv. Eng. 2022, 2, 123–134. [Google Scholar] [CrossRef]
- Gehri, N.; Mata-Falcón, J.; Kaufmann, W. Automated Crack Detection and Measurement Based on Digital Image Correlation. Constr. Build. Mater. 2020, 256, 119383. [Google Scholar] [CrossRef]
- Lins, R.G.; Givigi, S.N. Automatic Crack Detection and Measurement Based on Image Analysis. IEEE Trans. Instrum. Meas. 2016, 65, 583–590. [Google Scholar] [CrossRef]
- Fan, Z.; Wu, Y.; Lu, J.; Li, W. Automatic Pavement Crack Detection Based on Structured Prediction with the Convolutional Neural Network. arXiv 2018, arXiv:1802.02208. [Google Scholar]
- Dung, C.V.; Anh, L.D. Autonomous Concrete Crack Detection Using Deep Fully Convolutional Neural Network. Autom. Constr. 2019, 99, 52–58. [Google Scholar] [CrossRef]
- THE LENS. Available online: https://www.lens.org/ (accessed on 8 September 2024).
- Naik, S.K.; Murthy, C.A. Hue-Preserving Color Image Enhancement without Gamut Problem. IEEE Trans. Image Process. 2003, 12, 1591–1598. [Google Scholar] [CrossRef] [PubMed]
- Boubenna, H.; Lee, D. Image-Based Emotion Recognition Using Evolutionary Algorithms. Biol. Inspired Cogn. Archit. 2018, 24, 70–76. [Google Scholar] [CrossRef]
- Zhou, D.; Dong, W.; Shen, X. Image Zooming Using Directional Cubic Convolution Interpolation. IET Image Process. 2012, 6, 627–634. [Google Scholar] [CrossRef]
- Yang, X.; Li, H.; Yu, Y.; Luo, X.; Huang, T.; Yang, X. Automatic Pixel-Level Crack Detection and Measurement Using Fully Convolutional Network. Comput. Aided Civ. Infrastruct. Eng. 2018, 33, 1090–1109. [Google Scholar] [CrossRef]
- Zou, Q.; Zhang, Z.; Li, Q.; Qi, X.; Wang, Q.; Wang, S. DeepCrack: Learning Hierarchical Convolutional Features for Crack Detection. IEEE Trans. Image Process. 2019, 28, 1498–1512. [Google Scholar] [CrossRef]
- Jo, Y.; Ryu, S. Pothole Detection System Using a Black-Box Camera. Sensors 2015, 15, 29316–29331. [Google Scholar] [CrossRef]
- Decker, D.S. Best Practices for Crack Treatments in Asphalt Pavements. In Proceedings of the 6th Eurasphalt & Eurobitume Congress, Prague, Czech Republic, 1–3 June 2016; Czech Technical University in Prague: Prague, Czech Republic, 2016. [Google Scholar]
- Ayenu-Prah, A.; Attoh-Okine, N. Evaluating Pavement Cracks with Bidimensional Empirical Mode Decomposition. EURASIP J. Adv. Signal Process. 2008, 2008, 861701. [Google Scholar] [CrossRef]
- Zhang, L.; Yang, F.; Zhang, Y.D.; Zhu, Y.J. Road Crack Detection Using Deep Convolutional Neural Network. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 3708–3712. [Google Scholar]
- Maeda, H.; Sekimoto, Y.; Seto, T.; Kashiyama, T.; Omata, H. Road Damage Detection Using Deep Neural Networks with Images Captured Through a Smartphone. arXiv 2018, arXiv:1801.09454. [Google Scholar] [CrossRef]
- Chen, H.; Su, Y.; He, W. Automatic Crack Segmentation Using Deep High-Resolution Representation Learning. Appl. Opt. 2021, 60, 6080. [Google Scholar] [CrossRef]
- Feng, X.; Xiao, L.; Li, W.; Pei, L.; Sun, Z.; Ma, Z.; Shen, H.; Ju, H. Pavement Crack Detection and Segmentation Method Based on Improved Deep Learning Fusion Model. Math. Probl. Eng. 2020, 2020, 1–22. [Google Scholar] [CrossRef]
- Yang, F.; Zhang, L.; Yu, S.; Prokhorov, D.; Mei, X.; Ling, H. Feature Pyramid and Hierarchical Boosting Network for Pavement Crack Detection. IEEE Trans. Intell. Transp. Syst. 2020, 21, 1525–1535. [Google Scholar] [CrossRef]
- Wang, X.; Zhaozheng, H.; Li, N.; Qin, L. Pavement Crack Analysis by Referring to Historical Crack Data Based on Multi-Scale Localization. PLoS ONE 2020, 15, e0235171. [Google Scholar] [CrossRef] [PubMed]
- Li, L.; Liu, R.; Ali, R.; Chen, B.; Lin, H.; Li, Y.; Zhang, H. DFP-Net: A Crack Segmentation Method Based on a Feature Pyramid Network. Appl. Sci. 2024, 14, 651. [Google Scholar] [CrossRef]
- Ranyal, E.; Sadhu, A.; Jain, K. Enhancing Pavement Health Assessment: An Attention-Based Approach for Accurate Crack Detection, Measurement, and Mapping. Expert Syst. Appl. 2024, 247, 123314. [Google Scholar] [CrossRef]
- Ashraf, A.; Sophian, A.; Akramin Shafie, A.; Surya Gunawan, T.; Ismail, N.N.; Aryo Bawono, A. RCD-IIUM: A Comprehensive Malaysian Road Crack Dataset for Infrastructure Analysis. In Proceedings of the 2024 9th International Conference on Mechatronics Engineering (ICOM), Kuala Lumpur, Malaysia, 13–14 August 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 200–206. [Google Scholar]
- Arya, D.; Maeda, H.; Ghosh, S.K.; Toshniwal, D.; Sekimoto, Y. RDD2020: An Annotated Image Dataset for Automatic Road Damage Detection Using Deep Learning. Data Brief 2021, 36, 107133. [Google Scholar] [CrossRef]
- Bawono, A.A. State of the Art: Functional Performance of Pavement. In Engineered Cementitious Composites for Electrified Roadway in Megacities: A Comprehensive Study on Functional Performance; Springer International Publishing: Berlin/Heidelberg, Germany, 2022; pp. 37–63. [Google Scholar]
- Rosso, M.M.; Aloisio, A.; Randazzo, V.; Tanzi, L.; Cirrincione, G.; Marano, G.C. Comparative deep learning studies for indirect tunnel monitoring with and without Fourier pre-processing. Integr. Comput.-Aided Eng. 2024, 31, 213–232. [Google Scholar] [CrossRef]
- Zhu, G.; Liu, J.; Fan, Z.; Yuan, D.; Ma, P.; Wang, M.; Sheng, W.; Wang, K.C. A lightweight encoder–decoder network for automatic pavement crack detection. Comput.-Aided Civ. Infrastruct. Eng. 2024, 39, 1743–1765. [Google Scholar] [CrossRef]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).