
Temporal Relationship between Daily Reports of COVID-19 Infections and Related GDELT and Tweet Mentions



Abstract
:1. Introduction
- Assess time-lagged relationships between new COVID-19 cases and the number of COVID-19-related GDELT articles and tweets in selected countries using cross-correlation analysis.
- Identify anomalies and their causes on days with abnormally high COVID-19-related responses on GDELT and Twitter but low numbers of new COVID-19 cases.
2. Literature Review
3. Materials and Methods
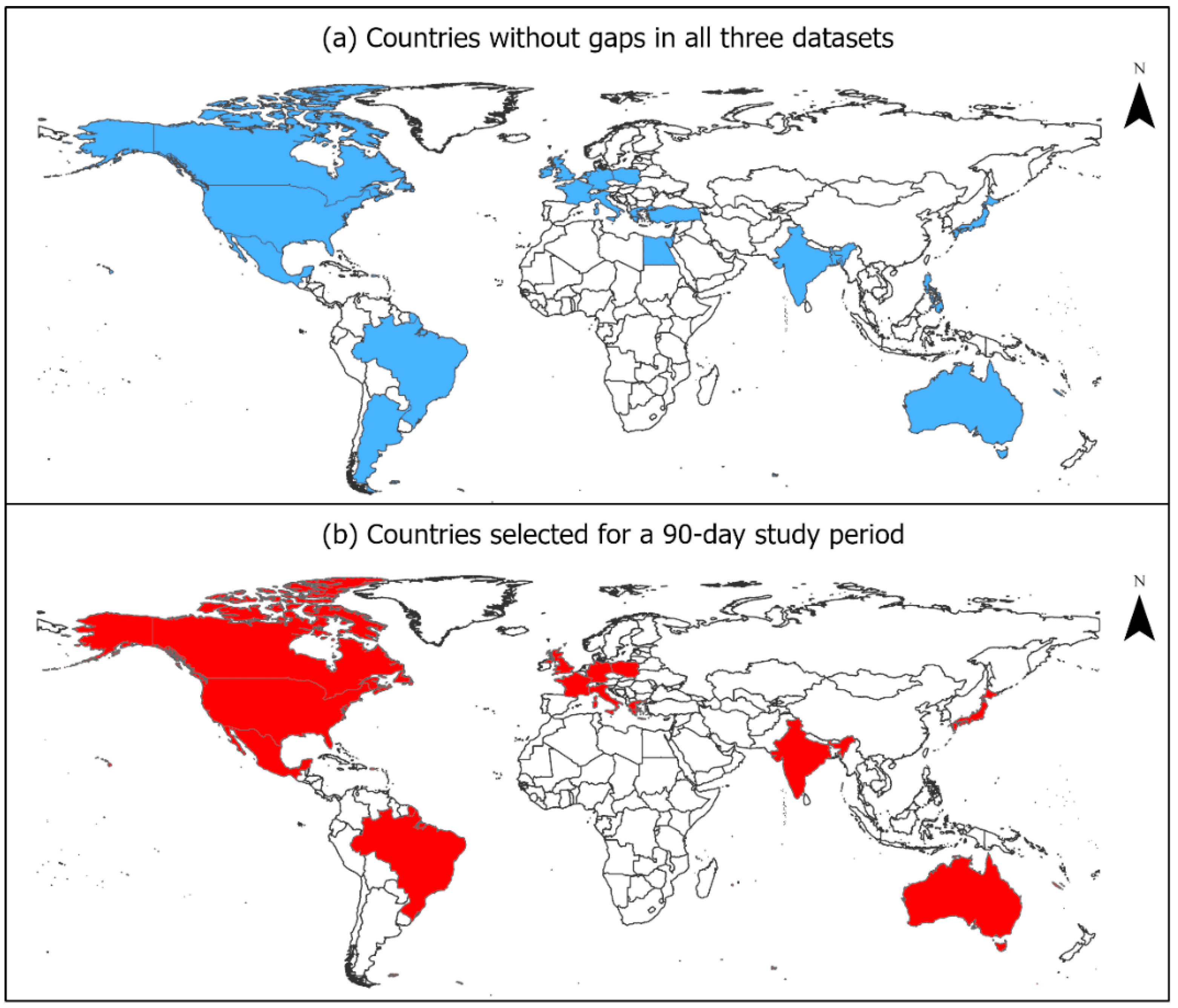
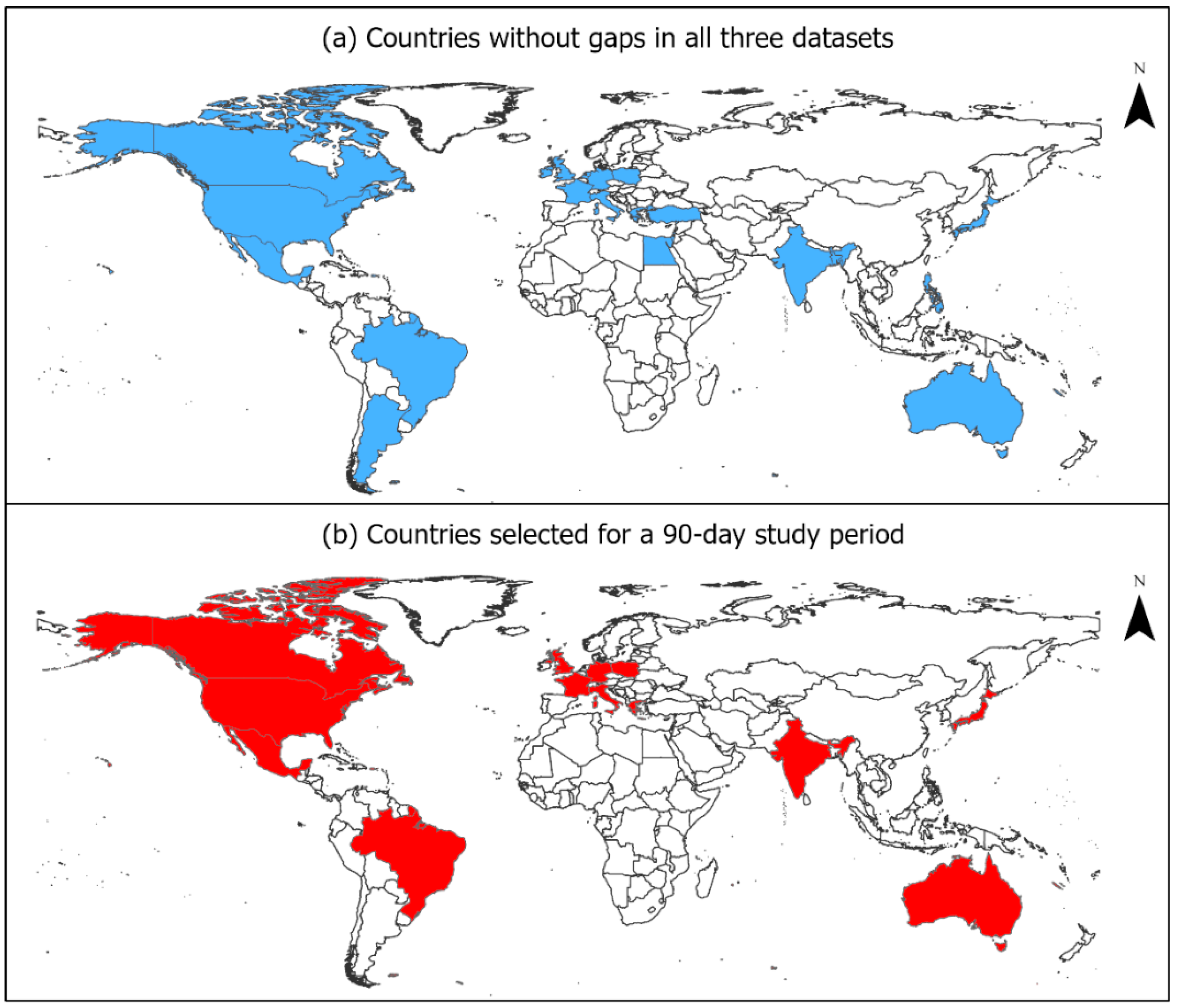
3.1. Data Sources
3.1.1. New Daily COVID-19 Infections
3.1.2. Twitter
3.1.3. GDELT
3.2. Data Preprocessing
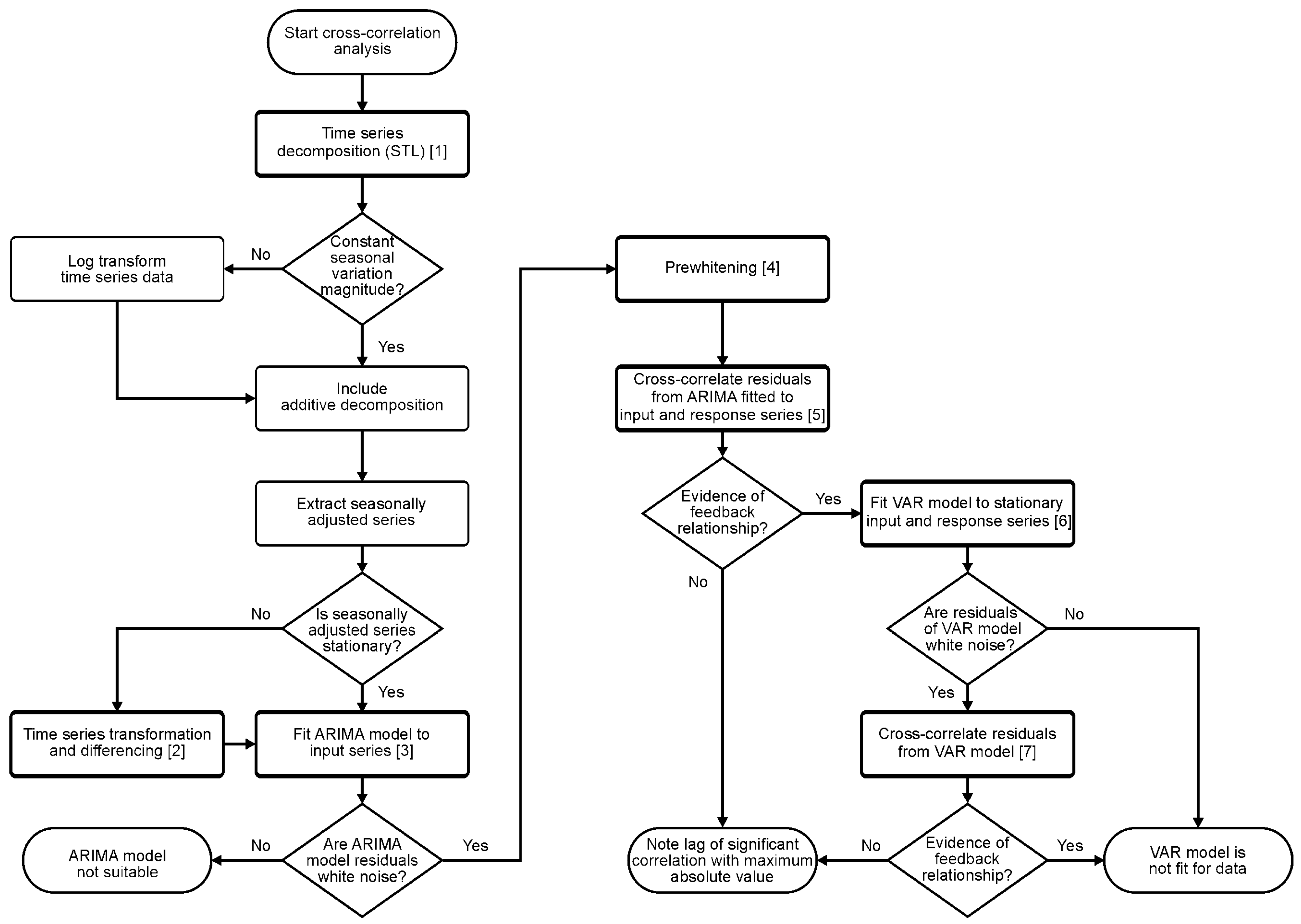
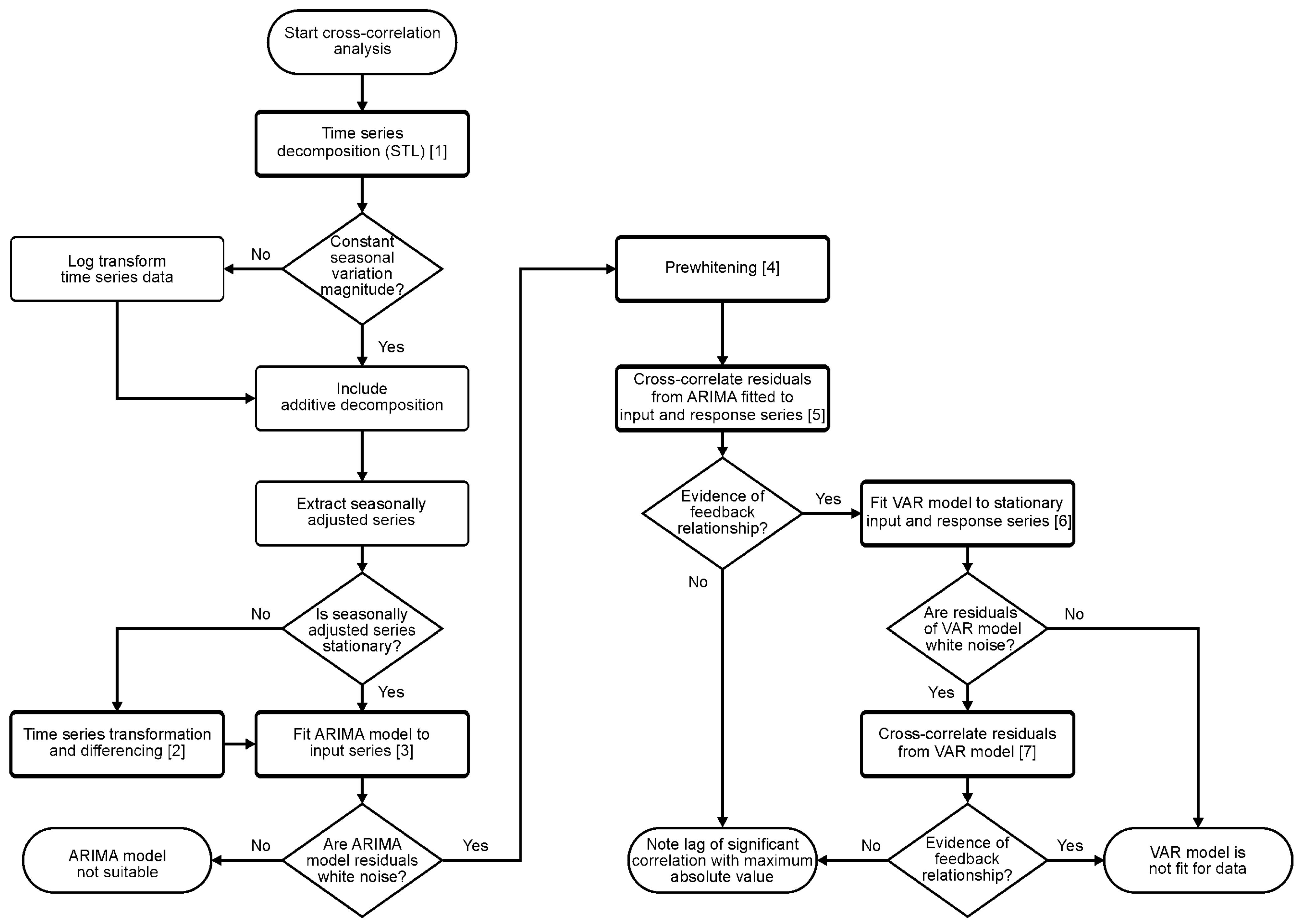
3.3. Cross-Correlation Analysis
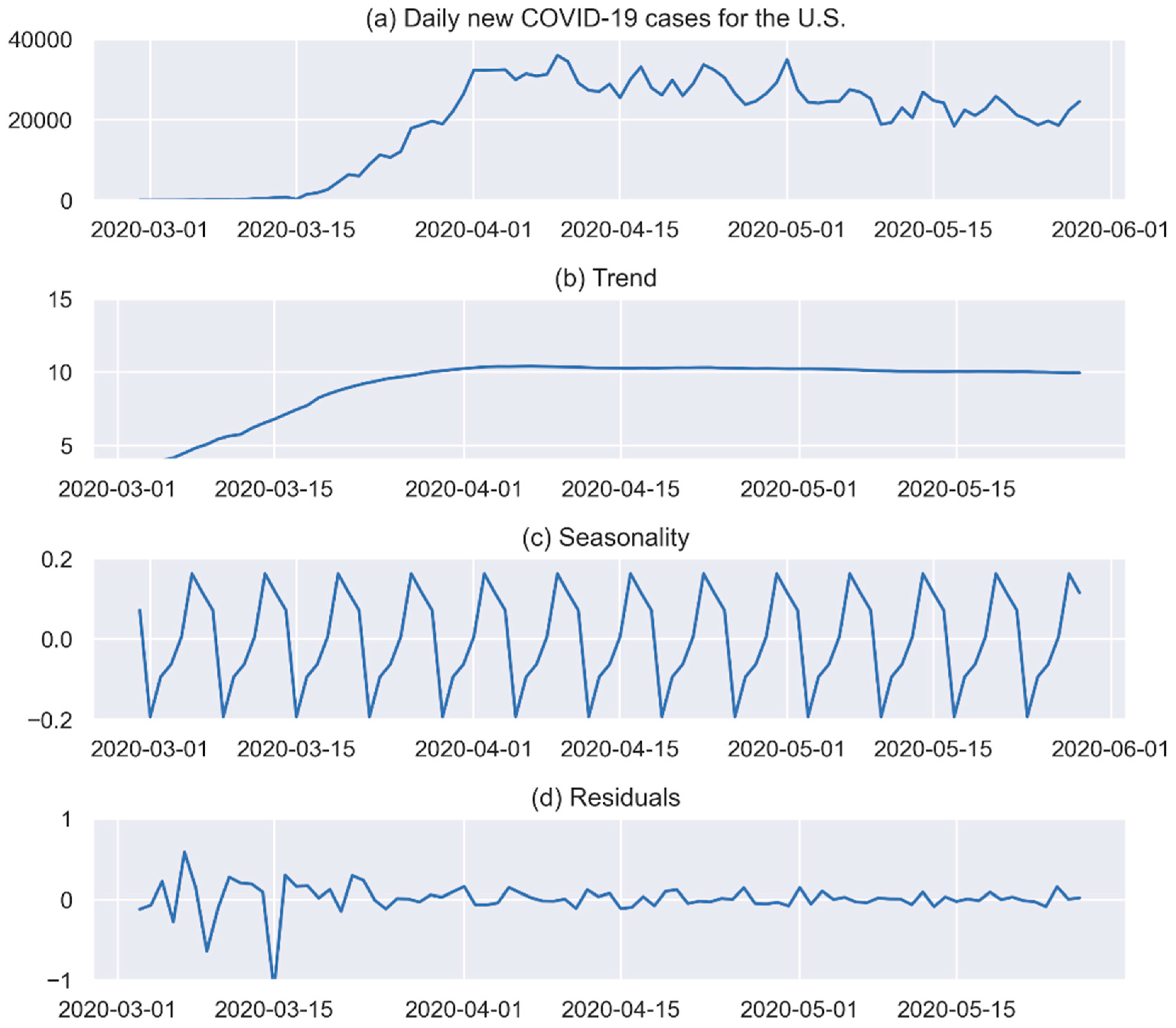
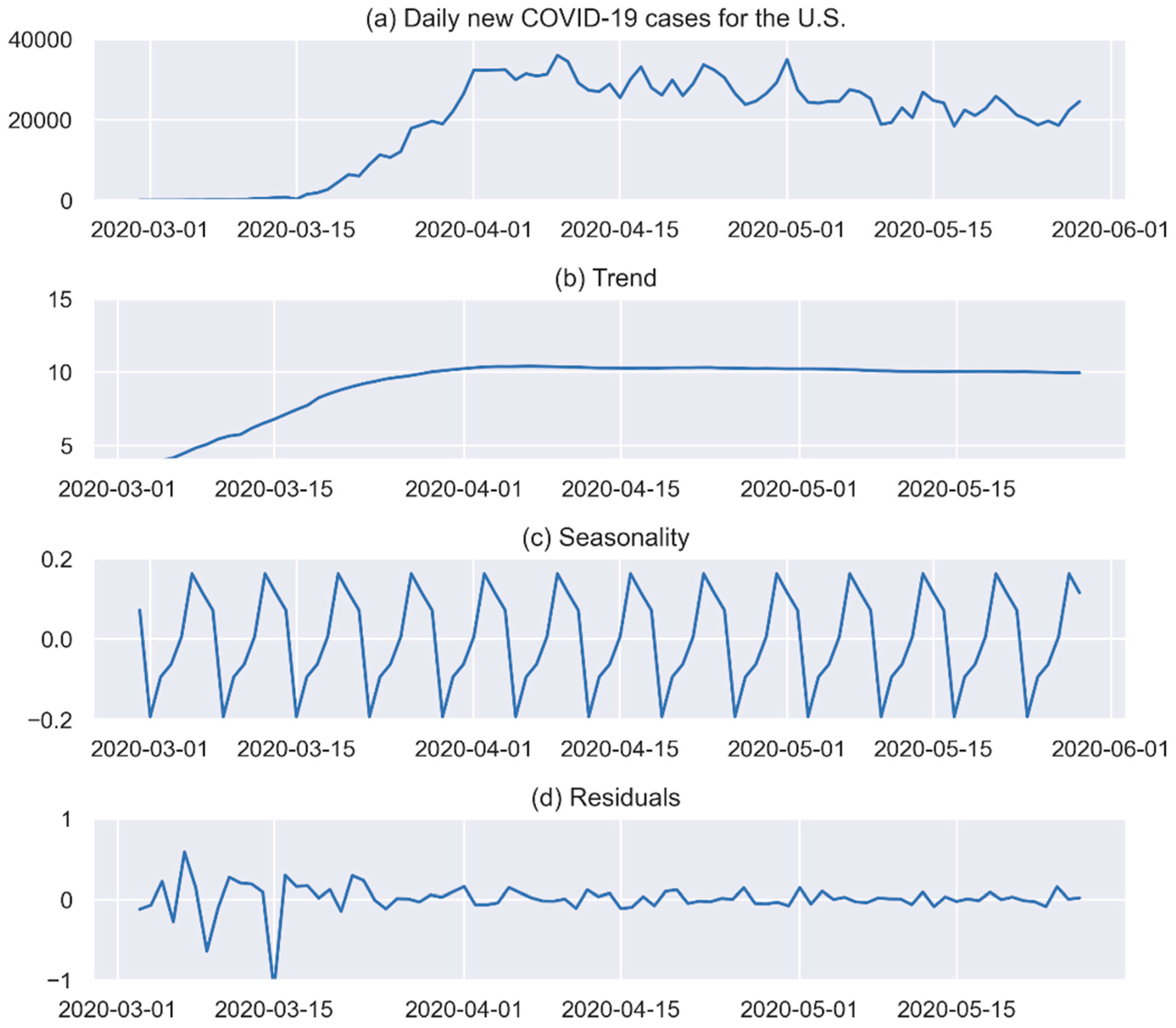
3.3.1. Step 1: Time Series Decomposition
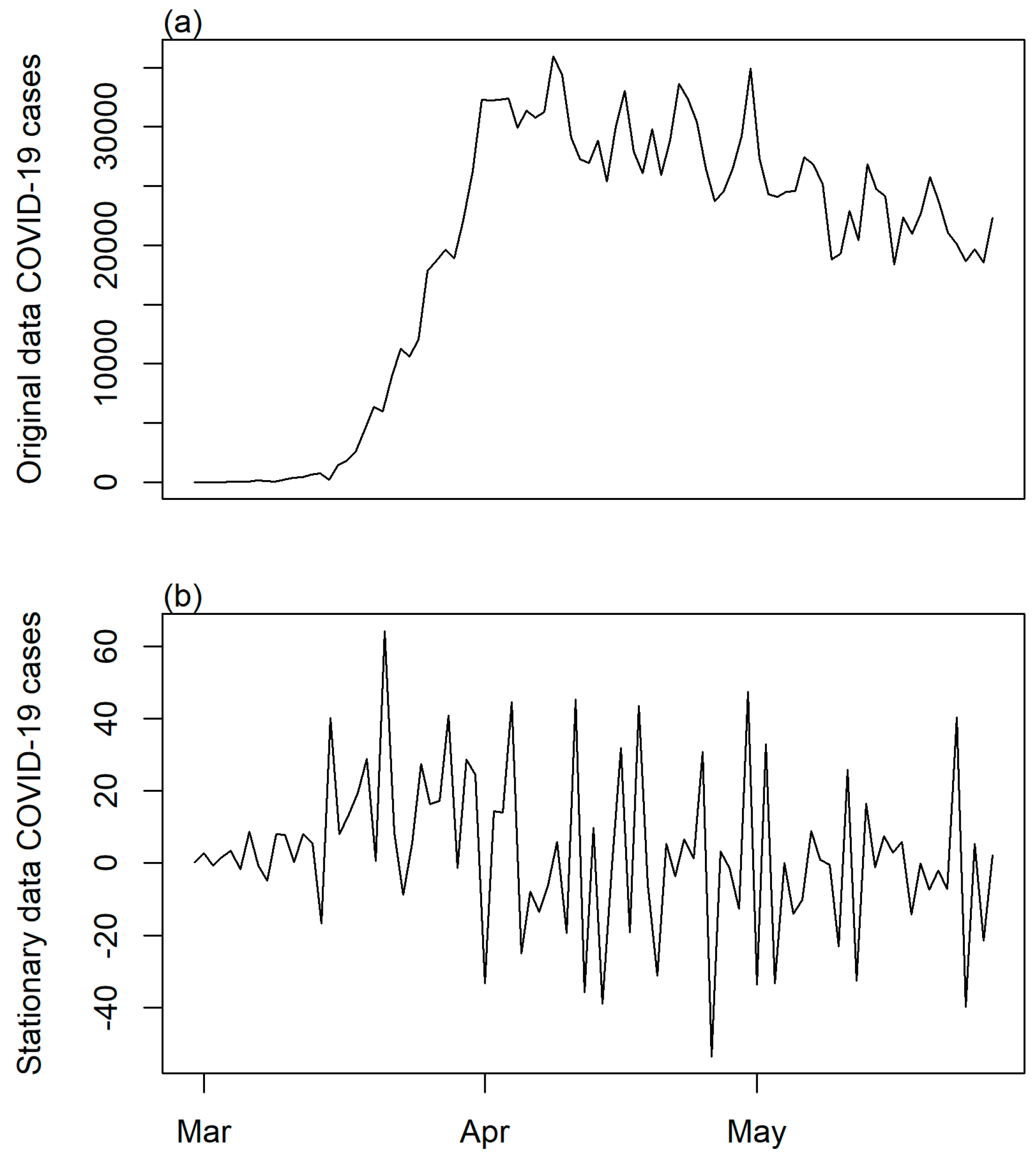
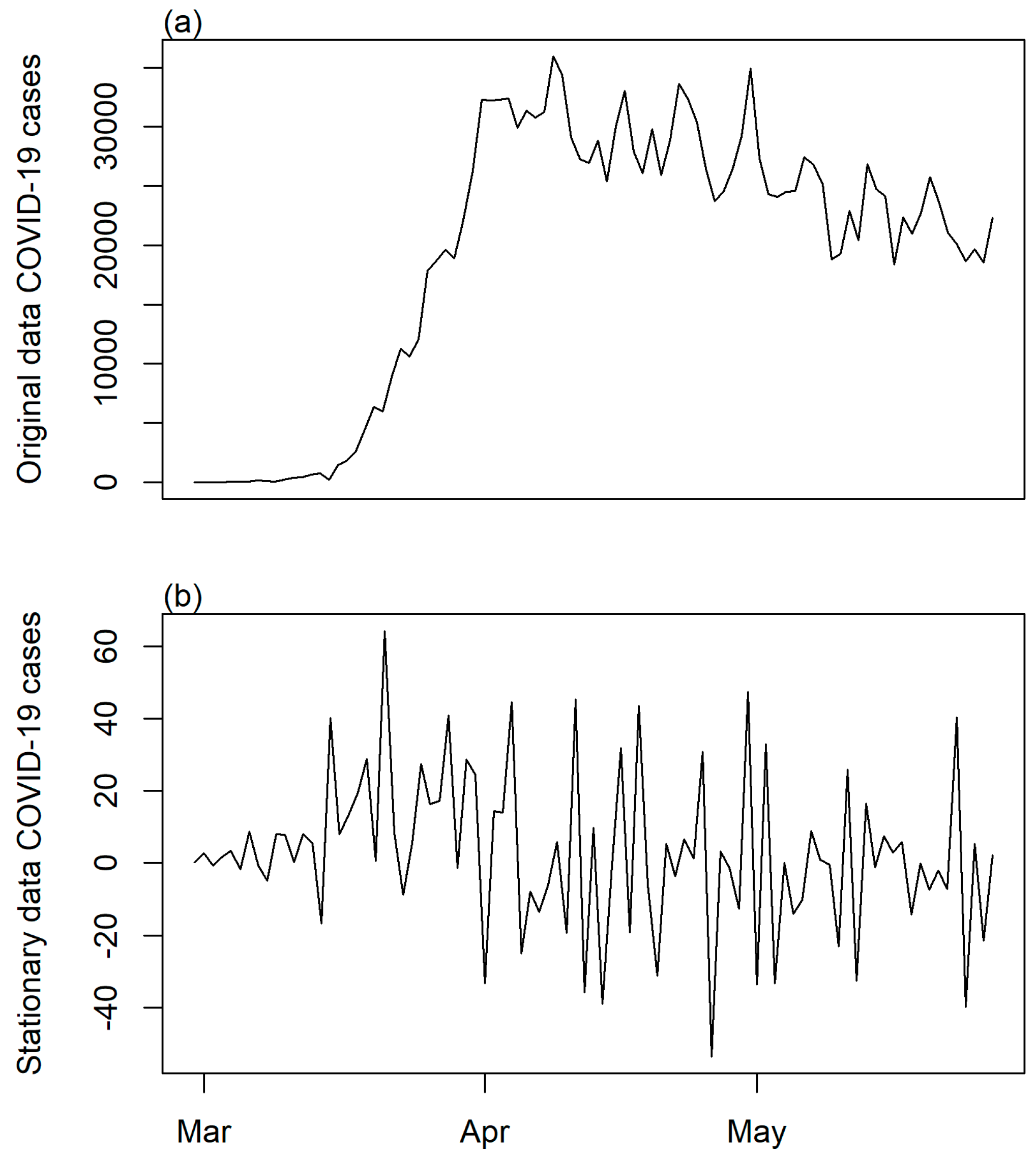
3.3.2. Step 2: Time Series Transformation and Differencing
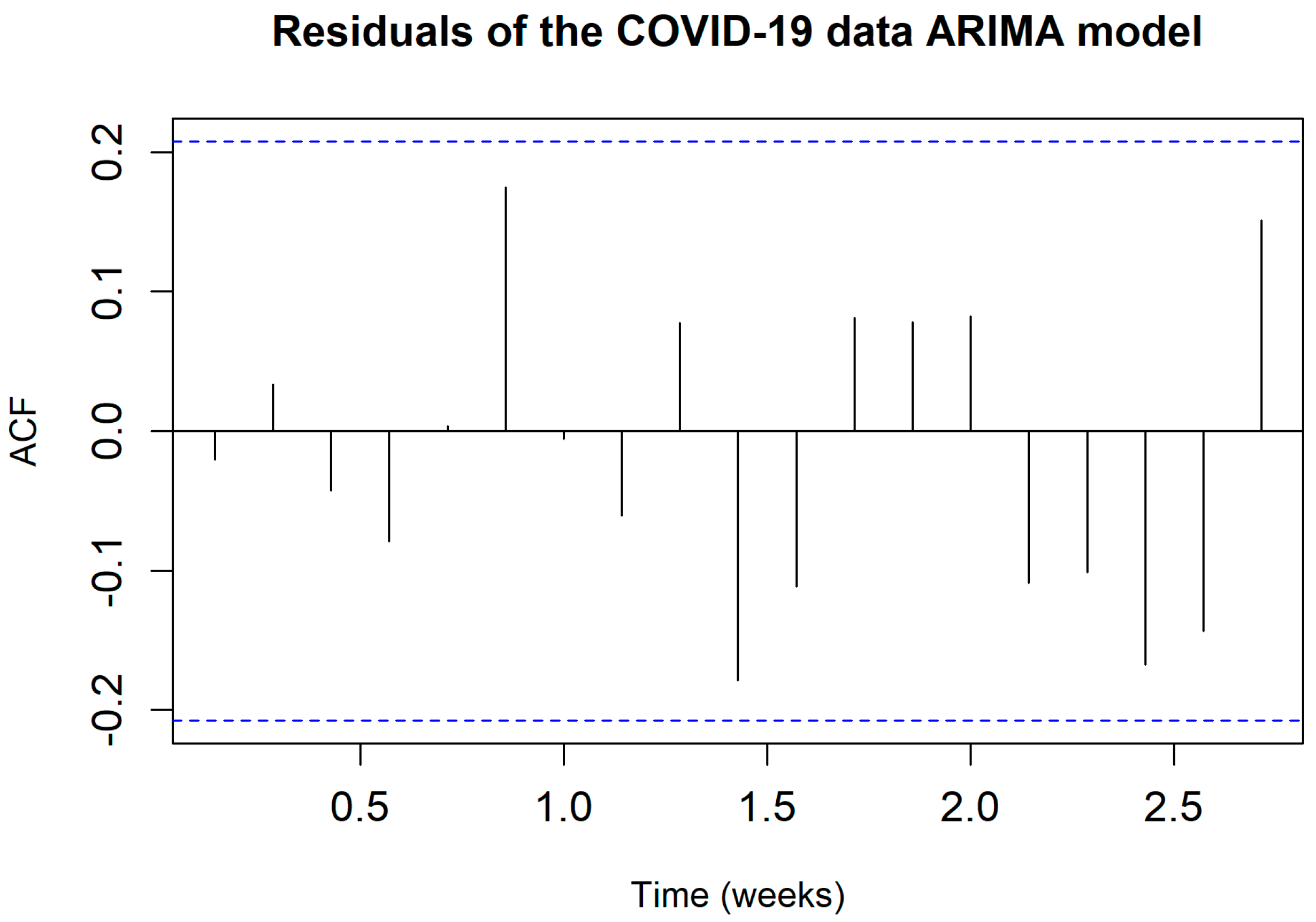
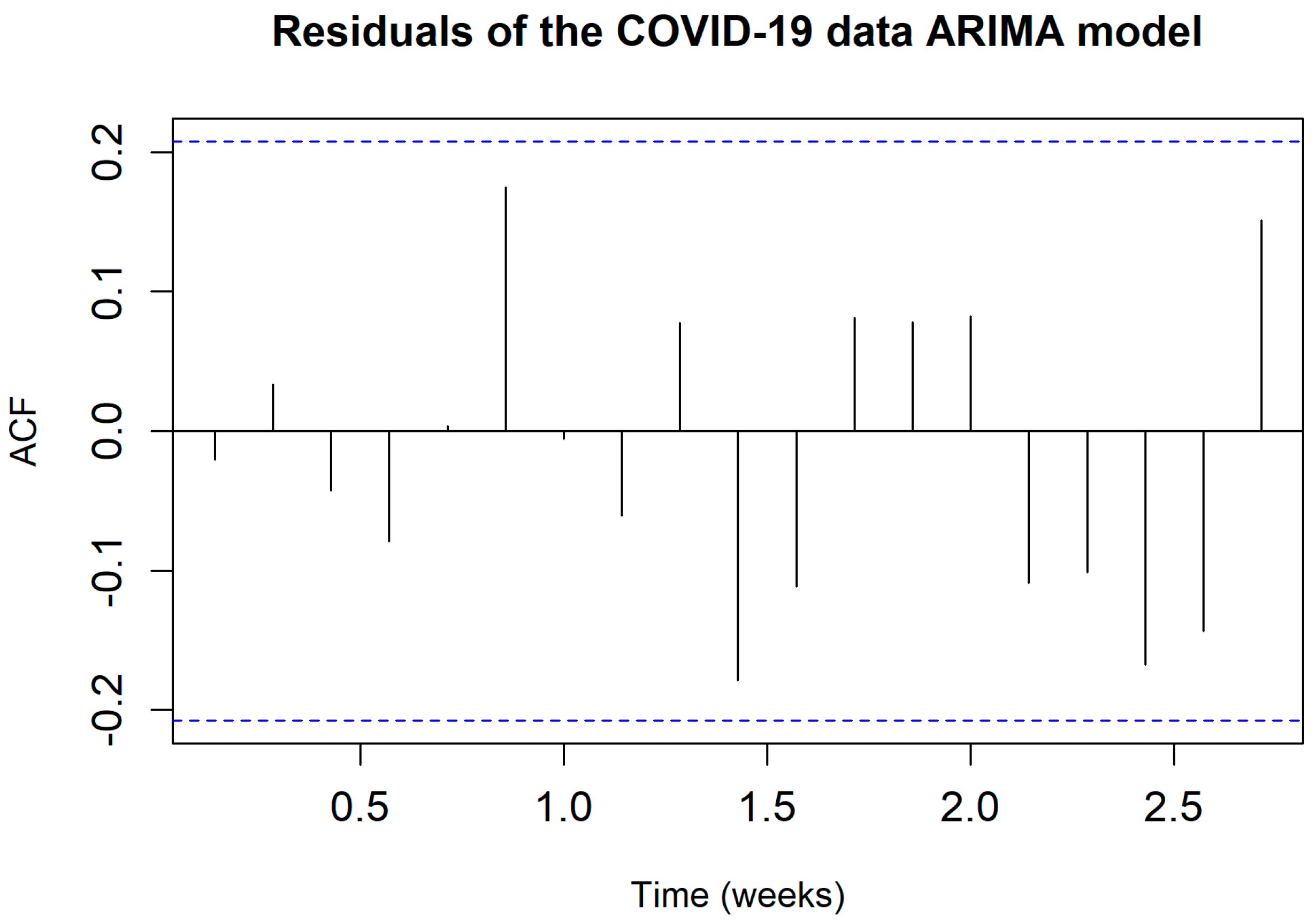
3.3.3. Step 3: Fitting an ARIMA Model to the Input Series
3.3.4. Steps 4 and 5: Prewhitening and Cross-Correlation of Residuals
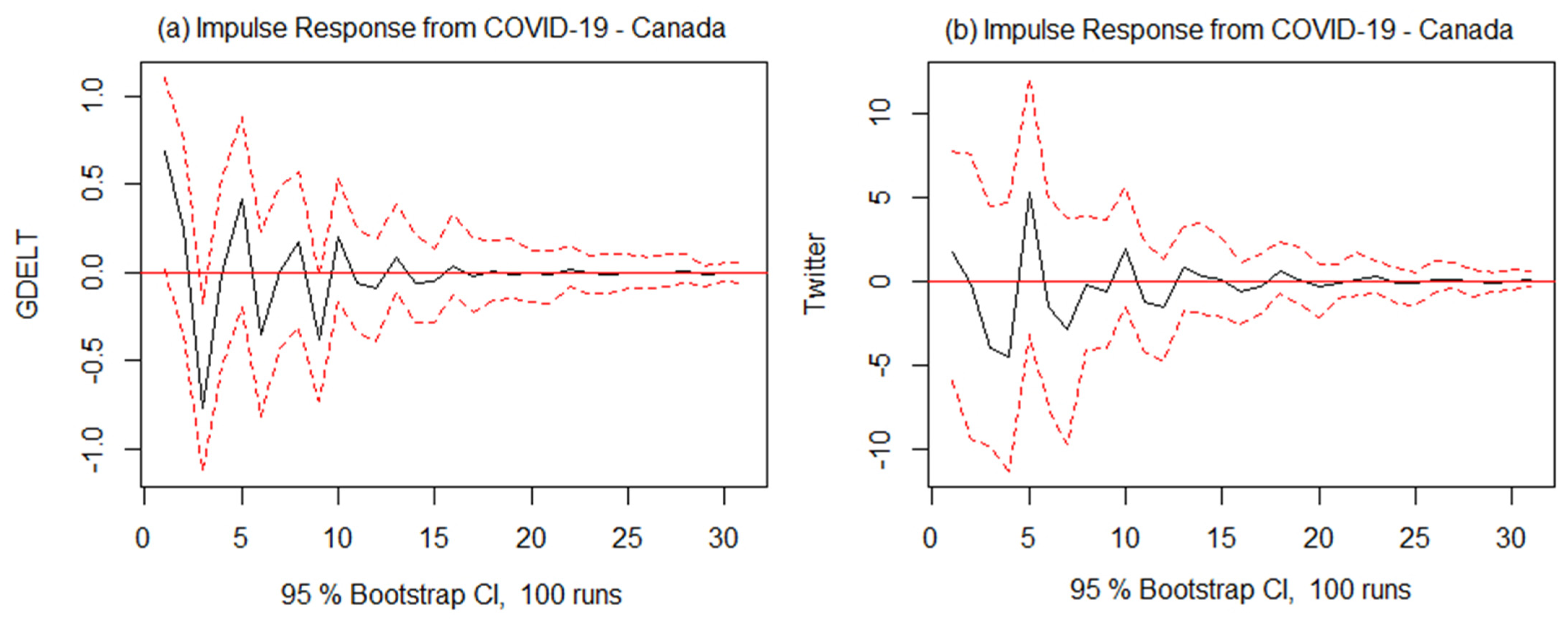
3.3.5. Steps 6 and 7: Vector Autoregressive Models and Cross-Correlation of Residuals
3.4. Anomaly Detection
3.5. Word Frequency Analysis
4. Results
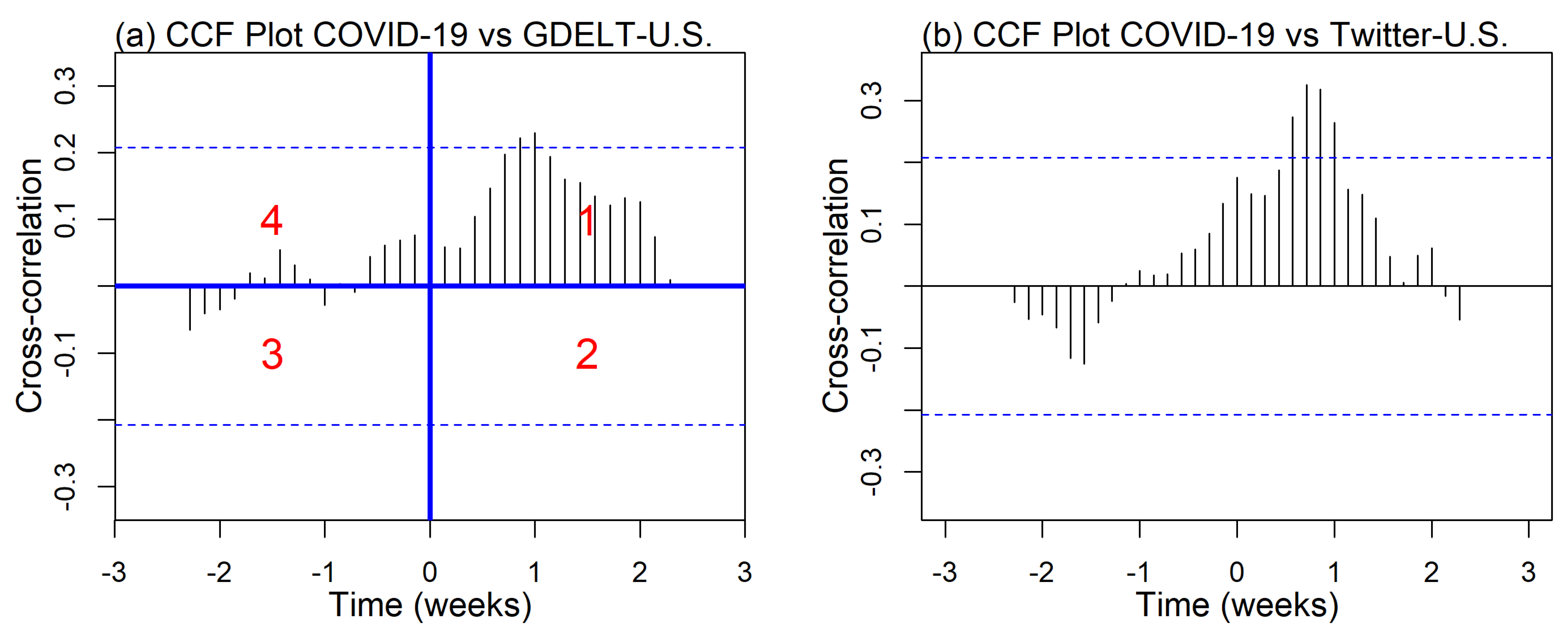
4.1. Cross-Correlation
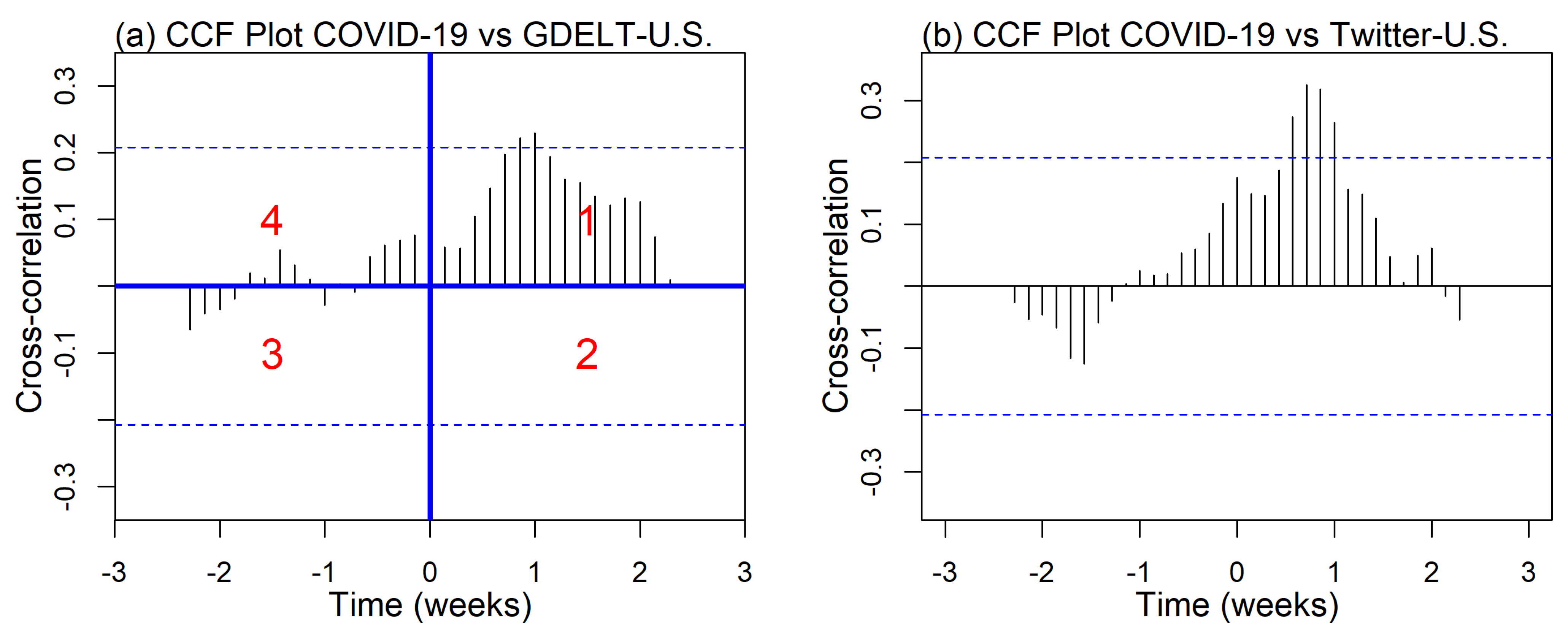
4.1.1. Positive Lag
4.1.2. Negative Lag
4.1.3. Positive and Negative Lag
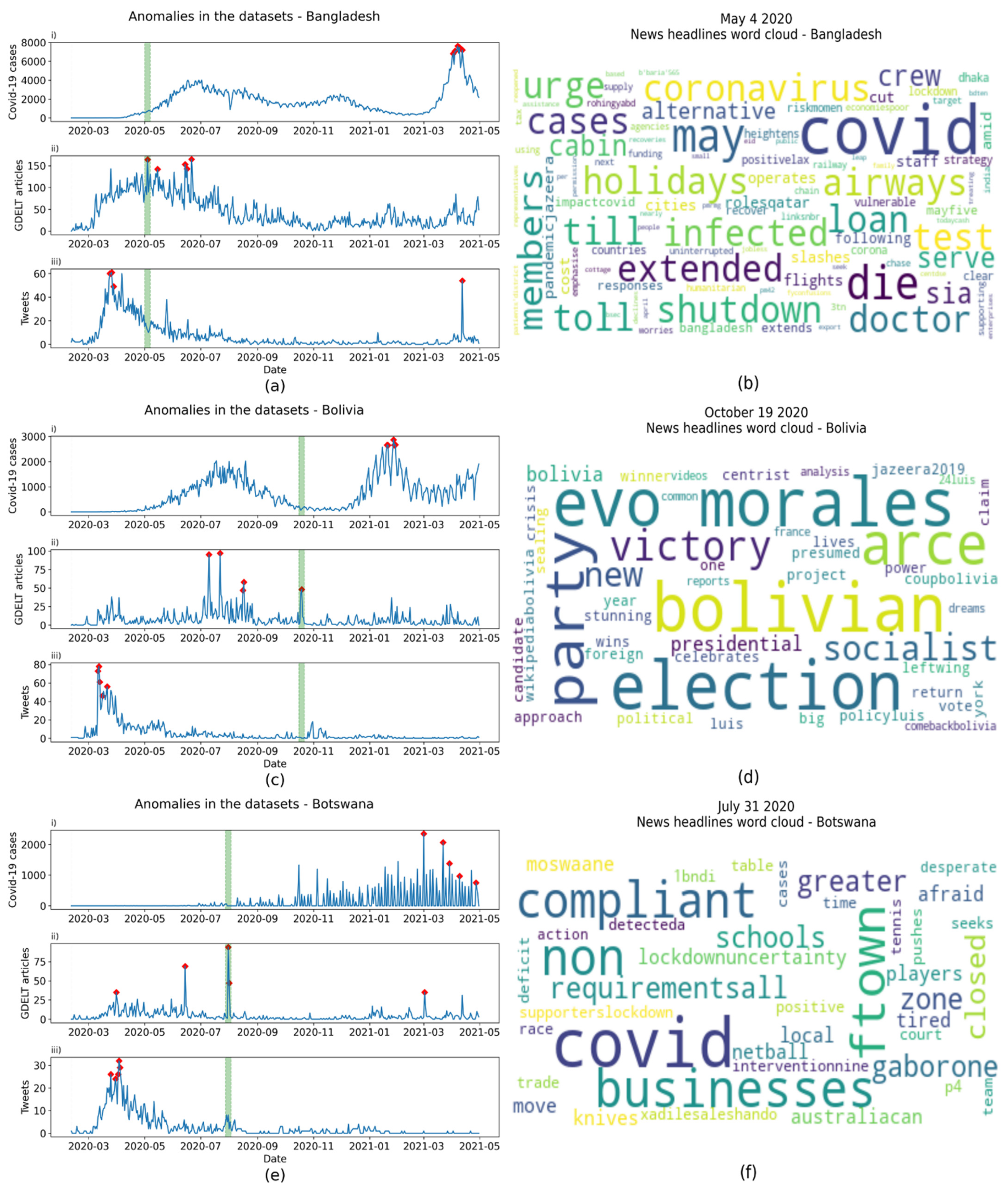
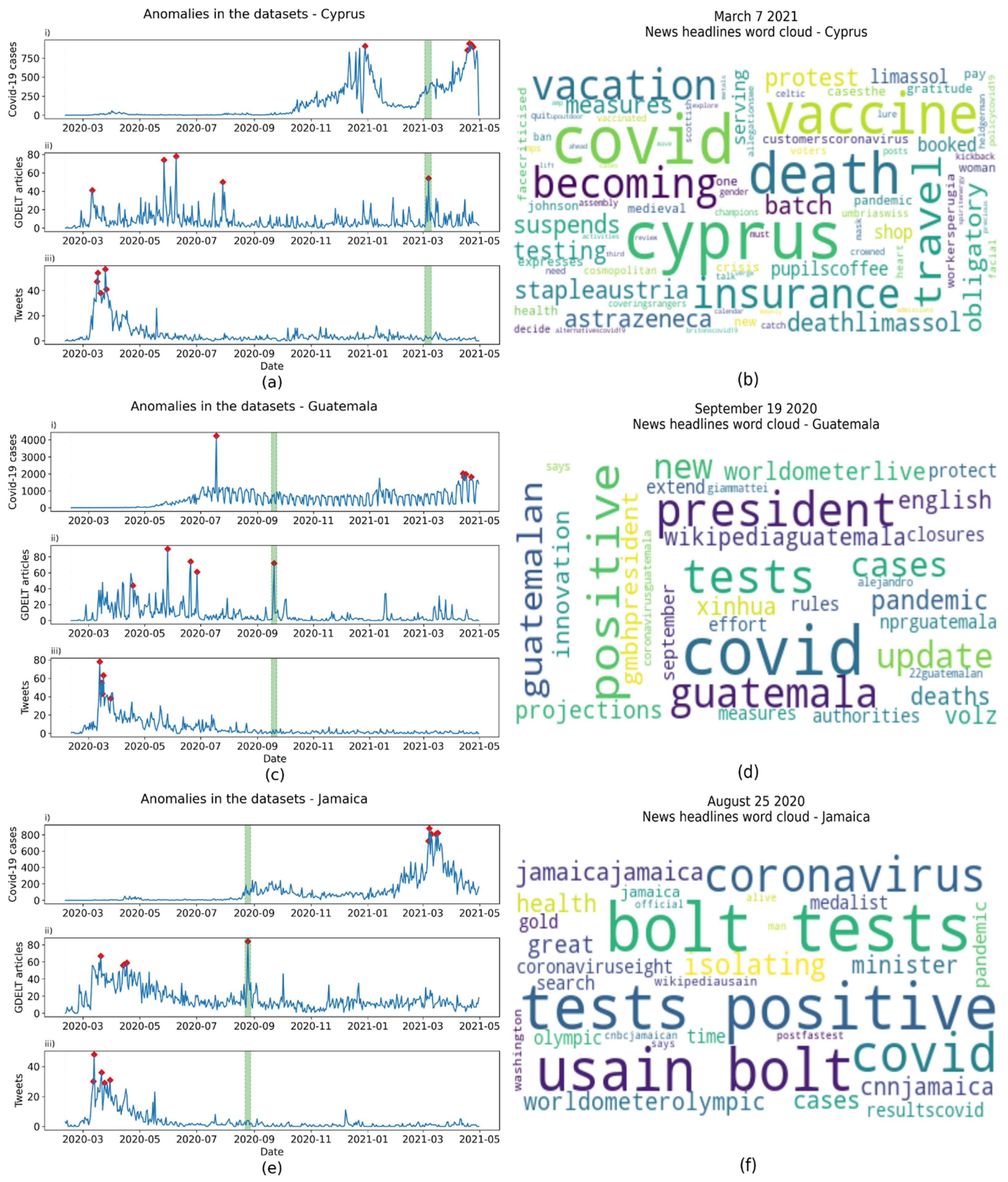
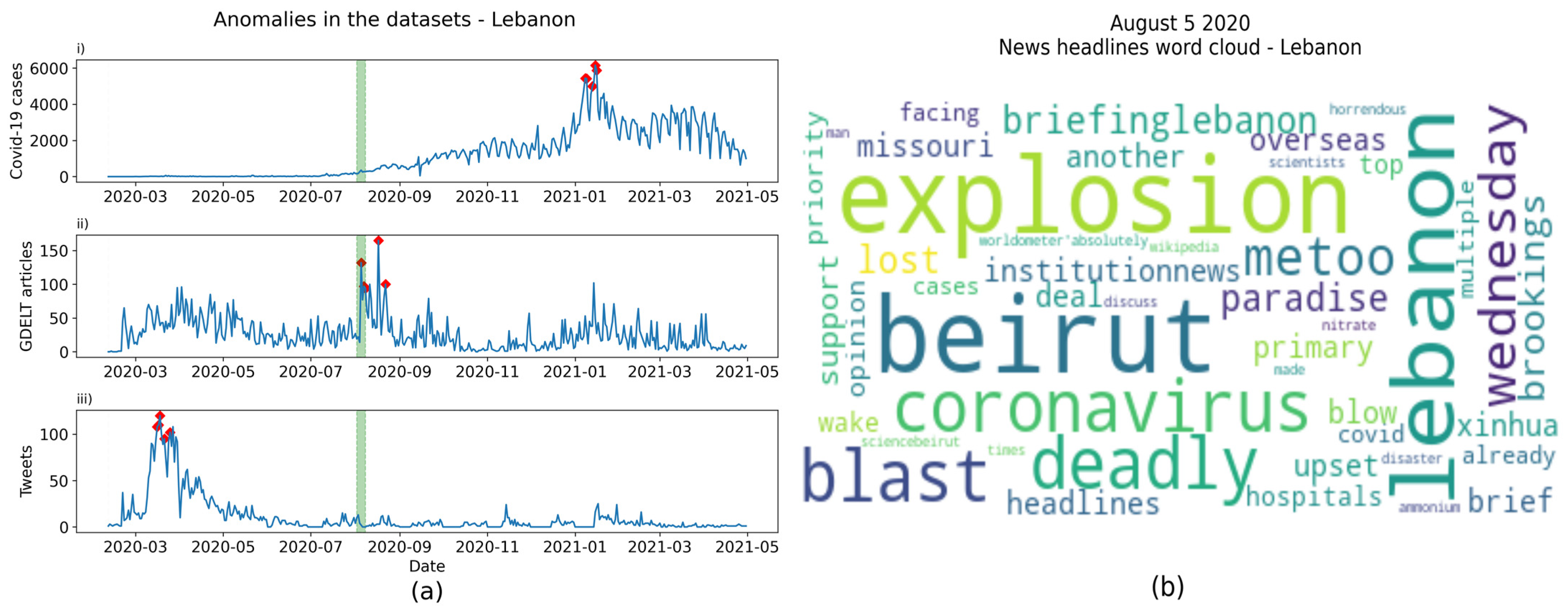
4.2. Anomaly Detection
5. Discussion
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Lag | VAR (COVID-19 vs. GDELT) | Lag | VAR (COVID-19 vs. Twitter) | |||
|---|---|---|---|---|---|---|
| COVID-19 | GDELT | COVID-19 | ||||
| U.K. | GDELT (1) | −0.429 *** (0.128) | Twitter (2) | −0.546 *** (0.125) | ||
| GDELT (2) | −0.291 ** (0.141) | Twitter (6) | 0.218 * (0.126) | |||
| COVID-19 (5) | −0.087 * (0.045) | COVID-19 (7) | 0.229 ** (0.123) | |||
| COVID-19 (7) | 0.217 * (0.122) | Twitter (4) | 0.213 * (0.123) | |||
| N | 82 | 82 | 82 | 82 | ||
| R2 | 0.482 | 0.281 | 0.448 | 0.416 | ||
| Adjusted R2 | 0.312 | 0.046 | 0.267 | 0.225 | ||
| Philippines | COVID-19 (1) | −0.615 *** (0.101) | 5.450 ** (2.173) | COVID-19 (1) | −0.599 *** (0.121) | |
| GDELT (1) | −0.448 *** (0.103) | Twitter (1) | 0.191 * (0.114) | −0.594 *** (0.118) | ||
| COVID-19 (2) | −0.475 *** (0.105) | COVID-19 (2) | −0.449 ** (0.138) | |||
| GDELT (2) | −0.421 *** (0.098) | Twitter (2) | −0.375 * (0.132) | |||
| Twitter (3) | −0.301 ** (0.131) | |||||
| N | 87 | 87 | 82 | 82 | ||
| R2 | 0.391 | 0.364 | 0.449 | 0.352 | ||
| Adjusted R2 | 0.311 | 0.281 | 0.338 | 0.222 | ||
| Germany | COVID-19 (1) | −0.625 *** (0.113) | 0.011 ** (0.005) | COVID-19 (1) | −0.653 *** (0.125) | |
| GDELT (1) | −0.665 *** (0.121) | Twitter (3) | 1.692 * (0.915) | |||
| GDELT (2) | −0.513 *** (0.145) | COVID-19 (4) | 0.322 ** (0.132) | |||
| GDELT (3) | −0.430 *** (0.150) | Twitter (4) | 0.213 * (0.123) | |||
| COVID-19 (4) | 0.302 ** (0.131) | COVID-19 (5) | 0.443 *** (0.136) | |||
| COVID-19 (5) | 0.386 *** (0.112) | Twitter (6) | 2.079 ** (0.937) | |||
| N | 84 | 84 | 82 | 82 | ||
| R2 | 0.522 | 0.418 | 0.598 | 0.322 | ||
| Adjusted R2 | 0.408 | 0.280 | 0.467 | 0.099 | ||
References
- McKibbin, W.; Fernando, R. The Economic Impact of COVID-19. In Economics in the Time of COVID-19; CEPR Press Centre for Economic Policy Research: London, UK, 2020; Volume 45. [Google Scholar]
- Prime, H.; Wade, M.; Browne, D.T. Risk and Resilience in Family Well-Being during the COVID-19 Pandemic. Am. Psychol. 2020, 75, 631. [Google Scholar] [CrossRef] [PubMed]
- Chipidza, W.; Akbaripourdibazar, E.; Gwanzura, T.; Gatto, N.M. Topic Analysis of Traditional and Social Media News Coverage of the Early COVID-19 Pandemic and Implications for Public Health Communication. Disaster Med. Public Health Prep. 2021, 16, 1881–1888. [Google Scholar] [CrossRef] [PubMed]
- Ng, R.; Chow, T.Y.J.; Yang, W. News Media Narratives of COVID-19 across 20 Countries: Early Global Convergence and Later Regional Divergence. PLoS ONE 2021, 16, e0256358. [Google Scholar] [CrossRef] [PubMed]
- World Health Organization WHO Director-General’s Opening Remarks at the Media Briefing on COVID-19–11 March 2020. Available online: https://www.who.int/director-general/speeches/detail/who-director-general-s-opening-remarks-at-the-media-briefing-on-covid-19---11-march-2020 (accessed on 20 August 2023).
- Moreland, A.; Herlihy, C.; Tynan, M.A.; Sunshine, G.; McCord, R.F.; Hilton, C.; Poovey, J.; Werner, A.K.; Jones, C.D.; Fulmer, E.B.; et al. Timing of State and Territorial COVID-19 Stay-at-Home Orders and Changes in Population Movement—United States, March 1–May 31, 2020. Morb. Mortal. Wkly. Rep. 2020, 69, 1198–1203. [Google Scholar] [CrossRef] [PubMed]
- Islam, M.S.; Rahman, K.M.; Sun, Y.; Qureshi, M.O.; Abdi, I.; Chughtai, A.A.; Seale, H. Current Knowledge of COVID-19 and Infection Prevention and Control Strategies in Healthcare Settings: A Global Analysis. Infect. Control. Hosp. Epidemiol. 2020, 41, 1196–1206. [Google Scholar] [CrossRef]
- Anwar, A.; Malik, M.; Raees, V.; Anwar, A. Role of Mass Media and Public Health Communications in the COVID-19 Pandemic. Cureus 2020, 12, e10453. [Google Scholar] [CrossRef]
- Cinelli, M.; Quattrociocchi, W.; Galeazzi, A.; Valensise, C.M.; Brugnoli, E.; Schmidt, A.L.; Zola, P.; Zollo, F.; Scala, A. The COVID-19 Social Media Infodemic. Sci. Rep. 2020, 10, 16598. [Google Scholar] [CrossRef]
- Boon-Itt, S.; Skunkan, Y. Public Perception of the COVID-19 Pandemic on Twitter: Sentiment Analysis and Topic Modeling Study. JMIR Public Health Surveill. 2020, 6, e21978. [Google Scholar] [CrossRef]
- Tagliabue, F.; Galassi, L.; Mariani, P. The “Pandemic” of Disinformation in COVID-19. SN Compr. Clin. Med. 2020, 2, 1287–1289. [Google Scholar] [CrossRef]
- Tsao, S.-F.; Chen, H.; Tisseverasinghe, T.; Yang, Y.; Li, L.; Butt, Z.A. What Social Media Told Us in the Time of COVID-19: A Scoping Review. Lancet Digit. Health 2021, 3, e175–e194. [Google Scholar] [CrossRef]
- Hargittai, E. Potential Biases in Big Data: Omitted Voices on Social Media. Soc. Sci. Comput. Rev. 2020, 38, 10–24. [Google Scholar] [CrossRef]
- GDELT. The GDELT Project. Available online: https://www.gdeltproject.org/ (accessed on 9 May 2023).
- Tizzoni, M.; Panisson, A.; Paolotti, D.; Cattuto, C. The Impact of News Exposure on Collective Attention in the United States during the 2016 Zika Epidemic. PLoS Comput. Biol. 2020, 16, e1007633. [Google Scholar] [CrossRef]
- Yao, Y.; Zhang, Y.; Liu, J.; Li, Y.; Li, X. Analysis of Spatiotemporal Characteristics and Influencing Factors for the Aid Events of COVID-19 Based on GDELT. Sustainability 2022, 14, 12522. [Google Scholar] [CrossRef]
- Goswami, A.; Kumar, A. A Survey of Event Detection Techniques in Online Social Networks. Soc. Netw. Anal. Min. 2016, 6, 107. [Google Scholar] [CrossRef]
- Hendriks, W.; Boshuizen, H.; Dekkers, A.; Knol, M.; Donker, G.A.; van der Ende, A.; Altes, H.K. Temporal Cross-Correlation between Influenza-like Illnesses and Invasive Pneumococcal Disease in The Netherlands. Influenza Other Respir. Viruses 2017, 11, 130–137. [Google Scholar] [CrossRef] [PubMed]
- Probst, W.N.; Stelzenmüller, V.; Fock, H.O. Using Cross-Correlations to Assess the Relationship between Time-Lagged Pressure and State Indicators: An Exemplary Analysis of North Sea Fish Population Indicators. ICES J. Mar. Sci. 2012, 69, 670–681. [Google Scholar] [CrossRef]
- Hasan, M.; Orgun, M.A.; Schwitter, R. Real-Time Event Detection from the Twitter Data Stream Using the TwitterNews+ Framework. Inf. Process. Manag. 2019, 56, 1146–1165. [Google Scholar] [CrossRef]
- Mavragani, A.; Gkillas, K. COVID-19 Predictability in the United States Using Google Trends Time Series. Sci. Rep. 2020, 10, 20693. [Google Scholar] [CrossRef]
- Alsharif, M.H.; Younes, M.K.; Kim, J. Time Series ARIMA Model for Prediction of Daily and Monthly Average Global Solar Radiation: The Case Study of Seoul, South Korea. Symmetry 2019, 11, 240. [Google Scholar] [CrossRef]
- Hyndman, R.J.; Athanasopoulos, G. Forecasting: Principles and Practice, 3rd, ed.; OTexts: Melbourne, Australia, 2021. [Google Scholar]
- Wang, Y.; Gao, S.; Gao, W. Investigating Dynamic Relations between Factual Information and Misinformation: Empirical Studies of Tweets Related to Prevention Measures during COVID-19. J. Contingencies Crisis Manag. 2021, 30, 427–439. [Google Scholar] [CrossRef]
- Matei, S.A.; Kulzick, R.; Sinclair-Chapman, V.; Potts, L. Setting the Agenda in Environmental Crisis: Relationships between Tweets, Google Search Trends, and Newspaper Coverage during the California Drought. PLoS ONE 2021, 16, e0259494. [Google Scholar] [CrossRef] [PubMed]
- Alamro, R.; McCarren, A.; Al-Rasheed, A. Predicting Saudi Stock Market Index by Incorporating GDELT Using Multivariate Time Series Modelling. In Proceedings of the Advances in Data Science, Cyber Security and IT Applications, Riyadh, Saudi Arabia, 10–12 December 2019; Alfaries, A., Mengash, H., Yasar, A., Shakshuki, E., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 317–328. [Google Scholar]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly Detection: A Survey. ACM Comput. Surv. 2009, 41, 15:1–15:58. [Google Scholar] [CrossRef]
- Hochenbaum, J.; Vallis, O.S.; Kejariwal, A. Automatic Anomaly Detection in the Cloud Via Statistical Learning. arXiv 2017, arXiv:1704.07706. [Google Scholar]
- Caputi, T.L. Google Searches for “Cheap Cigarettes” Spike at Tax Increases: Evidence from an Algorithm to Detect Spikes in Time Series Data. Nicotine Tob. Res. 2018, 20, 779–783. [Google Scholar] [CrossRef]
- Rosner, B. Percentage Points for a Generalized ESD Many-Outlier Procedure. Technometrics 1983, 25, 165–172. [Google Scholar] [CrossRef]
- Shahsavari, S.; Holur, P.; Wang, T.; Tangherlini, T.R.; Roychowdhury, V. Conspiracy in the Time of Corona: Automatic Detection of Emerging COVID-19 Conspiracy Theories in Social Media and the News. J. Comput. Soc. Sci. 2020, 3, 279–317. [Google Scholar] [CrossRef] [PubMed]
- Krawczyk, K.; Chelkowski, T.; Laydon, D.J.; Mishra, S.; Xifara, D.; Gibert, B.; Flaxman, S.; Mellan, T.; Schwämmle, V.; Röttger, R.; et al. Quantifying Online News Media Coverage of the COVID-19 Pandemic: Text Mining Study and Resource. J. Med. Internet Res. 2021, 23, e28253. [Google Scholar] [CrossRef] [PubMed]
- Badawi, D. Intelligent Recommendations Based on COVID-19 Related Twitter Sentiment Analysis and Fake Tweet Detection in Apache Spark Environment. IETE J. Res. 2023, 1–24. [Google Scholar] [CrossRef]
- Thakur, N. Sentiment Analysis and Text Analysis of the Public Discourse on Twitter about COVID-19 and MPox. Big Data Cogn. Comput. 2023, 7, 116. [Google Scholar] [CrossRef]
- Fu, K.-W.; Liang, H.; Saroha, N.; Tse, Z.T.H.; Ip, P.; Fung, I.C.-H. How People React to Zika Virus Outbreaks on Twitter? A Computational Content Analysis. Am. J. Infect. Control. 2016, 44, 1700–1702. [Google Scholar] [CrossRef]
- Odlum, M.; Yoon, S. What Can We Learn about the Ebola Outbreak from Tweets? Am. J. Infect. Control. 2015, 43, 563–571. [Google Scholar] [CrossRef] [PubMed]
- Broniatowski, D.A.; Paul, M.J.; Dredze, M. National and Local Influenza Surveillance through Twitter: An Analysis of the 2012–2013 Influenza Epidemic. PLoS ONE 2013, 8, e83672. [Google Scholar] [CrossRef] [PubMed]
- Dong, E.; Du, H.; Gardner, L. An Interactive Web-Based Dashboard to Track COVID-19 in Real Time. Lancet Infect. Dis. 2020, 20, 533–534. [Google Scholar] [CrossRef]
- Sáez, C.; Romero, N.; Conejero, J.A.; García-Gómez, J.M. Potential Limitations in COVID-19 Machine Learning Due to Data Source Variability: A Case Study in the NCov2019 Dataset. J. Am. Med. Inform. Assoc. 2021, 28, 360–364. [Google Scholar] [CrossRef] [PubMed]
- Huang, B.; Carley, K.M. A Large-Scale Empirical Study of Geotagging Behavior on Twitter. In Proceedings of the IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, The Hague, The Netherlands, 7–10 December 2020; Association for Computing Machinery: New York, NY, USA, 2019; pp. 365–373. [Google Scholar]
- Alsmadi, I.; O’Brien, M.J. How Many Bots in Russian Troll Tweets? Inf. Process. Manag. 2020, 57, 102303. [Google Scholar] [CrossRef]
- Cleveland, R.B.; Cleveland, W.S.; McRae, J.E.; Terpenning, I. STL: A Seasonal-Trend Decomposition. J. Stat. 1990, 6, 3–73. [Google Scholar]
- Shi, X.; Ling, G.H.T.; Leng, P.C.; Rusli, N.; Matusin, A.M.R.A. Associations between Institutional-Social-Ecological Factors and COVID-19 Case-Fatality: Evidence from 134 Countries Using Multiscale Geographically Weighted Regression (MGWR). One Health 2023, 16, 100551. [Google Scholar] [CrossRef]
- Cryer, J.D.; Chan, K.-S. Time Series Analysis: With Applications in R; Springer: Berlin/Heidelberg, Germany, 2008; Volume 2. [Google Scholar]
- Box, G.E.P.; Cox, D.R. An Analysis of Transformations. J. R. Stat. Soc. Ser. B (Methodol.) 1964, 26, 211–243. [Google Scholar] [CrossRef]
- Chatfield, C.; Xing, H. The Analysis of Time Series: An Introduction with R; CRC Press: Boca Raton, CA, USA, 2019; ISBN 1-4987-9564-1. [Google Scholar]
- Hyndman, R.J.; Khandakar, Y. Automatic Time Series Forecasting: The Forecast Package for R. J. Stat. Softw. 2008, 27, 1–22. [Google Scholar] [CrossRef]
- Ljung, G.M.; Box, G.E. On a Measure of Lack of Fit in Time Series Models. Biometrika 1978, 65, 297–303. [Google Scholar] [CrossRef]
- Minitab Interpret the Key Results for Correlation. Available online: https://support.minitab.com/en-us/minitab/21/help-and-how-to/statistics/basic-statistics/how-to/correlation/interpret-the-results/key-results/ (accessed on 20 June 2022).
- Duraj, A.; Szczepaniak, P.S. Outlier Detection in Data Streams—A Comparative Study of Selected Methods. Procedia Comput. Sci. 2021, 192, 2769–2778. [Google Scholar] [CrossRef]
- Newsbank Access World News—Historical and Current\Textbar Easy Search: All Content. Available online: https://infoweb.newsbank.com/apps/news/?p=WORLDNEWS (accessed on 12 January 2022).
- Kogan, N.E.; Clemente, L.; Liautaud, P.; Kaashoek, J.; Link, N.B.; Nguyen, A.T.; Lu, F.S.; Huybers, P.; Resch, B.; Havas, C.; et al. An Early Warning Approach to Monitor COVID-19 Activity with Multiple Digital Traces in near Real Time. Sci. Adv. 2021, 7, eabd6989. [Google Scholar] [CrossRef] [PubMed]
- Ginsberg, J.; Mohebbi, M.H.; Patel, R.S.; Brammer, L.; Smolinski, M.S.; Brilliant, L. Detecting Influenza Epidemics Using Search Engine Query Data. Nature 2009, 457, 1012–1014. [Google Scholar] [CrossRef]
- Li, C.; Chen, L.J.; Chen, X.; Zhang, M.; Pang, C.P.; Chen, H. Retrospective Analysis of the Possibility of Predicting the COVID-19 Outbreak from Internet Searches and Social Media Data, China, 2020. Eurosurveillance 2020, 25, 2000199. [Google Scholar] [CrossRef] [PubMed]
- Gencoglu, O.; Gruber, M. Causal Modeling of Twitter Activity during COVID-19. Computation 2020, 8, 85. [Google Scholar] [CrossRef]
- Wong, C.M.L.; Jensen, O. The Paradox of Trust: Perceived Risk and Public Compliance during the COVID-19 Pandemic in Singapore. J. Risk Res. 2020, 23, 1021–1030. [Google Scholar] [CrossRef]
- Jordan, S.E.; Hovet, S.E.; Fung, I.C.-H.; Liang, H.; Fu, K.-W.; Tse, Z.T.H. Using Twitter for Public Health Surveillance from Monitoring and Prediction to Public Response. Data 2019, 4, 6. [Google Scholar] [CrossRef]
- Sun, K.; Chen, J.; Viboud, C. Early Epidemiological Analysis of the Coronavirus Disease 2019 Outbreak Based on Crowdsourced Data: A Population-Level Observational Study. Lancet Digit. Health 2020, 2, e201–e208. [Google Scholar] [CrossRef]
- Lee, K.; Agrawal, A.; Choudhary, A. Real-Time Disease Surveillance Using Twitter Data: Demonstration on Flu and Cancer. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Anchorage, AK, USA, 4–8 August 2019; Association for Computing Machinery: New York, NY, USA, 2013; pp. 1474–1477. [Google Scholar]
- Rubin, R. The Challenges of Expanding Rapid Tests to Curb COVID-19. JAMA 2020, 324, 1813–1815. [Google Scholar] [CrossRef]
- Apuke, O.D.; Omar, B. Fake News and COVID-19: Modelling the Predictors of Fake News Sharing among Social Media Users. Telemat. Inform. 2021, 56, 101475. [Google Scholar] [CrossRef]
- Schroepfer, M. An Update on Our Plans to Restrict Data Access on Facebook. Available online: https://about.fb.com/news/2018/04/restricting-data-access/ (accessed on 8 May 2023).
- Cao, J.; Hochmair, H.H.; Basheeh, F. The Effect of Twitter App Policy Changes on the Sharing of Spatial Information through Twitter Users. Geographies 2022, 2, 33. [Google Scholar] [CrossRef]
- Souza, R.C.S.N.P.; Assunção, R.M.; Neill, D.B.; Meira, W. Detecting Spatial Clusters of Disease Infection Risk Using Sparsely Sampled Social Media Mobility Patterns. In Proceedings of the 27th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Dallas/Fort Worth, TX, USA, 4–7 November 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 359–368. [Google Scholar]
- Rivieccio, B.A.; Micheletti, A.; Maffeo, M.; Zignani, M.; Comunian, A.; Nicolussi, F.; Salini, S.; Manzi, G.; Auxilia, F.; Giudici, M.; et al. COVID-19, Learning from the Past: A Wavelet and Cross-Correlation Analysis of the Epidemic Dynamics Looking to Emergency Calls and Twitter Trends in Italian Lombardy Region. PLoS ONE 2021, 16, e0247854. [Google Scholar] [CrossRef] [PubMed]
- O’Leary, D.E.; Storey, V.C. A Google–Wikipedia–Twitter Model as a Leading Indicator of the Numbers of Coronavirus Deaths. Intell. Syst. Account. Financ. Manag. 2020, 27, 151–158. [Google Scholar] [CrossRef]
- Dargin, J.S.; Fan, C.; Mostafavi, A. Vulnerable Populations and Social Media Use in Disasters: Uncovering the Digital Divide in Three Major U.S. Hurricanes. Int. J. Disaster Risk Reduct. 2021, 54, 102043. [Google Scholar] [CrossRef]
- Chevallier, J. Time-Varying Correlations in Oil, Gas and CO2 Prices: An Application Using BEKK, CCC and DCC-MGARCH Models. Appl. Econ. 2012, 44, 4257–4274. [Google Scholar] [CrossRef]
| Lag | VAR (COVID-19 and GDELT) | Lag | VAR (COVID-19 and Twitter) | ||
|---|---|---|---|---|---|
| COVID-19 | GDELT | COVID-19 | |||
| COVID-19 (1) | −0.860 *** (0.122) | COVID-19 (1) | −0.865 *** (0.22) | ||
| GDELT (1) (1) | −0.289 ** (0.121) | Twitter (1) | 0.002 * (0.001) | ||
| GDELT (2) | −0.288 *** (0.125) | Twitter (2) | −0.466 *** (0.120) | ||
| GDELT (3) | 0.029 * (0.015) | Twitter (3) | 0.303 * (0.130) | ||
| COVID-19 (5) | 0.346 ** (0.156) | Twitter (4) | 0.002 * (0.001) | ||
| COVID-19 (6) | 0.234 * (0.122) | Twitter (5) | 2.079 ** (0.937) | 0.334 *** (0.124) | |
| N | 83 | 83 | 84 | 84 | |
| R2 | 0.614 | 0.219 | 0.601 | 0.385 | |
| Adjusted R2 | 0.506 | 0.091 | 0.506 | 0.238 | |
| Country | Model | Time Lag in Days | Quadrant | |
|---|---|---|---|---|
| COVID-19 vs. GDELT | COVID-19 vs. Twitter | |||
| Australia | ARIMA (1, 0, 2) | 12 | 3 | 1 |
| Brazil | ARIMA (0, 0, 1) with nonzero mean | 7 | 10 | 1 |
| France | ARIMA (0, 0, 1) | none | 8 | 1 |
| Greece | ARIMA (0, 0, 1) | 1 | 0 | 1 |
| India | ARIMA (4, 0, 0) with nonzero mean | 7 | 14 | 1 |
| Italy | ARIMA (0, 1, 2) (0, 0, 1)7 | 16 | 1 | 1 |
| Poland | ARIMA (2, 0, 0) with nonzero mean | −16 | 0 | 1 and 3 |
| U.S. | ARIMA (0, 1, 2) (1, 0, 1)7 | 7 | 5 | 1 |
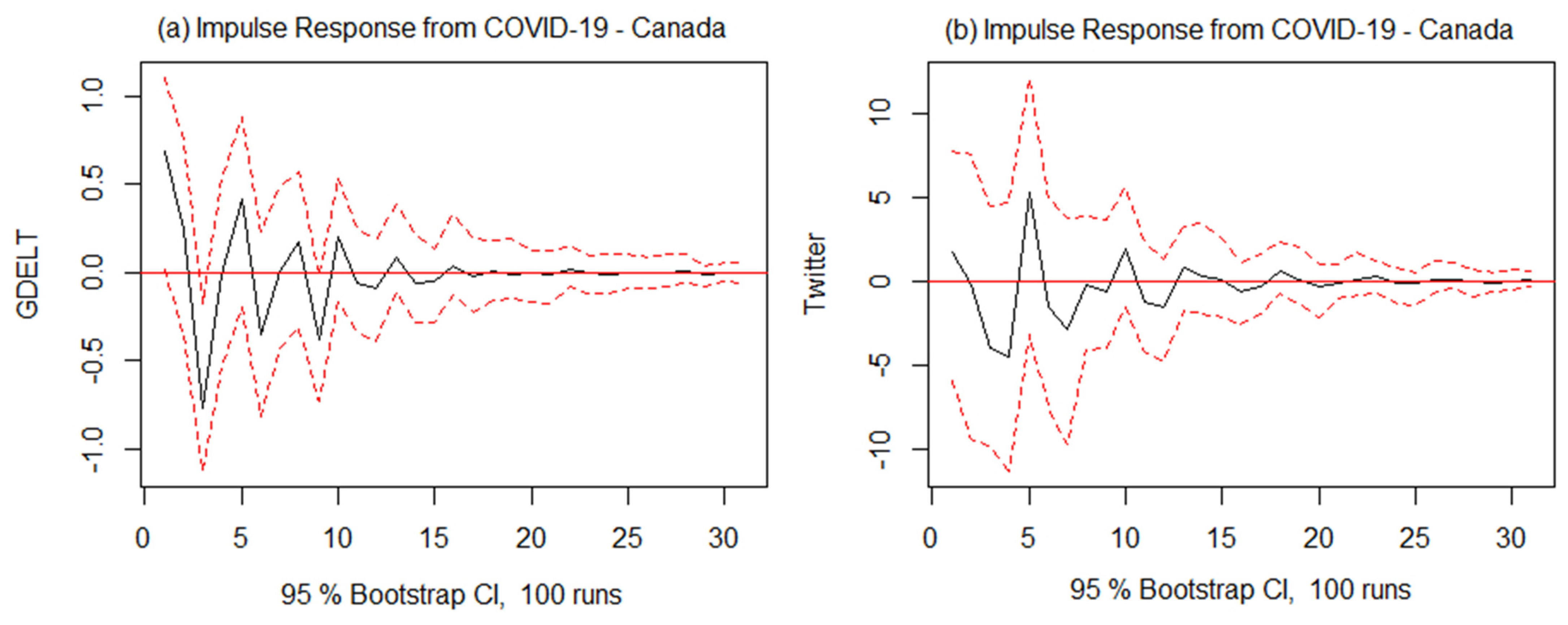
| Canada | VAR (6)—COVID-19 and GDELT VAR (5)—COVID-19 and Twitter | 0 | 11 | 1 |
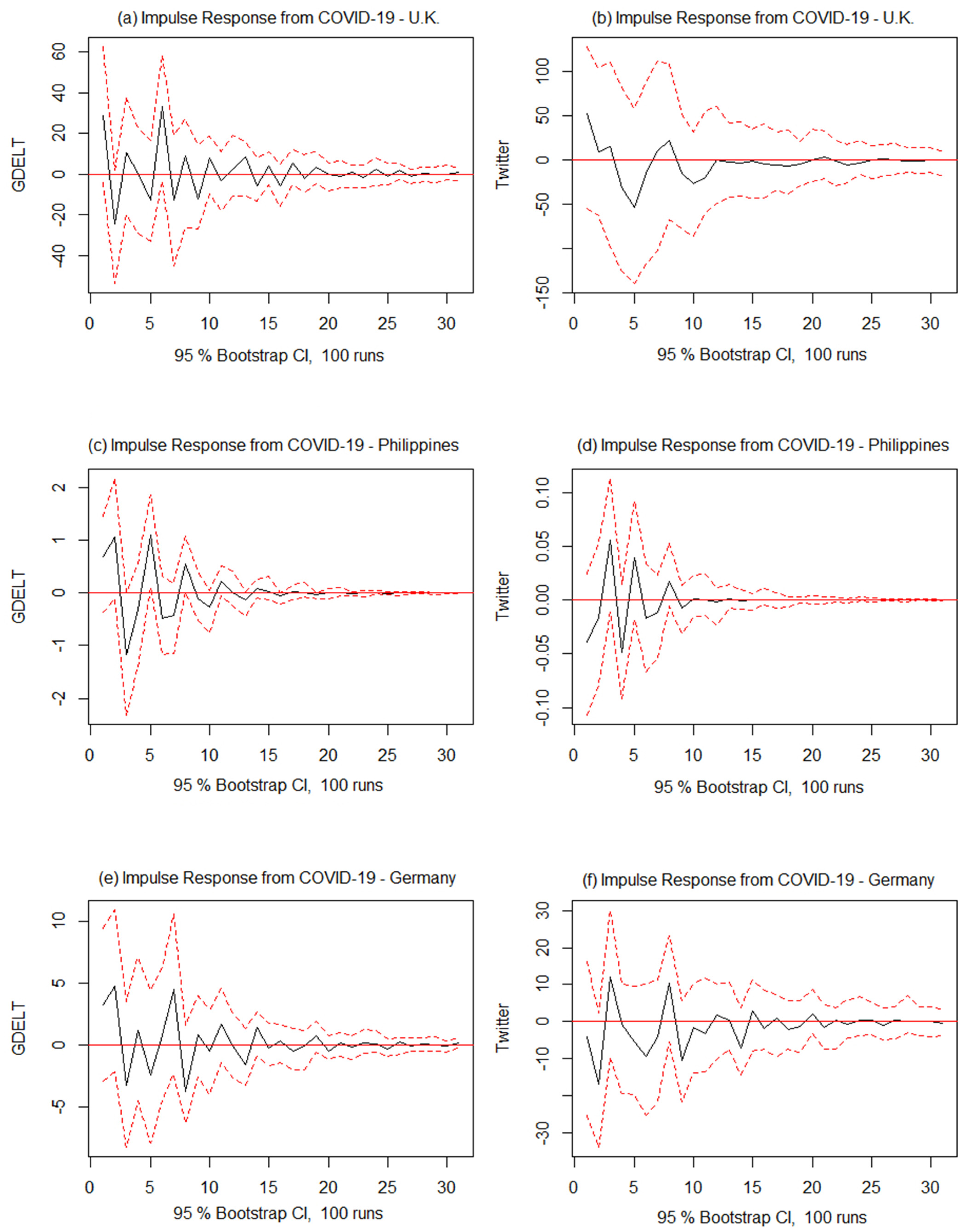
| Germany | VAR (5)—COVID-19 and GDELT VAR (7)—COVID-19 and Twitter | 7 | 11 | 1 |
| Philippines | VAR (2)—COVID-19 and GDELT VAR (4)—COVID-19 and Twitter | −7 | 4 | 1 and 3 |
| U.K. | VAR (7)—COVID-19 and GDELT VAR (7)—COVID-19 and Twitter | 15 | 13 | 1 |
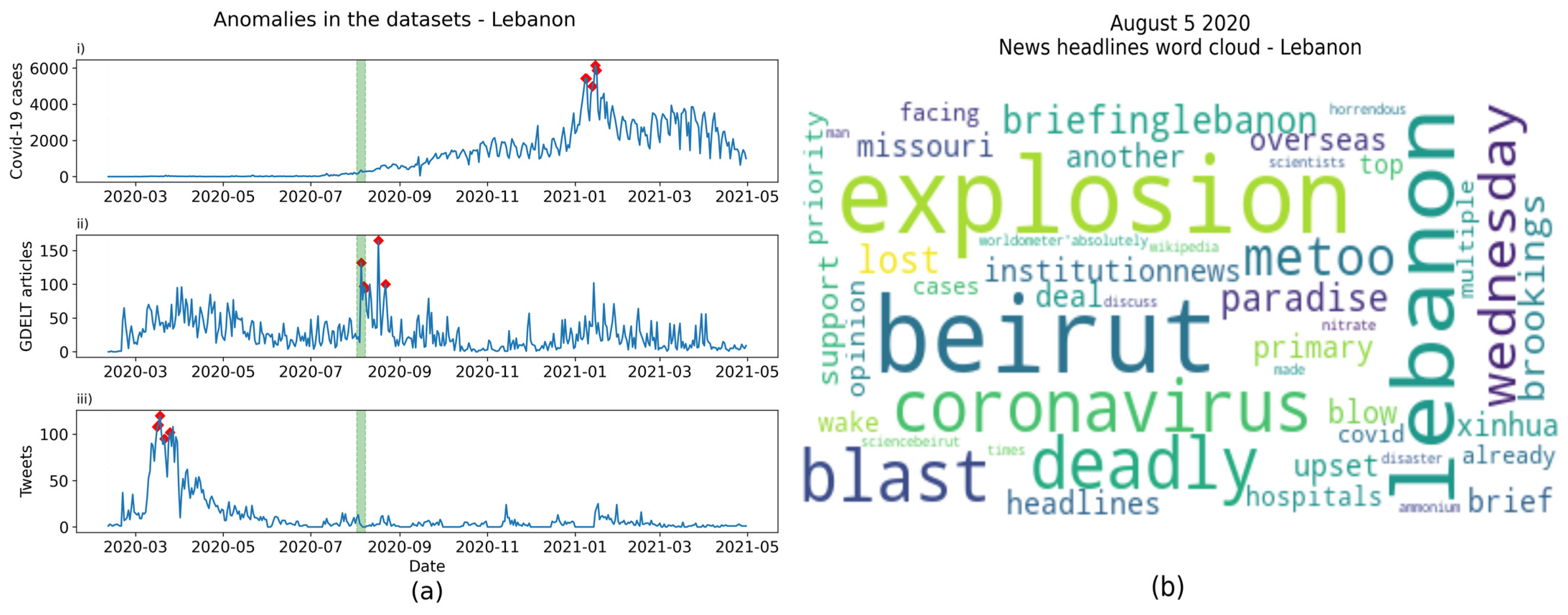
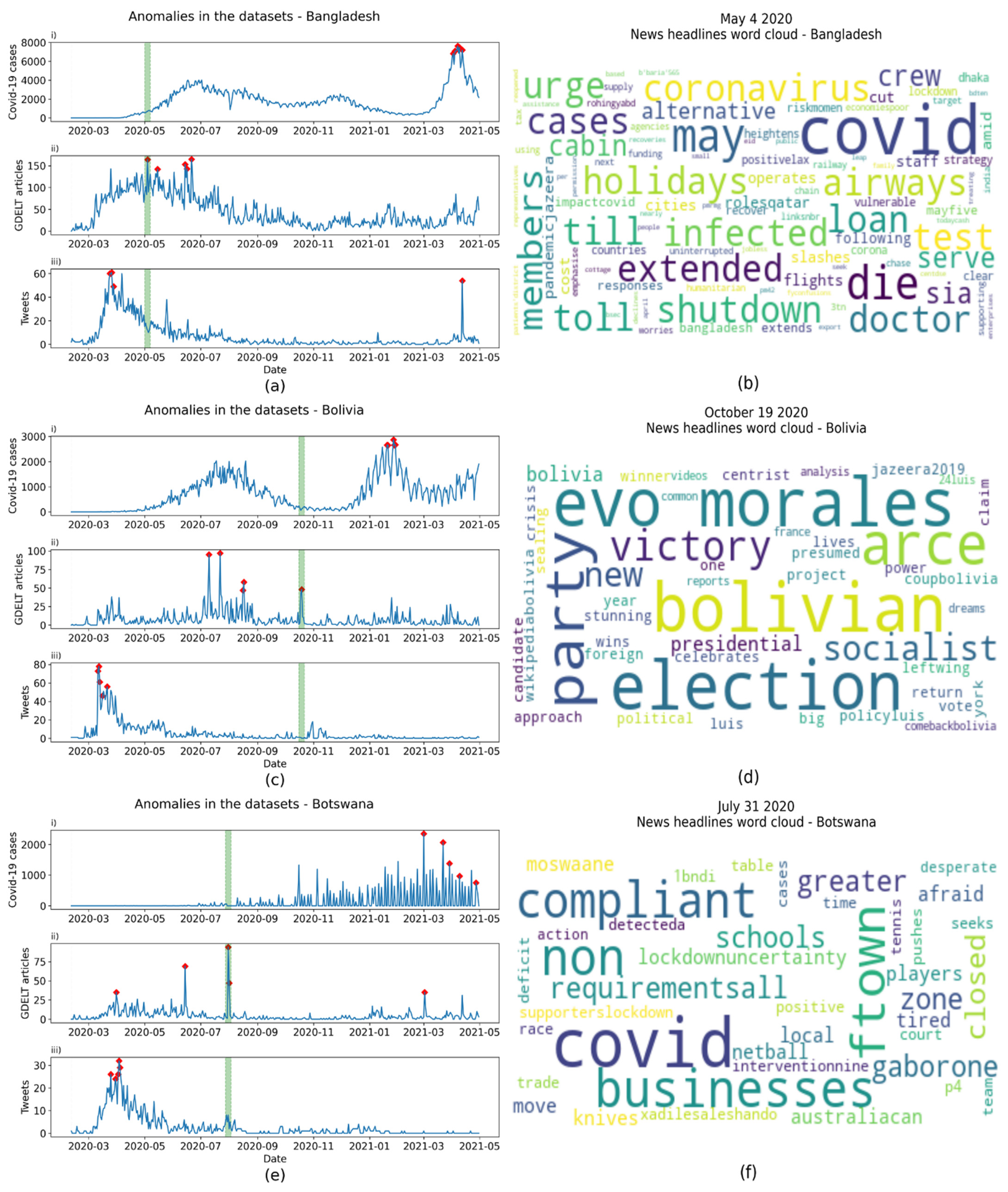
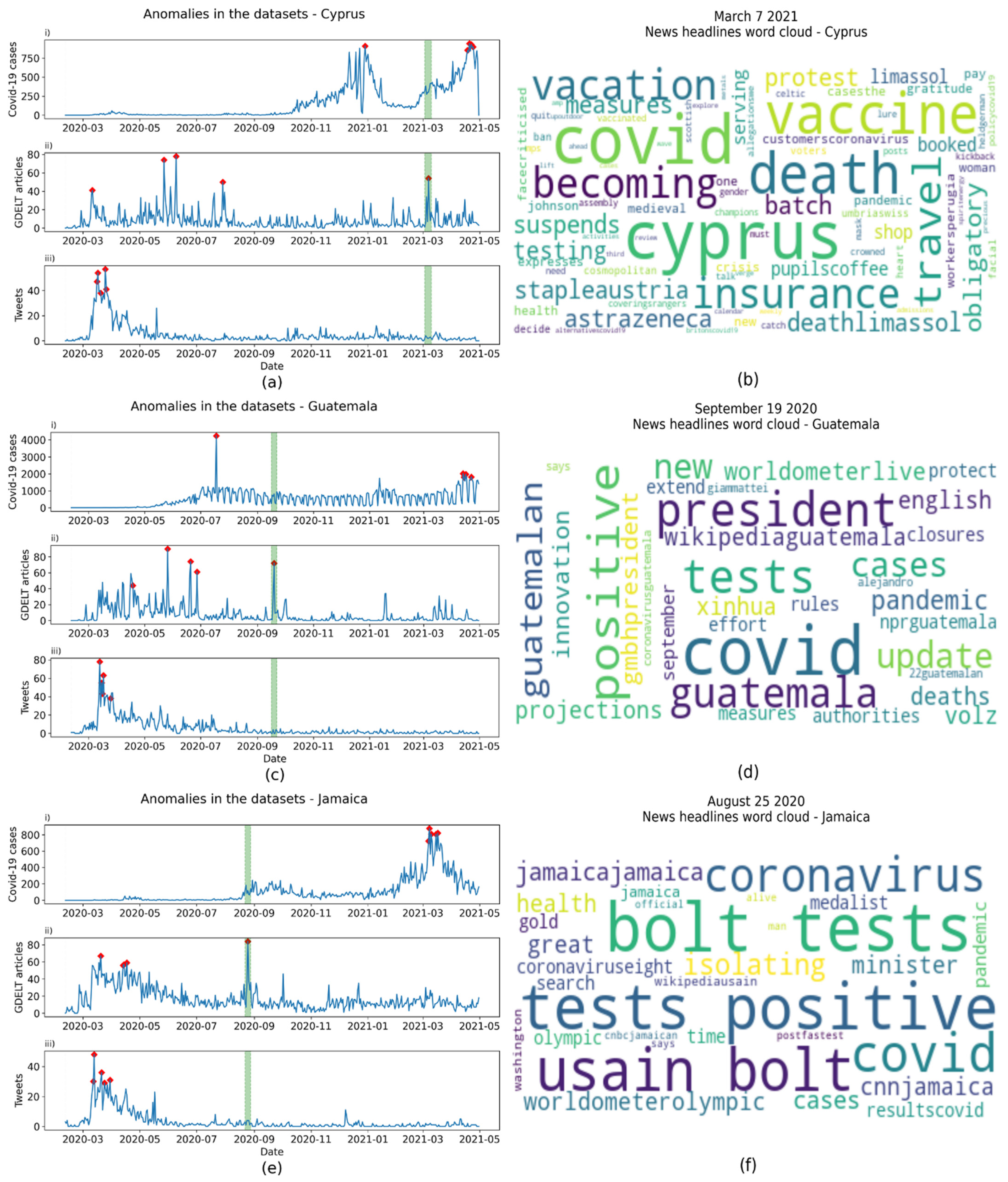
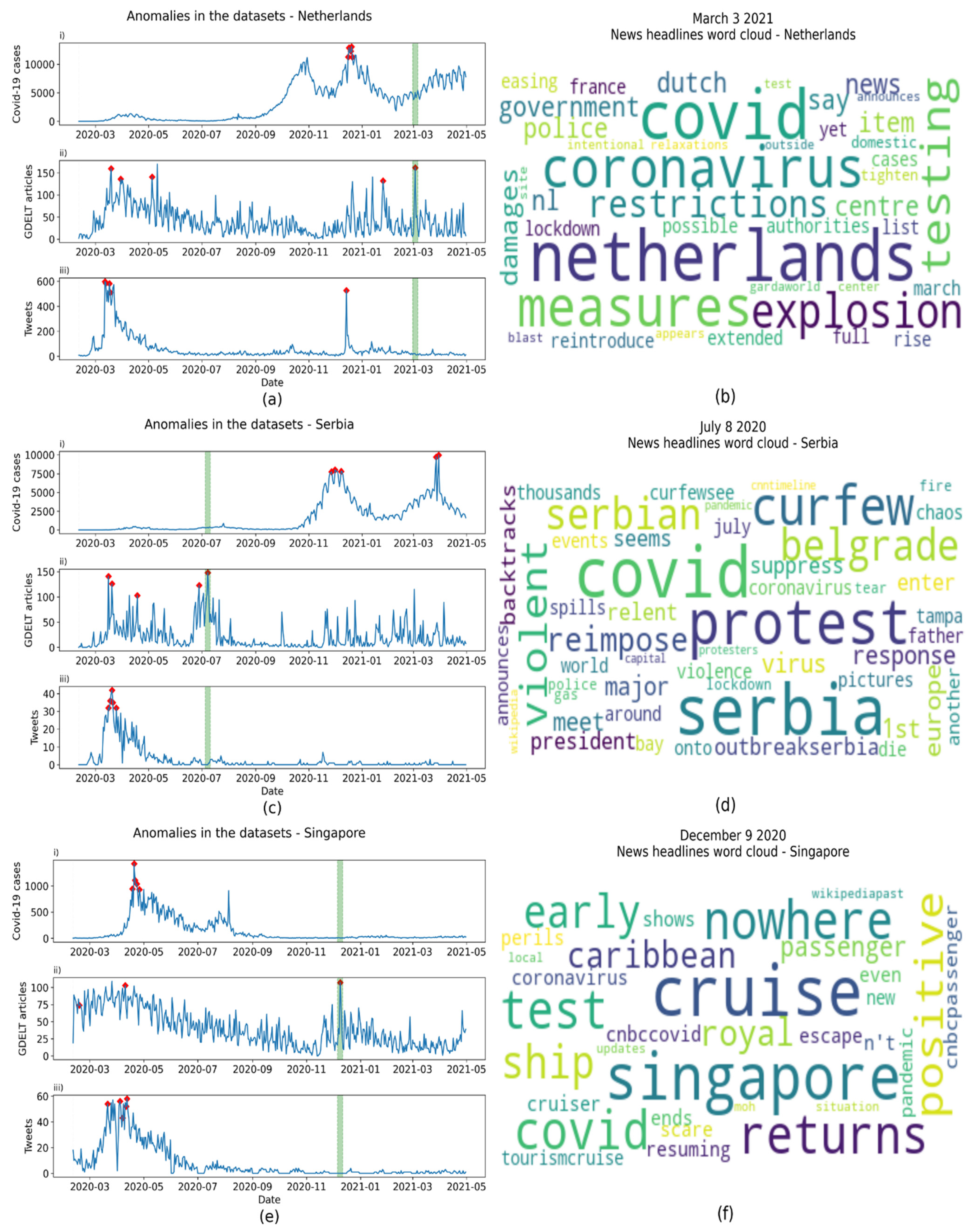
| Country | Anomaly Date | Frequent Words | Events |
|---|---|---|---|
| Bangladesh | 2020-05-04 | holidays | National holiday |
| Bolivia | 2020-10-19 | election, party, victory | General elections |
| Botswana | 2020-7-31 | requirements, compliant | Introduction of lockdown |
| Cyprus | 2021-03-07 | Cyprus, protest | Protests |
| Guatemala | 2020-09-19 | president | President of Guatemala contracted COVID-19 |
| Jamaica | 2020-08-25 | Usain Bolt | Jamaican Olympian contracted COVID-19 |
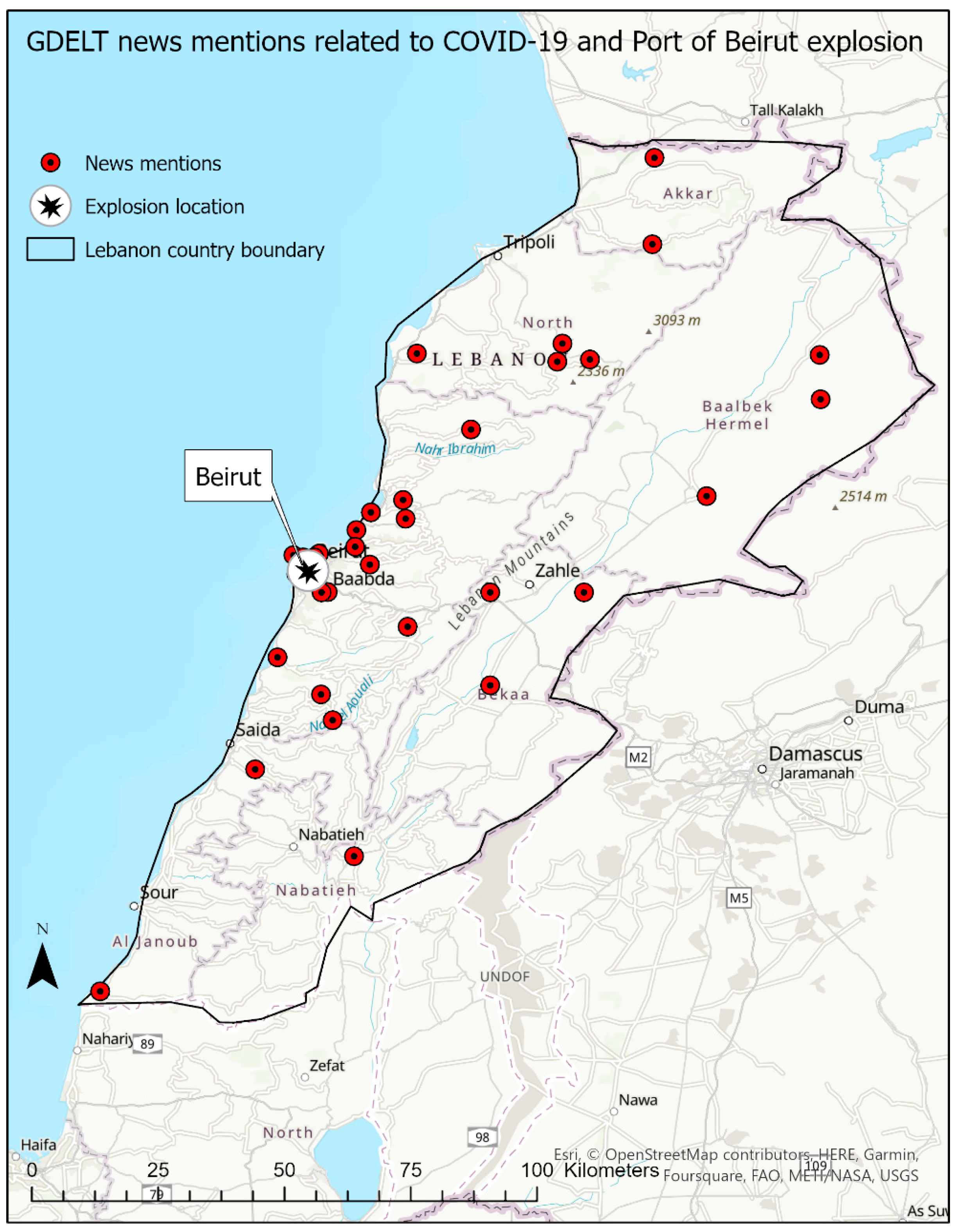
| Lebanon | 2020-08-05 | explosion, deadly, Beirut | Beirut port explosion |
| Netherlands | 2021-03-03 | explosion | Explosion |
| Serbia | 2020-07-08 | protest, violent | Protests |
| Singapore | 2020-12-09 | cruise | COVID-19 scare on a cruise ship |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Owuor, I.; Hochmair, H.H. Temporal Relationship between Daily Reports of COVID-19 Infections and Related GDELT and Tweet Mentions. Geographies 2023, 3, 584-609. https://doi.org/10.3390/geographies3030031
Owuor I, Hochmair HH. Temporal Relationship between Daily Reports of COVID-19 Infections and Related GDELT and Tweet Mentions. Geographies. 2023; 3(3):584-609. https://doi.org/10.3390/geographies3030031
Chicago/Turabian StyleOwuor, Innocensia, and Hartwig H. Hochmair. 2023. "Temporal Relationship between Daily Reports of COVID-19 Infections and Related GDELT and Tweet Mentions" Geographies 3, no. 3: 584-609. https://doi.org/10.3390/geographies3030031
APA StyleOwuor, I., & Hochmair, H. H. (2023). Temporal Relationship between Daily Reports of COVID-19 Infections and Related GDELT and Tweet Mentions. Geographies, 3(3), 584-609. https://doi.org/10.3390/geographies3030031