
Simple Methods for Improving the Forensic Classification between Computer-Graphics Images and Natural Images

Abstract
1. Introduction
- We have investigated a simple yet effective method of carefully designed data-augmentation operations to improve the forensic classification performance between NIs and CG images;
- We have studied the combination of local and global prediction results in order to determine the loss function of a neural network and thus to make better use of the information contained in each image for achieving better classification results for the CG forensics problem;
- We have carried out experimental studies to test and validate the above two methods, which achieved an improvement in terms of the generalization capability and the test accuracy with reduced training sets, while remaining computationally efficient.
2. Related Work
3. Datasets and Network
3.1. Datasets
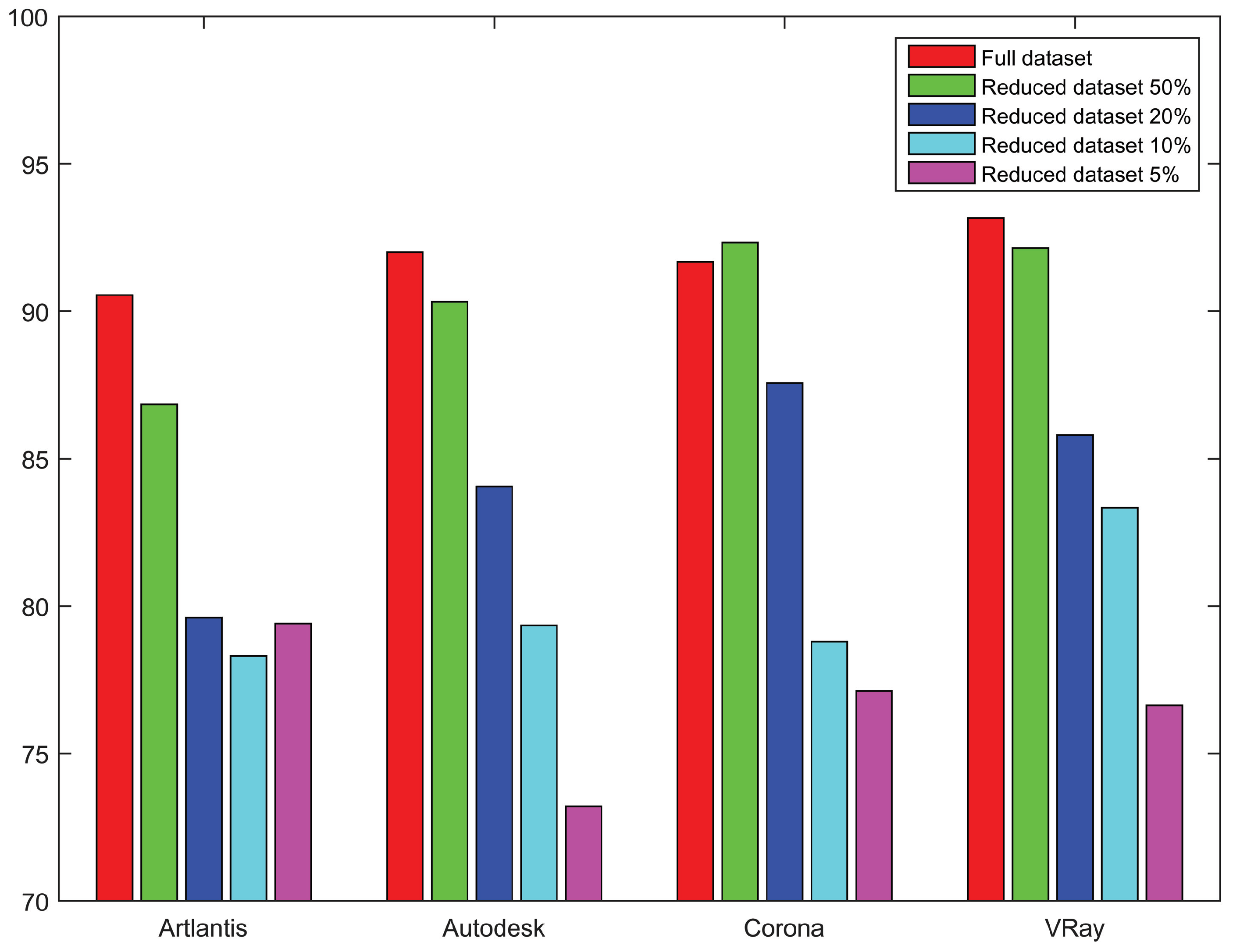
- Reduced datasets. In addition to conducting an experimental study on the full datasets detailed above, we aimed to carry out a comprehensive study of the forensic performance on reduced datasets, corresponding to the challenging situation with training data scarcity. Reducing the amount of data for training brings us closer to real-life application conditions, where obtaining large quantities of data is often complicated. In order to prepare experimental data for this challenging yet practical situation, we constructed different versions of reduced datasets from the full datasets of [5], with different ratios of images from the full datasets. More specifically, for each full training set with 10,080 images, we used four reduction ratios of 50%, 20%, 10% and 5% to construct reduced training sets with respectively 5040, 2016, 1008 and 504 images. For each ratio, we still had four training sets corresponding to the four rendering engines, and all the reduced training sets still remained balanced with an equal number of CG images and NIs. The test sets remained unchanged when the training was carried out on reduced or full training sets, so that we could fairly evaluate and compare the test classification performance under different qualities of training samples. We report experimental results on both full and reduced datasets in Section 5.
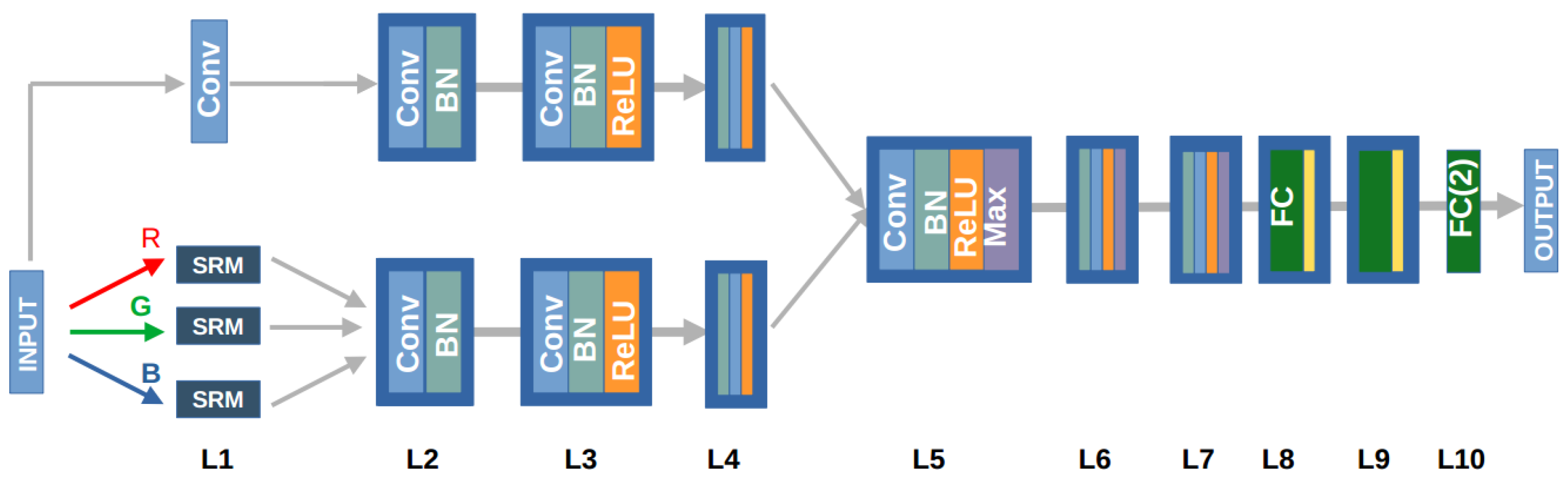
3.2. Neural Network
4. Proposed Methods
4.1. Motivations
4.2. Data Augmentation
4.2.1. Reducing the Impact of Processing History
4.2.2. Increasing the Diversity of Training Samples
| Algorithm 1 Color transfer from a source image to a target image. |
|
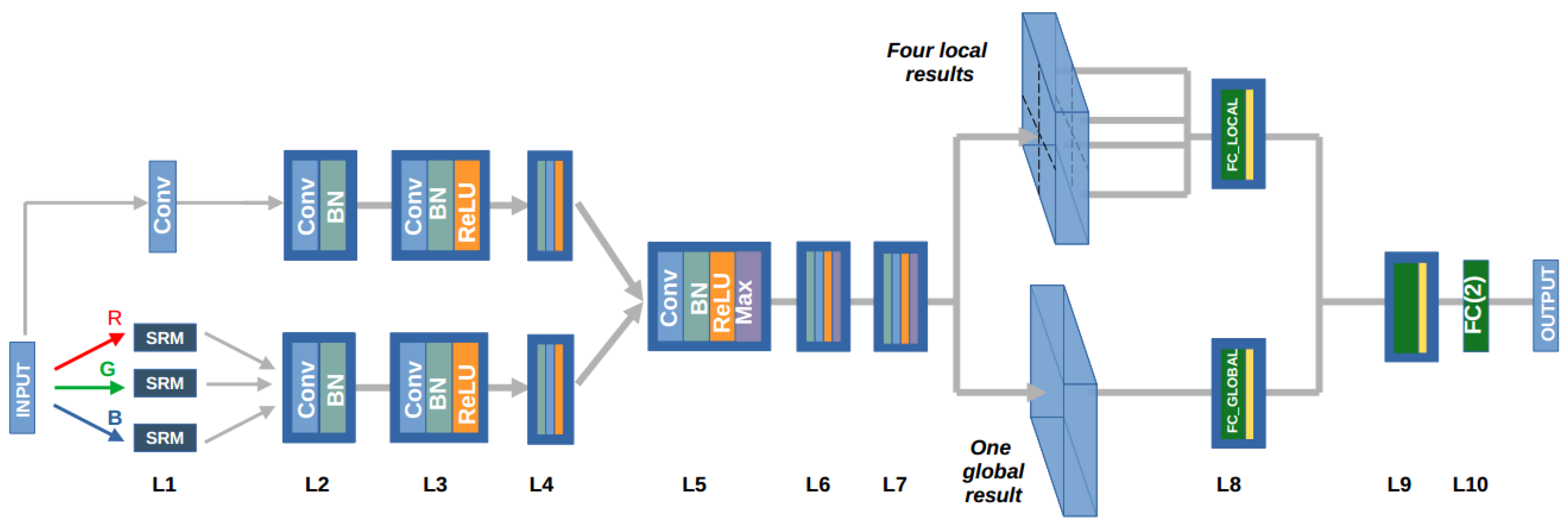
4.3. Combining Local and Global Predictions
5. Experimental Results
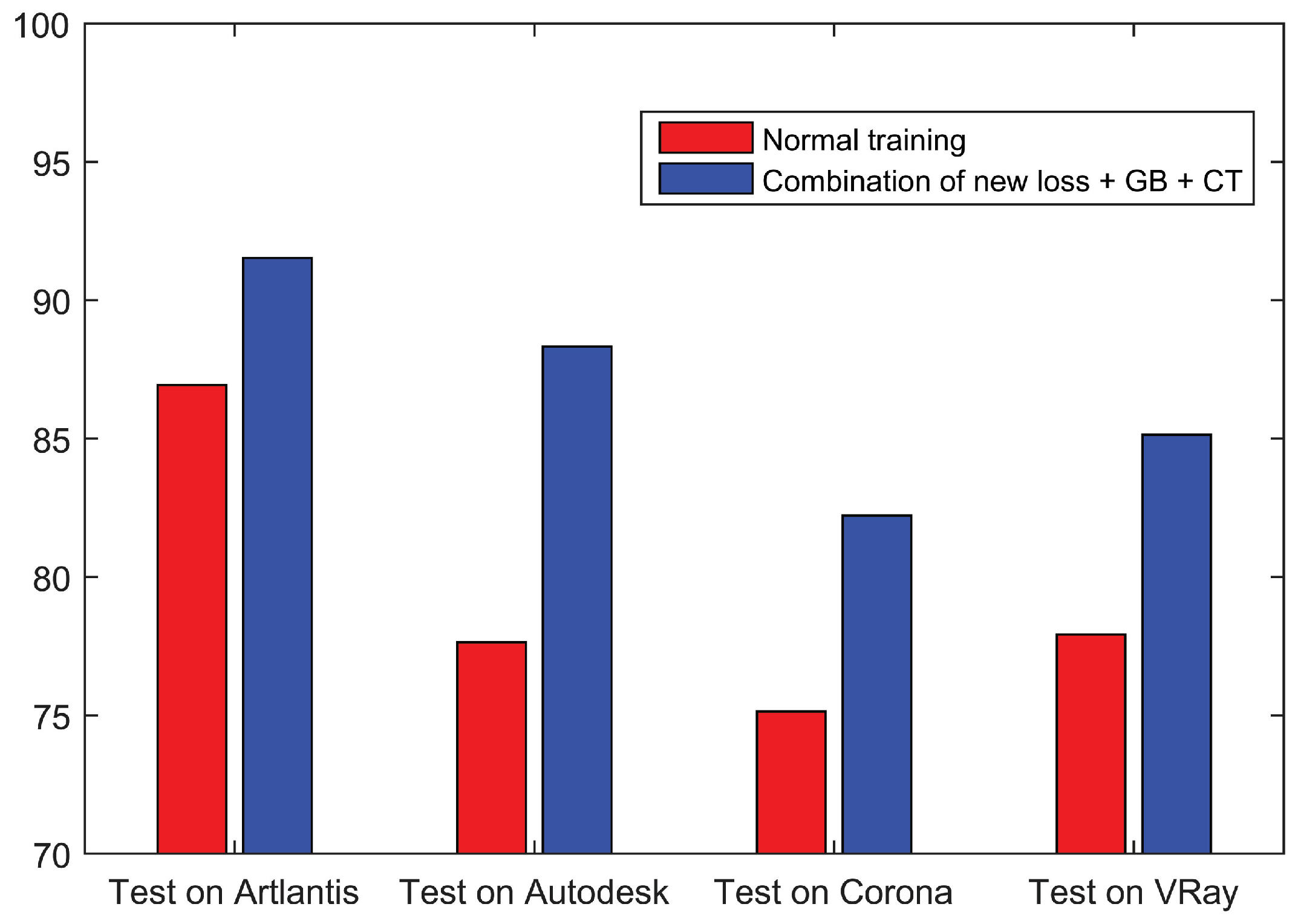
5.1. Results on Full Datasets
5.2. Results on Reduced Datasets
5.3. Comparisons in Terms of Test Accuracy and Training Time
5.4. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Verdoliva, L. Media forensics and deepfakes: An overview. IEEE J. Sel. Top. Signal Process. 2020, 14, 910–932. [Google Scholar] [CrossRef]
- Castillo Camacho, I.; Wang, K. A comprehensive review of deep learning-based methods for image forensics. J. Imaging 2021, 7, 69. [Google Scholar] [CrossRef] [PubMed]
- Lyu, S.; Farid, H. How realistic is photorealistic? IEEE Trans. Signal Process. 2005, 53, 845–850. [Google Scholar] [CrossRef]
- Quan, W.; Wang, K.; Yan, D.M.; Zhang, X. Distinguishing between natural and computer-generated images using convolutional neural networks. IEEE Trans. Inf. Forensics Secur. 2018, 13, 2772–2787. [Google Scholar] [CrossRef]
- Quan, W.; Wang, K.; Yan, D.M.; Zhang, X.; Pellerin, D. Learn with diversity and from harder samples: Improving the generalization of CNN-based detection of computer-generated images. Forensic Sci. Int. Digit. Investig. 2020, 35, 301023. [Google Scholar] [CrossRef]
- Chaosgroup Gallery. https://www.chaosgroup.com/gallery; Learn V-Ray Gallery. Available online: https://www.learnvray.com/fotogallery/ (accessed on 1 February 2024).
- Corona Renderer Gallery. Available online: https://corona-renderer.com/gallery (accessed on 1 February 2024).
- Shullani, D.; Fontani, M.; Iuliani, M.; Shaya, O.A.; Piva, A. VISION: A video and image dataset for source identification. EURASIP J. Inf. Secur. 2017, 2017, 15. [Google Scholar] [CrossRef]
- Dang-Nguyen, D.T.; Pasquini, C.; Conotter, V.; Boato, G. RAISE: A raw images dataset for digital image forensics. In Proceedings of the ACM Multimedia Systems Conference, Portland, OR, USA, 18–20 March 2015; pp. 219–224. [Google Scholar]
- Wang, K. Self-supervised learning for the distinction between computer-graphics images and natural images. Appl. Sci. 2023, 13, 1887. [Google Scholar] [CrossRef]
- Ng, T.T.; Chang, S.F.; Hsu, J.; Xie, L.; Tsui, M.P. Physics-motivated features for distinguishing photographic images and computer graphics. In Proceedings of the ACM International Conference on Multimedia, Singapore, 6–11 November 2005; pp. 239–248. [Google Scholar]
- Zhang, R.; Wang, R.D.; Ng, T.T. Distinguishing photographic images and photorealistic computer graphics using visual vocabulary on local image edges. In Proceedings of the International Workshop on Digital-Forensics and Watermarking, Shanghai, China, 31 October–3 November 2012; pp. 292–305. [Google Scholar]
- Sankar, G.; Zhao, V.; Yang, Y.H. Feature based classification of computer graphics and real images. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, Taipei, Taiwan, 19–24 April 2009; pp. 1513–1516. [Google Scholar]
- Özparlak, L.; Avcibas, I. Differentiating between images using wavelet-based transforms: A comparative study. IEEE Trans. Inf. Forensics Secur. 2011, 6, 1418–1431. [Google Scholar] [CrossRef]
- Wang, J.; Li, T.; Shi, Y.Q.; Lian, S.; Ye, J. Forensics feature analysis in quaternion wavelet domain for distinguishing photographic images and computer graphics. Multimed. Tools Appl. 2017, 76, 23721–23737. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Available online: http://www.deeplearningbook.org (accessed on 1 February 2024).
- Rahmouni, N.; Nozick, V.; Yamagishi, J.; Echizen, I. Distinguishing computer graphics from natural images using convolution neural networks. In Proceedings of the IEEE International Workshop on Information Forensics and Security, Rennes, France, 4–7 December 2017; pp. 1–6. [Google Scholar]
- He, P.; Jiang, X.; Sun, T.; Li, H. Computer graphics identification combining convolutional and recurrent neural networks. IEEE Signal Process. Lett. 2018, 25, 1369–1373. [Google Scholar] [CrossRef]
- Artlantis Gallery. Available online: https://artlantis.com/en/gallery/ (accessed on 1 February 2024).
- Autodesk A360 Rendering Gallery. Available online: https://gallery.autodesk.com/a360rendering/ (accessed on 1 February 2024).
- Fridrich, J.; Kodovský, J. Rich models for steganalysis of digital images. IEEE Trans. Inf. Forensics Secur. 2012, 7, 868–882. [Google Scholar] [CrossRef]
- Reinhard, E.; Ashikhmin, M.; Gooch, B.; Shirley, P. Color transfer between images. IEEE Comput. Graph. Appl. 2001, 21, 34–41. [Google Scholar] [CrossRef]
- Fernandez, P.; Couairon, G.; Jégou, H.; Douze, M.; Furon, T. The stable signature: Rooting watermarks in latent diffusion models. In Proceedings of the International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 22466–22477. [Google Scholar]
- Araghi, T.K.; Megías, D. Analysis and effectiveness of deeper levels of SVD on performance of hybrid DWT and SVD watermarking. Multimed. Tools Appl. 2024, 83, 3895–3916. [Google Scholar] [CrossRef]
- Corvi, R.; Cozzolino, D.; Zingarini, G.; Poggi, G.; Nagano, K.; Verdoliva, L. On the detection of synthetic images generated by diffusion models. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Guo, X.; Liu, X.; Ren, Z.; Grosz, S.; Masi, I.; Liu, X. Hierarchical fine-grained image forgery detection and localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 3155–3165. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tested on | Artlantis | Autodesk | Corona | VRay | Average | |
|---|---|---|---|---|---|---|
| Methods | ||||||
| Normal training [5] | 98.69% | 89.94% | 85.42% | 88.14% | 90.55% | |
| With aug. NA | 98.75% | 81.25% | 79.31% | 89.44% | 87.19% | |
| With aug. GB | 98.75% | 91.39% | 90.00% | 94.17% | 93.58% | |
| With aug. CJ | 98.89% | 88.06% | 87.92% | 92.36% | 91.81% | |
| With aug. CT | 98.61% | 87.64% | 85.97% | 90.97% | 90.80% | |
| With new loss | 99.58% | 80.56% | 83.61% | 86.11% | 87.47% | |
| With aug. GB + CJ | 98.33% | 89.58% | 91.11% | 95.00% | 93.51% | |
| With aug. GB + CT | 97.64% | 94.31% | 93.75% | 95.14% | 95.21% | |
| With new loss + GB + CT | 99.44% | 89.31% | 89.31% | 93.61% | 92.92% | |
| Tested on | Artlantis | Autodesk | Corona | VRay | Average | |
|---|---|---|---|---|---|---|
| Methods | ||||||
| Normal training [5] | 90.61% | 98.44% | 92.33% | 86.61% | 92.00% | |
| With aug. NA | 89.17% | 98.33% | 88.19% | 87.50% | 90.80% | |
| With aug. GB | 95.56% | 98.33% | 95.28% | 93.89% | 95.77% | |
| With aug. CJ | 90.69% | 98.98% | 95.14% | 92.64% | 94.36% | |
| With aug. CT | 90.28% | 98.75% | 95.28% | 90.42% | 93.68% | |
| With new loss | 91.25% | 98.61% | 95.83% | 90.42% | 94.03% | |
| With aug. GB + CJ | 94.73% | 98.06% | 96.25% | 93.61% | 95.66% | |
| With aug. GB + CT | 94.31% | 97.92% | 96.81% | 94.17% | 95.80% | |
| With new loss + GB + CT | 94.31% | 98.61% | 97.08% | 92.78% | 95.70% | |
| Tested on | Artlantis | Autodesk | Corona | VRay | Average | |
|---|---|---|---|---|---|---|
| Methods | ||||||
| Normal training [5] | 83.92% | 92.08% | 98.50% | 92.22% | 91.68% | |
| With aug. NA | 87.08% | 91.81% | 97.92% | 95.56% | 93.09% | |
| With aug. GB | 95.28% | 94.58% | 97.50% | 96.67% | 96.01% | |
| With aug. CJ | 88.19% | 92.92% | 98.89% | 95.00% | 93.75% | |
| With aug. CT | 84.44% | 92.64% | 98.89% | 92.08% | 92.01% | |
| With new loss | 89.31% | 94.03% | 99.17% | 93.89% | 94.10% | |
| With aug. GB + CJ | 94.31% | 94.31% | 96.94% | 95.83% | 95.35% | |
| With aug. GB + CT | 96.25% | 95.56% | 97.50% | 95.56% | 96.22% | |
| With new loss + GB + CT | 92.64% | 94.86% | 98.75% | 94.31% | 95.14% | |
| Tested on | Artlantis | Autodesk | Corona | VRay | Average | |
|---|---|---|---|---|---|---|
| Methods | ||||||
| Normal training [5] | 88.42% | 90.03% | 95.47% | 98.75% | 93.17% | |
| With aug. NA | 90.97% | 84.17% | 93.75% | 97.78% | 91.67% | |
| With aug. GB | 95.97% | 94.72% | 94.17% | 96.53% | 95.35% | |
| With aug. CJ | 89.44% | 87.92% | 96.53% | 97.64% | 92.88% | |
| With aug. CT | 93.19% | 91.39% | 96.81% | 98.33% | 94.93% | |
| With new loss | 94.31% | 92.64% | 95.97% | 98.61% | 95.38% | |
| With aug. GB + CJ | 94.86% | 93.06% | 94.44% | 95.69% | 94.51% | |
| With aug. GB + CT | 97.08% | 95.14% | 96.25% | 97.50% | 96.49% | |
| With new loss + GB + CT | 97.64% | 95.83% | 96.94% | 98.33% | 97.19% | |
| Trained on | Full | Reduced 50% | Reduced 20% | Reduced 10% | Reduced 5% | |
|---|---|---|---|---|---|---|
| Methods | ||||||
| Normal training [5] | 90.55% | 86.84% | 79.61% | 78.30% | 79.41% | |
| With aug. GB | 93.58% | 86.49% | 83.12% | 80.17% | 84.41% | |
| With aug. CJ | 91.81% | 87.47% | 86.60% | 80.77% | 78.20% | |
| With aug. CT | 90.80% | 89.41% | 88.40% | 84.37% | 82.02% | |
| With new loss | 87.47% | 86.11% | 85.10% | 80.52% | 77.99% | |
| With aug. GB + CT | 95.21% | 93.23% | 89.55% | 86.77% | 83.48% | |
| With new loss + GB + CT | 92.92% | 92.61% | 91.32% | 87.12% | 86.81% | |
| Trained on | Full | Reduced 50% | Reduced 20% | Reduced 10% | Reduced 5% | |
|---|---|---|---|---|---|---|
| Methods | ||||||
| Normal training [5] | 92.00% | 90.32% | 84.06% | 79.34% | 73.20% | |
| With aug. GB | 95.77% | 93.58% | 89.83% | 80.73% | 75.35% | |
| With aug. CJ | 94.36% | 91.35% | 87.12% | 82.33% | 76.56% | |
| With aug. CT | 93.68% | 92.92% | 85.00% | 84.38% | 74.79% | |
| With new loss | 94.03% | 92.12% | 87.29% | 81.74% | 77.36% | |
| With aug. GB + CT | 95.80% | 93.27% | 88.68% | 83.47% | 81.39% | |
| With new loss + GB + CT | 95.70% | 96.25% | 87.61% | 87.88% | 82.33% | |
| Trained on | Full | Reduced 50% | Reduced 20% | Reduced 10% | Reduced 5% | |
|---|---|---|---|---|---|---|
| Methods | ||||||
| Normal training [5] | 91.68% | 92.33% | 87.57% | 78.79% | 77.12% | |
| With aug. GB | 96.01% | 93.85% | 89.76% | 85.63% | 81.18% | |
| With aug. CJ | 93.75% | 86.60% | 85.84% | 75.52% | 73.78% | |
| With aug. CT | 92.01% | 91.98% | 88.96% | 82.08% | 79.65% | |
| With new loss | 94.10% | 93.09% | 90.38% | 78.72% | 78.02% | |
| With aug. GB + CT | 96.22% | 94.65% | 90.73% | 88.33% | 80.52% | |
| With new loss + GB + CT | 95.14% | 95.00% | 91.18% | 89.00% | 84.72% | |
| Trained on | Full | Reduced 50% | Reduced 20% | Reduced 10% | Reduced 5% | |
|---|---|---|---|---|---|---|
| Methods | ||||||
| Normal training [5] | 93.17% | 92.15% | 85.80% | 83.33% | 76.63% | |
| With aug. GB | 95.35% | 92.05% | 87.78% | 86.63% | 82.64% | |
| With aug. CJ | 92.88% | 93.37% | 88.16% | 81.01% | 74.97% | |
| With aug. CT | 94.93% | 92.22% | 89.79% | 84.97% | 80.07% | |
| With new loss | 95.38% | 92.95% | 88.72% | 83.54% | 77.90% | |
| With aug. GB + CT | 96.49% | 96.15% | 93.06% | 89.41% | 82.15% | |
| With new loss + GB + CT | 97.19% | 94.10% | 90.38% | 89.72% | 86.46% | |
| Methods | Training Time | Additional Time Compared to Normal Training |
|---|---|---|
| Normal training | 347 | - |
| With additional enhanced training [5] | 672 | +325 |
| With aug. GB | 356 | +9 |
| With aug. GB + CT | 356 | +9 |
| With new loss | 355 | +8 |
| With new loss and aug. of GB + CT | 368 | +21 |
| Tested on | Artlantis | Autodesk | Corona | VRay | Average | |
|---|---|---|---|---|---|---|
| Trained on | ||||||
| Artlantis (full) | 97.25/97.64 | 95.69/94.31 | 92.72/93.75 | 94.50/95.14 | 95.04/95.21 | |
| Autodesk (full) | 94.42/94.31 | 97.61/97.92 | 95.14/96.81 | 91.78/94.17 | 94.74/95.80 | |
| Corona (full) | 93.61/96.25 | 92.97/95.56 | 97.86/97.50 | 95.61/95.56 | 95.01/96.22 | |
| VRay (full) | 94.61/97.08 | 93.92/95.14 | 96.83/96.25 | 98.28/97.50 | 95.91/96.49 | |
| Tested on | Artlantis | Autodesk | Corona | VRay | Average | |
|---|---|---|---|---|---|---|
| Trained on | ||||||
| Reduced Artlantis (20%) | 96.25/95.00 | 81.39/90.14 | 83.19/87.22 | 84.86/92.92 | 86.42/91.32 | |
| Reduced Autodesk (20%) | 82.36/83.89 | 94.31/96.67 | 82.36/86.39 | 80.56/83.47 | 84.90/87.61 | |
| Reduced Corona (20%) | 80.97/89.17 | 85.00/89.86 | 93.06/93.33 | 87.50/92.36 | 86.63/91.18 | |
| Reduced VRay (20%) | 87.78/89.58 | 82.50/89.86 | 90.00/90.00 | 92.64/92.08 | 88.23/90.38 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bouhamidi, Y.; Wang, K. Simple Methods for Improving the Forensic Classification between Computer-Graphics Images and Natural Images. Forensic Sci. 2024, 4, 164-183. https://doi.org/10.3390/forensicsci4010010
Bouhamidi Y, Wang K. Simple Methods for Improving the Forensic Classification between Computer-Graphics Images and Natural Images. Forensic Sciences. 2024; 4(1):164-183. https://doi.org/10.3390/forensicsci4010010
Chicago/Turabian StyleBouhamidi, Yacine, and Kai Wang. 2024. "Simple Methods for Improving the Forensic Classification between Computer-Graphics Images and Natural Images" Forensic Sciences 4, no. 1: 164-183. https://doi.org/10.3390/forensicsci4010010
APA StyleBouhamidi, Y., & Wang, K. (2024). Simple Methods for Improving the Forensic Classification between Computer-Graphics Images and Natural Images. Forensic Sciences, 4(1), 164-183. https://doi.org/10.3390/forensicsci4010010