1. Introduction
The healthcare framework in the UK, the National Health Service (NHS), is structured into two overarching components. The first component is responsible for formulating strategies, setting policies, and managing the system, whereas the second primarily focuses on providing medical services [
1]. This latter component is further subdivided into three distinct tiers. Primary care encompasses general practitioners (GPs), community health services, pharmacists, etc. Secondary care involves hospital-based healthcare accessible through primary care providers. Specialised hospitals provide tertiary care. Primary care professionals have the discretion to refer a patient to another healthcare provider within the primary care setting (community health services) or to secondary care (hospitals) if the patient’s medical condition demands more specialised treatment or further investigation.
Community health services aim to provide a wide range of services to improve the health and wellness of people from birth to the end of life and allow them to live independently in their own homes by bringing those forms of care closer to one’s home [
2]. Therefore, community services work closely with all the primary, secondary, and tertiary care system providers, such as GPs, pharmacies, and hospitals. For instance, the hospital determines when it is safe to discharge a person and implements a discharge plan. During this decision-making process, the hospital staff is required to determine whether the person needs to be referred for ongoing care in the community setting after discharge. The community care teams accept referrals from 111 (24 h National Health Service advice), the ambulance service (AS), the rapid-access therapy team (RATT), fall pickup, GPs, and acute hospitals after discharging patients [
2,
3]. While ambulance services focus on emergency transportation, rapid-access therapy teams aim to provide timely care at home, helping individuals avoid hospitalisation whenever possible. Similar to the RATT, fall pickup services provide appropriate care for falls and related injuries among elderly people to prevent hospital admissions. Ambulance services in the UK are under the control of various bodies, such as local authorities, commissioning bodies, and NHS trusts. Ambulance services differ from tertiary care, which is responsible for highly specialised medical care provided to patients with severe, complex, or life-threatening conditions. However, ASs play a crucial role in connecting patients to appropriate levels of healthcare, including tertiary services when required.
Variations in the delivery of services seems to be proportional to an imbalance between the available capacity and the demand in healthcare systems such as community health services, resulting in extended waiting periods [
4]. Efficient triage and referral assessments play a crucial role in ensuring prompt medical intervention to prevent fatalities and disabilities [
5]. Nevertheless, the existing manual referral assessment method is time-consuming, and referrals from general practitioners for specific disease conditions, such as heart failure, often lack accuracy due to ambiguous initial symptoms.
According to Kim et al. [
6], heart failure (HF) impacts over 900,000 individuals in the United Kingdom, leading to substantial morbidity and mortality, frequent hospital admissions, and a diminished quality of life. Machine learning for the triaging of patients with heart failure can provide clinical benefits by improving decision making in individual care, assessing disease severity [
7], and minimising the waiting times. The American College of Cardiology suggests crucial in-hospital data components for determining the care and results of patients with heart failure [
8]. These include demographic information, medical history, current home medications, clinical presentation details, hospitalisation course, laboratory test results, imaging studies, cardiac catheterisation information, administered treatments, and any complications arising during the hospital stay. Primary care professionals record this information in electronic health records using various formats, such as digital notes, handwritten notes, images, videos, emails, and other media [
9]. The patient records mentioned above can be optimally utilised for training machine learning models to perform the triaging for patients with heart failure in community settings through a streamlined feature-engineering process, enhancing the data’s quality and relevance for a comprehensive analysis.
This study aimed to develop a quantitative data-driven machine learning approach to analyse, sort, and categorise patients according to their medical condition using streamlined feature-engineering methods. Also, this research employed three distinct classification algorithms to forecast the triaging outcomes, and a retrospective examination was conducted to analyse the predictive performance of these algorithms. The research stages included data preprocessing and feature-engineering techniques such as data imputation and normalisation, correlation analysis, and feature encoding and ranking. The predictive modelling employed several machine learning algorithms for triaging patients with heart failure in community healthcare services.
This paper is conscientiously structured in a way that allows the readers to logically progress through the research.
Section 2 presents the related works discussing human-based, online-platform-based, and machine learning-based triaging approaches.
Section 3 provides a detailed description of the dataset, data preprocessing techniques, and the feature-engineering methods used to perform the research.
Section 4 is a comprehensive analysis of the outcomes of various classification algorithms, where XGBoost demonstrated the highest efficiency in triaging patients with heart failure.
Section 5 completes the paper with a discussion and a direction for future works.
2. Related Works
Research on the systematic methods used for triaging patients from prior studies helped us to categorise those methods into traditional human-based, telephone- or online platform-based, and machine learning-based methods. After differentiating these systems, a retrospective survey supported us in identifying the current gap within each system. The study presented below addresses the identified gaps and contributes valuable insights to the field.
2.1. Human-Based Triage
Health professionals, especially triage nurses across the globe, use numerous methods to prioritise patients at various levels of the treatment process. For example, the Emergency Severity Index is used in the United States of America, the Canadian Triage Acuity Scale is followed in Canada, the Australasian Triage Scale in Australia, and the Manchester Triage Scale is used by many European countries, especially the United Kingdom and Germany [
10].
Moxham and McMahon-Parkes [
11] conducted a study to estimate the effect of triaging patients referred to an acute National Health Service hospital by an advanced nurse practitioner. Their study aimed to identify whether waiting time and hospital admissions would be reduced as a result. Also, their study examined whether critical investigation and treatments were accelerated through a triaging process performed by an advanced nurse practitioner. The research undertaken by Jennings [
12] and Woo, Lee, and Tam [
13] discussed the efficacy of employing advanced nurse practitioners to fulfil service requirements. The triage role of advanced nurse practitioners was directed and structured in accordance with the Revised Standards for Quality Improvement Reporting Excellence guidelines [
14]. The introduction of advanced nurse practitioners in patient triage roles resulted in a statistically notable decrease in the waiting time for patient evaluation. The limitations included the generalisability of the results as the study was based on retrospective data collected from medical records, which also contained heterogeneous samples. Furthermore, the variations in the skills and experience of the advanced nurse practitioners who participated in the study were also a limitation. According to Göransson, Persson, and Abelsson [
15], experience and knowledge in primary care can vary among nurses, depending on their experience in the field. Their research sought to delineate the background of nurses involved in triaging patients at walk-in clinics within primary healthcare centres in Sweden. Most medical professionals can gain expertise through long-term work. In contrast, machine learning models can identify patterns and gain understanding quickly, significantly speeding up the decision-making process.
The human-based triage method does have some crucial drawbacks, which include the increase in triage workload when a patient needs to be referred to speciality care. Usually, in a community setting, a specially trained triage nurse is assigned to read and analyse a patient’s past medical history, current medications, test/lab results, together with the current symptoms of the patient, to refer them to special services. The lack of experienced triage nurses and the exponential growth in the time needed to assess a patient’s past medical history for decision making underline the necessity for the implementation of automated AI-supported triaging systems.
2.2. Telephone- or Online Platform-Based Triage
The NHS introduced various methods, such as phone, email, and online triage systems, as an alternative to face-to-face consultations, which indeed increase the workload. Patients can describe their problems through online triage systems, emails, or a phone. Afterwards, a general practitioner contacts the patient for a telephone consultation or to schedule an in-person appointment if required.
The study conducted by Eccles [
16] aimed to investigate usage patterns and gather insights into patients’ encounters with an online triage system. In the abovementioned retrospective study, data routinely collected from all practices utilising the ‘askmyGP’ platform throughout the study period were analysed using a combination of quantitative and qualitative methods. Patients commonly use the platform for inquiries about medications, reporting specific symptoms, and administrative requests. The number of users registered to the platform is broad. The highest proportion of users is made up of young patients, which points to the difficulty of elderly people in using online platforms.
2.3. Machine Learning-Based Triage
In the study conducted by Raita [
17], various machine learning models, including lasso regression, random forest, gradient-boosted decision tree, and deep neural network, were employed to predict clinical outcomes. They assessed the outcomes by comparing them qualitatively with the performance of a conventional human-based triaging system, called Emergency Severity Index (ESI), in the USA. The ESI is a tool used in emergency department (ED) triage within the healthcare system. It has five levels, from 1, which is the “most urgent,” to 5, the “least urgent.” For example, level 3 or “urgent” includes patients with serious symptoms but stable vital signs. The research concludes that machine learning models displayed excellent predictive performance for hospitalisations and critical care outcomes compared to the conventional reference model.
Levin [
18] introduced e-triaging, employing a machine learning model for triaging data to predict critical care necessity, emergency procedures, and hospitalisation. The study affirmed the model’s accuracy in categorising level 3 patients based on the ESI. Machine learning’s utility in clinical settings allows the classification of patients’ subgroups according to the predicted outcomes [
19]. The proposed approach ensured stable predictions [
20] and facilitated variable selection during model construction, especially for digital health record applications. The model demonstrated superior accuracy in classifying ESI level 3 patients compared to conventional methods, underscoring the potential of predictive analysis in triage decision making. However, the limitations included potential retrospective data entry errors and dependence on a robust and precise electronic health record system.
Few studies have used machine learning in emergency departments in a hospital setting [
17]. However, machine learning applications for triaging in community care remain undiscovered. This study concentrates explicitly on triaging patients with heart failure in community care. It gives an additional perspective to implementing AI-supported triaging technologies for a wider range of diseases.
3. Computational Framework for Processing and Triaging Using Patient Data
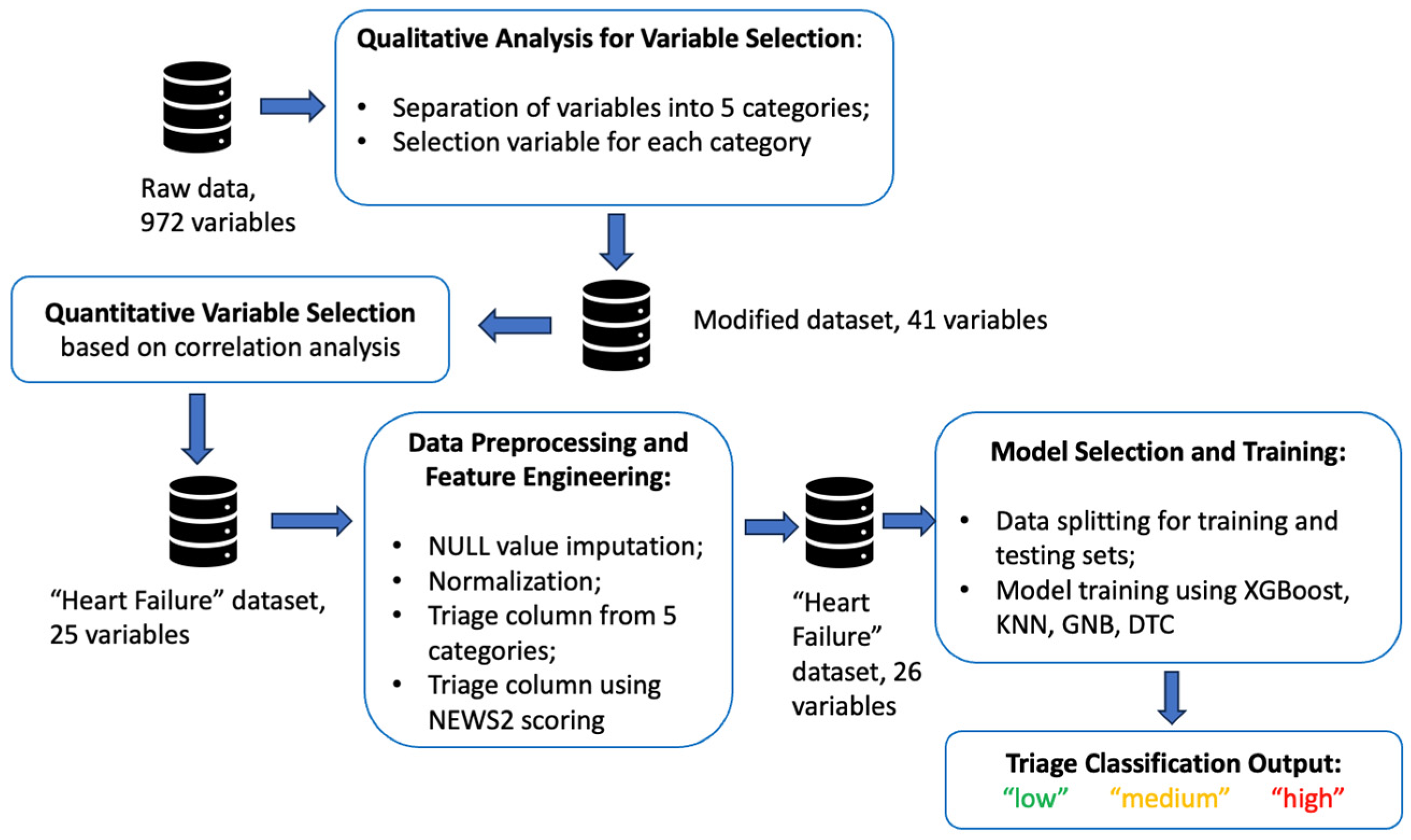
The proposed framework with various stages of data processing is represented in
Figure 1.
In the initial stage, qualitative research data interpretation [
21] was adopted to determine the most necessary variables from the collected dataset, whereas quantitative research, which involved computational and statistical methods [
22] for data analysis, was performed throughout our study. The following subsections provide a more detailed description of the implementation stages.
3.1. Medical Dataset
The dataset used for the current study was primarily utilised by Hong [
23] for the prediction of hospital admissions to the emergency department. The data collected from three EDs covered the period from March 2013 to July 2017 and included all the admissions to and discharges from the hospitals. The dataset consisted of 560,486 patient records collected during their hospital visits. The 972 variables in the dataset contained the patients’ past medical history, vitals, signs and symptoms, test results, and medications.
Variable selection was one of the most critical tasks in this study because the probability of heart failure and other cardiological problems could be determined by multiple factors. The choice of the most powerful variables could increase the heart failure prediction rate and speed up the diagnostic process. This study incorporated several qualitative research techniques to select the majority of informative features and utilise them for predictive modelling.
The feature and model selection steps are explained below.
3.2. Variable Selection Using Qualitative Analysis
The variables from the raw data were grouped into five categories such as “Demographics”, “Past Medical History”, “Vitals”, “Medications”, and “Symptoms”. The demographics included age and gender variables. According to Edelmann [
24], multiple chronic conditions and death rates in the case of heart failure increase with age. The study presented by Coats [
25] states that the typical pathophysiology leading to heart failure occurs in older patients. A group of disease conditions that can affect both heart and blood vessels are classified as cardiovascular disease (CVD), thereby including coronary heart disease (CHD), coronary artery disease (CAD), acute coronary vascular disease (acute CVD), and many other conditions [
26]. As specified by Boateng and Sanborn [
27], an acute myocardial infarction (AcuteMI) is a subset of acute coronary syndrome that affects blood vessels and the heart. Also, multiple myeloma [
28], hypothyroidism [
29], rheumatoid arthritis [
30], and hypertension [
31] may contribute to heart failure. Vital signs such as heart rate [
32], systolic blood pressure [
33], diastolic blood pressure [
34], respiratory rate [
35], oxygen saturation levels [
36], and temperature need to be taken into account, one by one, while diagnosing and triaging a patient with heart failure. In compliance with NHS England [
37], shortness of breath, breathing difficulty, hypertension, and oedema are some of the main symptoms of heart failure, whilst cough, wheezing, and palpitations are less-common symptoms. Therefore, the variables related to all the abovementioned categories were selected to create a “Heart Failure” dataset, which was used in the subsequent steps.
3.3. Variable Selection Using Quantitative Analysis
A quantitative analysis method was used to identify more correlated variables among the selected variables. This step involved a correlation matrix to identify the columns that were related to each other. In this study, Spearman’s correlation coefficient, which belongs to a distribution-free rank statistic, was used to measure the strength of the monotonic association between the two [
38].
The correlation matrix helped us to identify the most correlated variables and create the heart failure dataset from the raw data. It is important to note that the newly created dataset did not include a particular column describing whether the patient had heart failure or not or any other columns containing the triage values of a patient with heart failure. Thus, only parameters highly correlated and contributing to the development of cardiological problems were included in the dataset. For instance, the column of age had a positive correlation with hypertension, with a value of 0.53, which made it evident that hypertension increased progressively with age [
39].
After removing weakly correlated variables using qualitative and quantitative methods, the final heart failure dataset was represented by 25 columns. After the additional feature-engineering procedure, these columns were used for the training and testing of the machine learning models.
3.4. Feature Engineering
Nargesian [
40] stated that feature engineering involves enhancing the performance of predictive models on a dataset by modifying or transforming its set of features. In this study, the dataset lacked a triage column, which would have given the values obtained after triaging patients with heart failure. Therefore, we used feature-engineering techniques to create the missing triage column from the existing data and then train the machine learning models with the feature-enriched dataset. Prior to feature engineering, the null value imputation technique was applied to the heart failure dataset. The missing values were imputed using the K-Nearest Neighbour approach. The process of generation of a triage column using the existing variables of different categories of features can be described in the following steps.
3.4.1. Generating Triage Values from Different Categories
In this step, a column for each category was created using a scoring system in each category variable such as “Past Medical History”, “Medication”, and “Symptoms”. Every variable in these categories was based on the Boolean principle. If the patient records showed past medical history and medication intake or indicated any symptom related to cardiovascular problems, a value of 1 was imputed in the column. Alternatively, a value of 0 demonstrated the absence of these parameters in the medical records. This method of assigning scores depended on the number of variables in the category.
Therefore, the score for each variable can be represented with the following equation:
where n is the total number of variables, and n
p is the number of variables with a value of 1.
For instance, the “Past Medical History” category consisted of four columns with Boolean values. Using the above formula, the triage column for past medical history generated a value of 0.25 if the patient had one medical condition in their past medical history records. If the patient had two medical conditions in their past medical history, then the score calculated would be 0.5. Thus, the output of the feature generation process showed three new columns with the triage scores for the categories of past medical history, medications, and symptoms for every patient.
3.4.2. Generating Triage Values Using NEWS2 Score
The National Early Warning Score 2 (NEWS2) serves as the established track and trigger system for evaluating the severity of illness and the potential risk of deterioration in patients with acute health conditions. This system is adopted within the United Kingdom and internationally [
41]. It is used as an assessment tool for illness severity and deterioration risk. According to the Royal College of Physicians [
42], the NEWS2 is based on a straightforward aggregating approach, which scores the physiological measurements during a routine healthcare check when a patient visits a hospital. The scoring system is grounded in six basic physiological parameters, including respiratory rate, oxygen saturation, systolic blood pressure, pulse rate, level of consciousness, and temperature.
Each parameter is assigned a score based on its measured value, with the score magnitude indicating the degree of deviation from the norm. For individuals who receive supplemental oxygen to achieve a certain level of oxygen saturation, an additional 2 points are added to the aggregated score. This pragmatic approach highlights a central focus on standardised practices across the entire healthcare system. It underscores the utilisation of physiological parameters that are already routinely assessed in NHS hospitals and prehospital care, documented on a standardised clinical chart known as the NEWS2 chart.
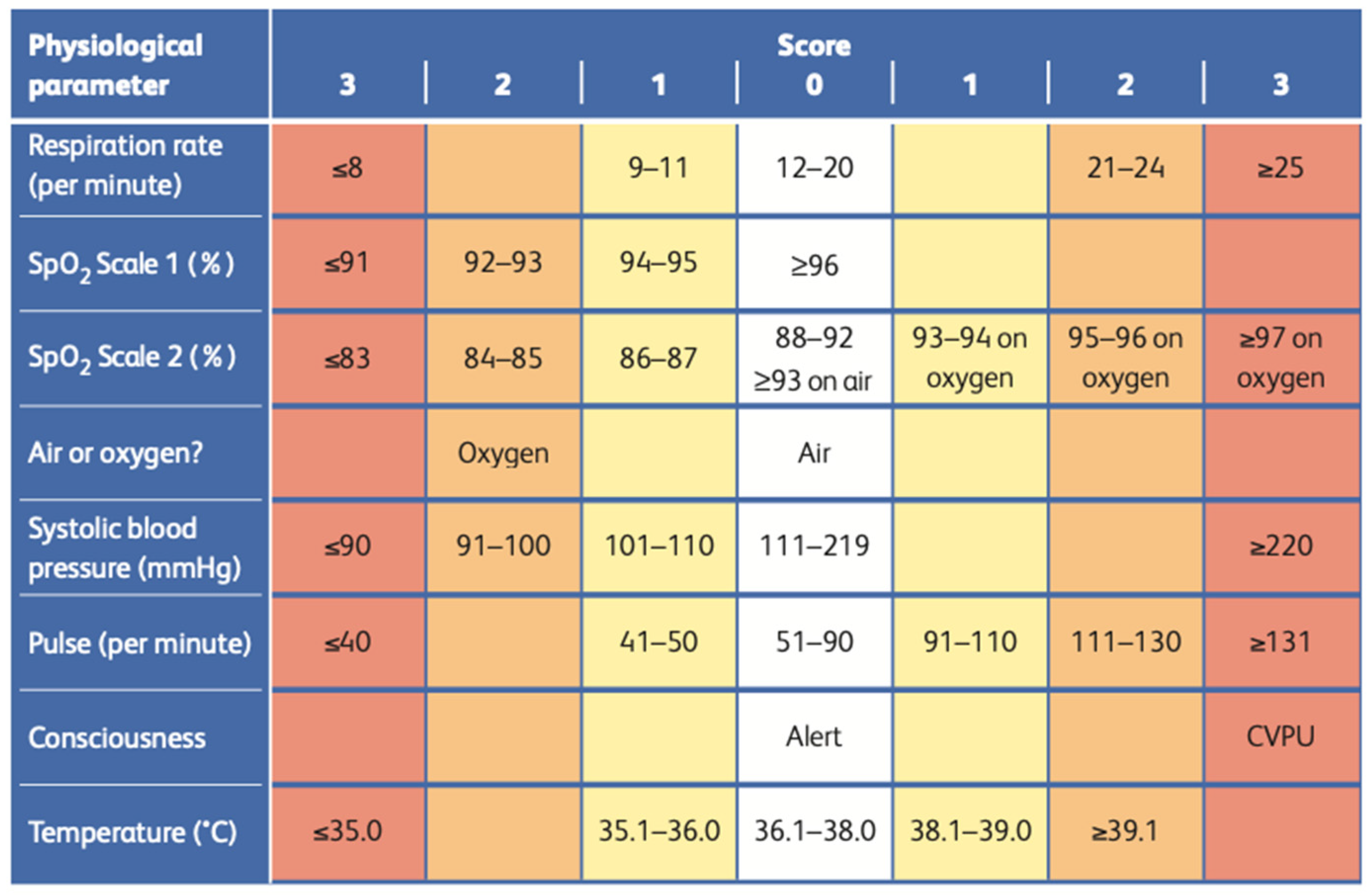
Figure 2 represents the chart of the NEWS2 scoring system consisting of the scores and values of all six parameters. The scoring system is divided into four levels of severity, scoring from 0 to 3. The “vitals” category of the heart failure dataset used in this study contains respiratory rate values, SpO
2 scale values, air or oxygen values, systolic blood pressure values, pulse values, and temperature. The dataset does not have consciousness values in the vitals category, which is considered one of the dataset’s limitations. However, the dataset includes all six critical parameters used in the NEWS2 scoring system to obtain better triage results.
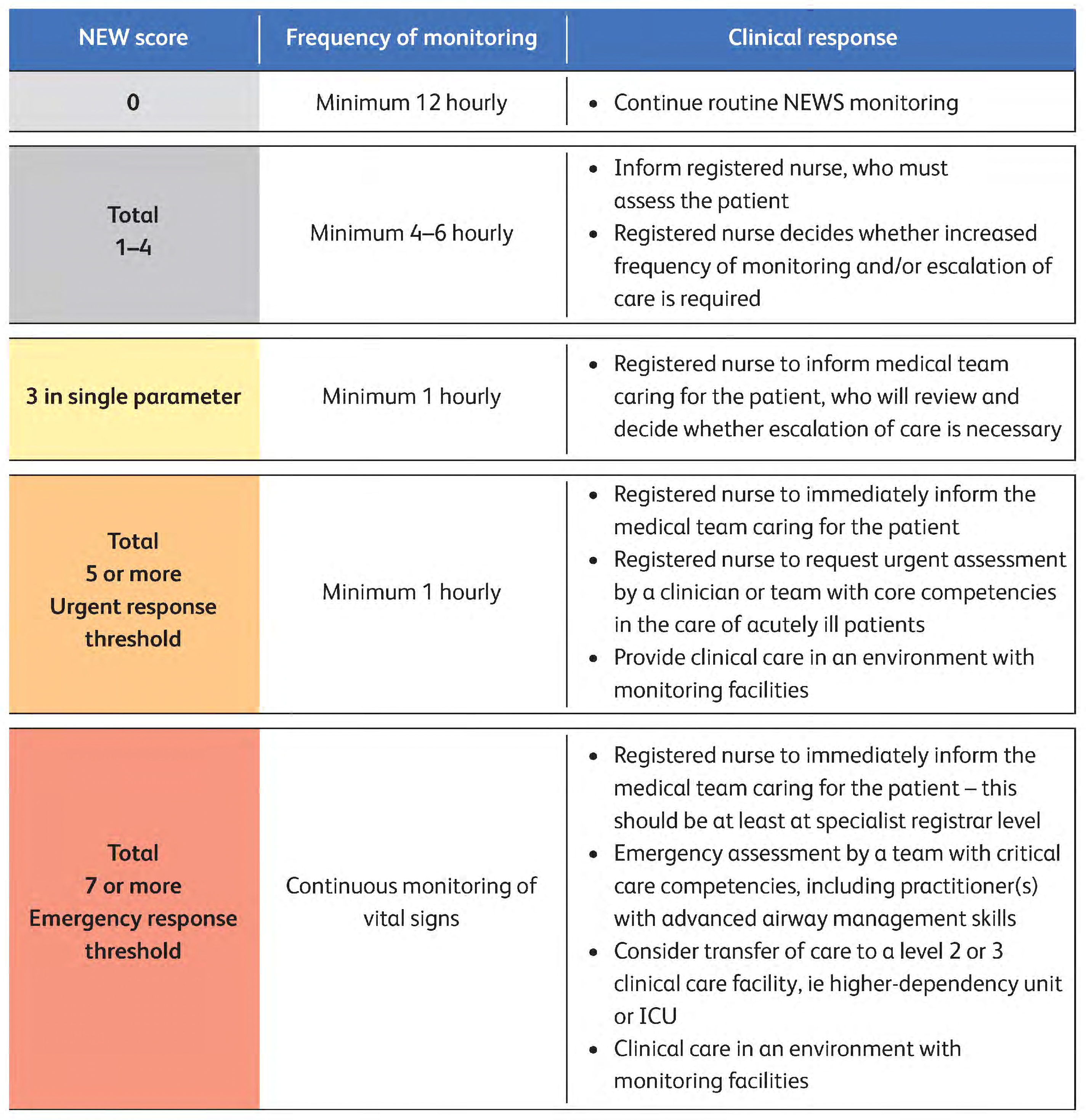
Figure 3 represents the clinical response and frequency of monitoring patients depending on the NEWS2 score. If the patient’s NEWS2 score is 0, then the patient needs to continue routine NEWS2 monitoring at a frequency of a minimum of 12 h and needs no triaging at this stage. If the patient’s NEWS2 score is between 1 and 4, then the patient needs attention within 4–6 h. If any single parameter in the NEWS2 has a score of 3, then the patient needs to be attended to within 1 h. Also, a score of a total of 5 needs attention in less than 1 h. If the NEWS2 score is 7 or more, then the patient needs immediate attention. In such a situation, the registered nurse must report the case to the medical team immediately, and the patient must be continuously monitored for vital signs.
This current research used the NEWS2 scoring system to generate a new column. Subsequently, we compared this column with others created using the scoring system for different categories, aiming to estimate the final triage column. As a result, the final triage column contained three values: a value of 0, indicating the patient as a “low”-priority case; a value of 1, showing a “moderate” priority; and a value of 2 points for “high”-priority cases. The final triage value for each row was determined using the four conditions represented below.
If the value is 1 in any of the three columns, then the patient would be considered a “high”-priority case, and the triage_target value would be 1.
If the total value of the three columns is between 0 and 0.25, the patient would be considered a “low”-priority case, and the triage_target would be 0.
If the estimated value of the three columns is between 0.25 and 0.75, the patient would be considered a “moderate”-priority case, and the triage_target value would be 1.
If the estimated value of the three columns is greater than 0.7, the patient would be considered a “high”-priority case, and the triage_target value would be 2.
3.4.3. Normalisation
Normalisation, the final step of feature engineering, transforms individual features to a unit norm scale to improve a model’s performance and stability in training [
43]. Using the normalisation technique in feature engineering ensures that all features contribute equally to the model’s training process and eliminates the dominance of features with larger values.
In this study, the dataset of 26 variables, including the triage column, created using the feature-engineering process underwent normalisation. Normalisation scaled all the numerical values in the column within the range between 0 and 1. It helped us avoid biased model performances and difficulties in the learning process.
Table 1 represents the variable name, description, and the datatype of each variable in the derived heart failure dataset.
Furthermore, after normalisation, the dataset was divided into training and testing parts. The training part included two categories of data: train_data, in 26 columns, and target_data, in the final triage column. Some classification algorithms do not accept decimal values as classes; therefore, the final triage column was labelled. After the label-encoding process, the train_data and target_data were split into two different datasets, where 80% of the data was used for training and 20% was used for testing.
3.5. Model Selection and Training
This study can be considered in the classification problem category because it aimed to classify patients with three stages of triaging depending on the severity of the condition. Therefore, the model learned how to separate new observations into three stages of triaging with low, medium, and high priorities. The extreme gradient-boosting (XGBoost) machine learning algorithm was chosen as the classification approach for the current cardiological problem. XGBoost is a gradient-boosting technology that utilises an inclination-boosting system based on a decision tree [
44]. The choice of the algorithm was based on the state-of-the-art literature applied to similar problems [
45]. For the performance comparison, additional tests were utilised with the K-Nearest Neighbour (KNN), Gaussian Naïve Bayes (GNB), and decision tree (DTC) classification algorithms.
4. Results and Analysis
This chapter presents a comparative study of the results generated by XGBoost and other algorithms for multi-class classification. The performance metrics such as accuracy, precision, F1-score, and recall were calculated from the confusion matrix.
The predicated and test data had three classes that represented “low”, “medium”, and “high” priorities in the triaging outputs. The “low” priority was represented by a value of 0, the “medium” priority had a value of 1, and the “high” priority was denoted by a value of 2, respectively.
4.1. Analysing the Results of XGBoost
As mentioned above, the XGBoost machine learning model was chosen to triage patients with cardiological conditions.
Table 2 describes the evaluation measures, which help us identify the machine learning model’s efficiency in predicting class 0, 1, and 2 patients.
For class 0, the sensitivity of the model was 1.000, and the specificity was 0.9970. The precision, accuracy, and F1-score were 0.9996, 0.9996, and 0.9998, respectively. The other values, such as the negative predictive value, the false-positive rate, the false discovery rate, and the false-negative rate, were 0.9998, 0.0030, 0.0004, and 0.0000, respectively. The false-positive rate, the false discovery rate, and the false-negative rate were close to zero, which indicated a high model performance in predicting class 0.
The sensitivity and specificity for class 1 prediction were 0.9966 and 0.9998, respectively. The precision, accuracy, and F1-score were 0.9987, 0.9995, and 0.9976. Finally, the negative predictive value, the false-positive rate, the false discovery rate, and the false-negative rate were 0.9996, 0.0002, 0.0013, and 0.0034, respectively. The values of the false discovery rate, the false-negative rate, and the false-positive rate in predicting class 1 were close to zero and indicated a very high precision for the detection of class 1.
The sensitivity and specificity metrics for class 2 prediction were 0.9909 and 1.0000. The precision, accuracy, and F1-score calculated from the confusion matrix of class 2 were 0.9977, 0.9998, and 0.9943, respectively. Finally, the negative predictive value, the false-positive rate, and the false discovery rate derived from the confusion matrix of class 2 were 0.9998, 0, 0.0023, and 0.0091. Here, the false-positive rate, the false discovery rate, and the false-negative rate were close to zero or had a value of zero. It demonstrated the efficiency of XGBoost classification in the detection of “high”-priority class 2.
The performance metrics obtained for the above three classes proved the efficiency of the XGBoost classification model in triaging cardiological patients into “low”-, “medium”-, and “high”-priority groups.
4.2. Comparison of XGBoost Results with other Classification Algorithms
In this chapter, a comparative analysis is discussed, contrasting the outcomes of XGBoost with those of other classification algorithms such as KNN, GNB, and DTA.
The KNN is a non-parametric, supervised-learning classifier [
46]. It relies on proximity to categorise or forecast the grouping of a given data point. The KNN algorithm exhibited an accuracy of 96.84%, indicating its effectiveness in correctly predicting outcomes. The precision of 0.9068 indicated the model’s efficiency in identifying positive instances among its predictions, and the recall of 0.7084 demonstrated its capability to capture a substantial portion of actual positive instances. The F1-score of 0.7602, combining the precision and recall, further signified the overall balanced performance of the KNN algorithm in classifying the priority levels in the “Heart Failure” data. However, the XGBoost algorithm showcased even higher accuracy, precision, recall, and F1-score values than the KNN algorithm.
The Naïve Bayes (NB) algorithm, a probabilistic machine learning technique rooted in Bayes’ theorem, finds extensive use in various classification tasks. The GNB serves as an extension of the original NB algorithm. The GNB predicted the results with an accuracy of 89.41%, which was lower than the accuracy of the XGBoost. Likewise, the precision, recall, and F1-score metrics, which were 0.6122, 0.7675, and 0.6612, respectively, also fell below the corresponding values achieved by XGBoost.
DTA is a non-parametric supervised-learning algorithm applicable to both classification and regression tasks. It adopts a hierarchical structure resembling a tree, encompassing a root node, branches, internal nodes, and leaf nodes. The output produced by the decision tree obtained an accuracy of 99.68, closely approaching the accuracy achieved by XGBoost, which was 99.94%. In addition, evaluation parameters such as precision (0.9756), recall (0.9704), and F1-score (0.9730) fell behind the corresponding values attained by XGBoost.
Table 3 summarises the specificity, sensitivity, precision, negative prediction value, false-positive rate, false discovery rate, false-negative rate, accuracy, and F1-score of individual classes of the classification algorithms used for the comparative study.
Figure 4 provides a graphical comparison of four classification models in terms of accuracy, precision, recall, and F1-score.
Consequently, based on our assessment, XGBoost’s predictions outperformed the performance of all the other machine learning models used for comparison. This evaluation indicated that the predictions generated by GNB and KNN exhibited a relatively poor performance. In contrast, the DTA approach demonstrated a performance closely resembling that of XGBoost.
5. Discussion and Conclusions
There is a significant need to implement AI-driven triaging systems in local healthcare services. In the healthcare community, triaging is a routine event that health workers follow at every level. It occurs when a new patient is discharged and transferred to a community setting or when a nurse visits a patient.
This study aimed to classify cardiological patients into certain levels of triaging using machine learning methods. The quantitative variable selection method involved utilising the correlation matrix with the data preprocessing stage, including null value imputation techniques and a data normalization approach.
Subsequently, the preprocessed dataset underwent feature-engineering stages to establish the triage column and was prepared for training using the XGBoost algorithm. The trained model’s outcomes were evaluated against those of other classification algorithms trained on the same dataset. Compared to Ref. [
47], the achieved accuracy was significantly higher, as we utilised a novel feature-engineering approach incorporating feature selection and the NEWS2 scoring system.
The examination of the evaluation metrics led to the conclusion that the XGBoost machine learning algorithm yielded the most favourable outcomes when triaging cardiological patients, including the “high”-priority class with symptoms of heart failure. Moreover, the computed evaluation parameters for each class, specifically for “low”, “medium”, and “high” levels of triaging, demonstrated the superior performance of XGBoost compared to the other machine learning algorithms used in this study.
The approach used in this study can help healthcare professionals reduce triage time and focus on the immediate treatment of patients. XGBoost’s processing time for triaging 2,35,982 patients was remarkably swift and took less than 0.01 s, in our case.
As discussed above, we used quantitative values and explainable ML algorithms for the modelling. Within this particular situation, generative AI can be added to generate textual responses in the output. At the same time, it seems there is no need to apply large language models (LLMs) to solve the triaging problem. Contemporary LLMs have significant limitations in this context, as they mostly deal with textual (qualitative) data and lack explainability. Also, they do not comply with healthcare regulations regarding the privacy and security of patient data.
This study’s findings can be adapted not only to emergency healthcare services but also to be more widely implemented in healthcare communities. While several studies described machine learning for triaging patients in emergency departments, there is a noticeable lack of research using machine learning for triaging patients in local community healthcare providers. Limited studies represented a triaging approach joining primary and secondary healthcare. For instance, Wang et al. [
5] performed a study on unstructured data to improve the triaging of patients with early inflammatory arthritis (EIA) from primary care to secondary care using a heterogeneous machine learning model. The research team used a data-driven hybrid approach to triage EIA patients using referral letters from GPs and blood test results.
However, the primary limitation in this study pertained to the dataset, as the dataset used in this study encompassed 970 variables of clinical data from patients, which were not specifically tailored to patients with heart failure. Furthermore, the derived dataset for patients with heart failure from the raw dataset, which had 970 variables, contained a wide range of null values and impurities. Certain crucial variables, such as the test results, could not be considered in this study due to a substantial number of null values and impurities being associated with them. The second major limitation was the absence of a triage column in the dataset. Thus, creating a triage column was one of the main stages in the current study.
Thus, we can conclude that this study successfully accomplished its stated objective by addressing the various challenges encountered. Depending on access to the appropriate datasets, the proposed approach can be iterated to various medical conditions. Moreover, the calculation of the NEWS2 score, along with the other approaches used in this study, can be used together to classify and triage other medical conditions. The XGBoost algorithm can be a method of choice for triaging purposes.











{kind=link}
{kind=link}
{kind=link}
{kind=link}