2.1. Peak Detection
The first component of the code-base, the peak detection algorithm, is based on Mariscotti’s second difference method [
8]. This method continues to be heavily utilised in computer systems performing peak searches, especially in spectroscopy software such as Genie™ 2000 [
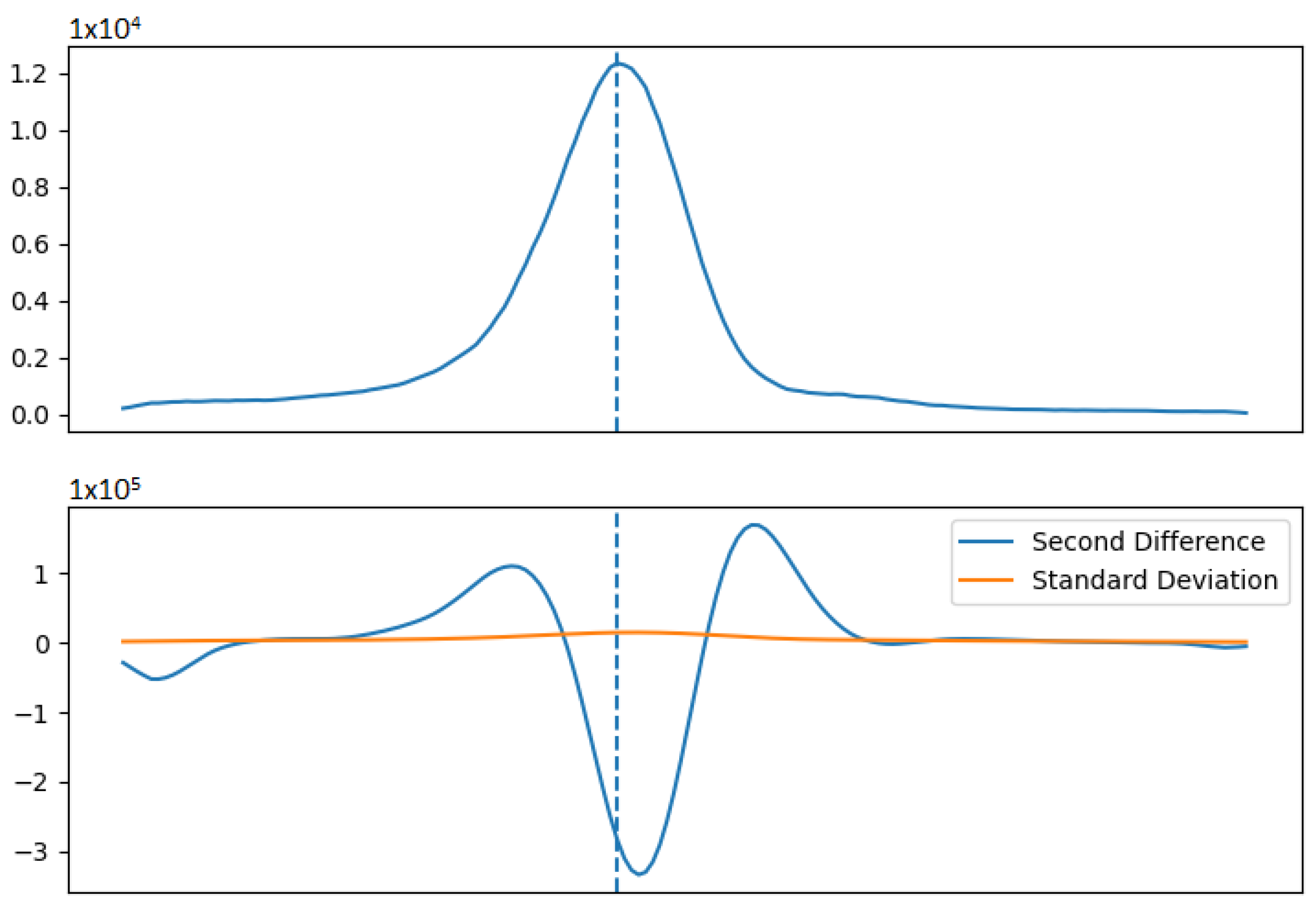
15]. It is centred on the underlying principle that for a Gaussian peak on a linear background, the second derivative will only be non-zero in the presence of curvature, such as a peak. This is demonstrated schematically in
Figure 2, as the ’second difference’ plot of the upper peak.
The ‘second difference’ is the discrete analogue of the second derivative and is given by:
where
is the count in the
ith channel. The standard deviation,
, of this derivative analogue is given by:
These are calculated for all
i and smoothed multiple times by summing neighbouring values:
where
is the smoothed second difference,
z is the number of sums completed and
. The optimum values for
z and
w found empirically by Mariscotti are 5 and
respectively [
8], where
is the full width at half maximum (FWHM) for peaks in the spectrum (a value, defined by the Gaussian distribution, that is specific for a given detector material, yet consistent across all peaks-referenced as a percentage value at the 662 keV Cs–137 photopeak). This smoothing procedure works well for single peaks which are well resolved spatially. However in the case of multiple peaks very close together, the result of this smoothing may be a single broad peak. Relative intensity comparisons already included in the identification algorithm may help to resolve this issue, however there is no alternative smoothing procedure currently implemented for cases such as this.
Smoothing is necessary to reduce the standard deviation relative to the second derivative and remove high-frequency noise from the spectral data that would otherwise result in the false identification of small peaks associated with such non-peak ‘ripples’. Peaks can therefore be identified with the condition
, where
f is the factor of confidence. They can also be resolved from some types of non-linear background using this condition since, in some cases, the second difference will be much larger in the presence of a peak than for curved background features. Here, through empirical analysis and refinements, a value of
was chosen to detect peaks for ‘static’ (pre-recorded/post-processed) spectra read into the software [
5]. For ‘dynamic’ (online) spectra, fluctuations as a result of the source-detector environment may necessitate a smaller confidence factor. Once a peak(s) is identified within a gamma-ray spectrum, its energy and intensity are appended to various arrays so an attempt can be made to identify the contributing isotopes by their comparison with a database of known gamma emitters.
Through the use of a configuration file within the module, it is possible to change various parameters affecting the peak search. This file allows the discriminators to be changed so that the peak search only takes place in a specific range of energy of the spectrum (e.g., between 300 keV and 2250 keV). The channel-energy relation parameters (slope and y-intercept of the line or coefficients of the polynomial if required) are found within this configuration file and can easily be changed to fit the spectrum/detector being used. A FWHM estimate provided to the peak search algorithm is also found here, which can be changed to best match the spectrum being examined since this will affect the performance of the algorithm as detailed above. The value of f can also be varied in this file, which affects the sensitivity of the algorithm to parts of the spectrum with negative second derivative. Essentially, this value represents the limit of detection (LoD) for the method. Also contained in the configuration file are: a list of common isotopes to be parsed when attributing an isotope to a peak if other identification methods within the module are otherwise unable to do so (detailed in the next section); a setting for the isotope library being used and the detector material and thickness which are used to select the energy-efficiency relation (exponential function) if one is present in another separate file for the same material/thickness.
2.3. Isotopic Identification
To determine the isotope(s) responsible for the peak(s) identified following the application of the formerly described second derivative method, a number of conditions, scenarios and characteristics must be assessed and implemented. Analogous to the multiple point recognition that underpins highly accurate human fingerprint identification; a similar multiple ‘feature’ (signature) approach is also employed as part of the peak screening, identification and discrimination methodology where multiple peaks are identified within a spectrum. Herein, the candidate isotope(s) attributable to each photopeak are cross-checked against/compared with all other second derivative identified peaks within the spectrum for common radionuclide identifications at different energies; utilising the primary, secondary and/or any number of potentially multiple gamma-ray peaks derived from the isotope. Detecting such multiple emission peaks associated with a single isotopic species (e.g., Bi-214 and Pb-214) makes identification through their characteristic ‘spectral fingerprint’ markedly easier, alongside reducing the peak ascribing error and uncertainty—as the likelihood of other emitter(s) yielding photopeaks with multiple, similar, gamma energies is unlikely; albeit with a number of caveats and considerations.
While more applicable to scenarios associated with the identification of a mono-energetic gamma emitter in contrast to multiple-peak ‘fingerprinting’ of isotopes with two (or more) characteristic emissions (thereby allowing for such an internal ‘validation’ and confirmatory ‘cross-checking’ of the other peaks existence), if the algorithms isotopic identification is incorrect, this would consequently indicate the presence of another (fortuitous) source (or sources), emitting at similar energies. This could also result from one or a combination of; (i) local attenuating materials around the source serving to introduce minor modifications the peak energy—consequently downwards ‘shifting’ the peak position from the ‘true’ value [
18], and/or (ii) variations in the detectors intrinsic (energy and geometry dependant) photon absorption efficiency inducing minor peak shifts [
19]. Therefore, within this embeddable python module developed for integration into various software platforms (primarily those utilised for robotic deployments and inspections, such as the ROS) multiple emitters are ascribed to a photopeak in scenarios where their energies are comparable and cannot be differentiated (a discussion of this, the error/uncertainty propagation and the algorithms transcription of the peak ID(s) within the python module are subsequently detailed below). It is noted that this contribution from the ‘environment’ in which the radioactive source resides represents a significant and complex contribution to the (various detector types) intrinsic detection efficiency across the full energy range of incident gammas [
18].
While the applicable Mass Attenuation Coefficients,
(and the associated Mass Energy-Absorption Coefficients,
) are empirically and mathematically well constrained by organisations such as the US National Institute of Standards and Technology (NIST) [
18] for various elements, mixtures, compounds and tissue types across the broad gamma ray photon spectrum; this is not true for more complex systems. Here, the inhomogeneity and contextual variability associated with sources contained within ‘real-world’ field/site decommissioning and assay scenarios envisaged for the deployment of this module introduces considerable complexity due to the resultant variations in photopeak intensity (at different energies). Whereas the detection efficiency and associated relative peak intensities for multiple photopeak emitting radionuclides are well-calibrated (for both detectors and geometric configurations) when associated with laboratory scenarios—delivering minimal uncertainties and errors for peak-fitting when using known inter-peak magnitudes, such an adoption of this approach is not possible, nor reliable, in this instance due to variations induced through the source-detector configuration. Therefore, the relative intensities of a radionuclides multiple photopeaks are not used as the primary discriminator/identifier of an isotopes occurrence—with reference peak intensities rather only used (alongside large tolerance values) to corroborate peak determination.
As detailed formerly, resulting from the Gaussian nature of photopeaks, such a mathematical fit can be easily applied to a single peak, unless it is comprised of more than one contribution. In this scenario, the peaks are ’subdivided’ with additional source(s), from the radionuclide lookup tables, ascribed as a contribution to the peak; identified as being erroneously large/non-Gaussian in order to make the peak area consistent relative to other peaks. Dealing with such peaks that do not match the anticipated peak Gaussian profiles through an alternate ‘division and contribution’ methodology is more challenging, and consequently no procedure currently exists for this.
As is the case for all solid-state type radiation detection materials, the inherent detection efficiency of such scintillators or semiconductors is greatest at the lowest incident gamma-ray energies (namely between 10 keV and 220 keV), although zero at energies tending to zero. Efficiency decreases rapidly (exponentially in many instances) as photon energies surpass 0.5 MeV [
19]. If such detection efficiencies were to not depend upon the incident photon energy and assuming non-attenuated gamma rays, then the well-constrained relative peak intensities from non mono-energy gamma-emitting radionuclides could be easily normalised and compared, irrespective of the crystal material, to facilitate photopeak identification. However, as this is not the case—a correction function is required, based on this energy related decline in detection efficiency. As is conventional for most commercially available gamma detection systems [
20], to compensate for, this python program includes an efficiency decay function, with parameters that are specific to each detector (such as; material, crystal thickness, shape and geometry)—which can be selected from pre-set values within the wrapper by specifying a material and geometry in the configuration file, or new parameters entered by the user. As this python code-base has been designed to operate on the readout derived from any USB-based detector module, all of these parameters are user-defined in the configuration setup and are based upon calibrations provided by the detector manufacturer or are mathematically/empirically derived, then added to the file containing the detection efficiency relations [
19]. Where no efficiency calibration is able to be made, the program makes no attempt to subdivide peaks, as the relative intensities of peaks in this case are unlikely to be consistent with the expected spectrum.
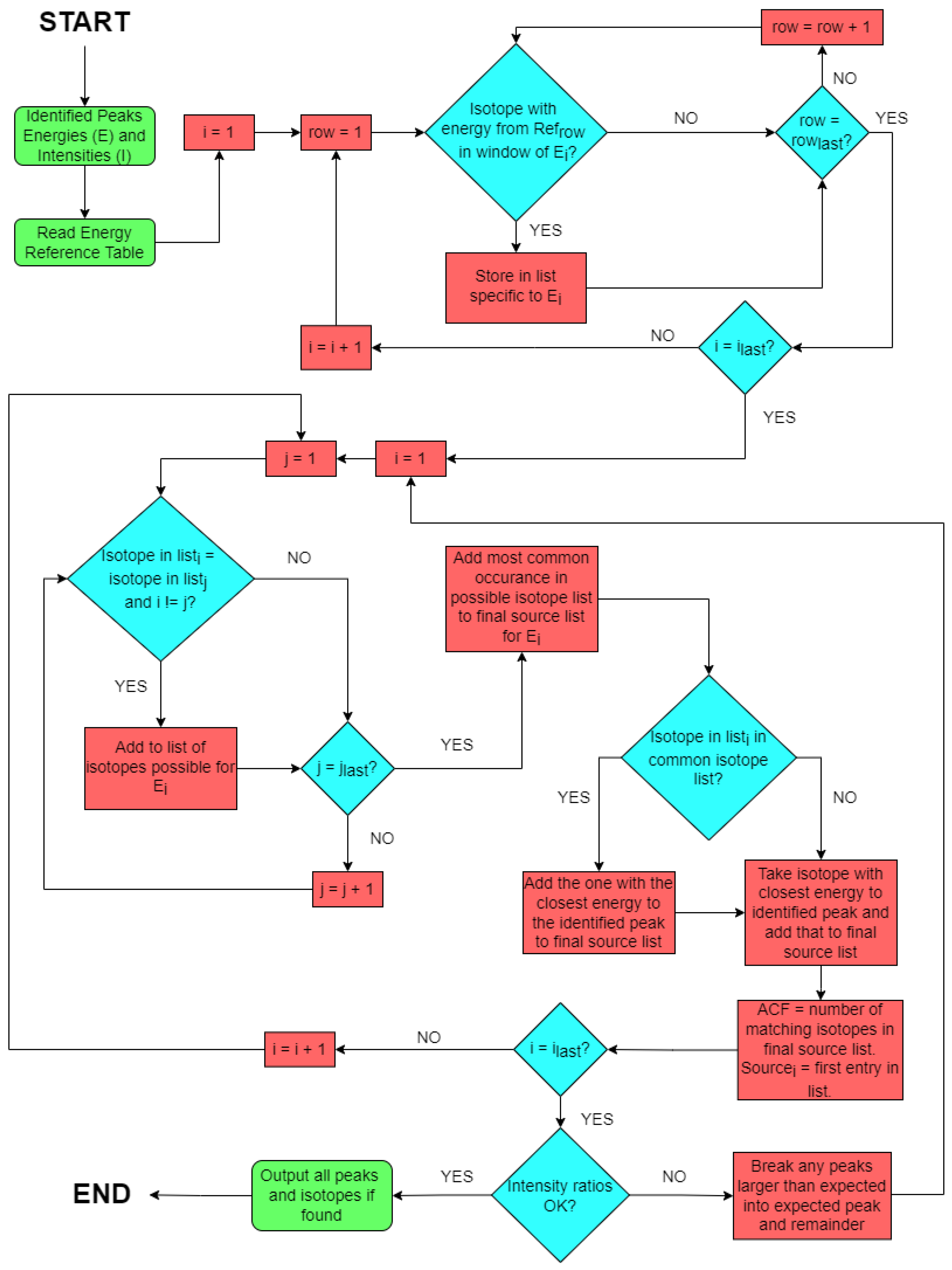
For scenarios where peaks are identified through the aforementioned ‘second derivative’ methodology and there are not multiple peaks with a common candidate isotope, a list of isotopes (with associated energies) known to be of common interest is cross-checked as part of a peak ‘pre-screen’. If a peak (or multiple peaks) energy is within a specified bin around that of an isotope in this list, then that isotope is assumed to be the incident radionuclide generating that peak—with the ID, intensity and error then output by the code-base. However, if no isotope(s) can be ascribed from the peak(s) present within this list, an attempt is then made to match the isotope(s) with a peak energy from the same (user) pre-selected reference list that most closely matches the energy of the peak. This deeper analysis consequently represents a more computationally intensive process.
As is typical for instances where only one photopeak is identified by the algorithm, e.g., Cs-137 (N.B. while the Cs-137 gamma spectrum is characterised by a primary emission peak resulting from the 0.512 MeV − decay, through the Ba-137m isomeric level, its disintegration to the same Ba-137 ground-state is also via a 1.17 MeV − emission—alongside accessory escape peaks), any reference to inter-peak intensity will be non-existent as no other emission photopeaks are present within the spectrum obtained. Therefore, where no other isotopic identification has been successfully made, peak energy is examined exclusively within the identification algorithm when attempting to correctly attribute an isotope to a peak. The algorithm simply attempts to attribute the source with the closest gamma energy to the identified peak.
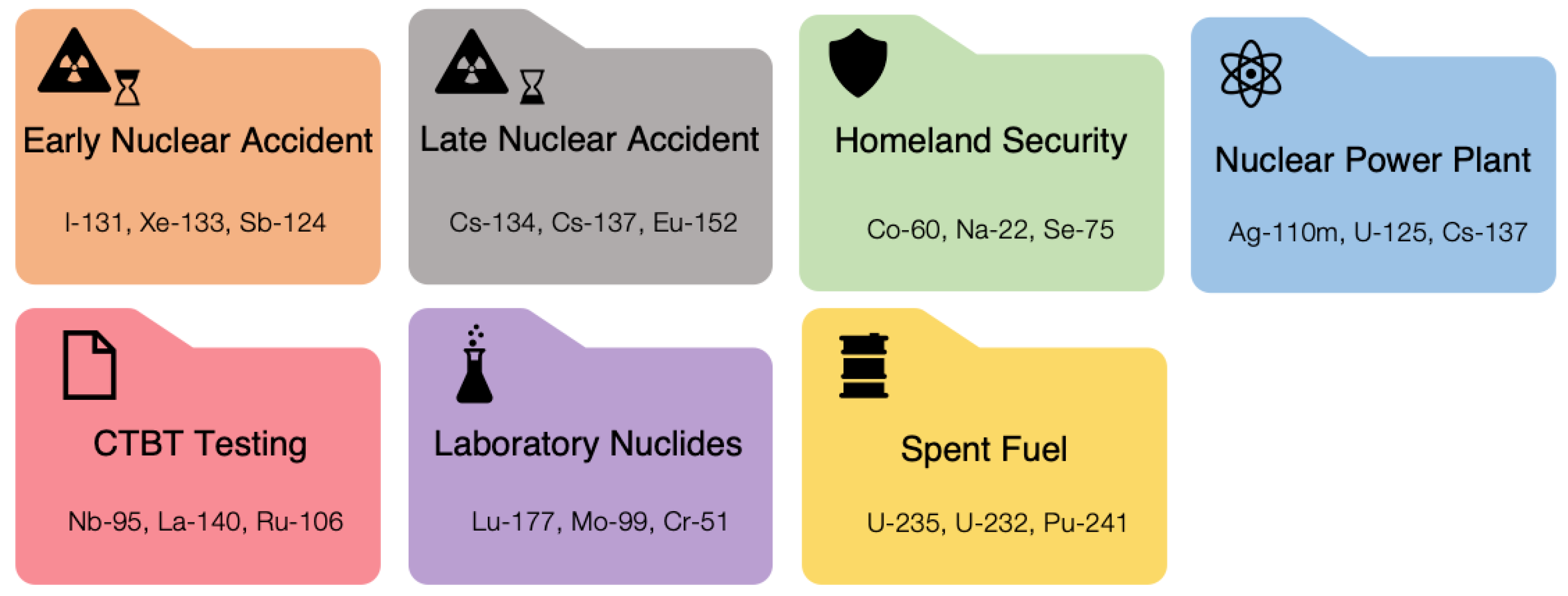
If the aforementioned initial ‘coarse’ peak ‘pre-screen’ identification fails to appropriately identify peaks based on the common interest suite of emitters (namely Cs-134, Cs-137, Co-60, Ag-110m, as well as those within the U and Th decay series) then a full search and fitting is performed. To facilitate a more accurate and efficient peak attribution from the algorithm by reducing the number of potential solutions, the contributing gamma-emitting isotopes are categorised into a number of libraries—a schematic representation of which is shown in
Figure 3. During setup, the library most applicable to the scenario is selected by the user via the codes wrapper—although to avoid an incorrect ‘brute-force’ fitting if no peaks within the user-selected library are statistically appropriate, then the peaks contained in other libraries are searched for potential fits. This database is also included within the open-access code-base—with the details of the link to this repository contained within the information at the end of the manuscript. These seven libraries together comprise the scenarios for which gamma radiation would be encountered [
21,
22], and contain the isotopic information that is specific to each—albeit with a number of emitters common between groupings. For example, both I-131 and Xe-133 are specific to the ‘Early Nuclear Accident’ library (i.e., highly volatile radionuclides with short, days to week, half-lives that constitute the primary radioactive inventory following a reactor release event that are rapidly dispersed within the environment [
23]), however, Cs-134 and Cs-137 are contained within both ‘Early’ and ‘Late Nuclear Accident’ suites (alongside being listed within other source libraries). While the ‘Early Nuclear Accident’ library comprised radioisotopes that are the primary inventory/dose contributor shortly after a reactor/site release, the ‘Late Nuclear Accident’ suite constitutes nuclides with longer (generally > 2 year) half-life that are not as volatile and short-lived. The species contained within the ‘Laboratory Nuclides’ comprise those used as part of biological tracing experiments or within medical procedures/treatments.
The three formerly outlined methods (same isotope to multiple peaks, isotope in list of common sources and closest energy) are all applied to each peak in order to obtain a candidate isotope. In order to give some idea of the robustness of the result found, an arbitrary confidence factor (ACF) has been defined and is returned with the table of isotopes output by the algorithm. This factor is an integer from 1 to 3 detailing how many of these methods agree on the obtained isotope. This factor is included as an extra check of the likelihood of a certain source being correct, though even if a value of 1 is obtained the result can still be correct.
If a peak is found and an isotope cannot be attributed to it using the methods included in the algorithm, the peak is reported without a value in the source column. A flowchart for the full isotope identification procedure, including the various caveats and sub-processes, is shown in
Figure 4.
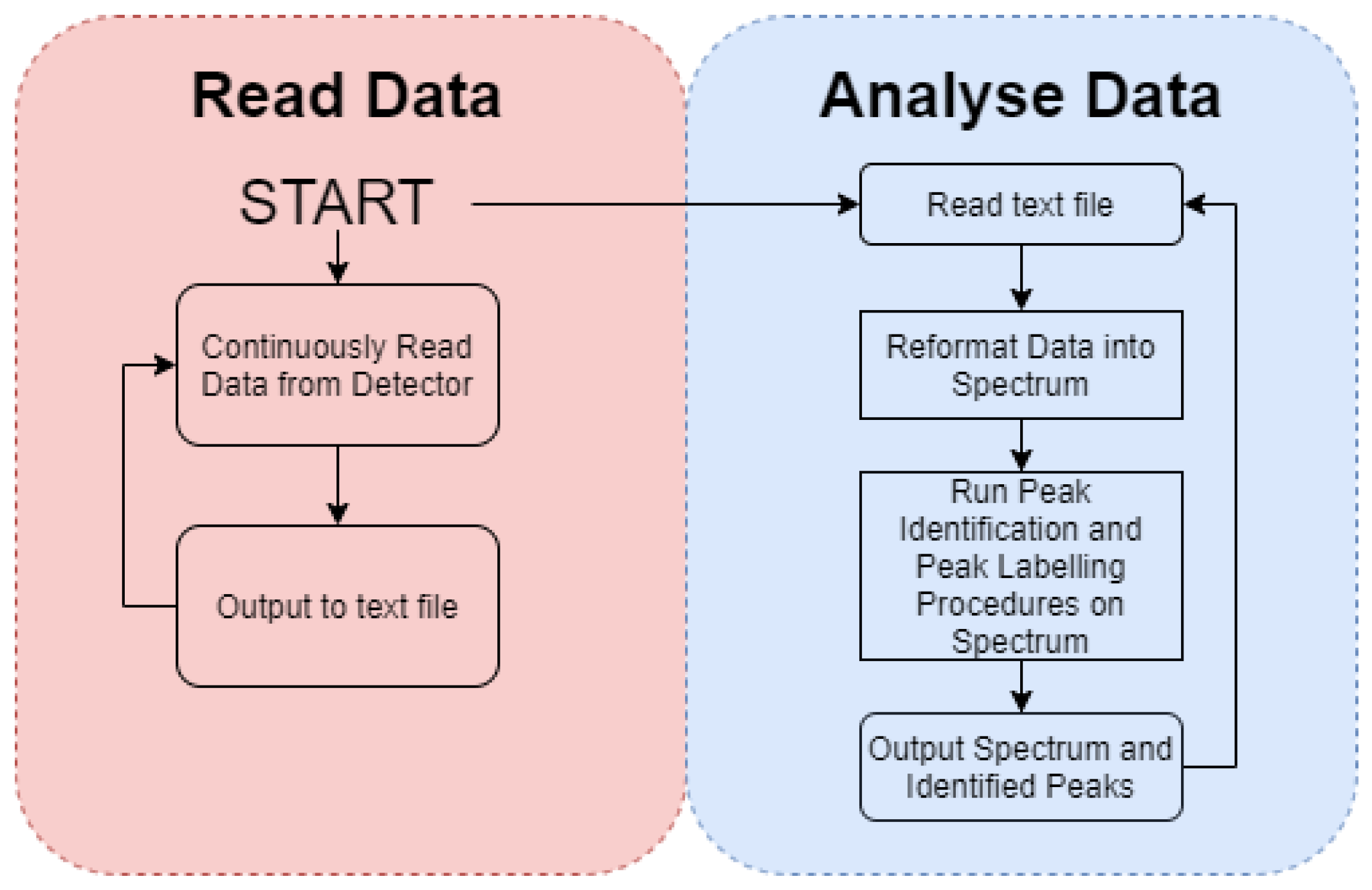
As formerly detailed, to facilitate the post-collection analysis of a gamma-ray spectrum alongside the online (live) isotopic evaluation vital for response and mapping scenarios, the algorithm’s wrapper script can be adapted. This user-configurable facility is such that it can handle both online ‘dynamic’ inputs (with the incoming detector channel data being appended to the array; serving to continually improve the counting statistics) as well as the post-processing of a ‘static’ output that comprises data (arrays) already written to a text file (or any other file format a user specified). The program can then parse either the formerly collected or online spectral data through the analysis code, where the peak(s) can be identified. These wrapper scripts allow changes to be made to the appearance of the output data and in the case of an online/dynamic input: the method of data collection and reformatting can be rewritten by the user to suit the system being deployed.
2.4. Detector and Algorithm Performance Trials
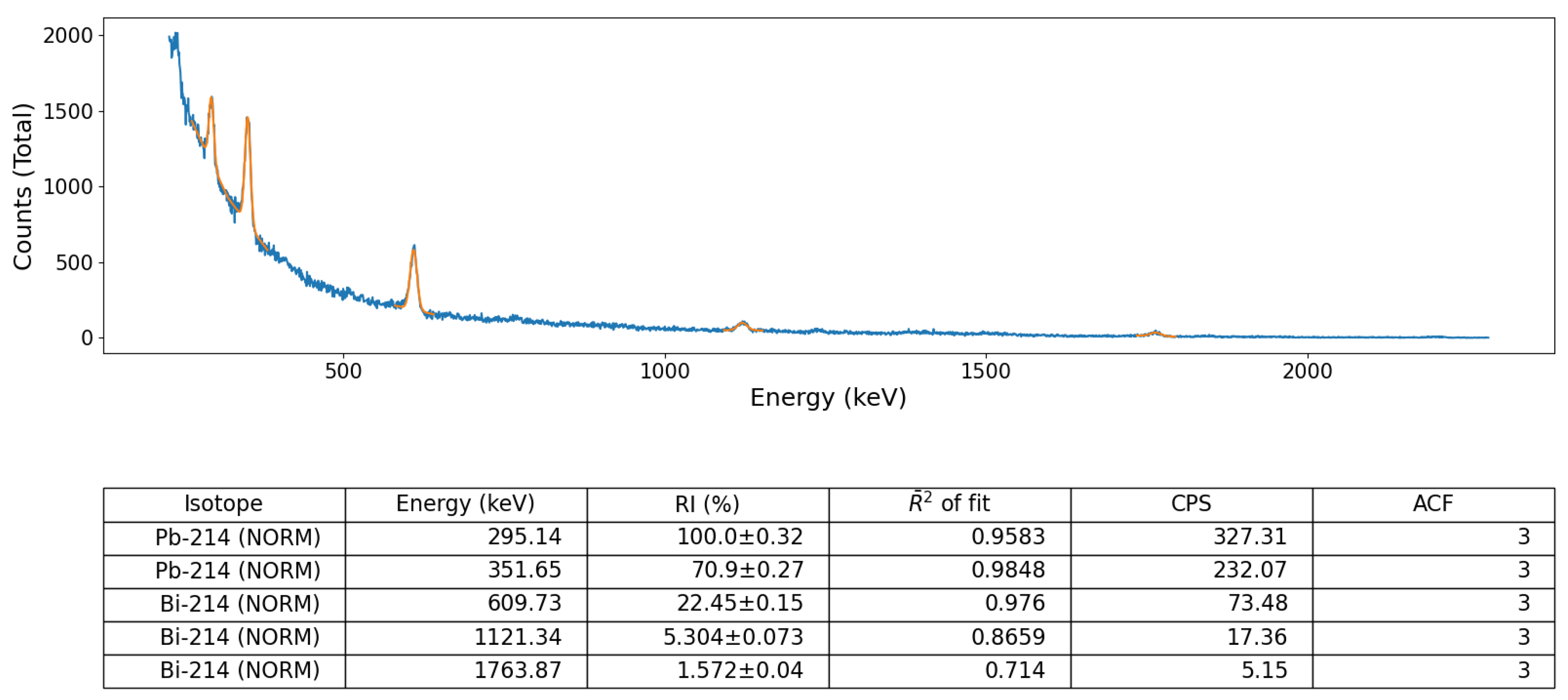
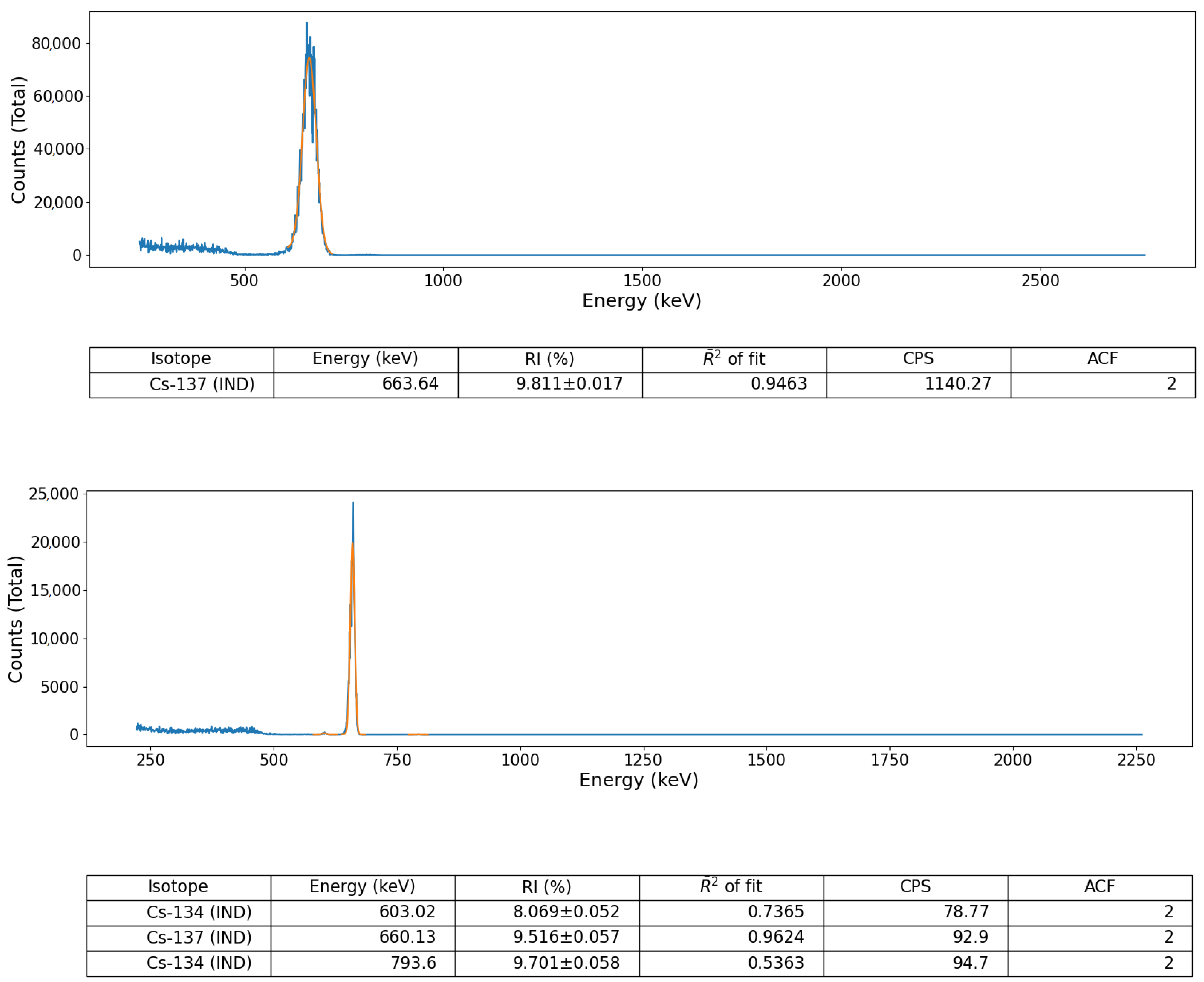
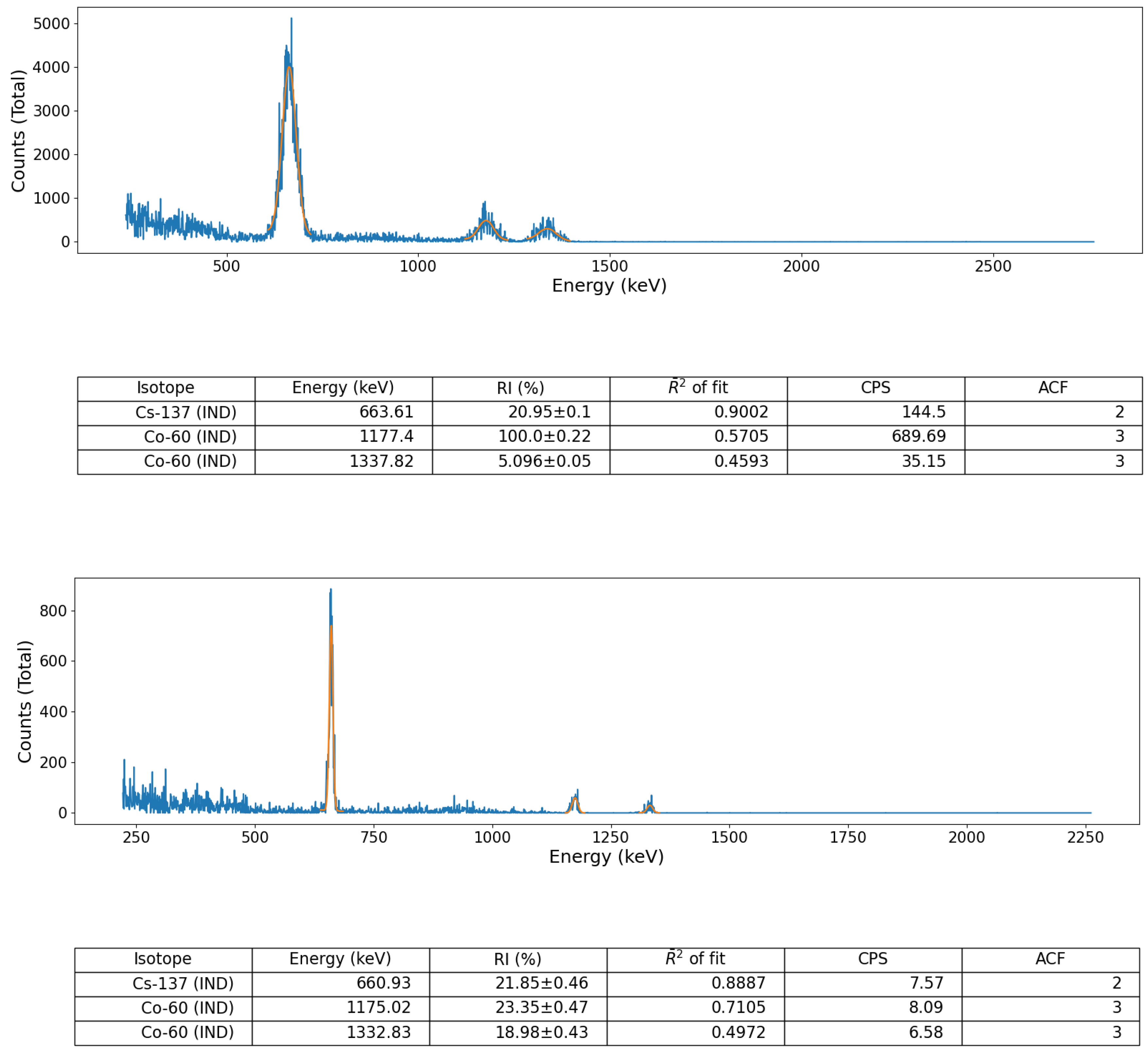
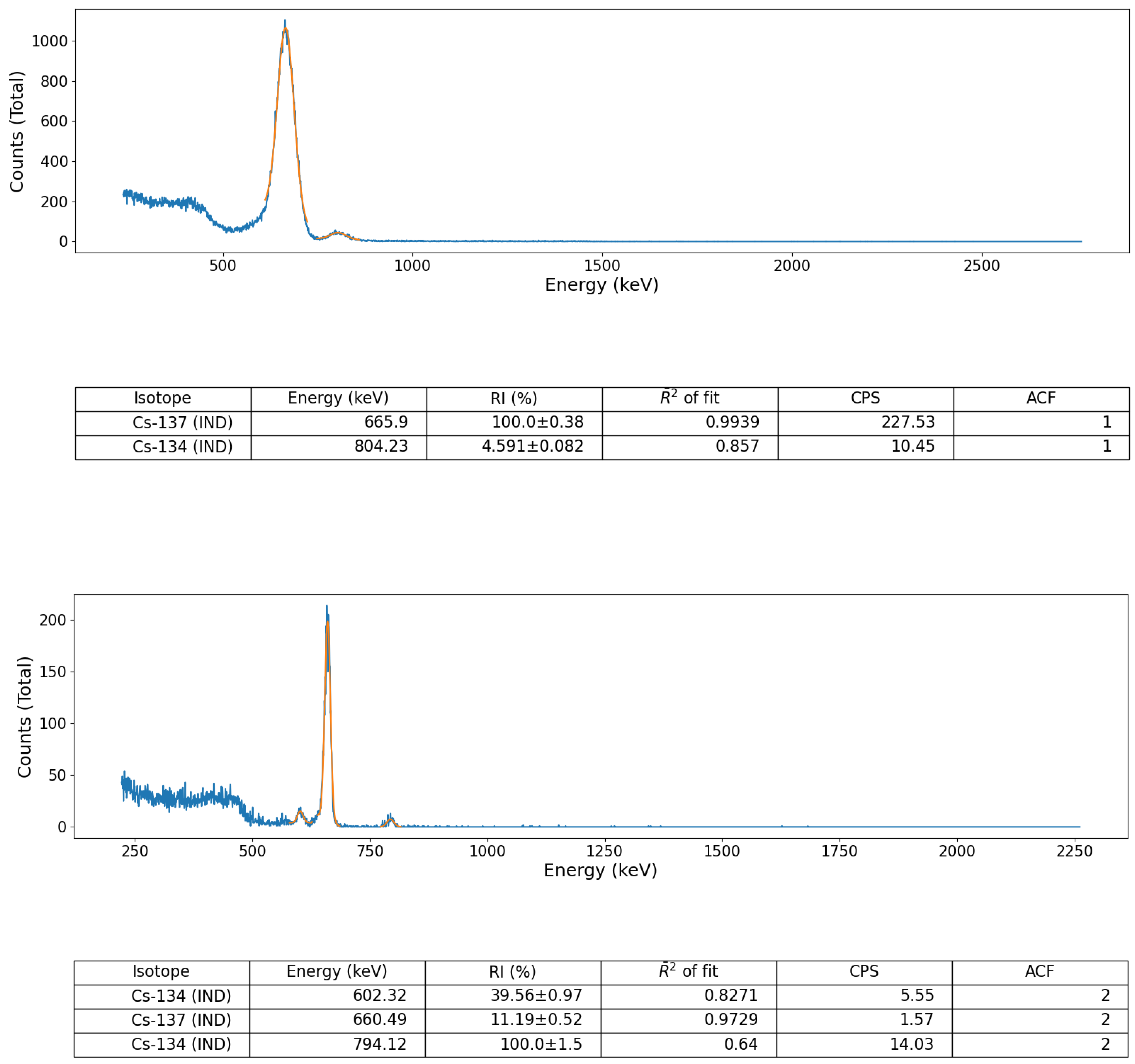
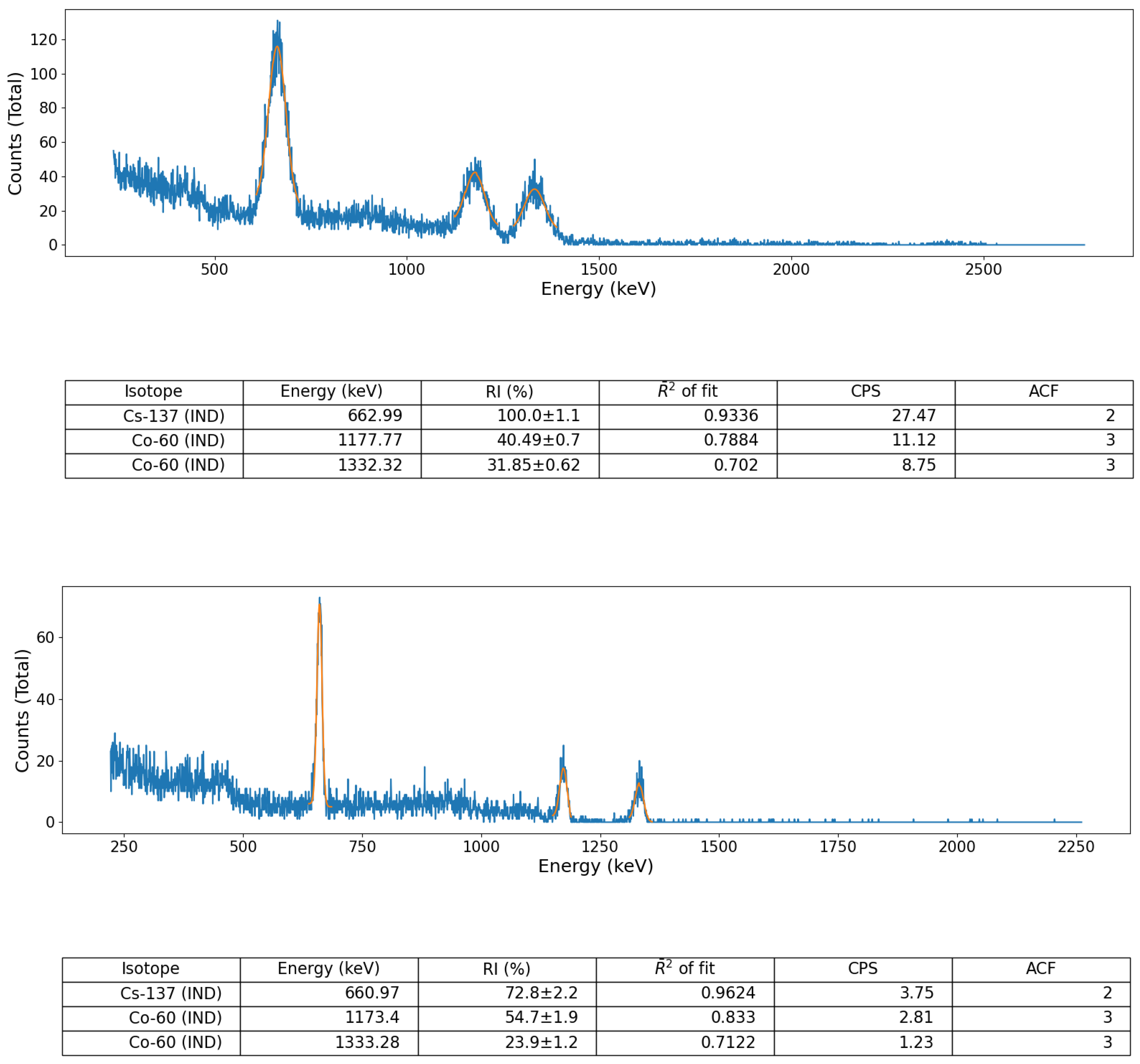
Validation of the peak identification algorithm was performed using a number of sealed radioactive sources (for both spectral file ‘post-processing’ and ‘online’, live, data-stream algorithm assessment) as well as on a suite of formerly collected spectra derived from a radioactively contaminated environment, detailed below. These sealed-sources, each with characteristic and well-defined gamma emission peaks, comprised; (i) soil derived from Fukushima Prefecture (Japan) radioactively contaminated with Cs-137 and (ii) a multi-radionuclide gamma-ray calibration coupon (QCRB22618 from Eckert and Ziegler™), constituting emitters (with activities at the time of production in 2016) detailed in
Table 1.
For testing of the peak identification against online (live) data (compiled as a string of gamma-ray energies continually appended onto the end of a text file) spectra were derived of the aforementioned sources using; (i) a Kromek D3S combined gamma-ray/neutron spectrometer module (with gamma detecting CsI(Tl) crystal of 51.0 mm × 25.4 mm × 12.5 mm dimensions, a and LiF:ZnS neutron detecting crystal of 32 mm × 100 mm dimensions) [
24], (ii) a Hamamatsu C12137-01 CsI(Tl) spectrometer module (of 38.0 mm × 38.0 mm × 25.0 mm crystal dimensions) [
25], and (iii) a Kromek GR1 CdZnTe (CZT) semiconductor micro-gamma spectrometer (of 10 mm × 10 mm × 10 mm crystal dimensions) [
26]—with the serial output strings from each parsed through the peak identification code-base. In each instance, the applicable radionuclide library (‘Nuclear Power Plant’ for both sources) was selected in the codes associated wrapper function—alongside the detector-specific parameters (such as; crystal type, size and geometry). It is noted that while more advanced, higher-sensitivity and resolution radiation detector modules exist on the market, the highly miniaturised, rugged and USB-controlled solid-state units used in this work constitute those most widely employed within nuclear robotics, in-field/site characterisation/assay and decommissioning. Their low-cost and accessible (unencrypted) output format additionally allows for ready integration of such devices into a wide range of monitoring applications not possible for larger, albeit potentially more sophisticated, detectors.
Tests on the algorithm were also performed using ’post-processed’ spectra obtained from the same calibration sources, again collected using the three aforementioned portable radiation detection systems commonly deployed for remote/robotic monitoring applications. The spectral data was parsed into the analysis code from a text file that comprised channel number vs. event frequency. It is noted, however, that the wrapper functionality within the code permits for other alternate data and file formats to be translated and parsed through the analysis code; such as .csv, .msc and, .spc.
The acquisition of spectral data (using the sealed-sources), for both online (live) and subsequent post-processing analysis via the algorithm was performed using a simple detector-source configuration in each instance. The experimental setup comprised the detector held within a conventional laboratory stand with the units crystal positioned such that its long-axis was directed vertically down, orthogonal to the bench—with the base of the detector (and crystal) at a height of 11 cm from the surface. Each 1 cm thick source was then positioned directly under the detector (resulting in a 10 cm separation), with spectra acquired for a duration of 5 min (real-time).
In addition, to provide a further test of the algorithm, away from the aforementioned well-calibrated/defined source-detector environment, a gamma-ray spectrum formerly obtained from the naturally occurring radioactive material (NORM) and Industrial (IND) associated radionuclide contaminated Pridneprovsky Chemical Plant (PChP) site in Dnieprodzerzhinsk, south Ukraine, was also used to validate the algorithm, owing to the multiple daughter radionuclide emission peaks associated with the U/Th decay chain (e.g., Bi-214, Bi-210, Pb-214, Pb-210). This measurement was obtained using the same Kromek GR1 CdZnTe detector module using the manufacturer’s KSpect™ spectral acquisition software, with the resulting spectrum stored (and exported) as a text file (of channel numbers vs. counts) for subsequent peak analysis using the python algorithm. An identical 5 min acquisition time was used to acquire the spectrum, with the measurement of the sample taken with the same 10 cm detector-sample separation.
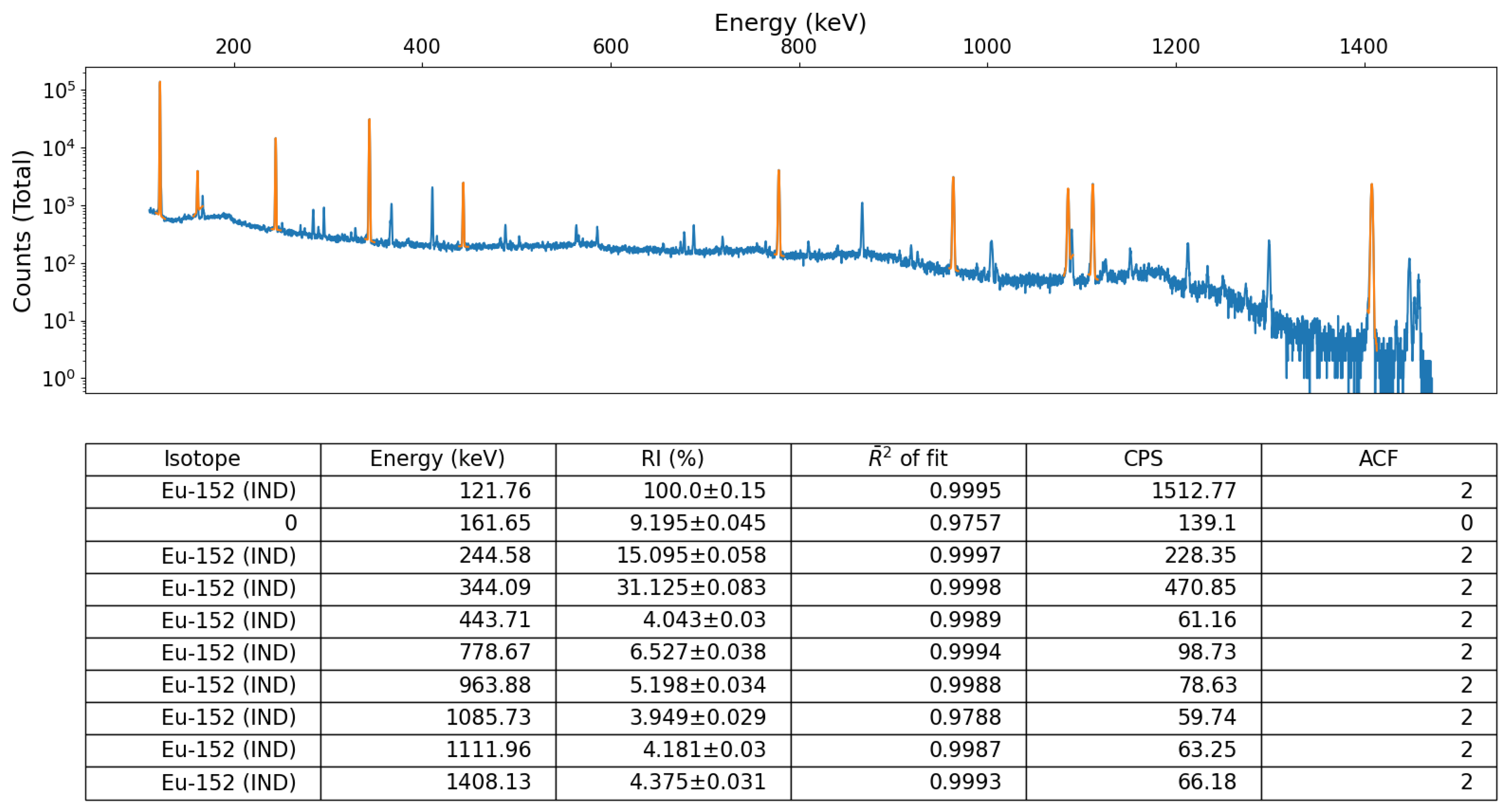
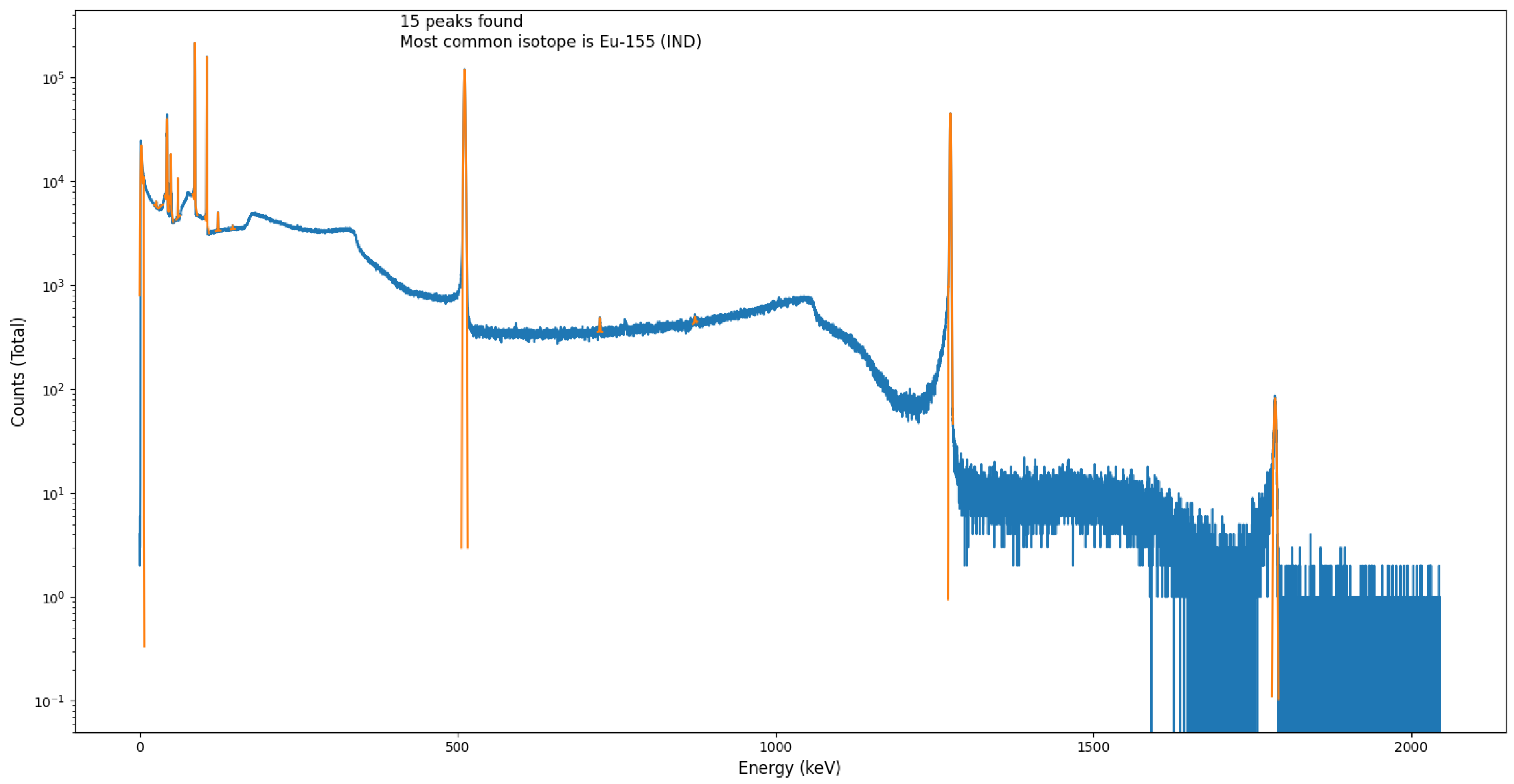
To numerically quantify the performance and accuracy of this python algorithm against other, accepted, peak-fitting approaches, the algorithm was additionally tested and quantified through the post-processing of a Eu-152 spectrum as well as the spectrum obtained from an Na-22 and Eu-155 source. A peak locate report was generated using Genie™ 2000 and compared to the peaks found using the module presented here for validation. The spectral data for these was obtained using the same experimental setup/methodology as detailed above; using a Mirion Technologies (Canberra) SAGe™ Well detector [
27]. While this detector possesses a superior FWHM value (of 2.2 keV at the 1332 keV Co-60 photopeak) than any of the other three radiation detector devices used for testing (of which the detector-specific FWHM value are inserted as parameters within the modules ‘wrapper’ code), the high cost, need for cooling, size and mass currently prevents this detector type being deployed by robotic or remotely operated systems—for which this code-base is developed to facilitate within such ROS applications.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}