1. Introduction
Next generation sequencing (NGS) has globally revolutionized the field of genomics and bioinformatics. Whether addressing whole genomes, whole exomes, or targeted regions, the ability to sequence millions of DNA fragments in a single run at a relatively low cost per base has harbored great appeal to clinicians and researchers. NGS has been transformative by providing a more comprehensive and efficient way to analyze genetic information, leading to new insights and applications across various disciplines. Targeted panels, specifically, have generated interest due to quicker turnaround time, cost effectiveness, and increased coverage depth compared to whole exome sequencing (WES) and whole genome sequencing (WGS) [
1]. This allows for querying specific genes of significance with high accuracy in variant detection. Although WES and WGS have their own select advantages depending on the application, targeted panels have practical implications in specific areas of disease management.
The results of NGS are designed to output a multitude of variants from the genes of interest, with a common goal of understanding the significance of each variant with respect to disease. To achieve this goal, steps are needed to ensure accurate and comprehensive variant annotation. Bioinformatic analysis and interpretation of variants have been proven to be non-trivial based on multiple factors, including number and complexity of variants, conflicting literature, and varying classification methods. In an effort to mitigate these complexities and standardize these processes, several international professional societies have published classification guidelines for the interpretation and reporting of genomic variants [
2]. For classification of variants, the most notable international guidelines include AMP/ASCO/CAP (Association for Molecular Pathology/American Society of Clinical Oncology/College of American Pathologists), ESCAT (ESMO Scale of Clinical Actionability for molecular Targets), and ACMG/AMP (American College of Medical Genetics/Association for Molecular Pathology) guidelines [
3,
4,
5]. All of these guidelines employ different evidence frameworks to answer different questions. In the AMP/ASCO/CAP guidelines, a tiering system (Tiers I-IV) is employed to categorize variants by the evidence supporting their “diagnostic, prognostic, or therapeutic significance” [
3]. In the ESCAT guidelines, a tiering system of 6 tiers ranks variants by evidence supporting “clinical actionability” [
4]. In the ACMG/AMP guidelines, variants are classified across five categories of functional pathogenicity [
5]. Oftentimes, one or more of these classification frameworks are implemented in laboratories running NGS, as well as in some commercial and non-commercial variant annotator software solutions.
In this study, we analyzed and compared variant classification differences among four different variant annotator software tools: navify® Mutation Profiler (Roche; Santa Clara, CA, USA; RUO*), SOPHIA DDMTM (SOPHiA GENETICS; Boston, MA, USA; RUO in the USA), QIAGEN® (Hilden, Germany) Clinical Insights Interpret (QIAGEN; RUO), and Franklin (Genoox, Tel Aviv, Israel), a free, publicly-available annotator. By examining the differences in variant tier assignments and the underlying criteria employed by these tools, we aim to show the nuances of somatic variant interpretation and offer potential reasons for tier classification differences across the solutions, which, in turn, may help researchers select the most appropriate tertiary analysis software solution for their specific needs.
4. Discussion
As the demand for variant annotation and interpretation software solutions has increased, there has been more of a necessity for labs to understand the strengths and weaknesses of these tools in order to decide on the right solution for their needs. This study compared Tier IA, IB, and IIC classifications for alterations identified from comprehensive genomic profiling of 80 pan-cancer cases across four variant annotation software solutions: navify® Mutation Profiler (RUO*), SOPHIA DDMTM (RUO in the U.S.), QIAGEN® Clinical Insights (QCI) Interpret (RUO), and Franklin’s free annotator.
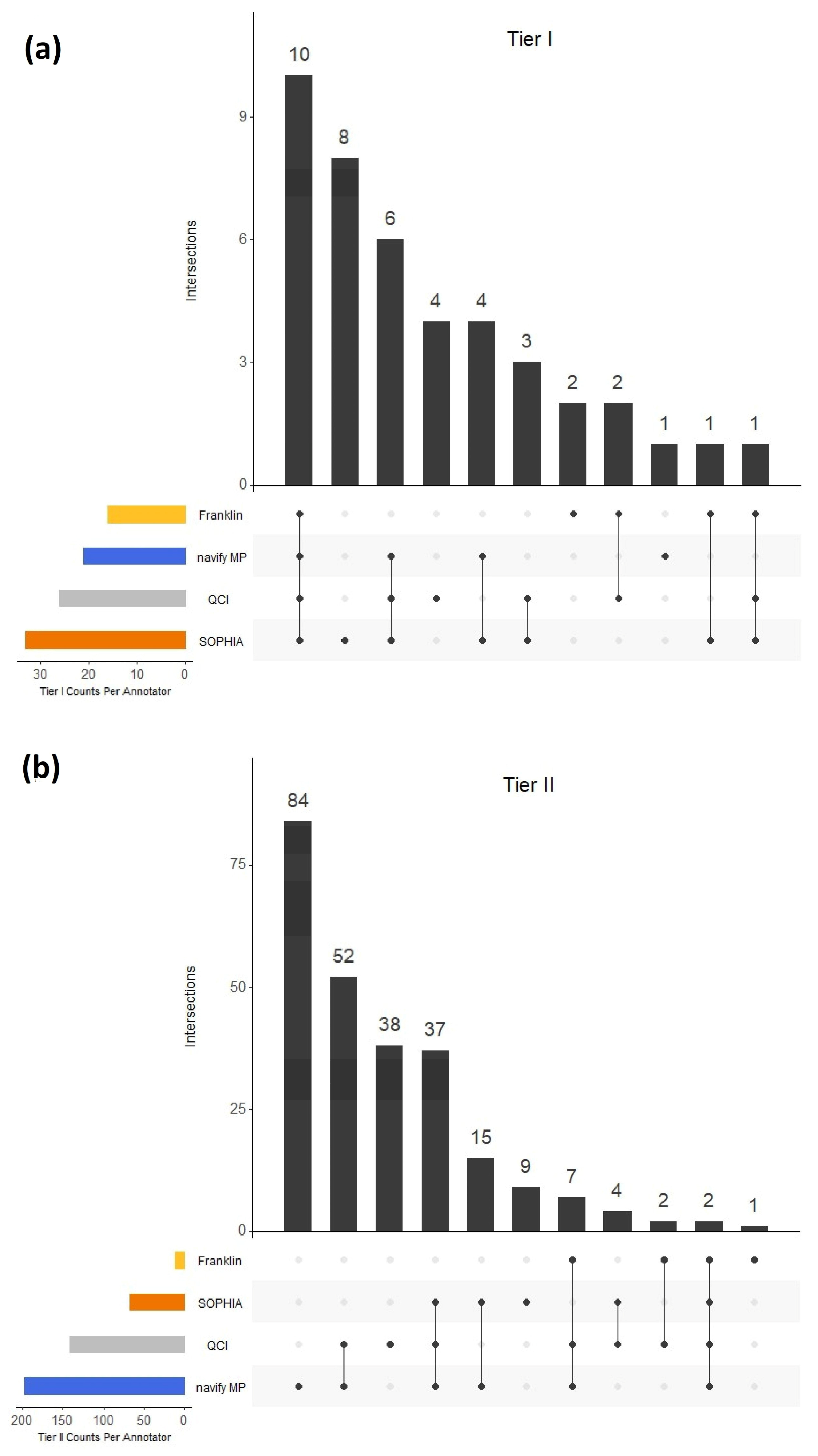
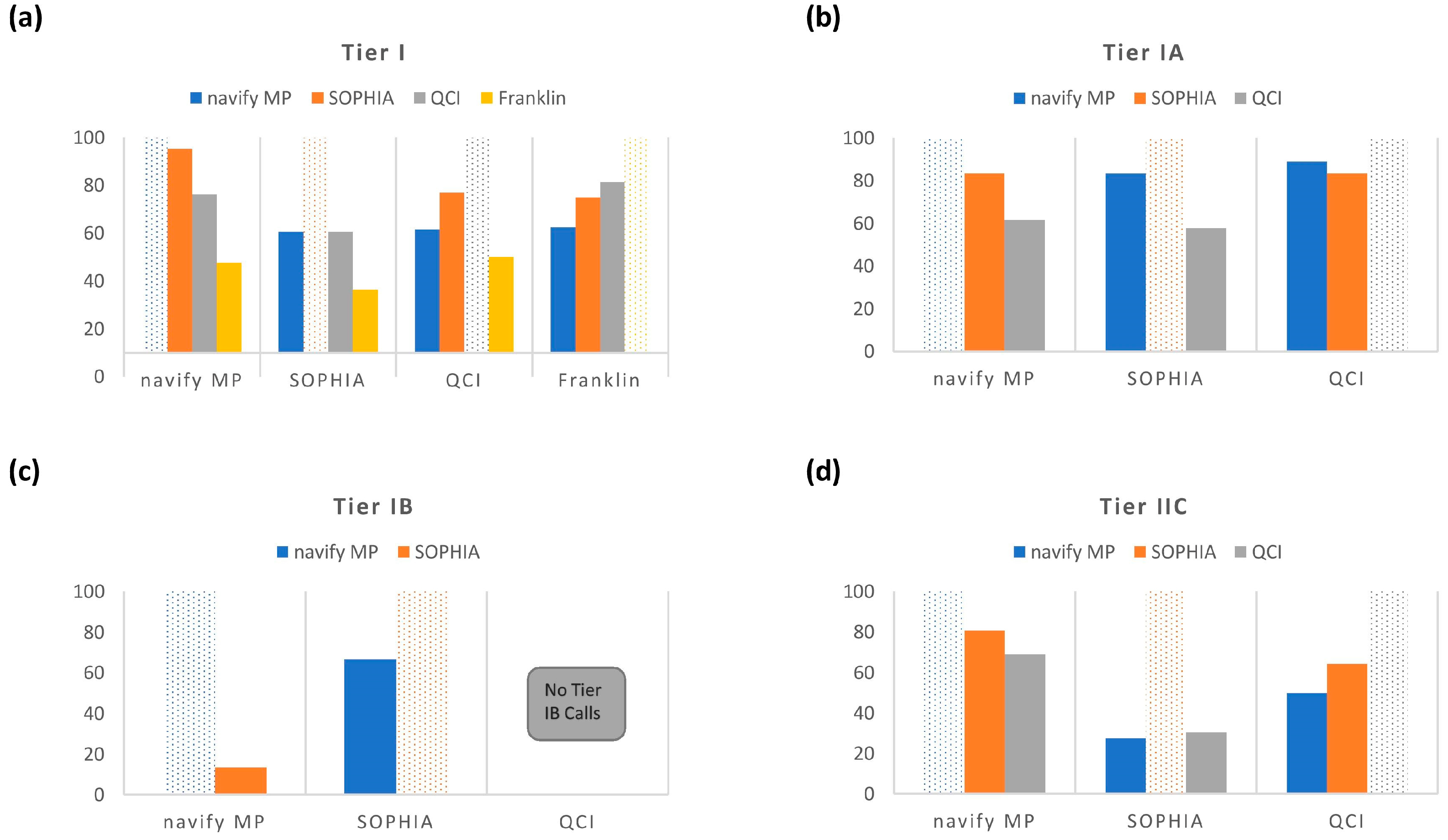
Across all four annotators, in general, classification concordance for Tier I and II variants was quite variable (
Figure 4). Clearly, there was a stark difference in the observed Tier I concordance with the Franklin annotator compared to the other tools. One possible explanation is that simply combining Tiers IA and IB in the other annotators may not actually be equivalent to Franklin’s “Tier I”, potentially due to different evidence sources at play. This is currently unclear but highlights the importance of questioning tiering rules when choosing an annotator, especially for high impact AMP/ASCO/CAP categories such as Tier I and II. These findings also may suggest different levels of robustness between commercial and free tertiary analysis solutions. That stated, there were demonstrations of discordance even across the three commercial annotators as evidenced by PPA comparisons made across just those tools (
Figure 4b–d). For example, for Tier IA, the PPA between QCI vs. SOPHIA was 57.7% (
Figure 4b) with an even lower PPA observed (27.4%) for Tier IIC calls between navify MP and SOPHIA (
Figure 4d). These low PPA observations may be explained, in part, by gene-level nuances. In the case of Tier IIC, 132 (52.6%) variants in this category did not overlap among any of the annotators (
Figure 2b). Upon closer examination of the 84 variants that were unique to navify MP for Tier IIC classification, it is interesting to note that 17 of these variants belong to the
TET1 gene (
Figure 2a;
Table S1). In this case, these variants were grouped into the broad category of “
TET1 mutation” to reflect content that described variants at this level. This behavior is not unique to navify MP. All annotators have handling for broader mutation groups, mostly notably of the type called “inactivating/activating” mutations. In these cases, users should take extra care to scrutinize the evidence for such mutations to determine relevance for their case.
In general, the comparisons made across annotators for Tier IA revealed tighter concordance overall than for Tiers IB and IIC (
Figure 4b–d). Notably, the highest PPA for Tier IA was between QCI and navify MP (PPA-88.9%). However, with Tier IA being the least subjective category in the AMP/ASCO/CAP guidelines (discussed below with respect to
Table 3), the expectation would have been that concordance would be high and similar for all possible comparison permutations. But this was not the case and raises concerns since Tier IA is the most actionable category. It’s possible that concordance would be higher for specific cancer types and it would be interesting to understand whether classification concordance improves for variants from specific cancer types. For example, it would be expected that Tier IA classifications would be more highly concordant across annotators for variants from non-small cell lung cancer cases since this type of cancer is rich with targetable biomarkers in the NCCN guidelines [
8].
While concordance for Tier I and II variants in this study was variable, it is important to note that NPA analysis depicted strong agreement for all 4 annotators (
Figure S1). Furthermore, the sample sizes for NPA calculations were much higher than the ones used for PPA, as variants from this testing had a much higher tendency to not be classified as Tier IA, IB, or IIC. This may also indicate that these variants are not somatic i.e., common germline, or are possibly skewed to a few specific tumor types. In addition, the high NPA as compared to PPA observed for classifications across the four solutions supports the notion that positive calls are fraught with complexities not present in negative calls. The lack of strong concordance in positive calls was previously demonstrated in a similar study published in 2020 [
9], where navify MP and QCI were compared and found to have 14/61 (23.0%) concordant Tier IA classifications. This is significantly lower than what was observed for Tier IA alterations in the present study. However, for Tier IB classifications, the previous study [
9] had higher concordance between navify MP and QCI (8 out of 39; 20.5%). These differences between studies implicate multiple factors, including a lower sample size in the previous study (
n = 48) compared to the current study (
n = 80), tumor type differences (e.g., lung cancer comprises 39% in the previous study vs. 20% in the current study), new approvals and new study data, as well as statistical analysis differences (Kappa statistic in the previous study vs. PPA/NPA in the present study).
In the present study, a Kappa statistic was intentionally not used and instead positive percent agreement (PPA) and negative percent agreement (NPA) [
7] were employed in order to account for the lack of a true gold standard reference, as well as account for small sample sizes. The absence of a gold standard is underscored by the weak (59%) concordance demonstrated in the Variant Interpretation Testing Among Laboratories (VITAL) study where 134 participants interpreted the same 11 variants across 4 cancers using the AMP/ASCO/CAP guidelines [
10]. The strength of PPA and NPA to compare tier classifications between annotators is the ability to gain a more targeted and meaningful assessment of the annotators’ performance in identifying relevant variants and ensuring that the classifications are aligned with the relevant context. In contrast, the Kappa statistic may not provide the same level of specificity, especially when the primary focus is on accurately identifying disease-associated variants. In addition, the Kappa statistic is not ideal for comparing auto-classification of tiers since it takes into account the potential for guessing (which never occurs in auto-classification) and makes certain assumptions about the independence of the comparators, thus potentially providing an underestimate of the level of agreement between comparators [
11].
In this study, complex variants, including microsatellite instability (MSI) status, tumor mutation burden (TMB) levels, amplifications, fusions, exon skipping, and combination alterations were separately analyzed (
Table 2;
Table S3) across navify MP, SOPHIA, and QCI, as these three annotators had support for this category, while the Franklin annotator did not (
Table 1). For the four complex variants across 57 cases,
Table 2 shows classifications by the three annotators were largely in agreement.
It is important to note that complex-type biomarkers are not “in scope” for the AMP/ASCO/CAP guidelines; therefore, tertiary analysis solutions must assess them and provide classifications under their intended uses. This has led to annotators applying “AMP/ASCO/CAP guideline-like” tiering to such biomarkers as evidenced by the classifications seen for these types of alterations in such tools. For example, SOPHIA and navify MP auto-classified several combination alterations, which QCI did not. In addition, navify MP automatically classified wildtype NRAS/KRAS in a colorectal adenocarcinoma case as Tier IA, while QCI did not. This finding was, however, expected in this case as “pertinent negative” genes, including NRAS/KRAS were not pre-defined in the metadata for the analyses performed in QCI (underscoring the criticality of specifying pertinent negatives in platforms that require it in order to not miss actionable biomarkers of this nature). Furthermore, navify MP and QCI auto-classified several cases of TMB-high as well as key gene amplifications (including ERBB2 amplification and MET amplification), but SOPHIA did not. In the software version used for this study, it appeared that SOPHIA took a more conservative approach for some complex variant types, including TMB and CNVs. While SOPHIA calculated TMB levels, they did not auto-classify TMB alterations into tiers. SOPHIA also did not auto-classify several CNV amplifications and provided a rationale of a strict requirement for eight samples or more in the same run to address the possibility of a batch effect bias.
Multiple factors may explain the complexities and lack of concordance across different variant annotation software solutions. It is therefore important to consider how these factors may influence the performance of these decision support tools. In the next sections, several reasons for lack of concordance are proposed and discussed.
4.1. Subjectivity in the Guidelines
We believe that the lack of concordance seen across the solutions is in part due to the fact that the underlying classification structure published in the AMP/ASCO/CAP guidelines [
3] has a large degree of subjectivity, as evidenced by ambiguity in words and phrases describing different types of evidence that power the tier classifications. Tier I evidence definitions have four subjective words or phrases while Tier II evidence definitions have seven subjective words or phrases (
Table 3). These phrases may indeed be interpreted differently by different individuals.
For example, for Tier IB (
Table 3, Row 2), several questions have arisen for the guidance that the variant should be the focus of “well-powered studies with consensus from experts in the field”. How does one define a well-powered study? By sample size? By study type? By journal in which it is published? Also, what constitutes “consensus?” Two concordant studies? 10 concordant studies? 100 concordant studies? And how does one define an “expert in the field?” Individuals with specific credentials? Individuals with a certain number of publications? Individuals only in the genomics field? Clearly, there are many questions, and this guidance for Tier IB is a good example of where there needs to be further definition by AMP/ASCO/CAP to standardize language in order to ensure consistency in Tier IB classifications, as well as other tiers with subjective phrasing in the guidelines.
4.2. Variant Allele Frequency (VAF) Thresholds
It is important to highlight that different annotators have different variant allele frequency (VAF) threshold defaults for variants identified from tumor sequencing.
Table 1 shows default VAF settings for navify MP (none), SOPHIA (2%), QCI (5%), and Franklin (5%), where variants under these thresholds are filtered out and not subjected to classification. navify MP does not impose a default VAF setting and provides users the opportunity to define the threshold when creating an assay or for each individual case. For this study, a VAF cut-off was not defined in navify MP, and here is an example of a potential negative consequence of not doing so. When investigating discrepant variant classifications across annotators,
RB1 p.E209* was uncovered in a breast cancer case where the tier classifications were as follows: Low Confidence (LC)—SOPHIA, Tier IB—navify MP, LC—Franklin, Tier III+—QCI. This variant had a VAF of 1.7%, which resulted in a low confidence annotation via SOPHIA and Franklin (with default VAF cutoffs of 2% and 5%, respectively). Upon closer investigation of the Tier IB classification by navify MP, it was clear that this variant should not have passed through and been classified due to the low VAF. Not filtering out the variant in question resulted in a classification based on broader categorization of this variant as an
RB1 inactivating (truncating) mutation. It is therefore critical to ensure that VAF cut-offs are determined ahead of time based on the analytical sensitivity of the specific assay used, where the user should establish the lowest VAF that can reliably be detected at a given amount of input DNA/RNA.
4.3. Minor Allele Frequency (MAF) Thresholds
Another notable characteristic is the gray line cutoff of the minor allele frequency (MAF) thresholds across annotators. MAF measures the frequency at which the variant (minor allele) is seen in general population, where the significance cutoff has been reported to range from 1% to 5% [
3]. Of the annotators in this study, only QCI and Franklin have default thresholds of 1% for MAF, while navify MP and SOPHIA do not have default MAF thresholds and rely upon user definition (
Table 1). One variant,
BRCA1 p.Q356R from a pancreatic adenocarcinoma case, had a wide range of tier classifications across the annotators: Tier IA—navify MP, Tier IA—SOPHIA DDM, Tier III+—QCI, Tier IV—Franklin and was therefore flagged in this study for a deeper dive investigation. This
BRCA1 variant had a MAF of 4.7%, which resulted in being filtered out in QCI and Franklin, and explains their Tier III+ and Tier IV classifications, respectively. Without MAF thresholds set, both navify MP and SOPHIA classified this as Tier IA, which would not have been the case had the MAF threshold been set accordingly.
Another variant,
TERT c.-245T > C, was classified as follows: Tier IA—navify MP, LC—SOPHIA, QCI—III+, Franklin—Tier IV. This variant had a high MAF as reported in gnomAD, varying from 12% in African/African Americans to 52% in South Asians. In spite of these high MAFs, the variant was classified as a Tier IA variant for glioblastoma via navify MP based on strong, supporting evidence for
TERT promoter mutations, in general [
12,
13]. This raises two important considerations users should understand about their population: (1) pre-defining the MAF cutoff should be considered to avoid potentially misleading results; and (2), more importantly, users need to recognize that the MAF varies by genomic ancestry. Thus, pre-defined cut-offs could remove important variants that differ in frequency by ancestry.
4.4. Disease Ontologies
Disease ontology differences can contribute to tier classification differences that may not be evident when using broad cancer types, such as “breast cancer”.
BRCA1 p.Q356R was depicted in two separate cases, one ER+ breast cancer case as well as one triple-receptor negative breast cancer case. In the absence of a MAF filter (as described above), this variant was considered to be in a class of “inactivating
BRCA1 alterations” and thus, was auto-classified by navify MP as Tier IB for ER+ breast cancer due to well-powered studies [
14,
15] and Tier IIC for triple-negative breast cancer due therapies indicated for a different type of breast cancer. The message therefore is that it is very important to be as specific as possible with input cancer types, as variants can fall in or out of higher tier classifications strictly based on the cancer type selected. Choosing a less specific cancer type will often cause inclusion of additional information potentially not relevant to the case at hand.
4.5. Additional Considerations
There are additional factors that may account for tier classification differences, and several are summarized below.
4.5.1. Genome Builds
Discrepancies arising from diverse genome builds (e.g., GrCh38, hg38, GrCh37, hg19) influence the genomic coordinates assigned to variants, affecting their positional accuracy and compatibility with various reference genomes. Some annotators are set up to support VCFs generated from a wide variety of genome builds (e.g., QCI), while others (e.g., navify MP) are optimized for a primary genome build and then perform a liftover function to map coordinates from one build to another. This may cause variants to fail liftover for regions in the primary genome build that are not present in other builds.
4.5.2. Splice Site Regions of Interest
Annotators have distinct regions of interest which are driven by their intended application. When a variant does not fall in these regions, they may be filtered out of the analysis. This was the case for a TP53 variant (c.920-2A > G), where navify MP and QCI classified this variant as Tier IIC, while SOPHIA called this LC due to being an “off-target” region. This may cause missed highly relevant variants, an incomplete biological understanding, or skewed data interpretation when excluding a variant based on predefined regions. It is advisable to periodically review and update the predefined regions of interest, considering the evolving knowledge in the field and the potential implications of variants outside these regions.
4.5.3. Classification Context
Classification contexts of “therapeutic, diagnostic, prognostic”, and/or hereditary significance [
3,
4,
5] can lead to mis-prioritization of variants, thus impacting the interpretation of variants for specific applications. For example,
TERT promoter alterations are evidenced to be “diagnostic” for glioblastoma as stated in the NCCN and WHO guidelines [
16,
17]. One of the glioblastoma cases in this study, previously mentioned above, harbors a
TERT c.-245T > C variant where 3 annotators (navify MP, QCI, and Franklin) provided a classification (this variant was classified as a “low confidence” call in SOPHIA). Only navify MP classified this variant as Tier IA, as this qualifies as a “diagnostic” Tier IA classification in accordance with the AMP/ASCO/CAP guidelines [
3]. Both QCI and Franklin classified this variant as Tier III or IV, presumably due to having different rules around classification context. Understanding whether a tier classification is “therapeutic, diagnostic, and/or prognostic” in accordance with guidelines [
3,
4] is therefore critical to proper interpretation of variants and this context should be as transparent as possible in tertiary analysis solutions to avoid misinterpretation. While not the immediate focus of this study, an interesting follow-up activity would be to measure AMP/ASCO/CAP tier classification concordance for therapeutic significance vs. diagnostic/prognostic significance.
4.5.4. Implications of Variant Misclassifications
Over-classifying variants to a higher tier can severely impact downstream management and lead to wasted resources, ethical concerns, and issues with data quality and reproducibility. In this study,
PIK3CA variants have been subject to overcalling, as this gene is known to be of high relevance to disease [
18]. For example, of the 10 variants that only QCI classified as Tier IA (
Figure 3a), 7 of these were
PIK3CA variants. This dramatically affected PPAs for QCI compared to navify MP and SOPHIA, which were 61.5% and 57.7%, respectively (
Figure 4b). This highlights the need for users in certain cases to confirm any suspicious Tier I and II calls with additional review of literature and trusted databases.
Under-classifying variants to a lower tier can also have profound implications. In this study, there were many examples of classification discordance, and inevitably, some of this discordance stemmed from the under-classification of variants. For example, of variants classified as Tier I (A or B) by navify MP, SOPHIA, and QCI, there were six variants classified as non-IA-IB-IIC by the Franklin annotator (
Table S1). It is important to recognize cases of both over- and under-classification through regular quality control measures and provide feedback of any issues to the tertiary analysis software support teams.
As with any comparison-type study, it is crucial to ensure an “apples to apples” strategy is employed to interrogate the data. As a follow-up to this study, it would be interesting to understand the nature of variants that were not present in all four annotators to understand the level at which variants were “unfit” for classification comparisons. This type of exercise would likely uncover interesting nuances in secondary analysis, variant processing for tertiary analysis, and specific rules in tertiary analysis software solutions that result in lack of tier classification. For example, SOPHIA and Franklin have created rules to categorize post-processed variants as “LC”, or low confidence, and understanding the concordance for this category across both annotators would be useful. Finally, we recognize that since the time the data were captured and compared, it is possible that newer versions of all the annotators would show improved calls of Tier I and II variants based on updated content and/or software feature enhancements. It would be of paramount interest to perform the same analysis over time to see if concordance improves across the annotators in this study.


 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}