1. Introduction
Rainfall–runoff modelling is believed to be complex, nonlinear, and time-varying because the basin response depends not only on hydrometeorological parameters but also on spatiotemporal irregularity in basin characteristics and rainfall patterns [
1]. Usually, hydrologists develop and use different types of models to simulate hydrological processes. Regardless of their structural variations, these models generally fall into three main types, including physical, conceptual, and data-driven models (DDMs) [
2].
Over the past two decades, data-driven approaches based on artificial intelligence (AI), have gained drastically increasing interest from hydrologists [
3], due to their significant contribution to improving the accuracy, versus the failure stories, of the classical and conventional methods in terms of spatial scale, time scale, the amount of data needed, facilities, the inability to handle nonlinear and nonstationary hydrological processes, and even in terms of accuracy, viewing the complexity of the equations governing the hydrological cycle’s mechanisms which often require simplifications and theoretical assumptions leading to considerable errors and uncertainties [
4].
Many different statistical methods, such as multiple linear regression (MLR), and various types of AI and machine learning (ML) algorithms such as support vector machines (SVM) and artificial neural networks (ANN), have been widely applied in recent years [
5]. Especially, ANN and SVM have the advantage of handling complex relationships between input and output variables and have been used successfully in various water resources problems [
6]. However, despite the application of several ML techniques available in the literature, the gradient boosting (GB) approach has not been widely applied to predict daily flows [
7]. Also, for hydrological extremes, GB and random forest (RF) are more often explored for qualitative predictions rather than quantitative predictions [
4].
In this sense, this paper presents the application of three regression ML algorithms—support vector regression, random forest regression and gradient boosting regression—were compared to MLR and used to model the daily flow discharge at the outlet of the Besós River basin (Spain) under two scenarios: without and with consideration of the antecedent hydrologic conditions. The objective is to discuss and evaluate the performance of the aforementioned DDMs in daily streamflow prediction based on open-source flow discharge and rainfall historical time series by comparing them with each other and with the MLR model based on several statistical evaluation measures, and to evaluate the impact of using the preceding hydrologic conditions.
3. Results and Discussion
The values of the DDM-statistical performance metrics for the training and test periods are presented in
Table 1. Hydrographs were also plotted to visualize the DDM behaviour, particularly for extreme values.
It is clear from
Table 1 that the RFR and GBR models were more efficient in predicting the flow for the first scenario, in the training period, with a slight victory for the RFR model, reaching R
2 values of 0.945 and 0.936, respectively; RMSEs of 0.983 m
3/s and 1.062 m
3/s; MAEs of 0.259 m
3/s and 0.558 m
3/s, and approximately equal NSEs. However, the SVR outperformed all models in the test period for all metrics.
MLR performance was not as good as that of the three other DDMs, but it was very acceptable concerning performance metrics. It outperformed the RF model in the test period with respect to the MAE and the SVR model in the training period regarding the NSE. The fact that the MLR prediction values have a good correlation with the observed values is related to the fact that the number of input gauging stations was slightly higher than that of meteorological stations, that the flow discharge values had more weight in the MLR equation than those for rainfall, and that the flow inputs showed a good linear correlation with each other, unlike the rainfall inputs.
Interestingly, the prediction results are satisfactory, and there are some improvements in the performance of the models in the test period compared to the training period, except for GBR regarding the R² and NSE and RFR regarding the MAE, R² and NSE. This may have been the result of overfitting these models.
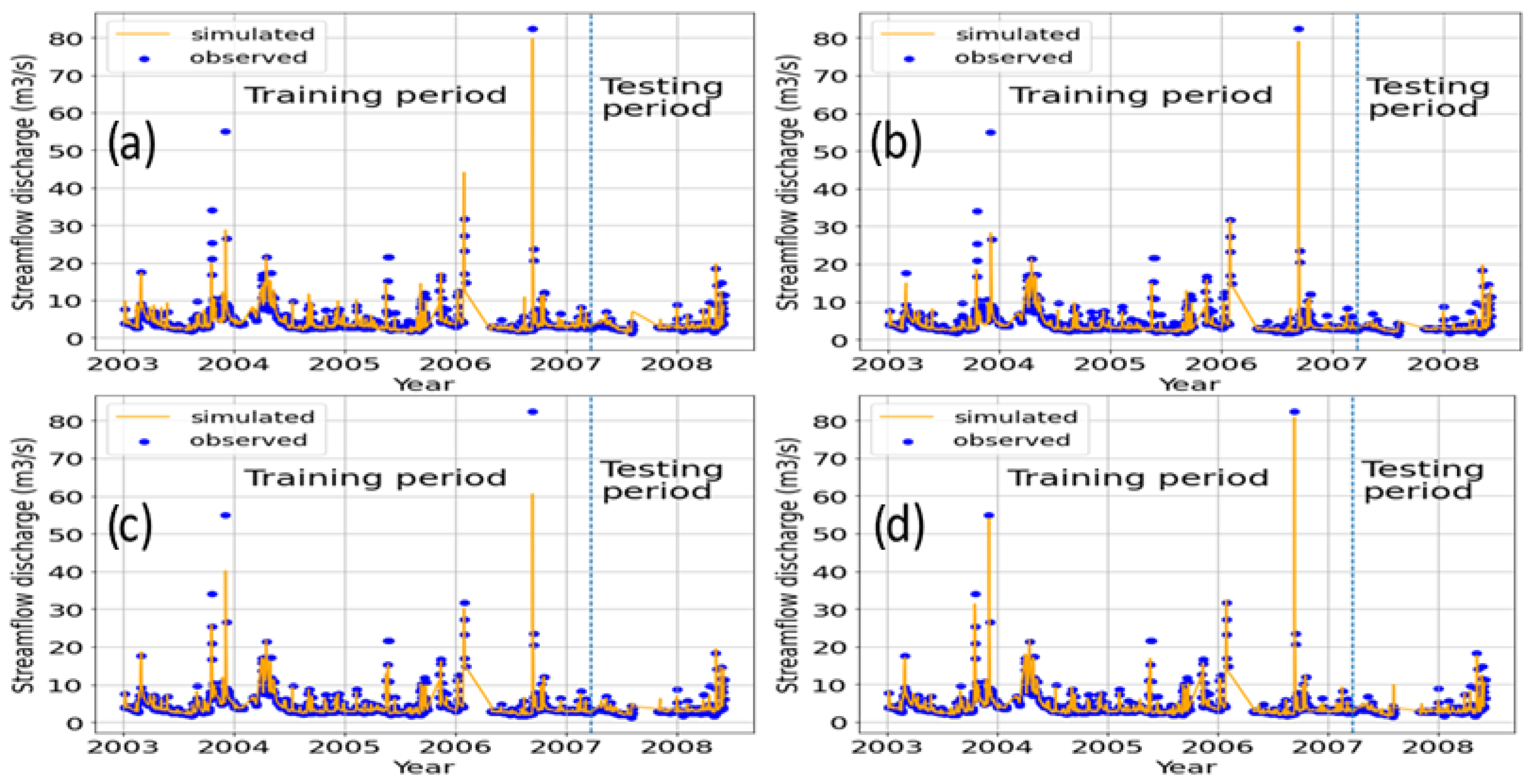
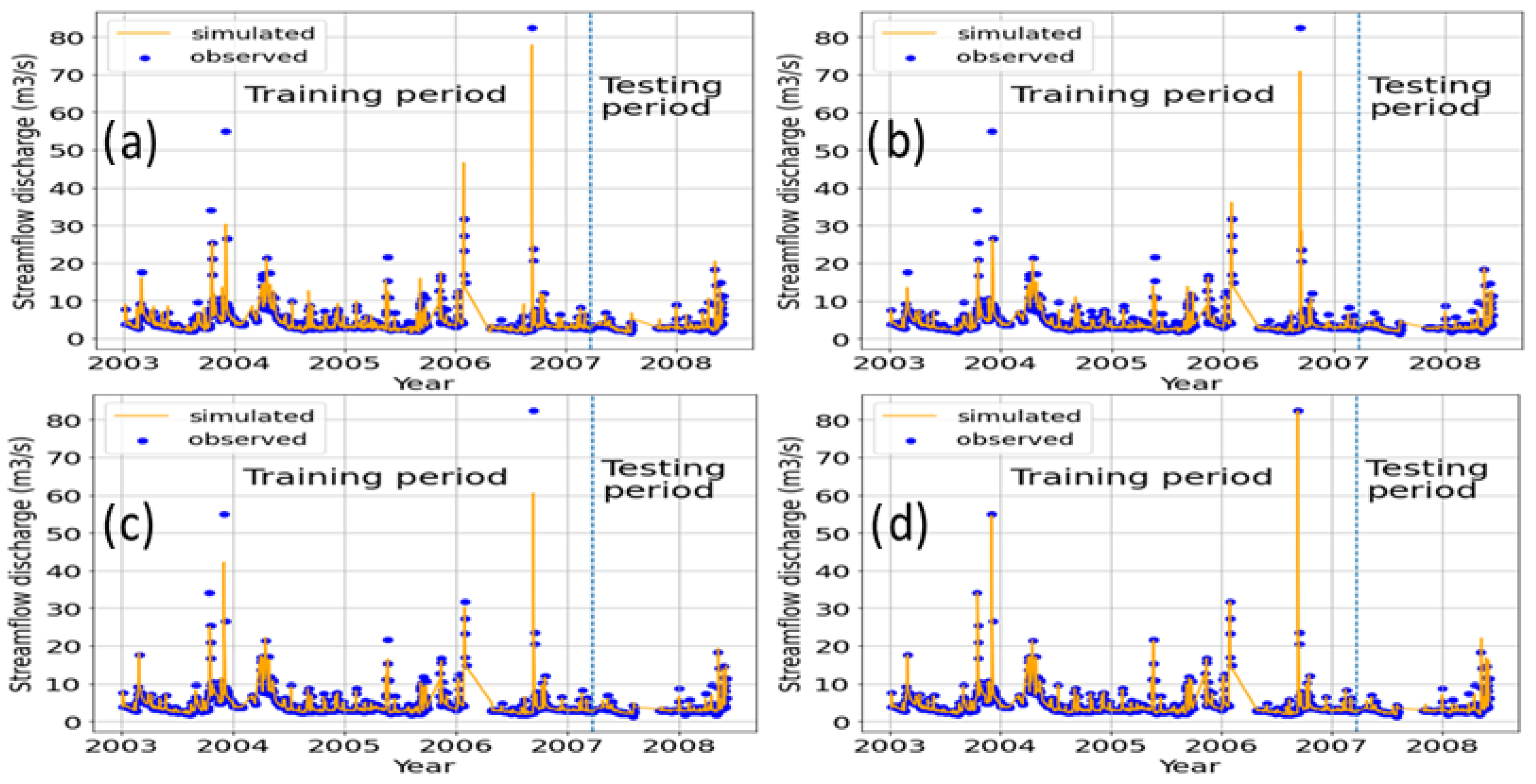
The hydrographs in
Figure 2 and
Figure 3 of the observed and predicted values for each model in the training period, as well as the test period at the target station, indicate that, in general, the predicted flow fits well with the observed flow.
However, for the training period, it can be seen that there were more peaks than there were in the test period. The maximum peak observed in the training period was underestimated by all the models, but it can be seen that MLR, SVR and GBR managed to approximate it well, while RFR presented a high relative error at this point. In general, the RFR had the best performance in the training period.
Possible reasons for this result could be the better generalisation ability of SVR due to the structural risk minimisation approach which led to an optimal global solution. Regarding the overfitting of the GBR and the RFR models, it should first be remembered that these two models are based on building trees from a random Bootstrap sample, which makes both models stochastic, with an uncertainty associated with the predicted value. The high number of trees that was found to have trained the two models may have been behind this overfitting. Also, GBR is a nondeterministic algorithm; i.e., even for the same input, it can present different outputs in different executions.
Regarding the second scenario, the GBR outperformed all models in the training period with near-perfect performance. In the test period, the SVR in this case was also the best regarding all metrics.
Some DDM performance improvements were shown in the test period compared to the training period. Regarding SVR, all metrics improved. For MLR, only RMSE and MAE improved. In contrast, the GBR and the RFR showed a decrease in their performance, except for the RMSE of the RFR, which improved. This overfitting, in addition to the aforementioned reasons, may have been due to the insufficient data size, or that the data’s split ratio for training and testing the models was not adequate. Generally, the simulated hydrographs fit well with the observed hydrographs. It is seen that GBR has a great ability to predict flow peaks. All models predicted the flow at the basin outlet well.
When comparing the DDMs, it can be seen that the use of the antecedent flow discharges had a great impact in improving their performance, with a reduction in the MAEs of 23%, 17%, 21% and 33% for the MLR, SVR, GBR and RFR models. The RFR showed the greatest improvement in performance during the test period with a decrease in the RMSE and MAE of 18% and 33%, and an increase in the R² and NSE of 6% and 7%, respectively.
4. Conclusions
To predict the daily flow at the outlet of the Besós river basin, the MLR and three data-driven ML models, SVR, RFR and GBR, were used. The obtained results show that the SVR model outperformed the other models whether or not the preceding hydrologic conditions were considered. MLR, as well as the decision tree ensemble models (RFR and GBR), has also shown a good flow prediction capacity. It is worth noting that the proposed DDMs have demonstrated high efficiency in capturing the real trend and the underlying phenomena of rising and falling flow curves. The use of the antecedent flows in the target gauging station had a positive impact on improving the performance of all models.
To improve the prediction capabilities of ML models, in future work, it is recommended to use other variables to build a strong relationship with the streamflow; to perform a sensitivity analysis of input features to bring out those that contribute the most to the flow prediction; to pay close attention to the data length and split ratio; to ensure that the training phase experiences most of the streamflow patterns to allow the models in the test period to simulate the flow discharge with an acceptable level of accuracy.




{kind=link}
{kind=link}
{kind=link}