1. Introduction
In recent decades, the frequency of extreme events, including natural disasters such as droughts, heatwaves, floods, hurricanes, wildfires, earthquakes, and winter storms, as well as man-made disruptions like cyber-attacks, has notably increased [
1]. Research conducted by the U.S. Energy Information Administration has confirmed a significant rise in the occurrence of weather-related extreme events in the United States between 1992 and 2012 [
2,
3].
Figure 1 provides a visual representation of the notable increase in weather-related extreme events in the United States, characterized by economic damages exceeding one billion dollars. The data, sourced from the National Oceanic and Atmospheric Administration [
4], spans the years from 1980 to 2022. Notably, the year 2022 witnessed the occurrence of 18 severe weather-related disasters within the United States, each resulting in economic losses exceeding the billion-dollar threshold. Extreme events are impacting regions across the globe, not limited to the United States. Examples of such events include a severe storm in Australia in 2016, a windstorm in Canada in 2015, and the 2016 tornado of Jiangsu Province in China [
5]. These events have had a devastating impact on critical power and energy system components, resulting in extensive and prolonged power disruptions. The significant increase in the frequency and economic impact of extreme weather events, as depicted in
Figure 1, underscores the pressing need for resilient power and energy systems.
The growing influence of global warming, exemplified by the increasing prevalence of hurricanes and other natural disasters, has heightened the importance of power and energy system resilience. While power infrastructure has historically focused on reliability, aiming to withstand known threats and ensure uninterrupted power supply, the rise in extreme weather events presents a significant challenge [
6]. Between 2003 and 2012, approximately 679 large-scale power outages in the United States were attributed to extreme weather, each affecting a minimum of 50,000 customers and resulting in an annual economic loss exceeding USD 18 billion [
3]. These recurring and disruptive events underscore the limitations of current power facilities in effectively mitigating their impact [
7]. While the likelihood of extreme natural events may be relatively low, the severity of their impact is indisputable. Consequently, there is an urgent need to enhance power and energy systems’ resilience to withstand and recover from such events.
Figure 1.
Occurrence of climate disasters in the United States from 1980 to 2022 [
8].
Figure 1.
Occurrence of climate disasters in the United States from 1980 to 2022 [
8].
To enhance the reliability and resilience of power and energy systems, various analytical and population-based heuristic approaches employing dynamic modeling and optimization techniques have been used in the literature. For instance, previous work [
9] has utilized dynamic modeling and classical optimization to address threats like wildfires to power distribution networks, focusing on resilience with renewable energy resources and evaluated on a 33-node distribution system. Another study [
10] analyzed microgrid operation using a multicarrier energy hub, considering various energy carriers and resources to reduce environmental impact and operational costs while enhancing resilience and flexibility. Similarly, methodologies based on graph theory and cooperative game theory [
11,
12] were introduced to determine optimal locations and sizes of movable energy resources for power distribution system resilience. Additionally, an optimal energy storage sizing method [
13] aimed to improve reliability and resilience in networked microgrids through bi-level optimization, showcasing the benefits of microgrid interconnection in enhancing both reliability and resilience during grid outages compared to non-networked microgrids. Furthermore, addressing the impact of unfavorable weather and natural disasters, an article [
14] emphasized evaluating network resilience and proposed a cost-effective method involving tie-lines for power restoration, outperforming other optimization techniques. In [
15], a labor-economics-based framework, employing contract theory, was introduced to model interactions in modern smart grid systems, focusing on the microgrid operator and prosumers, with the potential to establish optimal personalized contracts for energy selling and purchasing, thereby contributing to resilient energy management and control in smart grids while satisfying the involved parties’ profit and requirements. The evolutionary swarm algorithm (ESA) [
16] was introduced for reliability assessment, offering advantages in accuracy, computational efficiency, and precision over other heuristic approaches. However, these analytical and heuristic techniques have limitations, including modeling inaccuracies due to data scarcity and scalability challenges [
17]. Additionally, these methods require repeated calculations when applied to new scenarios [
18]. To address these shortcomings, recent advances have introduced deep reinforcement learning (DRL)-based approaches for enhancing the resilience of power and energy systems.
Within power and energy systems, DRL, a combination of reinforcement learning (RL) and deep learning, has emerged as an attractive alternative for conventional analytical and heuristic methods, offering solutions to their inherent shortcomings. Similar to other learning-driven methodologies, DRL makes use of past experiences to inform decision making. In [
19], a real-time dynamic optimal energy management system for microgrids utilized DRL, specifically the proximal policy optimization (PPO) technique, to enhance efficiency and stability while integrating renewable energy sources. This approach showcased superior computational accuracy and efficiency compared to conventional mathematical programming or heuristic strategies. Additionally, in [
20], a new energy management approach employed DRL within a Markov decision process (MDP) framework to minimize daily operating costs without the need for explicit uncertainty prediction, highlighting its effectiveness with real power-grid data. Furthermore, an innovative DRL-based Volt-VAR control and optimization method was introduced in [
21], showcasing its effectiveness in improving voltage profiles, reducing power losses, and optimizing operational costs on various test cases. References [
22,
23] implemented Volt-VAR optimization in distribution grids with high DER penetration and volt-VAR control in active distribution systems, respectively, both leveraging DRL for efficient reactive power management. A DRL-based trusted collaborative computing has been proposed and analyzed in [
24] for intelligent vehicle networks. A federated DRL-based approach for wind power forecasting has been proposed in [
25], which is supposed to handle data sharing and privacy concerns. Beyond these aforementioned DRL applications, there is a growing landscape of wide-area applications in enhancing power system resilience, making this review paper a comprehensive exploration of DRL’s increasing significance in this field.
Numerous review papers exist in the fields of power and energy systems, resilience improvements, and DRL. The review papers [
5,
26] explored a variety of topics, from conventional power system resilience methods to the metrics and assessment techniques for power system resilience. The review paper [
27] comprehensively discussed machine learning strategies and their applications in conserving energy and managing it effectively, emphasizing their efficiency in addressing various decision and management challenges. Reference [
28] discussed the transformation of power systems into cyber-physical systems (CPSs) and the unique resilience challenges posed by CPSs. The paper also highlighted the differences between conventional power systems and cyber-physical power systems (CPPSs), delving further into the realm of cyber-physical disturbances, resilience techniques for CPPSs confronting natural hazards and cyber threats, and the intriguing dimension of leveraging social behaviors to enhance CPPS resilience. Additionally, the review paper [
29] scrutinized RL techniques in the context of power and energy systems, covering RL concepts, algorithmic diversity, and real-world applications, while considering the future course of RL within these domains. Reference [
30] explored the utility of RL in navigating the intricacies of energy systems, offering an insightful classification of RL applications within the energy landscape and highlighting its potential to tackle rising system complexities, even as it struggles with utilization and benchmarking challenges. Lastly, the review paper [
31] unraveled the expansive domain of DRL in power systems, highlighting foundational concepts, modeling intricacies, algorithmic diversity, and contemporary advancements. However, amid this wealth of knowledge, a significant gap exists: the application of DRL to enhance resilience in power and energy systems. Notably, previous works have primarily focused on showcasing the capabilities and applications of DRL in these domains, often overlooking the need to provide a comprehensive overview of the existing limitations, challenges, and future avenues. Given the increasing reliance on DRL for resilience enhancement within these domains, this review paper emerges as a pivotal and missing link, illuminating the transformative potential of DRL in steering the trajectory of resilient power and energy systems.
In this article, an overview of the current progress in applying DRL to enhance the resilience of power and energy systems is presented. The foundations of different categories of DRL methods, including value-based, policy-based, and actor–critic methods, are laid out to aid in the understanding of their applications. Subsequently, an exploration of DRL applications within various domains of resilient power and energy systems, including dynamic response, recovery and restoration, energy management and control, communications and cybersecurity, and resilience planning and metrics development, is undertaken, with a focus on outlining the detailed methodologies and contributions of these studies. This in-depth analysis of DRL applications is followed by a discussion of the challenges and limitations associated with incorporating DRL into resilient power and energy systems. These revelations shed light on the practical limitations and possible consequences that researchers and practitioners need to take into account. Finally, the future is examined and a roadmap of potential research possibilities in this area is provided. Novel discoveries and solutions are eagerly anticipated in this field of research.
The remainder of this review article is organized as follows:
Section 2 provides an introduction to DRL and its various categories.
Section 3 offers a detailed exploration of DRL applications across various dimensions of resilient power and energy systems.
Section 4 examines the existing challenges, limitations, and opportunities for future research in DRL applications for power and energy system resilience. Finally,
Section 5 summarizes the key findings and highlights the transformative potential of DRL in ensuring the resilience of critical power and energy infrastructure.
3. Deep Reinforcement Learning Applications in Different Aspects of Resilient Power and Energy Systems
This section presents an in-depth exploration of the multifaceted applications of DRL within various critical aspects of resilient power and energy systems. Power and energy system resilience refers to the capacity of a power and energy infrastructure to endure, absorb, and promptly recover from various disruptions, including natural disasters and man-made events, while maintaining the continuity and reliability of power supply to end consumers [
59]. This concept acknowledges the increasing challenges posed by extreme weather events, cyber-attacks, climate change, and the need for adaptive responses in the power sector. Evaluating the resilience of a complex system, particularly in the context of power and energy systems, necessitates a comprehensive and systematic approach. The Disturbance and Impact Resilience Evaluation (DIRE) methodology offers precisely such a framework for assessing and enhancing resilience [
60]. In
Figure 5, the various stages within the DIRE approach are illustrated, each of which plays a critical role in resilience assessment and evaluation. The DIRE framework consists of five distinct stages, namely, reconnaissance (recon), resist, respond, recover, and restore. These stages are integral in assessing a system’s ability to endure and adapt to disruptions. DRL emerges as a powerful tool that finds applications across all of these resilience stages. DRL offers the capacity to adapt, optimize, and enhance system behavior in response to evolving conditions and disturbances, making it a valuable asset in the pursuit of resilience.
Figure 5 not only depicts the stages but also showcases typical DIRE curves for both resilient and unresilient systems. These curves offer a visual representation of how system performance evolves over time in the face of extreme events and disturbances. It is clear from the figure that after an extreme event occurs, at time
, the performance level of the system undergoes a deterioration. This decline in performance persists throughout the “resist” stage until reaching time
. However, the “respond” stage, which extends to
, marks the onset of a slow but steady performance improvement. Subsequently, as the system enters the “recover” and “restore” stages, its performance continues to improve, ultimately returning to pre-disturbance levels.
Power and energy system resilience encompasses a spectrum of research areas and methodologies, including the development of resilience metrics, resilience planning, and operational resilience enhancement, each addressing critical aspects of ensuring the robustness of power and energy systems.
Figure 6 shows five different aspect categories of resilient power and energy systems that are outlined in this section. Understanding these aspects of resilient power and energy systems is critical for devising comprehensive strategies to ensure the reliability and robustness of power and energy infrastructure in the face of evolving challenges and disruptions. Each aspect contributes to a holistic approach aimed at enhancing the resilience of power and energy systems and safeguarding the uninterrupted supply of electricity to end consumers.
3.1. Dynamic Response
Dynamic response consists of adaptive measures and strategies aimed at addressing and mitigating the consequences of unforeseen and critical events or disasters, whether natural or human-made. These events may include hurricanes, earthquakes, floods, wildfires, cyber-attacks, industrial accidents, or acts of terrorism. Dynamic response can operate proactively, linking situational awareness with resilience enhancement and ensuring effective and efficient responses in both preventive and emergency contexts [
61]. The primary objectives of emergency response in the context of power and energy systems resilience include ensuring the integrity and functionality of critical infrastructure, minimizing downtime, and restoring operations swiftly and effectively.
Table 4 presents a summary of papers on DRL applications in the dynamic response aspect of resilient power and energy systems.
In [
62], a new model-free online dynamic multi-microgrid formation (MMGF) scheme for enhancing power system resilience was introduced. This approach formulated the dynamic MMGF challenge as a Markov decision process and tailored a comprehensive DRL framework for microgrids capable of changing their topologies. To address the complexity of operating network switches, a search space reduction technique based on spanning forest was introduced, and an action-independent value function was implemented. Subsequently, an advanced approach utilizing a CNN-based double DQN was designed to enhance the learning capabilities beyond the original DQN approach. This DRL approach has been supposed to provide real-time computational support for online dynamic MMGF, effectively addressing long-term resilience enhancement challenges by adaptively forming microgrids in response to changing conditions. Validation of the proposed method was carried out using both a 7-bus system and the IEEE 123-bus system, demonstrating its robust learning ability, timely response to varying system conditions, and effective enhancement of resilience.
In [
63], a model-free optimization framework rooted in DRL was introduced to optimize rescheduling strategies, thereby enhancing the responsiveness of resilient distribution systems. The proposed approach leveraged deep neural networks to extract and process extensive features from a complex and stochastic state space. Multivariate Gaussian distributions were employed to manage high-dimensional continuous control actions effectively. The study conducted comprehensive testing and comparison of the proposed framework against a basic RL method (i.e, Q-learning) and two distinct DRL algorithms (VPG and PPO) across various power system configurations, including the IEEE 9-bus, IEEE 39-bus, and IEEE 123-bus systems. The empirical results underscored the remarkable effectiveness of the proposed DRL-based framework in both radial and meshed topologies.
In [
64], a data-driven multi-agent framework based on a DRL algorithm was developed to address power system resilience in emergency scenarios, focusing on voltage violations during windstorms. The framework utilized a hybrid soft actor–critic algorithm for both offline and online tasks related to shunt reactive power compensators’ deployment and control. The multi-agent system learned from past experiences to determine optimal locations and sizes for shunts, mitigating voltage violations during line failures. Demonstrated on the IEEE 57-bus and IEEE 300-bus systems, the approach effectively improved power system resilience by enhancing the scalability of existing DRL-based methods, offering flexibility for various control problems, and ensuring a balance between exploration and exploitation. This work streamlined information sharing among actors and critics, reducing the computational burden for large-scale integrated power systems.
In [
65], a distributed DRL framework was employed to address the active power correction control (APCC) problem in large-scale power systems. They established an APCC model, including topology reconfiguration actions, and utilized a fully cooperative stochastic game to represent interactions among active power controllers. A model-free approach was adopted to find the Nash equilibrium for the game, with the discrete nature of the APCC problem addressed using the QMIX method. To meet practical application requirements for large-scale power systems, they proposed a structure involving centralized online training and offline distributed execution. The method’s effectiveness was verified using an open-source platform with relevant scenarios and cases. This research demonstrated the potential of distributed DRL in managing complex power systems, opening avenues for future work to address control problems with high dimensionality and nonlinearity.
In [
66], an RL-based method has been introduced for distribution network reconfiguration (DNR) aimed at improving the resilience of electric power supply systems. Resilience improvements often involve tackling computationally intensive and sometimes infeasible large-scale stochastic optimization challenges. The study leveraged the exceptional performance of RL techniques in power system control applications, particularly for real-time resilience-based scenarios. They developed a single-agent framework using an actor–critic algorithm (ACA) to determine the statuses of tie-switches in a distribution network impacted by extreme weather events. The approach reconfigured the feeder topology to minimize or eliminate load shedding, treating the problem as a discrete Markov decision process. Actions involved opening or closing specific tie-switches, with rewards computed to evaluate their practicality and advantages. Through iterative Markov processes, the ACA was trained under various failure scenarios and demonstrated on a 33-node distribution system, achieving action accuracy exceeding 93%.
In [
67], the authors worked on addressing the proactive control problem within the context of resilient power and energy systems during extreme events, specifically wildfires. They formulated the problem as an MDP to minimize load outages, taking into account the dynamic nature of wildfire events. Their approach introduced an integrated testbed that combined a wildfire propagation simulator with a power-system simulator, enabling comprehensive evaluations. By leveraging DRL for power generation coordination, their approach aimed to provide intelligent proactive control for power grid operators. The results demonstrated its effectiveness in reducing load outages during extreme events, offering a valuable contribution to enhancing emergency response in power and energy systems.
In [
68], the authors developed an RL-based model to facilitate intentional islanding in power systems, offering real-time switching control and adaptability to changing system conditions. They framed the intentional islanding process as an MDP and utilized RL to learn the optimal transmission switching policy. This approach incorporated a PSS/E model of the power transmission system, interfacing with the OpenAI Gym [
71]. The primary goal was to create stable and self-sustainable islands while maintaining voltage stability and reducing power mismatches. They implemented a PPO algorithm with multilayer perceptrons for policy and value networks to control switch statuses. Their framework’s effectiveness in grid self-recovery through intentional islanding was validated on a modified IEEE 39-bus test network using dynamic simulations, demonstrating its potential for online topology control in transmission networks during outages.
In [
69], the authors worked on addressing the need for resilience in power grids during extreme weather events, focusing on microgrid formation for resilient distribution networks (RDNs) when the primary utility power is unavailable. They proposed a model-free RDN-oriented microgrid formation method based on DRL techniques. The approach treated microgrid formation as an MDP, considering intricate factors like unbalanced power flow analysis of the microgrid along with its operational limitations. They developed a simulation environment utilizing OpenAI Gym [
71], facilitating the application of the DRL methodology. The DQN was employed to find the optimal configuration of microgrids. Furthermore, a framework based on an offline training and real-time implementation was developed. Thorough examination of numerical results was conducted, offering a model-free solution for microgrid formation with complex scenarios and fast application efficiency. Key contributions included the MDP formulation, simulator-based environment, and the introduction of DRL for near-optimal solutions.
In [
70], the authors worked on addressing the challenge of ensuring the resilience of commercial buildings (CBs) during high-impact, low-frequency extreme weather events. They introduced a resilient proactive scheduling strategy based on safe reinforcement learning (SRL) to optimize customer comfort levels while minimizing energy reserve costs. The strategy leveraged the correlation between various CB components equipped with demand response capabilities to maintain desired comfort levels with limited energy reserves. To handle uncertainties associated with extreme weather events, they developed an SRL algorithm by combining DQN and conditional-value-at-risk (CVaR) methods. This approach enabled proactive scheduling decisions that balanced exploration and exploitation, effectively mitigating the impact of extreme events during the learning process. Extensive simulations using real-world commercial campus data demonstrated the capability of the proposed framework to enhance both power and heating/cooling resilience, ensuring power balance and maintaining comfort levels in CBs subject to extreme weather conditions. The study presented a valuable contribution by integrating correlated demand response with proactive scheduling to support maximum comfort levels while conserving energy reserves in commercial buildings exposed to extreme weather events.
3.2. Recovery and Restoration
The phases of recovery and restoration are of utmost importance in the context of power and energy system resilience. These phases cover the plans and methods used to restore order to the power and energy system after a disruptive event. Recovery and restoration are intrinsically linked to dynamic response methods, with subsequent recovery efforts being made easier by the initial response phase.
Recovery entails a diverse strategy aimed at determining the degree of damage, stabilizing the power and energy system, and starting the restoration and repair operations. This step comprises a thorough assessment of the state of the power system, including the identification of crucial elements that might have been jeopardized during the incident [
72]. Critical loads quickly regain access to power due to recovery mechanisms that prioritize the restoration of key services.
On the other hand, restoration concentrates on the systematic approach of returning the entire power and energy system to its pre-disruption state [
73]. In this phase, damaged infrastructure is coordinately repaired and reconnected, system integrity is tested and verified, and non-essential services are gradually brought back online. The goal of restoration efforts is to bring the power and energy system back to full functionality so that it can efficiently meet consumer needs [
74].
This subsection examines the application of DRL approaches to speed up recovery and restoration procedures in power and energy systems. In-depth discussion is provided regarding how DRL may improve prioritizing, resource allocation, and decision making during these crucial times, thereby improving the overall resilience and dependability of the power and energy system.
Table 5 presents a summary of papers on DRL applications in the restoration and recovery aspect of resilient power and energy systems.
In [
75], a DRL-based model was developed to efficiently restore distribution systems following major outages. The model employed a Monte Carlo tree search (MCTS) to expedite training and enhance decision making in scenarios with partial and asynchronous information. Through iterative exploration and exploitation, the model determined restoration actions, including load prioritization, resource allocation, and power system performance evaluation. A reward function incentivized actions that served critical loads, ensured system security, and minimized restoration efforts. The integration of a power flow simulation tool (OpenDSS) and MCTS improved training performance and scalability. While the paper focused on distribution systems’ resilience, the DRL-based model demonstrated potential applicability to resilience challenges at both the transmission and distribution levels, particularly in the context of extreme events and the increasing complexity of modern distribution grids with DERs and low observability.
In [
76], DRL was employed to create an intelligent resilience controller (IRC) capable of making rapid real-time operational decisions for dispatching distributed generation and energy storage units to restore power following sudden outages. The IRC was designed to learn the patterns associated with uncertain high-impact events, exemplified by a spatiotemporal hurricane impact analysis model, and used this knowledge to explore a wide range of actions in partially observable states of distribution grids during extensive outages. The distribution grid’s operation under uncertainty was modeled as an MDP, and operator actions were rewarded based on operational costs. To address scalability challenges due to several DERs, the problem was reformulated as a sequential MDP. Implementation of the proposed model on a hurricane-affected test distribution grid demonstrated its superiority in terms of reduced operation costs and nearly instantaneous decision making, showcasing its adaptability to hurricanes of varying intensities. This study introduced an intelligent approach to enhance the resilience of distribution grids during extreme weather conditions, utilizing DRL and a spatiotemporal hurricane model to inform real-time dispatch decisions for DERs.
In [
77], the authors addressed the challenge of efficiently scheduling and dispatching DERs in islanded microgrids to support service restoration and enhance system resilience during utility grid outages. Conventional model-based methods for DER coordination often lack generalization and adaptability, relying on precise distribution network models. To overcome these limitations, the authors proposed a two-stage learning framework based on deep deterministic policy gradient from demonstrations (DDPGfD). During the initial training phase, imitation learning was employed to provide the control agent with expert experiences, ensuring a satisfactory starting level of performance. In the subsequent online training phase, techniques such as reward shaping, action clipping, and the inclusion of expert demonstrations were harnessed to support secure exploration and expedite the training procedure. The proposed approach, applied to the IEEE 123-node system, was shown to outperform representative model-based methods and the standard DDPG method, demonstrating both solution accuracy and increased computational efficiency. This study introduced a pioneering application of DRL from demonstrations for distribution service restoration, addressing the high-dimensional complexity of continuous action spaces and providing a valuable contribution to enhancing microgrid resilience.
In [
78], the concerns of electric utilities, government agencies, and the public regarding the impacts of natural disasters and extreme weather events on distribution systems’ security, reliability, and resilience was addressed through the use of movable energy resources (MERs). The study focused on MERs, which are flexible and dispatchable to power outage locations following disasters. The dissertation encompassed three interdependent tasks for enhancing distribution system resilience using MERs. The first task involved determining the optimal total size and number of MERs, employing graph theory and combinatorial techniques. The second task focused on pre-positioning MERs using cooperative game theory, based on weather forecasts and monitoring data. The final task was post-disaster routing of MERs, which was addressed using a DRL-based model. The research’s overarching thesis was that a combination of planning and operation-based strategies for MERs would significantly enhance the resilience of electric distribution systems.
In [
79], the authors focused on enhancing the long-term resilience of power distribution systems faced with extreme climatic events by employing grid-hardening strategies. To address the challenges of limited budgets and resources, a planning framework based on DRL was developed. The resilience enhancement problem was treated as an MDP, and an approach was developed, combining ranking strategies, neural networks, and RL. Unlike conventional methods that target resilience against single future hazards, this framework quantified life-cycle resilience, considering the possibility of multiple stochastic events during the system’s lifetime. A temporal reliability model was introduced to account for gradual deterioration and hazard effects, particularly in the context of stochastic hurricane occurrences. The framework was applied to a substantial power distribution system with thousands of poles, and the results demonstrated a significant improvement in long-term resilience compared to existing strategies, including the National Electric Safety Code (NESC) strategy, with an enhancement of over 30% for a 100-year planning horizon. Additionally, the DRL-based approach provided optimal solutions for computationally challenging problems that were difficult to solve using the branch and bound (BB) algorithm, making it a promising approach for enhancing system resilience in the face of extreme events.
In [
80], the authors addressed the vulnerability of power grids to extreme events and the critical need for efficient restoration strategies to bolster grid resilience. They proposed an integrated recovery strategy that aimed to maximize the total electricity supplied to loads during the recovery process, taking into account various time scales of restoration methods. This strategy harmoniously combined the gradual component repair process with the swift restoration method of optimal power dispatch. To achieve this, they utilized the Q-learning algorithm to determine the sequence for repairing damaged components and updating the network topology. Additionally, linear optimization was employed to maximize power supply on a given network structure. Simulation results, based on testing the proposed method on the IEEE 14-bus and IEEE 39-bus systems, indicated its effectiveness in coordinating available resources and manpower to swiftly restore the power grid following extreme events. This research is supposed to offer valuable insights for power operators aiming to enhance grid resilience.
In [
81], a distribution service restoration (DSR) algorithm was presented as a crucial component of resilient power systems, offering optimal coordination for enhanced restoration performance. Typically, model-based control methods were employed for this purpose, but they suffered from low scalability and required precise models. To overcome these challenges, the study introduced an approach based on graph-reinforcement learning (G-RL). G-RL integrated graph convolutional networks (GCNs) with DRL to address the intricacies of network restoration in power grids, capturing interactions among controllable devices. The scalability of the solution was ensured by treating DERs as agents within a multi-agent environment. This framework utilized latent features derived from graphical power networks, which were processed by GCN layers to guide network restoration decisions through RL. Comparative evaluations conducted on the IEEE 123-node and 8500-node test systems demonstrated the effectiveness and scalability of the proposed approach, offering a versatile solution for dynamic DSR problems in power systems.
In [
82], the authors focused on addressing the real-time routing and scheduling challenges posed by multiple mobile energy storage systems (MESSs) within power and transportation networks, to enhance system resilience. Prior research primarily employed model-based optimization for MESS routing, which was time consuming and demanded extensive global network information, raising privacy concerns. Moreover, real-time control of MESSs was challenging due to system variability. To address these issues, the study introduced a model-free real-time multi-agent DRL approach. In this approach, parameterized double DQNs were employed to reconfigure the coordination of MESS scheduling, accommodating both continuous and discrete types of actions. The RL environment was represented by the interconnected transportation network and a linearized AC optimal power flow solver, which integrated uncertainties arising from factors such as renewable generation, line outage information, etc., into the learning process. Thorough numerical studies performed on 6-bus and 33-bus power networks confirmed the superior performance of the proposed approach over traditional model-based optimization methods, making it a valuable contribution to resilience enhancement.
In [
83], the authors focused on addressing the challenges posed by extreme events on microgrids, which could lead to significant outages and restoration costs. Repair crews (RCs) are essential for system resilience due to their mobility and adaptability in both transportation and energy systems. Coordinating RC dispatch is complex, particularly in multi-energy microgrids with dynamic uncertainties. The paper tackled this by formulating the RC dispatch problem in an integrated power–gas transportation network as an MDP. A hierarchical MARL algorithm was introduced, featuring a two-level optimization problem with switching decisions being the higher-level optimization and routing and repairing decisions of RCs the lower-level optimization. An abstracted critic network was integrated to capture the system dynamics and stabilize the training performance while preserving privacy. Thorough numerical investigations on an integrated power–gas transportation network demonstrated the algorithm’s superiority over traditional MARL methods based on various efficiency metrics. The approach’s scalability was also validated on a larger 33-bus power and 15-bus gas network with an 18-node 27-edge transportation network.
In [
84], the authors focused on enhancing the post-disaster resilience of a distribution system that experiences power supply interruptions due to extreme disasters, forcing it to operate as an islanded microgrid. To optimize the utilization of limited generation resources and provide extended power supply to critical loads during the outage, a multi-agent DRL approach was developed. This method implemented dual control policies for managing energy storage and load shedding within the microgrid. The goal was to maximize the cumulative utility value of the microgrid over the duration of the power outage. A comprehensive simulation environment, constructed using OpenAI Gym and OpenDSS, facilitated testing and validation. The results demonstrated the adaptability of the proposed approach under various conditions, including different available generation resources and microgrid outage durations. The main contributions of this work included the development of a multi-agent DRL model for sequential decision making, the formulation of dual optimal control policies for source and load sides, and the creation of an RL environment for islanded microgrid operation, accounting for generation limitations, power flow, and microgrid uncertainties.
In [
85], an RL-based approach was introduced to dispatch DERs and enhance the operational resilience of electric distribution systems following severe outage events. The escalating computational intricacies and the need for intricate modeling procedures in resilience-based enhancement strategies prompted the adoption of intelligent algorithms tailored for real-time control applications. The authors utilized a multi-agent DRL algorithm to efficiently dispatch DERs in the aftermath of extreme events, with the primary objective of providing a swift and effective control mechanism for improved resilient operation of islanded distribution power systems. The problem was formulated as an iterative MDP, encompassing system states, action spaces, and reward functions. Each agent was responsible for dispatching a specific DER and was trained to maximize its cumulative reward value. System states represented the system’s topology and characteristics, actions denoted DER power-supply decisions, and rewards were computed based on the power balance mismatch for each agent. The proposed model was trained using various failure scenarios and demonstrated on a 33-node distribution system in islanded mode, illustrating its capability to dispatch DERs for resilience enhancement.
In [
86], a DRL approach was proposed for post-disaster critical load restoration within active distribution systems, with the aim of forming microgrids using network reconfiguration to reduce the amount of curtailed critical loads. The power distribution networks (PDNs) were modeled using graph theory, and the best system configurations, involving microgrids, were determined by finding the optimal spanning forest while adhering to various distribution system-related constraints. In contrast to existing methods, which required repetitive calculations for every line outage case to determine the optimal spanning forest, the proposed methodology, once adequately trained, could rapidly identify the best spanning forest even when line outage cases varied. In situations involving multiple line failures, the DRL-based model established microgrids with DERs, minimizing the need for curtailing critical loads. The model underwent training using the REINFORCE algorithm, an RL technique that relies on the VPG method. The paper was concluded with a numerical investigation performed on a 33-node distribution system, illustrating the capability of the proposed methodology in restoring critical loads after a disaster.
In [
87], a DRL-based approach aimed at optimizing the reconfiguration of PDNs to improve their resilience against extreme events was presented, with the primary objective of reducing the amount of curtailed critical loads. The PDN was depicted as a graph theoretic network, and the optimal system configuration was determined by seeking the optimal spanning forest while adhering to various distribution system operational constraints. Differing from traditional techniques that necessitate repeated calculations for each system operating state to find the optimal network configuration, the DRL-based approach, once adequately trained, exhibited the capability to rapidly identify the optimal or near-optimal configuration even in the face of changing system states. To minimize critical-load curtailment resulting from multiple line outages during extreme events, the proposed approach formed microgrids incorporating DERs. A DQN-based model was utilized. The paper was supported by a numerical analysis conducted on a 33-node distribution test system, confirming the efficiency of the proposed methodology for enhancing PDN resilience through reconfiguration.
In [
74], the authors explored the utilization of mobile energy storage systems (MESSs) to bolster distribution system resilience. They devised an MDP framework that integrated service restoration strategy by orchestrating MESS scheduling and microgrid resource dispatching while considering load consumption uncertainties. Their objective was to maximize service restoration in microgrids by effectively coordinating microgrid resource dispatching and MESS scheduling, with MESS fleets being dynamically dispatched among microgrids to facilitate load restoration in tandem with microgrid operation. To optimally schedule these processes, they employed a DRL algorithm, specifically the twin delayed deep deterministic policy gradient (TD3), which facilitated the training of deep Q-networks and policy networks. The well-trained policy network was then applied online to execute multiple actions simultaneously. Their proposed model was assessed using an integrated test system comprising three microgrids interconnected by the Sioux Falls transportation network. Simulation results underscored the successful coordination of mobile and stationary energy resources in enhancing system resilience.
In [
73], the authors focused on enhancing grid resilience by utilizing DERs in distribution systems to restore critical loads following extreme events. They recognized the complexity of coordinating multiple DERs in a sequential restoration process, especially in the presence of uncertainties related to renewable energy sources and fuel availability. To address this challenge, the researchers turned to RL due to its capability to handle system nonlinearity and uncertainty effectively. RL’s ability to be trained offline and provide immediate actions during online operations made it well suited for time-sensitive scenarios like load restoration. Their study centered on prioritized load restoration within a simplified distribution system, considering imperfect renewable generation forecasts, and compared the performance of an RL controller with that of a deterministic model predictive control (MPC) approach. The results demonstrated that the RL controller, by learning from experience and adapting to imperfect forecasts, offered a more reliable restoration process compared to the baseline controller. This study underscored the potential of RL-based controllers in addressing load restoration challenges in uncertain environments, particularly when coupled with high-performance computing (HPC), showcasing their effectiveness in the power system domain.
Reference [
88] focused on enhancing the resilience of microgrids through the coordinated deployment of mobile power sources (MPSs) and repair crews (RCs) following extreme events. Unlike previous centralized approaches, which assumed uninterrupted communication networks, this research adopted a decentralized framework to address real-world scenarios where communication infrastructure might be compromised. They introduced a two-level hierarchical MARL method. At the high level, this approach determined when to prioritize power or transport networks, while the low level handled scheduling and routing within these networks. To improve learning stability and scalability, an embedded function capturing system dynamics was incorporated. Case studies using power networks validated the method’s effectiveness in microgrid load restoration. This work represents a significant advancement in decentralized coordination for enhancing microgrid resilience, offering privacy preservation and robustness while outperforming existing centralized and decentralized methods.
3.3. Energy Management and Control
Energy management (EM) and adaptive control within the context of resilient power and energy systems are integral strategies and methodologies employed to enhance the reliability, efficiency, and robustness of energy distribution and consumption. Energy management encompasses a range of practices that involve monitoring, optimizing, and controlling various aspects of energy usage, generation, and distribution. These practices aim to achieve multiple objectives, including minimizing energy costs, reducing peak loads, maintaining a balance between electricity supply and demand, and ensuring the stable operation of energy systems. EM plays a crucial role in enhancing resilience by allowing for proactive responses to disruptions, optimizing resource allocation, and minimizing the impact of unforeseen events [
70]. Adaptive control, on the other hand, refers to the ability of an energy system to autonomously adjust its operation in real time based on changing conditions and requirements. It involves the use of feedback mechanisms, data analytics, and control algorithms to continuously monitor system performance, detect anomalies or faults, and make rapid and informed decisions to maintain system stability and reliability. Adaptive control is essential in resilient energy systems as it enables them to self-regulate, adapt to dynamic situations, and recover quickly from disturbances or failures [
89]. Together, energy management and adaptive control form a dynamic framework that ensures the efficient use of energy resources, maintains grid stability, and responds effectively to various challenges, including load variations, demand fluctuations, cyber threats, equipment faults, and other disruptions. These strategies are critical for enhancing the resilience and sustainability of power and energy systems in the face of evolving complexities and uncertainties.
Table 6 presents a summary of papers on DRL applications in energy management and control aspects of resilient power and energy systems.
In [
90], the authors focused on energy management within microgrids, anticipating the growing role of small-scale renewable energy sources like photovoltaic panels and wind turbines. To address the inherent variability of renewables, the researchers applied MARL, with each agent representing a component of the microgrid. These agents were trained to autonomously optimize energy distribution, leveraging historical energy consumption and renewable production data. The simulation results demonstrated effective energy flow management, and a quantitative evaluation compared the approach to linear programming solutions. Furthermore, the study emphasized decentralization, envisioning systems capable of independently responding to grid disturbances. Real-world energy data and input from industrial users contributed to the model’s development, and a generalization method was introduced to enhance its adaptability, ultimately leading to improved resilience and reliability in microgrid energy management compared to models trained on specific data.
In [
91], the authors addressed the global shift towards cleaner energy systems with increased reliance on renewable energy sources (RESs) and recognized the vulnerability of power systems to extreme events due to reduced backup capacity and heightened uncertainty in RES generation. To confront these challenges in multi-energy microgrids, a Bayesian DRL approach was proposed. Unlike traditional deterministic RL, this approach incorporated a Bayesian probabilistic network to approximate the value function distribution, mitigating the Q-value overestimation problem. The study compared this Bayesian approach, known as Bayesian deep deterministic policy gradient (BDDPG), with the conventional DDPG and optimization methods across various operational scenarios. Case studies revealed that BDDPG, by utilizing the Monte Carlo posterior mean of the Bayesian value function distribution, could achieve near-optimal policies with enhanced stability, underscoring its robustness and practicality in resilient multi-energy microgrid control, particularly in the face of uncertainties associated with extreme events.
In [
92], the authors focused on enhancing incentive demand response (DR) with interruptible load (IL), which allows for swift response and improved demand-side resilience. Conventional model-based optimization algorithms for IL necessitate explicit system models, posing challenges in adapting to real-world operational conditions. Therefore, a model-free DRL approach, employing the dueling deep Q-network (DDQN) structure, was introduced to optimize IL-driven DR management under time-of-use (TOU) tariffs and varying electricity consumption patterns. The authors constructed an automatic demand response (ADR) architecture based on DDQN, enabling real-time DR applications. The IL’s DR management problem was formulated as an MDP to maximize long-term profit, defining state, action, and reward functions. The DDQN-based DRL algorithm effectively addressed noise and instability issues observed in traditional DQN methods, achieving the dual objectives of reducing peak load demand and operational costs while maintaining voltage within safe limits.
Ref. [
93] focused on addressing the escalating need for resilient energy supply in the face of rising natural disasters, which often disrupt the conventional electrical grid. The study built upon prior research, which demonstrated that intelligent control systems could reduce the size of PV-plus-battery setups while maintaining post-blackout service quality. However, the established approach, reliant on MPC, encountered challenges related to the necessity for accurate yet straightforward models and the complexities surrounding the discrete control of residential loads. To surmount these obstacles, the paper introduced an alternative method employing RL. The RL-based controller was then rigorously compared to the previously proposed MPC system and a non-intelligent baseline controller. The results indicated that the RL controller could deliver resilient performance on par with MPC but with significantly reduced computational demands. The research centered on a single-family dwelling equipped with solar PV panels, a battery storage system, and three distinct loads, with a primary focus on preserving refrigerator temperature and prolonging battery life during extended power outages. Despite the inherent challenges, including state constraints, the RL-based formulation was supposed to effectively address these issues, demonstrating its potential for robust energy management in the face of grid disruptions.
In [
94], the authors focused on addressing the challenges associated with integrating renewable energy resources into microgrid energy management systems (EMSs) while participating in the electricity market and providing ancillary services to the utility grid. To tackle these complexities, the researchers deployed DDPG and SAC methods within an RL framework. This approach aimed to optimize the microgrid’s energy management in a high-dimensional, continuous, and stochastic environment. Additionally, the microgrid was designed to act as a participant in the power system integrity protection scheme, responding promptly to utility grid protection requirements using its available resources. A real-world dataset was used to validate the proposed methods. The key contributions of the paper included defining the microgrid’s structure, elements, and constraints for the MDP, introducing a DRL framework for microgrid EMS using DDPG and SAC, and evaluating the technique’s performance in both normal and contingency scenarios.
In [
95], a control strategy for a resilient community microgrid was developed. This microgrid model incorporated solar PV generation, electric vehicles (EVs), and an improved inverter control system. To enhance the microgrid’s ability to operate in both grid-connected and islanded modes and improve system stability, a combination of universal droop control, virtual inertia control, and RL-based control mechanisms was employed. These mechanisms dynamically adjusted the control parameters online to fine-tune controller influence. The model and control strategies were implemented in MATLAB/Simulink and subjected to real-time simulation to assess their feasibility and effectiveness. The experimental results demonstrated the controller’s effectiveness in regulating frequency and voltage under various operating conditions and microgrid scenarios, contributing to enhanced energy reliability and resilience for communities. The study also addressed the challenges posed by multiple solar PV systems and EVs in the microgrid, providing a more accurate approach to power sharing and improved stability and power quality through dynamic control adjustments.
3.4. Communications and Cybersecurity
The rise of smart grid technologies and the integration of advanced communication systems within power and energy networks have led to cybersecurity becoming a paramount concern for these systems’ operators [
96]. Within this context, the security of critical elements such as data availability, data integrity, and data confidentiality is seen as crucial for ensuring cyber resiliency. These fundamental elements are strategically targeted by cyber adversaries, with the aim of compromising the integrity and reliability of data transmitted across the communication networks of the power grid. The objectives pursued by these adversaries encompass a range of disruptive actions, including tampering with grid operations, the interruption of the secure functioning of power systems, financial exploitation, and the potential infliction of physical damage to the grid infrastructure. To counteract these threats, extensive research efforts have been devoted to the development of preventive measures within the realm of communications and cybersecurity. These measures are designed to deter cyber intruders from infiltrating network devices and databases [
97]. The overarching goal of these preventative measures is to enhance the security posture of power and energy systems by safeguarding their communication channels and the associated cyber assets.
In this subsection, an exploration of the pertinent literature addressing the multifaceted dimensions of communications and cybersecurity within the realm of resilient power and energy systems is undertaken. Through this examination, insights are provided into the diverse strategies contributing to the protection and resilience of critical power infrastructure in the face of evolving cyber threats.
Table 7 presents a summary of papers on DRL applications in the communications and cybersecurity aspects of resilient power and energy systems.
In [
98], the authors focused on addressing the efficiency challenges associated with resource allocation and user scheduling within wireless networks to support near-real-time control of community resilience microgrids. To address these challenges, they introduced a DQN-based resource allocation methodology leveraging DRL. This approach aimed to optimize resource allocation for both macrocell base stations and small-cell base stations within densely populated wireless networks. The DQN scheme outperformed traditional proportional fairness (PF) and an optimization-based algorithm called distributed iterative resource allocation (DIRA) by achieving a 66% and 33% reduction in latency, respectively. Additionally, DQN demonstrated improved throughput and fairness, making it a valuable solution for latency-critical applications like future smart grids’ connected microgrids. The algorithm’s distributed nature reduced signaling overhead and enhanced adaptability in the network. Overall, DQN showcased its potential for various latency-sensitive applications.
In [
99], the focus was on the optimal placement of phasor measurement units (PMUs) in smart grids to ensure complete system observability while minimizing the number of PMUs required. The proposed approach, termed the attack-resilient optimal PMU placement strategy, addressed the specific order in which PMUs should be placed. Using RL-guided tree search, the study employed sequential decision making to explore effective placement orders. The strategy began by identifying vulnerable buses, aiming to protect as many buses as possible during staged PMU installation to mitigate costs. This reduced the state and action space in large-scale smart grid environments. The RL-guided tree search method efficiently determined key buses for PMU placement, resulting in a reasonable order of PMU installation. Extensive testing on IEEE standard test systems confirmed the effectiveness of this approach, demonstrating its superiority over existing methods. The study’s main contributions included the introduction of a new approach that considered placement order, the use of tree search to enhance learning efficiency, and the application of a least-effort attack model for identifying vulnerable buses, making it well suited for large-scale grid environments.
In [
100], a comprehensive strategy for mitigating the impact of cyber-attacks on critical power infrastructures was presented. The integration of cyber-physical systems has introduced vulnerabilities that can be exploited by malicious attackers, potentially disrupting power transfer by tripping transmission lines. To effectively recover from such attacks, the paper proposed an innovative recovery strategy focused on determining the optimal reclosing time for the tripped transmission lines. This strategy leveraged the power of DRL, specifically utilizing the DDPG algorithm. The continuous action space of the problem makes DDPG a suitable choice for this task. The DDPG framework consisted of a critic network and an actor network, with the former approximating the value function and the latter generating actions. To develop and train the strategy, an environment was established to simulate the power system’s state transitions during cyber-attack recovery processes. Additionally, a reward mechanism based on transient energy function was used to evaluate the performance of recovery actions. Through offline training using state, action, and reward data, the DDPG-based strategy was equipped to make optimal reclosing decisions during online cyber-attack recovery. This approach was shown to outperform existing recovery strategies that either reclose immediately or follow fixed time-delay protocols. The paper’s contributions encompassed the introduction of an adaptive cyber-attack recovery strategy, the development of a simulation environment for replicating power system dynamics under attack conditions, and the ability to continuously yield optimal or near-optimal actions for different cyber-attack scenarios, effectively reducing the risks associated with cascading outages in critical power infrastructure.
In [
101], a resilient optimal defensive strategy was introduced to address the challenges posed by false data injection (FDI) in demand-side management, which can impact security, voltage stability, power flow, and economic costs in interconnected microgrids. The approach utilized a Takagi–Sugeuo–Kang (TSK) fuzzy-system-based RL method, specifically employing the DDPG algorithm to train both actor and critic networks. These networks aid in security switching control strategies and multi-index assessment. An improved alternating direction method of multipliers (ADMM) method was employed for policy gradient with online coordination, ensuring convergence and optimality. Moreover, a penalty-based boundary intersection (PBI)-based multiobjective optimization technique was utilized to simultaneously address economic cost, emissions, voltage stability, and rate of change of frequency (RoCoF) limits. Simulation results validated the effectiveness of the resilient strategy in mitigating uncertain attacks on interconnected microgrids, offering an adaptable and promising solution.
In [
102], an event detection algorithm based on RL was proposed for non-intrusive load monitoring (NILM) in residential applications. The method involved a feedback system that utilized several traditional event detection algorithms to train the RL agent without direct access to consumer data. The RL agent, equipped with a dual replay memory (DRM) structure, learned the knowledge of existing event detection algorithms and combined them into a versatile model. A real-world dataset was used to validate the algorithm’s performance under various scenarios, including non-ideal conditions. The results showed that the proposed algorithm outperformed traditional event detection algorithms and improved the cybersecurity of participating households by isolating the agent from consumer data. The contributions of this work included the development of an RL-based event detection algorithm that excels in both ideal and non-ideal conditions, the proposal of a cybersecurity-enhancing architecture inspired by federated learning, and the introduction of a DRM structure to significantly enhance the RL algorithm performance in NILM applications.
In the context of the increasing threat of FDI attacks on the demand side of interconnected microgrids, the study by Zhang et al. [
103] introduced a resilient optimal defensive strategy using distributed DRL. To assess the impact of FDI attacks on demand response, an online evaluation method employing the recursive least-square (RLS) technique was devised to gauge the effect on supply security and voltage stability. Based on this security confidence assessment, a distributed actor network learning approach was proposed to derive optimal network weights, facilitating the generation of an optimal defensive plan that addresses both economic and security concerns within the microgrids system. This methodology not only enhanced the autonomy of each microgrid but also improved DRL efficiency. Simulation results demonstrated the effectiveness of the approach in evaluating FDI attack impacts, highlighting the potential of an enhanced distributed DRL approach for robustly defending microgrids against demand-side FDI attacks. The key contributions of this work encompassed the development of a two-stage optimal defensive strategy, the introduction of a regularized RLS method for online FDI impact evaluation, and the proposal of a distributed RL approach to ensure microgrid economic and security resilience with improved autonomy and learning efficiency compared to existing methods.
In [
104], the authors delved into the realm of data-driven approaches for controlling electric grids using machine learning, with a particular focus on RL. RL techniques, renowned for their adaptability in uncertain environments like those influenced by renewable generation and cyber system variations, present a compelling alternative to traditional optimization-based solvers. However, effectively training RL agents necessitates extensive interactions with the environment to acquire optimal policies. While RL environments for power systems and communication systems exist separately, bridging the gap between them in a unified, mixed-domain cyber-physical RL environment has been a significant challenge. Existing co-simulation methods, while efficient, demanded substantial resources and time for generating extensive datasets to train RL agents. Therefore, this study concentrated on crafting and validating such a mixed-domain RL environment, utilizing OpenDSS for power systems and SimPy, a versatile discrete event simulator in Python, for cyber systems, ensuring compatibility across different operating systems. The primary objective was to empower the distribution feeder system to exhibit resilience in both the cyber and physical domains. This was achieved through the training of agents for tasks like network reconfiguration, voltage control, and rerouting, thereby minimizing the steps required to restore communication and power networks in the face of various threats and contingencies. The key contributions of this paper included the development of a discrete event simulation-based cyber RL environment for training agents, the creation of an OpenDSS-based RL environment for distribution grid reconfiguration, the integration of SimPy and OpenDSS for comprehensive cyber-physical defense, validation across different power and cyber system sizes, and the successful training of well-known RL agents using these environments, applying the MDP model to rerouting and network reconfiguration tasks in their respective environments.
In [
105], the role of demand response in enhancing grid security by maintaining the demand–supply balance in real time through consumer flexibility adjustments was explored. The proliferation of digital communication technologies and advanced metering infrastructures has led to the adoption of data-driven approaches, such as MARL, for solving demand response challenges. However, the increased data interactions within and outside the demand response management system have introduced significant cybersecurity threats. This study aimed to address the cybersecurity aspect by presenting a resilient adversarial MARL framework for demand response. The framework constructed an adversary agent responsible for formulating adversarial attacks to achieve worst-case performance. It then employed periodic alternating robust adversarial training with the optimal adversary to mitigate the impacts of adversarial attacks. Empirical assessments conducted within the CityLearn Gym environment highlighted the vulnerability of MARL-based demand response systems to adversary agents. However, the proposed approach exhibited substantial improvements in system resilience, reducing net demand ramping by approximately 38.85%. The work introduced new adversarial training methods, addressed robustness challenges, and provided insights into the impact of pre-training on control policies, contributing significantly to enhancing the cybersecurity of MARL-based demand response systems.
In [
106], an investigation was conducted into the resilience of data transmission between agents in a cluster-based, heterogeneous, MADRL system when subjected to gradient-based adversarial attacks. To address this challenge, an algorithm utilizing a DQN approach, in combination with a proportional feedback controller, was introduced to enhance the defense mechanism against fast gradient sign method (FGSM) attacks and improve the performance of DQN agents. The feedback control system served as a valuable auxiliary tool for mitigating system vulnerabilities. The resilience of the developed system was evaluated under FGSM adversarial attacks, categorized into robust, semi-robust, and non-robust scenarios based on average reward and DQN loss. Data transfers were examined within the MADRL system, considering both real-time and time-delayed interactions, in leaderless and leader–follower scenarios. The contributions of this research included the design of a proportional controller to bolster the DQN algorithm against FGSM adversarial attacks, the exploration of on-time and time-delayed data transmissions to enhance the defense strategy, and the demonstration of the superior performance achieved by integrating the proportional controller into the DQN learning process, resulting in higher average cumulative team discounted rewards for the MADRL system.
In [
107], a decentralized secondary control scheme was presented for multiple heterogeneous BESSs within islanded microgrids. Unlike prior approaches, that involve extensive information transmission among secondary controllers, this scheme eliminated the need for excessive real-time data exchange, reducing communication costs and minimizing vulnerability to cyber-attacks. The secondary control method simultaneously achieved frequency regulation and state-of-charge (SoC) balancing for BESSs, all without necessitating precise BESS models. This was achieved through an asynchronous advantage actor–critic (A3C)-based MADRL algorithm, featuring centralized offline learning with shared convolutional neural networks (CNNs) to maximize global rewards. A decentralized online execution mechanism was employed for each BESS. Additionally, to counter potential denial-of-service (DoS) attacks on local communication networks, a signal-to-interference-plus-noise ratio (SINR)-based dynamic and proactive event-triggered communication mechanism was introduced, reducing the impact of DoS attacks and conserving communication resources. Simulation results demonstrated that the proposed decentralized secondary controller effectively accomplishes simultaneous frequency regulation and SoC balancing. Comparative analysis against other event-triggered methods and MA-DRL algorithms highlighted the superiority of the A3C-based MA-DRL algorithm with CNN, capable of adapting its release frequency based on real-time SINR to mitigate network bandwidth occupation and packet loss rates induced by DoS attacks. The paper contributed to the development of a data-driven decentralized secondary control system for microgrids with multiple heterogeneous BESSs, offering a new approach to address these challenges.
In [
108], a dynamic defense strategy was introduced to counter dynamic load-altering attacks (D-LAAs) in the context of cyber-physical threats to interconnected power grids. Unlike traditional static defense approaches, this strategy has been designed to consider a multistage game between the attacker and defender, where both parties’ actions evolve dynamically. Minimax Q-learning was applied to determine the optimal strategies at each state, with the attacker adjusting their actions based on feedback, particularly the cascading failure and load shedding measurements. The proposed model’s effectiveness was assessed using the IEEE 39-bus system, demonstrating its superiority over passive defense strategies. This dynamic defense approach was supposed to offer improved power system resilience by addressing evolving cyber-physical threats, making it a valuable preemptive strategy for safeguarding critical infrastructure. Key contributions included the extension of one-shot D-LAAs to sequential attacks, a two-player multistage game framework, and empirical evidence showcasing its effectiveness in reducing load losses caused by D-LAAs.
In [
109], the authors addressed the growing vulnerability of cyber systems due to the increasing number of connected devices and the sophistication of cyber attackers. Traditional cybersecurity measures, such as intrusion detection and firewalls, are deemed insufficient in the face of evolving threats. Cyber resilience, as a complementary security paradigm, was introduced to adapt to both known and zero-day threats in real time, ensuring that the critical functions of cyber systems remain intact even after successful attacks. The cyber-resilient mechanism (CRM) has been central to this concept, relying on feedback architectures to sense, reason, and act against threats. RL plays a vital role in enabling CRMs to provide dynamic responses to attacks, even with limited prior knowledge. The paper reviewed RL’s application in cyber resilience and discussed its effectiveness against posture-related, information-related, and human-related vulnerabilities. It also addressed vulnerabilities within RL algorithms and introduced various attack models aimed at manipulating information exchanged between agents and their environment. The authors proposed defense methods to safeguard RL-enabled systems from such attacks. While discussing future challenges and emerging applications, the paper highlighted the need for further research in defensive mechanisms for RL-enabled systems.
3.5. Resilience Planning and Metric Development
Resilience planning in the context of power and energy systems involves planning efforts to develop comprehensive strategies for fortifying electricity infrastructure to withstand and recover from potential extreme events in the future [
110]. It primarily focuses on identifying and prioritizing investments in the electricity grid to ensure the reliable and resilient supply of power to end-use customers. These planning-based strategies may encompass initiatives such as the installation of underground cables, strategic energy storage planning, and other infrastructure enhancements aimed at reinforcing the system’s ability to deliver uninterrupted electricity [
78]. On the other hand, metric development within the realm of power and energy system resilience is a foundational component for quantifying and evaluating a power and energy system’s ability to endure and rebound from disruptions. These metrics serve as precise and measurable indicators, offering a quantitative means to assess the performance of a power system concerning its resilience. They provide valuable insights into how the system operates under normal conditions and its ability to withstand stressors or adverse situations. Metric development plays a crucial role in systematically gauging and enhancing the resilience of power systems, allowing for informed decision making and the optimization of infrastructure investments.
Table 8 presents a summary of papers on DRL applications in resilience planning and metric development aspect of resilient power and energy systems.
In [
111], the primary objective was to enhance power resilience while minimizing overall costs in long-term microgrid expansion planning. Unlike the existing literature, this study incorporated the real-world battery degradation mechanism into the microgrid expansion planning model. The approach involved employing RL-based simulation methods to derive an optimal expansion policy for microgrids. Through case studies, the effectiveness of this model was confirmed, and the impact of battery degradation was investigated. Additionally, the paper explored how the unavailability of power plants during extreme outages affected optimal microgrid expansion planning. Battery capacity naturally diminishes over time and use due to chemical reactions within the battery, ultimately leading to its disposal. Considering this battery degradation in storage-expansion planning for microgrids, the paper introduced a long-term expansion planning framework using a DRL algorithm and simulation-based techniques.
In [
112], the authors focused on developing a model for long-term microgrid expansion planning using various DRL algorithms including DQN, Double DQN, and REINFORCE. This model introduced multiple energy resources and their associated uncertainties, such as battery cycle degradation. The study employed a DRL approach to derive cost-effective microgrid expansion strategies aimed at enhancing power resilience, particularly during grid outages. Through case studies, the paper demonstrated the effectiveness of this approach, showcasing how it optimized microgrid expansion planning while accounting for factors like battery degradation and resilience constraints. The proposed method offered valuable insights into creating backup power solutions for customers during grid disruptions, considering the real-world characteristics and uncertainties associated with various power generation and energy storage units.
In [
113], the authors focused on enhancing the resilience of power distribution systems against extreme events, particularly high-impact low-probability (HILP) incidents, through the optimization of grid-hardening strategies. The study employed a risk-based metric for quantifying resilience and used a Q-learning algorithm to determine the optimal sequence of grid-hardening actions while adhering to a budget constraint. The objective was to minimize the conditional value at risk (CVaR) for the loss of load. The research demonstrated the practical application of this approach through a case study involving the IEEE 123-bus test feeder, highlighting its effectiveness in strategically allocating limited resources for resilient distribution system planning. This study contributed to the field by providing a risk-aware framework for enhancing distribution grid resilience, with a specific focus on undergrounding distribution lines to withstand wind storms, offering valuable insights for power distribution system operators aiming to strengthen their networks against extreme events.
In [
114], an assessment of power system resilience was performed by introducing a metric called the level of resilience (LoR), which quantified system resilience in terms of the minimum number of faults required to induce a blackout through sequential topology attacks. The study employed four DRL methods, namely, DQN, double DQN, REINFORCE, and REINFORCE with baseline, to determine the LoR. The research conducted three case studies using the IEEE 6-bus test system, focusing on evaluating the agents’ performance. Notably, the double DQN agent excelled by achieving the highest success rate and demonstrating superior efficiency compared to the other agents. This work’s main contribution was to utilize DRL techniques to evaluate power system resilience by determining the minimum fault count necessary for a system blackout under sequential topological attacks, offering valuable insights for system designers in selecting the most resilient topology.
5. Summary
In this review article, a comprehensive exploration of DRL in the context of resilient power and energy systems was provided, highlighting its applications, current progress, challenges, and potential for future research. The article began by outlining the origin of DRL as a fusion of RL and deep learning, setting the foundation for understanding its multifaceted applications.
The article subsequently delved into various DRL methods and algorithms, meticulously dissecting their merits and drawbacks. This analytical foundation served as a starting point for highlighting applications of DRL across different aspects of resilient power and energy systems. These aspects included dynamic response, restoration and recovery, energy management and control, communications and cybersecurity, and resilience planning and metrics development.
One distinguishing feature of this review was its in-depth analysis of the limitations and challenges inherent in DRL. These challenges included concerns related to sub-optimality, scalability, the delicate balance between speed and accuracy, intricacies associated with system complexity, safety considerations, and the pursuit of robust generalization. This comprehensive examination not only shed light on the present hurdles but also unveiled a spectrum of future research opportunities.
The future avenues discussed encompassed enhancing training methodologies, fostering transparency through Explainable AI, leveraging hybrid approaches, integrating human expertise into DRL through human-in-the-loop paradigms, drawing inspiration from physics-based RL, and establishing the foundations of safe RL. This article equipped researchers and practitioners with a roadmap for navigating the evolving landscape of DRL in resilient power and energy systems, thereby contributing to the continual advancement of this critical field.




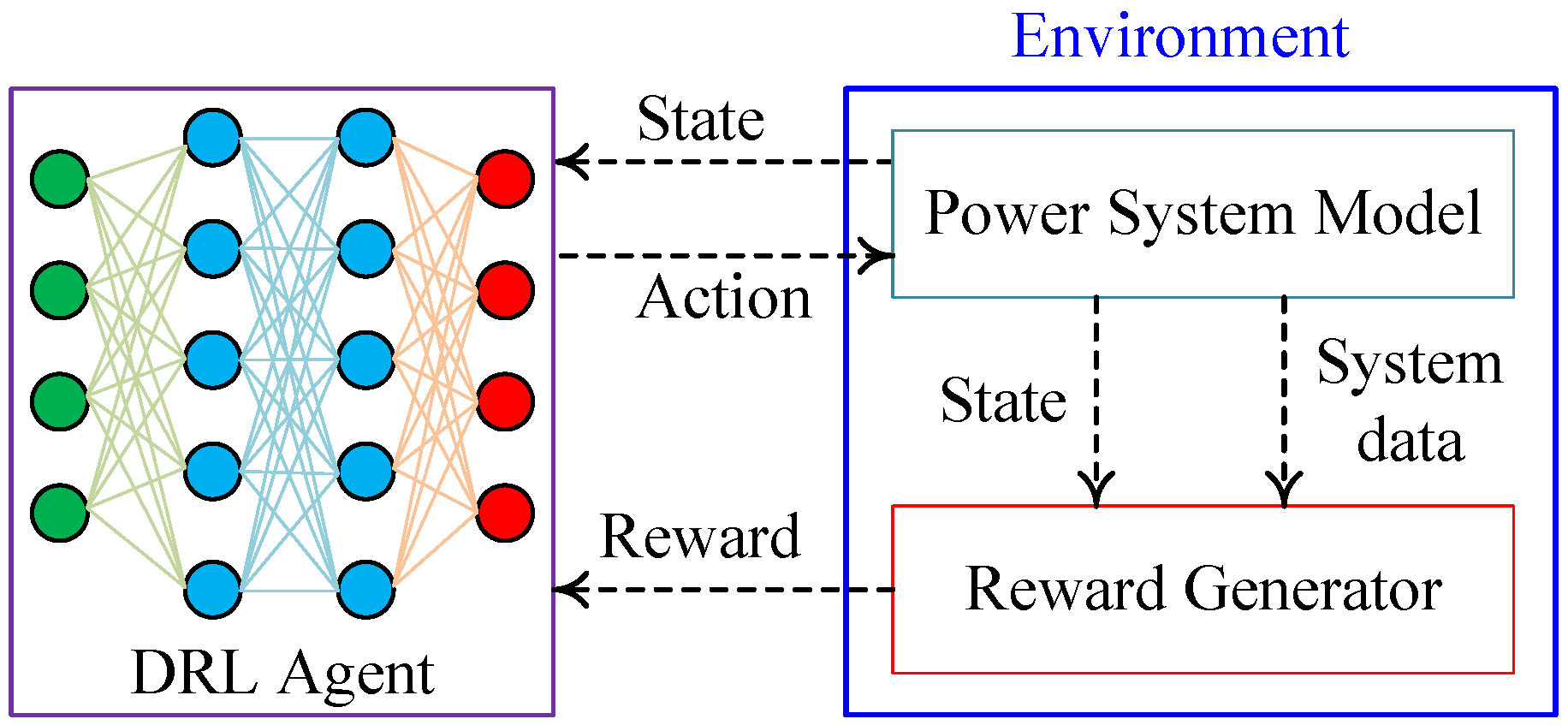

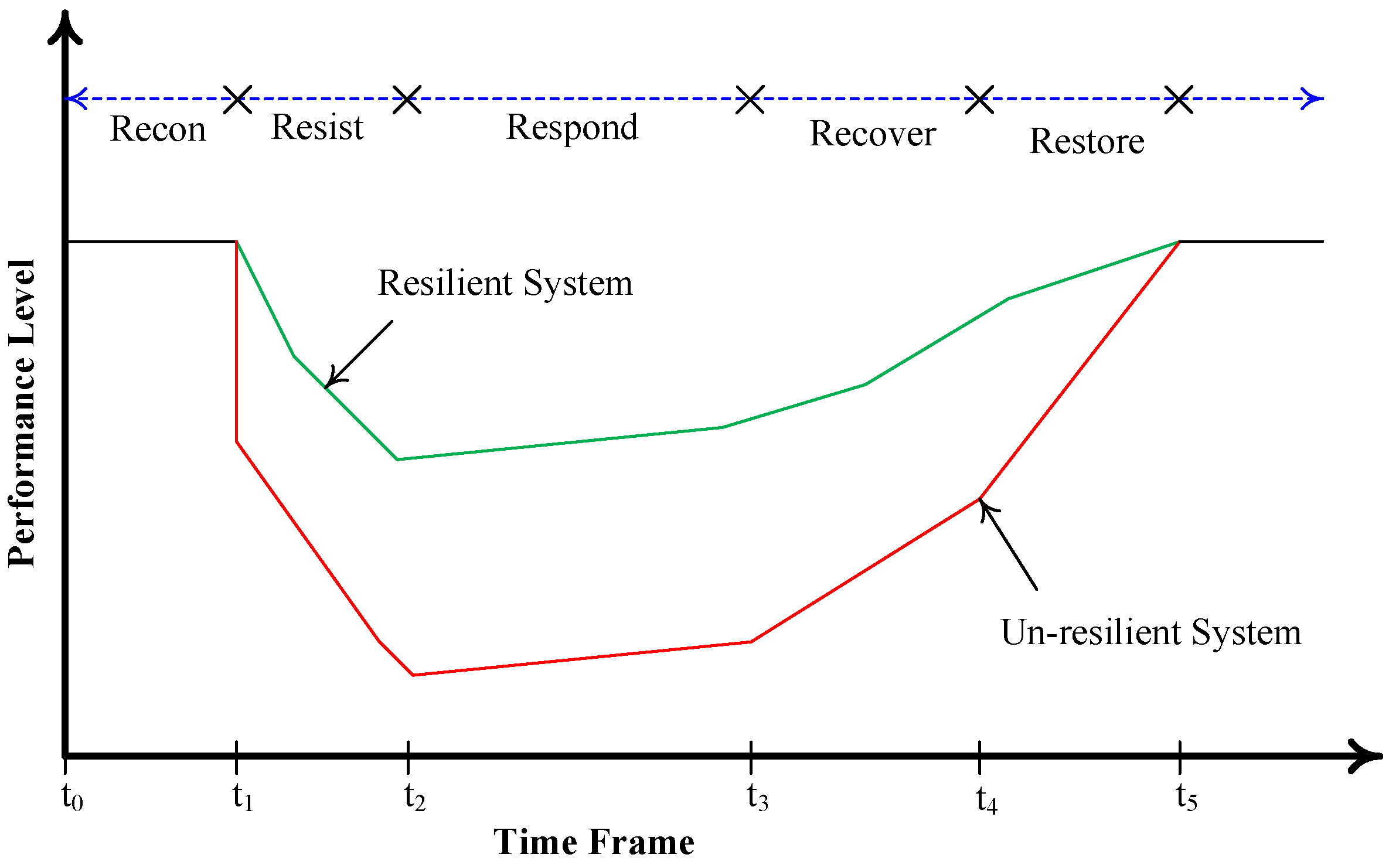


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}