1. Introduction
The binary hypothesis test is used to select better hypotheses between
and
infers based on measurement data. Many applications are used in management and business [
1,
2], communications [
3,
4], and biology [
5,
6,
7]. The hypothesis test enables the analysis and evaluation of the causes and effects of important management decisions. Using the hypothesis test, data-driven decision-makers translate data into their business strategy.
Traditionally, the hypothesis test is conducted using the Bayesian approach. Recently, machine learning (ML) has attracted considerable attention due to its outstanding classification capability using features embedded in observed data. Characterized by the use of data and algorithms, ML is used to solve problems by imitating the way that humans learn and improve their performance (or intelligence). Convolutional neural networks (CNNs) [
8,
9] are popular deep learning technologies that are often used in image or speech recognition, object detection, and other fields. Compared with the traditional multilayer perceptron (MLP), the CNN introduces the concept of windows. This allows the CNN to effectively capture high-level features of the data observed through these windows. CNNs usually contain various layers, such as convolutional layers, activation functions, pooling layers, and fully connected layers [
8].
In contrast to the conventional likelihood ratio test, we studied the binary hypothesis test using the ML approach. Using the CNN, a solution was proposed, and the results were compared with that of the optimum likelihood ratio test in this study. Consequently, the learning capability of CNN models is promising for solving the considered problem of binary hypothesis tests in wide applications.
The rest of this article is organized as follows.
Section 2 introduces the problem.
Section 3 presents two case studies employing the conventional likelihood ratio test.
Section 4 introduces the proposed CNN scheme, and
Section 5 demonstrates simulation results and concludes this study.
2. Problem Formulation
Without a loss of generality, the binary hypothesis test was investigated, assuming that data were sampled from the stationary Gaussian random process. Therefore, the joint probability density function (PDF) of
N data samples
x =
under hypothesis
,
I = 0, 1, was expressed as follows:
where
denotes data samples;
n = 0, 1, …,
N − 1;
denotes the product operation;
and
denote the mean and standard deviation of
under hypothesis
, respectively; and
. Given the data samples, the true hypothesis must be selected. That is, based on
x and its joint PDF(1), the most probable hypothesis is inferred as follows:
3. Case Study Using Likelihood Ratio Test
We explored two cases using the likelihood ratio test.
3.1. Case A: Different Mean with Same Variance
Since mean and variance are basic statistics of Gaussian random variables, their effects on the considered problem were studied. First, we investigated a simple condition with a different mean and the same variance, i.e.,
(
) and
. According to the likelihood ratio test,
After several manipulations, Equation (4) was used.
where
.
The decision metrics (Equation (4)) are comprehensive. When the average value of x is less than (or the average value of means and ), is decided; otherwise, is inferred.
Under
(i.e.,
,
), let
; one has
, where
denotes the PDF of a Gaussian random variable,
is the mean of
, and
is the variance of
. Therefore, the type I error of case A,
, can be subsequently written as follows:
where
denotes the probability.
Apparently,
does not have the closed-form expression. However, since
has the standard normal distribution,
is rewritten as follows:
where
denotes the Q function, i.e.,
Under
(i.e.,
,
), let
; one has
, where
denotes the PDF of a Gaussian random variable,
is the mean of
, and
is the variance of
. Therefore, the type II error of case A,
, can be subsequently written as follows:
where
. Let
:
3.2. Case B: Different Mean with Different Variance
In this general case,
(
) and
. According to the likelihood ratio test (Equation (3)), after several manipulations, the following is derived:
where
and
denote the natural logarithm function.
Even though the decision metric (Equation (10)) is not concise, it is enough to be used as the algorithm of the likelihood ratio test for case B. Since the exact distributions of the decision metric under both hypotheses are involved, we derived their asymptotical expressions when
N was large. Hence, under
(i.e.,
,
), let
and
; according to the central limit theorem, one has
and
, where
,
,
,
(
Appendix A).
Let
, then
, where
and
(
Appendix B). Therefore, the type I error of case B,
, is written as follows:
Under
(i.e.,
,
), the statistics of
and
are similar to
and
, where
,
,
, and
. Additionally, let
, then
, where
and
. Therefore, the type II error of case B,
, can be written as follows:
4. Proposed ML Based on CNN
Table 1 presents the proposed CNN structure for the considered hypothesis test with
N = 40. The stride and activation functions of the CNN are one and ReLU, respectively. Compared with the conventional optimum likelihood ratio test, the probability distribution and/or statistical properties of the data samples are not required by CNNs. However, training data and their correct classifications (or labels) are necessary for the ML.
5. Discussion and Conclusions
Monte Carlo simulations were used to assess the performance of binary hypothesis tests using different approaches in this study. For case A, 20,000 sets of input data were evenly sampled from the Gaussian random variables with and for and , respectively. Each set had N data samples. On the contrary, for case B, 20,000 sets of input data were also evenly sampled from the Gaussian random variables with and for and , respectively. In each case, we divided all sample data into two datasets for the proposed CNN: training data (80%) and testing data (20%).
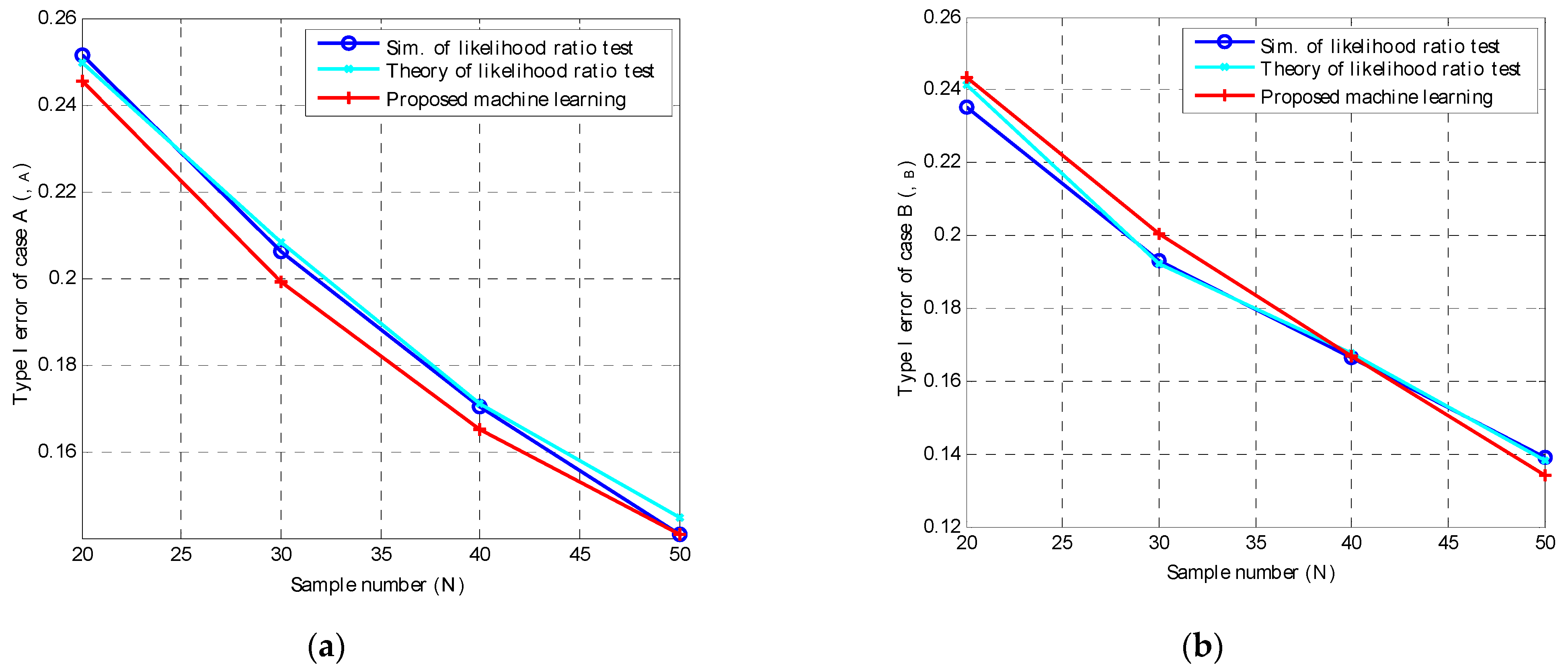
Figure 1a,b present the type I error plotted against the sample number,
N, of the proposed ML based on the CNN, as well as the theoretical and simulation results of the likelihood ratio test for cases A and B, respectively. All performances produced similar results. This confirms that the proposed CNN performed similarly to the conventional optimum likelihood ratio test. Notably, similar results were observed for the type II error, which is omitted here.
This trial confirmed that the proposed CNN can be adopted for binary decision-making. Accompanied by the sampling method, the learning capability of ML is appropriate for the classification problem with an unknown probability distribution and statistical data, i.e., the mean and variance. By integrating deep learning technology, ML is used for common and/or complicated data, which do not require any confirmed statistical properties.
Author Contributions
Conceptualization, S.-H.C.; methodology, S.-H.C. and C.-Y.C.; validation, C.-Y.C.; formal analysis, S.-H.C.; writing, S.-H.C. and C.-Y.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
All research data were obtained through MATLAB R2012a.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A
Derivations of , , and under :
By definition,
where
denotes the expectation operator. In addition,
Therefore, using Equations (13) and (16),
Similarly, we obtained
and
Appendix B
Derivation of :
Since
and
and
are correlated,
where
Finally, using Equations (13), (17)–(19), (20)–(22), one can determine the following:
References
- Dayanik, S.; Sezer, S. Multisource Bayesian sequential binary hypothesis testing problem. Ann. Oper. Res. 2012, 201, 99–130. [Google Scholar] [CrossRef]
- Mehdi, I.K.E. An examination of the naive-investor hypothesis in accruals mispricing in Tunisian firms. J. Int. Financ. Manag. Account. 2011, 22, 131–164. [Google Scholar] [CrossRef]
- Chin, W.L. On the noise uncertainty for the energy detection of OFDM signals. IEEE Trans. Veh. Technol. 2019, 68, 7593–7602. [Google Scholar] [CrossRef]
- Chin, W.L.; Le, T.N.; Tseng, C.L. Authentication scheme for mobile OFDM based on security information technology of physical layer over time-variant and multipath fading channels. Inf. Sci. 2015, 321, 238–249. [Google Scholar] [CrossRef]
- Read, J.; Sharma, S. Hypothesis-driven science in large-scale studies: The case of GWAS. Biol. Philos. 2021, 36, 46. [Google Scholar] [CrossRef]
- Li, J.J.; Tong, X. Statistical hypothesis testing versus ML binary classification: Distinctions and guidelines. Patterns 2020, 1, 100115. [Google Scholar] [CrossRef] [PubMed]
- Wei, Z.; Yang, A.; Rocha, L.; Miranda, M.F.; Nathoo, F.S. A Review of Bayesian Hypothesis Testing and Its Practical Implementations. Entropy 2022, 24, 161. [Google Scholar] [CrossRef] [PubMed]
- Chinga, A.; Bendezu, W.; Angulo, A. Comparative Study of CNN Architectures for Brain Tumor Classification Using MRI: Exploring GradCAM for Visualizing CNN Focus. Eng. Proc. 2025, 83, 22. [Google Scholar] [CrossRef]
- Chin, W.L.; Lai, S.C.; Lin, S.W.; Chen, H.H. Pipelined neural network assisted mobility speed estimation over doubly-selective fading channels. IEEE Wirel. Commun. 2022, 31, 163–168. [Google Scholar] [CrossRef]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).



{kind=link}