Abstract
The advent of large language models (LLMs), characterized by their immense scale, deep understanding of language nuances, and remarkable generative capabilities, has sparked a revolution across numerous industries and reshaped the way of machines’ comprehension of human languages. In this context, the low-altitude economy, an emerging domain that encompasses a wide spectrum of activities and services leveraging unmanned aerial vehicles (UAVs), drones, and other low-flying platforms, benefits significantly from the integration of LLMs. We developed a novel framework to explore the applications of LLMs in the low-altitude economy, outlining how these advanced models enhance aerial operations, optimize service delivery, and foster innovation in a rapidly evolving industry.
1. Introduction
The rapid advancement of artificial intelligence (AI) has led to the development of large language models (LLMs) [1] and multimodal models [2] to handle a wide range of tasks, from text generation and understanding to visual perception and reasoning. These models have shown remarkable capabilities in processing various types of data, including mathematical [3,4], textual [5,6,7,8], graphical [9,10], and dynamic imagery [11,12,13,14]. We explored the comparative strengths and characteristics of these models in handling different data types and their potential applications in the low-altitude economy [15,16,17], specifically in the areas of air transportation [18,19], drone operations [20,21,22,23], and aerial travel services [24,25,26].
We gathered and curated datasets encompassing existing LLMs and multimodal models. This dataset was meticulously compiled to include performance metrics across various evaluation dimensions, such as logical reasoning, attribute inference, relational reasoning, single-object perception, multi-object perception, and coarse-grained perception. This dataset served as the foundation for subsequent analyses and comparisons.
A comparative analysis was conducted to evaluate the performance of the models in handling diverse data types, including mathematical, textual, graphical, and dynamic imagery data. To ensure a standardized and robust assessment, the models were evaluated using MMbench [27], a benchmark that provides a comprehensive framework for assessing multimodal capabilities. This analysis was conducted to compare the models’ strengths and weaknesses across different modalities.
2. Literature Review
2.1. Mathematical Problems
To assess LLMs’ performance in mathematical problem-solving, multiple datasets have been developed as benchmarks. The GSM8K [28] dataset is used for elementary school-level math problems that provided a benchmark for assessing LLMs abilities in basic arithmetic and algebra. The MATH [29] dataset, on the other hand, contains high school competition-level math problems that cover more advanced mathematical concepts and present a higher challenge to LLMs. In addition, the MathCoder [30] framework is a mathematical problem-solving framework that combines code execution, which allows LLMs to generate and execute code to solve mathematical problems, thus further broadening the scope of LLMs application in mathematical problem-solving.
2.2. Textual Content
To evaluate the performance of LLMs in text content processing tasks, the GLUE and SuperGLUE benchmark [31] is used as it covers a wide range of NLP tasks, including text classification, sentiment analysis, and question-answering, enabling an assessment framework for LLMs. These test sets help measure the performance of the model in various tasks and provide an important reference for model improvement and optimization. In addition, the CLUE benchmark [32] test set for Chinese NLP tasks focuses on evaluating LLM performance, supporting research and development of Chinese NLPs. In addition, the Hellaswag [33] and PIQA [34] datasets are used for common sense reasoning tasks, further revealing the model’s performance and challenges in complex contexts by testing LLMs’ ability to understand and reason about common situations in everyday life.
2.3. Graphical Information
To evaluate the performance of LLMs in graphic information processing, large-scale datasets and frameworks are used. ImageNet [35] is a large image recognition dataset that provides rich image sample and label information and a standard benchmark for the performance evaluation of LLMs in image classification tasks. The common objects in context (COCO) [36] dataset provides detailed object detection and segmentation annotation information so that the performance of LLMs in these tasks can be evaluated. In addition, the VisionLLM [37] framework focuses on open visual tasks, allowing LLMs to generate natural language descriptions and answers based on visual input, providing a wider range of possibilities for LLMs applications in the field of graphic information processing.
2.4. Dynamic Imagery
To evaluate the performance of LLMs in dynamic image processing tasks, the UCF101 [38] dataset is used as it contains 101 action categories, providing a standard benchmark for LLMs performance evaluation in action recognition tasks. The Kinetics [39] dataset contains videos of human actions in a variety of contexts, allowing LLMs to identify and classify actions in a wider range of contexts. In addition, the VITA [40] dataset, as a multimodal dataset, combines multiple data types such as video, image, text, and audio and enables the performance evaluation of LLMs when processing different types of data. These datasets are resources for the training and evaluation of LLMs and the development of dynamic image processing.
3. Simulation and Comparison
We investigated the feedback mechanism of LLM models in simulating the response system problems of the low-altitude economy and response feedback effects in airspace management and route optimization. The results provide a basis for the sustainable development of the low-altitude economy through in-depth analysis and empirical research.
3.1. MMbench Framework
MMBench is a multi-modal benchmark launched by researchers from Shanghai Artificial Intelligence Lab, Nanyang Technological University, Chinese University of Hong Kong, National University of Singapore, and Zhejiang University. The system has an evaluation process from perception to cognitive abilities, covering 20 fine-grained abilities. The system collects more than 3000 multiple-choice questions from the Internet and authoritative benchmark datasets. The routine question and answer are broken down to extract options for evaluation based on rule matching and verify the consistency of the output results. Options are modified based on the ChatGPT 4.0 accurate matching model.
3.2. Data Structure
- Method: The names of the models or methods are recorded in this column as the basis of the dataset to distinguish different models. In this column, the performance of different models on the same task is identified and compared.
- Release date: In this column, the release date of the model is recorded. This information is crucial to understand the progress and evolution of the model. By comparing models with different release dates, improvements or changes in performance are traced over time.
- Parameters: The number of parameters of the model is recorded in (in billions). The number of parameters is an important index to measure model complexity. In general, a model with more parameters has stronger learning ability and representation ability, but it also requires higher computational costs and a higher risk of overfitting.
- Language model: The underlying language model used by the model is recorded. Language model is a basic technology in natural language processing with an important impact on the performance of the model. By comparing the use of different language models, their impact on model performance is analyzed.
- Visual model: The underlying visual model used by the model is stored. Visual models play a key role in computer vision tasks. The performance and applicability of different visual models for cross-modal tasks are recorded.
- Average score: The overall score of the model and an assessment result of the model’s performance across all tasks are recorded. This score helps to understand the overall performance of the model and compare it between different models.
- Logical reasoning: The model’s score on the logical reasoning task is recorded. Logical reasoning ability is one of the important indexes to measure the level of model intelligence. The ability of the model in logical inference, reasoning judgment, and so on is analyzed.
- Attribute inference: The model’s score on the attribute inference task is recorded. Attribute inference refers to the inference of attributes or characteristics of objects or events based on existing information. The model’s ability in attribute inference and its application potential in different scenarios is assessed.
- Relational reasoning: The model’s score on the relational reasoning task is recorded. Relational reasoning refers to the ability to understand and infer relationships between objects. This ability is of great significance for the understanding and application of the model in complex scenarios.
- Single-object perception: The model’s score on the single-object perception task is recorded. Single-object perception refers to the ability of a model to recognize and perceive a single object. The performance of the model is analyzed in terms of single object recognition.
- Multi-object perception: The model’s score on the multi-object perception task is recorded. Multi-object perception refers to the ability of a model to recognize and perceive multiple objects. This ability is critical to the understanding and application of models in complex scenarios.
- Coarse-grained perception: The model’s score on the coarse-grained perception task is recorded. Coarse-grained perception refers to the model’s ability to understand and perceive objects or scenes at a larger scale or higher level. Using the score, the model performance is assessed in terms of coarse-grained perception and its applicability in different application scenarios.
3.3. Data Collection and Variables
The 12 metrics were used for a multi-faceted evaluation of each model’s performance. The average score (AS) served as a general indicator of overall model quality, while logical reasoning (LR), attribute inference (AI), and relational reasoning (RR) measure specific cognitive abilities. The perception-related metrics—single object perception (SOP), multiple object perception (MOP), and coarse-grained perception (CGP) were used for applications involving real-time environmental understanding and decision-making for safe and efficient operations in the low-altitude domain. To understand the impact of integrating language and visual components, we introduced the binary variables LM_a and VM_a. These variables indicate whether a model includes a dedicated language or visual component, respectively. This categorization presented how the presence of these components affected the overall performance and specific capabilities of the models. The experimental variable is presented in Table 1.

Table 1.
Descriptive statistics of dataset.
For the low-altitude economy, advanced LLMs are used to enhance a variety of applications, from autonomous navigation and real-time traffic management to customer service and regulatory compliance. The strong performance in logical reasoning, attribute inference, and relational reasoning suggests that these models enable informed decisions and adapt to changing conditions, which is crucial for the safe and efficient operation of low-altitude vehicles. The high scores in perception metrics (SOP, MOP, and CGP) indicate that LLMs accurately interpret and respond to visual data and perform tasks such as object detection, tracking, and scene understanding. This capability is particularly important for applications like aerial surveillance, emergency response, and urban air mobility, where real-time situational awareness is essential.
The descriptive statistics of the 153 LLMs provide information to understand the current landscape of AI models and their potential to transform the low-altitude economy. The integration of language and visual components, along with the strong performance in cognitive and perceptual tasks, positions these models as powerful tools for innovation and growth. Future research is needed to validate the results of this study and implement LLMs in the low-altitude economy.
3.4. Regression Analysis
The ordinary least square (OLS) regression model was used to assess the relationship between the presence of visual and language models (VM_a and LM_a) and the performance metrics: AI, LR, SOP, MOP, and CGP. The dependent variables were the scores for each of these metrics, while the independent variables included the binary indicators for the presence of visual and language models, as well as the number of parameters (Pa).
The regression equation is represented as
Score; = βo + β1·VMa + β2·LMa + β3·Pa + Ei
The OLS regression results are summarized in Table 2 and show the performance of LLMs with and without visual and language components.
Table 2.
Regression models used to compare and analyze results.
For AI, the coefficient for VM_a in the AI regression was positive, indicating that the presence of a visual model increased attribute inference performance by 12.5%. This suggests that visual models enhanced the ability of LLMs to accurately infer attributes from data for tasks such as object recognition and classification in the low-altitude economy. The effect of LM_a on AI was negative but not statistically significant, suggesting that the presence of a language model did not substantially impact attribute inference. The coefficient for VM_a in the LR regression was not statistically significant, indicating that the presence of a visual model did not have a substantial impact on logical reasoning. The effect of LM_a on LR was positive but not statistically significant, suggesting that the presence of a language model slightly improved logical reasoning, but the effect was not strong enough to be considered significant. The coefficient for VM_a in the SOP regression was negative and statistically significant, indicating that the presence of a visual model decreased SOP by 11.7%. While visual models excelled in several areas, they struggled with specific perceptual tasks. The effect of LM_a on SOP was negative but not statistically significant, suggesting that the presence of a language model did not substantially impact SOP. The coefficient for VM_a in the MOP regression was not statistically significant, indicating that the presence of a visual model did not have a substantial impact on multiple object perception. The effect of LM_a on MOP was negative but not statistically significant, suggesting that the presence of a language model did not substantially impact multiple object perception. The coefficient for VM_a in the CGP regression was negative and statistically significant, indicating that the presence of a visual model decreased CGP by 11.7%. While visual models excelled in some areas, they struggled with broader perceptual tasks. The effect of LM_a on CGP was positive but not statistically significant, suggesting that the presence of a language model slightly improved CGP, but the effect was not strong enough to be considered significant. The coefficient for Pa was negative and statistically significant, indicating that an increase in the number of parameters led to a 1.77% decrease in overall performance. While larger models may have more capacity, they introduced complexity that negatively impacted efficiency.
3.5. Correlation Matrix Heat Map
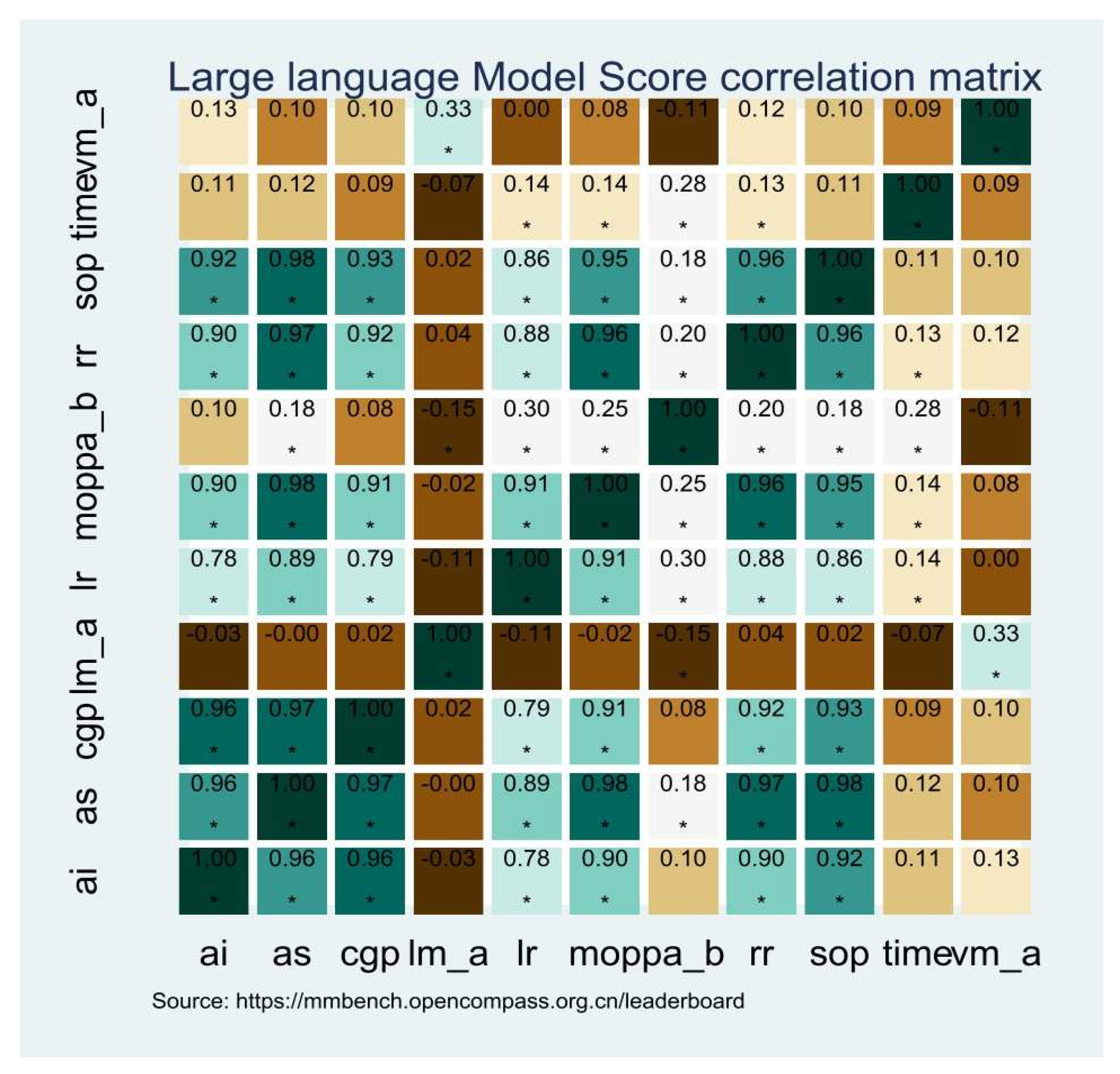
The correlation matrix heat map (Figure 1) shows a color gradient to represent the strength of the correlations. Darker colors indicate stronger positive or negative correlations, while lighter colors represent weaker correlations. This visualization helps to identify patterns and dependencies within the dataset, providing valuable insights into the performance characteristics of LLMs.
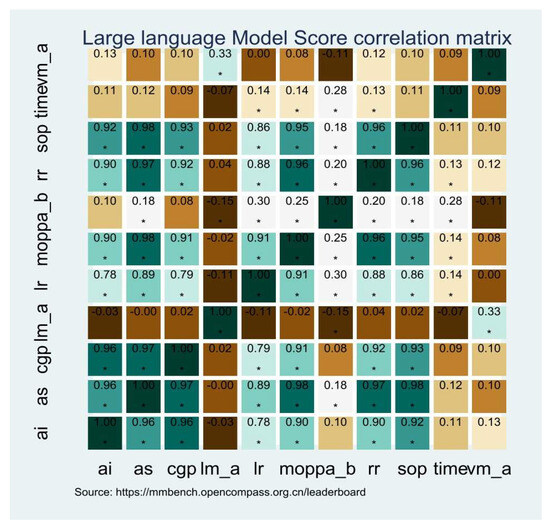
Figure 1.
Correlation matrix heat map. * p < 0.05.
- Negative of Pa
The correlation matrix revealed that Pa deteriorated the performance of models with a visual component. Specifically, the correlation coefficient was −0.15, indicating that as the number of parameters increased, the performance of visual models decreased. This suggests that larger and more complex visual models suffer from overfitting or computational inefficiency. Similarly, the presence of a language model was also negatively correlated with the number of parameters, with a correlation coefficient of −0.11. This effect was more pronounced for language models, suggesting that they were more sensitive to parameter size. The negative impact of parameters on performance highlighted the importance of efficient model design, especially in resource-constrained environments such as the low-altitude economy.
- High correlation of MOP
MOP showed strong positive correlations with AI, AS, CGP, LR, RR, and SOP. These correlations were significant, with p-values above 0.90, indicating that models capable of handling multiple objects performed well across a wide range of tasks. LLMs with strong multi-object processing capabilities were versatile enough to handle complex, real-world scenarios effectively.
- Relationship between visual and language models
A significant positive correlation between the presence of a visual model and the performance of language models was observed. The correlation coefficient was 0.33, indicating that language models benefited from the inclusion of a visual component. Visual information enhanced the overall performance of LLMs, particularly in tasks that required linguistic and visual understanding. However, the reverse relationship—i.e., the influence of language models on visual models—was not strong. This asymmetry indicated that while visual models significantly boosted the performance of language models, the impact of language models on visual models was less pronounced. This highlights the complementary nature of visual and language components, where visual data were useful in linguistic tasks but were not critical for visual tasks.
- Significant correlations with AS
AS is an important measure of overall model performance. The correlation matrix showed that AS was highly correlated with MOP, RR, SOP, CGP, and AI, with correlation coefficients of higher than 0.90. Models with high average scores excelled in multiple areas, reflecting a well-rounded and robust performance profile. Interestingly, the high correlations with AS were not dependent on whether the model included a visual or language component. The overall performance of an LLM was influenced by a combination of factors, and the presence of specific components (visual or language) did not ensure excellent performance. Instead, these components and the model’s ability were integrated to process diverse types of information showing superior performance.
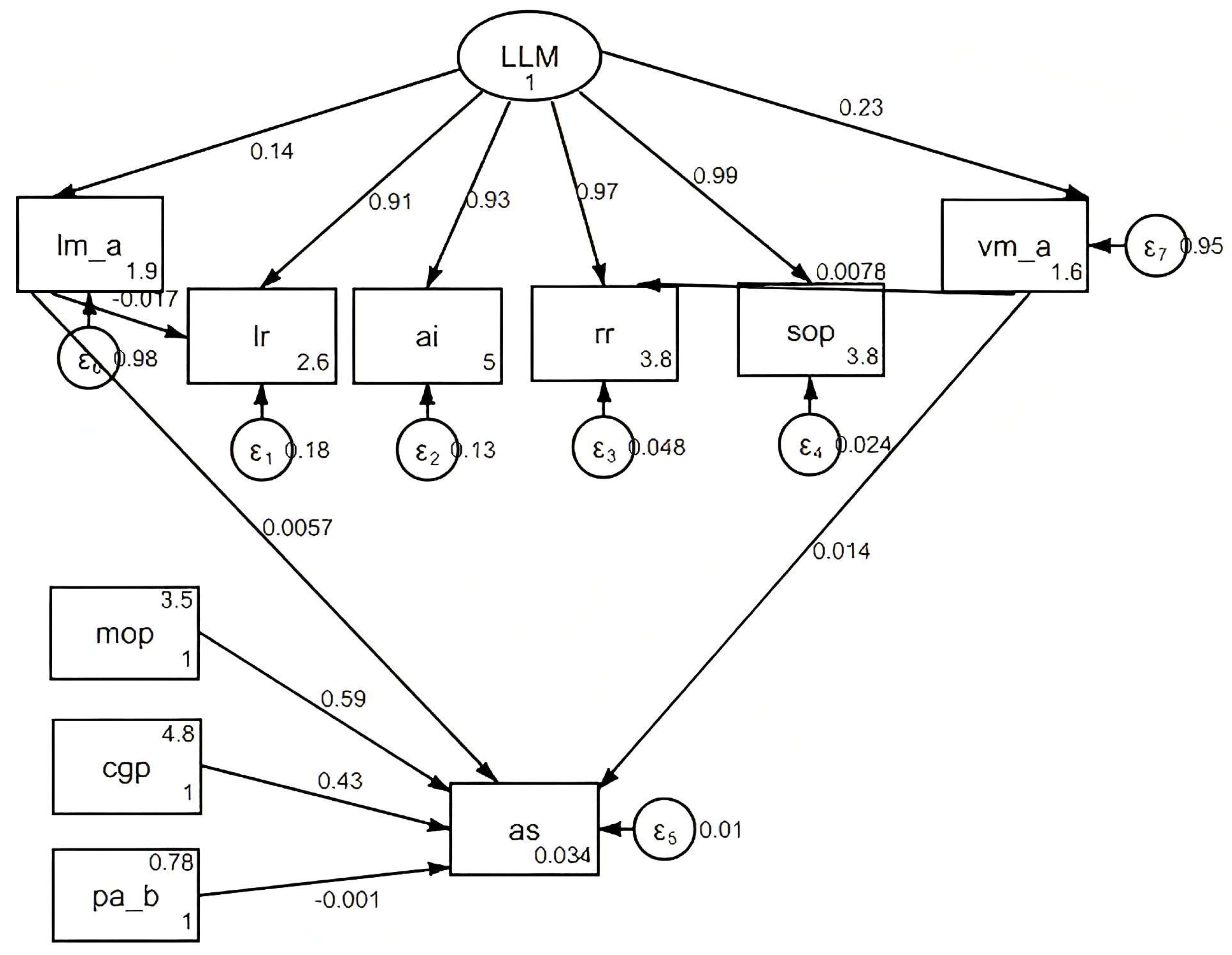
3.6. Structural Equation Model and Path Dependence
The student engagement metric (SEM) analysis result is summarized in Figure 2, showing the direct and indirect effects of the LLM components on the AS.
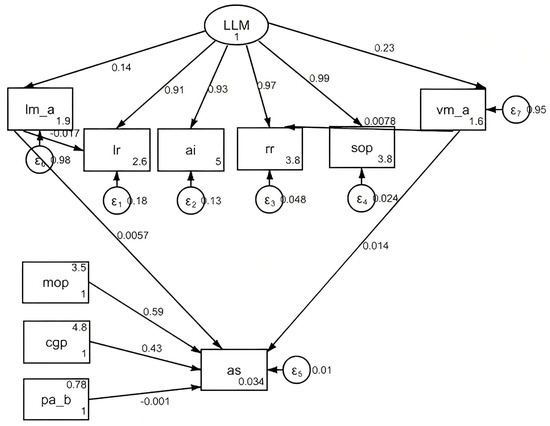
Figure 2.
Effects of LLM components on AS.
The direct effect score of the visual model on the AS was 0.0057, which was small. The presence of a visual component showed a limited direct impact on the overall average score. The direct effect score of LM on AS was 0.014, indicating a slightly stronger but still modest direct influence. Pa had a negative direct effect on AS, with a coefficient of −0.0177. This confirmed that larger models suffered from decreased efficiency and performance, especially under current computational constraints.
The SEM results showed that LLMs, particularly those with visual and language components, had strong direct effects on LR, AI, RR, and SOP. These metrics, in turn, had significant indirect effects on AS. For example, the presence of a visual model significantly enhanced LR, AI, RR, and SOP, which then positively contributed to AS. MOP and CGP played mediating roles in the relationship between the LLM components and AS. Specifically, MOP had a substantial indirect effect on AS, accounting for over 50% of the total effect. The ability to handle multiple objects is a key factor in achieving high overall performance. Additionally, CGP contributed significantly to AS, to a lesser extent than MOP.
4. Mechanism Flowchart
LLMs and related technologies are applied to a wide range of problems, from mathematical computations to text analysis, image processing, and dynamic video imagery. While the general workflow for these applications shares commonalities, the specific implementation details and focus areas differ significantly. A detailed comparison and summary of the workflows for handling mathematical, textual, graphical, and dynamic video imagery data are as follows.
4.1. Impact Mechanism of LLMs
The user request is processed using natural language for a variety of services, such as drone delivery, aerial photography, or any other low-altitude service. The user can specify details including the destination, time constraints, and any special requirements. LLM serves as the core component to receive and process the user’s request. The model uses advanced NLP to understand and interpret the user’s intent. This step is crucial to set the foundation for the entire service delivery process. LLM analyzes the user’s request to understand the specific needs and expectations. For example, if a user requests a drone delivery, the model identifies the type of package, the delivery location, and any time constraints. This understanding is essential for providing accurate and relevant responses.
Once the user intent is understood, the LLM further refines the user’s requirements. It extracts key information such as the exact delivery address, preferred delivery window, and any special instructions. This step ensures that all necessary details are captured and organized for the next stages. Based on the parsed requirements, LLM plans the task by determining the best approach to fulfill the request. For drone delivery, the most efficient route is selected, considering weather conditions and ensuring compliance with local regulations. LLM prioritizes tasks based on urgency and resource availability. LLM designs the optimal flight path or action sequence for the drone or aerial vehicle by calculating the shortest and safest route, avoiding obstacles, and planning for contingencies. The model generates a detailed action plan, specifying each step the drone needs to take to complete the task. LLM generates a response to the user, confirming the details of the planned task or requesting additional information. The user is informed to make necessary adjustments to an estimated delivery time, a summary of the planned route, and any other relevant information before the task is executed. With the plan in place, LLM sends the task instructions to the drone or aerial vehicle. The device then initiates the task, following the predefined route and actions. In this phase, LLM monitors the progress and provides real-time updates to the user.
The drone or aerial vehicle carries out the task, such as delivering a package or capturing images. The device follows the planned route and performs the required actions. Advanced sensors and onboard systems ensure that the task is completed accurately and safely. Throughout the task execution, the system continuously monitors the drone’s status and environmental conditions. If any unexpected issues arise, such as adverse weather or technical problems, LLM makes real-time adjustments to the flight plan. This dynamic monitoring and adjustment capability mitigates risks and ensures the successful completion of the task. Once the task is completed, the system records the relevant data, including the time taken, distance traveled, and any deviations from the original plan. This information is used to evaluate the performance of the service and identify areas for improvement.
After the task is completed, the system collects feedback from the user. This feedback includes the user’s satisfaction with the service, any issues encountered, and suggestions for improvement. Collecting and analyzing user feedback is crucial for continuous improvement and maintaining high service standards. The collected data, including user feedback, is analyzed to assess the overall quality of the service. In the analysis, patterns, trends, and potential problem areas are identified to understand how well LML is performing and where improvements can be made. Based on the data analysis, LLM is updated and improved to refine the NLP algorithms, enhance the task planning capabilities, and improve the real-time monitoring and adjustment features. Continuous improvement of the LLM ensures effectiveness and adaptability to changing user needs and environmental conditions. The results of the data analysis and model improvement are used to optimize the overall service by streamlining the task planning process, improving communication with users, or enhancing the safety and efficiency of the drones. Service optimization aims to enhance the user experience and increase operational efficiency.
A detailed report is generated, summarizing the performance of the service. The report includes key metrics, success stories, and areas for improvement. This documentation provides a comprehensive overview of the service and serves as a basis for future planning and decision-making. The generated report is shared with relevant stakeholders of management, partners, and regulatory bodies. These stakeholders use the report to understand the service’s performance, make informed decisions, and plan for future developments. Sharing the report ensures transparency and accountability and helps to build trust among all parties involved.
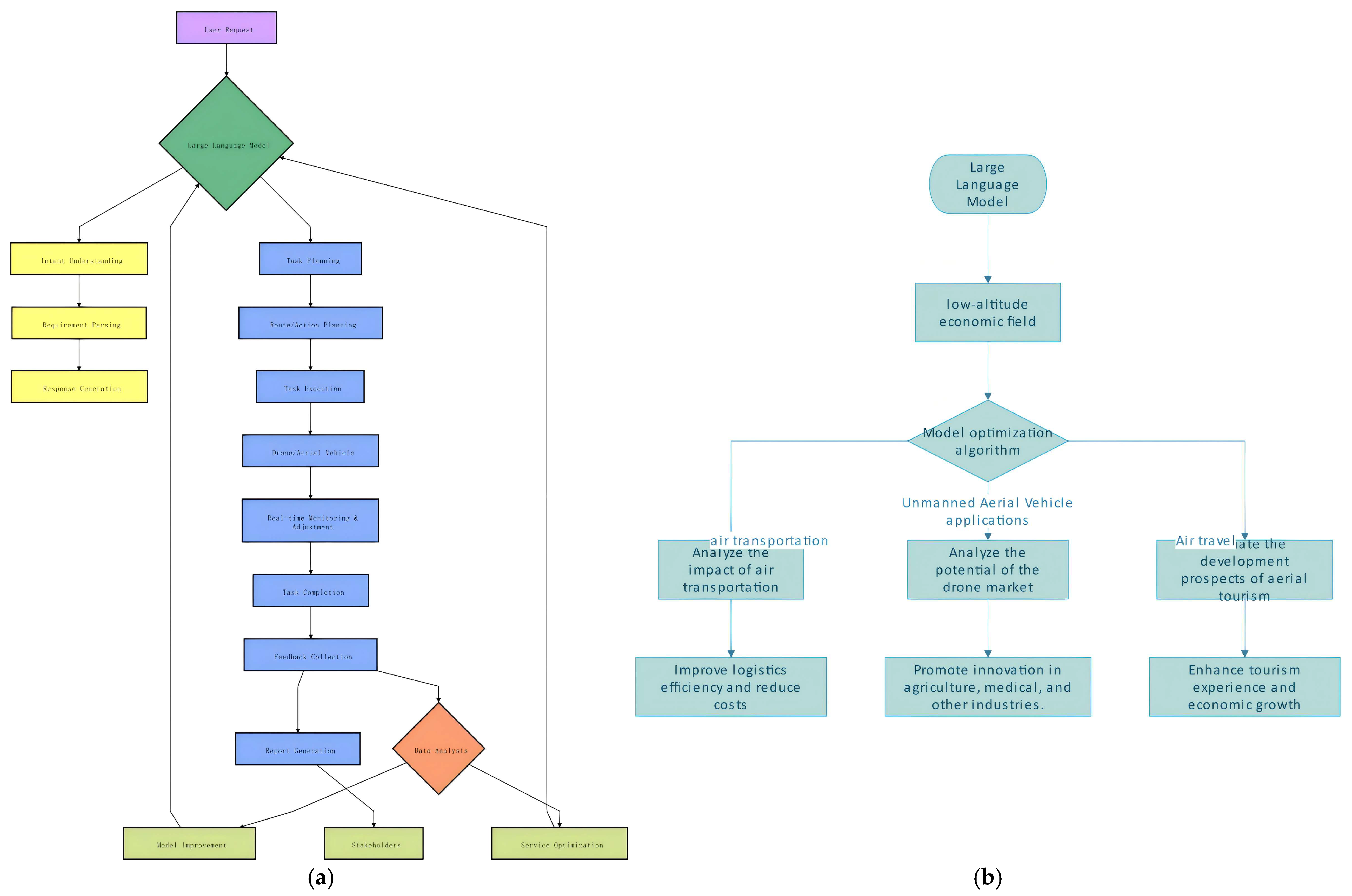
Figure 3 shows a detailed flowchart that illustrates the entire process from the initial user request to the final feedback and reporting, highlighting the role of LLM at each stage. The power of LLMs allows the low-altitude economy to have a higher level of efficiency, safety, and user satisfaction, ultimately driving growth and innovation in the sector.
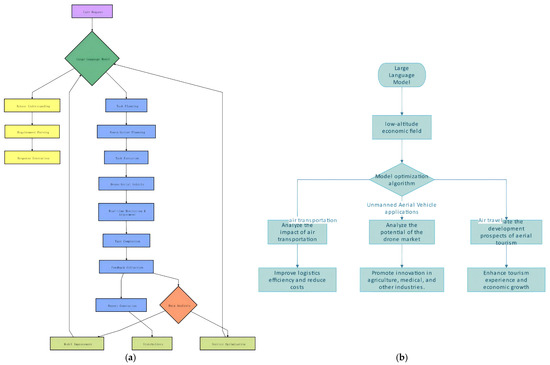
Figure 3.
Mechanism of LLMs (a,b).
The relationship between Figure 3a and Figure 3b. Through Figure a, the process mechanism of the large language model answering test questions in the simulation experimental data is sorted out and refined. Then, through Figure b, the above mechanism is simulated and applied to the process mechanism of the low-altitude economy.
4.2. Flowchart of LLMs
Recently, the development of AI has brought about significant changes across various industries, particularly in the low-altitude economy. A wide range of applications are used from unmanned aerial vehicles (UAVs) to air transportation and tourism, all of which have been advanced due to the integration of LLMs (Figure 3b). LLMs are characterized by their ability to process vast amounts of text data and generate human-like responses being indispensable tools in many sectors. Their applications extend beyond traditional domains, finding innovative uses in emerging technologies such as those within the low-altitude economy.
In the low-altitude economy, a diverse array of activities are conducted below 400 feet altitude. Air transportation, UAV applications, and air travel are included in the low-altitude economy. The advent of LLMs has significantly influenced the economy, leading to enhanced efficiencies, reduced costs, and new growth opportunities. In integrating LLMs into the low-altitude economy, the model optimization algorithm is necessary. This algorithm tailors the capabilities of LLMs to meet the unique demands of various applications such as optimizing flight paths for UAVs, predicting market trends in air transportation, or enhancing tourist experiences in air travel, the model optimization algorithm ensures that LLMs perform optimally.
One of the primary impacts of LLMs in the low-altitude economy is observed in air transportation. Through sophisticated analyses, LLMs predict traffic patterns, optimize routes, and even forecast maintenance needs, thereby improving logistics efficiency and reducing operational costs. This benefits commercial enterprises and enhances the overall reliability and speed of air transportation services. UAVs have revolutionized numerous industries, thanks to the integration of LLMs. In agriculture, UAVs equipped with LLMs analyze crop health, predict yields, and recommend precise application of fertilizers and pesticides. In medicine, they deliver life-saving supplies quickly and efficiently. Moreover, LLMs enable UAVs to navigate complex environments autonomously, promoting innovation across multiple sectors. Air travel is another facet of the low-altitude economy and has also been transformed by LLMs. These models evaluate consumer preferences, predict demand fluctuations, and suggest personalized travel packages. They enhance the tourism experience by offering tailored recommendations and ensuring seamless travel arrangements. Additionally, LLMs forecast the development prospects of aerial tourism, guiding strategic investments, and policy-making.
The integration of large language models into the low-altitude economy represents a significant leap forward in technological advancement. From optimizing air transportation to revolutionizing UAV applications and enhancing air travel experiences, LLMs have proven to be versatile tools capable of driving innovation and fostering growth. As technology continues to evolve, the applications of LLMs are broadened with enhanced efficiency and opportunities in the low-altitude economy.
5. Applications of LLMs in Low-Altitude Economy
5.1. Dynamic Mission Planning
One of the primary challenges in aerial operations is ensuring safe and efficient flight paths amidst constantly changing conditions. LLMs play a pivotal role in this task by analyzing real-time data sources, including weather reports, airspace congestion, and regulatory restrictions, to optimize mission plans. By leveraging their ability to process and comprehend vast amounts of information, LLMs provide operators with tailored flight plans that minimize risks and maximize operational efficiency.
5.2. Natural Language Interfaces for UAV Control
Another significant application of LLMs in the low-altitude economy is the development of natural language interfaces for UAV control. Traditional UAV control systems rely on complex user interfaces that require specialized training and expertise to operate. By integrating LLMs, operators command their drones with voice or text, lowering the barrier of entry for non-expert users. This enhances user experience and provides new possibilities for widespread adoption and commercialization of aerial services.
5.3. Automated Data Annotation and Analysis
UAVs and drones are equipped with an array of sensors and cameras that capture vast amounts of imagery and data during their operations. Manually annotating and analyzing the data is time-consuming and resource-intensive. However, LLMs, with their advanced natural language processing capabilities, automate this process. By understanding the context and content of the captured data, LLMs automatically annotate images, detect patterns, and generate insights, significantly streamlining the data analysis workflow.
5.4. Customer Service and Support
As the low-altitude economy continues to expand, the need for efficient and effective customer service and support increases. LLMs provide personalized assistance to customers, addressing their queries, troubleshooting issues, and offering guidance to utilize aerial services. By engaging in natural language interactions, LLMs enhance the overall user experience and foster greater customer loyalty.
5.5. Challenges and Mitigation Strategies
While the potential of LLMs in the low-altitude economy is undeniable, several challenges must be addressed. One of the primary concerns is data privacy and security, as the collection and analysis of vast amounts of data pose significant risks. To mitigate these risks, robust data encryption protocols and privacy-preserving algorithms must be implemented. Additionally, the computational requirements of LLMs are high, particularly for real-time applications. To overcome this challenge, edge computing solutions need to be employed to reduce latency and improve performance. Finally, the need for specialized training and fine-tuning of LLMs to the unique demands of aerial operations cannot be overstated. This requires collaboration between researchers, industry experts, and policymakers to ensure that LLMs are tailored to the specific needs of the low-altitude economy.
6. Conclusions
The integration of LLMs into the low-altitude economy enhances the capabilities and potential of aerial operations and services. The advanced capabilities of LLMs allow the industry to streamline mission planning, enhance user experience through natural language interfaces, automate data annotation and analysis, improve customer service and support, and ensure regulatory compliance and risk management.
The OLS regression analysis and robustness testing results enable an understanding of the performance and characteristics of LLMs, highlighting the strengths and limitations of visual and language models. These results provide valuable data for the development and deployment of AI systems in the low-altitude economy, paving the way for safer, more efficient, and more intelligent operations. The correlation matrix analysis results showed the relationships between various performance metrics in LLMs, revealing important patterns and dependencies. The negative impact of parameter size on performance, the significance of multi-object processing capabilities, and the complementary nature of visual and language components enable the understanding of the factors that drive the performance of LLMs. This result is important for developing and deploying AI systems in the low-altitude economy, highlighting the need for efficient, versatile, and robust models that can handle the diverse and dynamic challenges of this domain.
The SEM analysis results showed the direct and indirect effects of LLM components on AS, revealing the complex interplay between visual and language models, logical and perceptual metrics, and overall performance. The importance of multi-object processing capabilities and the need for efficient model design showed that robust and versatile models are required to address the diverse and dynamic challenges of the domain. The benefits of this integration are significant. For example, operators can make informed and efficient decisions in real-time, reducing the risk of accidents and increasing the overall safety of aerial operations. Consumers benefit from more accessible and user-friendly services, enabling wider adoption of drone-based technologies for delivery, mapping, and surveillance. Policymakers can understand the evolving landscape to formulate regulations that support innovation while safeguarding public safety and privacy.
The continued advancement of LLMs, coupled with advancements in other technologies such as artificial vision, autonomous systems, and 5G/6G connectivity, shows the potential of the low-altitude economy. As these technologies converge, new business models emerge to transform industries and create new economic opportunities. However, the benefits of LLMs in the low-altitude economy can be created through a collaborative effort of all stakeholders. Researchers must continue to enhance LLM capabilities for the unique demands of aerial operations. The industry must invest in the necessary infrastructure and integrate LLMs into their operations effectively. Policymakers must keep up with technological advancements and formulate regulations to foster innovation and ensure public safety.
The integration of LLMs into the low-altitude economy presents a transformative opportunity for the aerospace industry. By leveraging the advanced capabilities of LLMs, the industry can enhance efficiency, safety, and accessibility, driving the growth of a vibrant and dynamic low-altitude economy that benefits all stakeholders. It is essential to address related challenges and harness the potential of LLMs in shaping the future of aerial operations and services though collaboration.
Author Contributions
Conceptualization, J.W. and Y.S.; methodology, J.W.; software, J.W.; validation, J.W. and Y.S.; formal analysis, J.W.; investigation, Y.S.; resources, Y.S.; data curation, Y.S.; writing—original draft preparation, J.W.; writing—review and editing, Y.S.; visualization, Y.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The original data presented in the study are openly available in MMBench at https://mmbench.opencompass.org.cn/leaderboard.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Austin, J.; Odena, A.; Nye, M.; Bosma, M.; Michalewski, H.; Dohan, D.; Jiang, E.; Cai, C.; Terry, M.; Le, Q.; et al. Program synthesis with large language models. arXiv 2021, arXiv:2108.07732. [Google Scholar]
- Sapp, B.; Taskar, B. Modec: Multimodal decomposable models for human pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Luger, G.F. LLMs: Their Past, Promise, and Problems. Int. J. Semant. Comput. 2024, 18, 501–544. [Google Scholar] [CrossRef]
- Yamauchi, R.; Sonoda, S.; Sannai, A.; Kumagai, W. Lpml: Llm-prompting markup language for mathematical reasoning. arXiv 2023, arXiv:2309.13078. [Google Scholar]
- Chivereanu, R.; Cosma, A.; Catruna, A.; Rughinis, R.; Radoi, E. Aligning actions and walking to llm-generated textual descriptions. In Proceedings of the 2024 IEEE 18th International Conference on Automatic Face and Gesture Recognition (FG), Istanbul, Turkiye, 27–31 May 2024; IEEE: Piscataway, NJ, USA, 2024. [Google Scholar]
- Gopali, S.; Abri, F.; Namin, A.S.; Jones, K.S. The Applicability of LLMs in Generating Textual Samples for Analysis of Imbalanced Datasets. IEEE Access 2024, 12, 136451–136465. [Google Scholar] [CrossRef]
- Schneider, J.; Schenk, B.; Niklaus, C. Towards llm-based autograding for short textual answers. arXiv 2023, arXiv:2309.11508. [Google Scholar]
- Tan, J.; Xu, S.; Hua, W.; Ge, Y.; Li, Z.; Zhang, Y. Idgenrec: Llm-recsys alignment with textual id learning. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, Washington, DC, USA, 14–18 July 2024. [Google Scholar]
- Cai, Y.; Mao, S.; Wu, W.; Wang, Z.; Liang, Y.; Ge, T.; Wu, C.; You, W.; Song, T.; Xia, Y.; et al. Low-code LLM: Graphical user interface over large language models. arXiv 2023, arXiv:2304.08103. [Google Scholar]
- Zhang, S.; Zhang, Z.; Chen, K.; Ma, X.; Yang, M.; Zhao, T.; Zhang, M. Dynamic planning for llm-based graphical user interface automation. arXiv 2024, arXiv:2410.00467. [Google Scholar]
- Bazi, Y.; Bashmal, L.; Al Rahhal, M.M.; Ricci, R.; Melgani, F. Rs-llava: A large vision-language model for joint captioning and question answering in remote sensing imagery. Remote Sens. 2024, 16, 1477. [Google Scholar] [CrossRef]
- Naseh, A.; Thai, K.; Iyyer, M.; Houmansadr, A. Iteratively prompting multimodal llms to reproduce natural and AI-generated images. arXiv 2024, arXiv:2404.13784. [Google Scholar]
- Noever, D.; Noever, S.E.M. The multimodal and modular ai chef: Complex recipe generation from imagery. arXiv 2023, arXiv:2304.02016. [Google Scholar]
- Yang, Z.; Lin, X.; He, Q.; Huang, Z.; Liu, Z.; Jiang, H.; Shu, P.; Wu, Z.; Li, Y.; Law, S.; et al. Examining the commitments and difficulties inherent in multimodal foundation models for street view imagery. arXiv 2024, arXiv:2408.12821. [Google Scholar]
- Zhang, S. A High-Flyer in the Making. Beijing Rev. 2024, 67, 32–33. [Google Scholar]
- Zheng, B.; Liu, F. Random Signal Design for Joint Communication and SAR Imaging Towards Low-Altitude Economy. IEEE Wirel. Commun. Lett. 2024, 13, 2662–2666. [Google Scholar] [CrossRef]
- Fan, B.; Li, Y.; Zhang, R. Initial analysis of low-altitude internet of intelligences (IOI) and the applications of unmanned aerial vehicle industry. Prog. Geogr. 2021, 40, 1441–1450. [Google Scholar] [CrossRef]
- Chen, C.; He, Y.; Wang, H.; Chen, J.; Luo, Q. Delayptc-llm: Metro passenger travel choice prediction under train delays with large language models. arXiv 2024, arXiv:2410.00052. [Google Scholar]
- Liu, Y. Large language models for air transportation: A critical review. J. Air Transp. Res. Soc. 2024, 2, 100024. [Google Scholar] [CrossRef]
- Balcacer, A.; Hannon, B.; Kumar, Y.; Huang, K.; Sarnoski, J.; Liu, S.; Li, J.J.; Morreale, P. Mechanics of a Drone-based System for Algal Bloom Detection Utilizing Deep Learning and LLMs. In Proceedings of the 2023 IEEE MIT Undergraduate Research Technology Conference (URTC), Cambridge, MA, USA, 6–8 October 2023; IEEE: Piscataway, NJ, USA, 2024. [Google Scholar]
- Jiao, A.; Patel, T.P.; Khurana, S.; Korol, A.; Brunke, L.; Adajania, V.K.; Culha, U.; Zhou, S.; Schoellig, A.P. Swarm-GPT: Combining large language models with safe motion planning for robot choreography design. arXiv 2023, arXiv:2312.01059. [Google Scholar]
- Lykov, A.; Tsetserukou, D. LLM-BRAIn: AI-driven Fast Generation of Robot Behaviour Tree based on Large Language Model. arXiv 2023, arXiv:2305.19352. [Google Scholar]
- Xie, Q.; Zhang, T.; Xu, K.; Johnson-Roberson, M.; Bisk, Y. Reasoning about the Unseen for Efficient Outdoor Object Navigation. arXiv 2023, arXiv:2309.10103. [Google Scholar]
- Javaid, S.; Khalil, R.A.; Saeed, N.; He, B.; Alouini, M. Leveraging large language models for integrated satellite-aerial-terrestrial networks: Recent advances and future directions. IEEE Open J. Commun. Soc. 2024, 6, 399–432. [Google Scholar] [CrossRef]
- Li, H.; Xiao, M.; Wang, K.; Kim, D.I.; Debbah, M. Large language model based multi-objective optimization for integrated sensing and communications in uav networks. IEEE Wirel. Commun. Lett. 2025, 14, 979–983. [Google Scholar] [CrossRef]
- Rasal, S.; Boddhu, S.K. Beyond segmentation: Road network generation with multi-modal llms. In Science and Information Conference; Springer Nature: Cham, Switzerland, 2024; pp. 308–315. [Google Scholar]
- Liu, Y.; Duan, H.; Zhang, Y.; Li, B.; Zhang, S.; Zhao, W.; Yuan, Y.; Wang, J.; He, C.; Liu, Z.; et al. Mmbench: Is your multi-modal model an all-around player? In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; Springer: Berlin, Germany, 2024. [Google Scholar]
- Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; Agarwal, S.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Hoffmann, J.; Borgeaud, S.; Mensch, A.; Buchatskaya, E.; Cai, T.; Rutherford, E.; Casas, D.D.L.; Hendricks, L.A.; Welbl, J.; Clark, A.; et al. Training compute-optimal large language models. arXiv 2022, arXiv:2203.15556. [Google Scholar]
- Ouyang, L.; Wu, J.; Jiang, X.; Almeida, D.; Wainwright, C.; Mishkin, P.; Zhang, C.; Agarwal, S.; Slama, K.; Ray, A.; et al. Training language models to follow instructions with human feedback. Adv. Neural Inf. Process. Syst. 2022, 35, 27730–27744. [Google Scholar]
- Wang, A.; Singh, A.; Michael, J.; Hill, F.; Levy, O.; Bowman, S.R. GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding. arXiv 2018, arXiv:1804.07461. [Google Scholar]
- Xu, L.; Liu, J.; Pan, X.; Lu, X.; Hou, X. DataCLUE: A Benchmark Suite for Data-centric NLP. arXiv 2021, arXiv:2111.08647. [Google Scholar]
- Zellers, R.; Holtzman, A.; Bisk, Y.; Farhadi, A.; Choi, Y. Hellaswag: Can a machine really finish your sentence? arXiv 2019, arXiv:1905.07830. [Google Scholar]
- Bisk, Y.; Zellers, R.; Gao, J.; Choi, Y. Piqa: Reasoning about physical commonsense in natural language. In Proceedings of the AAAI Conference on Artificial Intelligence, Philadelphia, PA, USA, 25 February–4 March 2025. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the IEEE Computer Vision & Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Lin, T.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin, Germany, 2014. [Google Scholar]
- Wang, W.; Chen, Z.; Chen, X.; Wu, J.; Zhu, X.; Zeng, G.; Luo, P.; Lu, T.; Zhou, J.; Qiao, Y.; et al. Visionllm: Large language model is also an open-ended decoder for vision-centric tasks. Adv. Neural Inf. Process. Syst. 2023, 36, 61501–61513. [Google Scholar]
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A dataset of 101 human actions classes from videos in the wild. arXiv 2012, arXiv:1212.0402. [Google Scholar]
- Kay, W.; Carreira, J.; Simonyan, K.; Zhang, B.; Hillier, C.; Vijayanarasimhan, S.; Viola, F.; Green, T.; Back, T.; Natsev, P.; et al. The kinetics human action video dataset. arXiv 2017, arXiv:1705.06950. [Google Scholar]
- Fu, C.; Lin, H.; Long, Z.; Shen, Y.; Zhao, M.; Zhang, Y.; Dong, S.; Wang, X.; Yin, D.; Ma, L.; et al. Vita: Towards open-source interactive omni multimodal llm. arXiv 2024, arXiv:2408.05211. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).