1. Introduction
The world energy landscape is transforming due to a gradual increase in electricity consumption over the years, which is forecast to reach historic levels in the next few decades [
1]. The increased demand for renewable energy sources and smart grid technology has led to a greater need for reliable long-term power load forecasts. Accurate forecasting is essential for the efficient planning of resources, the development of infrastructure, and the maintenance of the stability and reliability of power systems [
2].
Long-term load forecasting (LTLF) poses particular challenges compared to short-term forecasting. It requires models that can handle short-term fluctuations as well as long-term trends induced by economic growth, technological advancements and climate change [
3]. Although traditional forecasting methods are good for their simplicity and interpretability, they are ineffective in handling the complexity and non-linearity associated with long-term power load patterns [
4].
This indicates that significant developments have been made in power load forecasting methodologies. The initial approach was largely statistical, with the majority using autoregressive integrated moving average (ARIMA) models [
5]. While these models are effective for stationary time series, they are highly limited when it comes to handling the non-stationarity and non-linearity of long-term power load data [
6].
This completely changed the dynamics of forecasting. Improvements in AI techniques and machine learning have enhanced the architecture of neural networks, particularly RNNs and LSTM networks, which have a greater ability to capture time dependencies [
7]. However, these models have been shown to degrade over larger time horizons due to issues such as vanishing gradients [
8].
In recent years, attention-based models have emerged, inspired by advances in natural language processing. These models, as exemplified by the Transformer model, appear to have potential for modeling long-range dependencies [
9]. However, they are sometimes insensitive to local patterns that are important in power load dynamics [
10].
Despite these advances, a significant gap remains in successfully blending the strengths of various modeling techniques for LTLF. No matter how advanced they are, standalone models tend not to accommodate the entire range of factors that contribute to long-term power load patterns [
11]. Recent advances in neural architectures have shown promise in addressing these limitations. Long-term load forecasting has been approached through hierarchical neural models with time integrators [
12], while machine learning techniques have been applied to traffic classification and prediction tasks [
13]. Additionally, recurrent neural networks have been successfully applied to long-term generating power forecasting for wind power systems [
14].
To address this issue, we propose a model called MP-RWKV-TS. As an improvement on the efficient RWKV-TS framework [
15], it combines the advantages of recurrent networks’ good fit in short-term correlations with transformer-based models’ good fit in long-range dependence capabilities.
Our work makes a number of significant contributions to the field of long-term power load forecasting:
We introduce MP-RWKV-TS, a combined model that extends the capabilities of RWKV-TS by utilizing parallel computation paths to identify both temporal patterns and cross-variable relationships.
We utilize an Adaptive Time-Mixing Operator (ATMO) to enhance the model’s temporal variable dependency strength across timescales.
Our approach incorporates a Cross-Variable Attention (CVA) mechanism that operates in parallel with temporal processing, enabling the modeling of complex interactions between factors affecting power load.
We conduct thorough and detailed experiments on real-world data from a North African urban power grid distribution network, demonstrating the advantages of MP-RWKV-TS in long-term forecasting scenarios.
We also introduce the interpretability aspects of the model to provide greater insight into the factors responsible for long-term power load dynamics.
The rest of this paper is organized as follows:
Section 2 formulates the problem,
Section 3 details our proposed MP-RWKV model,
Section 4 presents the experimental results, and
Section 5 concludes the paper.
2. Problem Formulation
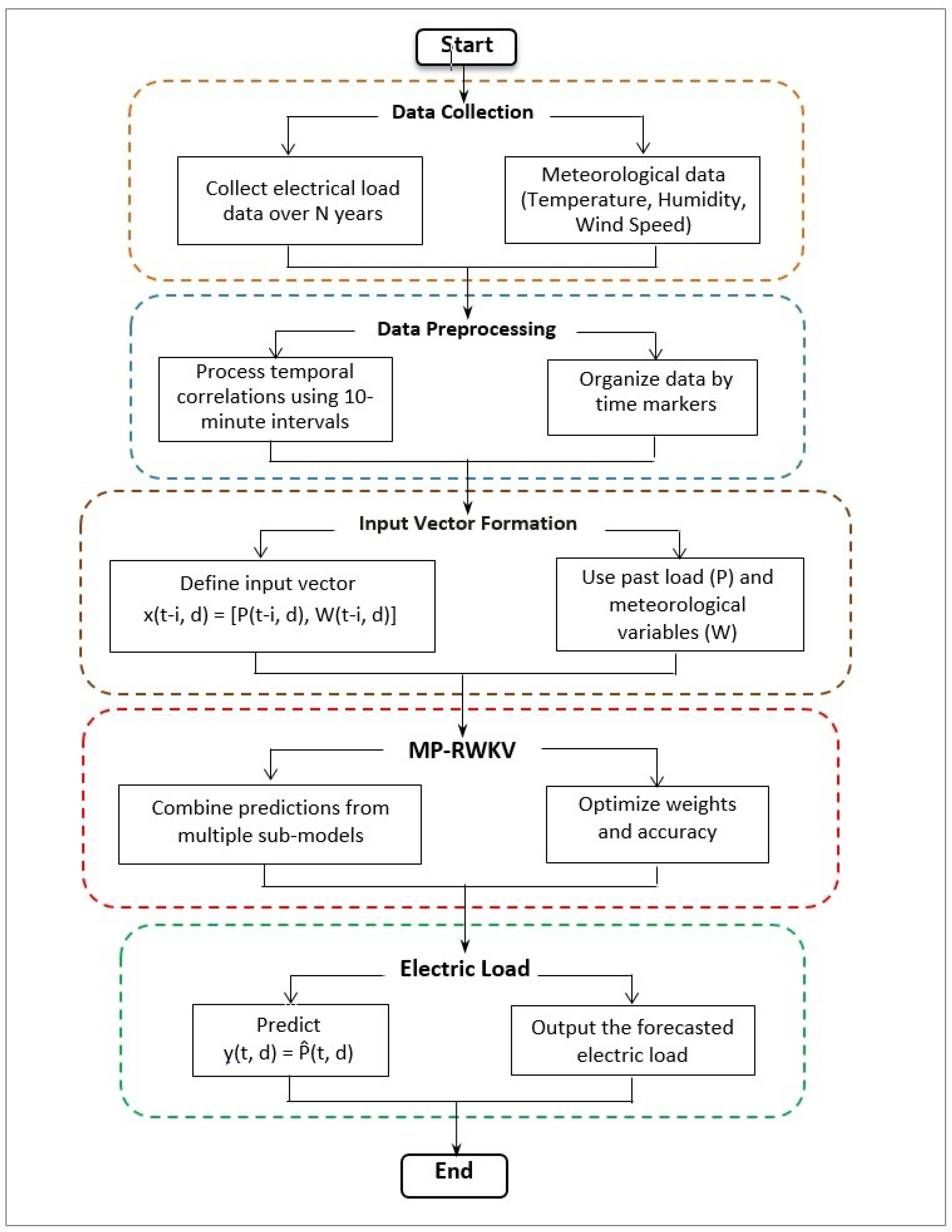
Let denote a dataset spanning N years containing both power load measurements and associated meteorological variables. We define the following:
2.1. Input Variables
For any time step t and dayd:
2.1.1. Weather Variables
Let
denote the weather feature vector:
where
represents temperature;
represents humidity;
represents wind speed.
2.1.2. Power Load
Let denote the power load at time step t of day d.
2.2. Temporal Modeling
Given a temporal context window
, we construct the input feature vector
as
where
represents historical load values;
represents historical weather conditions.
2.3. Prediction Objective
The forecasting task can be formulated as learning a function
f:
where
is the predicted power load;
represents the model parameters;
is the prediction function.
The objective is to minimize the prediction error:
where
is an appropriate loss function measuring the discrepancy between predicted and actual power load values.
3. The Proposed Model
3.1. Theoretical Foundation
The MP-RWKV architecture extends the RWKV-TS model [
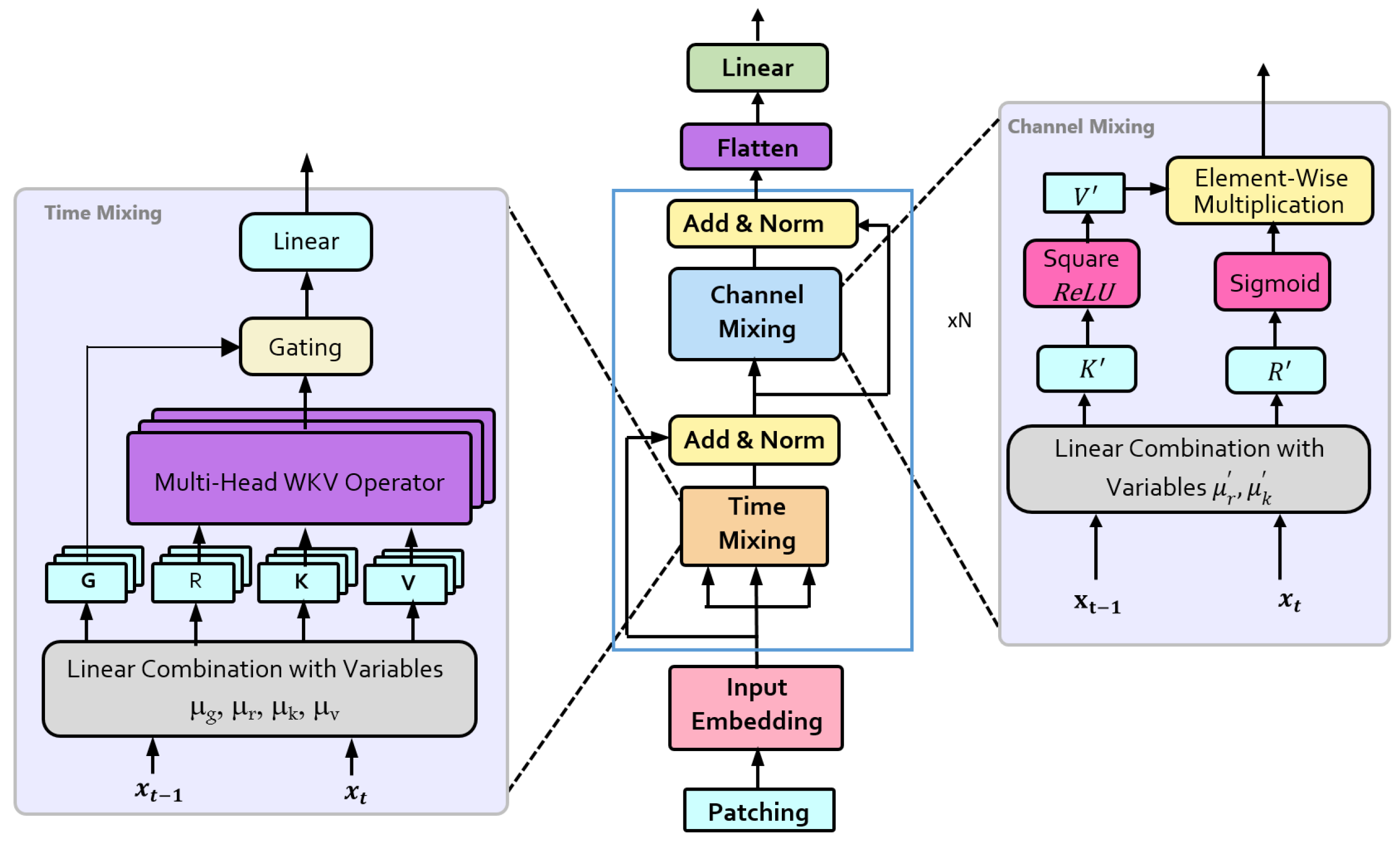
15] by incorporating principles of parallel information processing inspired by cognitive science theories. While maintaining the core efficiency of RWKV-TS, our enhanced model introduces parallel processing paths to concurrently handle different aspects of temporal data. This approach allows the model to simultaneously process temporal patterns and cross-variable dependencies, similar to how biological systems process sequential and relational information.
Figure 1 illustrates the foundational RWKV-TS architecture that serves as the basis for our enhanced MP-RWKV model.
3.2. Input Processing and Representation
Consider a multivariate time series , where L represents the sequence length and M denotes the number of variables. The input processing consists of three critical stages:
3.2.1. Instance Normalization
To ensure numerical stability and consistent gradient flow, each univariate sequence undergoes instance normalization:
where
represents the
i-th variable sequence.
3.2.2. Patch Segmentation
The normalized sequence is segmented into overlapping patches to capture local temporal structures:
where
P denotes patch length and
S represents stride length. This segmentation creates patches
.
3.2.3. Token Projection
The projection phase maps the segmented patches into a high-dimensional feature space through a learned linear transformation. Given patches
, where
N denotes the number of patches and
P represents the patch length, the projection is formulated as follows:
where
is a learnable projection matrix that transforms the input to dimension
D. This transformation enables the model to learn rich feature representations while preserving temporal relationships within the sequence. The projected tokens
serve as the foundation for subsequent temporal and cross-variable processing in the multi-path architecture.
3.3. Parallel Path Processing
Consider a multivariate time series , where represents the input embedding at time step t. The enhanced architecture decomposes temporal processing into two complementary paths: a temporal path for sequential pattern extraction and a channel path for cross-variable dependency modeling. This decomposition enables specialized processing while maintaining parameter efficiency through strategic weight sharing.
As shown in
Figure 2, our MP-RWKV architecture introduces parallel processing pathways that enable specialized handling of temporal patterns and cross-variable relationships.
3.3.1. Time-Mixing Path
The temporal path implements sequential pattern extraction through a hierarchical process consisting of adaptive mixing and position-aware attention mechanisms.
Adaptive Time-Mixing Operator (ATMO)
The ATMO computes dynamic interpolation coefficients to adaptively balance temporal dependencies:
where
defines the mixing transformation and
ensures the coefficients lie in
. The temporal representations are then computed through weighted interpolation:
where
projects the interpolated state into key–value pairs. This formulation enables the model to dynamically adjust the influence of recent and historical information.
Time-Aware Attention
The temporal context is integrated through position-sensitive attention:
with the attention mechanism defined as
The temporal bias matrix
encodes relative positional information, enabling the model to capture position-dependent patterns in the sequence.
3.3.2. Channel-Mixing Path
The channel path focuses on modeling relationships between variables through parameter-efficient transformations and gated attention mechanisms.
Cross-Variable Processing
The channel-specific representations leverage the latter half of the mixing coefficients:
This formulation shares the projection matrix
with the temporal path, promoting parameter efficiency while maintaining representational capacity.
Channel-Aware Attention
Cross-variable dependencies are modeled through a gated attention mechanism:
defined as
where
serves as an adaptive gating mechanism that modulates attention weights based on the relative importance of different variables. The scaling factor
ensures stable gradient propagation during training.
3.4. Path Integration and Output Generation
The integration of temporal and channel paths is achieved through an adaptive fusion mechanism that dynamically balances their contributions while maintaining residual connections to the input signal.
Adaptive Path Fusion
Let
and
denote the outputs from temporal and channel paths, respectively. The fusion mechanism computes dynamic weights through
where
is a learnable projection matrix and
denotes concatenation.
The paths are integrated through weighted combination with residual connection:
This formulation ensures that the model can adaptively prioritize temporal or cross-variable patterns while maintaining access to the original input features.
3.5. Advancing upon RWKV-TS
Our MP-RWKV model builds upon the foundation established by RWKV-TS [
15], introducing several enhancements that specifically address the challenges of long-term power load forecasting:
Parallel processing paths: While RWKV-TS processes all variables through a single computational path, MP-RWKV introduces parallel processing paths that enable specialized handling of temporal patterns and cross-variable relationships simultaneously. This allows the model to maintain the computational efficiency of RWKV-TS while expanding its representational capacity.
Cross-Variable Attention (CVA): MP-RWKV enhances the original model with a dedicated path for modeling relationships between different variables through a specialized attention mechanism. This is particularly crucial for power load forecasting, where interactions between meteorological factors and temporal indicators significantly impact prediction accuracy.
Adaptive path integration: Unlike the single-path processing in RWKV-TS, our model dynamically balances the contributions of temporal and cross-variable information based on the forecasting context, leading to more adaptive and robust predictions across varying horizons.
Enhanced gradient flow: By separating concerns into parallel paths, MP-RWKV mitigates potential gradient issues that can affect single-path recurrent models when dealing with long-term dependencies.
These enhancements maintain the computational efficiency that makes RWKV-TS attractive while extending its capability to handle the complex temporal and cross-variable relationships present in power load data across multiple time scales.
3.6. Training Objective
The model is optimized through a composite objective function that combines reconstruction accuracy with temporal consistency:
where
denotes the model parameters and
is a hyperparameter controlling the trade-off between objectives.
The mean-squared error term measures prediction accuracy:
where
and
represent the ground truth and predicted values, respectively.
The temporal regularization term promotes smoothness in the temporal representations:
This regularization encourages the model to learn continuous temporal patterns while allowing for abrupt changes when supported by the data.
The optimization problem can be formally stated as
solved through stochastic gradient descent with adaptive moment estimation:
where
and
are bias-corrected first- and second-moment estimates of the gradients.
3.7. Complexity Analysis
We analyze the computational and space complexity of MP-RWKV-TS in terms of sequence length L and feature dimension D. The analysis considers both the forward pass computation and memory requirements.
Table 1 presents the computational and space complexity analysis for different sequence models, where
L represents sequence length and
D represents feature dimension. While Transformers offer full parallelization, they suffer from quadratic complexity in sequence length. Recurrent models like RNN and LSTM have linear time complexity but cannot be parallelized. Our proposed MP-RWKV-TS model achieves linear time complexity while supporting partial parallelization, offering a balanced trade-off between efficiency and computational requirements.
4. Experiments
Extensive experimentation on diverse time series datasets was conducted to validate the effectiveness of MP-RWKV in temporal pattern recognition and forecasting tasks. The model is systematically evaluated against state-of-the-art architectures, including RWKV-TS, Transformer variants, and traditional forecasting methods, using three complementary performance metrics: mean-squared error (MSE) to quantify prediction accuracy with emphasis on larger deviations, Mean Absolute Error (MAE) to assess absolute prediction differences, and Mean Absolute Percentage Error (MAPE) to measure relative accuracy across different scales. Furthermore, comprehensive ablation studies were performed to analyze the individual contributions of key architectural components, including the Adaptive Time-Mixing Operator, Cross-Variable Attention mechanism, and multi-path integration strategy. This rigorous evaluation framework demonstrates the superiority of MP-RWKV in capturing complex temporal and cross-variable dependencies while providing insights into the model’s interpretability and the effectiveness of its architectural enhancements.
4.1. Dataset Description
4.1.1. Data Collection
The dataset comprises power consumption measurements from three distinct regions (Quads, Smir, and Boussafou) in the urban power distribution network of Tetouan, Morocco. Data collection was conducted throughout 2017, resulting in 52,416 samples with a granularity of 10-minute intervals.
4.1.2. Feature Composition
Each data point consists of nine features:
Meteorological Variables
Temperature ();
Relative Humidity ();
Wind Speed ().
Temporal Indicators
Hour of Day ();
Day of Week ();
Month ().
Power Generation
Region 1 Power Load ();
Region 2 Power Load ();
Region 3 Power Load () - Target Variable.
4.1.3. Data Characteristics
The dataset exhibits the following properties:
Temporal coverage: 365 days;
Sampling frequency: 144 samples per day;
Total duration: 8736 h;
Missing values: <0.1%;
Data range: Normalized to [0,1] for each feature.
Figure 3 presents the statistical characteristics of weather factors and power consumption across the three monitored regions, providing insights into the data distribution and seasonal patterns.
4.2. Baseline Models for Comparison
We evaluate our proposed model against several state-of-the-art architectures specialized in time series forecasting:
Advanced Neural Architectures
RWKV-TS [
15]: The foundation model upon which our enhanced MP-RWKV is built, featuring efficient recurrent computation with the ability to handle long sequences.
Transformer [
16]: The canonical attention-based architecture that revolutionized sequential modeling. Recent studies have demonstrated its effectiveness in Long-Sequence Time Series Forecasting (LSTF).
Autoformer [
17]: A Transformer-based model incorporating decomposition blocks to explicitly model seasonal–temporal patterns, specifically designed for long-horizon forecasting.
Informer [
18]: An enhanced Transformer variant optimized for long-term sequence prediction, featuring improved computational efficiency through sparse attention mechanisms.
Reformer [
19]: A memory-efficient variant utilizing locality-sensitive hashing for attention computation, achieving
complexity while maintaining comparable performance.
LSTM [
20]: A foundational recurrent architecture that addresses gradient instability through gating mechanisms, enabling effective modeling of long-term dependencies.
4.3. Evaluation Metrics
Model performance is evaluated using two standard metrics: Mean Absolute Error (MAE) and mean-squared error (MSE). Let denote the ground truth values and denote the model predictions.
4.3.1. Mean Absolute Error
MAE measures the average magnitude of prediction errors:
where
n represents the number of prediction points.
4.3.2. Mean-Squared Error
MSE quantifies the average squared deviation of predictions:
These metrics provide complementary perspectives on model performance:
MAE offers an interpretable measure of prediction accuracy in the original scale
MSE penalizes larger errors more heavily, making it particularly sensitive to outliers
For both metrics, lower values indicate better performance. The statistical significance of performance differences is assessed through paired t-tests with .
4.4. Short-Term Forecasting Results
Table 2 presents the performance comparison of different models on short-term power load forecasting tasks using 48 h of input data to predict power loads at various horizons from 24 h to 120 h.
Figure 4 shows the MAE performance of the selected models using 48 h of data to predict power loads at various horizons. In short-term forecasting scenarios, the MP-RWKV model demonstrates superior performance compared to other models, indicating that preserving past information through context states is crucial for effective prediction. The RWKV-TS model, which also utilizes a similar mechanism, shows comparable performance, highlighting the effectiveness of this approach. Notably, our enhanced MP-RWKV consistently outperforms the base RWKV-TS model, demonstrating the value of parallel processing paths for handling temporal patterns and cross-variable relationships simultaneously.
4.5. Long-Term Forecasting Results
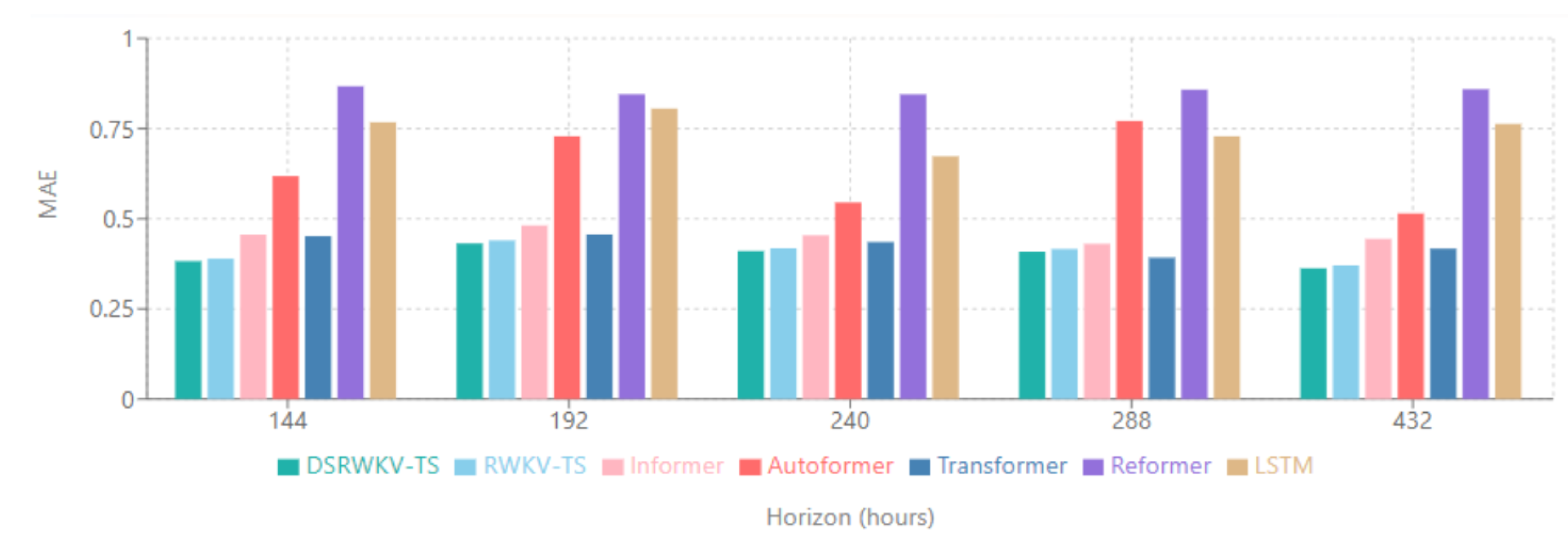
Table 3 presents the performance comparison for long-term forecasting scenarios, where models use 8 h of input data to predict power loads at extended horizons from 144 h to 432 h.
Figure 5 presents the long-term forecasting results showing MAE performance when using 8 h of data to predict power loads at horizons ranging from 144 h to 432 h. In these extended prediction scenarios, traditional Transformer-based models (Informer, Autoformer, and Reformer) show significant performance deterioration as the prediction horizon increases. The MP-RWKV model maintains consistent performance even over extended forecasting periods, demonstrating its robustness through parallel processing paths, adaptive fusion mechanisms, and position-aware attention that effectively capture both short-term patterns and long-term dependencies.
The experimental results demonstrate that MP-RWKV consistently outperforms the base RWKV-TS model across all long-term forecasting horizons, with the performance gap increasing at more extended prediction ranges. This indicates that the parallel pathway processing and adaptive integration of temporal and cross-variable information become increasingly beneficial as the forecasting horizon extends. While the base LSTM model shows declining accuracy as the prediction horizon increases due to gradient vanishing issues, the MP-RWKV model maintains stable performance across all tested scenarios.
5. Conclusions
This paper introduces MP-RWKV, an enhanced model that builds upon RWKV-TS to address the limitations of existing approaches in time series forecasting, particularly for power load prediction. Through our comprehensive experimental analysis, we demonstrate that MP-RWKV consistently outperforms other state-of-the-art models across both short-term and long-term forecasting horizons.
The experimental results show that MP-RWKV achieves superior performance in short-term forecasting scenarios, effectively capturing temporal patterns through its context state mechanism. In long-term forecasting, while traditional models like LSTM suffer from gradient vanishing and Transformer-based models show deteriorating performance, MP-RWKV maintains consistent accuracy even at extended prediction horizons, demonstrating its robust handling of temporal dependencies.
The key findings from our experiments include
MP-RWKV demonstrates consistently lower MAE values compared to baseline models, including its predecessor RWKV-TS
The model maintains stable performance across different prediction horizons, from 24 h to 432 h
The parallel processing path approach effectively balances short-term pattern recognition with long-term dependency modeling
The adaptive fusion mechanism successfully integrates temporal and cross-variable information, leading to more robust predictions
Future research directions include
Extending the model to handle multi-variable forecasting scenarios with even more diverse data sources
Incorporating additional parallel processing paths for specialized handling of different data characteristics
Exploring applications in other domains requiring time series forecasting
Optimizing computational efficiency for real-world deployments
In conclusion, MP-RWKV represents a significant advancement in power load forecasting, building upon and enhancing the capabilities of RWKV-TS. Its consistent performance and versatility make it a promising solution for power system operations and planning, contributing to the development of more efficient and reliable smart grid technologies.
Author Contributions
Conceptualization, A.R. and A.T.; methodology, A.R.; software, A.R. and A.E.; validation, A.R., A.T. and M.A.; formal analysis, A.R.; investigation, A.R.; resources, A.T.; data curation, A.E.; writing—original draft preparation, A.R.; writing—review and editing, A.T. and M.A.; visualization, A.E.; supervision, A.T.; project administration, A.R. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are available upon request from the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Tang, L.; Wang, X.; Wang, X.; Shao, C.; Liu, S.; Tian, S. Long-term electricity consumption forecasting based on expert prediction and fuzzy Bayesian theory. Energy 2019, 167, 1144–1154. [Google Scholar] [CrossRef]
- Kim, T.Y.; Cho, S.B. Predicting the household power consumption using CNN-LSTM hybrid networks. In Intelligent Data Engineering and Automated Learning–IDEAL 2018: 19th International Conference, Madrid, Spain, November 21–23, 2018, Proceedings, Part I 19; Springer: Berlin/Heidelberg, Germany, 2018; pp. 481–490. [Google Scholar]
- Fan, D.; Sun, H.; Yao, J.; Zhang, K.; Yan, X.; Sun, Z. Well production forecasting based on ARIMA-LSTM model considering manual operations. Energy 2021, 220, 119708. [Google Scholar] [CrossRef]
- Ahmad, T.; Zhang, D.; Huang, C.; Zhang, H.; Dai, N.; Song, Y.; Chen, H. Artificial intelligence in sustainable energy industry: Status Quo, challenges and opportunities. J. Clean. Prod. 2021, 289, 125834. [Google Scholar] [CrossRef]
- Yu, C.; Li, Y.; Chen, Q.; Lai, X.; Zhao, L. Matrix-based wavelet transformation embedded in recurrent neural networks for wind speed prediction. Appl. Energy 2022, 324, 119692. [Google Scholar] [CrossRef]
- Nowicka-Zagrajek, J.; Weron, R. Modeling electricity loads in California: ARMA models with hyperbolic noise. Signal Process. 2002, 82, 1903–1915. [Google Scholar] [CrossRef]
- Chen, X.; Jia, S.; Ding, L.; Xiang, Y. Reasoning over temporal knowledge graph with temporal consistency constraints. J. Intell. Fuzzy Syst. 2021, 40, 11941–11950. [Google Scholar] [CrossRef]
- Valipour, M.; Banihabib, M.E.; Behbahani, S.M.R. Comparison of the ARMA, ARIMA, and the autoregressive artificial neural network models in forecasting the monthly inflow of Dez dam reservoir. J. Hydrol. 2013, 476, 433–441. [Google Scholar] [CrossRef]
- Divina, F.; Gilson, A.; Goméz-Vela, F.; García Torres, M.; Torres, J.F. Stacking ensemble learning for short-term electricity consumption forecasting. Energies 2018, 11, 949. [Google Scholar] [CrossRef]
- Gu, B.; Shen, H.; Lei, X.; Hu, H.; Liu, X. Forecasting and uncertainty analysis of day-ahead photovoltaic power using a novel forecasting method. Appl. Energy 2021, 299, 117291. [Google Scholar] [CrossRef]
- Wang, J.; Gao, J.; Wei, D. Electric load prediction based on a novel combined interval forecasting system. Appl. Energy 2022, 322, 119420. [Google Scholar] [CrossRef]
- Carpinteiro, O.A.S.; Leme, R.C.; de Souza, A.C.Z.; Pinheiro, C.A.M.; Moreira, E.M. Long-term load forecasting via a hierarchical neural model with time integrators. Electr. Power Syst. Res. 2007, 77, 371–378. [Google Scholar] [CrossRef]
- Eldeeb, E. Traffic Classification and Prediction, and Fast Uplink Grant Allocation for Machine Type Communications via Support Vector Machines and Long Short-Term Memory. Master’s Thesis, University of British Columbia, Vancouver, BC, Canada, 2020. [Google Scholar]
- Senjyu, T.; Yona, A.; Urasaki, N.; Funabashi, T. Application of recurrent neural network to long-term-ahead generating power forecasting for wind power generator. In Proceedings of the 2006 IEEE PES Power Systems Conference and Exposition, Atlanta, GA, USA, 29 October–1 November 2006; pp. 1260–1265. [Google Scholar]
- Hou, H.; Yu, F.R. RWKV-TS: Beyond traditional recurrent neural network for time series tasks. arXiv 2024, arXiv:2401.09093. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2017; pp. 5998–6008. [Google Scholar]
- Wu, H.; Xu, J.; Wang, J.; Long, M. Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2021; Volume 34, pp. 22419–22430. [Google Scholar]
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Li, J.; Xiong, H.; Zhang, W. Informer: Beyond efficient transformer for long sequence time-series forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence; AAAI Press: Palo Alto, CA, USA, 2021; Volume 35, pp. 11106–11115. [Google Scholar]
- Kitaev, N.; Kaiser, L.; Levskaya, A. Reformer: The efficient transformer. arXiv 2020, arXiv:2001.04451. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}