1. Introduction
With the rapid expansion of global trade networks, coffee production and consumption have increased, indirectly influencing modern lifestyles. Moreover, with the growing emphasis on sustainability, fair trade, and specialty coffee, consumers are increasingly focused on the flavor, quality, and cultivation and processing methods of coffee, pursuing higher-quality products. However, the current coffee production process requires a significant amount of labor, especially in coffee bean selection and processing, which makes the quality of coffee beans susceptible to subjective judgment, leading to inconsistent coffee bean quality. To address this issue, the coffee industry has adopted automation technology and intelligent systems to improve production efficiency and ensure consistent coffee bean quality. Although these systems effectively reduce labor costs, their relatively high expenses make widespread adoption challenging.
With recent advancements in artificial intelligence (AI) technology, many researchers have integrated AI with traditional computer vision (CV) techniques to significantly improve performance and increase the accuracy of coffee bean recognition. Wang et al. [
1] proposed a lightweight convolutional model based on depthwise separable convolution (DSC) to detect coffee bean defects. To further improve the model’s performance, they enhanced the model’s recognition ability through knowledge distillation (KD). Then, the model maintained high accuracy and significantly reduced the number of parameters. However, the method requires pre-training with a larger model before applying lightweight model architecture of KD, which increases the computational cost and complicates the training process. Ke et al. [
2] proposed a model composed of convolutional layers, DSC, and pooling layers for coffee bean defect detection. Although the method enhanced the model’s recognition ability through data augmentation methods such as random cropping and random rotation, data augmentation methods are difficult to use in maintaining coffee bean quality, hindering the model’s performance. Hsia et al. [
3] proposed a lightweight deep convolutional neural network (LDCNN) that incorporated DSC, squeeze-and-excite blocks, and residual blocks for coffee bean defect detection. To mitigate the impact of fewer parameters, the method utilized the rectified Adam, lookahead, and gradient centralization methods for model training. Although the LDCNN model showed a high accuracy of 98.38%, it could not capture long-range dependencies (LRDs) with a limited overall accuracy. Considering such results, we developed a lightweight vision transformer (ViT) method based on depthwise pooling blocks (DWP) to extract global features from coffee bean images for defect detection and roasting level classification. The new method effectively reduces the cost of the coffee production process.
2. Method
2.1. Overall Architecture
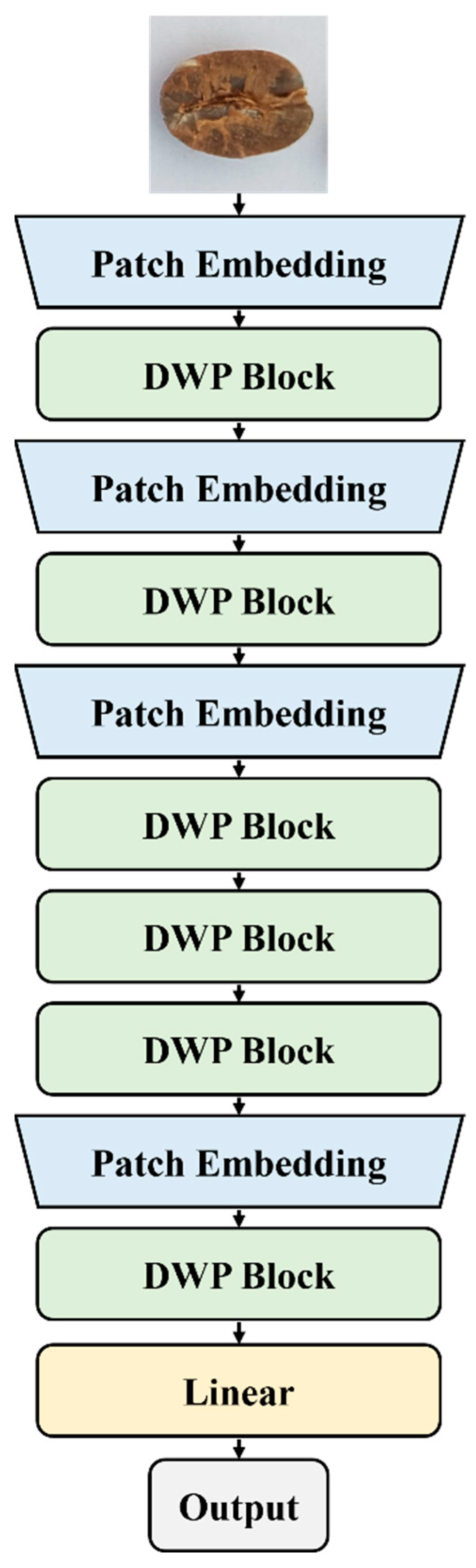
To effectively extract the appearance and structural features from coffee beans, we introduced a lightweight ViT based on DWP blocks to capture global features from coffee bean images (
Figure 1). The model included a convolutional layer in the patch embedding to aggregate local features of the coffee bean image and divide it into patches. The model omitted redundant features and simplified the computational complexity. By employing DWP blocks, the model enabled interactions between patches and extracted discriminative global features for subsequent coffee bean defect detection and roasting level classification. Finally, the model reduced the size of the coffee bean feature map by repeating its operations and distilled key features from the spatial dimension to the channel dimension.
2.2. Depthwise Pooling Block
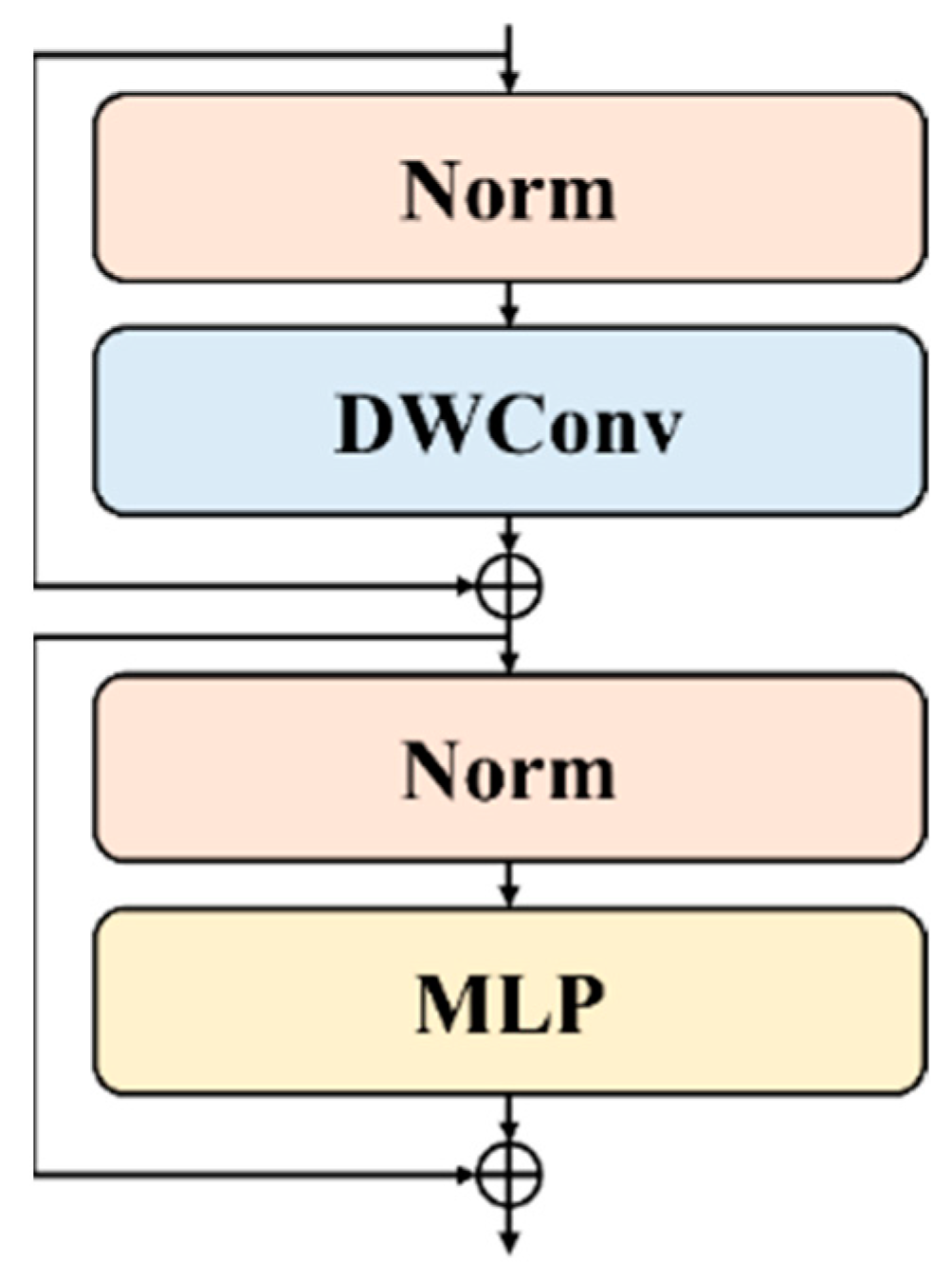
The DWP block was used in this study to replace the traditional self-attention mechanism with depthwise convolution (DWConv) (
Figure 2). The ViT’s attention mechanism was enabled to effectively extract global features from coffee bean images while reducing its parameters and computational complexity. The DWP block adopted layer normalization (LN) to normalize the input feature map and unified the scale of the input features, reducing the internal covariate shift in the ViT model and improving the stability of model training. Then, DWConv was used to fuse adjacent patches for efficient feature aggregation and improve the performance of the model. Finally, the block added the coffee bean feature map extracted by DWConv to the original feature map and utilized LN and a multi-layer perceptron (MLP) to interact with the channels of the coffee bean feature map. The model’s feature representation ability was enhanced for coffee bean recognition.
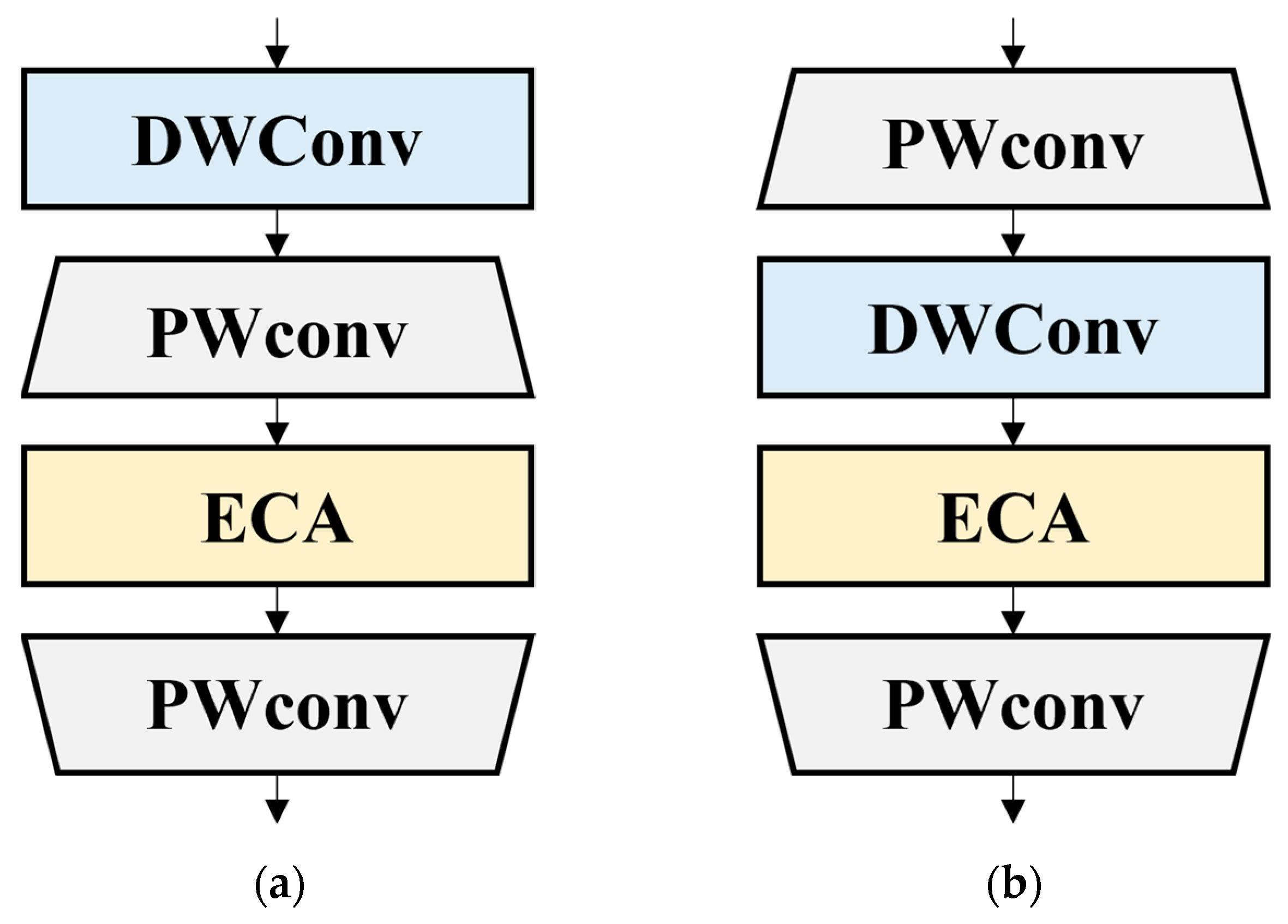
To investigate the impact of the MLP architecture on the performance of the model, two derived MLP architectures were used for comparative analysis, DPP-MLP and PDP-MLP (
Figure 3a,b). The DPP-MLP architecture included DWConv to independently extract and transform the spatial features of each channel, thereby enhancing the spatial information of the coffee bean feature maps. Subsequently, the architecture expanded the channel dimensions of the coffee bean feature maps using pointwise convolution (PWConv) and efficient channel attention (ECA) [
4] to learn the importance of the channel features within the expanded feature maps. Finally, the channel dimensions of the coffee bean feature maps were reduced to their original size to learn feature representations in a high-dimensional feature space. In contrast, the PDP-MLP architecture increased the channel dimension of the coffee bean feature maps through PWConv, using DWConv and ECA in the high-dimensional space. Then, the spatial and channel information was learned by the model to fully capture robust and rich coffee bean feature maps. Finally, the architecture maps were constructed on their original channel dimension using PWConv.
3. Results and Discussions
3.1. Coffee Bean Database
To evaluate the recognition and generalization abilities of the developed coffee bean recognition model, we used the Coffee Cobra [
5] and Roasting Coffee Bean [
6] public databases.
3.1.1. The Coffee Cobra Database [5]
This database contains 4626 coffee bean images captured under the same lighting conditions and classifies them into good and bad coffee beans based on their color and shape. Among these, 2149 images are of good coffee beans, while the remaining 2477 are of bad coffee beans.
3.1.2. The Roasting Coffee Bean Database [6]
This database includes 4800 coffee bean images captured under the same lighting conditions at four roasting levels determined based on the condition of the beans: green, light, medium, and dark. Each category contains 1200 images, allowing the model to effectively classify coffee beans at different roasting levels.
To effectively evaluate the model’s accuracy on the aforementioned databases, we split the data into training, validation, and test datasets with sample sizes of different classes, ensuring that each dataset maintained the same class distribution. Specifically, the sample size ratio for the training, validation, and test datasets in the Coffee Cobra database was 8:1:1, while that in the Roasting Coffee Bean database was 6:2:2.
3.2. Experimental Setup
In this study, the image size was set to 112 pixels, the batch size to 32, and the number of epochs to 200. AdamW was selected as the optimizer, with an initial learning rate of 0.002 and a weight decay of 0.002. The model was trained using PyTorch 2.2 on an nVIDIA RTX 3080 Ti graphic processing unit (GPU).
3.3. Results
To investigate the impact of the proposed MLP architecture variants on the developed model, the Coffee Cobra dataset was used (
Table 1). The PDP-MLP architecture extracted spatial information with an increased number of parameters but decreased the model’s accuracy when using an expanded channel dimension and DWConv. The PDP-MLP architecture was more prone to overfitting the feature distribution than the DPP-MLP architecture when trained on a dataset with noisy labels. The PDP-MLP architecture also reduced generalizability and hindered the effective learning of key coffee bean features. Therefore, we adopted the DPP-MLP architecture for extracting channel-wise features within the DWP block. This architecture improved the accuracy of the lightweight ViT model and allowed the model to avoid overfitting on databases with noisy labels, thereby enhancing its recognition ability.
To evaluate the overall performance of the coffee bean recognition model, we trained the model with the Coffee Cobra database. The developed lightweight ViT model significantly improved the performance, achieving a 98.49% accuracy with 0.13 M model parameters. The developed lightweight ViT model maintained a lower number of parameters but effectively detected coffee bean defects. It improved the accuracy by 0.11% and reduced the number of model parameters to less than 0.01 M compared to previous models, as shown in
Table 2.
To evaluate the robustness and generalization capabilities of the developed model, we compared the performance of the developed lightweight ViT model with existing models. The developed lightweight ViT model accurately identified the roasting level of coffee beans at an accuracy of 99.68% with only 0.13 M parameters (
Table 3). The model significantly reduced the number of parameters while maintaining high accuracy. The model decreased the number of parameters by 3.88 M and improved the accuracy by 0.65%.
4. Conclusions
To reduce the high labor costs in coffee bean selection and processing and ensure consistent coffee bean quality, a lightweight ViT model with an architecture based on the DWP block was developed. The developed DWP block enables the model to effectively capture global features from coffee bean images while significantly reducing the computational complexity of traditional ViT models. The developed method achieved recognition accuracies of 98.49 and 99.68% on the Coffee Cobra and Roasting Coffee Bean public databases, respectively, with 0.13 M model parameters. The developed model operates with fewer parameters but significantly improves accuracy compared with previous lightweight methods. The developed lightweight ViT model is feasible for real applications in coffee production.
Author Contributions
Conceptualization, L.-Y.K. and C.-H.H.; methodology, L.-Y.K.; software, L.-Y.K. and P.-F.L.; validation, L.-Y.K., P.-F.L. and C.-H.H.; formal analysis, L.-Y.K. and P.-F.L.; investigation, L.-Y.K.; resources, C.-H.H.; data curation, L.-Y.K.; writing—original draft preparation, L.-Y.K. and P.-F.L.; writing—review and editing, C.-H.H.; visualization, L.-Y.K. and P.-F.L.; supervision, C.-H.H.; project administration, C.-H.H.; funding acquisition, C.-H.H. All authors have read and agreed to the published version of the manuscript.
Funding
This work was partially supported by the Ministry of Science and Technology, Taiwan, under grant no. MOST 111-2221-E-197-020-MY3.
Institutional Review Board Statement
Not applicable. This study did not involve any humans or animals.
Informed Consent Statement
Not applicable. This study did not involve humans.
Data Availability Statement
This study did not report any data.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Wang, P.; Tseng, H.-W.; Chen, T.-C.; Hsia, C.-H. Deep convolutional neural network for coffee bean inspection. Sens. Mater. 2021, 33, 2299–2310. [Google Scholar] [CrossRef]
- Ke, L.-Y.; Chen, E.; Hsia, C.-H. Green coffee bean defect detection using shift-invariant features and non-local block. In Proceedings of the IEEE International Conference on Knowledge Innovation and Invention, Sapporo, Japan, 11–13 August 2023; pp. 430–431. [Google Scholar]
- Hsia, C.-H.; Lee, Y.-H.; Lai, C.-F. An explainable and lightweight deep convolutional neural network for quality detection of green coffee beans. Appl. Sci. 2022, 12, 10966. [Google Scholar] [CrossRef]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Coffee Cobra: Coffee Bean Dataset. Available online: https://github.com/chirag-jhamb/coffee_bean_quality_recognizer (accessed on 12 March 2024).
- Hassan, E. Enhancing coffee bean classification: A comparative analysis of pre-trained deep learning models. Neural Comput. Appl. 2024, 36, 9023–9052. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Maaten, L.v.D.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019. [Google Scholar]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).





{kind=link}
{kind=link}
{kind=link}