1. Introduction
Due to the impact of the COVID-19 pandemic, remote work and virtual meetings have become a trend. In a zero-trust network environment, the security of voice conferencing systems has become important. However, given the properties of network packets, they can easily be intercepted and recorded, necessitating packet encryption. End-to-end encryption is a mature and reliable method, where encryption and decryption are performed on the user’s device, and the server does not participate in any encryption or decryption. This ensures that only the communicating parties can decrypt and access the content, reducing the risk of communication content being leaked at any stage of the network (including intermediate servers), thereby securing the data during transmission. In this study, we implemented a voice conferencing solution that supports end-to-end encryption and is applicable in low-bandwidth network environments.
The remainder of this article is organized as follows. The
Section 2 describes homomorphic encryption for voice conferences and presents the findings from that process. The
Section 3 presents the end-to-end encrypted voice conferencing system we designed and developed, based on terminal-side voice mixing, which ensures security and is applicable in low-bandwidth networks. The
Section 4 provides the actual bandwidth measurements required for terminal-side voice mixing. Finally, the fifth chapter concludes the study.
2. Homomorphic Encryption
To achieve end-to-end voice encryption and mixing, we used the Paillier homomorphic encryption algorithm, a mature and easily implemented method available today [
1]. By utilizing its additive homomorphic properties in combination with mixing algorithms [
2], we performed ciphertext mixing. The plaintext for homomorphic encryption must be a positive integer, and there are limitations on the maximum length of plaintext encrypted. Therefore, we employed a value-shifting method to convert the voice data to positive integers and utilized the big integer library for preprocessing the voice data. This simplified complex bit operations and enabled reaching the maximum encryption plaintext length. We successfully solved the issue of signed operations encountered during the mixing process, thereby completing the homomorphic encryption-based end-to-end encrypted mixing function.
2.1. Sample Value Shifting Method
Voice data are composed of a series of samples, where the bit depth of samples is set by the microphone. Common sample bit depths include 8 and 16 bits, with values ranging from −128 to 127 and −32,768 to 32,767, respectively. Due to the signed operations involved in the additive mixing of individual samples, the resulting mixed sample values can be negative. However, in the next step, the voice samples are concatenated into a big integer format of the big integer library. If any sample is negative, the big integer format cannot represent the negative values of the internal samples. Furthermore, the additive homomorphic property of the Paillier encryption algorithm does not apply to negative numbers. Therefore, a value-shifting method is necessary to address the negative number issue. The process is described as follows.
Shift the sample value according to its n-bit length by adding (where n is the bit depth of a sample), making the range between 0 and a positive integer. For example, if the sample is 8 bits, add to shift the sample value range from −128 to 127 upwards to 0 to 255.
After completing step 1 for each sample, each sample is concatenated into a big integer format to perform the big integer format mixing, as detailed in the next section.
After the mixing of each audio track using the big integer format mixing method, the result of each sample is shifted down by subtracting (where k is the number of mixed audio tracks) to restore each sample to its original range.
For example, suppose that there are two audio tracks, Track A and B, each containing one sample (8 bits) (i.e., sample1 from Track A and sample 2 from Track B). After shifting each sample upward in step 1, the values are transformed into sample1 + , sample2 + , respectively. These are then additively mixed to obtain the mixed result sample3′ = sample1 + + sample2 + . Finally, according to step 3, sample3′ is shifted downward to yield the final mixed sample sample3 = sample3′ − × 2.
2.2. Big Integer-Based Mixing Method
In the next step, the homomorphic encryption algorithm is employed. To ensure that the audio plaintext length matches the maximum length for encryption and achieves maximum encryption efficiency, we concatenated each sample of the audio track as follows.
2.2.1. Segmentation and Overflow Buffering
Each audio track is segmented based on a specific number of samples, resulting in multiple segments with an equal number of samples.
At the beginning of each sample within an audio segment, a few bits (determined by floor(log2(k)), where k is the number of mixed tracks) are added as overflow buffer codes. This is to handle potential overflow issues during subsequent mixing.
Finally, each audio segment is stored as a big integer.
2.2.2. Big Integer-Based Mixing
Unlike traditional additive mixing, where individual samples from different tracks are added pairwise, the big integer-based mixing method developed in this study involves directly adding a big integer of audio segment that is composed of a sequence of samples, with the corresponding big integers of audio segments from other tracks.
This approach significantly reduces the implementation complexity and utilizes the carry representation provided by big integer libraries, making bitwise operations more readable and manageable.
2.2.3. Homomorphic Encryption and Mixing
The additive homomorphism property of the Paillier homomorphic encryption algorithm allows numerical addition to be performed on encrypted data.
For instance, consider two plaintext numbers, 100 and 200. After applying homomorphic encryption, they become E(100) and E(200). When these encrypted values are combined using additive homomorphism, the result is the ciphertext E(300). Decrypting this ciphertext yields the sum of the original plaintexts, which is 300.
Utilizing this property enables the mixing of audio data while these remain encrypted, eliminating the need to decrypt before mixing.
Figure 1 illustrates the process of obtaining mixed audio information after the user’s voice data undergo the aforementioned steps. The operation of the homomorphic encryption mixing algorithm is revealed too.
As shown in
Figure 1, the voice data of Alice, Bob, and John are captured by their microphones and converted into digital signals composed of three eight-bit samples. For example, Alice’s digital signal is [11110110, 00000110, 00011110]. Using Alice, the process is presented as follows.
2.3. Sample Value Shifting Method
Each of Alice’s three samples is adjusted using the sample value shifting method. Specifically, 128 is added to each sample (since ), ensuring that the sample values fall within the range of 0 to 255. After the adjustment, Alice’s three samples become 118, 134, and 158.
2.4. Overflow Buffer and Large Integer Conversion
To prevent overflow during the subsequent mixing process, each sample is prefixed with a 1-bit overflow buffer code, calculated as floor() = 1 bit. This step is crucial for the big integer conversion.
The adjusted samples are then concatenated into a single big integer, resulting in 1110110010000110010011110.
2.5. Homomorphic Encryption
This big integer is then encrypted using homomorphic encryption, generating the ciphertext E(1110110010000110010011110).
2.6. Processing Other Users
The same process is applied to Bob and John’s audio data, resulting in their respective encrypted voice data, which are then transmitted to the server, as shown in
Figure 2.
2.7. Homomorphic Mixing
Once the server receives the encrypted data from all three users, it performs an additive homomorphic operation to combine the ciphertexts. This results in the mixed encrypted audio data E(110110100110011100100111101).
2.8. Decryption and Audio Reconstruction
The server then transmits the mixed ciphertext back to all users, where it is decrypted into plaintext audio data 110110100110011100100111101 in the user’s devices. The decrypted big integer is segmented back into individual samples based on the bit length of each sample, including the overflow buffer code. The result is [110110100, 110011100, 100111101].
2.9. Sample Value Restoration
Finally, each sample undergoes a downward shift of 384 to restore the original sample values. The resulting mixed audio values are [52, 28, −67], which can then be played back as the mixed audio result.
This process demonstrates how homomorphic encryption and the big integer mixing method securely and efficiently mix audio data while preserving its integrity. In network communication, the commonly accepted standard for audio quality is based on the G711 codec, which uses a sample rate of 8 kHz and a bit depth of 8 bits. The sample rate represents the number of audio samples transmitted per second, while the bit depth indicates the number of bits per sample. Consequently, the bitrate, which is the amount of data transmitted per second, is calculated as Bitrate = 8000 (samples/second) × 8 (bits/sample) = 64 Kbps.
In this study, we used a homomorphic encryption mixing algorithm on three iPhones (iPhone 11, 13, and 14) to encrypt and mix audio calls. By observing the relationship between the length of the homomorphic encryption key and the resulting bitrate of the mixed plaintext, the following was observed.
When the encryption key length is 512 bits, the bitrate reaches its maximum value of 36.8 Kbps.
Although a longer encryption key allows for the encryption of longer plaintexts, it also requires more time to complete the encryption process, resulting in a lower bitrate.
Conversely, shorter encryption keys take less time to encrypt but also encrypt shorter plaintexts, leading to a decrease in bitrate.
Thus, under different key lengths of 256, 512, and 1024 bits, the 512-bit key length enables the highest bit rate. However, the experiment’s results did not meet the commonly accepted network communication quality standard, where a bitrate of 64 Kbps is typical. This difference indicates that the audio cannot be played back correctly at this bitrate (
Table 1).
To address this, we reduced the sample rate to 2.66 kHz to play the audio back. However, lowering the sample rate results in a significant loss of audio quality, leading to distortion. The results of this adjustment were insufficient and were not appropriate for the multi-bandwidth end-to-end encrypted mixing conference scenarios described in this article.
3. Terminal-Side Mixing Technology
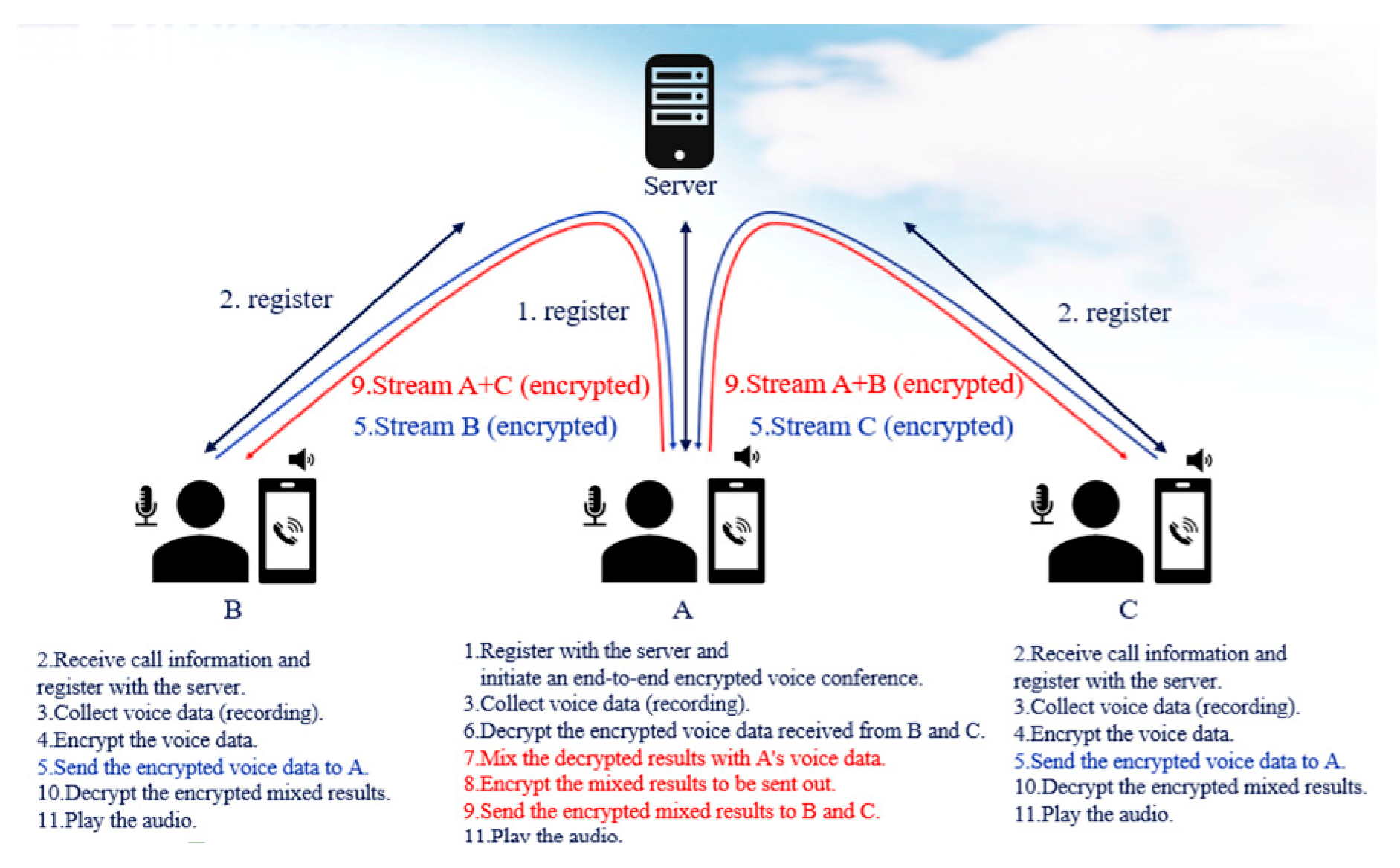
The homomorphic encryption method requires encrypting the original voice data to transmit the ciphertext to the server using homomorphic addition to directly mix the encrypted voice data on the server. The mixed result is then sent back to each mobile terminal for decryption and playback. Although this algorithm mixes encrypted voice data without a need to decrypt these on the server, it necessitates the transmission of the original voice data, which imposes a heavy burden on the mobile CPU and requires significant time for encryption and decryption. Additionally, the large amount of data processing reduces the audio sampling rate. During a meeting, all terminals must re-exchange keys to add a new member, which disrupts the meeting. In contrast, end-to-end encryption technology combined with terminal-side mixing technology allows the mobile terminal to encode the voice data to reduce its size before mixing and encrypting the encoded voice data. The ciphertext is then transmitted to the server, which forwards it to each mobile terminal for decryption and playback (
Figure 3).
This method secures communications for all terminals through end-to-end encryption and adjusts the mixing process, which originally required decryption on the server to the mobile terminal (
Figure 4).
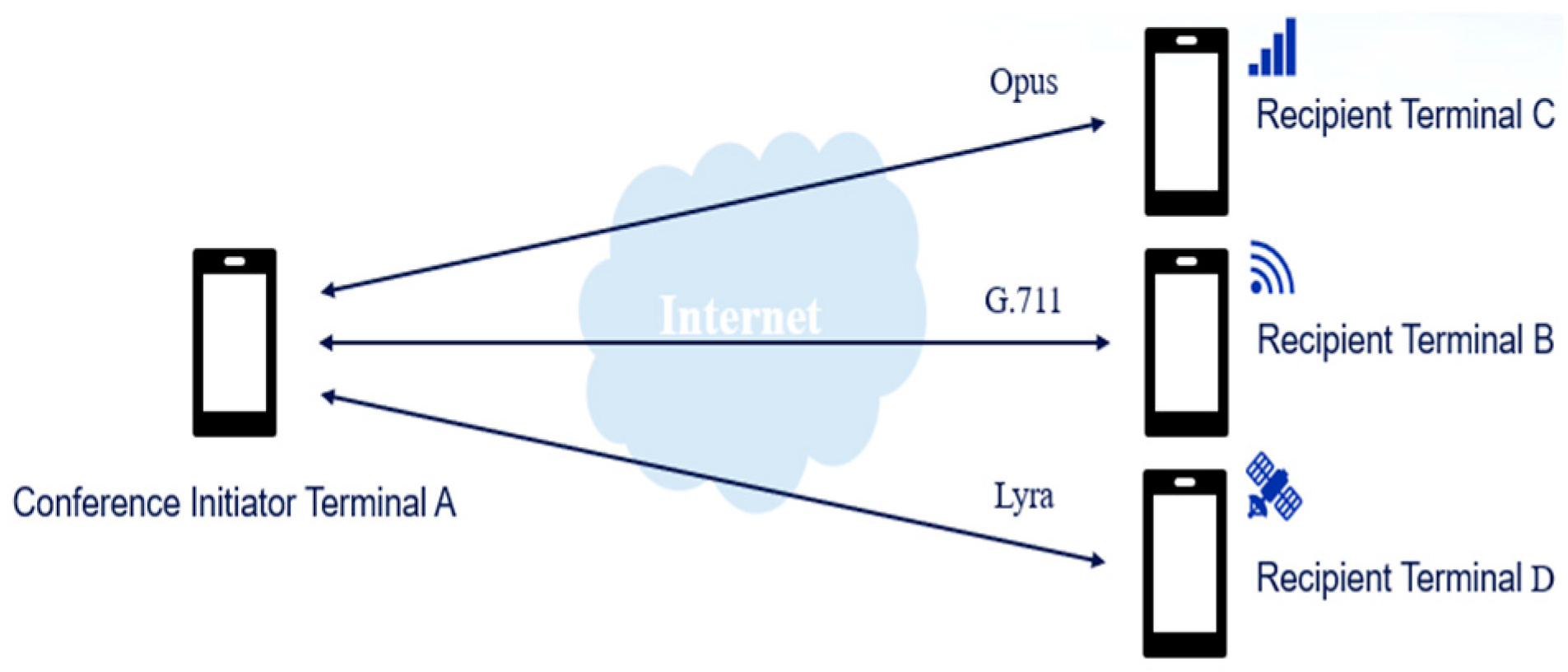
Voice data are transmitted using different encoding methods depending on the network environment (
Figure 5), enabling satellite calls even in the absence of mobile networks and Wi-Fi.
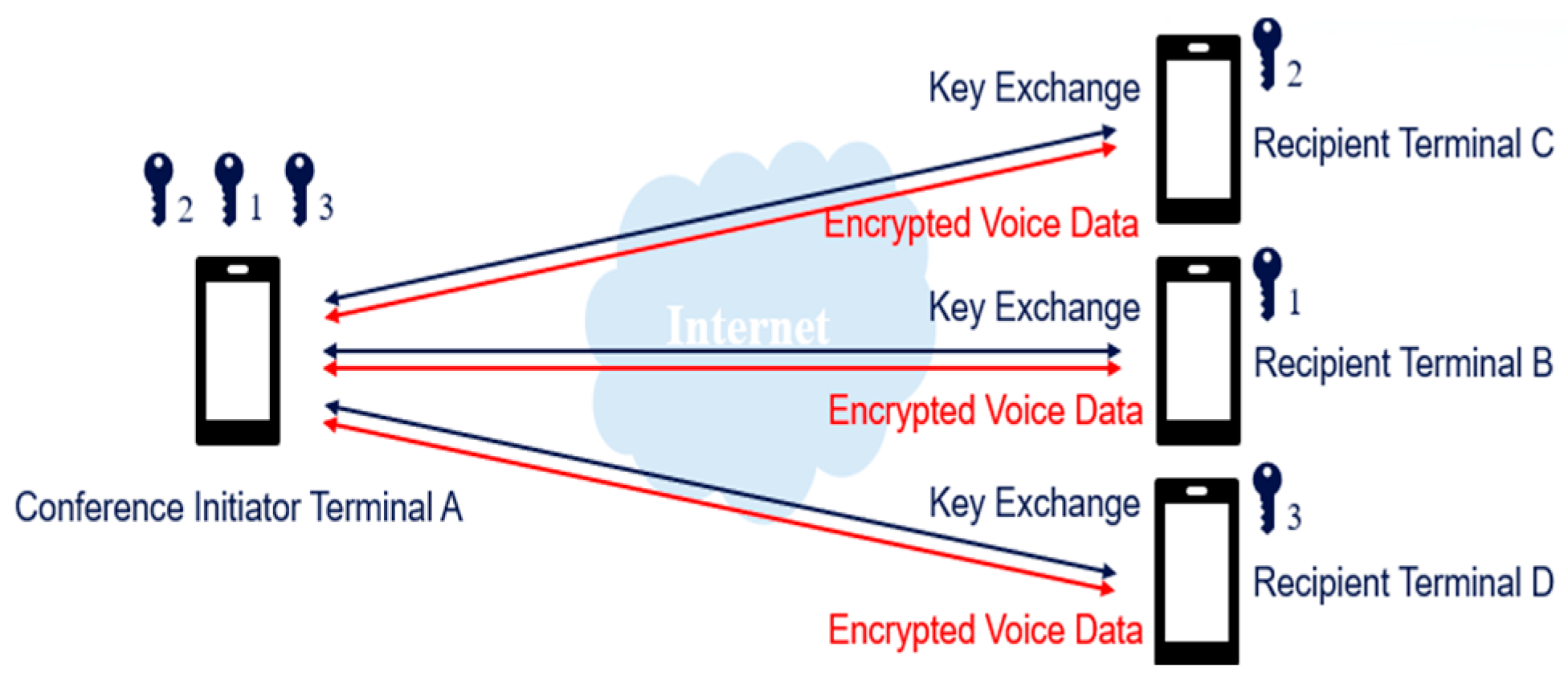
Since each mobile terminal and the conference-initiating terminal have different keys (
Figure 6), only the new member needs to perform the key exchange when joining a meeting in progress. This approach effectively handles and improves the issues arising from homomorphic encryption in group calls, creating a superior end-to-end group call environment.
The encrypted conference using terminal-side mixing technology is conducted in two stages. The first stage is the key exchange for end-to-end encryption, and the second stage is the encrypted voice conference with terminal-side mixing. In the key exchange stage, each terminal conducts key exchange with the conference-initiating terminal using the EC Diffie–Hellman (ECDH/DH) algorithm to obtain its independent encryption key. Since these encryption keys are independent, if a new member needs to join the meeting in progress, the new member only needs to perform a key exchange with the conference-initiating terminal, ensuring that the ongoing meeting is not disrupted.
In the encrypted voice conference with terminal-side mixing, the voice data collected by each terminal are encoded and compressed. The choice of encoding depends on the network environment. For example, Lyra delivers high-quality audio with low bandwidth in an environment with poor network conditions [
3]. G.711 offers low latency and low loss in VoIP environments [
4] and can be used in traditional telephony, while Opus provides excellent sound quality, stereo sound, wide bandwidth support, and low latency [
5,
6]. The encoded voice data are encrypted using the keys obtained during the key exchange stage, transmitted via user datagram protocol/real-time transport protocol (UDP/RTP) packets, and forwarded by the server to the conference-initiating terminal for decryption and mixing. The conference-initiating terminal then re-encrypts the mixed voice data according to each terminal’s encryption key and forwards these to each terminal via the server for decryption and playback. The conference-initiating terminal thus takes over the mixing task from the server, which is then only responsible for forwarding the voice data, achieving a truly end-to-end encrypted conference.
Compared with homomorphic encryption, terminal-side mixing technology enables the use of different voice encoding methods based on the network environment. In high-bandwidth networks, the G.711 or Opus encoding formats can be used, while in low-bandwidth environments such as satellite networks, the Lyra encoding is used as it requires extremely low bandwidth. This approach enables calls even without mobile networks and Wi-Fi, reducing the CPU load on mobile devices. Furthermore, since each mobile terminal and the conference-initiating terminal have different keys, only the new member needs to perform the key exchange when joining a meeting in progress. This effectively handles and improves the issues associated with homomorphic encryption in group calls, creating a superior end-to-end group calling environment.
4. Real-World Bandwidth Testing
The developed end-to-end group encryption workflow was validated using a self-developed multimedia server in conjunction with iOS terminal devices. The test scenario was conducted using an iPhone 11 with 64 GB of storage running OS 17. During the tests, all voice calls were encoded using the Opus codec. The test device served as the chairperson in the end-to-end group call, responsible for establishing communication with other meeting participants and mixing all voice data. We set the sampling rate to 8000 samples/second and the bit rate to 16,000 in normal conditions. When there were two participants in the meeting, network bandwidth for both incoming and outgoing data, as observed using Xcode tools, was 16.8 Kbps, with CPU usage at 5%. In low-bandwidth mode, we set the sampling rate to 2000 samples/second and the bit rate to 4096. With two participants, the bandwidth for both incoming and outgoing data was 7.2 Kbps, memory usage was 31 MB, and CPU usage remained at 5%. At this stage, the mixing mechanism was not yet engaged. When the number of participants increased to five, the results are summarized in
Table 2.
Each additional participant in the meeting increases the network bandwidth for incoming and outgoing data by 7.2 Kbps, memory usage by 3 MB, and CPU usage by 1%. Each new participant requires the chairperson to establish an additional channel for the new member. For 10 participants in the meeting, the network bandwidth for both incoming and outgoing data is 64.8 Kbps, memory usage is 55 MB, and CPU usage is 13%. These requirements must be satisfied with most commercially available mobile phones and networks when used with mobile or Wi-Fi networks. Any phone can act as the chairperson using the end-to-end group encryption developed. Those who are not the chairperson only need to satisfy a network bandwidth of 7.2 Kbps for both incoming and outgoing data. Considering that the high-orbit satellite network Thuraya provides a communication bandwidth of 16 Kbps or more, this is sufficient to meet communication needs.
5. Conclusions
We implemented end-to-end group mixing in this study. The original server-side mixing method using homomorphic encryption involved mixing the audio sent from each terminal on the server using homomorphic encryption and then forwarding the mixed audio to each terminal. The method presented three issues: (1) The audio encoding had to be unified as PCM; (2) key exchange took too long when adding new members; (3) terminal devices lacked sufficient performance for homomorphic decryption. To address these issues, we designed a terminal-side mixing mechanism, shifting the mixing process originally performed on the server using homomorphic encryption to the conference-initiating terminal. The developed mechanism uses different audio encoding methods depending on the network environment, enabling operation even in low-bandwidth satellite networks. Additionally, when new members join, key exchange is only required, reducing the complexity of key exchange and improving the overall communication experience. The application of end-to-end encryption technology with terminal-side mixing in voice conferencing significantly enhances security and usability as a new solution for secure communication.
Author Contributions
Conceptualization, C.-H.L. and J.-C.C.; methodology, Y.-C.T. and S.-L.L.; software, J.-C.C. and C.-Y.H.; validation, J.-J.J. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Paillier, P. Public-Key Cryptosystems Based on Composite Degree Residuosity Classes. In Advances in Cryptology—EUROCRYPT’99, Proceeding of the International Conference on the Theory and Application of Cryptographic Techniques, Prague, Czech Republic, 2–6 May 1999; Springer: Berlin/Heidelberg, Germany, 1999; pp. 223–238. [Google Scholar]
- Chandra, S.P.; Senthil, K.M.; Bala, M.P.P. Audio mixer for multi-party conferencing in VoIP. In Proceedings of the 2009 IEEE International Conference on Internet Multimedia Services Architecture and Applications (IMSAA), Bangalore, India, 9–11 December 2009; pp. 1–6. [Google Scholar] [CrossRef]
- Kleijn, W.B.; Storus, A.; Chinen, M.; Denton, T.; Lim, F.S.C.; Luebs, A.; Skoglund, J.; Yeh, H. Generative Speech Coding with Predictive Variance Regularization. In Proceedings of the ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021. [Google Scholar]
- Abou Haibeh, L.; Hakem, N.; Safia, O.A. Performance evaluation of VoIP calls over MANET for different voice codecs. In Proceedings of the 2017 IEEE 7th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 9–11 January 2017.
- Valin, J.-M.; Vos, K.; Terriberry, T. Definition of the Opus Audio Codec. RFC 6716, Internet Engineering Task Force, September 2012. Available online: https://www.rfc-editor.org/info/rfc6716 (accessed on 24 June 2024).
- Valin, J.-M.; Maxwell, G.; Terriberry, T.B.; Vos, K. High-quality, low-delay music coding in the opus codec. arXiv 2016, arXiv:1602.04845. [Google Scholar]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}