1. Introduction
With the rapid advancement of artificial intelligence (AI) technologies, deep learning has emerged for tackling complex tasks such as image and speech recognition. Specifically, in license plate recognition, efficient and accurate systems are essential. The automation of applications such as traffic management and parking lot monitoring is also required. Traditional license plate recognition systems rely on graphic processing units (GPUs) for high-speed data processing and deep learning models. While GPUs excel in parallel computation, their high power consumption and limited flexibility present significant challenges in embedded applications.
The field-programmable gate array (FPGA) is a promising alternative for AI computation in embedded systems due to its high performance, low power consumption, and configurability. By allowing for the hardware acceleration of neural network models customized for specific applications, FPGAs demonstrate enormous potential in applications that require low power and high efficiency. However, FPGAs lack the raw computational power of GPUs, which necessitates integrating ARM processors with FPGAs in embedded systems as an effective solution. The Zynq-7000 series SoC platform (AMD, Santa Clara, CA, USA) by Xilinx combines multi-core ARM processors with FPGA and offers an efficient framework for performing tasks such as license plate recognition.
This research aimed to develop an AI-based license plate recognition system on the Zynq-7000 SoC platform, combining FPGA’s low-power, high-efficiency hardware acceleration with the computational capability of ARM processors. The system employs image preprocessing and data augmentation techniques for training, followed by high-speed recognition on the FPGA, demonstrating its potential in smart city applications, intelligent transportation, and IoT environments.
2. Research Background
A literature review on deep neural networks (DNNs) and FPGA-based acceleration was conducted in this research, focusing on deep convolutional neural networks (DCNNs) for image recognition, FPGA’s parallel processing, and energy efficiency. By using the ARM Cortex-A9 processor on the Zynq-7000 SoC for image preprocessing and its FPGA for neural network execution, we created an efficient real-time recognition system.
DNNs are widely used in image recognition, natural language processing, and autonomous driving due to the mammalian visual system’s layered information processing. Popular DNN models include deep belief networks (DBNs), stacked autoencoders (SAEs), and DCNNs [
1].
FPGAs are increasingly used for deep learning due to their flexibility, parallelism, and efficiency in handling compute-intensive tasks, particularly in edge computing. Although they outperform computer processing units (CPUs) and GPUs in performance per watt, FPGAs face challenges in implementing large-scale models such as AlexNet due to memory and computational limitations. Model compression and reduced precision help address these challenges [
2]. FPGAs are ideal for DNN acceleration due to their parallelism and energy efficiency, especially for multiply-and-accumulate operations. Frameworks including Xilinx Vitis AI and FINN enable porting DNNs to FPGAs, although challenges remain with complex DNNs. FPGA system-on-chip (SoC) platforms enable a hybrid execution model where DNN inference is split between hardware and software, optimizing both performance and resource use by combining ARM-based processors and programmable logic [
3].
2.1. DNN
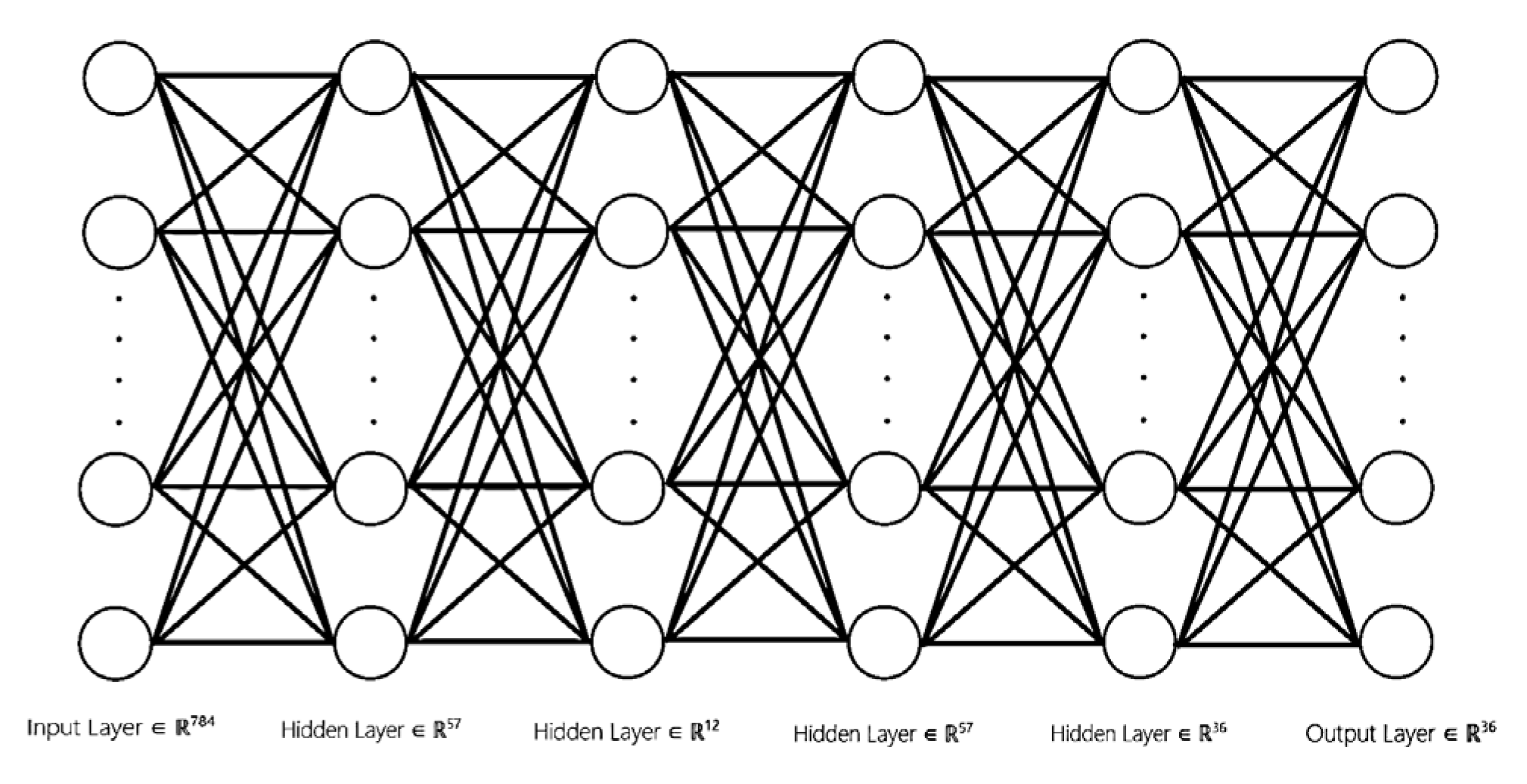
DNN is an artificial neural network architecture consisting of multiple layers of neurons, designed to simulate the learning and reasoning abilities of the human brain. DNNs are particularly well suited for solving complex pattern recognition and prediction problems, such as image recognition, speech recognition, and natural language processing, DNNs extract and learn high-level features from data through multiple hidden layers. The basic unit of a DNN is a neuron that receives input signals from neurons in the previous layer, processes them through an activation function, and passes the result to the next layer. A DNN typically consists of an input layer, hidden layers, and an output layer, as shown in
Figure 1. In training, DNNs use the backpropagation algorithm to update the weights and biases by propagating the error through the network and adjusting each weight to minimize the loss function, continuing until the network converges and the error is reduced to an acceptable level [
4].
Hyperparameters play a critical role in determining the performance of a DNN. These include learning rates, the number of neurons, and activation function choices, which cannot be learned directly from training data but need to be tuned through experimentation. Bayesian hyperparameter optimization is efficient in searching for optimal hyperparameters. It uses Bayesian statistical principles to infer the next potential optimal hyperparameter set based on prior search results, instead of exhaustively exploring all combinations. This method significantly reduces the search space and quickly finds near-optimal configurations, improving the efficiency of DNN training tasks that require substantial computational resources. In this study, Bayesian hyperparameter optimization was applied to optimize the architecture of the neural network, specifically adjusting the number of neurons in each layer and the learning rate to enhance recognition accuracy and computational efficiency.
The choice of activation function is crucial for DNN’s performance, as it introduces non-linearity into the network, allowing it to learn complex, non-linear mappings. Without activation functions, the network performs linear operations and reduces its effectiveness in capturing deeper data features. We compared the sigmoid and rectified linear unit (ReLU) activation functions. Sigmoid compresses input values between 0 and 1; it is appropriate for probability predictions and binary classification but suffers from the “vanishing gradient” problem, which slows training. On the other hand, ReLU is simple to compute and efficient for large datasets, but it causes “dead neurons” when inputs are negative. To mitigate this, leaky ReLU was introduced, allowing small gradients for negative inputs to avoid neuron inactivation. In this study, sigmoid and ReLU functions were compared to select the most appropriate activation function for the neural network.
2.2. FPGA
FPGA allows users to define its logic functions, making it ideal for hardware acceleration, embedded systems, and other high-performance computational tasks. Unlike application-specific integrated circuits (ASICs), FPGAs are highly configurable, enabling the flexible definition of logic based on application needs, thus making it a versatile hardware platform. FPGAs consist of multiple configurable logic blocks (CLBs), which are programmed using hardware description languages (HDL) such as Verilog or a very high- speed integrated circuit (VHDL) to implement specific logic circuits. Each logic block contains basic logic gates, flip-flops, and lookup tables (LUTs) to perform complex logical operations collectively. Additionally, FPGAs feature extensive programmable interconnects, allowing flexible connections between different logic units, all synchronized by clock signals.
A key advantage of the FPGA is its parallel computing capability, which significantly enhances computational efficiency. This makes the FPGA particularly well suited for tasks requiring high-speed processing and low latency, such as image processing, signal processing, and hardware-accelerated deep learning models. In this study, FPGA’s high-speed computing capability was utilized for license plate recognition. The neural network model was implemented in Verilog, enabling the digital circuit design to fully leverage the parallel processing advantages of FPGA to significantly improve the recognition speed. The trained neural network architecture was reflected in hardware circuits and deployed on the Zynq-7000 SoC platform for testing, achieving high-performance license plate recognition at the hardware level. Compared with software implementations, the developed system has high computation efficiency and provides low-latency recognition in real-time application scenarios.
2.3. Zynq-7000 SoC Platform and Zynet Library
The Zynq-7000 SoC from Xilinx is a highly integrated FPGA platform that combines an ARM processor with FPGA logic blocks and provides a powerful hardware–software co-processing environment. The core of the Zynq-7000 SoC consists of a dual-core ARM Cortex-A9 processor, which executes traditional processor instruction sets using the FPGA portion for highly customized parallel processing. This architecture makes the Zynq-7000 SoC ideal for applications such as image processing, machine learning, and digital signal processing with superior performance. The platform supports multiple hardware description languages and development tools, with Xilinx Vivado being a key tool for hardware design, simulation, and deployment. Developers transform their designs into hardware descriptions using these tools to compile and program on an FPGA for efficient hardware acceleration.
To further enhance the implementation of neural networks on FPGAs, the Zynet library was employed. Zynet is a Python library specifically designed for FPGA-accelerated neural network inference, helping developers efficiently apply trained neural network models into FPGA-based hardware designs. Zynet provides tools and interfaces to directly transform their neural network models into digital circuits on the FPGA, which is particularly beneficial for real-time image processing, object recognition, and embedded AI applications that require high computational efficiency. The advantage of Zynet lies in its ability to simplify the development process by automatically generating Verilog or VHDL code, reducing the developer’s need to manually write hardware description languages. Additionally, Zynet includes optimization techniques such as model compression and quantization to further improve FPGA computation efficiency [
5].
3. System Architecture
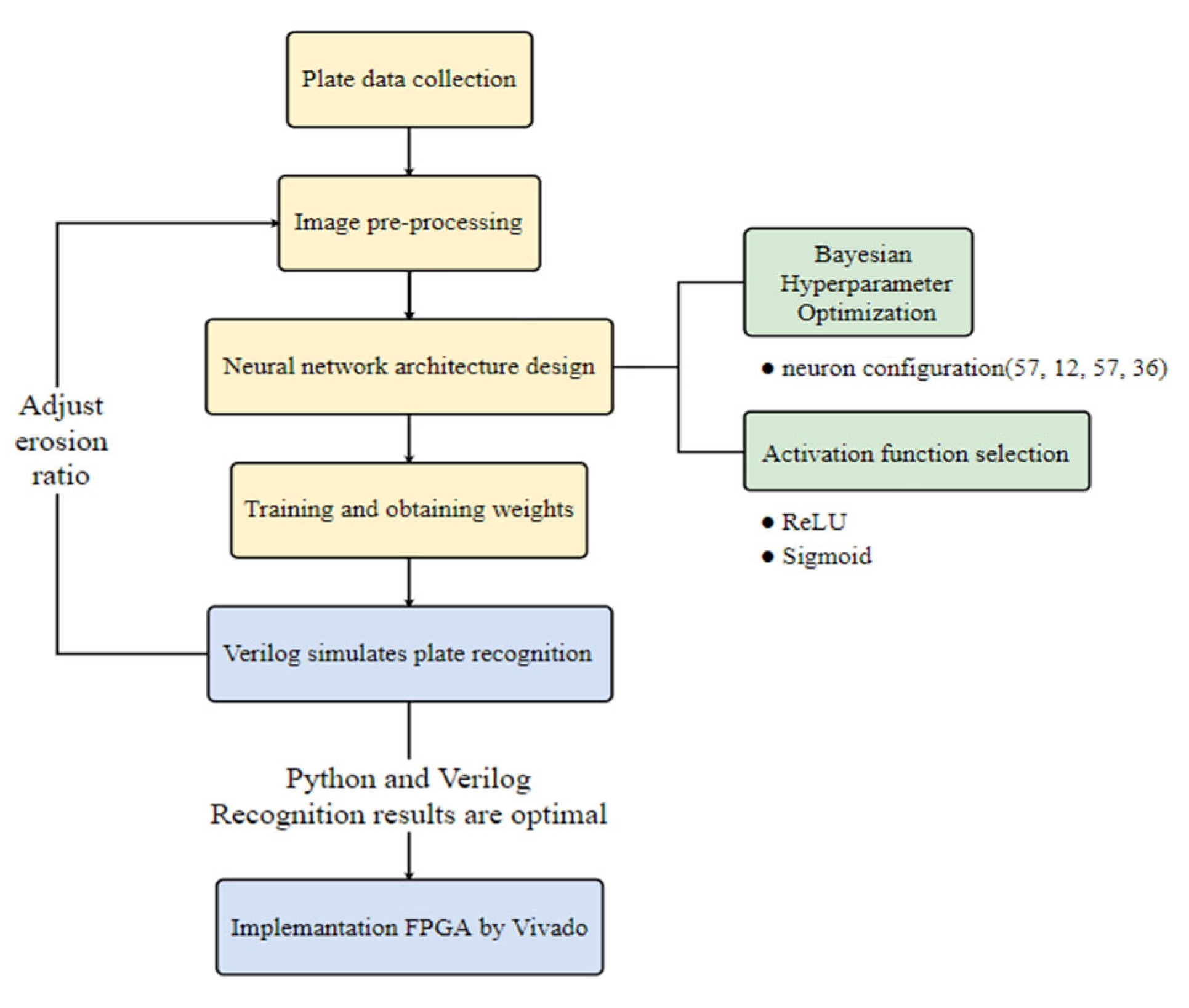
We performed license plate recognition using an FPGA and compared the recognition results of the hardware and software implementations.
3.1. Research Process
3.1.1. Data Collection and Image Preprocessing
Initially, license plate images were collected to ensure the diversity and representativeness of the training dataset. The collected license plate images were preprocessed using an ARM processor. The image preprocess included image cropping, color inversion, dilation, erosion, and grayscale conversion. These operations highlight the features of the license plate to create a high-quality training set for the subsequent neural network training.
3.1.2. Neural Network Architecture
A neural network architecture was designed specifically for license plate recognition. The processed image dataset was used to train the neural network. To improve the model’s performance, Bayesian hyperparameter optimization was employed to adjust the structure and training parameters of the neural network. The final configuration of the hidden layers was determined to be (57, 12, 57, 36) neurons. After 60 iterations of training, the neural network converged, resulting in stable weights and bias values.
3.1.3. FPGA Implementation and License Plate Recognition
After completing the neural network training, the neural network was implemented in digital circuits using Verilog. These digital circuits were embedded into FPGA, and the design was programmed onto the Zynq-7000 SoC development platform using Vivado v. 2024.1. Preprocessed license plate images were then input into FPGA for recognition to evaluate the hardware’s recognition performance and compare it to traditional software solutions.
The system architecture of this research is depicted in
Figure 2.
3.2. License Plates Model
3.2.1. Data Preprocessing
In data labeling, the letters on the license plate were converted into numeric labels, where the letter “A” was defined as 10, “B” as 11, and so forth, up to “Z”, defined as 35, while the digits 0–9 retained their original numeric values. A final dataset with 36 unique labels was created to distinguish each letter and digit on the license plates. For data collection, various license plate images were captured, and each number and letter was cropped and stored in the corresponding label folders. To improve recognition accuracy, the images underwent color inversion and grayscale conversion to simplify the data for the neural network. Subsequently, the processed images underwent edge detection through erosion, which enhanced the character edges on the license plates, highlighting the outlines of the letters and numbers. These operations ensured that the neural network could more effectively capture the key features of the license plate characters during training, as shown in
Figure 3.
A comparison of the images before and after erosion, using the digit “7” as an example, is illustrated in
Table 1.
3.2.2. Neural Network
After completing data preprocessing, the neural network model was constructed using Bayesian hyperparameter optimization. Bayesian optimization was applied to adjust the neural network structure and determine that the best configuration for the hidden layers was (57, 12, 57, 36) (
Figure 4). Then, the preprocessed license plate dataset was used to train the neural network. After 60 iterations, the network successfully learned the weights and biases, which formed the core of the neural network model.
Once training was completed, the Zynet library was used to convert the Python neural network model into Verilog code, further implementing the neural network architecture in FPGA hardware. The trained neural network could perform real-time operations through the hardware circuits on the FPGA platform.
3.2.3. Model Testing
After completing the training and hardware implementation of the neural network, the Python v. 3.11 model and the Verilog hardware model were tested to compare their efficiency and accuracy.
3.2.4. Python Model Testing
The Python neural network model was used to recognize the test set, which consisted of license plate images not previously seen by the model to avoid overfitting to the training data.
3.2.5. Verilog Model Testing
The test image data were then input into the Verilog model, which was implemented on the FPGA hardware platform. During testing, the hardware model’s recognition ability for the same test set was evaluated based on accuracy and efficiency.
4. Results and Discussion
The test results of the license plate recognition model were analyzed to determine the performance of hardware and software using efficiency and accuracy. By comparing the results of the Python software model and the Verilog hardware model, the advantages and disadvantages of each model on different computing platforms were explored.
4.1. Efficiency and Accuracy Testing
The same test set was used to compare the recognition efficiency and accuracy of the Python neural network model and the Verilog hardware model. The Python model showed a recognition accuracy of 91.67% on the test set, demonstrating the accuracy and stability of the software implementation. The model successfully recognized all the test data, even previously unseen data, indicating satisfactory generalization ability. The Verilog hardware model showed a recognition accuracy of 83.33% (
Table 2). Although the accuracy was lower than that of the software model, the hardware implementation had significantly higher operating efficiency, especially when processing large amounts of data. Due to the parallel computing capabilities of the FPGA, the hardware model recognized license plates at a much faster rate, which is important for real-time processing applications.
The model’s performance was tested under different levels of erosion. By comparing the results, the most appropriate dataset was selected for training, as shown in
Figure 5.
4.2. Zynq-7000 SoC Platform Deployment
After completing the hardware model design, the Verilog neural network model was successfully deployed on the Zynq-7000 SoC platform. Using Vivado software, the trained neural network weights and architecture were compiled and programmed onto Zynq-7000 SoC via FPGA programming tools. The Zynq-7000 SoC platform integrated an ARM processor with FPGA logic units, offering excellent computing power and flexibility. In this study, the ARM core was used for image preprocessing, while the FPGA was responsible for neural network recognition tasks. Through this platform deployment, the Zynq-7000 SoC effectively supported a neural-network-based license plate recognition system and demonstrated its potential for real-time applications. The system provides a solid foundation for further optimization of the hardware model in future studies.
5. Conclusions and Future Prospects
We successfully implemented a neural-network-based license plate recognition system on an FPGA and the Zynq-7000 SoC platform. We preprocessed license plate data using Python and trained a neural network model with high recognition accuracy. Subsequently, the neural network was implemented in Verilog as hardware architecture, programmed onto the FPGA, and used to perform license plate recognition at the hardware level. The Python model showed a recognition accuracy of 91.67%, while that of the Verilog hardware model reached 83.33%. Although the hardware model showed lower accuracy, significant advantages in computational efficiency were found, particularly in applications requiring large-scale real-time processing. The parallel computing capabilities of the FPGA provided a notable performance boost, indicating the immense potential of hardware technology for license plate recognition tasks, laying a solid foundation for future optimizations and applications. Using neural networks on FPGAs for license plate recognition is feasible and effective. By combining ARM processors for image preprocessing, the system balances processing and computation. The parallel nature of the hardware provides an efficient solution for meeting the demands of real-time applications.
Despite the promising results of the developed system, there is still room for further improvement in recognition accuracy and hardware performance. Although the FPGA efficiently performs parallel computing, it is necessary to improve the accuracy compared to the Python model and optimize the Verilog neural network architecture. Further adjustments are needed for network layers and neuron configurations, and additional hardware tests must be conducted to identify the optimal configuration. While the neural network structure used in this study effectively recognized license plates, deeper neural networks such as CNNs or other advanced architectures are required to improve recognition accuracy, particularly for more complex or blurry license plate images. In this study, the core technology of license plate recognition was developed, but, in the future, it is essential to integrate other systems such as traffic monitoring systems or parking management systems. To create a comprehensive intelligent transportation solution, the system must be tested on facial recognition or image classification tasks to expand its applications. Although the Zynq-7000 SoC provides sufficient computing power, it needs upgrading to higher-performance FPGA platforms, such as the Zynq Ultrascale+ or other advanced hardware to enhance computational speed and parallel processing capabilities. Then, larger-scale and higher-demand real-time applications can be developed.
In summary, the potential of FPGAs in neural-network-based license plate recognition was verified in this study. Ample opportunities exist for further exploration. As hardware technology advances and algorithms are optimized, the developed system will play a significant role in practical applications.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




