
An Improved Multi-Dimensional Data Reduction Using Information Gain and Feature Hashing Techniques †


Abstract
1. Introduction
2. Materials and Methods
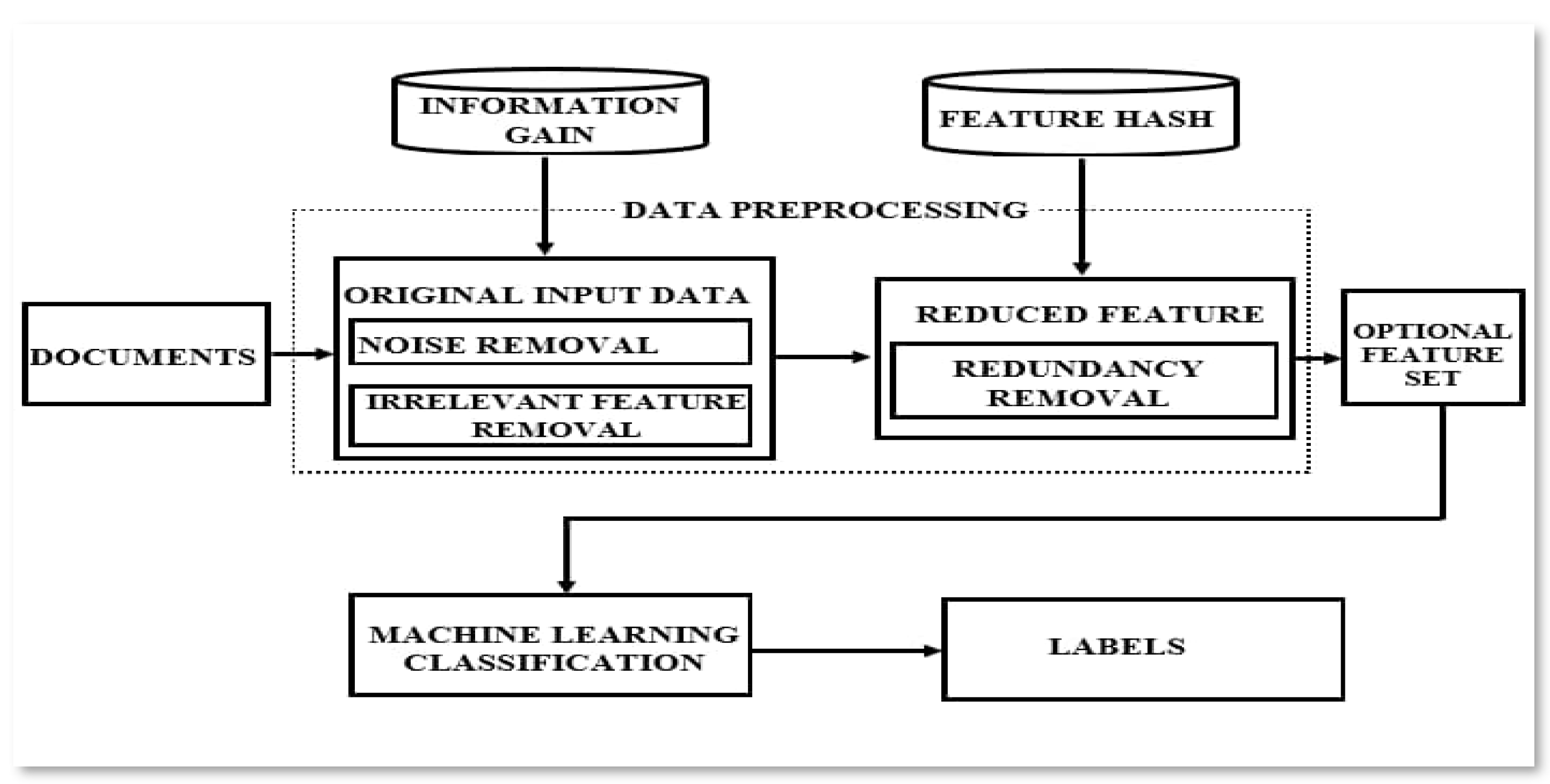
2.1. Proposed Framework of the Proposed Method
2.1.1. Information Gain on Movie Review
2.1.2. Feature Hashing on Movie Review
2.2. Dataset and Description
2.3. Classifiers
2.4. Feature Extraction
2.5. Evaluation Metrics
3. Result Discussion
4. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ahmad, S.R.; Rodzi, M.Z.M.; Shapiei, N.S.; Yusop, N.M.M.; Ismail, S. A review of feature selection and sentiment analysis techniques in issues of propaganda. Int. J. Adv. Comput. Sci. Appl. 2019, 10, 240–245. [Google Scholar] [CrossRef]
- Hamzah, M.B. Classification of Movie Review Sentiment Analysis Using Chi-Square and Multinomial Naïve Bayes with Adaptive Boosting. J. Adv. Inf. Syst. Technol. 2021, 3, 67–74. [Google Scholar] [CrossRef]
- Pratiwi, A.I.; Adiwijaya, K. On the feature selection and classification based on information gain for document sentiment analysis. Appl. Comput. Intell. Soft Comput. 2018, 2018, 1407817. [Google Scholar] [CrossRef]
- Maulana, R.; Rahayuningsih, P.A.; Irmayani, W.; Saputra, D.; Jayanti, W.E. Improved accuracy of sentiment analysis movie review using support vector machine based information gain. J. Phys. Conf. Ser. 2020, 1641, 12060. [Google Scholar] [CrossRef]
- Abubakar, A.; Mustafa, M.D.; Noor, A.S.; Aliyu, A. A New Feature Filtering Approach by Integrating IG and T-test Evaluation Metrics for Text Classification. Int. J. Adv. Comp. Sci. Appl. 2021, 12, 500–511. [Google Scholar] [CrossRef]
- Ahmad, I.S.; Bakar, A.A.; Yaakub, M.R. A review of feature selection in sentiment analysis using information gain and domain specific ontology. Int. J. Adv. Comput. Res. 2019, 9, 283–292. [Google Scholar] [CrossRef]
- Shi, Q.; Petterson, J.; Dror, G.; Langford, J.; Smola, A.; Vishwanathan, S. Hash kernels for structured data. J. Mach. Learn. Res. 2009, 10, 2615–2637. [Google Scholar]
- Weinberger, K.; Dasgupta, A.; Attenberg, J.; Langford, J.; Smola, A. Feature hashing for large scale multitask learning. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009. [Google Scholar]
- Ado, A. A new feature hashing approach based on term weight for dimensional reduction. In Proceedings of the 2021 International Congress of Advanced Technology and Engineering (ICOTEN), Taiz, Yemen, 4–5 July 2021. [Google Scholar]
- Gray, R.M. Entropy and Information Teory; Springer Science and Business Media: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Zhu, L.; Wang, G.; Zou, X. Improved information gain feature selection method for Chinese text classification based on word embedding. In Proceedings of the 6th International Conference on Software and Computer Applications, ACM International Conference Proceeding Series, Bangkok, Thailand, 26–28 February 2017; pp. 72–76. [Google Scholar] [CrossRef]
- Ernawati, S.; Yulia, E.R.; Frieyadie; Samudi. Implementation of the Naïve Bayes Algorithm with Feature Selection using Genetic Algorithm for Sentiment Review Analysis of Fashion Online Companies. In Proceedings of the 2018 6th International Conference on Cyber and IT Service Management, CITSM 2018, Citsm, Parapat, Indonesia, 7–9 August 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Caragea, C.; Silvescu, A.; Mitra, P. Combining hashing and abstraction in sparse high dimensional feature spaces. In Proceedings of the 26th AAAI National Conference on Artificial Intelligence, Toronto, ON, Canada, 22–26 July 2012; Volume 26, pp. 3–9. [Google Scholar] [CrossRef]
- Gao, J.; Ooi, B.C.; Shen, Y.; Lee, W.-C. Cuckoo feature hashing: Dynamic weight sharing for sparse analytics. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence (IJCAI-18), Stockholm, Sweden, 13–19 July 2018; pp. 2135–2141. [Google Scholar] [CrossRef]
- Ayesha, S.; Hanif, M.K.; Talib, R. Overview and comparative study of dimensionality reduction techniques for high dimensional data. Inf. Fusion 2020, 59, 44–58. [Google Scholar] [CrossRef]
- Mahmoud, U.; Hassan, M.; Zanga, A.I.; Rogo, A.A.; Umar, U. Application of Information Gain Based Feature Selection for Sentiment Analysis Using Movie Review Dataset. Niger. J. Comput. Engr. Tech. (NIJOCET) 2023, 2, 124–138. Available online: https://nijocet.fud.edu.ng/wp-content/uploads/2023/09/NIJOCET-VOL2-ISSUE-1-010.pdf (accessed on 1 January 2025).
- Forman, G.; Kirshenbaum, E. Extremely fast text feature extraction for classification and indexing. In Proceedings of the 17th ACM Conference on Information and Knowledge Management, New York, NY, USA, 26–30 October 2008; pp. 1221–1230. [Google Scholar]
- Johnson, L.; Lee, K. Investigating the Statistical Assumptions of Naïve Bayes Classifiers. In Proceedings of the 2021 55th Annual Conference on Information Sciences and Systems (CISS), Baltimore, MD, USA, 24–26 March 2021. [Google Scholar]
- Garcia, L.; Patel, S. k-Nearest neighbors in high-dimensional spaces: A comprehensive review. Mach. Learn. Adv. 2024, 18, 112–130. [Google Scholar]
- Pang, B.; Lee, L.; Vaithyanathan, S. Thumbs up: Sentiment classification using machine learning techniques. In Proceedings of the ACL-02 Conference on Empirical Methods in Natural Language Processing-Volume 10, Stroudsburg, PA, USA, 6 July 2002; pp. 1606–1624. [Google Scholar]
- Abubakar, A.; Abdulkadir, A.B.; Usman, H.; Mohammad, A.; Hahaya, G.S.; Romel, A.; Tayseer, A.; Theyazn, H.H.; Mahmoda, A.; Rami, S. An Improved Multi-Stage Framework for Large-scale Hierarchical Text Classification Problem Using a Modified Feature Hashing and Bi-filtering Strategy. Int. J. Data Net. Sci. 2024, 8, 2193–2204. [Google Scholar]

{kind=link}
{kind=link}
| Author | Year | Aim | Finding |
|---|---|---|---|
| [10] | 2016 | Implemented a feature ranking method for the context of aspect-level sentiment analysis using information gain. | Results showed that restricting the number of features during selection does not considerably affect accuracy. |
| [11] | 2017 | Presented a feature selection method that integrates information gain with word embeddings. | Experiments on Chinese text classification demonstrated enhanced results. |
| [12] | 2018 | Utilized Naïve Bayes and genetic algorithms for feature selection. | Naïve Bayes accuracy increased from 68.50% to 87.50% after applying genetic algorithm for feature selection. |
| [1] | 2019 | Proposed a method combining information gain with an ontology-based approach. | Information Gain effectively removed noise from the dataset, while the ontology-based method required more human intervention to eliminate redundancy. |
| [4] | 2020 | Applied Support Vector Machine with Information Gain for movie review classification. | Information gain enhanced the performance of the Support Vector Machine, but did not address feature redundancy. |
| [5] | 2021 | Presented a hybrid approach that integrate IG and T-test for selecting most informative features | The hybrid approach effectively selects the set of important features by complementing the backside of each method |
| [2] | 2021 | Proposed an approach using Chi-Square for feature selection in movie review analysis. | Chi-Square feature selection increased accuracy to 85.35%, and further improved to 87.74% with the application of AdaBoost. |
| Author | Year | Aim | Finding |
|---|---|---|---|
| [7] | 2009 | Introduced a novel technique called feature hashing. | The approach demonstrated exceptional performance, particularly in online applications. |
| [8] | 2009 | Suggested solutions to resolve challenges in current feature hashing techniques by introducing lower and upper bounds. | Results indicated a reduction in bias by almost 50%. |
| [13] | 2012 | Created an effective method for dimensionality reduction in text classification tasks by integrating hashing and abstraction techniques. | Effectively handled high-dimensional text data without compromising classification performance, demonstrating its usefulness for large-scale text data applications, including news categorization, web content analysis, and scientific document classification. |
| [14] | 2018 | Unveiled Cuckoo Feature Hashing (CCFH), a groundbreaking technique aimed at tackling issues related to feature hashing for large-scale sparse datasets. | Cuckoo Feature Hashing addressed feature collisions, decreased parameter dimensions, and preserved model sparsity, resulting in enhanced performance. Experimental results validated CCFH’s ability to reduce parameters while maintaining performance |
| [15] | 2020 | Conducted a study titled “HASHING” to tackle dimensionality issues in large-scale image categorization by employing a taxonomy hierarchical structure. | Offered both theoretical and empirical evidence for the method’s efficacy in lowering computational and storage demands while preserving classification accuracy. |
| [9] | 2021 | Proposed a new feature hashing method utilizing term weight to mitigate collision issues in existing feature hashing methods. | Experiments showed significant performance improvements, reducing collision issues by nearly 30%. |
| [16] | 2023 | Aimed to optimize sentiment analysis on the Stanford movie dataset using Feature Hashing for dimensional reduction. | The proposed method consistently achieved superior accuracy and precision across three classifier algorithms, though it negatively impacted recall. |
| Dataset Name | Movie review dataset |
| Number of Instance | 50,000 |
| Number of Classes | 2 |
| Number of Instances per Class | 25 instances per each class |
| Number of Attributes | 45,584 |
| Training | 70% |
| Testing | 30% |
| Classifier | All Feature | FS_(IG) | FS_(FH) | Propose Method (IG + FH) |
|---|---|---|---|---|
| Linear SVC | 86.12 | 86.67 | 87.13 | 89.48 |
| KNN | 63.12 | 64.11 | 66.08 | 67.23 |
| Naïve Bayes | 85.46 | 86.43 | 87.89 | 89.47 |
| Classifier | All Feature | FS_(IG) | FS_(FH) | Propose Method (IG + FH) |
|---|---|---|---|---|
| Linear SVC | 86.12 | 88.96 | 89.10 | 89.56 |
| KNN | 63.12 | 85.66 | 88.63 | 93.08 |
| Naïve Bayes | 85.41 | 86.66 | 88.68 | 88.89 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mahmud, U.; Ado, A.; Umar, H.A.; Bichi, A.A. An Improved Multi-Dimensional Data Reduction Using Information Gain and Feature Hashing Techniques. Eng. Proc. 2025, 87, 92. https://doi.org/10.3390/engproc2025087092
Mahmud U, Ado A, Umar HA, Bichi AA. An Improved Multi-Dimensional Data Reduction Using Information Gain and Feature Hashing Techniques. Engineering Proceedings. 2025; 87(1):92. https://doi.org/10.3390/engproc2025087092
Chicago/Turabian StyleMahmud, Usman, Abubakar Ado, Hadiza Ali Umar, and Abdulkadir Abubakar Bichi. 2025. "An Improved Multi-Dimensional Data Reduction Using Information Gain and Feature Hashing Techniques" Engineering Proceedings 87, no. 1: 92. https://doi.org/10.3390/engproc2025087092
APA StyleMahmud, U., Ado, A., Umar, H. A., & Bichi, A. A. (2025). An Improved Multi-Dimensional Data Reduction Using Information Gain and Feature Hashing Techniques. Engineering Proceedings, 87(1), 92. https://doi.org/10.3390/engproc2025087092