
Evaluation of Modified FGSM-Based Data Augmentation Method for Convolutional Neural Network-Based Image Classification †


 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Data Description
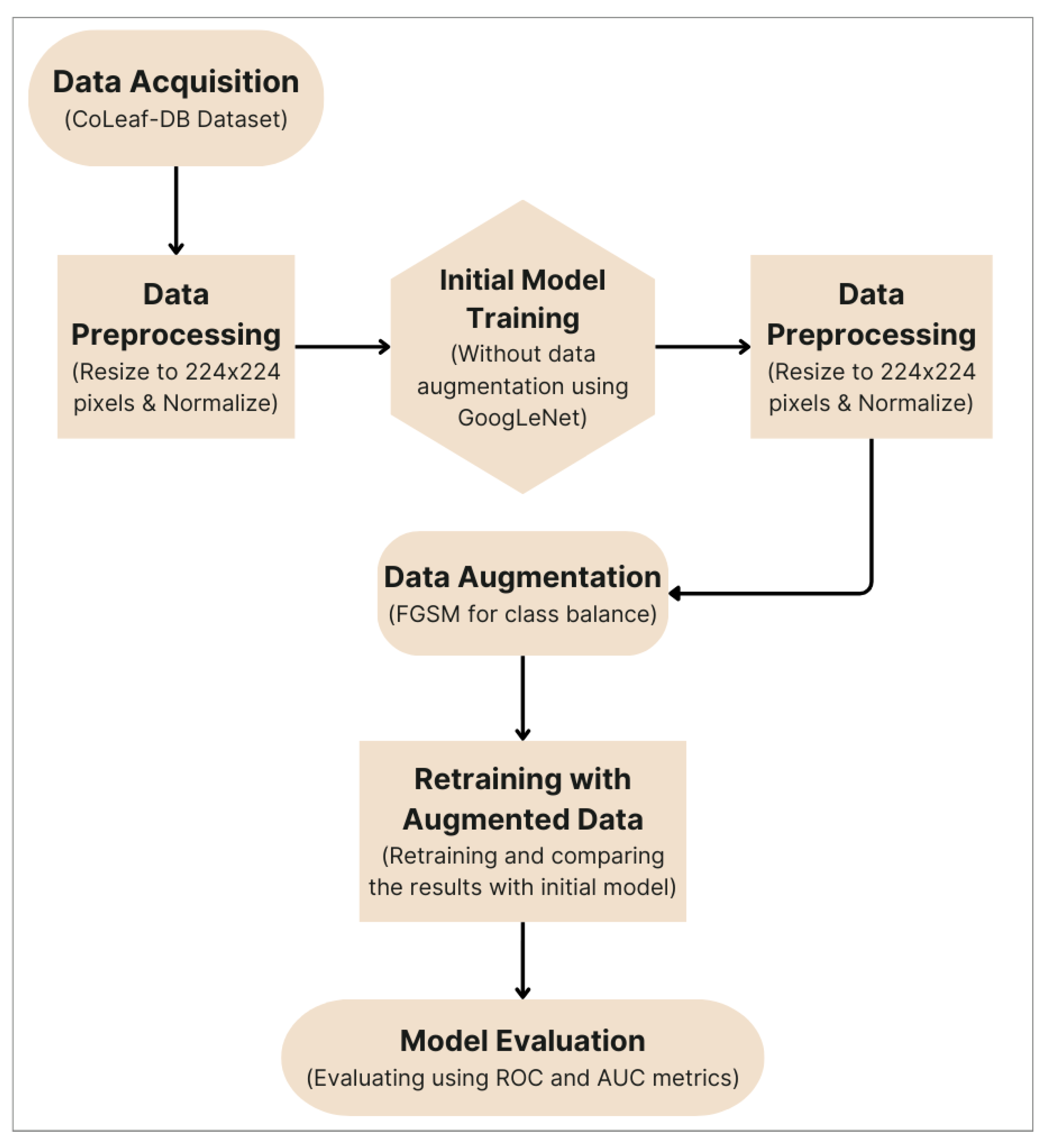
3. Proposed Method
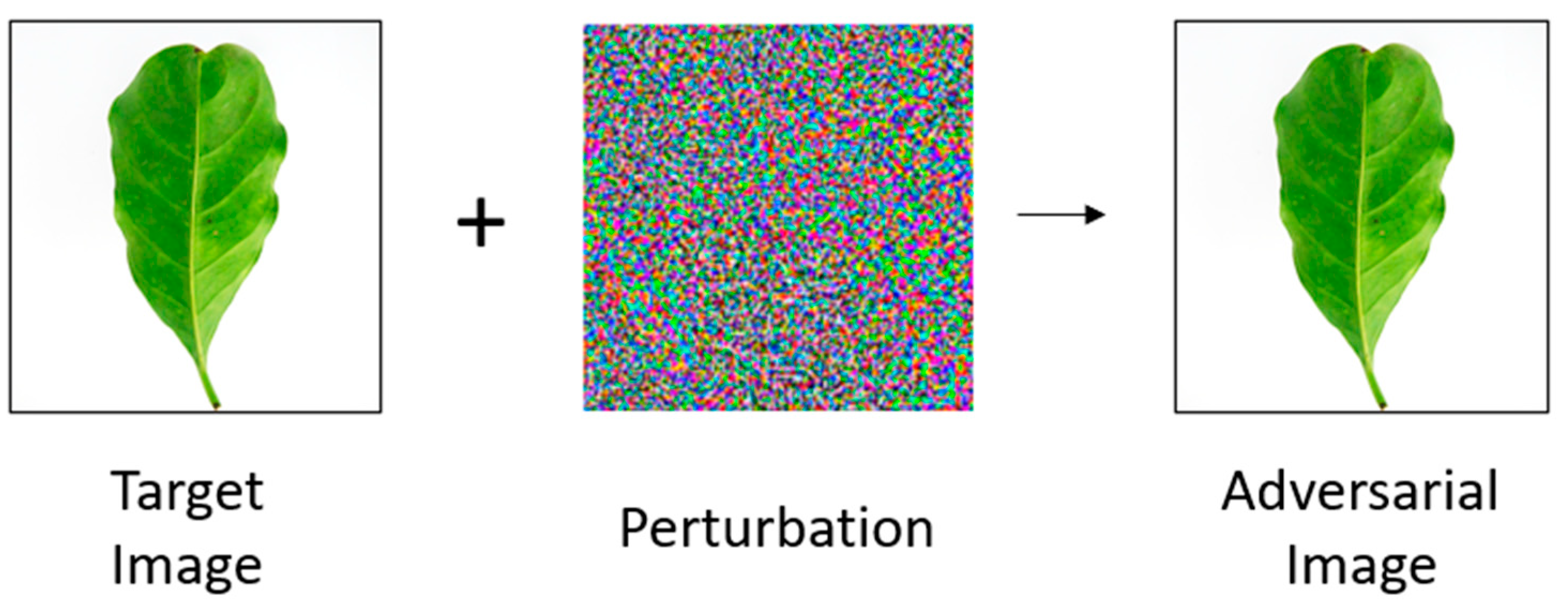
Data Augmentation Using Fast Gradient Sign Method (FGSM)
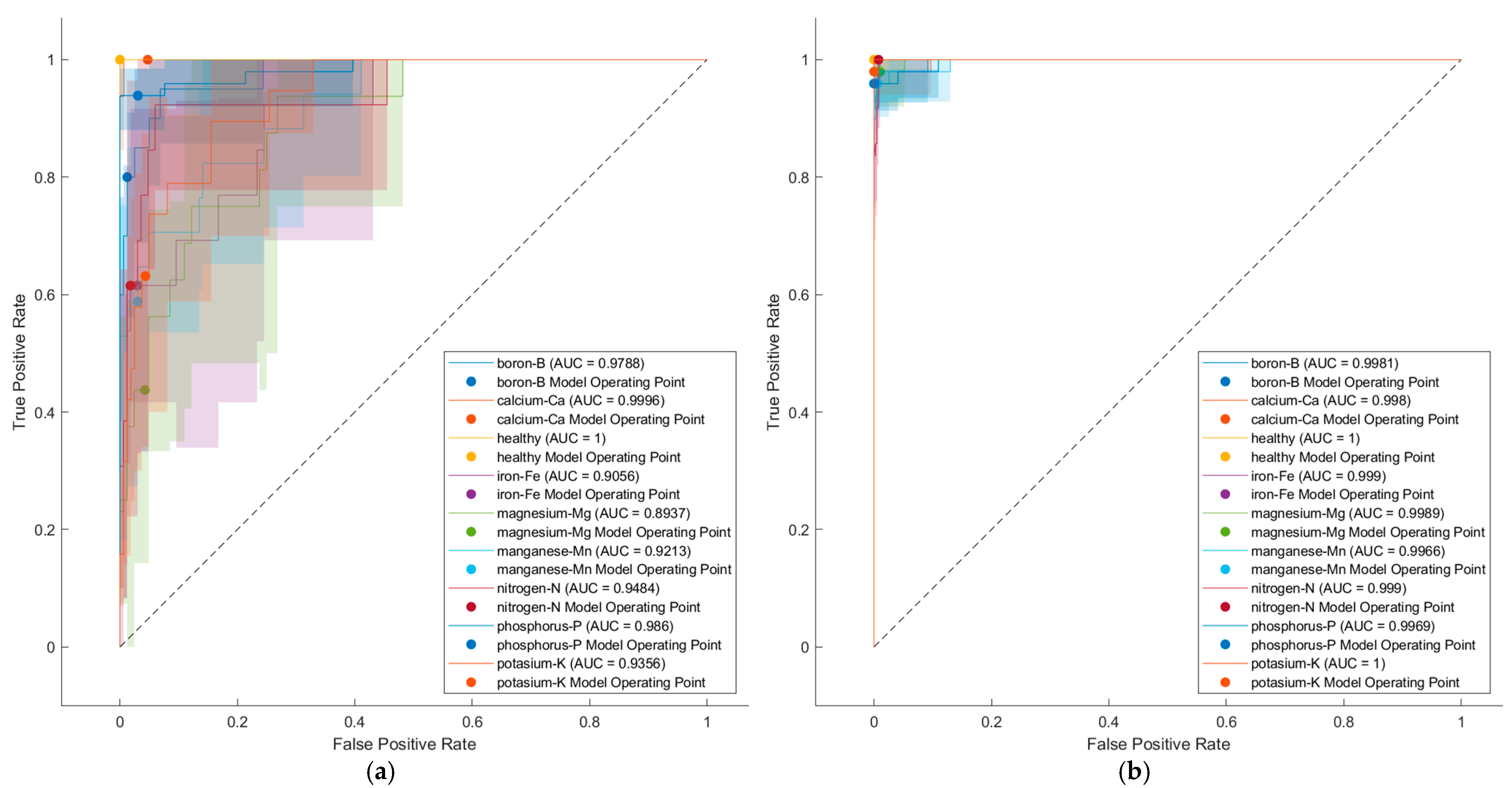
4. Result and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Buslaev, A.; Iglovikov, V.I.; Khvedchenya, E.; Parinov, A.; Druzhinin, M.; Kalinin, A.A. Albumentations: Fast and flexible image augmentations. Information 2020, 11, 125. [Google Scholar] [CrossRef]
- Lemley, J.; Bazrafkan, S.; Corcoran, P. Smart Augmentation Learning an Optimal Data Augmentation Strategy. IEEE Access 2017, 5, 5858–5869. [Google Scholar] [CrossRef]
- Zhang, Z.; Gao, Q.; Liu, L.; He, Y. A High-Quality Rice Leaf Disease Image Data Augmentation Method Based on a Dual GAN. IEEE Access 2023, 11, 21176–21191. [Google Scholar] [CrossRef]
- Cubuk, E.D.; Zoph, B.; Mané, D.; Vasudevan, V.; Le, Q.V. AutoAugment: Learning Augmentation Strategies From Data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 113–123. [Google Scholar]
- Waheed, A.; Goyal, M.; Gupta, D.; Khanna, A.; Al-Turjman, F.; Pinheiro, P.R. CovidGAN: Data Augmentation Using Auxiliary Classifier GAN for Improved COVID-19 Detection. IEEE Access 2020, 8, 91916–91923. [Google Scholar] [CrossRef] [PubMed]
- Yoo, J.; Kang, S. Class-Adaptive Data Augmentation for Image Classification. IEEE Access 2023, 11, 26393–26402. [Google Scholar] [CrossRef]
- Chen, L.; Wei, Y.; Yao, Z.; Chen, E.; Zhang, X. Data Augmentation in Prototypical Networks for Forest Tree Species Classification Using Airborne Hyperspectral Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Liu, B.; Li, L.; Xiao, Q.; Ni, W.; Yang, Z. Remote Sensing Fine-Grained Ship Data Augmentation Pipeline With Local-Aware Progressive Image-to-Image Translation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Takahashi, R.; Matsubara, T.; Uehara, K. Data Augmentation Using Random Image Cropping and Patching for Deep CNNs. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 2917–2931. [Google Scholar] [CrossRef]
- Tuesta-Monteza, V.A.; Mejia-Cabrera, H.I.; Arcila-Diaz, J. CoLeaf-DB: Peruvian coffee leaf images dataset for coffee leaf nutritional deficiencies detection and classification. Data Brief 2023, 48, 109226. [Google Scholar] [CrossRef]
- Googlenet Help Center. Available online: https://www.mathworks.com/help/deeplearning/ref/googlenet.html (accessed on 11 September 2024).
- Fan, J.; Upadhye, S.; Worster, A. Understanding receiver operating characteristic (ROC) curves. Can. J. Emerg. Med. 2006, 8, 19–20. [Google Scholar] [CrossRef]
- Compare Deep Learning Models Using ROC Curves Help Center. Available online: https://www.mathworks.com/help/deeplearning/ug/compare-deep-learning-models-using-ROC-curves.html#CompareDeepLearningModelsUsingROCCurvesExample-9 (accessed on 15 November 2024).
- Carter, J.V.; Pan, J.; Rai, S.N.; Galandiuk, S. ROC-ing along: Evaluation and interpretation of receiver operating characteristic curves. Surgery 2016, 159, 1638–1645. [Google Scholar] [CrossRef]
- Liu, Y.; Mao, S.; Mei, X.; Yang, T.; Zhao, X. Sensitivity of Adversarial Perturbation in Fast Gradient Sign Method. In Proceedings of the IEEE Symposium Series on Computational Intelligence (SSCI), Xiamen, China, 6–9 December 2019; pp. 433–436. [Google Scholar]
- Arbena Musa, K.V.; Rexha, B. Attack Analysis of Face Recognition Authentication Systems Using Fast Gradient Sign Method. Appl. Artif. Intell. 2021, 35, 1346–1360. [Google Scholar] [CrossRef]
- Naqvi, S.M.A.; Shabaz, M.; Khan, M.A.; Hassan, S.I. Adversarial Attacks on Visual Objects Using the Fast Gradient Sign Method. J. Grid Comput. 2023, 21, 52. [Google Scholar] [CrossRef]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Monson, P.M.d.C.; Almeida, V.A.D.d.; David, G.A.; Conceição Junior, P.O.; Dotto, F.R.L. Evaluation of Modified FGSM-Based Data Augmentation Method for Convolutional Neural Network-Based Image Classification. Eng. Proc. 2024, 82, 88. https://doi.org/10.3390/ecsa-11-20476
Monson PMdC, Almeida VADd, David GA, Conceição Junior PO, Dotto FRL. Evaluation of Modified FGSM-Based Data Augmentation Method for Convolutional Neural Network-Based Image Classification. Engineering Proceedings. 2024; 82(1):88. https://doi.org/10.3390/ecsa-11-20476
Chicago/Turabian StyleMonson, Paulo Monteiro de Carvalho, Vinicius Augusto Dare de Almeida, Gabriel Augusto David, Pedro Oliveira Conceição Junior, and Fabio Romano Lofrano Dotto. 2024. "Evaluation of Modified FGSM-Based Data Augmentation Method for Convolutional Neural Network-Based Image Classification" Engineering Proceedings 82, no. 1: 88. https://doi.org/10.3390/ecsa-11-20476
APA StyleMonson, P. M. d. C., Almeida, V. A. D. d., David, G. A., Conceição Junior, P. O., & Dotto, F. R. L. (2024). Evaluation of Modified FGSM-Based Data Augmentation Method for Convolutional Neural Network-Based Image Classification. Engineering Proceedings, 82(1), 88. https://doi.org/10.3390/ecsa-11-20476