1. Introduction
Digitalization is increasingly transforming business and scientific fields, making the automation of various analytics both easier and more crucial. This trend is particularly evident in corporate reporting. Today, digital financial and sustainability reporting is mandatory for all multinational companies in the European Union [
1]. New, complex requirements demand companies assess their sustainability from multiple perspectives. For instance, the Corporate Sustainability Due Diligence Directive (CSDDD) mandates that EU and non-EU companies meeting certain thresholds conduct due diligence across their operations, focusing on both internal and upstream activities as well as specific downstream activities such as distribution, transportation, and storage [
2]. Additionally, the European Commission’s Technical Expert Group on Sustainable Finance (TEG) developed the EU taxonomy for sustainable activities to determine the environmental sustainability of economic activities. This taxonomy aligns with the European Green Deal’s climate and energy targets for 2030 and the net-zero trajectory by 2050.
Despite companies publishing reports digitally, significant variations in format and data presentation pose challenges for mass information analysis. Multinational corporations, which significantly impact the economy and environment, often operate across multiple industries but classify themselves under a single industry code according to the NACE (Nomenclature statistique des Activités économiques dans la Communauté Européenne) or NAICS (North American Industry Classification System) [
3]. This practice can be misleading and exacerbate issues in data coherence and automated analysis, potentially leading to significant statistical misinterpretations.
Effective data examination requires systematic organization, which is often hampered when reports are uploaded in static formats like PDFs. These formats necessitate additional steps in the analytical process, such as parsing or optical character recognition (OCR), increasing the risk of errors. Manual data reading introduces further potential for human error, impacting the reliability of results. While these problems persist, some solutions have been implemented by numerous companies in the EU. One such method is using the eXtensible Business Reporting Language (XBRL) format. XBRL standardizes the organization and tagging of data in reports depending on the applied financial standard.
This study focuses on the tag ‘Description of Nature of Entity’s Operations and Principal Activities’ mandated by the International Financial Reporting Standards (IFRS). The labels, part of the IAS 1 ‘Presentation of Financial Statements’ standard, help identify relevant information about a company’s industrial activity. The analysis used over 6900 annual reports in XBRL format to demonstrate the advantages of combining standardized digital data presentation with machine learning (ML). Zero-Shot Learning was employed for topic classification from qualitative information to analyze the accuracy through the company activity tag’s analysis. Extracted report sections containing relevant textual information about companies’ industrial activities were broken down into sentences, which were then classified to identify the best-fitting NACE codes. The approach also aids in identifying sustainability reporting requirements, highlighting activities that demand more focus, and clarifying upstream–downstream relations. By systematically analyzing text blocks, it becomes possible to pinpoint key areas in sustainability reporting, ensuring companies address critical aspects of their operations and their broader environmental impact.
2. Literature Review
This review highlights the transformative impact of digital reporting, the necessity of accurate data formatting in sustainability reports, the importance of industry classification in understanding sustainable practices, and the potential for analyzing sustainable practices in XBRL databases across industries. It also examines integrated reporting methods, data analyses in financial and integrated reports, and AI implementation. Vitale et al. explore the positive impact of non-financial disclosure on key financial metrics like Operating Return on Asset, Return on Equity, and Return on Sales, despite regulatory moderation’s negative effects on sustainability and financial performance [
4]. Park (2018) finds a positive association between higher financial reporting quality and future innovation, especially in firms with robust R&D practices [
5]. Yang et al. (2019) introduce a method using XBRL taxonomies and graph mining to effectively map industry boundaries, offering an automated tool for precise industry classification [
6]. Jackson and Kwansa (2011) discuss XBRL’s transformative potential in enhancing financial reporting in the hospitality industry, addressing data security concerns and reasons behind early adoption [
7]. La Torre et al. (2018) emphasize integrated reporting (IR) for a holistic corporate report encompassing financial and non-financial information [
8]. Lee and Kim (2023) propose an ESG classifier to extract non-financial information accurately, highlighting its potential application across diverse sectors [
9]. Sriram (2020) investigates voluntary disclosure of financial ratios in India, suggesting mandatory reporting to enhance transparency and governance [
10]. Vitolla et al. (2020) identify profitability, size, leverage, and civil law systems as significant positive influences on integrated reporting quality in the financial industry [
11]. Digital corporate reporting through XBRL has transformed financial reporting and disclosures. Yang et al. (2019) and Jackson and Kwansa (2011) highlight XBRL’s efficacy in identifying industry boundaries and its prominence in the hospitality industry’s financial reporting, addressing data security and early adoption [
6,
7]. Suta et al. (2022) and Tóth et al. (2022) examine the impact of proposed sustainability reporting requirements on European automotive manufacturers, recommending incorporating climate-related disclosures and emphasizing transparency and comparability [
12,
13]. Both studies propose automated content analysis to enhance disclosure practices and transparency. Overall, these studies collectively emphasize the critical role of accurate, transparent, and innovative reporting practices in driving sustainable business performance and industry-wide advancements, providing a strong academic background and support for our current research.
3. Research Methodology
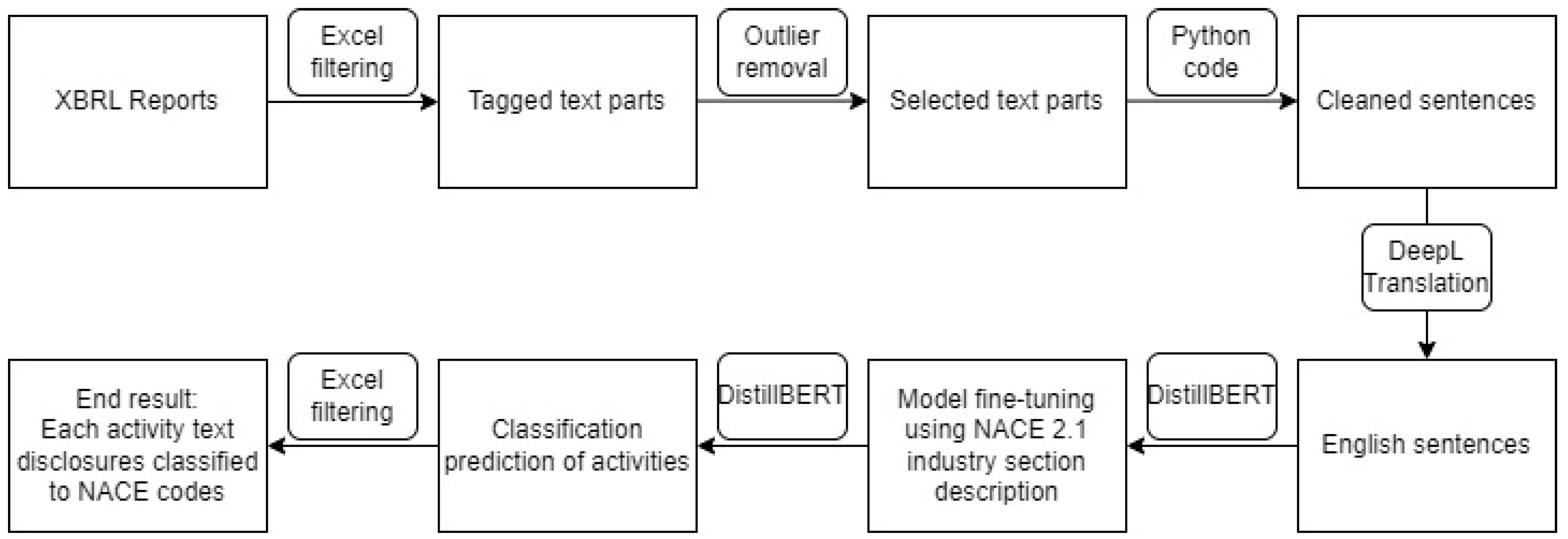
The main analysis followed a machine learning (ML) workflow, visualized in
Figure 1, which adhered to a basic Natural Language Processing (NLP) framework. The research objectives included testing a new methodology for classifying enterprises for statistical purposes, allowing multiple activity codes to be assigned to a single enterprise. This approach can handle large datasets in the ‘as-reported’ format from IFRS-compliant annual accounts. Additionally, text-based analysis applied sustainability criteria to the same activity descriptions.
The NACE Rev. 2.1 classification of business activities, retrieved from the ShowVoc system of the Publications Office of the European Union, was utilized. NACE Rev. 2.1, published in February 2023, includes several updates to reflect emerging economic activities. European statistics based on NACE Rev. 2.1 will be produced starting in 2025 according to EuroStat, (2023) [
3]. Subsequent steps involved fine-tuning a model using the BERT-uncased large language model. The process used the NACE dataset, covering 22 sections from A (‘Agriculture, Forestry and Fishing’) to V (‘Activities of Extraterritorial Organizations and Bodies’). A total of 1833 text blocks with an average length of 326.2 characters (st.dev. 287.6) were employed for fine-tuning.
Activity descriptions of companies were derived from annual European Single Electronic Format (ESEF) reports published by listed companies based on the XBRL framework. XBRL files, sourced from
https://filings.xbrl.org (accessed on 20 October 2024), were processed, and required data were extracted to a proprietary knowledge base management system in Java. Data analysis was conducted in a Python 3 environment. The packages used were pandas for database management, the tfidfvectorizer package for basic text analysis tasks (e.g., cleaning, preprocessing, frequencies, co-occurrences), and the transformers package for prediction procedures. Single-label classification probability was calculated using the SoftMax function.
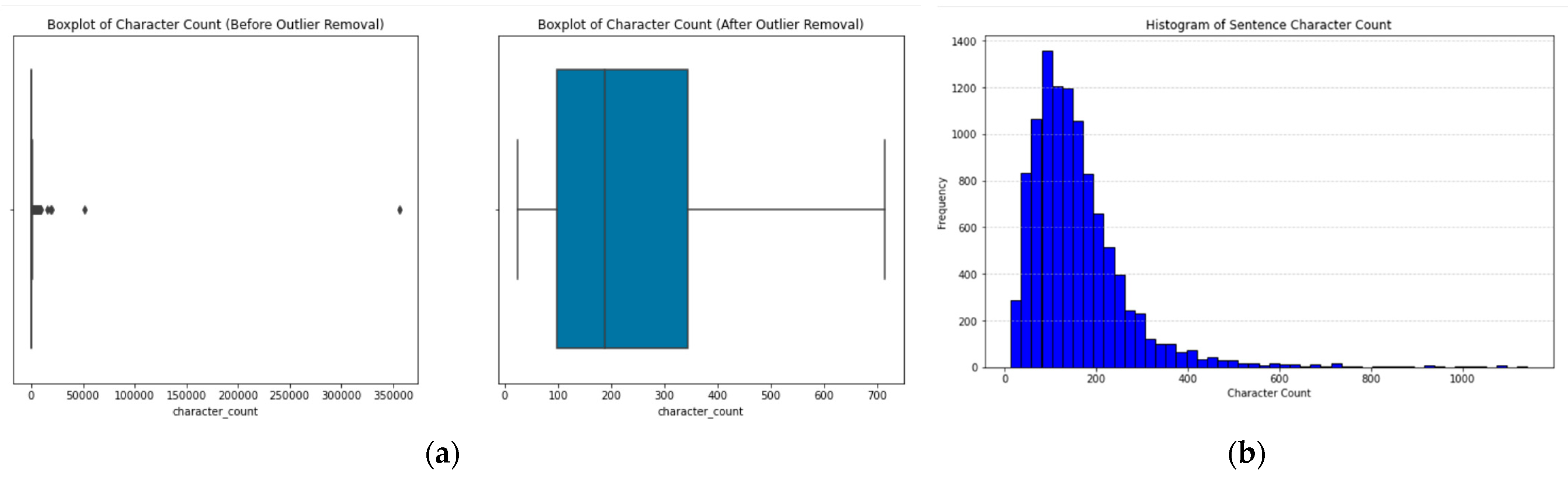
The tagged text was organized by company labels and contained reports published from 2019 to 2023. The initial dataset comprised 762,052 text disclosures. After filtering for the ‘Description of Nature of Entity’s Operations and Principal Activities’ tag, 9966 reports were identified. The removal of non-IFRS Ukraine-related data reduced this to 7337 reports. Further refinement, excluding data beyond the 5th and 95th percentiles based on character length, yielded 6,20 facts for analysis.
To enhance suitability for NLP, the text was segmented into sentences, resulting in 11,216 sentences. Excluding sentences shorter than three characters left 10,646 sentences for further examination. Visual representations, including a boxplot showing character length distribution and a histogram of sentence frequency, are presented in
Figure 2. DeepL translation service was used for translating text into English when necessary, focusing on unilingual models. The final analysis included 5671 sentences with classification probabilities above 50%. The disclosures are interpreted in the context of the years 2020 (499), 2021 (2178), 2022 (2697), and 2023 (291). Descriptive statistics provided insights into activity descriptions containing sustainability-related keywords.
4. Results and Discussion
The study aimed to classify enterprises by multiple activity codes and identify sustainability-related business activity disclosures using term-frequency observations of keywords such as ‘sustainab*’, ‘climate’, ‘circular’, and ‘pollution’.
Table 1 summarizes the results, showing the number of predicted classes, average probability per label, and sustainability-related instances for each NACE category.
The current research analyzed 5671 sentences, with an average of 180 sentences per disclosure. Each NACE category’s average probability per label indicated the confidence in classification, with Manufacturing (0.872) and Financial and Insurance Activities (0.841) showing the highest confidence levels. The Professional, Scientific and Technical Activities category had the most sustainability-related instances (60), indicating a strong focus on sustainability within this sector.
The results reveal that sectors such as Manufacturing; Financial and Insurance Activities; and Professional, Scientific and Technical Activities were prominently featured in sustainability-related disclosures. These findings suggest that companies within these categories were more likely to report on sustainability practices, aligning with regulatory requirements and societal expectations.
By identifying and classifying sustainability-related instances, the analysis highlights the sectors that prioritized sustainability in their reporting. The analyzed text data included disclosures from various companies, with an average character count of 401 and an average word count of 63 per disclosure. Out of the total disclosures, 72 companies explicitly mentioned sustainability-related keywords such as ‘circular economy’, ‘sustainable growth’, and ‘environmental sustainability’. Notably, companies like AAK AB highlighted efforts to make products healthier and more sustainable, while DS Smith PLC focused on sustainable fiber-based packaging supported by recycling and papermaking operations. Additionally, firms like Borealis AG emphasized their role in the circular economy by providing advanced recycling solutions. These specific instances illustrate how companies are actively integrating sustainability into their business models, aligning their operations with environmental and social governance (ESG) criteria to address industry-specific sustainability challenges.
5. Conclusions
The paper’s objective was to find systematic and sustainability-focused business practices through automated analyses. Using the algorithm of Zero-Shot Learning within a set of publicly available XBRL data among 22 sectors of industrial activities under the categorization of NACE, the following five leading categories were found: Professional, Scientific and Technical Activities; Financial and Insurance Activities; Telecommunication, Computer Programming and Consulting; Manufacturing; and Wholesale and Retail Trade.
However, the analysis has shown a number of limitations. First, the fairly small number of sentences—5671—may be insufficient to identify all NACE categories properly, as well as the low number of sentences used for model training—183. The fragmented nature of the sentence-based analysis may have lost the contextual meaning that would have provided greater insight into the depth of sustainability activities, particularly in those industries where such practices are described by longer, linked narratives. Additionally, the quality and structure of the sentences from various company reports were irregular. The fact that companies describe similar efforts on sustainability using different terminologies and frameworks mattered. Besides, the imbalance in the distribution of sentences across industries skewed the results, since sectors with more extensive reports could have been overrepresented.
Other crucial limitations included the low probabilities of prediction generated by the model, which stipulated further refinement of the algorithm in order to improve the model’s classification accuracy. Moreover, this fact relies on a narrow range of time—a period from 2019 to 2023—which might make long-term trends of sustainability or changing regulatory requirements hard to reflect in this study.
This study, notwithstanding the above-mentioned limitations, could show the potential of XBRL data and automated analysis for the large-scale identification of sustainability practices. Furthermore, this framework’s adaptability hints at a bigger variety of analytical applications. For future research, these are the limitations that have to be overcome: integrating a larger, more balanced dataset; refinement of the algorithm in capturing complex narratives; and more consistent data structures for higher accuracy in the identification of sustainability practices.





{kind=link}
{kind=link}