1. Introduction
Massive volumes of data must be efficiently gathered and processed in the era of the Internet in which we are constantly generating more information. In recent years, significant effort has been devoted to develop mechanisms to share data in standardized, machine-readable formats, leading to the so-called Web of Data. The Resource Description Framework (RDF) defines a common framework to describe resources using URIs to name associations between items. An RDF graph can be conceptually represented as a labeled graph or as a set of triples. The W3C also promotes SPARQL, a querying standard for RDF, which utilizes an SQL-like language. SPARQL specifies queries via graph pattern matching, imposing limitations on the resultant RDF subgraphs. At the core of SPARQL are triple patterns, which define basic matching with the collection of triples in the RDF graph.
The RDF standard only specifies a conceptual representation of data as a graph, not a specific data storage format. As a result, RDF may be stored in a variety of formats, and a slew of RDF storage solutions, or
RDF stores, have surfaced in recent years. Several full-featured RDF query engines, such as Virtuoso and Jena, provide full SPARQL support and can handle large RDF datasets [
1]. However, in recent years, a number of solutions based on compact data structures have arisen, with the goal of reducing the storage space while still providing efficient querying. Even though database-like solutions function well and fully support SPARQL, compact data structures have been proven to outperform the former in several areas, particularly for simpler query operations such as basic triple-pattern searches.
Compact data structures designed to store RDF usually divide the problem into two parts. On the one hand, there is a Triples component, which stores each RDF triple (
s,
p,
o) assuming that its components are integer identifiers (IDs). On the other hand, a dictionary component holds the mapping from the original strings of the RDF dataset to IDs, allowing the conversion from string to ID and versa. This leads to extremely specialized string dictionaries, such as libCSD [
2] and specialized methods for storing RDF triples encoded as integer IDs, such as K2-triples [
3] or RDFCSA [
4]. These solutions have been shown to be able to store RDF datasets in small spaces and perform very efficiently to answer basic triple-pattern and other simple queries. The HDT library [
5] provides a standard framework for the common representational notion of dictionary encoding, which divides an RDF dataset into three components (header, dictionary, and triples), and provides default implementations for the dictionary and triples. The main issue with most of these solutions based on compact data structures is that they do not completely support SPARQL; instead, they are designed to efficiently serve a limited number of queries using very specialized methods. For example, some solutions may only allow triple-pattern queries or basic join patterns.
In this paper, we present an architecture for the representation of RDF datasets that aim to provide a common framework for the representation of RDF based on compact data structures. Our approach seeks to store RDF data in little space while supporting sophisticated SPARQL searches. Our proposal has immediate applications as a common testing framework for compact data structures that have never been tested in complex SPARQL query scenarios.
2. Our Proposal
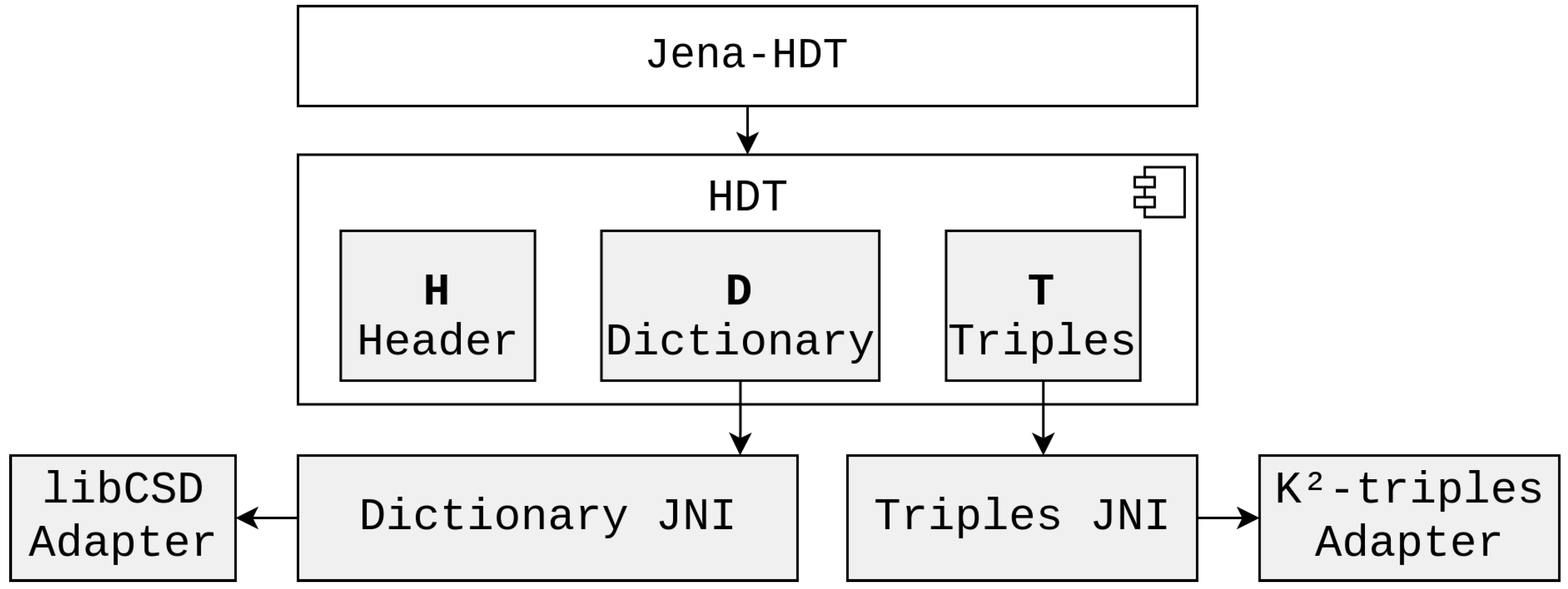
We propose an architecture that combines fully fledged RDF engines’ high-level capabilities with the compression performance of low-level compact data structures. We developed a prototype tool as an extension of the HDT Java library, a solution that proposes a relatively compact representation of RDF and provides SPARQL support through an integration with Apache Jena and Jena ARQ. We take advantage of this SPARQL support and aim to avoid the main drawback of this library: the data structures used for the dictionary and triples, while reasonably efficient, are much larger than other alternatives such as K2-triples. Our tool extends this framework to allow the utilization of different underlying representations for the storage of the RDF dictionary and triples components. This way, our tool provides a simple mechanism to incorporate and test different data structures using a common framework involving SPARQL queries. Particularly, our solution provides a simple mechanism to integrate existing solutions implemented in C/C++, using Java Native Interface (JNI) to transparently incorporate these structures into our extended HDT Java framework. Currently, we have a functional prototype that integrates the K2Triples and libCSD libraries, state-of-the-art representations able to efficiently compress RDF triples and RDF dictionaries, respectively, the two main components used in the HDT framework to store RDF data. A conceptual overview of the suggested framework can be seen in
Figure 1.
The main advantage of this proposal is the possibility to integrate fully functional alternatives, commonly implemented in C or C++, alternatives that are already known for efficiently solving basic problems. These techniques are not usually applied to solve bigger problems such as SPARQL, due to the additional cost of specifically redesigning all of the SPARQL queries processing mechanisms for each case. The proposed framework can take care of the high-level query processing, so that future integrations only need to build a specific adapter to query the desired data structure from the JNI extensions defined in our proposal, either for the dictionary or the triples component.
The proposed solution was tested with a dataset generated by the Berlin SPARQL Benchmark, containing 35 million triples. We compressed the data using the different components provided by our framework—first by using the original components given by the HDT library; secondly, by only using the component for the JNI triples and only the component for the JNI dictionary. Lastly, we compressed the dataset combining both JNI triples and dictionary components. A small sample of the results for this experiment can be seen in
Table 1. The queries listed below include filters, unbound predicates, unions, result modifiers such as LIMIT, ORDER BY and DISTINCT, and the DESCRIBE operator.
Our JNIDictionary implementation is based on plain front coding (PFC), a technique for compressed string dictionary that is also used by the original HDT library. It can be seen that the JNIDictionary component achieves similar results to the original HDT components. Considering that both solutions use similar implementations, but JNIDictionary has the additional cost of translating from Java to C++, the competitive results suggest that the dictionary overhead can be reduced in this scenario. On the other hand, JNITriples is slower, since K2-triples is much more compact than the solution posed by HDT but is also expected to be slower in many queries. Therefore, JNITriples is competitive in query times for the simpler queries, but significantly slower overall.
3. Conclusions and Future Work
Our proposal is currently a fully functional prototype, but we intend to improve it further in order to provide a competitive and flexible framework in the future. Upgrades in the scalability of the underlying compact data structures at construction time, as well as performance overheads owing to the usage of JNI, are currently possible. We also want to test a variety of state-of-the-art compact representations that should be simple to integrate into the existing framework and might lead to specific enhancements for various SPARQL query operations for specific implementations. As a result, our approach provides a standard framework for evaluating the performance of low-level data structures for RDF representation, as well as potential improvements.




{kind=link}