
Prediction of Mechanical Properties of Austenitic Stainless Steels with the Use of Synthetic Data via Generative Adversarial Networks †

Abstract
1. Introduction
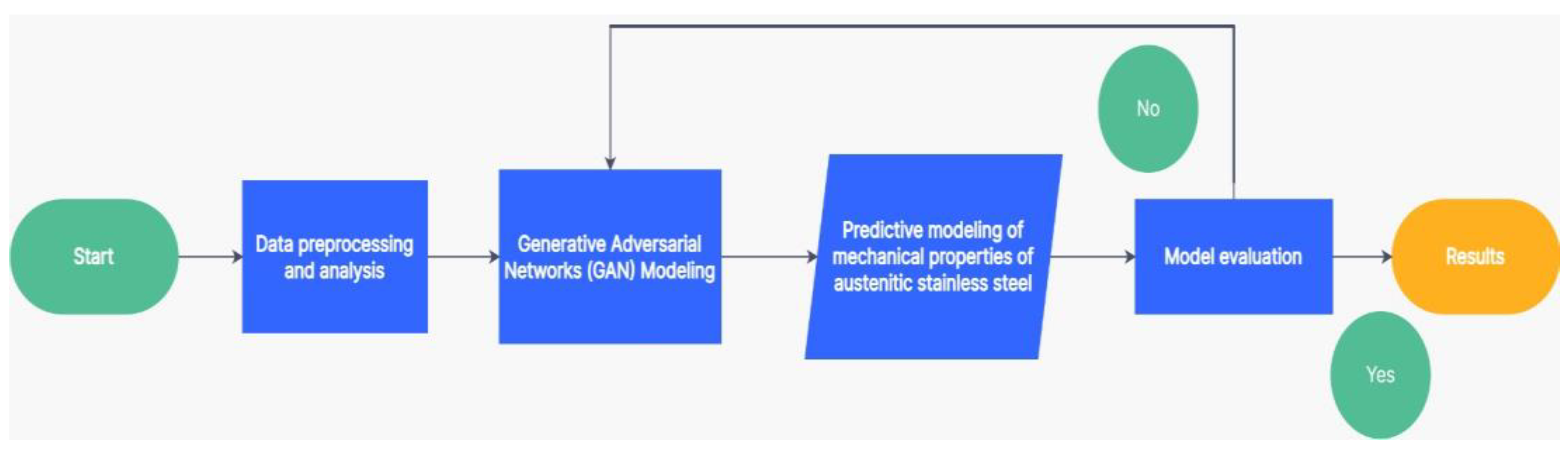
2. Research Method
2.1. Data Preprocessing and Analysis
2.2. Generative Adversarial Networks (GAN) Modeling
2.3. Modeling the Prediction of Austenitic Stainless Steel Mechanical Properties
2.4. Model Evaluation
- Mean Absolute Error (MAE)where i is the index of data in the sample, N is the total number of samples, yi is the actual value of the i-th data, and zi is the model’s predicted value for the i-th data.
- Root Mean Square Error (RMSE)where n is the number of data points used to test the model, f(Xi) is the value predicted by the model for the i-th data point, and Yi is the actual value for the i-th data point.
- R-squared
3. Results and Discussion
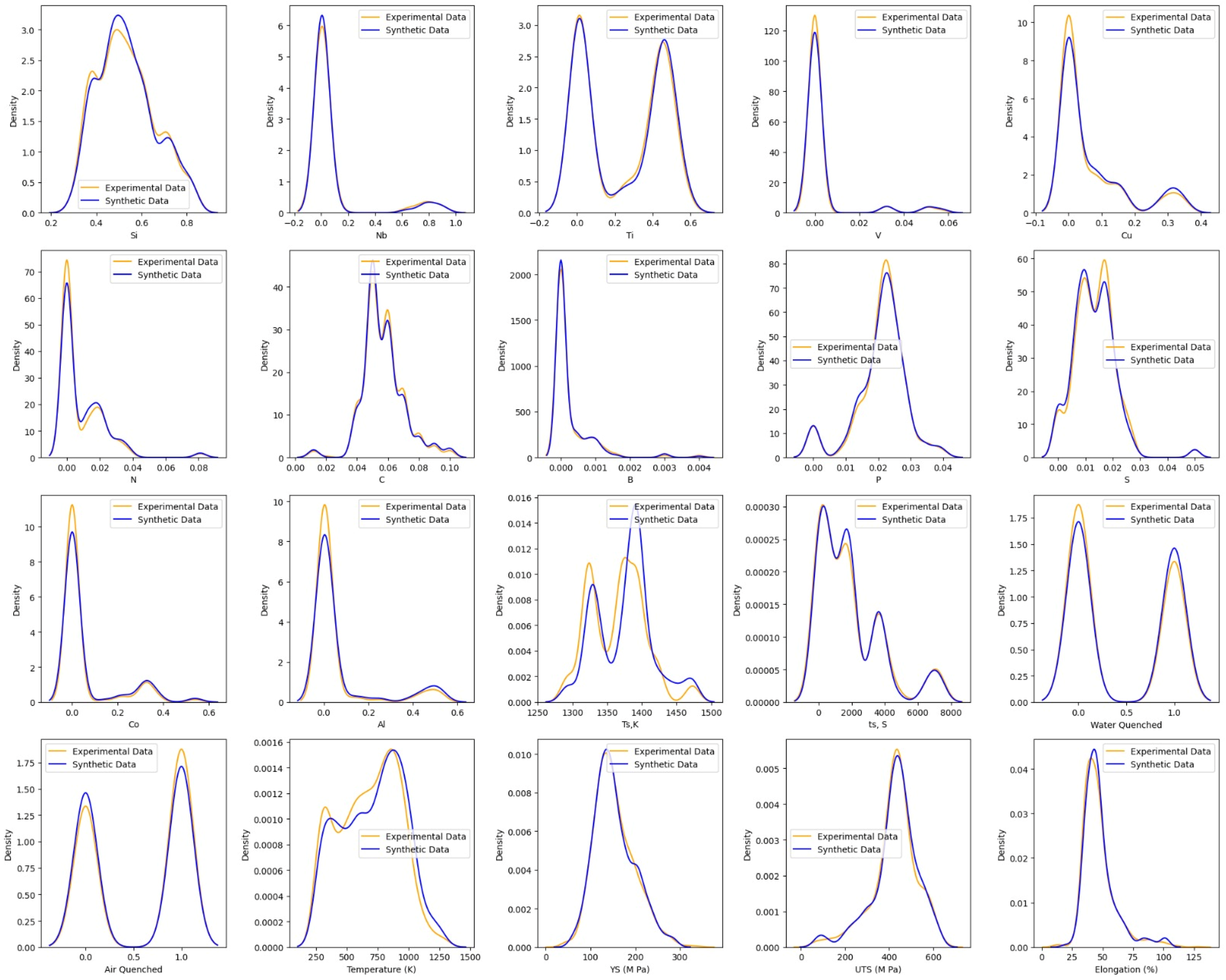
3.1. Data Preprocessing and Analysis
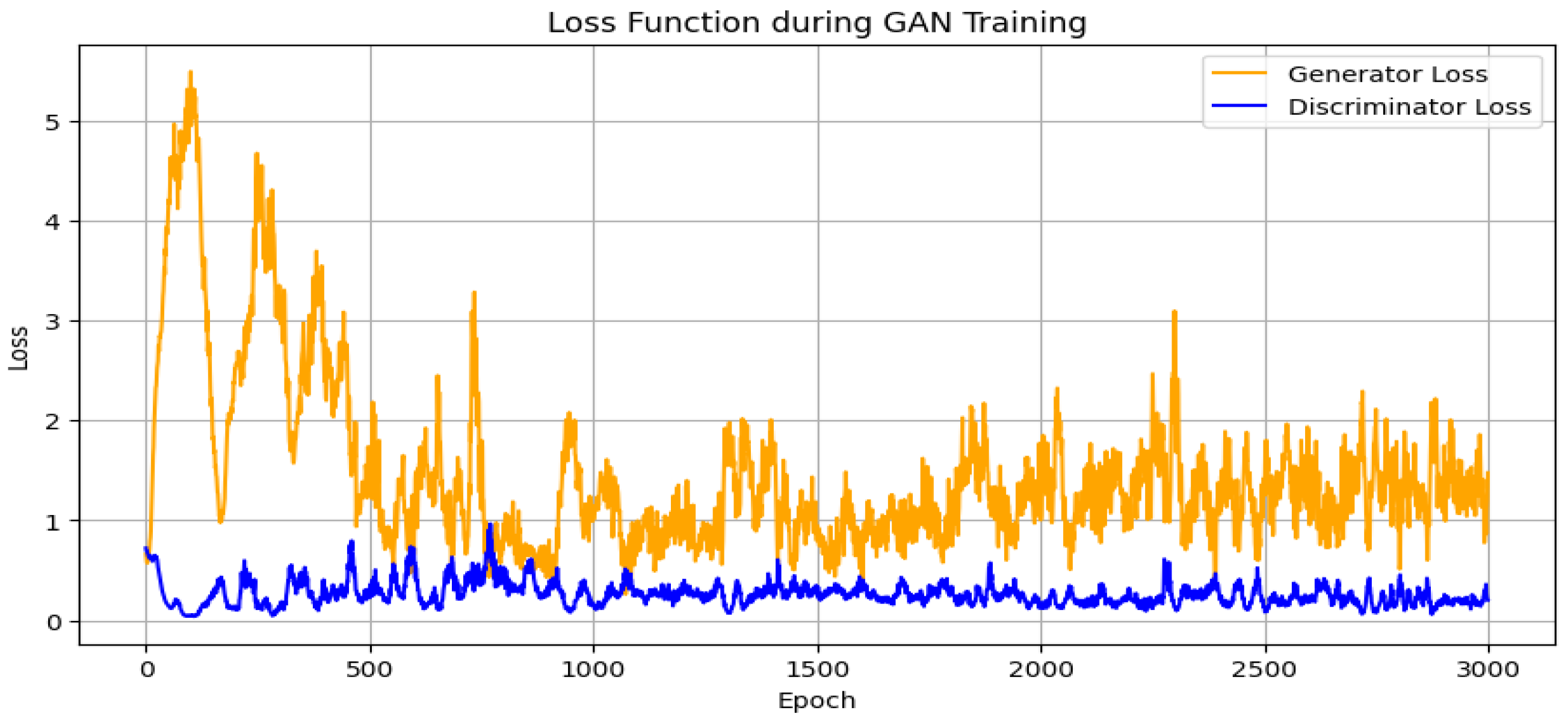
3.2. Generative Adversarial Networks (GAN) Modeling
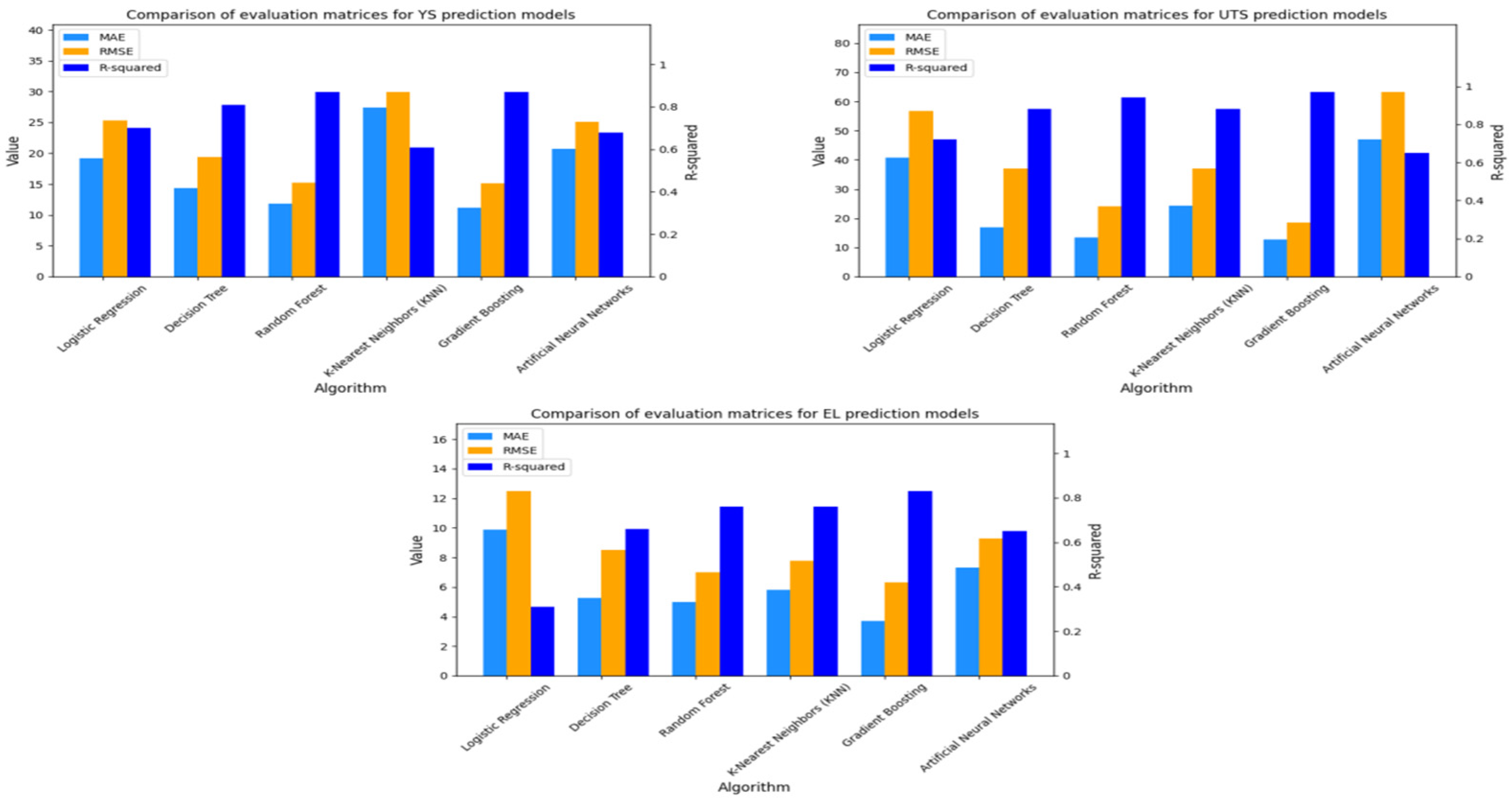
3.3. Modeling the Prediction of Austenitic Stainless Steel Mechanical Properties
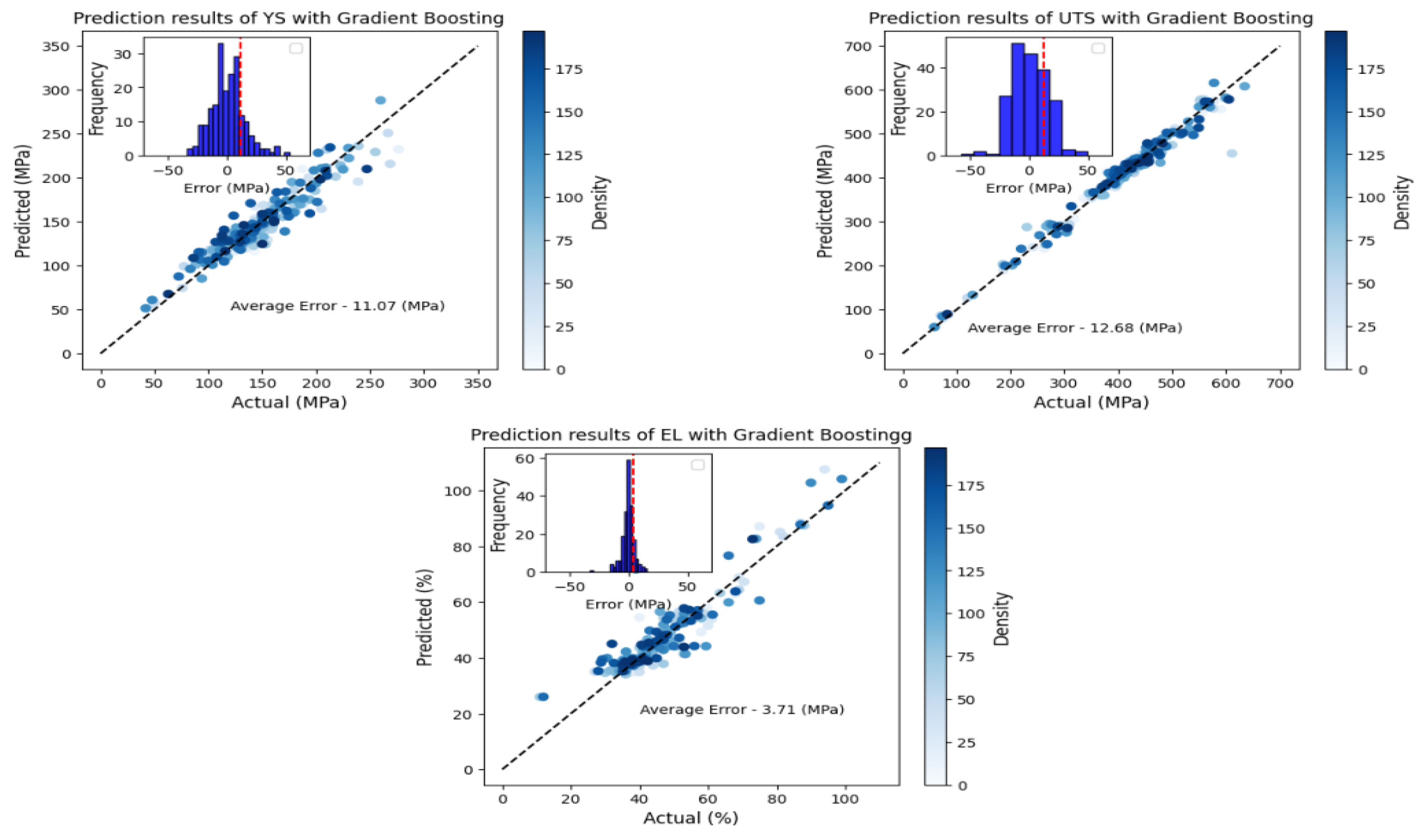
3.4. Model Evaluation
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Rajan, K. Materials Informatics: The Materials ‘Gene’ and Big Data. Annu. Rev. Mater. Res. 2015, 45, 153–169. [Google Scholar] [CrossRef]
- Frydrych, K.; Karimi, K.; Pecelerowicz, M.; Alvarez, R.; Dominguez-Gutiérrez, F.J.; Rovaris, F.; Materials, S.P. Informatics for Mechanical Deformation: A Review of Applications and Challenges. Materials 2021, 14, 5764. [Google Scholar] [CrossRef]
- Blaiszik, B.; Ward, L.; Schwarting, M.; Gaff, J.; Chard, R.; Pike, D.; Chard, K.; Foster, I. A data ecosystem to support machine learning in materials science. MRS Commun. 2019, 9, 1125–1133. [Google Scholar] [CrossRef]
- Agrawal, A.; Choudhary, A. Perspective: Materials informatics and big data: Realization of the ‘fourth paradigm’ of science in materials science. APL Mater. 2016, 4, 053208. [Google Scholar] [CrossRef]
- Yu, D.; Zhang, H.; Chen, W.; Yin, J.; Liu, T.-Y. How Does Data Augmentation Affect Privacy in Machine Learning? Proc. AAAI Conf. Artif. Intell. 2021, 35, 10746–10753. [Google Scholar] [CrossRef]
- Wang, K.; Gou, C.; Duan, Y.; Lin, Y.; Zheng, X.; Wang, F.-Y. Generative adversarial networks: Introduction and outlook. IEEECAA J. Autom. Sin. 2017, 4, 588–598. [Google Scholar] [CrossRef]
- He, G.; Zhao, Y.; Yan, C. Application of tabular data synthesis using generative adversarial networks on machine learning-based multiaxial fatigue life prediction. Int. J. Press. Vessel. Pip. 2022, 199, 104779. [Google Scholar] [CrossRef]
- Marani, A.; Jamali, A.; Nehdi, M.L. Predicting Ultra-High-Performance Concrete Compressive Strength Using Tabular Generative Adversarial Networks. Materials 2020, 13, 4757. [Google Scholar] [CrossRef] [PubMed]
- Sourmail, I.S.T. Materials Algorithms Project Program Library. Available online: https://www.phase-trans.msm.cam.ac.uk/map/data/materials/austenitic.data.html (accessed on 12 July 2023).
- Agrawal, A.; Deshpande, P.D.; Cecen, A.; Basavarsu, G.P.; Choudhary, A.N.; Kalidindi, S.R. Exploration of data science techniques to predict fatigue strength of steel from composition and processing parameters. Integr. Mater. Manuf. Innov. 2014, 3, 90–108. [Google Scholar] [CrossRef]
- Li, D.-C.; Chen, S.-C.; Lin, Y.-S.; Huang, K.-C. A Generative Adversarial Network Structure for Learning with Small Numerical Data Sets. Appl. Sci. 2021, 11, 10823. [Google Scholar] [CrossRef]
- Berger, V.W.; Zhou, Y. Kolmogorov–Smirnov Test: Overview. In Wiley StatsRef: Statistics Reference Online, 1st ed.; Balakrishnan, N., Colton, T., Everitt, B., Piegorsch, W., Ruggeri, F., Teugels, J.L., Eds.; Wiley: Hoboken, NJ, USA, 2014. [Google Scholar] [CrossRef]
- Leni, D. Pemilihan Algoritma Machine Learning Yang Optimal Untuk Prediksi Sifat Mekanik Aluminium. J. Engine Energi Manufaktur Dan Mater. 2023, 7, 35–44. [Google Scholar] [CrossRef]
- Leni, D.; Yermadona, H.; Berli, A.U.; Sumiati, R.; Haris, H. Pemodelan Machine Learning untuk Memprediksi Tensile Strength Aluminium Menggunakan Algoritma Artificial Neural Network (ANN). J. Surya Tek. 2023, 10, 625–632. [Google Scholar] [CrossRef]
- Agrawal, A.; Choudhary, A. An online tool for predicting fatigue strength of steel alloys based on ensemble data mining. Int. J. Fatigue 2018, 113, 389–400. [Google Scholar] [CrossRef]
- Fonseca, J.; Bacao, F. Tabular and latent space synthetic data generation: A literature review. J. Big Data 2023, 10, 115. [Google Scholar] [CrossRef]
- Lall, A. Data streaming algorithms for the Kolmogorov-Smirnov test. In Proceedings of the 2015 IEEE International Conference on Big Data (Big Data), Santa Clara, CA, USA, 29 October–1 November 2015; pp. 95–104. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Parameters | Value | No. | Parameters | Value |
|---|---|---|---|---|---|
| 1 | Epochs | 1500 | 7 | Gen Output Activation | 11 |
| 2 | Batch | 128 | 8 | Neuron Layer Dense Pert | 256 |
| 3 | Vektor Noise | 100 | 9 | Neuron Layer Dense Ked | 128 |
| 4 | Output Gen | 11 | 10 | Disc Output Activation | Sigmoid |
| 5 | Neuron Layer Dense Pert | 128 | 11 | Loss Function Disc | Binary Crossentropy |
| 6 | Neuron Layer Dense Ked | 256 | 12 | Loss Function GAN | Binary Crossentropy |
| No. | Variable | KS Statistic | p-Value | No. | Variable | KS Statistic | p-Value |
|---|---|---|---|---|---|---|---|
| 1 | Si | 0.025 | 0.909 | 11 | Co | 0.042 | 0.362 |
| 2 | Nb | 0.019 | 0.993 | 12 | Al | 0.05 | 0.158 |
| 3 | Ti | 0.08 | 0.004 | 13 | Ts, K | 0.28 | 0 |
| 4 | V | 0.009 | 1 | 14 | ts, S | 0.032 | 0.677 |
| 5 | Cu | 0.052 | 0.143 | 15 | Water Quenched | 0.045 | 0.28 |
| 6 | N | 0.053 | 0.129 | 16 | Air Quenched | 0.045 | 0.28 |
| 7 | C | 0.03 | 0.752 | 17 | Temperature (K) | 0.03 | 0.4 |
| 8 | B | 0.011 | 1 | 18 | YS (M Pa) | 0.027 | 0.854 |
| 9 | P | 0.032 | 0.677 | 19 | UTS (M Pa) | 0.039 | 0.457 |
| 10 | S | 0.05 | 0.175 | 20 | Elongation (%) | 0.061 | 0.052 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Leni, D.; Kesuma, D.S.; Maimuzar; Haris; Afriyani, S. Prediction of Mechanical Properties of Austenitic Stainless Steels with the Use of Synthetic Data via Generative Adversarial Networks. Eng. Proc. 2024, 63, 4. https://doi.org/10.3390/engproc2024063004
Leni D, Kesuma DS, Maimuzar, Haris, Afriyani S. Prediction of Mechanical Properties of Austenitic Stainless Steels with the Use of Synthetic Data via Generative Adversarial Networks. Engineering Proceedings. 2024; 63(1):4. https://doi.org/10.3390/engproc2024063004
Chicago/Turabian StyleLeni, Desmarita, Dytchia Septi Kesuma, Maimuzar, Haris, and Sicilia Afriyani. 2024. "Prediction of Mechanical Properties of Austenitic Stainless Steels with the Use of Synthetic Data via Generative Adversarial Networks" Engineering Proceedings 63, no. 1: 4. https://doi.org/10.3390/engproc2024063004
APA StyleLeni, D., Kesuma, D. S., Maimuzar, Haris, & Afriyani, S. (2024). Prediction of Mechanical Properties of Austenitic Stainless Steels with the Use of Synthetic Data via Generative Adversarial Networks. Engineering Proceedings, 63(1), 4. https://doi.org/10.3390/engproc2024063004