1. Introduction
Camouflaged object detection (COD) is a process that detects the objects that are presented in videos and images. Important patterns and parameters are detected from the images using COD. A rethinking COD method is commonly used to detect the objects from the images [
1]. The COD method detects the visual effects, patterns, color, texture, and motion features of the images. The COD method uses a feature-based structure to analyze the depth and content of the objects [
2]. The COD method also identifies the disguised targets that improve the functional performance range of the systems. The neighbor connection-based COD method is mainly used to detect the hidden similarities in the background in the images [
3]. Hierarchical information transfer (HIT) is used in a method that identifies the neighboring layers in the images. The HIT-based COD method enhances the effectiveness level of the object detection process [
4]. A semi-supervised search identification network-based COD approach is also used in the detection process. Both spatial and temporal features are detected in the images. The textual and statistical parameters are also detected, which produce optimal information for the COD process [
5].
Machine learning (ML) algorithms and techniques are used for the COD process. ML is mainly used to increase the accuracy level of the object detection process. A polarization imaging and deep learning (DL)-based COD method is used for the applications. A self-supervised DL algorithm is used here to detect the camouflaged targets from the given outputs. The polarization imaging detects the important parameters using a segmentation algorithm. The DL algorithm improves the effectiveness and performance range in target detection processes [
6,
7]. A deep gradient learning network (DGNet) is used for COD. The DGNet analyzes the context and texture features from the images. The DGNet detects the transparent and hidden objects which are presented in the images. The DGNet provides effective datasets for detection that reduce the latency in the computation process. The COD method also identifies the similarities among the objects that reduce the computational cost ratio of the systems [
8]. The contributions of this study are summarized as follows:
Designing a target object detection scheme in camouflaged images using segmentation and variation detection with high positive rates;
Incorporating the convolution neural network process with modified layer operations for differentiation detection and training;
Performing experimental and comparative analysis using external inputs and metrics for assessing the proposed scheme’s performance.
2. Related Works
Yuanying et al. [
9] introduced a camouflage detection approach using local minimum difference constraints (LMDC). The mirror differences are identified based on the moving target from the given input data. The introduced method removes the stable background region from the targets. It also calculates the attributes based on the details of the pixels, which reduces the latency in the computation process.
Zhai et al. [
10] proposed a new mutual graph learning (MGL) model for camouflaged object detection. Task-specific feature maps are used in the model which are necessary for detection. The MGL model detects the actual relationship between the interaction process. It provides higher-resolution services to the users that minimize the energy consumption level in object detection.
Xu et al. [
11] designed a new boundary guidance network for camouflage object detection (COD). A localization decoder is implemented in the method to capture multi-scale information for further processes. The localization decoder also identifies the missing parts of objects. A residual refinement is used here to enhance the region branch of the objects. The designed network increases the accuracy range in COD, which improves the effectiveness ratio of the systems.
Liu et al. [
12] introduced a bi-level recurrent refinement network (Bi-RRNet) for COD systems. The main aim of the network is to analyze the global information which is presented in the content. Both spatial and temporal features are detected that produce optimal information for the detection process. High-level semantic features are evaluated using an enhancement module that reduces the complexity of the identification process. The introduced network maximizes the accuracy in object detection, which enhances the performance level of the applications.
Ji et al. [
13] developed an edge-based reversible re-calibration network (ERRNet)-based COD method. A selection edge aggregation (SEA) module is implemented in the network to fetch prior edges of the nodes and pixels. The visual behaviors of the objects and scenes are also detected in the images.
Bi et al. [
14] proposed a COD framework named CFNet, CFNet, which is mainly used to solve problems in the detection process. The actual goal of the framework is to reduce the blurred edges and difficulties in object detection. The contradiction area detection module (CADM) and feature aggregation module (FAM) are used to address the important data that are relevant to the objects. The proposed framework improves the feasibility and effectiveness level of COD systems.
Zhang et al. [
15] designed a COD method using a transformer-included progressive refinement network (TPRNet). TPRNet detects the semantic and spatial parameters and information for the detection process. A refinement concurrency unit (RCU) is obtained here to prior the guidance for object detection. The RCU module provides rich parameters to detect the details of the objects for further processes. The designed framework increases the performance range of the systems.
Xiao et al. [
16] proposed a boundary-guided context-aware network (BCNet) for COD. The proposed network is a high-resolution object detection method that minimizes the complexity of the detection process. The BCNet identifies the multi-scale information and details of objects that are presented in the scenes. It boosts the inner layer of the detection process, which improves the reliability range of the systems. The proposed BCNet increases the real-time speed capacity in COD systems.
Apart from the above discussion, the problem of camouflaged boundary detection and the variation estimation problems are considered in this article. The boundary-based approach in [
16] requires certain textural classifications regardless of the image size and pixel representations. The contradiction method discussed in [
14] requires deviating instances that segregate the pixels, resulting in false negatives. Such issues are addressed in this proposed scheme for improving the positive rate of object detection.
3. Distribution-Differentiated Target Detection Scheme
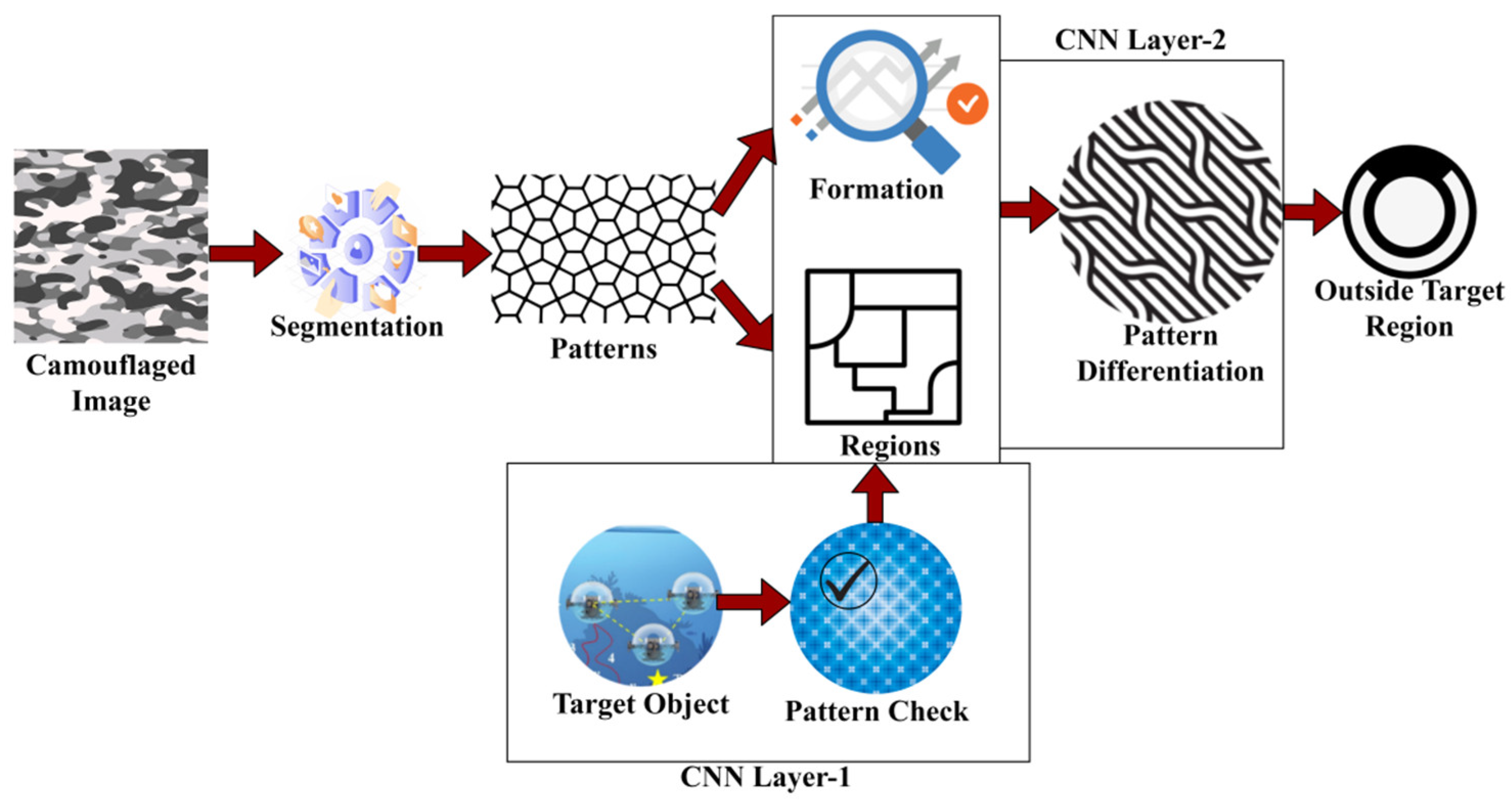
This proposed distribution-differentiated target detection scheme (DDTDS) helps in conveying the challenge of determining camouflaged objects within images or videos, where the target objects are masked by similar patterns and distributions, making it crucial to identify them precisely after classification. By manipulating textural pixel patterns, convolutional neural learning, and an iterative training process, this process efficaciously differentiates and determines camouflaged objects with enhanced positive rates and reduced false negatives. Furthermore, the use of non-uniform patterns in the training procedure helps in enhancing the process’s ability to detect diverse and complex camouflaged objects. A schematic illustration of the proposal is presented in
Figure 1.
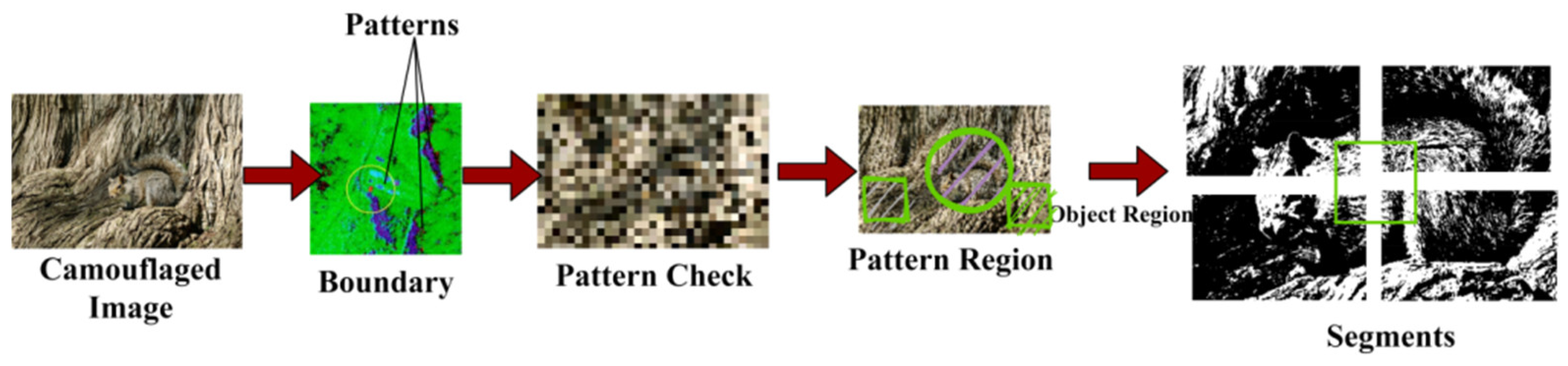
The camouflaged images are analyzed for the further segmentation procedure, and to extract patterns from the segmentation. This proposed DDTDS helps in determining the region that contains the potential camouflaged objects. This input analysis process helps in scrutinizing their linear differentiation to extract the valuable characteristics of the images and their distinctions between the target images and then the background. After determining the camouflage images, the segmentation process is performed according to it. The segmentation operation is employed to separate the camouflaged object from the surrounding background. This involves using the information which is obtained from the linear differentiation of the textural pixel patterns to describe the bounds of the potential target regions. The process of determining the camouflage image via the segmentation process is explained by the following equation given below:
where
denotes the input image,
represents the textural patterns,
denotes the segmentation operation in detecting the camouflaged object,
represents the characteristics of an image,
denotes the target regions. After the segmentation process, the pattern determination procedure is performed to extract the formation and regions of the target input images. This process involves training the neural network to distinguish between uniform and non-uniform patterns. Uniform textural patterns represent the background regions, while non-uniform patterns denote the presence of the potential camouflage object in the target images. The convolutional neural network helps in analyzing the pattern formations and distribution of the pixels within each segmented region. It extracts the patterns for every segmented region. The process of determining the patterns of segmented regions is explained by the following equation given below:
where
represents the patterns of the segmented regions, and
denotes the training operation. Now, the formation and regions of the camouflaged images are determined for further processes. This process ensures that the determined images are formed precisely according to the input images. They are identified for further training processes and also to determine the outside target regions. This ensures that the identified formation accurately corresponds to the potential camouflaged objects. The process of determining the formation of the images is explained by the following equation given below:
where
represents the formation of the image, and
represents the precise information of its origination. The image formation using the patterns is illustrated in
Figure 2.
The input camouflaged image is differentiated using
for multiple pixel regions. As pixels meet
the
is used for pattern checking across multiple regions. The CNN’s first layer is responsible for verifying the obtained patterns across various
and
regions through
. If the
is non-deviating (incremental), then
is obtained from
. The segments are thus classified from the patterns obtained; the patterns are used for image formation (
Figure 2). Now, the regions of the images are determined in this process. They are identified for the further verification operation of the targeted objects. These are the procedures conducted to reduce false positives and to improve the detection accuracy of the process. They help in achieving image recognition depending on the training of the network, and thus this process is explained by the following equation given below:
where
represents the region of the camouflage images. Now, the CNN first layer helps in checking the pattern of the target object. The training process is performed for the neural network to extract the formation and region of the target objects. Then, it is compared with the camouflaged image’s formation and region. After the training process, the neural network helps in extracting the distinctive features and formations of the region surrounding the target. In this CNN first-layer process, a procedure is performed to check whether the camouflaged formation and region are the same as the formation and region of the camouflaged image. The differentiated region is trained for its positive rate in identifying the region around the target. The process of the first layer of CNN is explained by the following equation given below:
where
represents the operation of the CNN layer 1 in this process. Now the pattern differentiation is determined in the second layer of the CNN. The non-uniform patterns are used for training the second layer of the neural network. These non-uniform patterns denote the difficult and precise characteristics present in the camouflaged images. By providing efficient training to the neural network with such patterns, it identifies the variations in the target object. After determining the pattern differentiation, the outside target region is extracted. Hence, the CNN second-layer process is explained by the following equation given below:
where
represents the pattern differentiation in the second layer of CNN. Now, the outside target region is determined after the two-layer process of the CNN. With both layers’ outcomes, this CNN helps in precisely delineating the outside of the target region. The second-layer process of the CNN is illustrated in
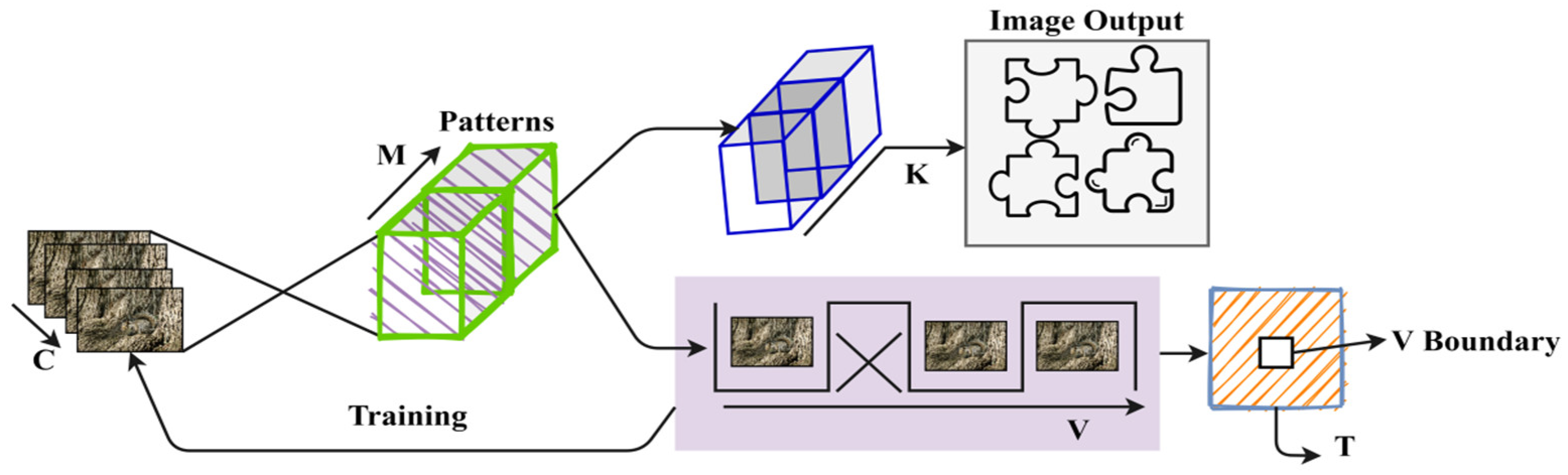
Figure 3.
The CNN’s second layer is responsible for differentiating
V from the input image. The mixed
and
are used for concurrent layer-based analysis through
in the first layer. In this process, either
or
is used for validating
throughout
. If
is observed anywhere, the variation boundaries are identified using the pixels present (Refer to
Figure 3). The outside regions of the targeted images are consolidated as the background region. This procedure helps in ensuring the CNN [
17,
18,
19] aims at the target area, establishing precise and efficacious target detection within the camouflaged images. The process of extracting the outside target region is explained by the following equation given below:
where
represents the outside target region. This proposed system helps in detecting the outside target region by assessing the positive rate, detection time, and false negatives. This helps to reduce unnecessary false information and the time taken for the detection of the outside target region. The patterns of the camouflaged image are detected and compared with the targeted objects to extract the pattern differentiation. Additionally, based on this output, the outside target region is determined.
6. Conclusions
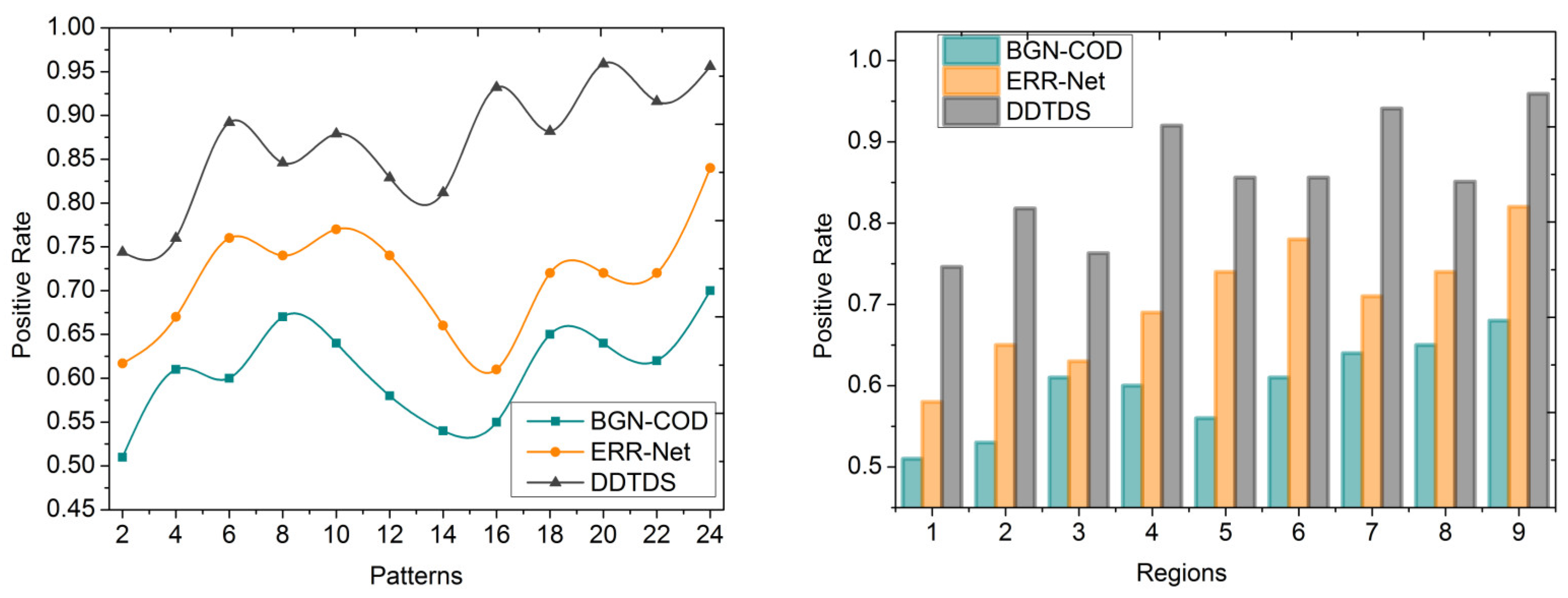
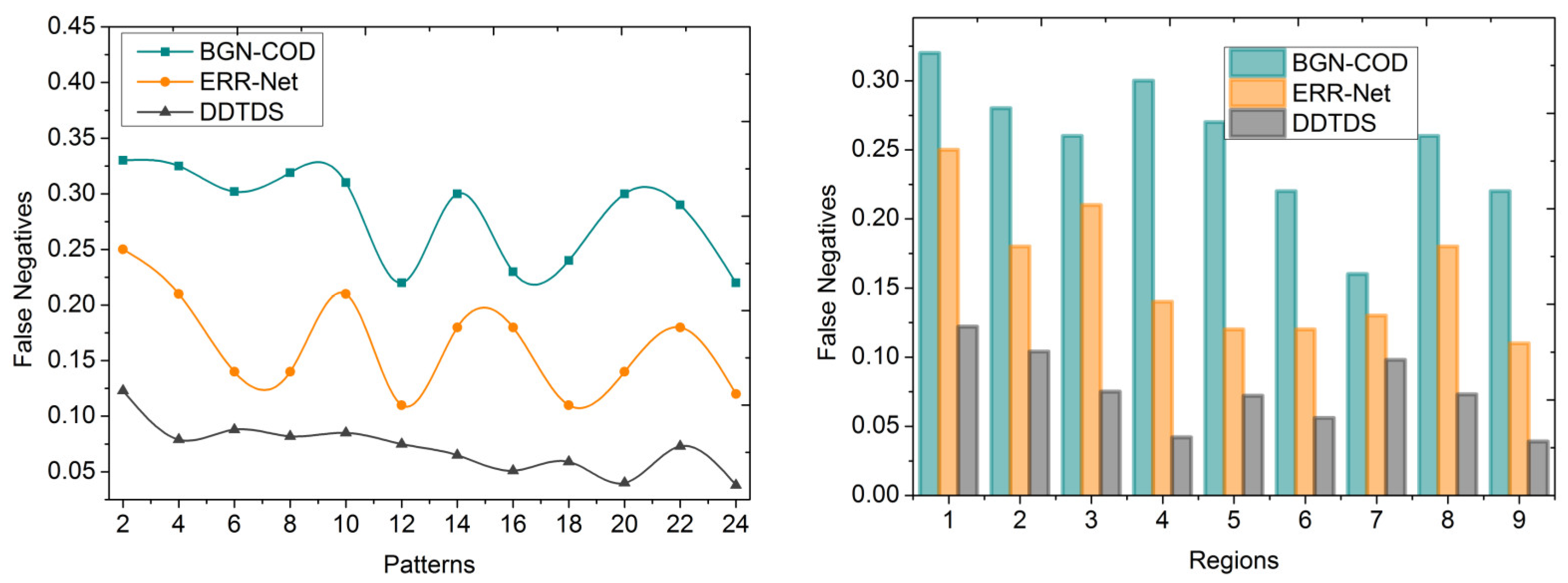
The DDTDS commences by separating the input image using textural pixel patterns, and then it performs linear differentiation on these patterns. This process helps to differentiate the regions that contain prospective camouflaged objects from the background. To attain this, a CNN is engaged in training the regions based on pixel distribution and pattern formations. The neural network consists of two layers, and its primary aim is to distinguish the patterns linearly. In the first layer, the differentiated region is trained to enhance its positive rate in determining the area around the target. The second layer of the neural network is trained using non-uniform patterns. Therefore, this proposed scheme engages are peated iteration process to continuously clarify the segmentation, mainly aiming for the maximum segmentation precision. This iterative approach allows the network to continuously enhance its capability to differentiate between the target objects and background elements, leading to better detection results. From the comparative analysis, it is seen that the proposed scheme improves the positive rate by 9.3%, and reduces detection time and false negatives by 9.39% and 13.2% for the different patterns observed.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}