
Deep Learning-Based Coverless Image Steganography on Medical Images Shared via Cloud †


Abstract
1. Introduction
- (i)
- A novel attention vector-guided GAN for transformation of cover image without distorting specialised regions in the image;
- (ii)
- Classification utility-preserving transformation without reducing the accuracy of disease diagnosis by a large factor in computer-aided disease diagnosis application.
2. Related Works
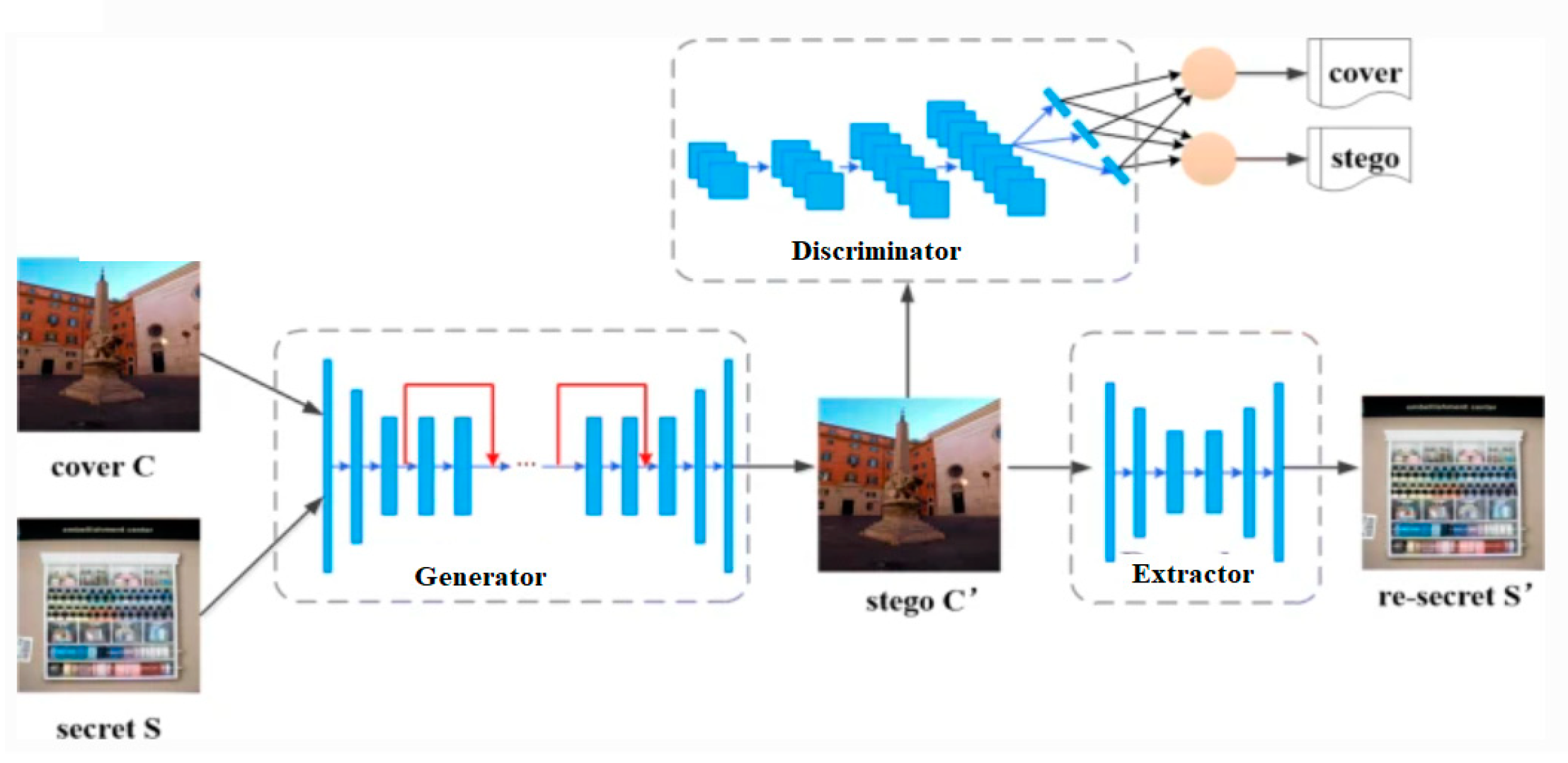
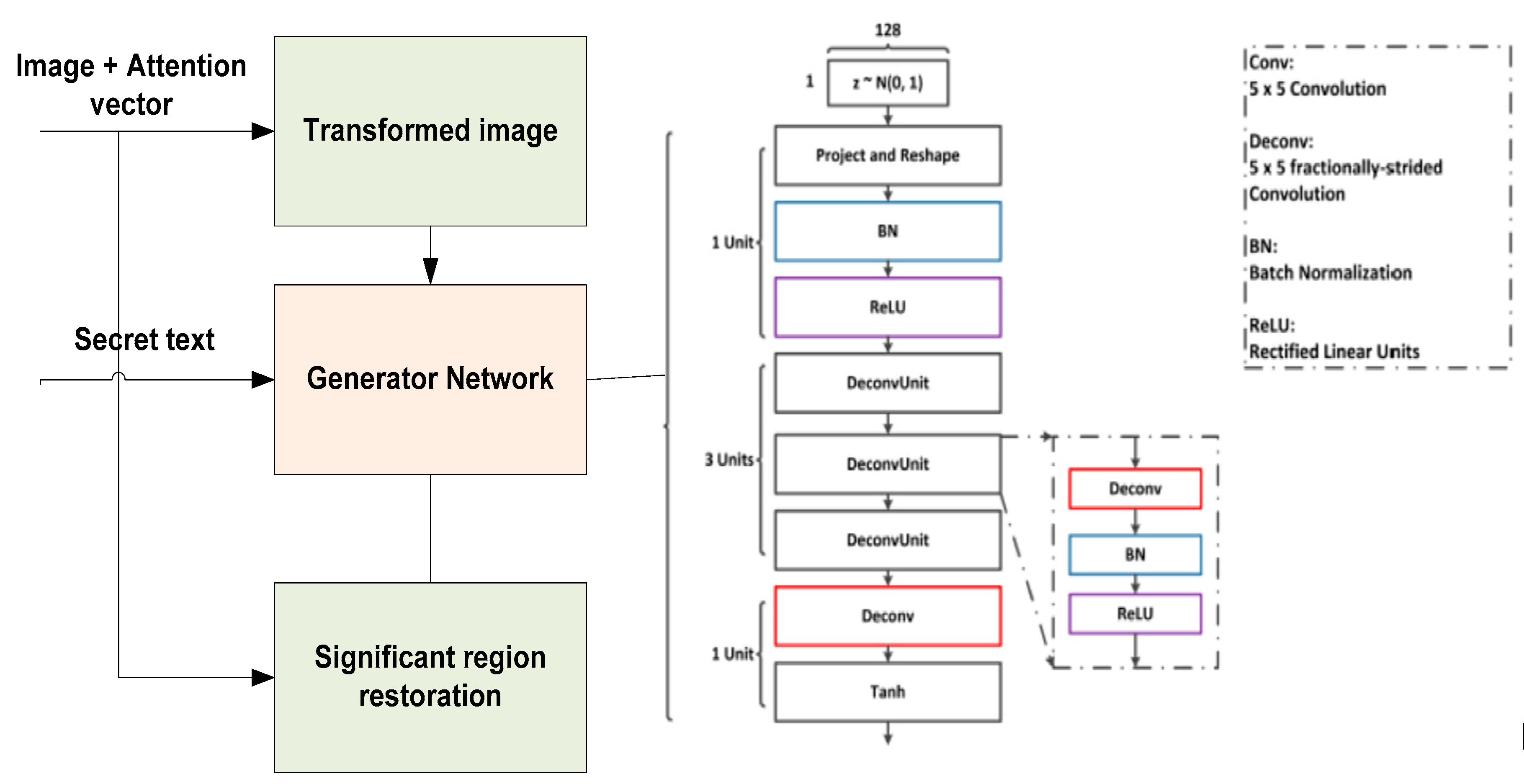
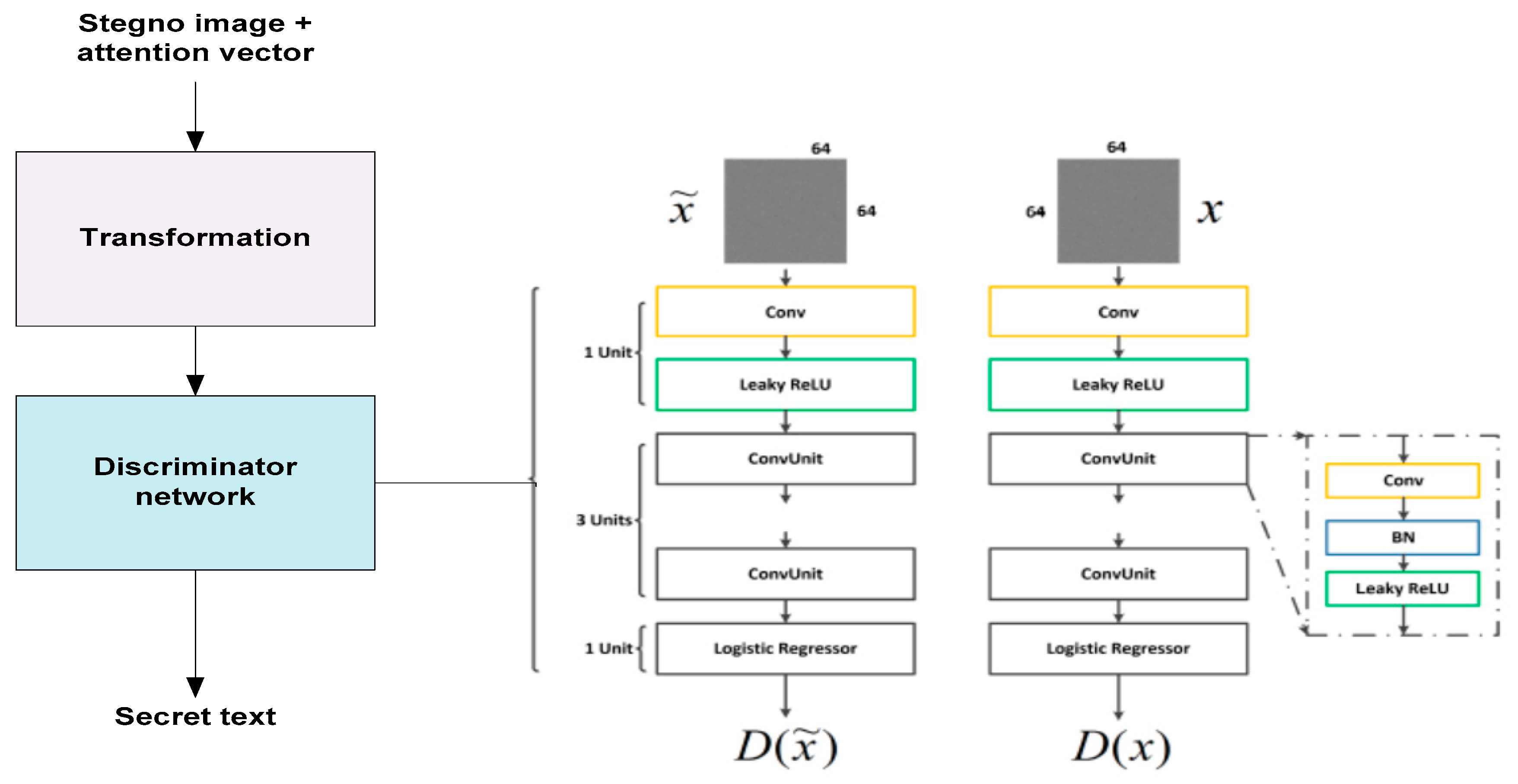
3. Attention Vector Guided GAN Steganographic Technique
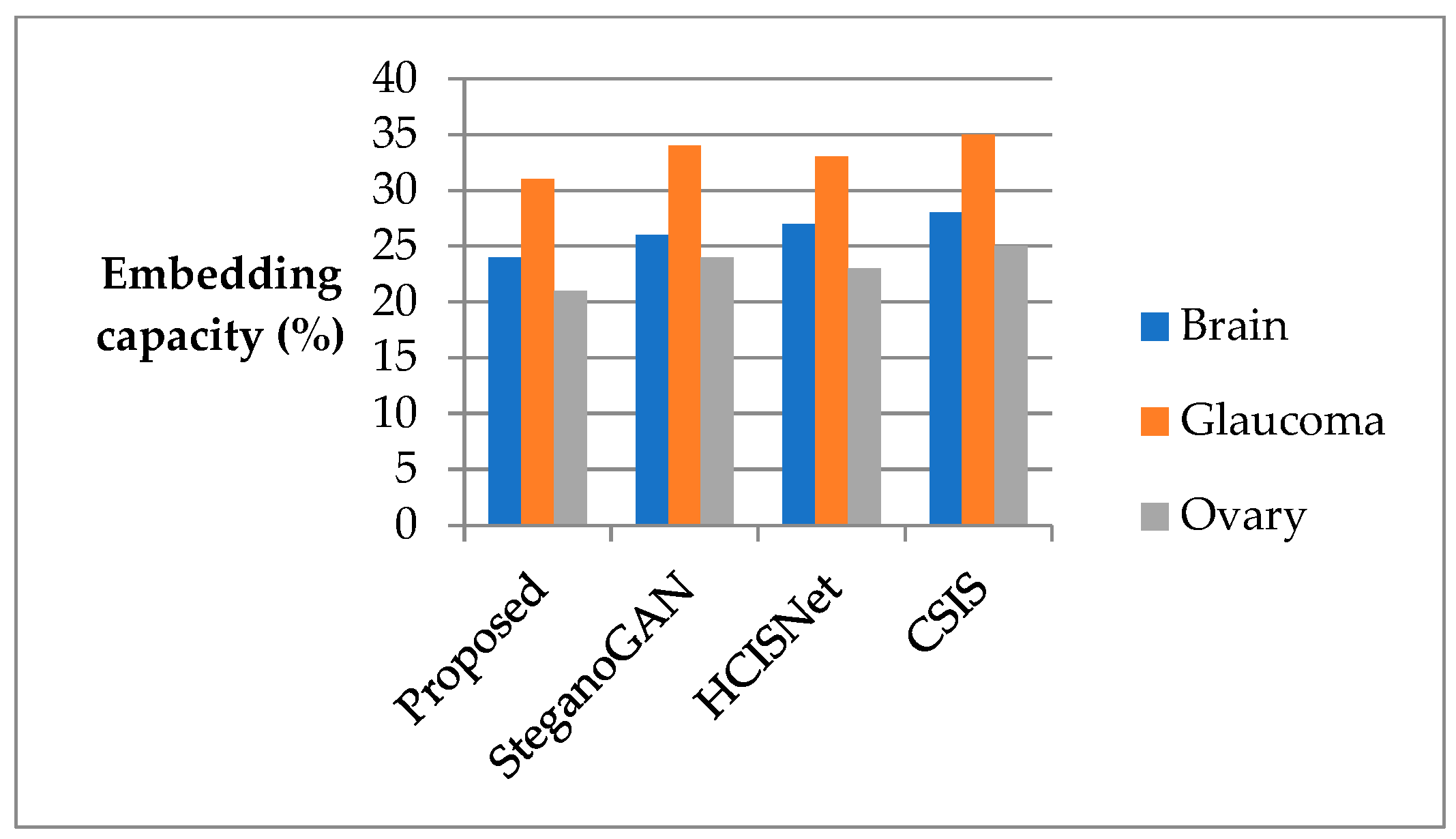
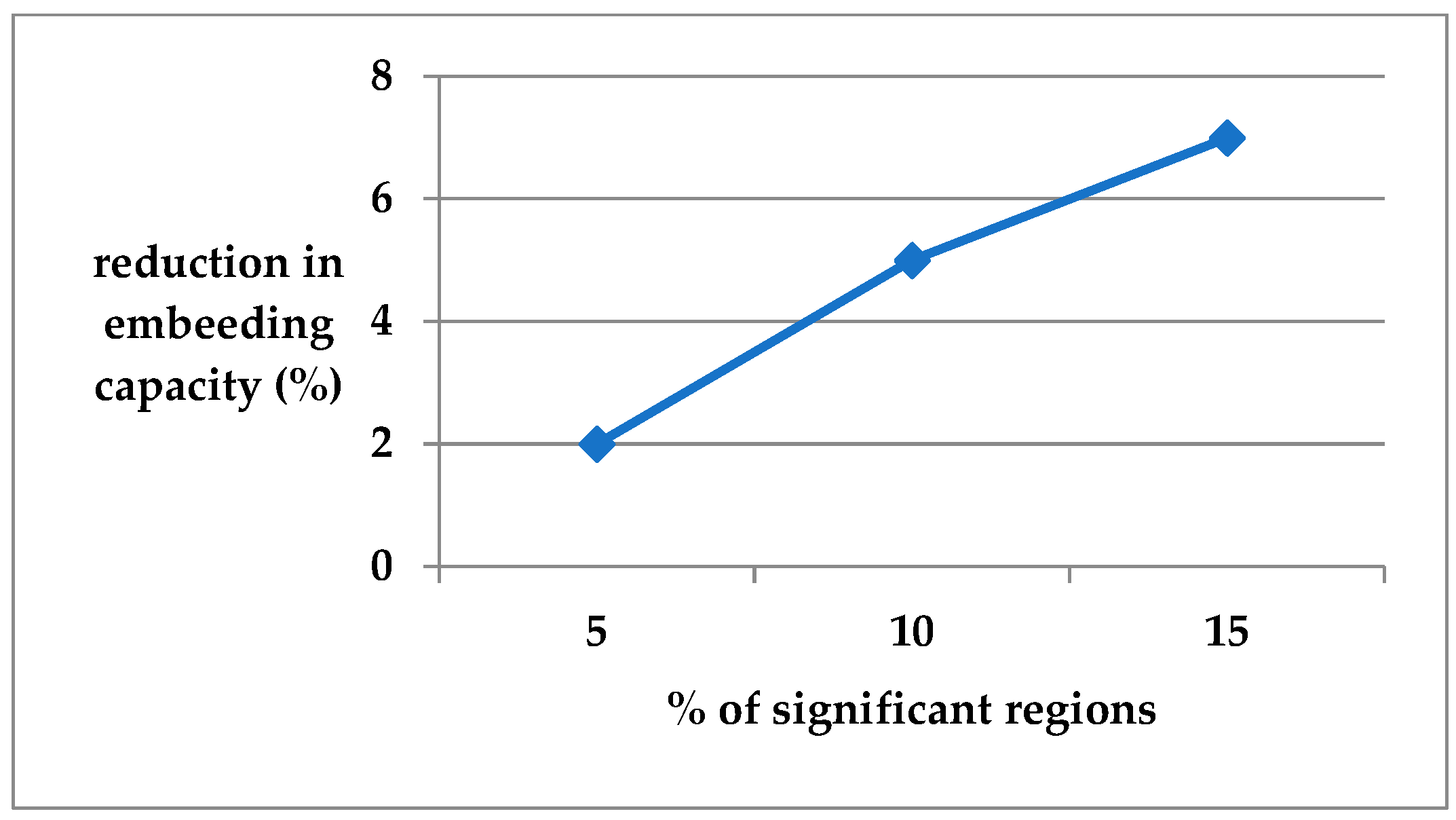
4. Result and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cachin, C. An information-theoretic model for steganography. Inf. Hiding 1998, 1525, 306–318. [Google Scholar]
- Pevný, T.; Filler, T.; Bas, P. Using high-dimensional image models to perform highly undetectable steganography. Inf. Hiding 2010, 6387, 161–177. [Google Scholar]
- Holub, V.; Fridrich, J.; Denemark, T. Universal distortion function for steganography in an arbitrary domain. EURASIP J. Inf. Secur. 2014, 1. [Google Scholar] [CrossRef]
- Holub, V.; Fridrich, J. Designing steganographic distortion using directional filters. In Proceedings of the 2012 IEEE International Workshop on Information Forensics and Security (WIFS), Costa Adeje, Spain, 2–5 December 2012; pp. 234–239. [Google Scholar]
- Fridrich, J.; Kodovský, J. Rich models for steganalysis of digital images. IEEE Trans. Inf. Forensics Secur. 2012, 7, 868–882. [Google Scholar] [CrossRef]
- Kodovský, J.; Fridrich, J. Quantitative steganalysis using rich models. Proc. SPIE 2013, 8665. [Google Scholar] [CrossRef]
- Goljan, M.; Fridrich, J.; Cogranne, R. Rich model for steganalysis of color images. In Proceedings of the 2014 IEEE International Workshop on Information Forensics and Security (WIFS), Atlanta, GA, USA, 3–5 December 2014; pp. 185–190. [Google Scholar]
- Ambika; Biradar, R.L. A robust low frequency integer wavelet transform based fractal encryption algorithm for image steganography. Int. J. Adv. Intell. Paradig. 2021, 19, 342–356. [Google Scholar]
- Zeng, J.; Tan, S.; Li, B.; Huang, J. Large-scale JPEG steganalysis using hybrid deep-learning framework. IEEE Trans. Inf. Forensics Secur. 2016, 13, 1200–1214. [Google Scholar]
- Qian, Y.; Dong, J.; Tan, T.; Wang, W. Deep learning for steganalysis via convolutional neural networks. Proc. SPIE 2015, 9409. [Google Scholar] [CrossRef]
- Barni, M. Steganography in digital media: Principles, algorithms, and applications. IEEE Signal Process. Mag. 2011, 28, 142–144. [Google Scholar] [CrossRef]
- Zhou, Z.; Sun, H.; Harit, R.; Chen, X.; Sun, X. Coverless image steganography without embedding. Proc. Int. Conf. Cloud Comput. Secur. 2015, 9483, 123–132. [Google Scholar]
- Zhou, Z.-L.; Cao, Y.; Sun, X.-M. Coverless information hiding based on bag-of-words model of image. J. Appl. Sci. 2016, 34, 527–536. [Google Scholar]
- Zheng, S.; Wang, L.; Ling, B.; Hu, D. Coverless information hiding based on robust image hashing. Intell. Comput. Methodol. 2017, 10363, 536–547. [Google Scholar] [CrossRef]
- Wu, K.-C.; Wang, C.-M. Steganography using reversible texture synthesis. IEEE Trans. Image Process. 2015, 24, 130–139. [Google Scholar] [PubMed]
- Liu, J. Recent Advances of Image Steganography With Generative Adversarial Networks. IEEE Access 2020, 8, 60575–60597. [Google Scholar]
- Xu, J. Hidden message in a deformation-based texture. Vis. Comput. Int. J. Comput. Graph. 2015, 31, 1653–1669. [Google Scholar] [CrossRef]
- Hayes, J.; Danezis, G. Generating steganographic images via adversarial training. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS’17), Long Beach, CA, USA, 4–9 December 2017; Curran Asso-ciates Inc.: Red Hook, NY, USA, 2017; pp. 1951–1960. [Google Scholar]
- Volkhonskiy, D.; Borisenko, B.; Burnaev, E. Steganographic generative adversarial networks. arXiv 2017, arXiv:1703.05502. [Google Scholar] [CrossRef]
- Tang, W.; Tan, S.; Li, B.; Huang, J. Automatic steganographic distortion learning using a generative adversarial network. IEEE Signal Process. Lett. 2017, 24, 1547–1551. [Google Scholar] [CrossRef]
- Hu, D.; Wang, L.; Jiang, W.; Zheng, S.; Li, B. A Novel Image Steganography Method via Deep Convolutional Generative Adversarial Networks. IEEE Access 2018, 6, 38303–38314. [Google Scholar] [CrossRef]
- Jiang, W.; Hu, D.; Yu, C.; Li, M.; Zhao, Z. A New Steganography Without Embedding Based on Adversarial Training. In Proceedings of the ACM Turing Celebration Conference, Hefei, China, 22–24 May 2020; pp. 219–223. [Google Scholar]
- Ke, Y.; Zhang, M.; Liu, J.; Su, T.; Yang, X. Generative steganography with Kerckhoffs’ principle. Multimed. Tools Appl. 2019, 78, 13805–13818. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Advances. Neural Inf.-Tion Process. Syst. 2014, 3, 2672–2680. [Google Scholar]
- Available online: https://www.kaggle.com/navoneel/brain-mri-images-for-brain-tumor-detection (accessed on 8 January 2022).
- Available online: https://www.kaggle.com/datasets/sshikamaru/glaucoma-detection (accessed on 8 January 2022).
- Available online: https://www.ultrasoundcases.info/ (accessed on 8 January 2022).
- Zhang, K.A.; Cuesta-Infante, A.; Xu, L. SteganoGAN: High capacity image steganography with GANs. arXiv 2019, arXiv:1901.03892. [Google Scholar]
- Wang, Z.; Gao, N.; Wang, X.; Xiang, J.; Zha, D.; Li, L. HidingGAN: High Capacity Information Hiding with Generative Adversarial Network. Comput. Graph. Forum. 2019, 38, 393–401. [Google Scholar] [CrossRef]
- Agrawal, R.; Ahuja, K. CSIS: Compressed sensing-based enhanced-embedding capacity image steganography scheme. IET Image Proc. 2021, 15, 1909–1925. [Google Scholar]
- Virupakshappa, A.B. An approach of using spatial fuzzy and level set method for brain tumor segmentation. Int. J. Tomogr. Simul. 2018, 31, 18–33. [Google Scholar]
- Patil, V.; Saxena, J.; Vineetha, R.; Paul, R.; Shetty, D.K.; Sharma, S.; Smriti, K.; Singhal, D.K.; Naik, N. Age assessment through root lengths of mandibular second and third permanent molars using machine learning and Artificial Neural Networks. J. Imaging 2023, 9, 33. [Google Scholar] [CrossRef]
- Rangayya; Virupakshappa; Patil, N. Improved face recognition method using SVM-MRF with KTBD based KCM segmentation approach. Int. J. Syst. Assur. Eng. Manag. 2022, 1–12. [Google Scholar] [CrossRef]
- Lim, S.J. Hybrid image embedding technique using Steganographic Signcryption and IWT-GWO methods. Microprocess. Microsyst. 2022, 95, 104688. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Brain Image | Glaucoma Image | Ovarian Image | |||
|---|---|---|---|---|---|
| Tumour | Normal | Glaucoma | Healthy | Cancer | Normal |
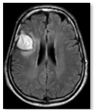 | 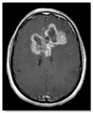 | 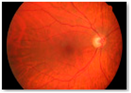 | 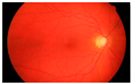 | 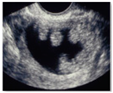 | 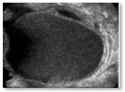 |
| Brain Image Dataset | Glaucoma Image Dataset | Ovarian Image Dataset | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR | RS-BPP | WPSNR | SSIM | PSNR | RS-BPP | WPSNR | SSIM | PSNR | RS-BPP | WPSNR | SSIM | |
| Proposed | 39.96 | 6.28 | 38.42 | 0.98 | 39.56 | 6.63 | 39.42 | 0.98 | 39.96 | 6.61 | 39.72 | 0.98 |
| SteganoGAN | 36.46 | 4.33 | 35.61 | 0.84 | 36.21 | 4.13 | 35.41 | 0.85 | 36.21 | 4.13 | 35.51 | 0.82 |
| HCISNet | 38.87 | 5.67 | 37.12 | 0.92 | 38.77 | 5.17 | 37.32 | 0.94 | 38.89 | 5.52 | 37.22 | 0.94 |
| CSIS | 33.80 | 2.06 | 32.34 | 0.94 | 33.82 | 2.03 | 32.84 | 0.95 | 33.82 | 2.17 | 32.14 | 0.96 |
| Brain tumour dataset | Mode 1 | Mode 2 | |||||||
| Accuracy | Precision | Recall | MCC | Accuracy | Precision | Recall | MCC | ||
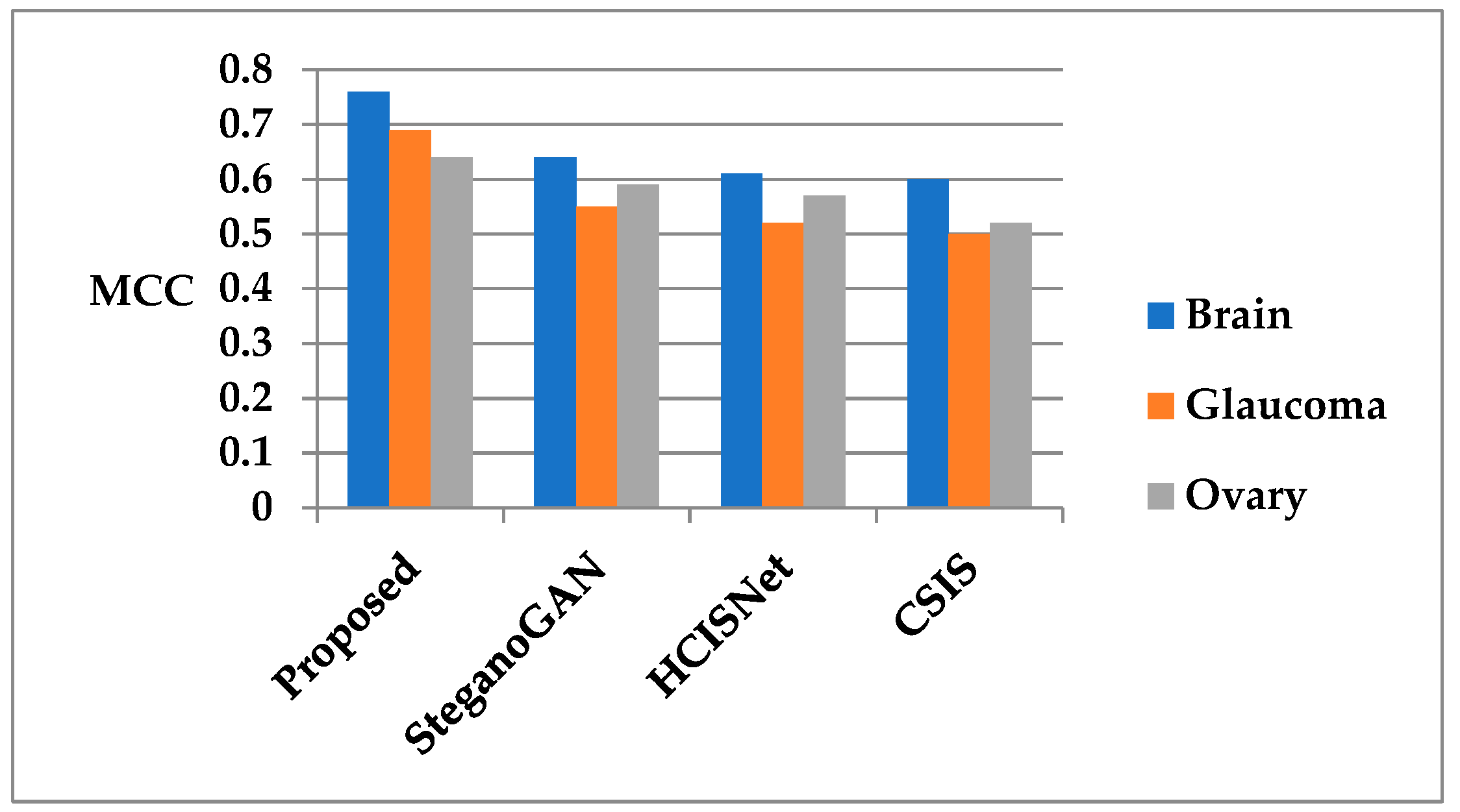
| Proposed | 96 | 97 | 94 | 0.76 | 97 | 98 | 94 | 0.8 | |
| SteganoGAN | 94 | 93 | 91 | 0.64 | 97 | 98 | 94 | 0.8 | |
| HCISNet | 93 | 92 | 90 | 0.61 | 97 | 98 | 94 | 0.8 | |
| CSIS | 92 | 93 | 90 | 0.60 | 97 | 98 | 94 | 0.8 | |
| Glaucoma dataset | Mode 1 | Mode 2 | |||||||
| Accuracy | Precision | Recall | MCC | Accuracy | Precision | Recall | MCC | ||
| Proposed | 94 | 95 | 89 | 0.69 | 96 | 97 | 92 | 0.72 | |
| SteganoGAN | 91 | 93 | 87 | 0.55 | 96 | 97 | 92 | 0.72 | |
| HCISNet | 90 | 92 | 86 | 0.52 | 96 | 97 | 92 | 0.72 | |
| CSIS | 89 | 91 | 85 | 0.50 | 96 | 97 | 92 | 0.72 | |
| Ovarian dataset | Mode 1 | Mode 2 | |||||||
| Accuracy | Precision | Recall | MCC | Accuracy | Precision | Recall | MCC | ||
| Proposed | 92 | 91 | 87 | 0.64 | 93 | 91 | 89 | 0.66 | |
| SteganoGAN | 90 | 90 | 86 | 0.59 | 93 | 91 | 89 | 0.66 | |
| HCISNet | 89 | 90 | 84 | 0.57 | 93 | 91 | 89 | 0.66 | |
| CSIS | 87 | 88 | 83 | 0.52 | 93 | 91 | 89 | 0.66 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ambika; Virupakshappa; Uplaonkar, D.S. Deep Learning-Based Coverless Image Steganography on Medical Images Shared via Cloud. Eng. Proc. 2023, 59, 176. https://doi.org/10.3390/engproc2023059176
Ambika, Virupakshappa, Uplaonkar DS. Deep Learning-Based Coverless Image Steganography on Medical Images Shared via Cloud. Engineering Proceedings. 2023; 59(1):176. https://doi.org/10.3390/engproc2023059176
Chicago/Turabian StyleAmbika, Virupakshappa, and Deepak S. Uplaonkar. 2023. "Deep Learning-Based Coverless Image Steganography on Medical Images Shared via Cloud" Engineering Proceedings 59, no. 1: 176. https://doi.org/10.3390/engproc2023059176
APA StyleAmbika, Virupakshappa, & Uplaonkar, D. S. (2023). Deep Learning-Based Coverless Image Steganography on Medical Images Shared via Cloud. Engineering Proceedings, 59(1), 176. https://doi.org/10.3390/engproc2023059176