
Multi-Modal Human Action Segmentation Using Skeletal Video Ensembles †


Abstract
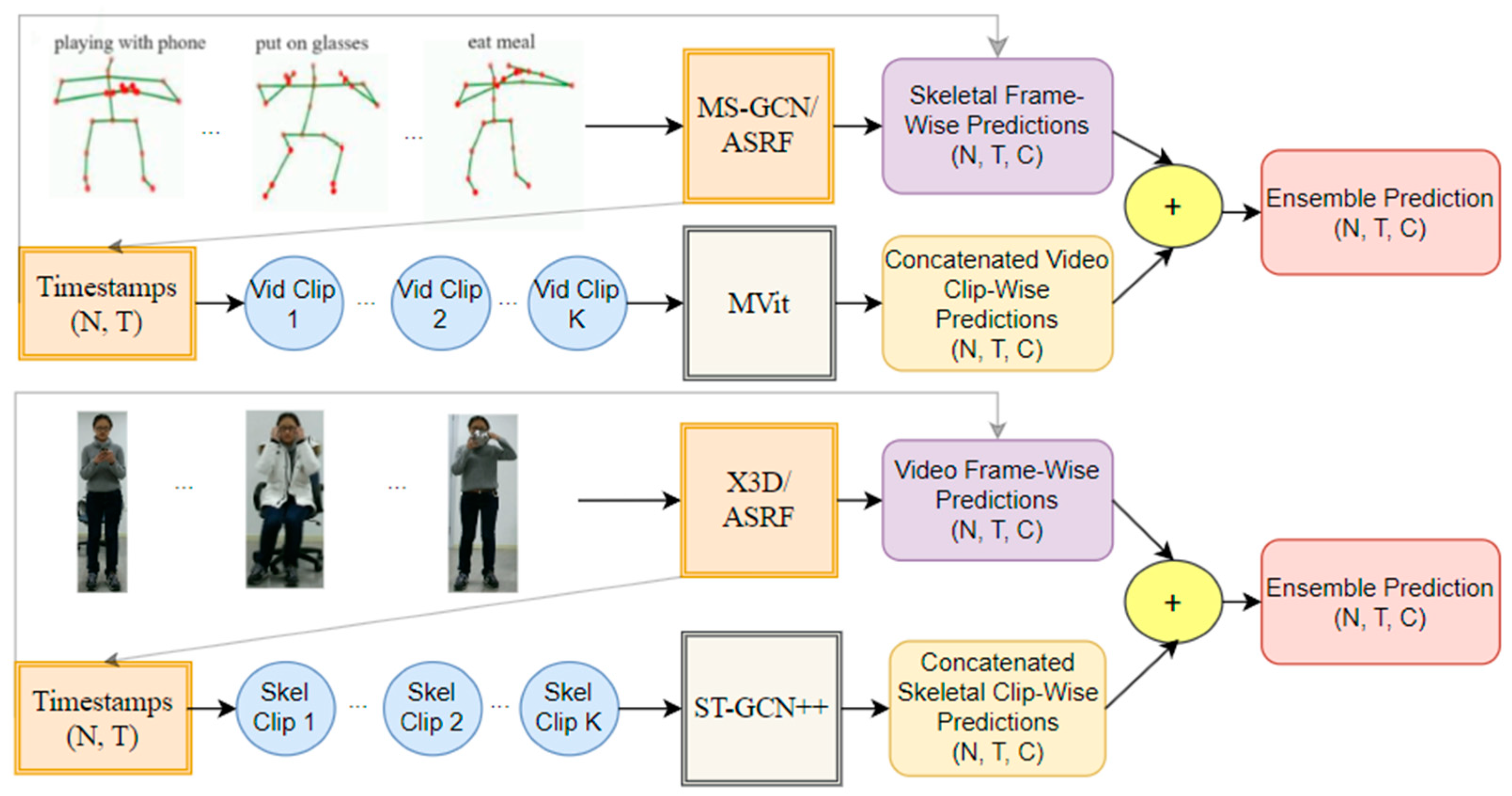
:1. Introduction
- A skeletal segmentation approach that predicts both frame-wise labels and timestamps, using a video classification model to refine predictions.
- A video segmentation approach which predicts both frame-wise labels and timestamps, using a skeletal action recognition model to refine predictions.
- An ensemble of video and skeletal models, each employing their own timestamp-based refinements, to predict frame-wise labels.
2. Methods
2.1. Skeletal Segmentation and Video Classification Ensemble
2.2. Skeletal Classification and Video Segmentation Ensemble
2.3. Skeletal and Video Segmentation Ensemble
3. Experimental Validation
3.1. Experiments
3.2. Results and Discussion
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, J.; Shahroudy, A.; Perez, M.; Wang, G.; Duan, L.-Y.; Kot, A.C. NTU RGB+D 120: A Large-Scale Benchmark for 3D Human Activity Understanding. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2684–2701. [Google Scholar] [CrossRef] [PubMed]
- Liu, C.; Hu, Y.; Li, Y.; Song, S.; Liu, J. PKU-MMD: A Large Scale Benchmark for Continuous Multi-Modal Human Action Understanding. In Proceedings of the Workshop on Visual Analysis in Smart and Connected Communities, Mountain View, CA, USA, 23 October 2017; pp. 1–8. [Google Scholar]
- Yan, S.; Xiong, Y.; Lin, D. Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar] [CrossRef]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Skeleton-Based Action Recognition With Multi-Stream Adaptive Graph Convolutional Networks. IEEE Trans. Image Process. 2020, 29, 9532–9545. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Zhang, Z.; Yuan, C.; Li, B.; Deng, Y.; Hu, W. Channel-wise topology refinement graph convolution for skeleton-based action recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 13359–13368. [Google Scholar]
- Duan, H.; Wang, J.; Chen, K.; Lin, D. PYSKL: Towards Good Practices for Skeletal Action Recognition. In Proceedings of the 30th ACM International Conference on Multimedia, Lisbon, Portugal, 10–14 October 2022; pp. 7351–7354. [Google Scholar]
- Carreria, J.; Zisserman, A. Quo Vadis, Action Recognition? A new Model and the Kinetics Dataset. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4724–4733. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning Spatiotemporal Features with 3D Convolutional Networks. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Tran, D.; Wang, H.; Torresani, L.; Ray, J.; LeCun, Y.; Paluri, M. A closer look at spatiotemporal convolutions for action recognition. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 6450–6459. [Google Scholar]
- Feichtonhofer, C. X3D: Expanding Architectures for Efficient Video Recognition. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Fan, H.; Xiong, B.; Mangalam, K.; Li, Y.; Yan, Z.; Malik, J.; Feichtenhofer, C. Multiscale vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Abu Farha, Y.; Gall, J. MS-TCN: Multi-Stage Temporal Convolutional Network for Action Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Li, S.; Abu Farha, Y.; Liu, Y.; Cheng, M.M.; Gall, J. MS-TCN++ Multi-Stage Temporal Convolutional Network for Action Segmentation. arXiv 2020, arXiv:2006.09220. [Google Scholar] [CrossRef] [PubMed]
- Ishikawa, Y.; Kasai, S.; Aoki, Y.; Kataoka, H. Alleviating Over-segmentation Errors by Detection Action Boundaries. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2021; pp. 2321–2330. [Google Scholar]
- Filtjens, B.; Vanrumste, B.; Slaets, P. Skeleton-Based Action Segmentation with Multi-Stage Spatial-Temporal Graph Convolutional Neural Networks. arXiv 2022, arXiv:2202.01727. [Google Scholar] [CrossRef]

{kind=link}
| Model | Framewise Acc (%) | Segment F1@50 | Timestamp—F1 |
|---|---|---|---|
| MS-GCN/ASRF only (Skeletal Segmentation) | 84.0 | 60.7 | 77.7 |
| X3D/ASRF only (Video Segmentation) | 82.2 | 73.1 | 64.1 |
| MS-GCN/ASRF + MVit (Skeletal Segmentation + Video Classification) | 84.6 | 60.7 | 77.7 |
| X3D/ASRF + ST-GCN++ (Video Segmentation + Skeletal Classification) | 82.6 | 74.4 | 64.1 |
| MS-GCN/ASRF + X3D/ASRF (Skeletal Segmentation + Video Segmentation) | 87.0 | 68.7 | 79.0 |
| Model | Framewise Acc (%) | Segment F1@50 | Timestamp—F1 |
|---|---|---|---|
| MS-GCN/ASRF only (Skeletal Segmentation) | 88.4 | 68.8 | 77.4 |
| X3D/ASRF only (Video Segmentation) | 76.4 | 64.4 | 61.9 |
| MS-GCN/ASRF + MVit (Skeletal Segmentation + Video Classification) | 89.2 | 70.1 | 77.4 |
| X3D/ASRF + ST-GCN++ (Video Segmentation + Skeletal Classification) | 75.1 | 65.8 | 61.9 |
| MS-GCN/ASRF + X3D/ASRF (Skeletal Segmentation + Video Segmentation) | 88.4 | 74.5 | 79.5 |
| Model | Framewise Acc (%) | Segment F1@50 |
|---|---|---|
| MS-GCN [15] | 68.5 | 51.6 |
| MS-GCN/ASRF + X3D/ASRF (Skeletal Segmentation + Video Segmentation) | 87.0 | 68.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dickens, J.; Payeur, P. Multi-Modal Human Action Segmentation Using Skeletal Video Ensembles. Eng. Proc. 2023, 58, 30. https://doi.org/10.3390/ecsa-10-16257
Dickens J, Payeur P. Multi-Modal Human Action Segmentation Using Skeletal Video Ensembles. Engineering Proceedings. 2023; 58(1):30. https://doi.org/10.3390/ecsa-10-16257
Chicago/Turabian StyleDickens, James, and Pierre Payeur. 2023. "Multi-Modal Human Action Segmentation Using Skeletal Video Ensembles" Engineering Proceedings 58, no. 1: 30. https://doi.org/10.3390/ecsa-10-16257
APA StyleDickens, J., & Payeur, P. (2023). Multi-Modal Human Action Segmentation Using Skeletal Video Ensembles. Engineering Proceedings, 58(1), 30. https://doi.org/10.3390/ecsa-10-16257