2.1.1. Design Flow of Mel-Frequency Cepstral Coefficients
The participants of the Hua Chao opera singing -evaluation system were students in grades 3 to 5, and the collected sample data were divided into training and testing audio sets. A total of 20,316 audio items with a chanting style were collected from the training set, while there were 4060 audio items from the training set with a fast singing style and 10,084 audio items from the training set with a traditional singing style. After the audio storage paths of the files were obtained, the labels of the speech signals, i.e., the specific feedback of the three singing voices, were imported.
- 2.
Specific implementation of MFCC coefficient generation speech signal model
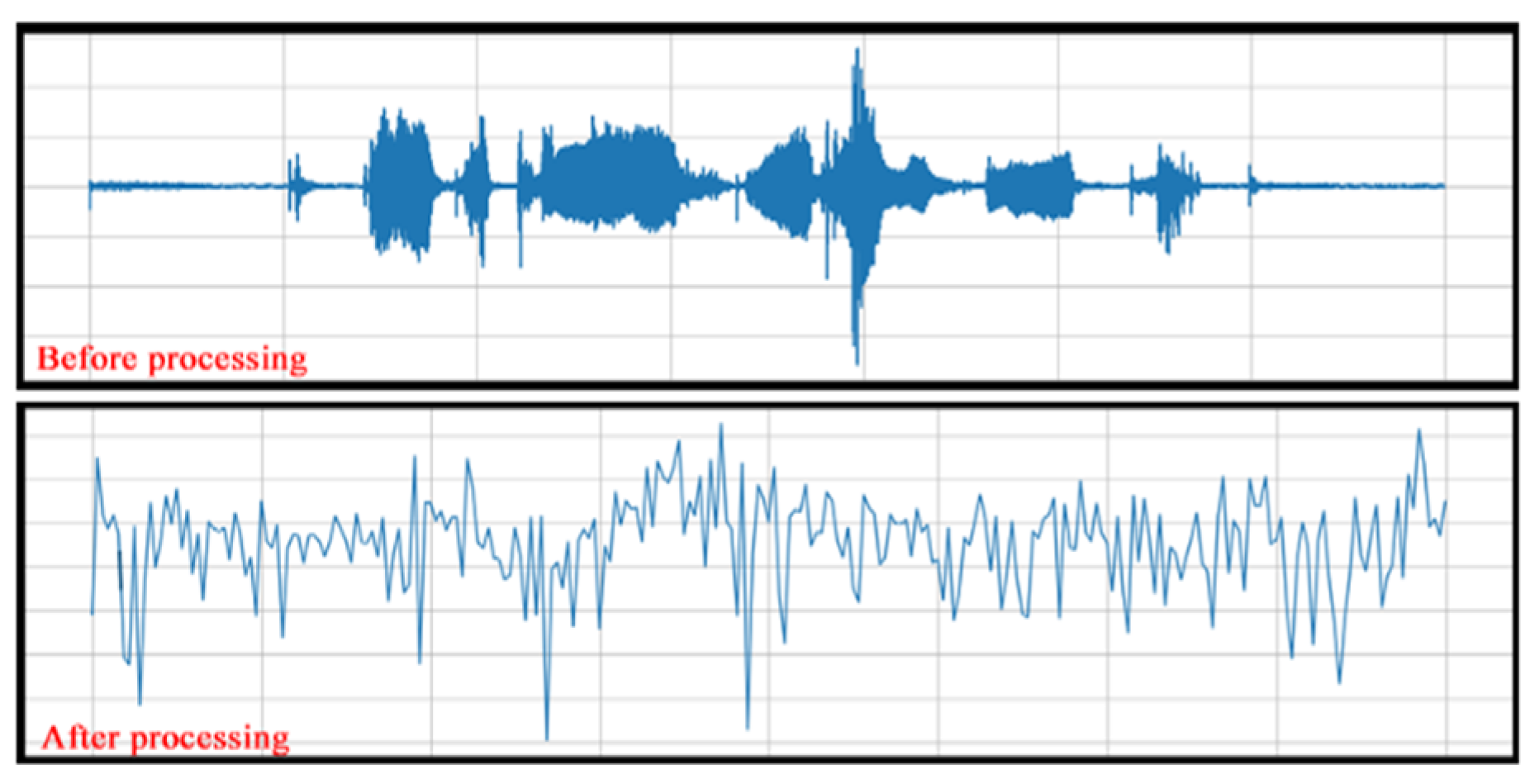
After the training set of audio sample data of Hua Chao opera was obtained, the continuous speech signals with a 16 KHz sampling frequency in 1 s were needed to improve the high-frequency part to reduce the noise output of the pre-emphasized overlapped sampling points to reduce the change in frame number in the sub-frame and increase the continuity of the left and right ends of the frame. Then, the spectral leakage of the plus window was reduced, and the time domain signal was converted into frequency domain energy to better observe the signal characteristics of the fast Fourier transform. The speech signal envelope and spectral details were extracted to obtain the sound properties of the cepstrum analysis using five processing methods. Finally, the speech signal model was generated to be used in the Heyuan Hua Chao opera singing-evaluation system (
Figure 1).
The sound interval of Hua Chao opera, such as more step-in, less jump-in, regular rhythm, and high-frequency signal transmission, can easily weaken [
2]. Based on the audio sample collection of vocal skills, volume, environment, and radio effect, the signal frequency varies, and a large number of speech signals are piled up in the low-frequency and high-frequency parts. The low-frequency part of the value gap is the large spectrum tilt (Spectral Tilt). The speech signal was taken through a high-pass filter method, a differential first-order signal value to reduce the high-frequency part (high-frequency change position) differential value and increase the low-frequency part (low-frequency change position) differential value so that the speech spectrum maintained a stable state (
Figure 2, Equation (1)).
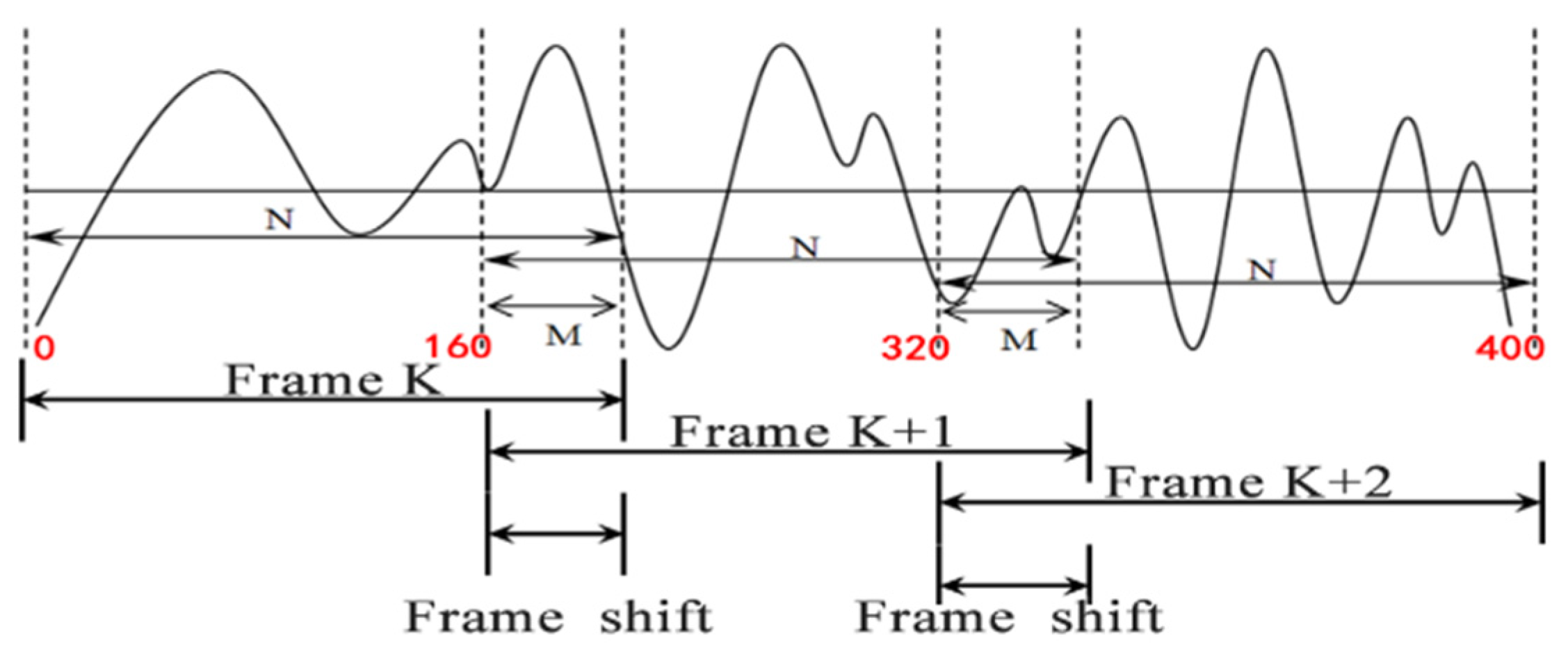
The voice in Hua Chao opera is simple and healthy, the lyrics are catchy, and the voice signal changes slowly. The frequency in the voice signal after pre-emphasis becomes unstable with the change in time, so it needs to be processed in frames. However, the length of frames must not be too long or short. An excessive length reduces the time resolution, while a short length aggravates the cost of operation. As the speech signal sampling frequency was 16 kHz, the standard resolution was 25 ms, and the frame length of 16 kHz signal had 0.025 × 16,000 = 400 samples (the chart unit is N). As the frameshift in the speech signal is usually 10 ms, there were 0.01 × 16,000 = 160 samples in the frame [
3]. The difference between frame length and frameshift in the overlapping area in the speech signal, the so-called “frame iteration”, accounted for about 1/3 of each frame, that is, 400 – 160 = 240 samples (the chart unit is M). The main role of the 240 samples was to maintain the frame number difference. The starting value of the speech frame with 400 sample points was 0, the starting value of the second speech frame was 160, and the starting value of the third speech frame was 320 (
Figure 3). According to this rule, the frames were divided until the end of the speech signal.
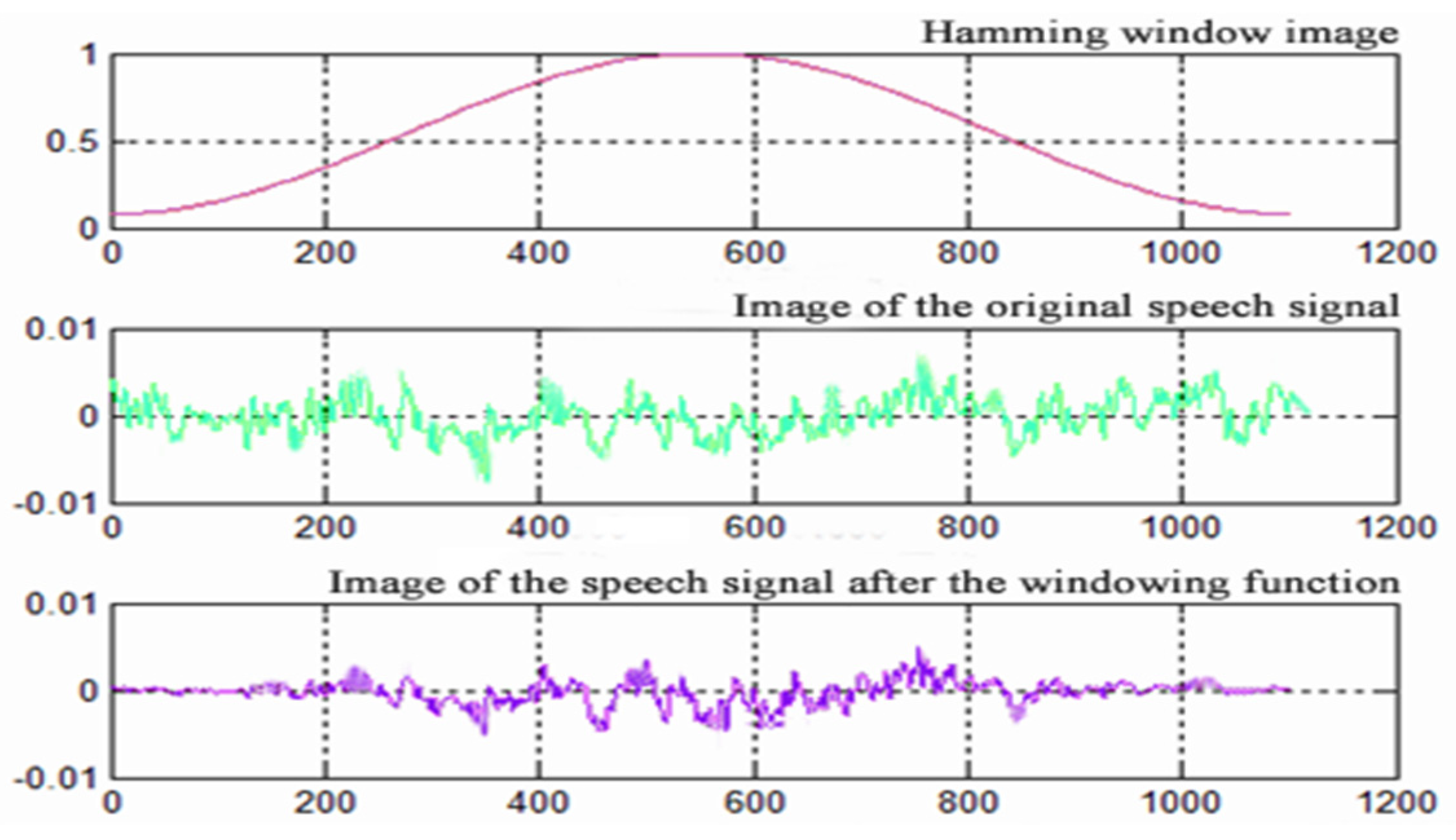
The speech signal of Hua Chao opera is a time series, but the middle domain values are disconnected when carrying out the frame splitting process, which causes the spectral leakage phenomenon. Considering the long-time fluctuation of the speech signal and the disconnection of the endpoints, it is necessary to process its fixed characteristics. Each frame number is substituted into the Hamming Windows function (Hamming Windows), which truncates the original speech sample signal with amplitude–frequency to achieve the finite speech signal and then supplements the continuity of the left end and right end of the frame. By formulating the out-of-window value of the Hamming Windows function as 0 (based on Equation (2)), one takes a generic 0.46 and applies the function to each frame number, the sharp angle in the truncated finite speech signal is blunted, and the waveform amplitude slowly tapers to 0, thus reducing the truncation effect of the speech frames (
Figure 4).
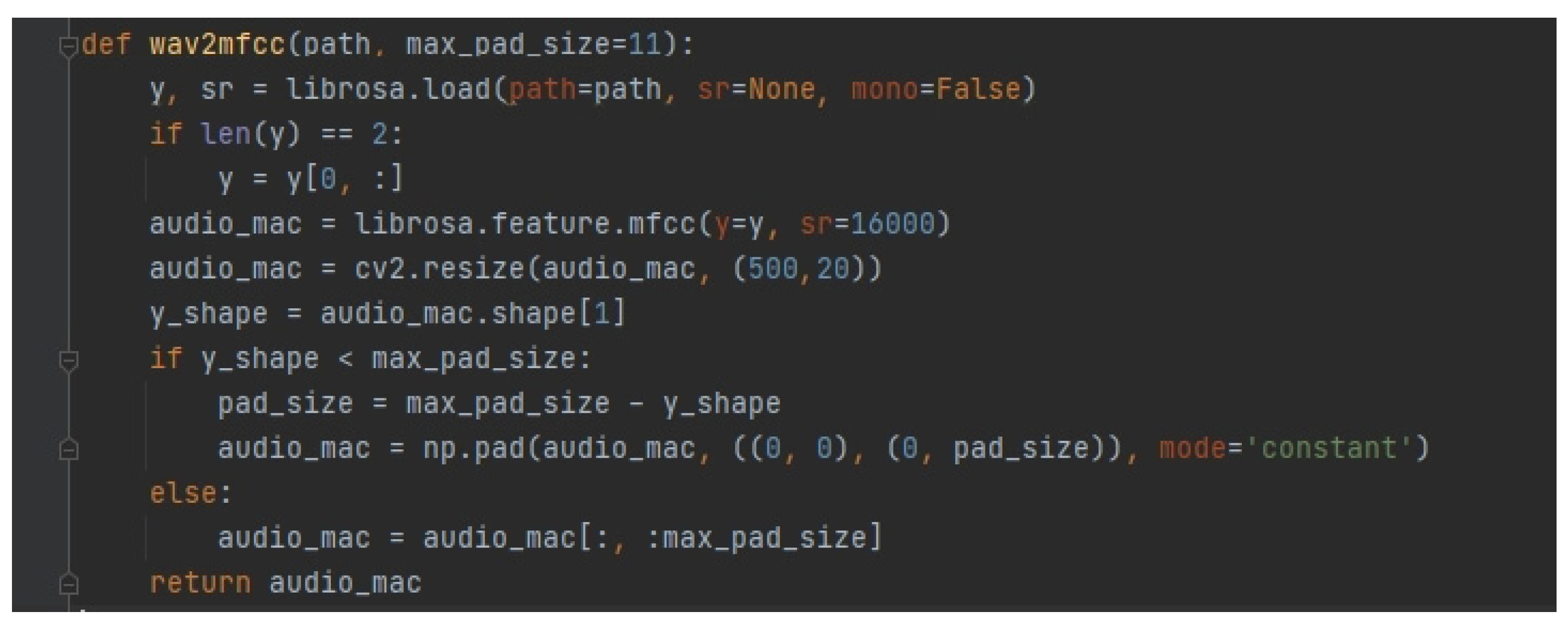
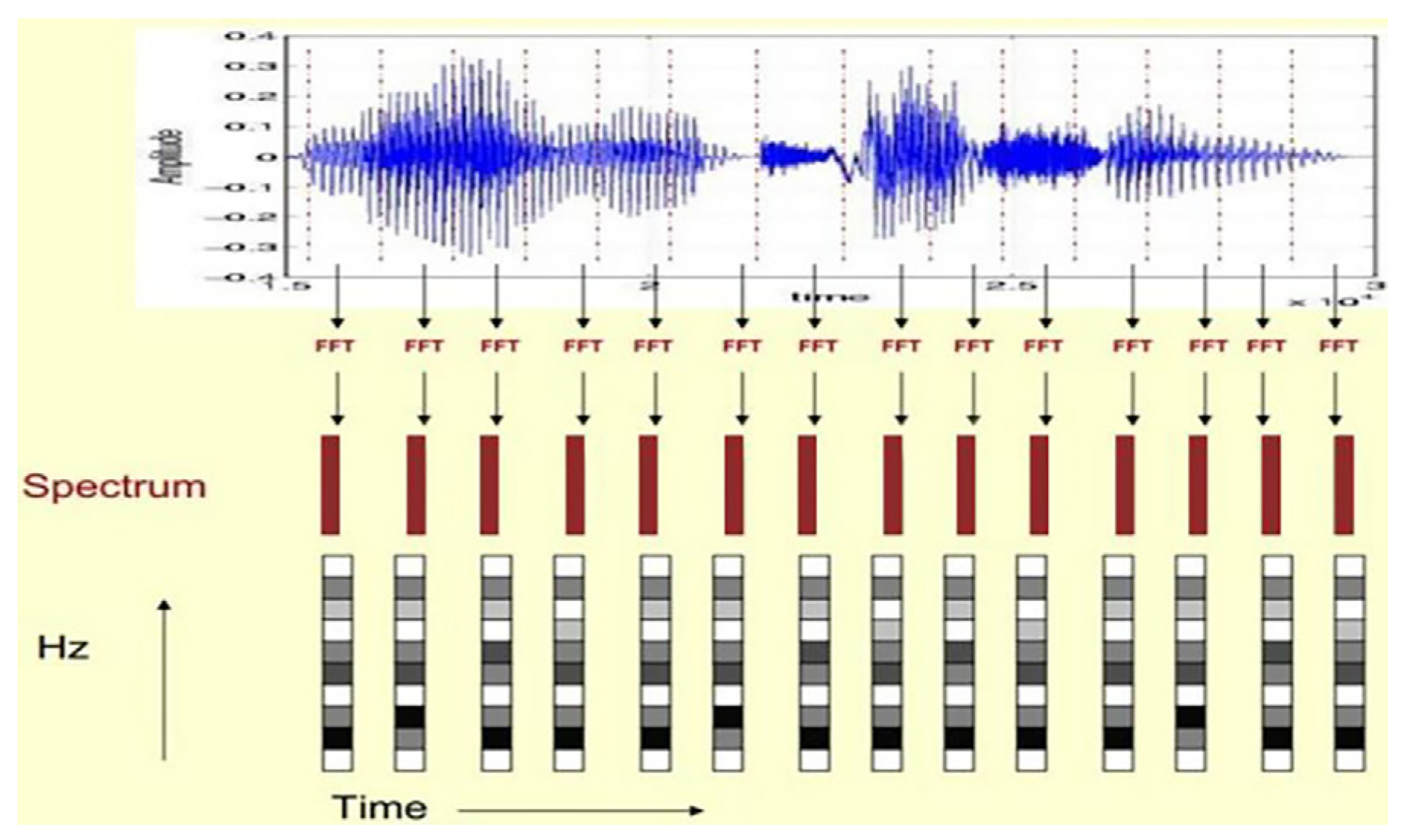
After the speech signal is substituted into the Hamming window function, the individual frames in the signal need to be fast-Fourier-transformed, because the melodic direction of the Hua Dynasty opera tune is rich and variable. It is more difficult to capture its dynamic information when the speech signal belongs to the one-dimensional signal. Thus, the time-domain information cannot be seen as frequency-domain information. Therefore, the speech signal must be processed and output into a 500 × 20 two-dimensional matrix model group as the MFCC matrix model generation code (
Figure 5). After that, the speech signal is arranged according to frame, and each frame of speech corresponds to a spectrum using coordinates. In the horizontal coordinate, the duration and vertical coordinate become the decibels of the sound, indicating the relationship between frequency and energy. The amplitude of the speech signal is mapped to a gray-level embodiment, and the amplitude value is proportional to the corresponding gray area. The larger the amplitude value, the darker the corresponding area. The display duration of the speech spectrum is increased to obtain a change over time depicting the sound spectrum of the speech signal (
Figure 6 and
Figure 7). By doing this, its energy distribution on the spectrum is obtained, and the influence of frequency points higher than the sampled signal is removed to make static and dynamic information parameters more intuitive for the improved robustness of speech signal data acquisition.
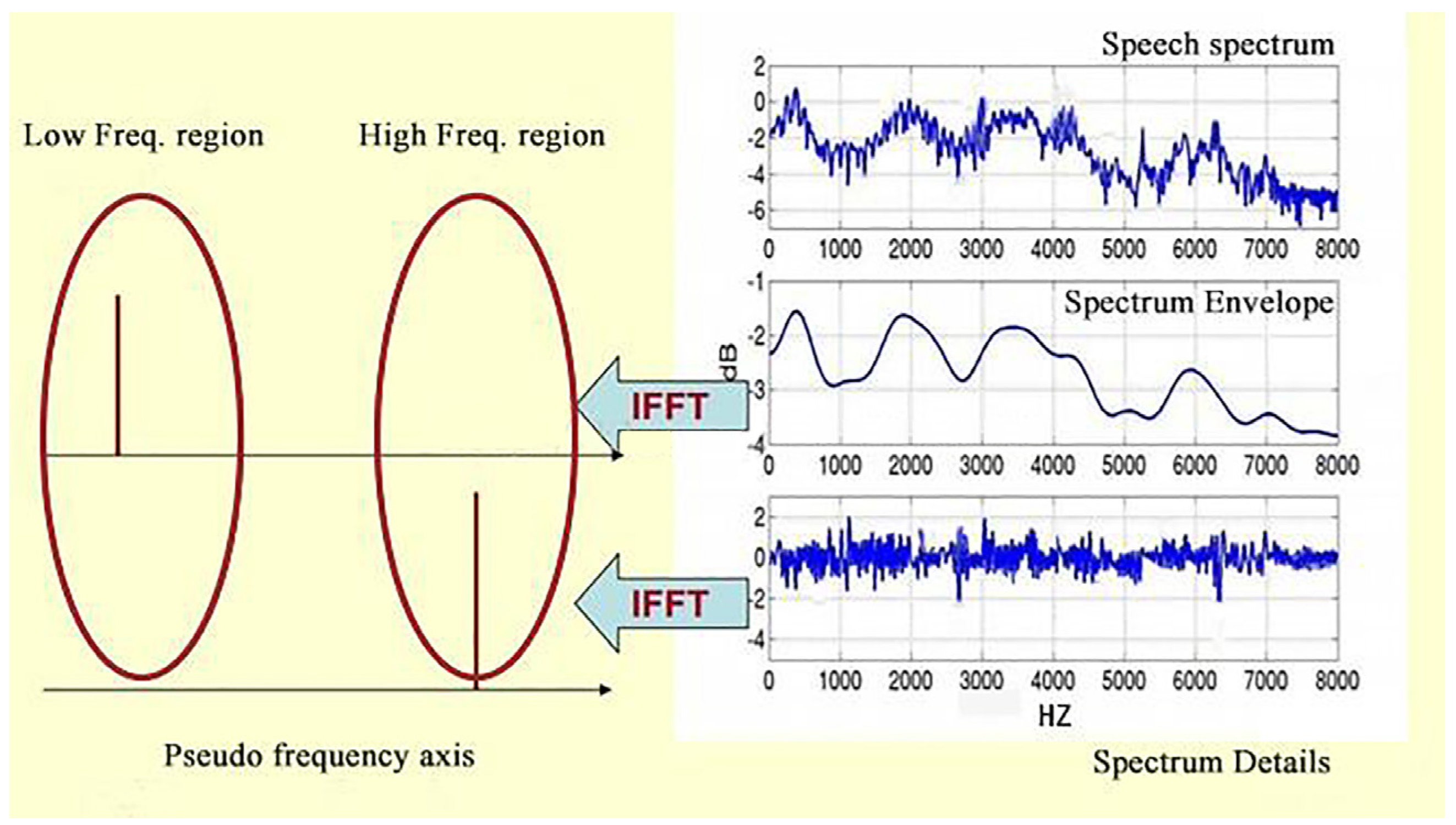
Since Hua Chao opera is sung in the Zijin dialect and its transcription recognition is poor, it is important to perform cepstral analysis on speech signals to extract speech components. The peak resonance peaks on the speech spectrogram carry important sound-recognition properties, while the smooth curve connecting the resonance peaks is called the envelope [
4]. To better identify the acoustic properties of the speech signal, the envelope needs to be separated from the peaks using inverse spectral analysis. Considering the peak as a detail of the spectrum, the horizontal axis is considered as the envelope E of the low-frequency component, which is considered as a sinusoidal signal with four cycles per second, giving a peak at 4 Hz on the coordinate axis. The vertical axis is the spectral detail H[k] of the high-frequency component, which is considered as a sinusoidal signal with 100 cycles. A peak is assigned to the position of 4 Hz on the pseudo-coordinate axis. The vertical axis is the spectral detail of the high-frequency component, H[k], viewed as a sinusoidal signal with 100 cycles per second, and a peak is assigned at 100 Hz on the coordinate axis (
Figure 8).
Firstly, the multiplicative signal (x[k]) is turned into a multiplicative signal via the convolution of the two superpositions; then, the multiplicative signal is transformed into an additive signal by taking the logarithm. Finally, an inverse transformation is performed, and the additive signal is restored to a convolutive signal, which is returned to the matrix model to generate a new speech signal model (
Figure 9).
- 3.
Accuracy testing of speech signal training models
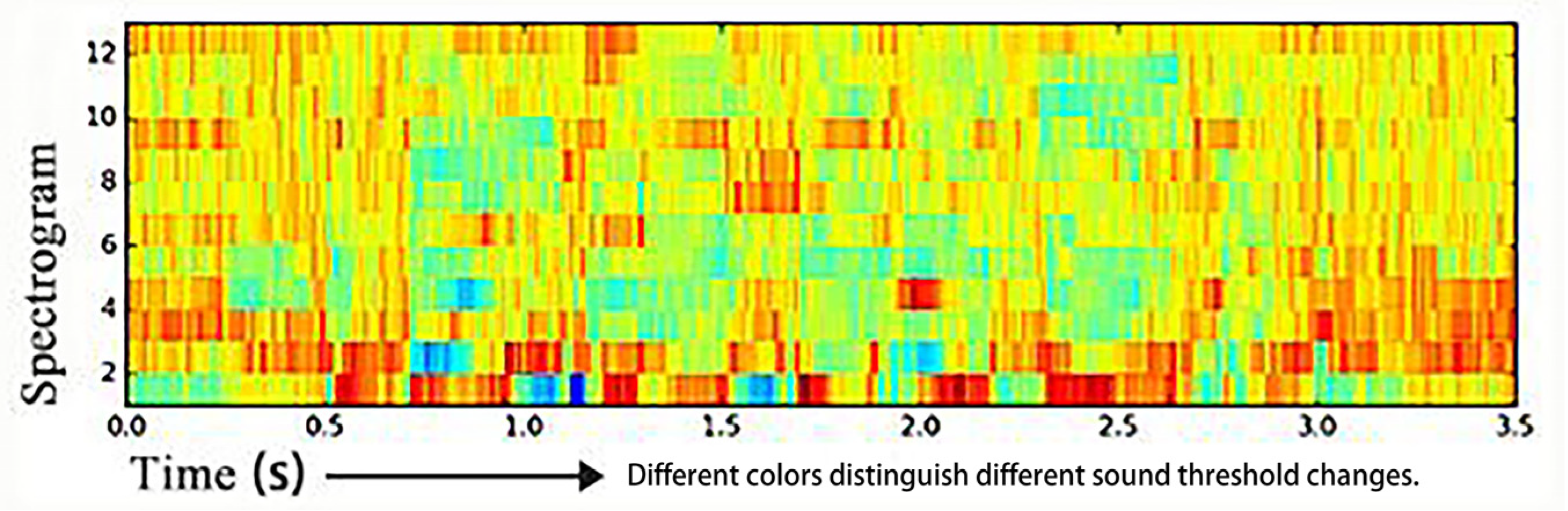
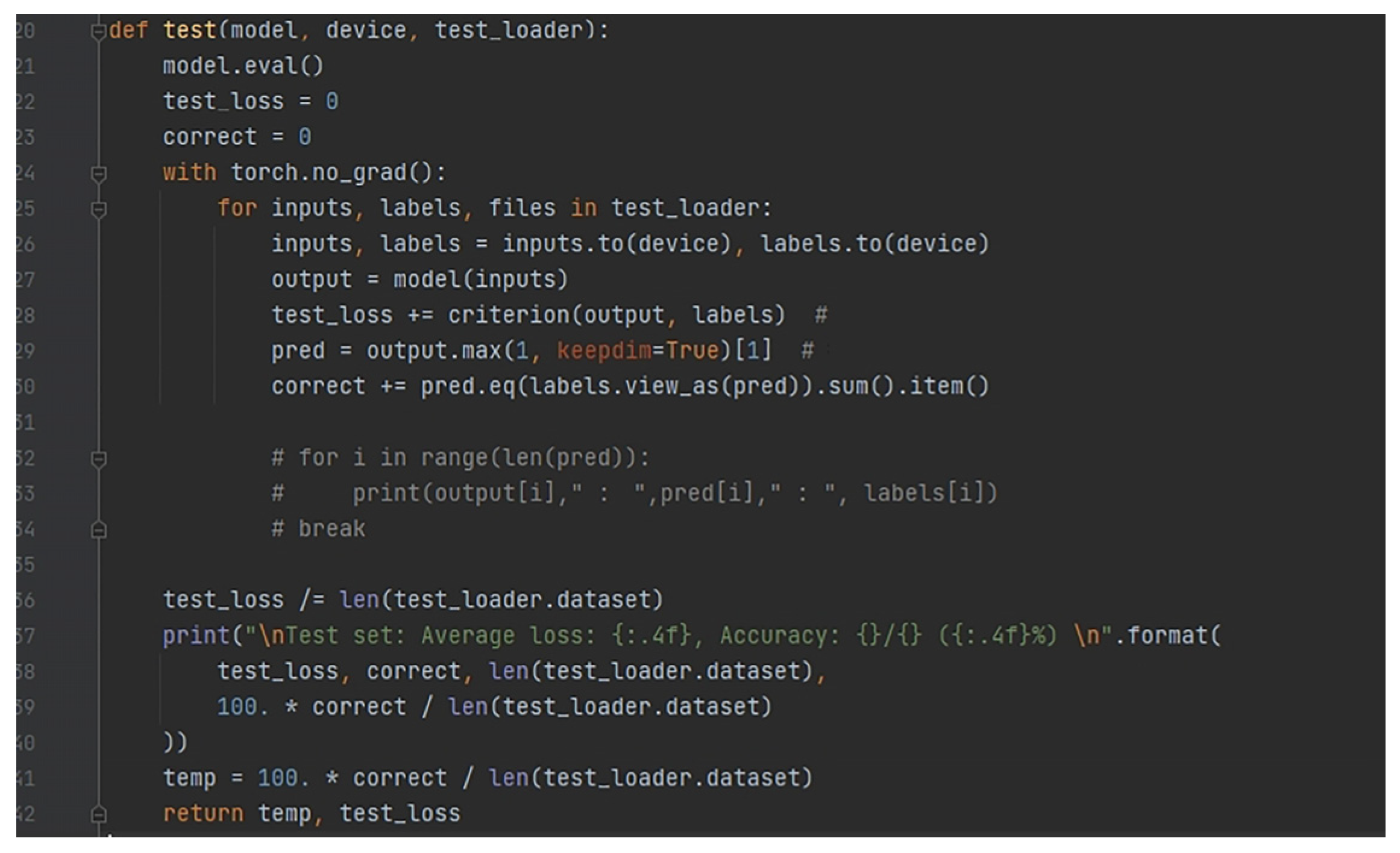
The training model is built on python, and the training set of audio sample data of the three singing voices collected in the early stage is imported into the model. There are 458 test audio samples of chanting-style singing, 124 test audio samples of fast-singing-style singing, and 301 test audio samples of traditional-singing-style singing. Then, the processed training set audio signals are imported into the test model together with the relevant speech parameters, and the accuracy of a test result is generated in the model through constant comparison of the two parameters. If the deviation between the two data is large, the model reverses the transmission to adjust the parameters of the speech layer until the accuracy rate rises, and the accuracy of the tested speech signal model is 65.1% (
Figure 10 shows the test function and the resulting accuracy results).
2.1.2. Convolutional Neural Network for Classification Processing
In the two-dimensional matrix processing of the speech signal in the training model and the frequency-domain information processing of the speech signal, the classification method of the convolutional neural network is integrated by using convolutional fixity to suppress the multiplicity of the speech signal [
5]. The main principle is to input the corresponding speech signal parameters, read the parameters through a layer of convolution, process the convolved information using pooling, and then perform the same operation as in the previous step. The secondary processed information is passed into the two neural layers (fully connected), which form an unusual two-layer neural network layer. Finally, a classifier is used to connect the layers for classification.
The convolutional neural network is not limited by having to process the input information of each pixel. Based on its characteristic of having a batch filter that continuously rolls over the two-dimensional graph, the information is collected in the graph. The fusion of MFCC coefficients is used to extract feature parameters and implement classification processing for each small block of the pixel area in the two-dimensional matrix model. The fusion enhances the continuity of vocal information in the speech signal such that the neural network can acquire graphical information, not a single pixel point, and deepens the neural network’s knowledge of graphical information, allowing the classification and collation to have an actual presentation.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}