
Lightweight Network for Single Image Super-Resolution with Arbitrary Scale Factor †


Abstract
:1. Introduction
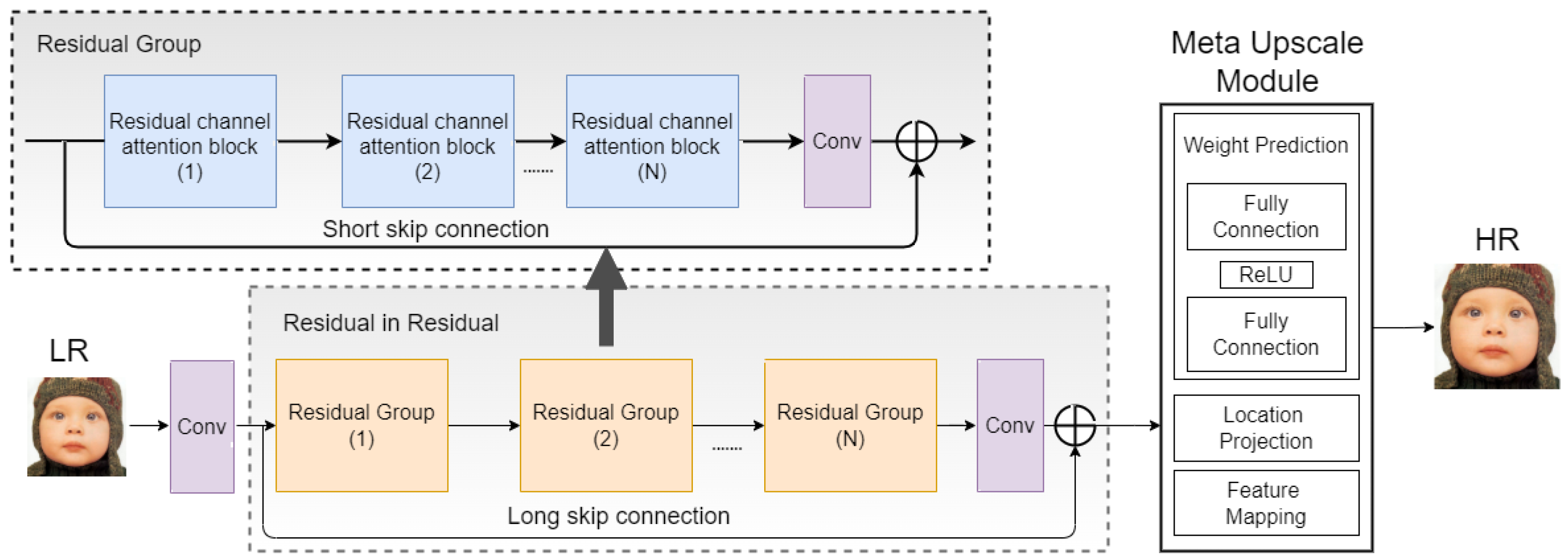
2. Proposed Method
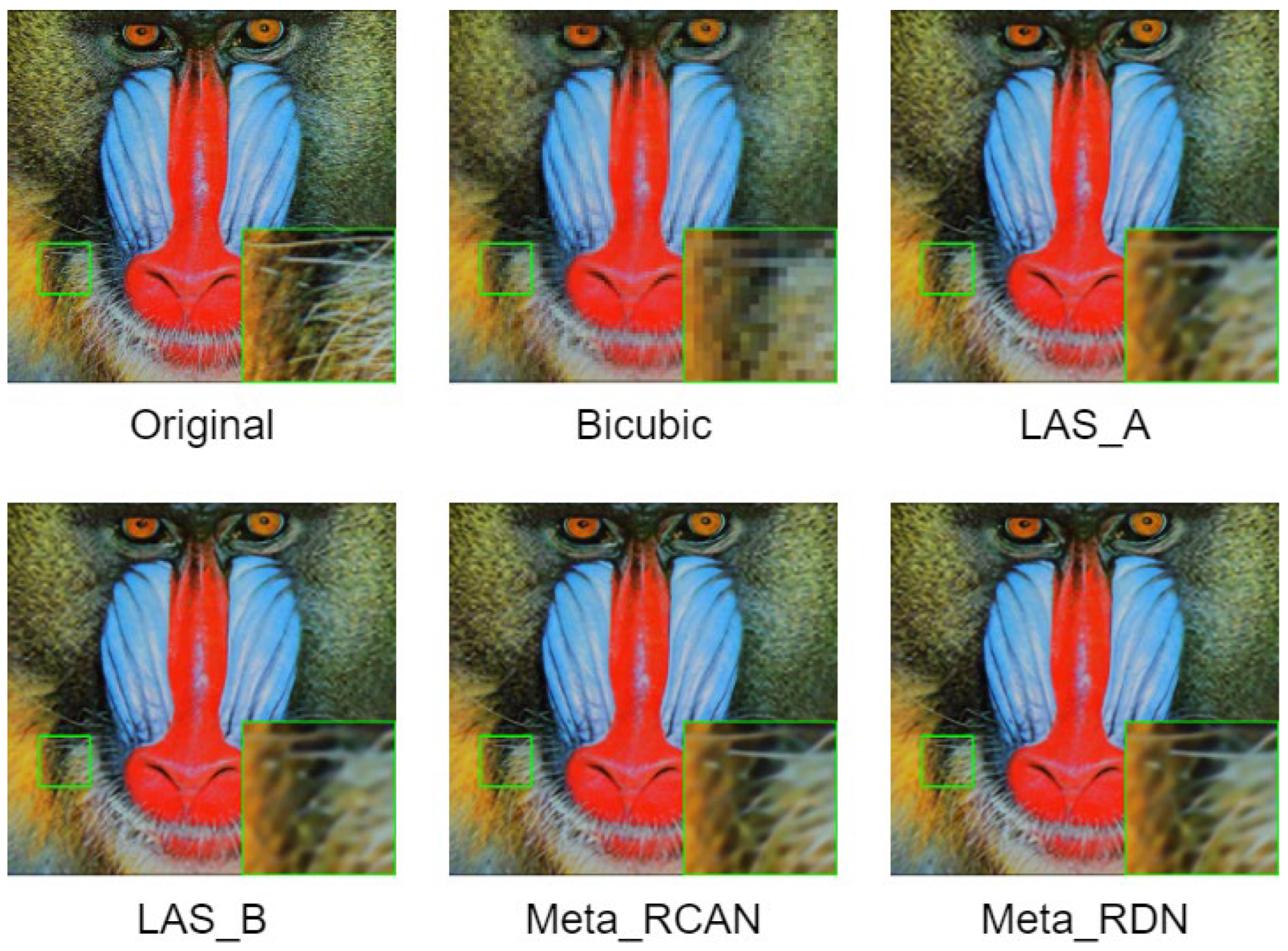
3. Experimental Result
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef] [PubMed]
- Hu, X.; Mu, H.; Zhang, X.; Wang, Z.; Tan, T.; Sun, J. Meta-SR: A magnification-arbitrary network for super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual dense network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Agustsson, E.; Timofte, R. NTIRE 2017 challenge on single image super-resolution: Dataset and study. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1122–1131. [Google Scholar]
- Bevilacqua, M.; Roumy, A.; Guillemot, C.; Alberi-Morel, M.-L. Low-complexity single-image super-resolution based on nonnegative neighbor embedding. In Proceedings of the British Machine Vision Conference 2012, Surrey, UK, 3–7 September 2012; pp. 1–10. [Google Scholar] [CrossRef]
- Zeyde, R.; Elad, M.; Protter, M. On single image scale-up using sparse-representations. In Proceedings of the 7th international conference on Curves and Surfaces, Avignon, France, 24–30 June 2010; pp. 711–730. [Google Scholar]
- Martin, D.; Fowlkes, C.; Tal, D.; Malik, J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In Proceedings of the Eighth IEEE International Conference on Computer Vision, Vancouver, BC, Canada, 7–14 July 2001. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Bicubic | VDSR [6] | LAS_A | LAS_B | LAS_C | Meta-RCAN | Meta-RDN [2] | ||
|---|---|---|---|---|---|---|---|---|
| Params | N/A | 665 K | 411 K | 634 K | 967 K | 12.7 M | 22 M | |
| Set5 | 2 | 33.66/0.9299 | 37.53/0.9587 | 37.52/0.9583 | 37.67/0.9591 | 37.72/0.9593 | 38.22/0.9611 | 38.23/0.9610 |
| 2.5 | - | - | 35.36/0.9395 | 35.60/0.9411 | 35.59/0.9410 | 36.20/0.9444 | 36.18/0.9441 | |
| 3 | 30.39/0.8682 | 33.66/0.9213 | 33.72/0.9209 | 34.03/0.9238 | 34.02/0.9240 | 34.73/0.9295 | 34.72/0.9296 | |
| 3.5 | - | - | 32.52/0.9019 | 32.81/0.9058 | 32.91/0.9071 | 33.56/0.9142 | 33.60/0.9146 | |
| 4 | 28.42/0.8104 | 31.35/0.8838 | 31.36/0.8807 | 31.72/0.8871 | 31.81/0.8886 | 32.52/0.8989 | 32.51/0.8986 | |
| Set14 | 2 | 30.24/0.8688 | 33.03/0.9124 | 33.05/0.9123 | 33.26/0.9149 | 33.27/0.9149 | 34.02/0.9206 | 34.03/0.9204 |
| 2.5 | - | - | 31.17/0.8704 | 31.37/0.8740 | 31.37/0.8735 | 31.97/0.8819 | 31.89/0.8814 | |
| 3 | 27.55/0.7742 | 29.77/0.8314 | 29.83/0.8319 | 30.06/0.8364 | 30.06/0.8366 | 30.58/0.8463 | 30.58/0.8465 | |
| 3.5 | - | - | 28.86/0.7970 | 29.08/0.8023 | 29.11/0.8035 | 29.59/0.8139 | 29.60/0.8140 | |
| 4 | 26.00/0.7027 | 28.01/0.7674 | 28.05/0.7672 | 28.28/0.7735 | 28.31/0.7749 | 28.84/0.7872 | 28.86/0.7878 | |
| B100 | 2 | 29.56/0.8431 | 31.90/0.8960 | 31.81/0.8940 | 31.97/0.8966 | 31.99/0.8971 | 32.33/0.9008 | 32.36/0.9011 |
| 2.5 | - | - | 29.95/0.8415 | 30.11/0.8450 | 30.12/0.8446 | 30.46/0.8509 | 30.48/0.8509 | |
| 3 | 27.21/0.7385 | 28.82/0.7976 | 28.75/0.7959 | 28.90/0.7999 | 28.92/0.8005 | 29.26/0.8079 | 29.28/0.8089 | |
| 3.5 | - | - | 27.89/0.7566 | 28.04/0.7617 | 28.06/0.7626 | 28.40/0.7718 | 28.42/0.7730 | |
| 4 | 25.96/0.6675 | 27.29/0.7251 | 27.22/0.7233 | 27.37/0.7289 | 27.40/0.7301 | 27.73/0.7409 | 27.76/0.7419 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dang, Q.T.D.; Huang, K.-Y.; Chen, P.-Y. Lightweight Network for Single Image Super-Resolution with Arbitrary Scale Factor. Eng. Proc. 2023, 55, 15. https://doi.org/10.3390/engproc2023055015
Dang QTD, Huang K-Y, Chen P-Y. Lightweight Network for Single Image Super-Resolution with Arbitrary Scale Factor. Engineering Proceedings. 2023; 55(1):15. https://doi.org/10.3390/engproc2023055015
Chicago/Turabian StyleDang, Quang Truong Duy, Kuan-Yu Huang, and Pei-Yin Chen. 2023. "Lightweight Network for Single Image Super-Resolution with Arbitrary Scale Factor" Engineering Proceedings 55, no. 1: 15. https://doi.org/10.3390/engproc2023055015
APA StyleDang, Q. T. D., Huang, K.-Y., & Chen, P.-Y. (2023). Lightweight Network for Single Image Super-Resolution with Arbitrary Scale Factor. Engineering Proceedings, 55(1), 15. https://doi.org/10.3390/engproc2023055015