Abstract
Guided by system science, we propose a cognitive model based on graph theory and explore personalized recommendation algorithms based on a deep knowledge point tracking model by integrating the learning characteristics, prior knowledge, and learning ability of learners. Recommendation of the knowledge point is provided by combining the deep knowledge point tracking model and cognitive model, and personalized curriculum recommendation is provided by combining a knowledge point tracking model and graph theory. A dynamic personalized learning path is recommended by combining the knowledge point network and a student model. Then, teaching resources are recommended, and learning efficiency is improved.
1. Introduction
To solve the problem of “information overload and maze” in education, personalized recommendations of teaching resources are introduced. Personalized recommendation of teaching resources refers to educational information and teaching resources that are provided based on personal information. Different from the “one-to-many” services provided by educational resources, the recommendation meets personal needs, so users do not need to go through many recommendation processes. Thus, the cost of finding the required educational resources can be significantly reduced [1,2]. The personalized recommendation service has changed from the simple mode of “resources found by users” to the intelligent mode of “resources for uses”. The service is for learner-centered adaptive learning [3,4,5]. Adaptive learning refers to the construction of learners’ interests and abilities based on online learning behavior data. Learner behavior is predicted to intelligently provide personalized learning paths, resources, or courses according to personal interests and abilities. The personalized recommendation of teaching resources effectively solves the problem of an “information maze” brought on by a massive amount of data. Therefore, the development of a personalized recommendation system is an important topic for research in educational information.
2. Research Status of Related System
Personalized recommendations have been extensively studied. In terms of learning course recommendation, references [6,7] propose a personalized course generation system based on the hierarchical recommendation algorithm. The system provided personalized courses in two stages according to the learning process of users. Personalized courses are recommended based on the analysis of the overall teaching plan and curriculum-based knowledge extracted from the massive knowledge base. Then, target learners can acquire the necessary knowledge before learning the courses through the pre-test module and a hierarchical recommendation algorithm. In learning, a dynamic update of the learner’s characteristics is performed with the genetic algorithm that generates personalized course contents according to the learning objectives of the course. Based on knowledge points and knowledge management theory, the 5-layer structure of knowledge and the 4-layer structure of using knowledge are recommended. The knowledge points and learning strategy are designed and developed based on recommended personalized courses [8]. A personalized course learning model for the program of the certificate in English language teaching (CELT) was developed based on the self-organized community [9,10]. The model used the similarity between peers and lecturers, and the pertinence of the algorithm to guide learners by recommending learning objects, pathways, and strategies was verified. The proposed model reduced the workload of the lecturers, and the experimental results showed that the proposed model effectively improved the learning quality and interest of the learners.
The current personalized recommendation system for teaching resources was proposed in 2015 with a depth knowledge tracking (DKT) model based on deep learning theory and knowledge tracking theory. With the big data of learning behaviors, the prediction accuracy of the system was higher than with Bayesian knowledge tracing (BKT) and item response theory (IRT). Without experts’ help, teachers could find the necessary knowledge, and favorable conditions for learners’ knowledge discovery were determined. In learning, knowledge takes a relatively small part as in the learning process, a cognitive law of knowledge, cognitive theory, and cognitive model are combined in the internal connection for mining knowledge. Based on the knowledge and its interconnection, the characteristics of learning courses can be recognized, which are used for learning courses and path recommendations. However, an appropriate knowledge-tracking model has not yet been developed. With higher accuracy of the deep knowledge-tracking model, the accuracy and satisfaction with recommended knowledge points and learning courses and paths will be improved.
3. Goals and Ideas of System Design
This study aims to develop a personalized recommendation algorithm based on a DKT model that considers the learning characteristics, prior knowledge, and learning ability of learners. Introducing the cognitive model and figure theory, the teaching resources are optimized, and the accuracy of the recommendation of teaching resources is improved. The wider coverage, better recall, and improved recommended rate allow learners to improve learning efficiency, enhance learning interest, optimize the learning effect, and relieve “cognitive overload”. Such advantages can be achieved with the proposed algorithm.
In the algorithm, the knowledge point recommendation algorithm, the deep knowledge point tracking model, and the cognitive model are integrated for accurate and enhanced interpretability of the prediction process. The Ebbinghaus forgetting curve is used to simulate learning status and recommend knowledge points that are forgotten. The deterministic inputs, noisy, and gate (DINA) model is also introduced to evaluate the guess and error rates so that the feature vector of the learners’ knowledge point can be closer to their real state. The graph theory is also used to explore the internal relationship between the knowledge points. Dependencies, reference relationships, parallel relationships, and pre- and post-relationships are determined to create the personalized knowledge graph of learners. The similarity or subordination between the features found and the feature vector in the knowledge graph of learning courses is tested to validate the algorithm’s performance. Based on the inherent relationship between knowledge points and learning courses, a personalized learning path is recommended.
4. System Design
According to the objectives of this study, the following processes are carried out.
- Constructing an algorithm for recommending personalized knowledge based on the DKT model and the cognitive model
- Constructing an algorithm for a personalized course recommendation based on the DKT model and graph theory
- Constructing an algorithm for personalized learning path recommendation based on the combination of knowledge point networks and student models
The DKT model has advantages over BKT and IRT in that it can train with the data parameters and study the algorithm mechanism. The long- and short-term memory model (LSTM) is used to predict the required knowledge points and test the prediction accuracy and operation rate. With the Ebbinghaus forgetting curve, the DINA model and LSTM are used to compare the prediction accuracy, recall rate, test time, and training time. Based on the prediction results, the algorithms recommend knowledge points that learners have not mastered well. In LSTM, the hidden Markov model (HMM) and K-means algorithm are adopted to explore the accuracy of the predicted knowledge relationship graph. The feature vector of the learning course is extracted to create the learning course graph. Then, the subordination relationship between the learners’ knowledge map and the learning course is investigated to recommend the relevant learning courses based on the knowledge points that the learners have mastered poorly. The learning path is recommended based on the directed knowledge point network graph and a personalized knowledge status map, which show cognition, ability, goals, and other characteristics of learners. The learning path is optimized for better effectiveness of personalized learning, and the most appropriate learning path is recommended for learners.
The algorithms are developed to improve the accuracy of the prediction and lay the foundation for the subsequent recommendation. For the algorithms, it is necessary to find the characteristic vector of the learner’s knowledge points and create a knowledge map. Through similarity or relationship tests of the knowledge graph and learning course characteristics, a personalized learning course recommendation can be provided. The learning path is planned with the group’s wisdom and the prior knowledge of the learner. To develop the algorithms, the public data is preprocessed. Then, combining the long and short-term model (LSTM), DINA model, and student model and based on knowledge point map theory and cognitive model theory, the learners’ knowledge points are predicted to create a personalized knowledge point map (Figure 1).
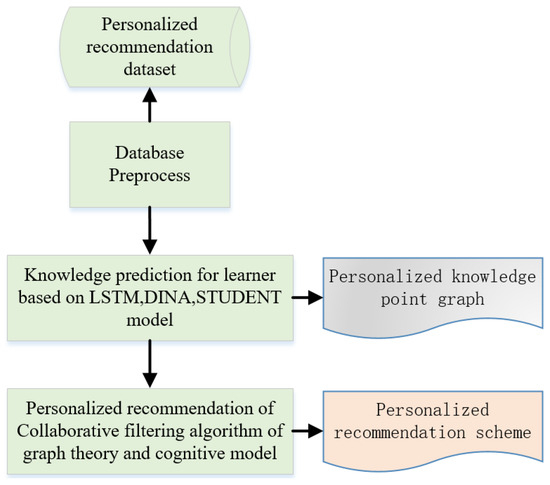
Figure 1.
System design route.
5. Experiments
5.1. Dataset
For the experiment, data from 2009−2010 is used. It contains 525,535 sets of the exercise data of 4217 students with the student number, question number, correct answer result, associated knowledge points, answer order, answer type, and others. The data on students’ lifestyles and studies is collected from the 10-week cell phone use of 48 students at Dartmouth College in the USA) including learners’ mental state, academic performance, and behavioral trends. The size of the data is 53 Gb, containing 32,000 self-reports and pre-post surveys. The Ted dataset, the Edx dataset, and the Datashop data are also used in the experiment.
5.2. Comparison and Evaluation
As comparison algorithms, we use the collaborative filtering algorithm, collaborative filtering recommendation algorithm, single-layer DKT model, two-layer DKT model algorithm, and BKT algorithm.
To evaluate the performance of the algorithms, the following index is calculated.
Mean absolute error:
Root-mean-square error:
Pearson Correlation factor:
Precision:
Recommended coverage:
6. Discussion, and Conclusions
We propose an algorithm for the personalized recommendation of knowledge points, learning paths, resources, and courses for learners. We use the DKT model to determine learning style characteristics, prior knowledge, and learning ability, and the cognitive model and graph theory to optimize personalized teaching resources. The developed algorithm improves the accuracy, coverage, recall, and rate of teaching resource recommendations, enhances learning efficiency, interest, and effect, and overcomes “overload” and “learning flight”. The algorithm also makes the knowledge point feature vector more accurate and improves the interpretability of the prediction. Learning courses are recommended to offer more comprehensive and accurate courses according to the learner’s needs. The algorithm can be used to develop further personalized educational recommendation systems.
Author Contributions
M.S. proposed conceptualization and methodology of this manuscript. The figures and partial writing were conducted by F.L. H.K. and S.Z. both are responsible for the formal analysis and investigation. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the Hainan Provincial Natural Science Foundation of China (No. 2020J01435, No. 2021J011169, 2022J011224). Ningde Normal University for service local action special plan (No. 2020ZX505).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
No data were created.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Montoya, M.M.; Massey, A.; Lockwood, P.N. 3D collaborative virtual environments: Exploring the link between collaborative behaviors and team performance. Decis. Sci. 2018, 42, 451–476. [Google Scholar] [CrossRef]
- Kevin, C.; Carsten, S.L.; Tae, K.L. Knowledge Tracing to Model Learning in Online Citizen Science Projects. IEEE Trans. Learn. Technol. 2019, 36, 2253–2278. [Google Scholar]
- Piech, C.; Spencer, J.; Huang, J.; Gang, H.G.; Sahami, M. Deep Knowledge Tracing. Comput. Sci. 2018, 7, 19–23. [Google Scholar]
- Melis, E.; Goguadze, G.; Homik, M.; Libbrecht, P. Semantic-aware components and services of Active Math. Br. J. Educ. Technol. 2011, 37, 405–423. [Google Scholar] [CrossRef]
- Dario, N.; Méndez, D.; Ramírez, C.J.; Alberto, J.I. A planning for automatic generation of customized virtual courses. In Proceedings of the ECAI, Stockholm, Sweden, 13–19 July 2018. [Google Scholar]
- Ullrich, C.; Melis, E. Pedagogically founded courseware generation based on HTN-planning. Expert Syst. Appl. 2017, 36, 9319–9332. [Google Scholar] [CrossRef]
- Karampiperis, P.; Sampson, D. Adaptive Learning Resources Sequencing in Educational Hypermedia Systems. J. Educ. Technol. Soc. 2015, 8, 128–147. [Google Scholar]
- Rumetshofer, H.; Wöβ, W. XML-based adaptation framework for psychological-driven e-learning systems. J. Educ. Technol. Soc. 2003, 6, 18–29. [Google Scholar]
- Li, G.Q.; Xia, J.L.; Mei, S.Y. Learning Resource Recommendation Method based on Fuzzy Logic. J. Eng. Sci. Technol. Rev. 2018, 51, 787–814. [Google Scholar]
- Chang, Y.C.; Kao, W.Y.; Chu, C.P. A learnings tyle classification mechanism for e-learning. Comput. Educ. 2019, 53, 273–285. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).