1. Introduction
The optimal control problem with phase constraints often has a multi-modal functional. Therefore, with its numerical solution by direct approach, it is possible to obtain several control functions that ensure the movement of the object along different trajectories in the state space with approximately the same value of the control quality criterion which is close to the optimal.
A numerical solution to the optimal control problem leads to some difficulties. As a rule, in most optimal control problems, it is necessary to minimize not one but at least two criteria, reach the control goal or minimize the error of reaching the terminal state and still minimize the given quality criterion. Addition of weight coefficients into criteria does not significantly simplify the problem, since the problem of choosing weights arises.
Another search problem is defined as the loss of unimodality of the functional on the space of parameters of the approximating function. Even a piecewise linear approximation of the control function, when only one parameter needs to be found on each interval for each control component, does not guarantee the presence of a single minimum of the goal functional on the space of parameters.
The problem becomes more complicated in the presence of phase constraints that describe the areas of state space forbidden for the optimal trajectory. It is most likely that due to these reasons, and despite numerous attempts [
1,
2], a universal computational method for the optimal control problem has not been created.
Further studies have shown that if a strictly optimal solution is not needed and solutions close to the optimal are quite satisfactory, then evolutionary algorithms can be successfully applied to the optimal control problems [
3].
Sometimes in practice the researcher knows how the object should move along the optimal trajectory, i.e., approximately knows the areas in the state space the optimal trajectory should pass through. If we introduce additional requirements in the form of passing through the given areas into the quality criterion, then the evolutionary algorithm should change the search area and look for a solution that satisfies the additional requirements. This approach is effective when using evolutionary algorithms. Due to the inheritance property, the improvement of the criterion value at each generation is performed on the basis of small evolutionary transformations of possible solutions to the previous generation. Therefore, if at some generation one of the possible solutions passes through the required areas specified by the researcher, then with a high probability the evolutionary algorithm will search for the optimal solution that preserves the obtained properties. A similar technique is used in machine learning with reinforcement [
4,
5], when the researcher awards the object by the change of the target functional value for the right actions. Currently, reinforcement learning is actively used in the practice of solving control problems [
6]. The paper contains a formal description and practical application of reinforcement learning for solving the optimal control problem.
2. The Optimal Control Problem and Reinforcement Learning
Consider a formal statement of the optimal control problem.
The mathematical model of a control object is given in the Cauchy form of an ordinary differential equation system
where
is a state space vector,
is a control vector,
,
, and
is a compact set.
The initial state is given by
The terminal state is given by
where
is the time to reach the terminal state (
3). Time
is not given, but it is limited to
, where
is a given positive value.
The quality criterion is given by
Assume that the researcher knows the areas in the state space of where the optimal trajectory should be. Then, additional conditions are included in the quality criterion
where
p is a penalty coefficient, and
is a Heaviside step function
, are given small positive values, and , are the centres of known areas.
According to the introduced additional conditions, if an optimal trajectory does not pass near some given point
, then value of criterion (
5) will grow.
3. Computation Experiment
Consider the optimal control problem for the spatial movement of a quadcopter. The mathematical model of the control object is
where
.
Control is constrained
where
,
,
,
,
,
,
and
.
The initial state is given by
The terminal state is given by
The phase constraints are given by
where
,
,
,
,
,
.
It is necessary to find a control function, taking into account the constraints in (
9), that minimizes the following criterion
where
,
.
To solve the control problem numerically, let us use a piecewise linear approximation. The time axis is divided into equal intervals
, and the search for constant parameters is performed at the interval boundaries for each control component. Control is a piecewise linear function that consists of segments connecting points at the bounds of intervals. Given the control constraints, the desired control function is as follows
where
and
K is a number of time interval boundaries
When solving the problem by a direct approach, the condition of reaching the terminal state is included in the quality criterion
where
,
To solve the problem, a hybrid evolutionary algorithm [
7] is used.
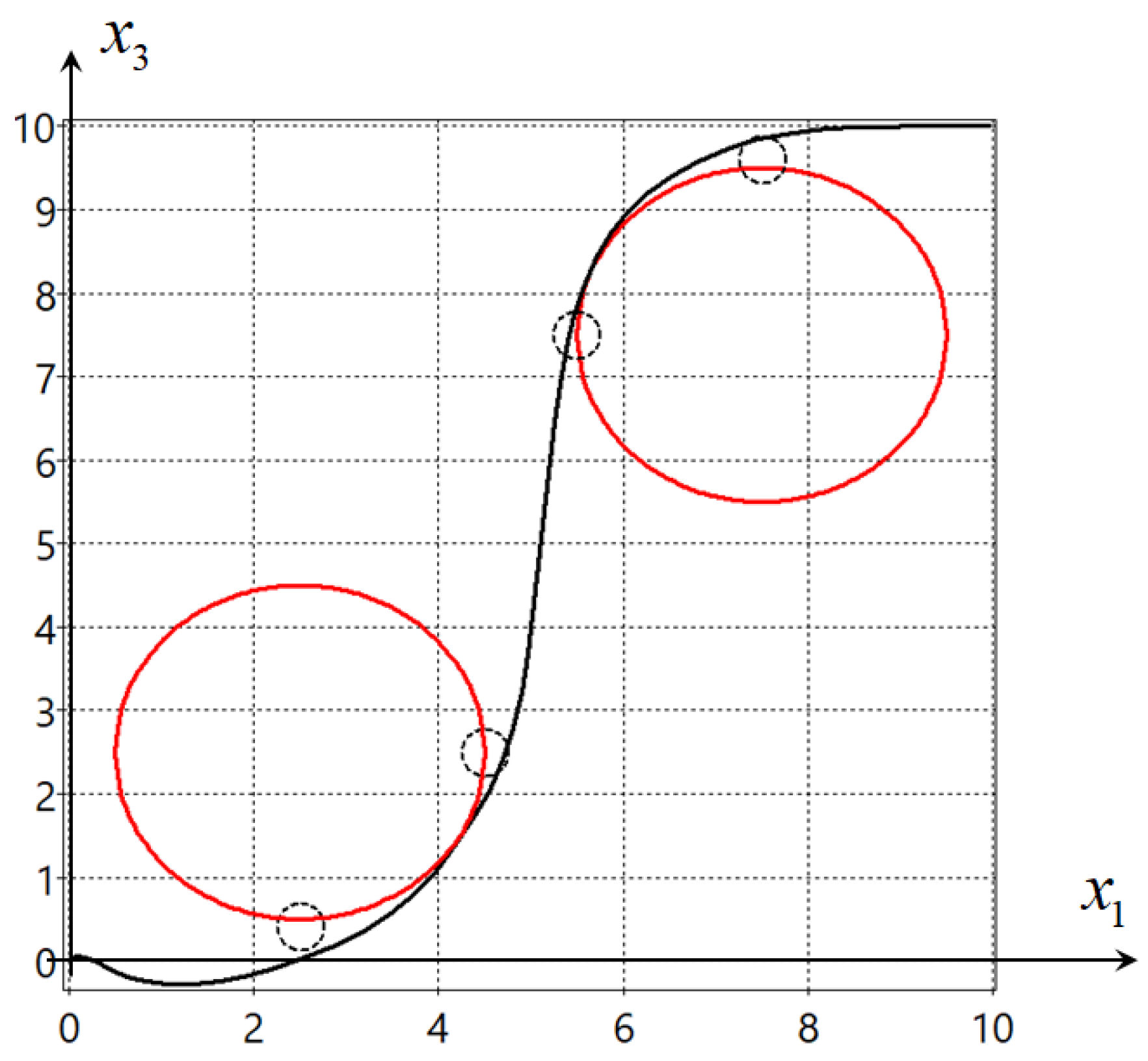
Figure 1 and
Figure 2 show projections on the horizontal plane
of the two found optimal trajectories. The big circles present the phase constraints in (
12).
The criterion for the solutions found had the following values: for the solution in
Figure 1 , for the solution in
Figure 2 .
As can be seen from the experiment, the values of the criteria practically coincide, the solutions found ensure the movement of the object from the given initial state (
10) to the given terminal state (
11) without violation of the phase constraints. In the series of experiments, the hybrid evolutionary algorithm found solutions that bypass the phase constraints either from above, as in
Figure 1, or from below, as in
Figure 2.
Suppose that we need the control object to move between obstacles. For this purpose the desired areas on the horizontal plane are defined. It is known that in the presence of interfering phase constraints, the optimal trajectory should be close to the boundary of these constraints. For the given problem four desired areas are defined as
The conditions for passing through the desired areas (
19) are included in the quality criterion
where
.
The hybrid evolutionary algorithm found the following optimal solution , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , , .
Figure 3 shows the projection of the found optimal trajectory for the solution with quality criterion
. Small dashed circles are the desired areas, while big circles are the constraints.
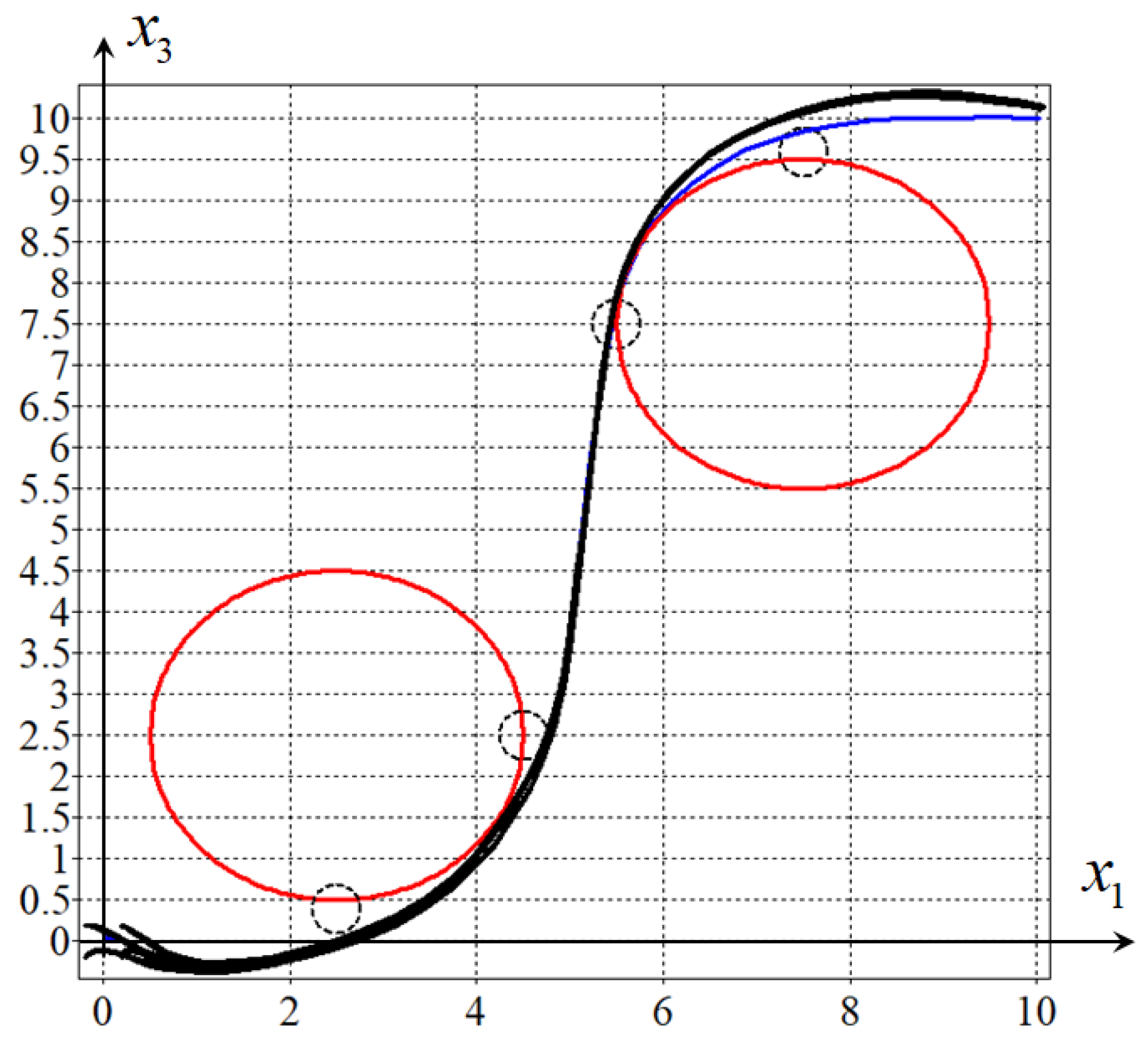
To implement the obtained solution according to the extended statement of the optimal control problem, it is necessary to build a system to stabilize the movement of the object along the optimal trajectory [
8]. For this purpose, machine learning control is used [
9]. The control function structure search is carried out by symbolic regression [
10].
The obtained solution is
where
where
,
,
,
,
,
and
is a state vector of the reference model.
Figure 4 shows the trajectories from eight initial states on the horizontal plane.





{kind=link}
{kind=link}
{kind=link}
{kind=link}