
Hate Speech Detection: Performance Based upon a Novel Feature Detection †

Abstract
:1. Introduction
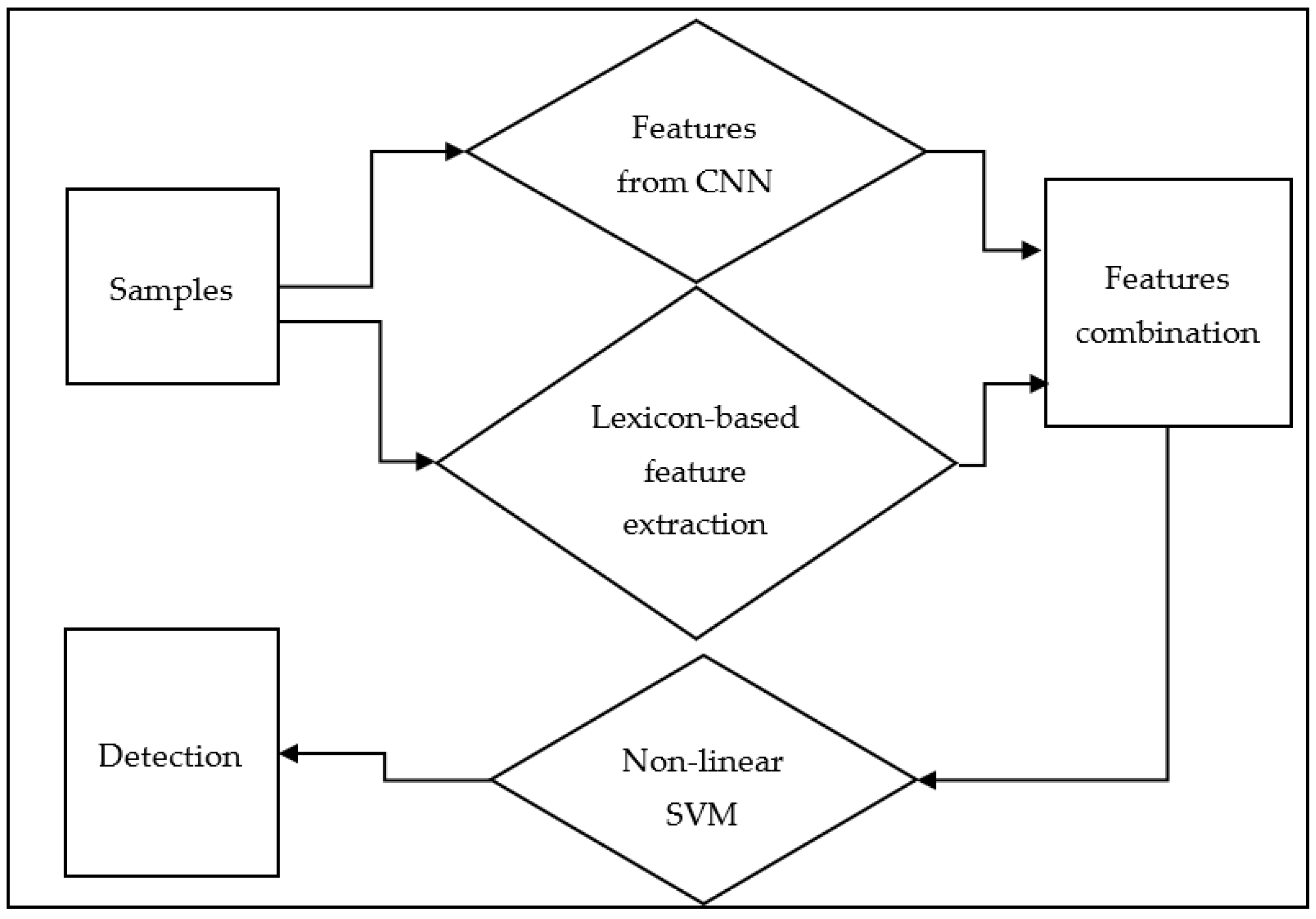
2. Proposed Method
3. Results
4. Conclusions
Supplementary Materials
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Know Your Limit: The Ideal Length of Every Social Media Post. Available online: https://sproutsocial.com/insights/social-media-character-counter/#facebook (accessed on 10 November 2022).
- Davidson, T.; Warmsley, D.; Macy, M.; Weber, I. Automated Hate Speech Detection and the Problem of Offensive Language. In Proceedings of the 11th International AAAI Conference on Web and Social Media (ICWSM-17), Montreal, Canada, 15–18 May 2017; pp. 512–515. [Google Scholar]
- Zhang, Z.; Robinson, D.; Tepper, J. Detecting hate speech on Twitter using a convolution-GRU based deep neural network. In Lecture Notes in Computer Science, Proceedings of the 15th Extended Semantic Web Conference, ESWC’18, Heraklion, Greece, 3–7 June 2018; Springer: Cham, Switzerland, 2018; Volume 10843, pp. 745–760. [Google Scholar]
- Founta, A.M.; Chatzakou, D.; Kourtellis, N.; Blackburn, J.; Vakali, A.; Leontiadis, I. A Unified Deep Learning Architecture for Abuse Detection. In Proceedings of the WebSci ’19: 10th ACM Conference on Web Science, Boston, MA, USA, 30 June 2019–3 July; pp. 105–114. [Google Scholar]
- Kshirsagar, R.; Cukuvac, T.; McKeown, K.; McGregor, S. Predictive Embeddings for Hate Speech Detection on Twitter. In Proceedings of the 2nd Workshop on Abusive Language Online (ALW2); Association for Computational Linguistics: Brussels, Belgium, 2018; pp. 26–32. [Google Scholar]

{kind=link}
| Dataset Type | Accuracy | Recall | Recall-Hate Class | Precision | Precision-Hate Class | Micro-F1 | Macro-F1 |
|---|---|---|---|---|---|---|---|
| Unbalanced | 0.936755 | 0.981986 | 0.199301 | 0.952371 | 0.404255 | 0.966952 | 0.266979 |
| Balanced | 0.702797 | 0.730769 | 0.674825 | 0.692053 | 0.714815 | 0.710884 | 0.694245 |
| Performance Reported on Davidson dataset [1] by Previous Studies | |||||||
| Dataset | Scores | ||||||
| [2] | 0.61 | 0.44 | 0.90 | ||||
| [3] | 0.94 | 0.30 | |||||
| [4] | 0.89 | 0.89 | 0.89 | ||||
| [5] | 0.924 | ||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bose, S. Hate Speech Detection: Performance Based upon a Novel Feature Detection. Eng. Proc. 2023, 31, 87. https://doi.org/10.3390/ASEC2022-13788
Bose S. Hate Speech Detection: Performance Based upon a Novel Feature Detection. Engineering Proceedings. 2023; 31(1):87. https://doi.org/10.3390/ASEC2022-13788
Chicago/Turabian StyleBose, Saugata. 2023. "Hate Speech Detection: Performance Based upon a Novel Feature Detection" Engineering Proceedings 31, no. 1: 87. https://doi.org/10.3390/ASEC2022-13788
APA StyleBose, S. (2023). Hate Speech Detection: Performance Based upon a Novel Feature Detection. Engineering Proceedings, 31(1), 87. https://doi.org/10.3390/ASEC2022-13788