1. Introduction
High-resolution 3D scanners have become popular devices for collecting point-cloud data from 3D objects. The exploratory analysis and visualization of such large amounts of data are crucial for many applications such as scene reconstruction, object recognition and autonomous navigation. As such, computing 3D importance (saliency) maps is a topic of interest in computer vision. While most of the saliency detection approaches take into consideration the geometrical features of objects, some research work targets reproducing human perception capabilities and uses them as a data selection strategy. In this context, the idea of mimicking human visual attention capabilities has the potential to improve recognition in terms of performance and time. On the other hand, the use of point clouds has become inevitable for several applications and domains such as robotic perception, video games, autonomous driving, virtual and augmented reality, etc. Most researchers transform these data into grids of 3D voxels or collections of images. However, this makes the data unnecessarily large and poses problems for an efficient interpretation of their contents. Using 3D learning algorithms on point cloud data presents a very promising approach for many problems, such as 3D object detection and classification. Some deep neural network algorithms [
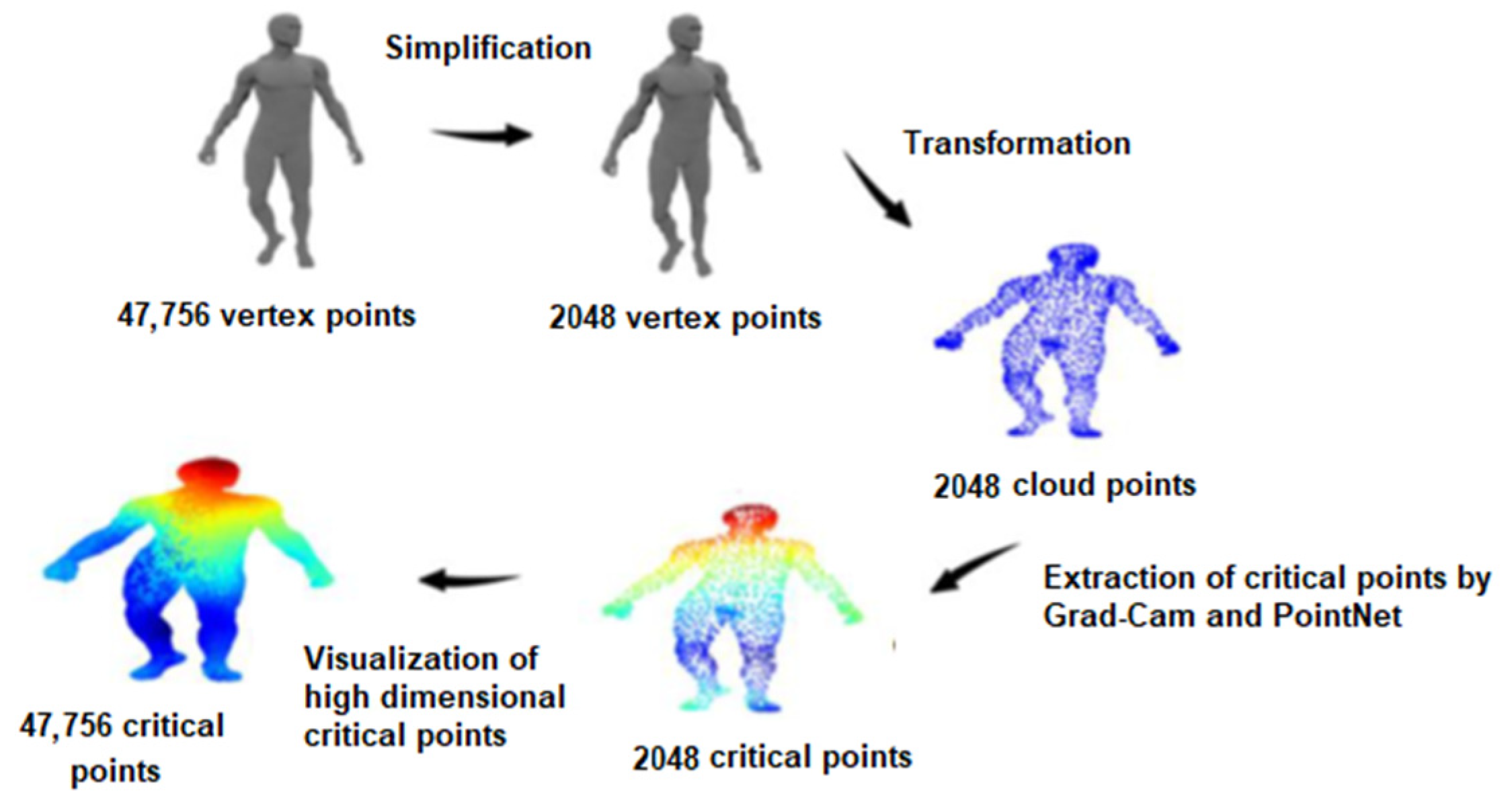
1] already propose methods for using point clouds for a 3D object representation and learning the global features to recognize the related object. The main contribution of this paper is proposing a novel approach to identifying a subset of salient (important and critical) points on the surfaces of 3D objects represented by point clouds (using a PointNet architecture), to specify and visualize the importance of each critical point with respect to its classification (using an adaptation of Grad-CAM from 2D to 3D), and then visualizing the detected salient regions and comparing the results with those of existing methods and against the ground truth.
2. State of the Art
As previously mentioned, the identification of salient regions of a 3D object has the potential to ease further analysis and processing of the object. Therefore, many research studies aim at the identification of saliencies on 3D objects. Leifman et al. [
2] introduce a vertex descriptor to highlight vertices with unique geometrical features with respect to their surroundings. Their descriptor is invariant to rigid transformation. A center-surround mechanism initially introduced in the classical model of visual attention [
3] was applied for curvature measures of 3D object meshes by Lee et al. [
4], as a method of saliency detection. Song et al. [
5] propose a 3D saliency detector for triangular meshes based on spectral mesh processing. Tasse et al. [
6] took advantage of fuzzy clustering to highlight salient regions on 3D meshes. While all these algorithms show promising solutions for saliency detection, it has been proven that these implementations are still far from the capabilities of the mechanism of visual attention in humans [
7].
In recent years, deep learning has strongly contributed to important advances in a variety of fields such as text understanding, speech recognition and computer vision. When trained on large number of training samples, deep-learning-based approaches are capable of extracting relevant information from the input data and using it for a variety of tasks such as classification and regression. While deep-learning architectures are generally considered black boxes, a huge research effort has been devoted to revealing the reasoning behind the decision of a deep neural network. In this direction, class activation mapping (CAM) [
8] is a method for highlighting important regions in an image for a specific decision. The global average pooling (GAP) layers in the architecture of deep neural networks are able to identify discriminating regions and retain the localization capability until the last layer in order to visualize the most informative regions in an image. Another approach, proposed in [
9], detects regions of interest in an image by passing it through a convolutional neural network (CNN) to classify it and computes the gradient of the classification score with respect to the activations of the last convolution layer. The regions of the image that have the highest weight are the regions that most influence the classification score. This approach is known as Gradient Weighted Class Activation Mapping (Grad-CAM). Considering the existing works, the main objective of this research work was to bring contributions to the identification of salient/critical points on the surfaces of 3D objects represented by point clouds. The work built on the deep convolutional network PointNet and addressed the problem of the lack of a means to evaluate the importance of critical points in relation to the classification performance as well as the lack of transparency and visualization of the results in an intuitive and understandable way. This was achieved by adapting the Grad-CAM algorithm for 3D objects in order to specify the importance of each critical point with respect to its classification.
4. Results and Discussion
We tested the proposed framework on five 3D objects that can be categorized in one of the categories of ModelNet [
11] and for which the ground-truth information is available [
7].
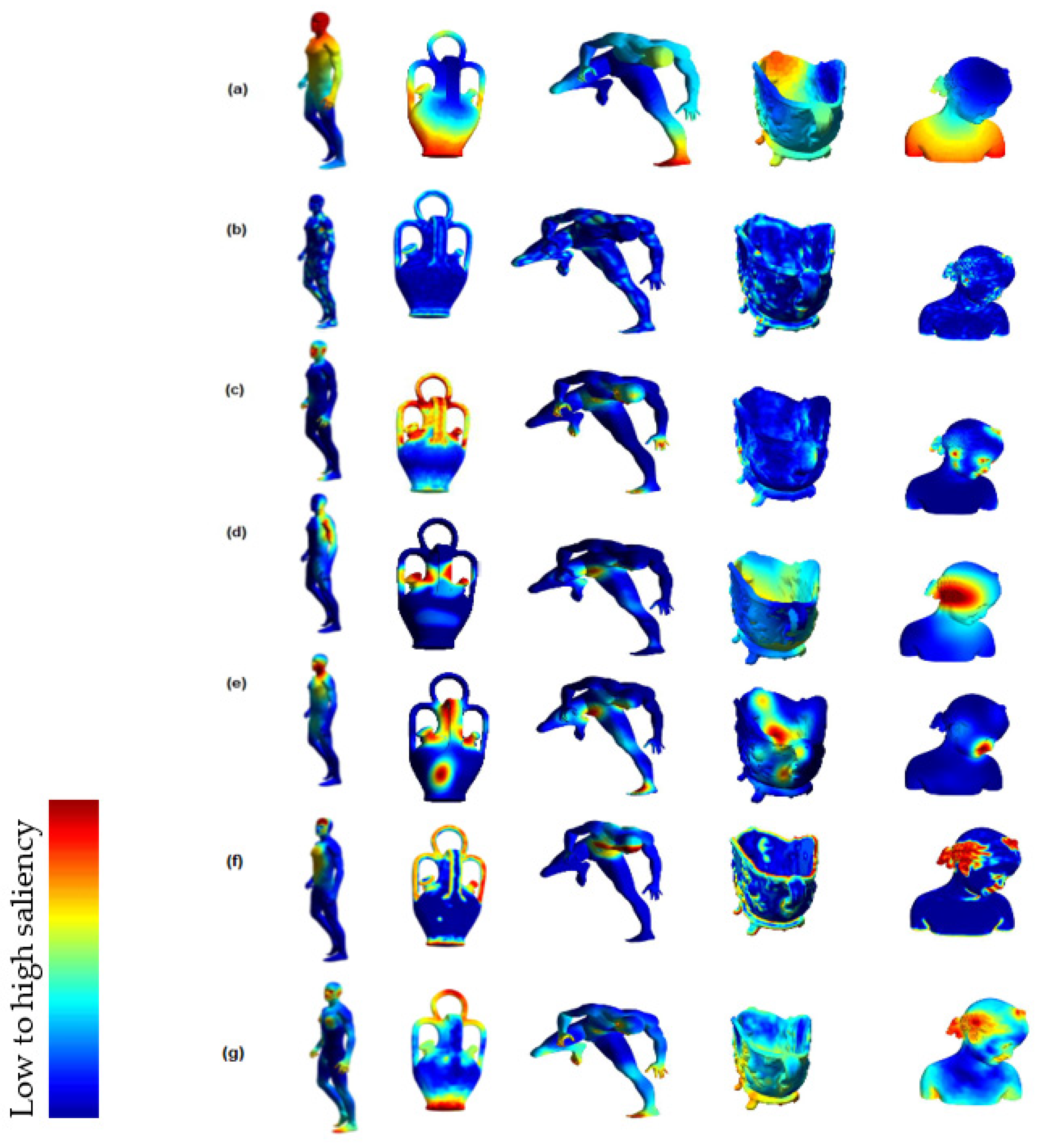
Figure 2 compares the saliencies rendered using a jet colormap for the five objects extracted from [
7] and with different methods from the literature.
It can be noticed that the critical regions on the surfaces of the objects are different, due to the different methods employed to create each model. Lee [
4] applied the center-surround paradigm used by Itti [
3] to a vertex curvature metric of a 3D object to compute saliency. Leifman [
2] proposed a surface saliency detector by highlighting vertices with unique geometry. For this purpose, they introduced a vertex descriptor that was invariant to the rigid transformation and searched for vertices that were highly dissimilar to their neighborhood. The algorithm for saliency detection of Song [
5] is based on spectral mesh processing. Tasse [
6] proposes a framework using fuzzy clustering to detect salient regions on 3D meshes. The 2D Grad-CAM algorithm VGG16 [
12] computes and integrates Grad-CAM maps for 2D images captured from various viewpoints of each 3D object based on their different shapes and semantic features. Further details about other methods are provided in
Section 2. The ground truth is generated by tracking the eye movement of human subjects when observing the object from three different viewpoints [
7].
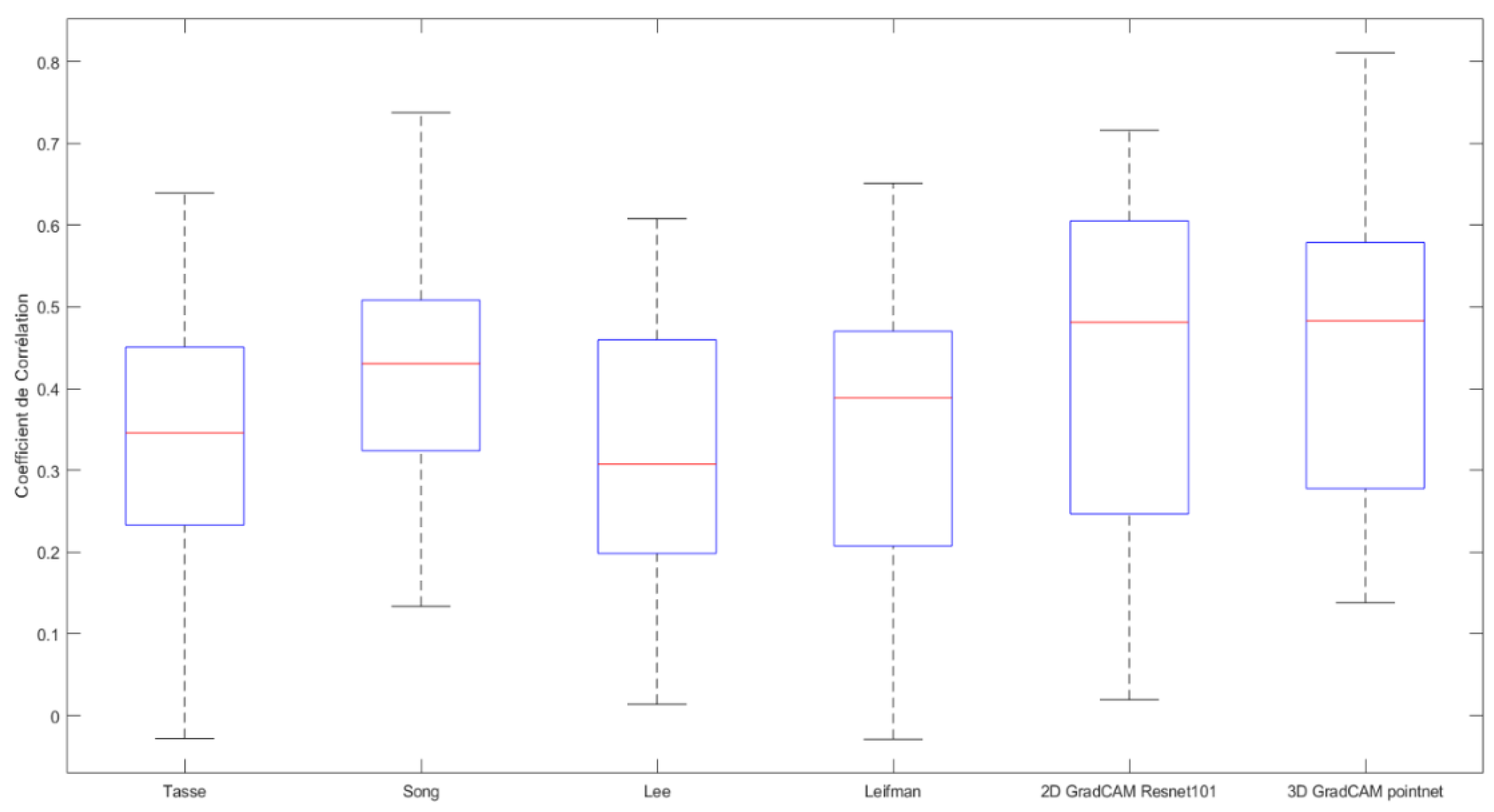
To quantitatively compare the similarity of the results of the different models, we chose a box plot diagram (
Figure 3) to visualize the similarity between the saliency level vectors and the ground reality (GT [
7]) for the comparison of results obtained for several objects. To obtain a fair comparison for each method, three saliency level vectors were obtained by multiplying the saliency level vectors by the visibility vectors (the list of vertices visible from each viewpoint); then, all the vectors were normalized between 0 and 1. The correlation coefficient used was Pearson’s linear correlation (
ρ), which allows a balanced treatment of false positives and false negatives. For two maps
x and
y, it is defined as follows:
.
The same correlation measure was used by Lavoué et al. [
7], who also concluded that none of the existing methods gave a strong correlation with the ground truth. It can be observed that, for all the methods, the interquartile ranges are very similar for the test objects used and range between 0.18 and 0.6. The interquartile mean varies between 0.34 and 0.47, demonstrating some similarity between the features extracted by different methods.
Figure 3 (which shows this correlation coefficient) also confirms that, for some viewpoints, our method (3D Grad-CAM PointNet) obtained the highest similarity values among all the methods compared. The success of the Grad-CAM-based methods can be explained by the fact that these methods assign the highest saliency level to the regions (pixels in 2D or vertices in 3D) with the highest gradient update when classifying the object, while the other methods are instead based on geometric features. Thus, the Grad-CAM based methods focus on a single region, while the other methods obtain sparse regions on the models.
5. Conclusions
In this work, we proposed a hybrid method that combines two architectures, the PointNet deep neural network and an adapted version of Grad-CAM, 3D Grad-CAM. Our solution includes the pre-processing of 3D data, implementation and training of the PointNet model, adaptation of Grad-CAM for 3D data, integration of Grad-CAM with the PointNet model and visualization of critical/salient points extracted by PointNet and Grad-CAM. The study demonstrated a good performance of the proposed method compared to similar work in the literature.





{kind=link}
{kind=link}
{kind=link}


