
Towards Time-Series Feature Engineering in Automated Machine Learning for Multi-Step-Ahead Forecasting †

 , ,
, ,  , , and
, , and
Abstract
:1. Introduction
- We adapt the auto-sklearn AutoML system to the task of forecasting and introduce three AutoML forecasting variants for multi-step-ahead TS forecasting.
- We demonstrate the importance of feature selection and window size selection in forecasting problems and further show that by incorporating such approaches, our TS AutoML techniques outperform available AutoML methods.
- We evaluate our methods on 20 benchmarking data sets from 20 different categories and against the baselines. We found that our proposed AutoML method outperformed the traditional ML baseline on 14 out of 20 data sets and N-BEATS on 15 out of 20 data sets.
2. Related Work
3. Problem Statement
AutoML for Multi-Step TS Forecasting
4. Methodology
4.1. Multi-Step Forecasting
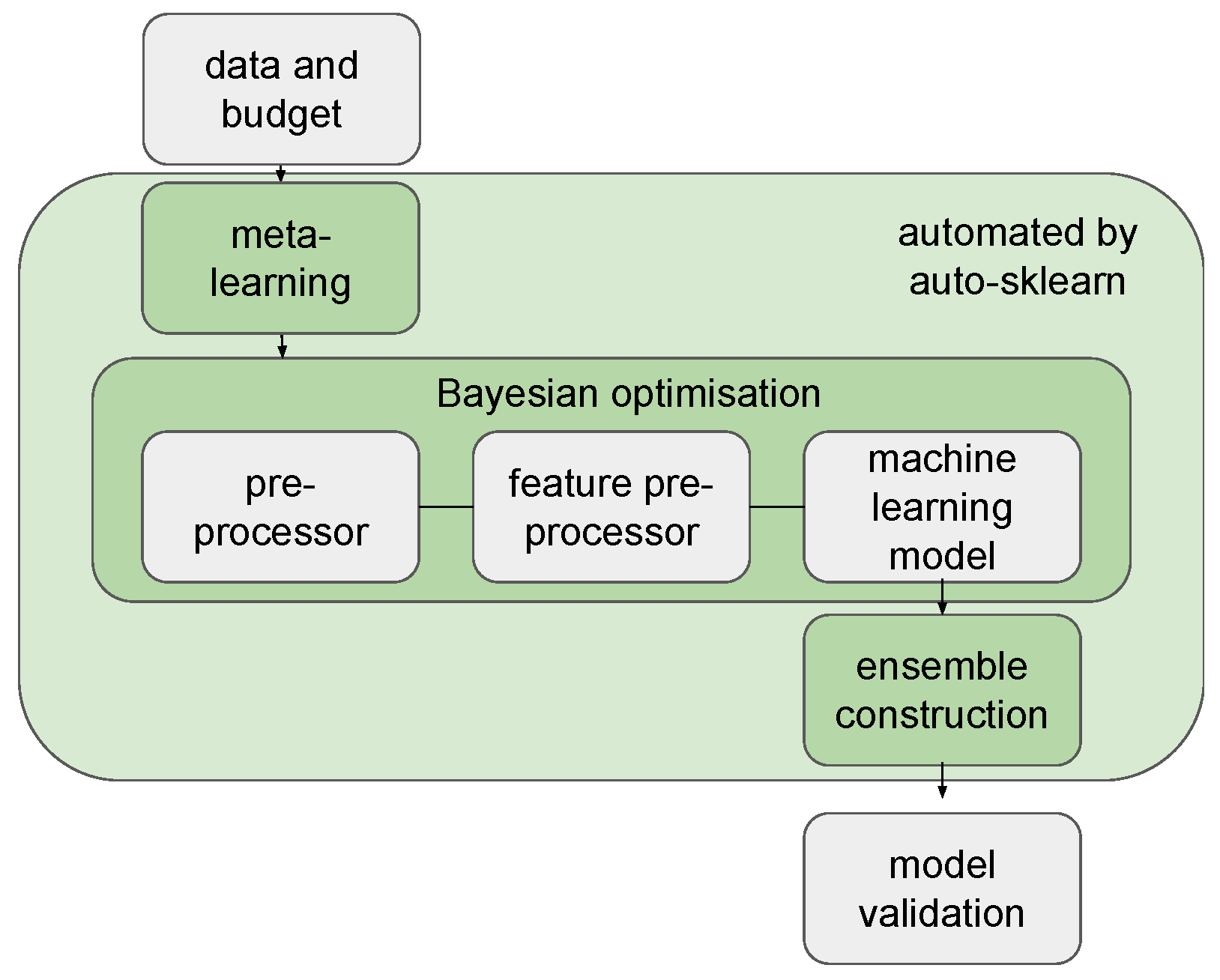
4.2. Auto-Sklearn with TS Feature Engineering
- (1)
- Auto-sklearn with automated window size selection (W): the first variant of auto-sklearn for TS forecasting optimises the window size w. The TS are used to train a model that predicts .
- (2)
- Auto-sklearn with tsfresh features (T): the second variant of auto-sklearn extracts tsfresh TS features from the TS segment to predict . In this case, the window size w is predefined and fixed. The TS features are calculated using the TS feature extractor g. Feature importance is calculated using the Benjamini-Hochberg procedure [29] to select the important features. The Benjamini-Hochberg procedure selects important features for each step in the TS separately. We then use the union of all the important features to predict .
- (3)
- Auto-sklearn with automated window size selection and tsfresh features (WT): this approach combines the two previously mentioned approaches. Both window size w and the TS extractor g are optimised in this variant.
5. Experimental Results
5.1. Data Sets
5.2. Experimental Setup
5.3. Baselines
- Gradient Boosting Machine (GBM): Gradient Boosting Machine is a classical ML model used for TS analysis tasks that has shown promising performance in the M3, M4 competitions [31]. For hyperparameter optimisation, we performed a random search on GBM with 30 iterations and window size [32]. In this case, the search space is the same as the search space of GBM in auto-sklearn. In this experiment, we did not split the training set into the training set and validation sets.
- Support vector machine (SVM): SVM is another classical ML model that has been used for TS forecasting (e.g., [13]). Similar to GBM experiments, we use 30 iterations of random search and window size . The search space is the same as the search space of SVM in auto-sklearn.
- N-BEATS: N-BEATS [33] uses fully-connected layers with residual links to improve 3% over the winner of the M4 competition, which demonstrates state-of-the-art performance. We used the default hyperparameter settings in the implementation provided by Oreshkin et al. [33] and the bootstrapping approach mentioned in Section 5 to create distributions of results. The number of epochs was set to 500.
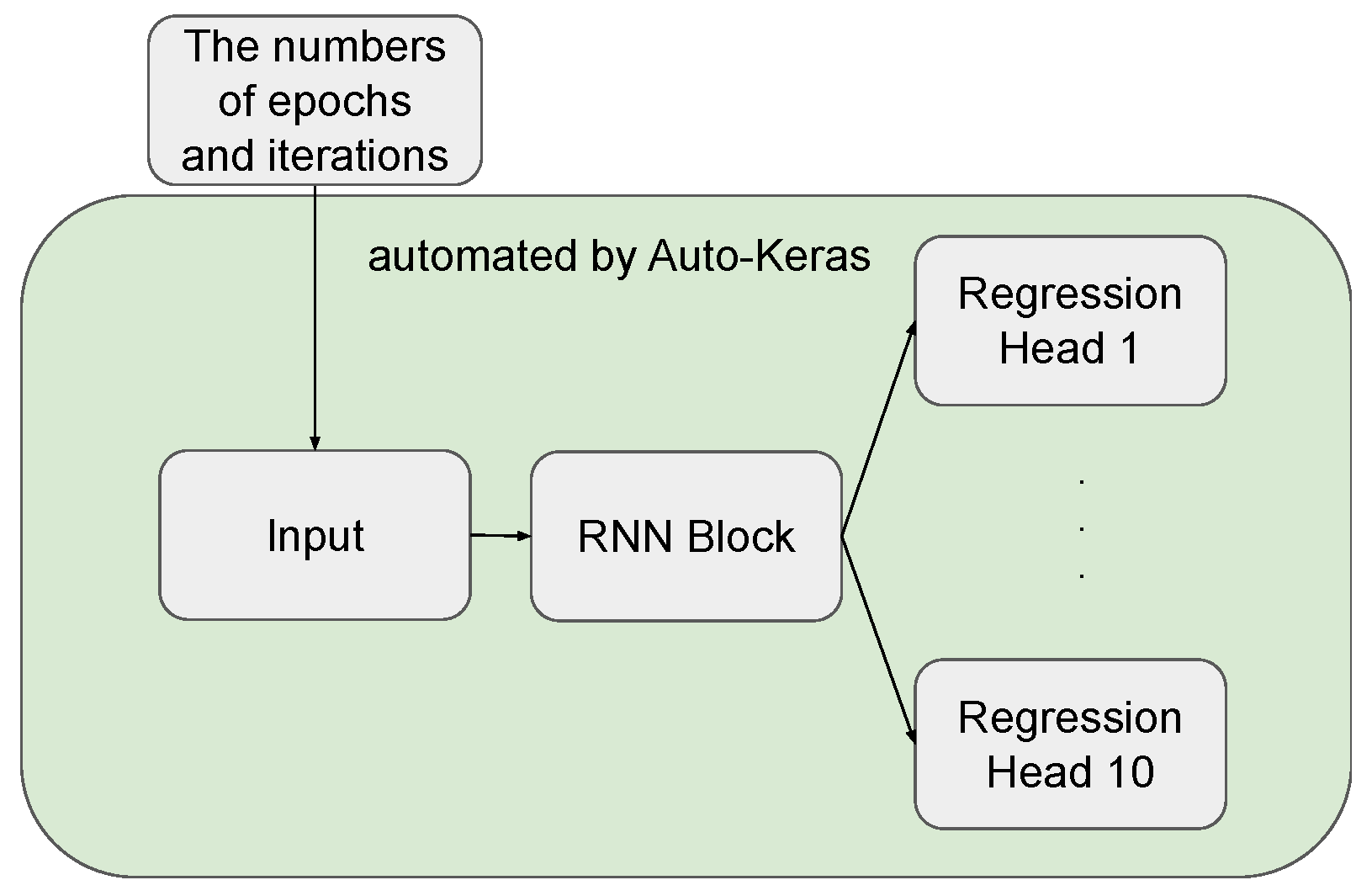
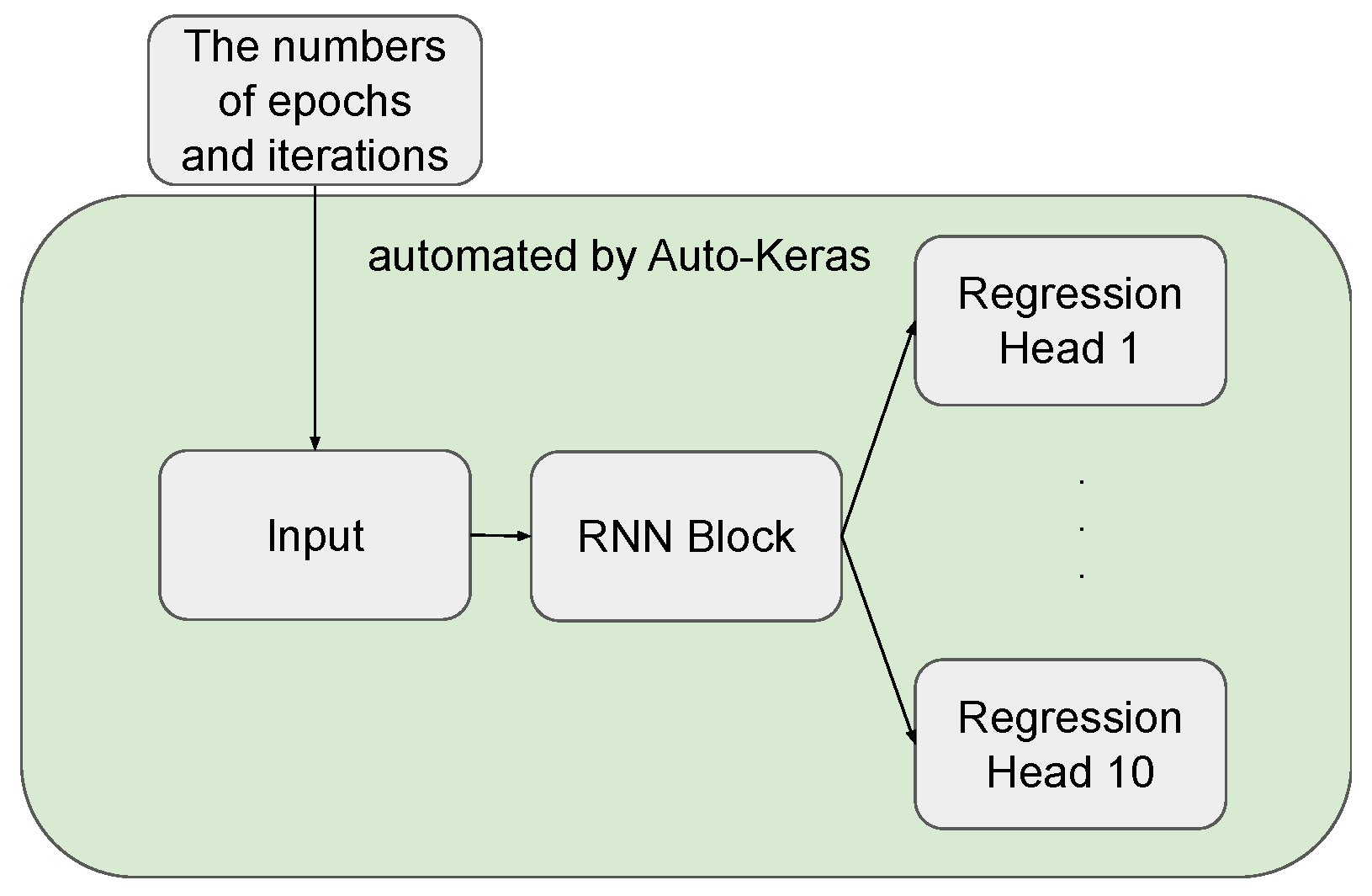
- Auto-Keras: Auto-Keras [26] is a neural architecture search system that uses Bayesian optimisation to search for high-performance neural network architectures. Some neural network units available in its search space (e.g., LSTM, GRU), have been used for TS forecasting (see, e.g., [34,35]). Vanilla Auto-Keras does not support multi-output models. To deal with multi-step forecasting tasks, we designed our new search space using three types of blocks available in Auto-Keras: Input block, RNN Block and Regression Head (see Figure 2). The RNN Block is the critical component in our networks. We use RNN as a baseline, as it has been recently studied in the literature on TS forecasting (see, e.g., [34,36]). Several hyperparameters need to be considered for this block, including bidirectionality, the number of layers and layer type (LSTM or GRU). Auto-Keras cannot choose the window size w automatically. We manually preprocessed the data with window size . We used Bayesian optimisation for architecture search. The number of epochs was set to 100, and we left the remaining settings of Auto-Keras at their default values.
- Vanilla auto-sklearn (VA): We manually preprocessed the data with window size and then fed it to the auto-sklearn. The time budget for the optimisation was set to 3 h.
5.4. Our Methods
- Auto-sklearn with automated window size selection (W): For the W variant, we did not need to manually preprocess the data, since the window size w is selected automatically. The window size ranges from 50 to 200.
- Auto-sklearn with tsfresh features (T): In the T variant, the TS feature extractor tsfresh was used as an internal component of auto-sklearn. Auto-sklearn used these TS features as input data to search over ML pipelines. The window size was set to .
- Auto-sklearn with automated window size selection and tsfresh features (WT): In WT, we set the window size w to range from 50 to 200. The TS features were extracted from these input data.
5.5. Research Questions
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| TS | Time-series |
| ML | Machine Learning |
| AutoML | Automated Machine Learning |
References
- Xiong, T.; Bao, Y.; Hu, Z. Beyond one-step-ahead forecasting: Evaluation of alternative multi-step-ahead forecasting models for crude oil prices. Energy Econ. 2013, 40, 405–415. [Google Scholar] [CrossRef] [Green Version]
- Chang, F.J.; Chiang, Y.M.; Chang, L.C. Multi-step-ahead neural networks for flood forecasting. Hydrol. Sci. J. 2007, 52, 114–130. [Google Scholar] [CrossRef]
- Chen, P.; Liu, S.; Shi, C.; Hooi, B.; Wang, B.; Cheng, X. NeuCast: Seasonal Neural Forecast of Power Grid Time Series. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, IJCAI 2018, Stockholm, Sweden, 13–19 July 2018; pp. 3315–3321. [Google Scholar]
- Nie, H.; Liu, G.; Liu, X.; Wang, Y. Hybrid of ARIMA and SVMs for Short-Term Load Forecasting. Energy Procedia 2012, 16, 1455–1460. [Google Scholar] [CrossRef] [Green Version]
- Box, G.E.; Jenkins, G.M.; Reinsel, G.C.; Ljung, G.M. Time Series Analysis: Forecasting and Control; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Nedellec, R.; Cugliari, J.; Goude, Y. GEFCom2012: Electric load forecasting and backcasting with semi-parametric models. Int. J. Forecast. 2014, 30, 375–381. [Google Scholar] [CrossRef]
- Guyon, I.; Sun-Hosoya, L.; Boullé, M.; Escalante, H.J.; Escalera, S.; Liu, Z.; Jajetic, D.; Ray, B.; Saeed, M.; Sebag, M.; et al. Analysis of the AutoML Challenge Series 2015–2018. In Automated Machine Learning; Springer: Berlin, Germany, 2019; pp. 177–219. [Google Scholar]
- Shi, X.; Mueller, J.; Erickson, N.; Li, M.; Smola, A. Multimodal AutoML on Structured Tables with Text Fields. In Proceedings of the 8th ICML Workshop on Automated Machine Learning (AutoML), Virtual, 23–24 June 2021. [Google Scholar]
- Wang, C.; Bäck, T.; Hoos, H.H.; Baratchi, M.; Limmer, S.; Olhofer, M. Automated Machine Learning for Short-term Electric Load Forecasting. In Proceedings of the 2019 IEEE Symposium Series on Computational Intelligence (SSCI), Xiamen, China, 6–9 December 2019; pp. 314–321. [Google Scholar]
- Christ, M.; Kempa-Liehr, A.W.; Feindt, M. Distributed and parallel time series feature extraction for industrial big data applications. arXiv 2016, arXiv:1610.07717. [Google Scholar]
- Hong, T.; Fan, S. Probabilistic electric load forecasting: A tutorial review. Int. J. Forecast. 2016, 32, 914–938. [Google Scholar] [CrossRef]
- Li, L.; Dai, S.; Cao, Z.; Hong, J.; Jiang, S.; Yang, K. Using improved gradient-boosted decision tree algorithm based on Kalman filter (GBDT-KF) in time series prediction. J. Supercomput. 2020, 76, 6887–6900. [Google Scholar] [CrossRef]
- Candanedo, L.M.; Feldheim, V.; Deramaix, D. Data driven prediction models of energy use of appliances in a low-energy house. Energy Build. 2017, 140, 81–97. [Google Scholar] [CrossRef]
- Taieb, S.B.; Bontempi, G.; Atiya, A.F.; Sorjamaa, A. A review and comparison of strategies for multi-step ahead time series forecasting based on the NN5 forecasting competition. Expert Syst. Appl. 2012, 39, 7067–7083. [Google Scholar] [CrossRef] [Green Version]
- Ferreira, L.B.; da Cunha, F.F. Multi-step ahead forecasting of daily reference evapotranspiration using deep learning. Comput. Electron. Agric. 2020, 178, 105728. [Google Scholar] [CrossRef]
- Sorjamaa, A.; Lendasse, A. Time series prediction using DirRec strategy. In Proceedings of the ESANN 2006, 14th European Symposium on Artificial Neural Networks, Bruges, Belgium, 26–28 April 2006; pp. 143–148. [Google Scholar]
- Coyle, D.; Prasad, G.; McGinnity, T.M. A time-series prediction approach for feature extraction in a brain-computer interface. IEEE Trans. Neural Syst. Rehabil. Eng. 2005, 13, 461–467. [Google Scholar] [CrossRef] [PubMed]
- Phinyomark, A.; Quaine, F.; Charbonnier, S.; Serviere, C.; Tarpin-Bernard, F.; Laurillau, Y. Feature extraction of the first difference of EMG time series for EMG pattern recognition. Comput. Methods Programs Biomed. 2014, 117, 247–256. [Google Scholar] [CrossRef] [PubMed]
- Christ, M.; Braun, N.; Neuffer, J.; Kempa-Liehr, A.W. Time series feature extraction on basis of scalable hypothesis tests (tsfresh—A python package). Neurocomputing 2018, 307, 72–77. [Google Scholar] [CrossRef]
- Lubba, C.H.; Sethi, S.S.; Knaute, P.; Schultz, S.R.; Fulcher, B.D.; Jones, N.S. catch22: CAnonical Time-series CHaracteristics. arXiv 2019, arXiv:1901.10200. [Google Scholar] [CrossRef] [Green Version]
- Fulcher, B.D.; Jones, N.S. hctsa: A computational framework for automated time-series phenotyping using massive feature extraction. Cell Syst. 2017, 5, 527–531. [Google Scholar] [CrossRef] [PubMed]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning Transferable Architectures for Scalable Image Recognition. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8697–8710. [Google Scholar]
- Bisong, E. Google automl: Cloud natural language processing. In Building Machine Learning and Deep Learning Models on Google Cloud Platform; Springer: Berlin, Germany, 2019; pp. 599–612. [Google Scholar]
- Wang, C.; Baratchi, M.; Bäck, T.; Hoos, H.H.; Limmer, S.; Olhofer, M. Towards time-series-specific feature engineering in automated machine learning frameworks. 2022; under review. [Google Scholar]
- Feurer, M.; Klein, A.; Eggensperger, K.; Springenberg, J.; Blum, M.; Hutter, F. Efficient and Robust Automated Machine Learning. In Advances in Neural Information Processing Systems 28; Curran Associates, Inc.: Montreal, QC, Canada, 7–12 December 2015; pp. 2962–2970. [Google Scholar]
- Jin, H.; Song, Q.; Hu, X. Auto-Keras: An Efficient Neural Architecture Search System. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; ACM: New York, NY, USA, 2019; pp. 1946–1956. [Google Scholar]
- Thornton, C.; Hutter, F.; Hoos, H.H.; Leyton-Brown, K. Auto-WEKA: Combined Selection and Hyperparameter Optimization of Classification Algorithms. In KDD’13, Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Chicago, IL, USA, 11–14 August 2013; ACM: New York, NY, USA, 2013; pp. 847–855. [Google Scholar]
- Taieb, S.B.; Bontempi, G. Recursive Multi-step Time Series Forecasting by Perturbing Data. In Proceedings of the 11th IEEE International Conference on Data Mining, ICDM 2011, Vancouver, BC, Canada, 11–14 December 2011; pp. 695–704. [Google Scholar] [CrossRef]
- Benjamini, Y.; Hochberg, Y. Controlling the false discovery rate: A practical and powerful approach to multiple testing. J. R. Stat. Soc. Ser. B (Methodol.) 1995, 57, 289–300. [Google Scholar] [CrossRef]
- Fulcher, B.D.; Lubba, C.H.; Sethi, S.S.; Jones, N.S. CompEngine: A self-organizing, living library of time-series data. arXiv 2019, arXiv:1905.01042. [Google Scholar]
- Januschowski, T.; Gasthaus, J.; Wang, Y.; Salinas, D.; Flunkert, V.; Bohlke-Schneider, M.; Callot, L. Criteria for classifying forecasting methods. Int. J. Forecast. 2020, 36, 167–177. [Google Scholar] [CrossRef]
- Bergstra, J.; Bengio, Y. Random Search for Hyper-Parameter Optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Oreshkin, B.N.; Carpov, D.; Chapados, N.; Bengio, Y. N-BEATS: Neural basis expansion analysis for interpretable time series forecasting. arXiv 2019, arXiv:1905.10437. [Google Scholar]
- Siami-Namini, S.; Tavakoli, N.; Namin, A.S. A Comparison of ARIMA and LSTM in Forecasting Time Series. In Proceedings of the 17th IEEE International Conference on Machine Learning and Applications, ICMLA, Orlando, FL, USA, 17–20 December 2018; pp. 1394–1401. [Google Scholar]
- Zhang, X.; Shen, F.; Zhao, J.; Yang, G. Time Series Forecasting Using GRU Neural Network with Multi-lag After Decomposition. In Proceedings of the Neural Information Processing—24th International Conference, ICONIP 2017, Guangzhou, China, 14–18 November 2017; Springer: Berlin, Germany, 2017; Volume 10638, pp. 523–532. [Google Scholar]
- Yamak, P.T.; Yujian, L.; Gadosey, P.K. A comparison between arima, lstm, and gru for time series forecasting. In Proceedings of the 2019 2nd International Conference on Algorithms, Computing and Artificial Intelligence, Sanya, China, 20–22 December 2019; pp. 49–55. [Google Scholar]
- Mann, H.B.; Whitney, D.R. On a test of whether one of two random variables is stochastically larger than the other. Ann. Math. Stat. 1947, 18, 50–60. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
| Dataset | RMSE (GBM -Recursive) | RMSE (GBM -Multioutput) | RMSE (SVM -Recursive) | RMSE (SVM -Multioutput) |
|---|---|---|---|---|
| Autoregre noise | 0.458890 | 0.461558 | 0.484516 | 0.459410 |
| Correlated noise | 1.872176 | 1.862137 | 2.012916 | 2.004572 |
| Lorenz Attractor | 0.102323 | 0.088045 | 0.188223 | 0.152384 |
| Pendulum | 0.112041 | 0.104519 | 0.172118 | 0.035350 |
| Driven oscillator | 0.121606 | 0.124701 | 0.231661 | 0.224206 |
| Two-well oscillator | 0.033950 | 0.032462 | 0.075318 | 0.007772 |
| Duffing oscillator | 0.025830 | 0.021330 | 0.075308 | 0.013762 |
| Moving average | 0.629791 | 0.627176 | 0.641453 | 0.622803 |
| Nonstationary | 6.049796 | 5.987631 | 6.796246 | 6.448516 |
| Random walk | 12.766561 | 13.690753 | 30.594553 | 25.654821 |
| Crude oil prices | 28.215008 | 32.909490 | 42.278003 | 20.867176 |
| ECG | 79.209558 | 103.881034 | 128.420743 | 126.1525026 |
| Exchange rate | 0.006880 | 0.006823 | 0.028571 | 0.005433 |
| Gas prices | 102.819893 | 100.612148 | 166.021626 | 172.605827 |
| Human speech | 0.059365 | 0.054838 | 0.085002 | 0.057631 |
| Macroeconomics | 779.515969 | 806.704035 | 713.073168 | 713.363569 |
| Microeconomics | 647.432403 | 705.051879 | 3500.094238 | 3865.235605 |
| Music | 0.082864 | 0.076047 | 0.068341 | 0.052978 |
| Tropical sound | 0.009468 | 0.006285 | 0.034925 | 0.008820 |
| Zooplankton | 312.033380 | 385.377067 | 319.839856 | 320.049399 |
| RMSE (N-BEATS) | RMSE (Auto-Keras) | RMSE (VA) | RMSE (W) | RMSE (T) | RMSE (WT) | |
|---|---|---|---|---|---|---|
| Autoregre noise | 0.491133 0.001470 | 0.468036 | 0.454026 0.000502 | 0.453002 0.000137 * | 0.464252 0.000286 | 0.463611 0.000302 |
| Correlated noise | 1.949831 0.012037 | 1.848905 | 1.832344 0.003727 | 1.822611 0.0009631 * | 1.841418 0.000878 | 1.843744 0.000858 |
| Lorenz Attractor | 0.076379 0.007143 | 1.248956 | 0.050628 0.009272 | 0.039705 0.003994 * | 0.140621 0.081695 | 0.249406 0.012638 |
| Pendulum | 0.113806 0.010232 | 0.512860 | 0.055285 0.020322 | 0.021416 0.022933 * | 0.154815 0.100197 | 0.177645 0.048287 |
| Driven oscillator | 0.101795 0.006627 | 0.232306 | 0.094895 0.010350 | 0.085300 0.005317 | 0.061014 0.001292 * | 0.149184 0.003854 |
| Two-well oscillator | 0.010395 0.000897 * | 0.201339 | 0.032185 0.006572 | 0.033103 0.000724 | 0.019638 0.001726 | 0.057722 0.009568 |
| Duffing oscillator | 0.004316 0.001006 * | 0.500197 | 0.011301 0.011301 | 0.010777 0.000844 | 0.020875 0.000919 | 0.019648 0.001661 |
| Moving average | 0.662554 0.002471 | 0.610291 | 0.615606 0.000661 | 0.614169 0.000080 | 0.609240 0.000326 | 0.608775 0.000241 * |
| Nonstationary | 6.253612 0.034291 | 9.888761 | 5.775404 0.048135 * | 5.783582 0.012927 * | 6.720498 0.023618 | 6.826646 0.022398 |
| Random walk | 3.099224 0.058073 * | 19.385011 | 13.478998 0.172438 | 13.240742 0.138406 | 14.765951 0.843100 | 15.411989 0.368020 |
| Crude oil prices | 32.199970 0.846056 * | 44.305246 | 34.766214 0.702608 | 34.669098 0.374047 | 33.134671 0.228864 | 35.373982 0.209542 |
| ECG | 143.617378 7.120182 | 149.577016 | 96.577900 3.258370 * | 102.0317220 14.282081 | 104.228003 1.6258357 | 103.260689 2.110540 |
| Exchange rate | 0.004831 0.001875 | 0.013859 | 0.006049 0.000130 | 0.003627 0.001326 * | 0.006886 0.000237 | 0.004569 0.001505 |
| Gas prices | 59.147486 3.122861 * | 126.112217 | 118.033606 25.754493 | 101.514037 0.021932 | 109.711360 4.170307 | 121.133289 1.387935 |
| Human speech | 0.089423 0.001085 | 0.065285 | 0.061140 0.001988 | 0.061280 0.002512 | 0.058722 0.000191 | 0.057920 0.000288 * |
| Macroeconomics | 755.905175 11.131619 | 711.622796 | 791.586127 37.469871 | 766.036513 31.082581 | 682.959633 3.559769 | 662.098158 24.511173 * |
| Microeconomics | 2179.375169 6643.906258 | 5545.979242 | 805.637017 61.049526 | 733.760632 12.795080 * | 1295.531031 34.305972 | 1348.425680 264.961810 |
| Music | 0.078767 0.001062 | 0.091060 | 0.085224 0.005985 | 0.072422 0.002119 | 0.068895 0.000906 * | 0.084715 0.002951 |
| Tropical sound | 0.010038 0.000203 | 0.010660 | 0.008483 0.000072 | 0.008407 0.000013 * | 0.008930 0.000029 | 0.008717 0.000044 |
| Zooplankton | 306.329197 2.591637 | 310.290963 | 297.091504 2.118263 | 282.485896 1.234165 | 278.597102 1.237304 * | 301.160979 4.331423 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, C.; Baratchi, M.; Bäck, T.; Hoos, H.H.; Limmer, S.; Olhofer, M. Towards Time-Series Feature Engineering in Automated Machine Learning for Multi-Step-Ahead Forecasting. Eng. Proc. 2022, 18, 17. https://doi.org/10.3390/engproc2022018017
Wang C, Baratchi M, Bäck T, Hoos HH, Limmer S, Olhofer M. Towards Time-Series Feature Engineering in Automated Machine Learning for Multi-Step-Ahead Forecasting. Engineering Proceedings. 2022; 18(1):17. https://doi.org/10.3390/engproc2022018017
Chicago/Turabian StyleWang, Can, Mitra Baratchi, Thomas Bäck, Holger H. Hoos, Steffen Limmer, and Markus Olhofer. 2022. "Towards Time-Series Feature Engineering in Automated Machine Learning for Multi-Step-Ahead Forecasting" Engineering Proceedings 18, no. 1: 17. https://doi.org/10.3390/engproc2022018017
APA StyleWang, C., Baratchi, M., Bäck, T., Hoos, H. H., Limmer, S., & Olhofer, M. (2022). Towards Time-Series Feature Engineering in Automated Machine Learning for Multi-Step-Ahead Forecasting. Engineering Proceedings, 18(1), 17. https://doi.org/10.3390/engproc2022018017