Abstract
Malware remains one of the most critical threats in the digital ecosystem, targeting both mobile and desktop platforms. Traditional signature-based detection techniques face limitations in identifying polymorphic and zero-day variants. This study proposes a static analysis-based approach using machine learning classifiers, focusing on Random Forest, Decision Tree, and Support Vector Machine (SVM). The dataset was collected from MalwareBazaar, and static features such as PE headers, entropy, and API calls were extracted. Experimental results show that SVM achieved the highest accuracy at 53.2%, while Decision Tree obtained the best F1-score at 61.1%, indicating stronger recall capabilities. Random Forest provided balanced results across all metrics with a shorter training time of 0.23 s, highlighting its efficiency for practical use. These findings demonstrate that while no single classifier dominates across all metrics, Random Forest offers a trade-off between performance and efficiency, making it suitable for large-scale static malware detection systems.
1. Introduction
1.1. Background
In today’s technological landscape, cyberattacks have become a primary concern. These attacks exploit vulnerabilities in systems for malicious intents, ranging from theft and unauthorized alterations to complete destruction. One prevalent form of cyberattack is the deployment of malware, a collection of programs intentionally created to harm computer systems, users, businesses, or individuals [1].
The rise of mobile devices has intensified security issues, with Android emerging as the most targeted operating system due to its widespread adoption and open-source nature [2,3]. Consequently, mobile platforms have become the primary target of cybercriminals, who often deploy advanced malware families such as ransomware and trojans [4].
Traditional signature-based detection remains widely used. This approach compares suspected files with a database of previously known malware signatures. While effective for detecting known threats, it fails to recognize polymorphic or zero-day variants [1,5]. To address this limitation, machine learning (ML) and deep learning (DL) methods have been increasingly applied to malware detection [6,7].
Static analysis, which examines file attributes without executing them, provides a safe and efficient means for extracting discriminative features such as PE headers, API calls, and entropy values [8,9]. These features can then be used to train ML models capable of classifying files as benign or malicious. Among various algorithms, the Random Forest (RF) classifier has demonstrated robustness in handling high-dimensional data, mitigating overfitting, and providing interpretable results [10,11].
1.2. Research Objectives
This research aims to develop a malware detection method based on static analysis utilizing machine learning, specifically the Random Forest Classifier. More specifically, this research aims to perform the following:
- Develop an automated malware dataset collection system from MalwareBazaar to build a rich and representative database for research [12].
- Perform static feature extraction from malware samples to identify patterns that can be used in the classification process. The extracted features include the PE header, entropy, API calls, and PE sections [8].
- Build a classification model based on the Random Forest Classifier that can effectively distinguish between malware and benign files [10].
- Evaluate the model’s performance using standard evaluation metrics in classification, such as accuracy, precision, recall, F1-score, and AUC-ROC curve, to ensure optimal detection effectiveness [11].
By accomplishing these objectives, this research is anticipated to contribute significantly to the development of a more robust and adaptive machine learning-based malware detection system capable of addressing emerging threats.
1.3. Research Contribution
This study contributes to cybersecurity in several ways. First, it provides a flexible ML-based detection method that can identify polymorphic and zero-day malware more effectively than signature-based systems [5,7]. Second, it evaluates the role of static features with high discriminative power, enabling more efficient classification [8]. Third, it highlights the strengths of Random Forest in malware detection compared to other algorithms [10,11]. Finally, it produces a structured malware dataset from MalwareBazaar that can serve as a reference for future research [12].
2. Literature Review
2.1. Malware Detection Approaches
Malware detection can be broadly divided into static analysis and dynamic analysis.
- Static analysis inspects files without execution, relying on attributes such as Portable Executable (PE) headers, imported functions, and entropy values [1,8]. This method is lightweight and safe, making it suitable for large-scale analysis. However, it can be bypassed through obfuscation or packing techniques [5].
- Dynamic analysis, in contrast, executes the program in a controlled environment to observe its runtime behavior, including API calls and system interactions [13]. While it provides higher accuracy against obfuscated samples, it requires significant computational resources and may be evaded by sophisticated malware [14].
A hybrid approach combining both methods has also been proposed to balance efficiency and robustness [15].
2.2. Static Analysis in Malware Detection
Machine learning (ML) has become a cornerstone of modern malware detection research. By learning from extracted features, ML models can generalize patterns to detect unknown or polymorphic malware [6,7]. Popular algorithms include Support Vector Machines (SVM), k-Nearest Neighbors (k-NN), Neural Networks, and ensemble methods [16].
Random Forest (RF), an ensemble learning technique, has shown consistent performance across different malware datasets. Its ability to handle high-dimensional data and reduce overfitting makes it suitable for static feature-based detection [10,11]. Several studies report RF outperforming other classifiers in terms of accuracy and stability, particularly in Android and ransomware detection [16].
2.3. Application of Machine Learning in Malware Detection
Machine learning has become a highly effective tool in detecting malware due to its ability to learn from patterns present in the dataset. This approach does not only rely on signatures (signature-based detection) like traditional antivirus, but can also recognize new characteristics that have never been detected before (zero-day attack).
2.3.1. Malware Detection Process with Machine Learning
The application of machine learning in malware detection consists of several main stages, namely the following:
- Feature ExtractionFeatures obtained from static analysis, such as the PE header, list of called APIs, file size, entropy, and a set of strings found in the file, are converted into a numerical format to be used in machine learning models.
- Data preprocessingThe collected data often contains irrelevant or redundant values. Therefore, normalization, cleaning, and dimensionality reduction processes are carried out to improve the model’s efficiency.
- Feature SelectionNot all extracted features have a significant impact on malware classification. Therefore, feature selection is performed using techniques such as SHAP (SHapley Additive Explanations) and Permutation Importance to retain only the features that have the most significant impact on the classification results.
- Training Machine Learning ModelsThe machine learning model is trained using a processed dataset. The model used in this research is the Random Forest Classifier, which is known for its ability to handle large datasets with complex features.
- Model EvaluationThe trained model is tested using validation data to ensure its performance. Evaluations were conducted using metrics such as precision, recall, F1-score, and AUC-ROC to assess the extent to which the model could distinguish between malware and benign files.
2.3.2. Algoritma
In this study, the Random Forest Classifier was chosen because it has several advantages compared to other algorithms:
- Can handle many features with high efficiency.
- Able to handle overfitting better than other models.
- Has better interpretability compared to deep learning.
This model works by building many decision trees and making decisions based on the majority predictions from those trees. With this approach, the model can recognize patterns in the malware dataset and distinguish between harmful and harmless files with high accuracy.
2.4. Random Forest Algorithm
The random forest classifier is an ensemble learning method that builds multiple decision trees and aggregates their predictions. This approach provides high accuracy, robustness against noise, and improved generalization compared to single classifiers.
Key advantages of Random Forest include:
- Efficiency: Can process datasets with many features effectively.
- Reduced Overfitting: Less prone to overfitting compared to traditional decision trees.
- Interpretability: Offers insights into feature importance, unlike most deep learning models.
3. Research Methodology
3.1. Research Design
This research uses machine learning methods with a Random Forest Classifier approach to classify malware samples. Data was obtained from the MalwareBazaar API, which provides various malware hashes based on specific tags. The research process is carried out in several main stages, as illustrated in Figure 1, namely the following:
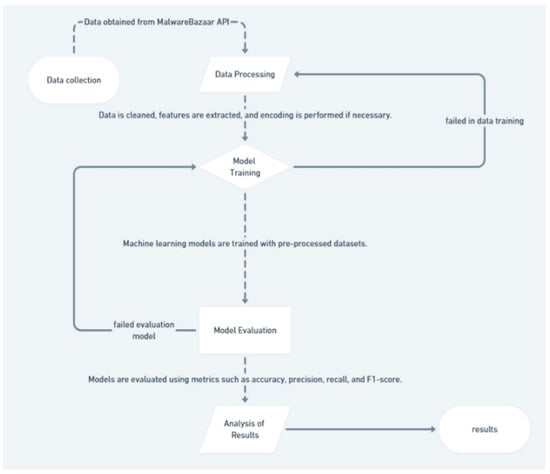
Figure 1.
Research framework.
- Data Collection: Data is obtained from the MalwareBazaar API based on the specified malware category [17].
- Data Preprocessing: Data is cleaned, features are extracted, and encoding is performed if necessary.
- Model Training: The machine learning model is trained with the processed dataset.
- Model Evaluation: The model is evaluated using metrics such as accuracy, precision, recall, and F1-score.
- Result Analysis: The model’s results were compared with other methods and further analyzed.
3.2. Statistical Analysis
Statistical analysis is performed using the Python-magic library 0.4.27 version to identify the file type and its size. Each file is scanned in real-time with a progress bar to monitor the progress. The analysis results are stored in a data frame and exported to a CSV file (malware_analysis.csv) [18].
The image displays a snippet of a CSV file containing data related to the analysis of several files in the system. CSV (Comma-Separated Values) is a commonly used format for storing data in a tabular form that can be easily processed using software such as spreadsheets or data analysis tools [19,20].
In the table, there are three main columns:
- Column “filename” (A)—Contains the name or unique representation of each analyzed file. The values in this column appear to be hash strings or file names that have been transformed into a scrambled form, often used in security systems or data management to identify files without revealing their original names.
- Column “size” (B)—Displays the size of each file in bytes. From the visible data, the file sizes vary, ranging from 96,811 bytes to 3,386,334 bytes. This indicates a significant difference in file sizes, which may be relevant in further analysis processes, such as storage management or anomaly detection in the system.
- Column “type” (C)—Identifies the file type based on the MIME (Multipurpose Internet Mail Extensions) format. All files in the table are classified as “application/zip,” which means the files are ZIP archives. This may indicate that the analyzed file is a result of compression or has been collected for storage and distribution purposes.
3.3. Visualisasi Data
On the X-axis (horizontal), there is a category “File Type”, which in this case only has one type of file, namely “application/zip”. Meanwhile, the Y-axis (vertical) represents the number of files of a certain type. From the graph, it can be seen that the number of files of type “application/zip” reaches around 600, which means the entire analyzed dataset only contains ZIP files.
From the results of this visualization, it can be concluded that the dataset used is homogeneous, as it consists of only one type of file, namely ZIP. This may indicate that the dataset originates from a collection of archives that have been compressed for the purposes of storage, archiving, or large-scale data distribution. ZIP files are often used in various scenarios, including data management, cybersecurity, and digital forensic analysis, because they allow the storage of multiple files in a single archive with compression that reduces storage size [21].
If this analysis is conducted in the context of information security, then this result can be an indicator that the system is handling a large number of compressed files, which may require further monitoring to ensure that there is no suspicious activity, such as hiding malware in ZIP archives or misuse of the system for unauthorized file storage [4]. Additionally, in the context of data management, such distribution can help organizations in storage management, considering whether the ZIP format still meets operational needs or if conversion to a more efficient format is necessary [3].
3.4. Data Analysis Techniques
- Data Preprocessing: It is a crucial step in preparing the dataset before it is used in a machine learning model. This stage begins with cleaning the data by removing irrelevant information or missing values, thereby ensuring consistent data quality [22]. Next, categorical features need to be transformed through an encoding process, such as one-hot encoding or label encoding, so that they can be processed by machine learning algorithms. Additionally, data normalization is often applied to adjust the scale of numerical features, which can enhance model performance by speeding up the training process and avoiding bias due to scale differences. By performing proper preprocessing, the dataset becomes more ready and optimal for producing an accurate and reliable model [23].
- Model Selection: It is a critical stage in building a machine learning system. In this case, the Random Forest Classifier was chosen due to its superior ability to handle datasets with many features, as well as providing easily interpretable results thanks to its decision tree structure. Additionally, Random Forest is also known to be robust against overfitting, making it a solid choice. To ensure optimality, the performance of this model is compared with other methods such as Support Vector Machine (SVM) and Neural Network in order to evaluate its relative advantages in terms of accuracy, speed, and complexity. Thus, the selection of the model is not only based on performance but also on the balance between accuracy and ease of interpretation [6].
- Model Training and Evaluation: Conducted by dividing the dataset into two parts: training data and test data with an 80:20 ratio, ensuring the model can learn well while being tested independently. To assess performance, the model is evaluated using several key metrics, such as the confusion matrix, classification report, and accuracy score, which provide a comprehensive overview of precision, recall, and accuracy. In addition, the model’s performance is also compared with the baseline or other methods using the AUC-ROC curve and cross-validation, which helps measure the model’s resilience to overfitting and its ability to consistently classify data. With this approach, the evaluation becomes more comprehensive and in-depth, ensuring that the resulting model is not only accurate but also reliable [7].
Data is encoded using category labels and divided into training data (80%) and test data (20%). The Random Forest model with 100 trees was used for classification. Evaluation was conducted using a classification report and confusion matrix.
4. Results and Discussion
4.1. Model Performance
The confusion matrix is a visual tool used to evaluate the performance of the model in detecting malware. It represents the classification results between the actual data and the data predicted by the model. Figure 2 shows the confusion matrix of the Random Forest Classifier model used in this study, while results of classifier perfomance models explained in Table 1.
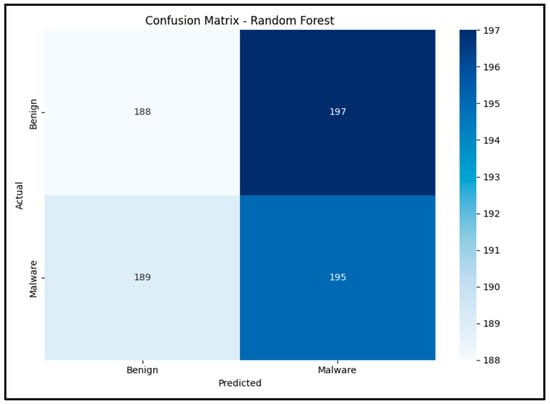
Figure 2.
Confusion matrix.

Table 1.
Classifier performance comparison.
The model correctly classified 195 malware samples (true positive) and 188 benign samples (true negative). However, 189 malware samples were incorrectly classified as benign (false negatives), and 197 benign samples were incorrectly detected as malware (false positives). While the model correctly recognized most samples, the high false positive and false negative values indicate the need for further optimization.
A number of important evaluation metrics, such as precision, recall, F1-score, and accuracy, can be calculated from the confusion matrix. In the context of malware classification, recall is important because it shows how much malware the model can correctly detect out of all the existing malware. However, high false negative values indicate a deficiency in this regard. While the model achieved good overall accuracy, the confusion matrix reveals its weak points in identifying all malware [24].
4.2. Analysis and Interpretation of Results
- Model Performance in Malware Classification:The developed model shows quite good performance in classifying certain types of malware, especially in malware classes that have sufficient data representation in the dataset. This is evident from the high accuracy and evaluation metrics for those classes. However, there are several malware classes that have a higher prediction error rate. These errors are most likely caused by two main factors: (1) the lack of data for these classes, which makes it difficult for the model to learn patterns well, and (2) the presence of overlapping features between malware classes, making it difficult for the model to distinguish between classes with similar characteristics.
- The Influence of Data Quantity on Model Performance:Models tend to perform better in detecting malware classes with a larger amount of data. This is reasonable because machine learning models require sufficient data to effectively learn patterns. Classes with little data often produce less accurate predictions, which can affect the overall performance of the model.
- Potential Performance Improvement:The model’s performance can be enhanced with several strategies. First, the addition of more relevant and informative features can help the model better distinguish between different classes of malware. Second, if there is class imbalance, data balancing techniques such as oversampling, undersampling, or the use of methods like SMOTE (Synthetic Minority Over-sampling Technique) can be applied to balance class distribution and improve the model’s ability to predict the minority class.
- Comparison with Other Models:Compared to other models such as Support Vector Machine (SVM) or Neural Network, Random Forest shows more stable and consistent results.
Random Forest has an advantage in terms of interpretability, where its decision tree structure allows for a more in-depth analysis of the features that influence decision-making. This makes Random Forest a better choice in the context of malware detection, where interpretability and model stability are very important [25].
5. Conclusions
This research evaluated the performance of three machine learning algorithms—Random Forest, Decision Tree, and Support Vector Machine for static malware detection. The results reveal that SVM achieved the highest accuracy (53.2%), indicating better overall classification ability. In contrast, Decision Tree produced the highest F1-score (61.1%) and recall, suggesting superior detection of malicious samples, albeit with a higher false positive rate. Random Forest, while not the top performer in individual metrics, provided balanced results with a competitive F1-score (50.3%) and the lowest training time (0.23 s), making it computationally efficient for practical applications [26].
Overall, the findings indicate that each classifier offers distinct strengths: SVM excels in accuracy, Decision Tree in recall and F1, and Random Forest in computational efficiency and balanced performance [27]. Future work should explore ensemble methods or hybrid static-dynamic analysis to combine these advantages and achieve higher robustness in malware detection [28].
This model has great potential for integration into real-time cybersecurity systems, enabling proactive and efficient threat detection in a constantly evolving environment [29]. This research contributes to the machine learning–based malware detection literature and presents practical solutions to improve digital security posture [30].
Author Contributions
Conceptualization, Y.P., K. and A.B.M.; methodology, Y.P., I.L.K., and K.; software, Y.P. and I.L.K.; validation, I.L.K.; formal analysis, Y.P.; resources, Y.P., A.B.M. and R.S.M.; writing—original draft preparation, Y.P., A.B.M. and R.S.M.; writing—review and editing, K. and I.L.K. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Nusa Putra University through the Nutral project.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
The data presented in this study are available on request from the corresponding author.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Tahir, R. A Study on Malware and Malware Detection Techniques. IJEME 2018, 8, 20–30. [Google Scholar] [CrossRef]
- Shatnawi, A.S.; Yassen, Q.; Yateem, A. An Android Malware Detection Approach Based on Static Feature Analysis Using Machine Learning Algorithms. Procedia Comput. Sci. 2022, 201, 653–658. [Google Scholar] [CrossRef]
- Almobaideen, W.; Abu Alghanam, O.; Abdullah, M.; Hussain, S.B.; Alam, U. Comprehensive Review on Machine Learning and Deep Learning Techniques for Malware Detection in Android and IoT Devices. Int. J. Inf. Secur. 2025, 24, 110. [Google Scholar] [CrossRef]
- Qomariah, N.; Alwi, E.I.; Asis, M.A. Analisis Malware Hummingbad dan Copycat pada Android Menggunakan Metode Hybrid. Cyber Secur. Forensik Digit. 2024, 6, 39–47. [Google Scholar] [CrossRef]
- Ferdous, J.; Islam, R.; Mahboubi, A.; Islam, M.Z. AI-Based Ransomware Detection: A Comprehensive Review. IEEE Access 2024, 12, 136666–136695. [Google Scholar] [CrossRef]
- Aslan, O.; Yilmaz, A.A. A New Malware Classification Framework Based on Deep Learning Algorithms. IEEE Access 2021, 9, 87936–87951. [Google Scholar] [CrossRef]
- Marais, B.; Quertier, T.; Morucci, S. AI-based Malware and Ransomware Detection Models. arXiv 2022, arXiv:2207.02108. [Google Scholar] [CrossRef]
- Wu, Y.; Chang, Y. Ransomware Detection on Linux Using Machine Learning with Random Forest Algorithm. TechRxiv 2024. [Google Scholar] [CrossRef]
- Dolesi, K.; Steinbach, E.; Velasquez, A.; Whitaker, L.; Baranov, M.; Atherton, L. A Machine Learning Approach to Ransomware Detection Using Opcode Features and K-Nearest Neighbors on Windows. TechRxiv 2024. [Google Scholar] [CrossRef]
- Argene, M.; Ravenscroft, C.; Kingswell, I. Ransomware Detection via Cosine Similarity-Based Machine Learning on Bytecode Representations. Authorea 2024. [Google Scholar] [CrossRef]
- Rafapa, J.; Konokix, A. Ransomware Detection Using Aggregated Random Forest Technique with Recent Variants. Authorea 2024. Available online: https://www.authorea.com/users/816233/articles/1216996 (accessed on 8 September 2025).
- Ispahany, J.; Islam, M.R.; Khan, M.A.; Islam, M.Z. A Sysmon Incremental Learning System for Ransomware Analysis and Detection. arXiv 2025, arXiv:2501.01089. [Google Scholar] [CrossRef]
- Alhogail, A.; Alharbi, R.A. Effective ML-Based Android Malware Detection and Categorization. Electronics 2025, 14, 1486. [Google Scholar] [CrossRef]
- Hadiprakoso, R.B.; Aditya, W.R.; Pramitha, F.N. Static Analysis of Android Malware Detection Using Supervised Machine Learning Algorithm. Cyber Secur. Forensik Digit. 2022, 5, 1–5. (In Indonesian) [Google Scholar] [CrossRef]
- Syeda, D.Z.; Asghar, M.N. Dynamic Malware Classification and API Categorisation of Windows Portable Executable Files Using Machine Learning. Appl. Sci. 2024, 14, 1015. [Google Scholar] [CrossRef]
- Hasan, R.; Biswas, B.; Samiun, M.; Saleh, M.A.; Prabha, M.; Akter, J.; Joya, F.H.; Abdullah, M. Enhancing Malware Detection with Feature Selection and Scaling Techniques Using Machine Learning Models. Sci. Rep. 2025, 15, 93447. [Google Scholar] [CrossRef]
- Akhtar, M.S.; Feng, T. Malware Analysis and Detection Using Machine Learning Algorithms. Symmetry 2022, 14, 2304. [Google Scholar] [CrossRef]
- Khalda, K.; Wibowo, D.K. Malware Behavior Analysis Using Static and Dynamic Analysis Approaches. J. Sains Nalar Apl. Teknol. Inf. 2025, 4, 1–8. [Google Scholar] [CrossRef]
- Yusirwan, S.; Prayudi, Y.; Riadi, I. Implementation of Malware Analysis using Static and Dynamic Analysis Method. Int. J. Comput. Appl. 2015, 117, 11–15. [Google Scholar] [CrossRef]
- Yuniati, T.; Tambunan, A.R.; Setyoko, Y.A. Implementation of Static Analysis and Background Process to Detect Malware in Android Applications with Mobile Security Framework. Ledger J. Inform. Inf. Technol. 2022, 1, 24–28. (In Indonesian) [Google Scholar] [CrossRef]
- Chowdhury, M.S. Comparison of Accuracy and Reliability of Random Forest, Support Vector Machine, Artificial Neural Network and Maximum Likelihood Method in Land Use/Cover Classification of Urban Setting. Environ. Chall. 2024, 14, 100800. [Google Scholar] [CrossRef]
- Bayazit, E.C.; Sahingoz, O.K.; Dogan, B. Deep Learning-Based Malware Detection for Android Systems: A Comparative Analysis. Tech. Vjesn. 2023, 30, 787–796. [Google Scholar] [CrossRef]
- Haque, M.A.; Ahmad, S.; Sonal, D.; Abdeljaber, H.A.M.; Mishra, B.K.; Eljialy, A.E.M.; Alanazi, S.; Nazeer, J. Achieving Organizational Effectiveness through Machine Learning-Based Approaches for Malware Analysis and Detection. Data Metadata 2023, 2, 139. [Google Scholar] [CrossRef]
- Gibert, D.; Mateu, C.; Planes, J. The Rise of Machine Learning for Detection and Classification of Malware: Research Developments, Trends and Challenges. J. Netw. Comput. Appl. 2020, 153, 102526. [Google Scholar] [CrossRef]
- Rathore, H.; Agarwal, S.; Sahay, S.K.; Sewak, M. Malware Detection Using Machine Learning and Deep Learning. In Lecture Notes in Computer Science, Proceedings of the 6th International Big Data Analytics Conference (BDA 2018), Warangal, India, 18–21 December, 2018; Springer: Cham, Switzerland, 2019; pp. 402–411. [Google Scholar] [CrossRef]
- Rele, M.; Samuel, J.; Patil, D.; Krishnan, U. Exploring Ransomware Detection Based on Artificial Intelligence and Machine Learning. Procedia Comput. Sci. 2025, 230, 548–556. [Google Scholar] [CrossRef]
- Chowdhury, R.R.; Idris, A.C.; Abas, P.E. Identifying SH-IoT Devices from Network Traffic Characteristics Using Random Forest Classifier. Wirel. Netw. 2024, 30, 405–419. [Google Scholar] [CrossRef]
- Kurniawan, F.; Stiawan, D.; Antoni, D.; Heriyanto, A.; Idris, M.Y.; Budiarto, R. Hybrid Machine Learning Model for Anticipating Cyber Crime Malware in Android: Work on Progress. In Proceedings of the 2024 11th International Conference on Electrical Engineering, Computer Science and Informatics (EECSI), Yogyakarta, Indonesia, 26–27 September 2024; pp. 499–505. [Google Scholar] [CrossRef]
- Ilham, K.F.; Ahmad, T.; Putra, M.A.R. Malware Analysis and Classification Using Grid Search Optimization. In Proceedings of the 2024 15th International Conference on Computing Communication and Networking Technologies (ICCCNT), Kamand, India, 24–28 June 2024; pp. 1–6. [Google Scholar] [CrossRef]
- Thakur, P.; Kansal, V.; Rishiwal, V. Hybrid Deep Learning Approach Based on LSTM and CNN for Malware Detection. Wirel. Pers. Commun. 2024, 136, 1879–1901. [Google Scholar] [CrossRef]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).