Abstract
This retrospective study of soft computing methods for rule mining examines the use of data mining as a method for finding important connections or trends in big datasets in order to solve challenging business problems. The effectiveness of data mining is crucial for organizations that analyze both historical and real-time data from diverse sources. However, the rapid growth in data volumes has presented challenges for traditional rule mining methods, creating demand for more advanced frameworks. This study incorporates soft computing algorithms and mathematical optimization techniques into rule mining, leading to more accurate and relevant results while reducing the time required for analysis.
1. Introduction
With the growing volume, diversity, and modular nature of data in the modern world, there is an increasing need to structure data effectively to enable the extraction of valuable information. Any predictive system, such as the weather application developed by Google, relies heavily on substantial amounts of historical data to generate forecasts for the future. The human brain serves as the most advanced computational architecture capable of identifying, thinking, and analyzing based on past experiences. This ability is a result of years of study and observation involving various aspects like objects, behaviors, and their relationships with multiple variables. However, as the volume and complexity of collected data continue to rise, the computational demands on the human brain increase significantly.
Computation complexity refers to the overall computation time required in order to perform an operation. Hence, a system-aided design is required to fulfill the increased volume and variety needs. If a system has to produce a result, there are three things that must be associated with the system, namely the dataset, the Ground Truth (GT) value, and the rule set. Dataset refers to the collection of data representing a particular event, point, or factor, and the verified, true data within it is referred to as the GT. The rule sets define the outcome of the input from the test data. The test data is the data that is generated from the real world and supplied to the system to quantify its relative class or GT in order to make a decision. Data mining is the name given to the entire process. To comprehend the architecture of the data, the data is bound with rules in the data mining architecture. For instance, two classes, “Bus” and “Train,” may have feature weights, for example, wt_train ≥ 20,000 kg and 5000 kg≤ wt_bus ≤ 20,000 kg, where wt_train and wt_bus stand for the weight of the train and the bus, respectively. In such a scenario, the associated rule would be as follows: Rule: if wt_test < 20,000 kg, then Refers Bus Else Refer Train.
With the high volume of data and variety in context, the GT needs to be defined by multiple features to establish greater co-relation among the data elements. With the increased number of attributes, the associated membership function of the input set also increases. The membership function refers to the variation in the supplied values. For example, a food dish may have three membership functions, “Good”, “Eatable” and “Avoidable”, and they are to be mapped on a statistical scale depending upon the requirement. Fuzzy logic, the Apriori algorithm, and the decision tree algorithm are some of the finest examples of statistical rule mining architectures [1]. Increasing rule sets will increase the overall computation complexity; hence, propagation-based learning behavior is proposed and works pretty well in real-world applications [2]. The recommendation system from “Netflix” is one of the perfect examples, where Netflix provides suggestions based on the previous history of the user profile.
2. Literature Review
Data mining represents a crucial process employed to unveil hidden patterns within extensive databases. Within this domain, a diverse array of functionalities, algorithms, models, and techniques are applied to uncover and extract pertinent patterns from vast data repositories [3,4]. In the last few decades, data mining has played a vital role in decision-making and is considered an essential tool for performing different operations [5,6]. The role of soft computing approaches in this context is illustrated in Figure 1.
Figure 1.
Soft computing techniques.
To discover the knowledge, data mining plays a vital role in applying the algorithms and data analysis techniques under certain limitations and produces a viable pattern over the data. According to various researchers, data mining is an effective process for discovering interesting patterns, associations, and relationships among significant structures within large databases. These databases are often stored across multiple sources, including data warehouses and data repositories. The classification of soft computing techniques is presented in Table 1.

Table 1.
Soft computing techniques.
Further, studying the literature review, it is explicit that data mining is divided into the types outlined below.
2.1. Data Mining and Functions
The kind of correlations or learning to be found throughout the data mining process can be specified using data mining functions or assignments. Summary, characterization and classification, relationship, segmentation, categorization, regression problems, extrapolation, and market analysis are a few of the key data mining functions [7]. These functions include classification, which allocates items to predetermined categories; regression, which predicts certain values as a result of some input variables; and clustering, which groups similar data points and association rule learning which finds relationships within the provided data. Each of these functions assists the data analytic workflows in the conversion of raw data into relevant output for any field, which can further be used for decision-making in marketing, finance, healthcare, etc. [8]. By leveraging these techniques, organizations can uncover trends, improve predictions, and enhance their strategic initiatives. The Functions of data mining are illustrated below.
2.1.1. The Classification
The classification of data on the predetermined classes is recognized as the process of classification, i.e., supervised learning. The classes are forecast using the classification algorithm [9]. In the literature, the researchers have proposed a large collection of classification algorithms. The algorithms include fuzzy set theory, semi-supervised learning, tough set, and fuzzy sets, as also proposed by some practitioners.
2.1.2. Summarization
Summarization generates a condensed set that provides a conceptually grounded overview of specific information. One widely employed technique for summarization is aggregation, which can be applied at multiple levels of aggregation.
2.1.3. Characterization and Discrimination
Characterization involves creating a data-driven description that helps to establish a conceptual hierarchy and characterization rules. In contrast, discrimination is used to differentiate between distinct datasets and identify variations among them. Discriminatory norms are produced as the result of discrimination.
2.1.4. Clustering
Clustering is a technique employed to partition data objects or observations into smaller, homogeneous groups known as clusters. In this process, objects that exhibit proximity or similarity are grouped together [10]. While clustering serves a similar purpose to classification by organizing related data objects, it operates under the paradigm of unsupervised learning, as the class labels are not predefined. Cluster analysis is a prominent methodology that finds applications not only in data mining but also across various disciplines, including statistics, pattern recognition, reinforcement learning, object tracking, knowledge representation, and biotechnology [11].
Various approaches are the minimum description length method, which is parameter-free and utilizes parallel computing, as well as density-based clustering. Furthermore, there is a genomic data clustering approach based on the z-score measure, a completely automated clustering method tailored for high-dimensional categorical data, as well as an intelligent swarm-based approach grounded in nature.
3. Related Work
The recent literature has explored various enhancements to traditional association rule mining. For instance, a study by Zhang et al. (2023) introduced an optimized version of the Apriori algorithm that significantly reduces the number of database scans, thereby improving efficiency in large datasets [1]. They implemented a novel pruning technique that selectively narrows down candidate item sets, leading to faster computation times without sacrificing accuracy.
Similarly, ref. [3] presented a hybrid approach that combines association rule mining with deep learning techniques. Their method utilizes neural networks to identify patterns in transactional data, which are then Patel-translated into interpretable rules. This approach demonstrates improved predictive performance and highlights the integration of machine learning with traditional rule mining methods.
The emergence of big data has necessitated the development of scalable rule mining techniques. Patel et al. [3] investigated the use of distributed computing frameworks, such as Apache Spark, to enhance the efficiency of rule mining algorithms. Their results indicate that distributed implementations significantly reduce processing times, making it feasible to analyze massive datasets in real time. Despite the progress in rule mining, several challenges persist. The research by Yang et al. [4] identifies issues such as handling noisy data and maintaining rule quality in dynamic environments. They suggest further investigation into robust algorithms capable of adapting to changes in data distributions.
Genetic algorithms (GAs) have been employed to optimize data mining processes, especially in feature selection and rule extraction. Ref. [6] developed a GA-based approach for optimizing clustering algorithms, which improved the quality of clusters in large datasets. Their research demonstrates how genetic algorithms can proficiently traverse intricate search areas to identify optimal answers. In e-commerce, rule mining techniques are utilized for customer behavior analysis and personalized marketing strategies [7]. Recent research focuses on using association rules to improve recommendation systems.
For mining sentimental analysis or finding patterns in market trends, finding vulnerability software [8], the verification of signatures [9], rule mining and finding possible patterns [10], and finding patterns in IoT systems [11,12], machine learning plays a significant role [13,14]. Classification techniques help in increasing the number of customers.
In the conducted literature review, certain research gaps were identified that will lay the foundation for certain research works.
Figure 2 illustrates the algorithm derived from the literature survey, identified through the analysis of existing research. This diagram serves to synthesize the methodologies and approaches that have been most effective in the studied field. It has been observed that there are many effective ways to enhance the rule mining approaches in which the support and confidence are evaluated by traditional methods and changes are made to the rule mining approach. There is the possibility of the application of swarm intelligence Algorithms that could be used to enhance support and confidence by a meta-heuristic approach. It has been observed that a frequent pattern approach subsequently provides what the user has demanded based on the ranking that is carried out on the basis of usage patterns [15,16].
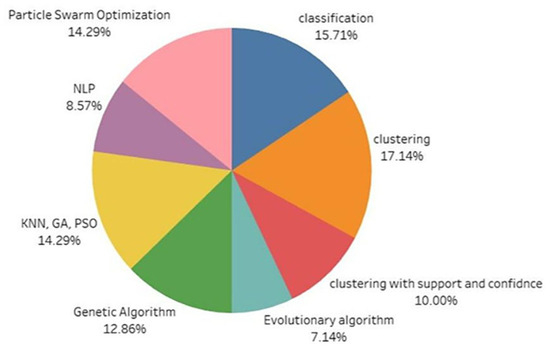
Figure 2.
This is an algorithm derived from literature survey.
The subtree generation process presented in the proposed approach not only increases the computation complexity but also produces score variation via root node shifting that sometimes results in bad mining results. The subtree graph generation could have been removed by using training and classification architecture. It has been observed that the swarm intelligence approach could be utilized to improve the rule mining that was carried out using the Apriori algorithm.
It has been observed that the genetic algorithm was used to reduce the computation complexity of the rule mining engine. GA belongs to the natural computing approach and requires an adaptive swarm-based architecture if it is applied to a small set of data. GA requires a larger amount of data for the generation of the mutation and the crossover [12]. Hence, a swarm intelligence-based combination could have been adopted.
Figure 3 presents a word cloud that visually highlights the most frequently used keywords in the literature survey. The size of each keyword indicates its prevalence, providing insight into the key themes and areas of focus within the research. Graph 1 represents the year-wise distribution of techniques. There was a significant rise in publications in 2015, as depicted in Figure 4.

Figure 3.
Word cloud representing frequently used keywords.
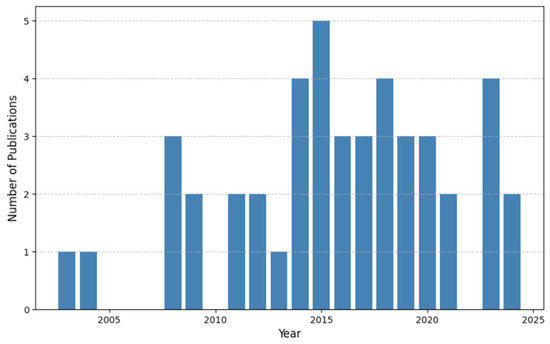
Figure 4.
Year-wise distribution of publication.
4. Conclusions
All things considered, this study stresses the value of applying the combined metrics of support, confidence, lift, leverage, and conviction when evaluating the interestingness of rules in association rule mining. These metrics have shown significant potential in deriving relevant and meaningful rules. Additionally, exploring new metrics, such as amplitude, may lead to the discovery of even more valuable patterns. The findings suggest that performance can be improved by automating the threshold selection for support and confidence, which would eliminate the need for manual tuning. Furthermore, the lack of application of algorithms tailored for categorical datasets in existing models reveals a promising direction for future research. Finally, increasing the support value has been shown to yield more relevant and efficient rules, offering opportunities to enhance the overall effectiveness of rule generation techniques.
Author Contributions
Conceptualization, M.R., U.M., I.B. and F.S.; methodology, M.R. and I.B.; validation, U.M. and F.S.; formal analysis, M.R. and U.M.; investigation, I.B.; resources, F.S.; writing, original draft preparation, M.R. and U.M.; writing review and editing, I.B. and F.S.; supervision, I.B. All authors have read and agreed to the published version of the manuscript.
Funding
No external funding was received for this study.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data supporting the findings of this study are available from the corresponding author upon reasonable request.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Zhang, X.; Zhang, J. Analysis and research on library user behavior based on apriori algorithm. Meas. Sens. 2023, 27, 100802. [Google Scholar] [CrossRef]
- Chen, W.; Liang, Y.; Zhu, Y.; Chang, Y.; Luo, K.; Wen, H.; Zheng, Y. Deep learning for trajectory data management and mining: A survey and beyond. arXiv 2024, arXiv:2403.14151. [Google Scholar] [CrossRef]
- Jha, P.; Tiwari, A.; Bharill, N.; Ratnaparkhe, M.; Patel, O.P.; Harshith, N.; Nagendra, N. Apache Spark-based scalable feature extraction approaches for protein sequence and their clustering performance analysis. Int. J. Data Sci. Anal. 2023, 15, 359–378. [Google Scholar] [CrossRef]
- Yang, J.; Wang, W.; Yu, P.S.; Han, J. Mining long sequential patterns in a noisy environment. In Proceedings of the 2002 ACM SIGMOD International Conference on Management of Data, Madison, WI, USA, 3–6 June 2002; pp. 406–417. [Google Scholar]
- Khalid, F.; Javed, A.; Ilyas, H.; Irtaza, A. DFGNN: An interpretable and generalized graph neural network for deepfakes detection. Expert Syst. Appl. 2023, 222, 119843. [Google Scholar] [CrossRef]
- Du, Z.; Fan, Z.P.; Sun, F. Live streaming sales: Streamer type choice and limited sales strategy for a manufacturer. Electron. Commer. Res. Appl. 2023, 61, 101300. [Google Scholar] [CrossRef]
- Ali, S.; Hafeez, Y.; Humayun, M.; Jhanjhi, N.Z.; Le, D.N. Towards aspect-based requirements mining for trace retrieval of component-based software management process in globally distributed environment. Inf. Technol. Manag. 2022, 23, 151–165. [Google Scholar] [CrossRef]
- Shah, I.A.; Rajper, S.; ZamanJhanjhi, N. Using ML and Data-Mining Techniques in Automatic Vulnerability Software Discovery. Int. J. Adv. Trends Comput. Sci. Eng. 2021, 10, 2109–2126. [Google Scholar] [CrossRef]
- Jindal, U.; Dalal, S.; Rajesh, G.; Sama, N.U.; Jhanjhi, N.Z.; Humayun, M. An integrated approach on verification of signatures using multiple classifiers (SVM and Decision Tree): A multi-classification approach. Int. J. Adv. Appl. Sci. 2021, 9, 99–109. [Google Scholar] [CrossRef]
- Batra, I.; Verma, S.; Janjua, K. Performance analysis of data mining techniques in IoT. In Proceedings of the 2018 4th International Conference on Computing Sciences (ICCS), Phagwara, India, 30–31 August 2018; pp. 194–199. [Google Scholar]
- Al-Quayed, F.; Humayun, M.; Alnusairi, T.S.; Ullah, I.; Bashir, A.K.; Hussain, T. Context-Aware Prediction with Secure and Lightweight Cognitive Decision Model in Smart Cities. Cogn. Comput. 2025, 17, 44. [Google Scholar] [CrossRef]
- Rana, M.; Dahiya, O.; Singh, P.; Boulila, W.; Ammar, A. Grouped ABC for feature selection and mean-variance optimization for rule mining: A hybrid framework. IEEE Access 2023, 11, 85747–85759. [Google Scholar] [CrossRef]
- Aldughayfiq, B.; Ashfaq, F.; Jhanjhi, N.Z.; Humayun, M. YOLO-Based Deep Learning Model for Pressure Ulcer Detection and Classification. Healthcare 2023, 11, 1222. [Google Scholar] [CrossRef] [PubMed]
- Aldughayfiq, B.; Ashfaq, F.; Jhanjhi, N.Z.; Humayun, M. Explainable AI for Retinoblastoma Diagnosis: Interpreting Deep Learning Models with LIME and SHAP. Diagnostics 2023, 13, 1932. [Google Scholar] [CrossRef] [PubMed]
- Aherwadi, N.; Mittal, U.; Singla, J.; Jhanjhi, N.Z.; Yassine, A.; Hossain, M.S. Prediction of Fruit Maturity, Quality, and Its Life Using Deep Learning Algorithms. Electronics 2022, 11, 4100. [Google Scholar] [CrossRef]
- Ray, S.K.; Sinha, R.; Ray, S.K. A smartphone-based post-disaster management mechanism using WIFI tethering. In Proceedings of the 2015 IEEE 10th Conference on Industrial Electronics and Applications (ICIEA), Auckland, New Zealand, 15–17 June 2015; pp. 966–971. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).