Abstract
Online Courses are one of the most popular ways to learn, but the technology used has a vital effect on the learner. In this study, we will research the prediction of students’ course engagement. International surveys show that students have a 70% interest in joining online learning, and just 30% of students are interested in traditional learning. However, keeping students engaged is one of the most difficult tasks, since low engagement contributes to lower learning outcomes and higher dropout rates. We studied more than 15 papers of existing research, and were able to achieve a 96% accuracy rate, which is a very welcome improvement on previous results. This paper examines machine learning algorithms, including Decision Trees, Random Forest, Gradient Booster, Naive Bayes, and K-Nearest Neighbors (KNN), to efficiently predict engagement during online courses. By systematically examining existing published research studies, we identify gaps and limitations of existing methods, such as problems with variant datasets, chances of overtraining, and a lack of accessibility to real-time engagement data.
1. Introduction
The change towards digital education has greatly enhanced the convenience of knowledge, removing traditional obstacles such as location, time, and financial constraints. Students can now engage in courses from any location at any time according to their learning preferences. While this method is beneficial, it also impacts their motivation to attend online lectures. With the flow of online educational programs, learners have access to extensive resources and various learning experiences. However, this move towards online education introduces several challenges, especially regarding student engagement.
Achieving effective engagement is essential for optimizing the learning experience, yet it remains a complicated and complex concept that includes behavioral, emotional, and cognitive dimensions. In another research paper, the behavioral and cognitive dimensions of engagement were explored. One study analyzed the impact of self-directed learning and motivation on academic performance. Using surveys and structural equation modeling, it revealed that self-directed learning had the strongest correlation with performance, while internet self-efficacy was insignificant [1]. When the internet was invented, the world changed to a global village. Today, every business requires a strong internet connection for activities. Nowadays, digital learning is at its peak; every person wants to learn digitally from any place and time. International surveys show that 70% of students want to take courses online, and just 30% want to join traditional learning. Through the analysis of data from student interactions, behaviors, and performance, machine learning models can identify learners at risk of disengagement early in the course. Figure 1 shows how such predictive models can reveal disengagement trends, allowing educators to implement proactive, personalized strategies to re-engage students. These models can predict disengagement trends, enabling educators to proactively introduce personalized strategies to re-engage students and prevent dropouts. Such predictive frameworks provide a more focused and efficient means of meeting learner needs compared to conventional approaches. In this study, we will verify the role of digital learning that predicts student participation in the online course and evaluate the existing methods used to analyze and predict student participation and emphasize their advantages and weaknesses. Our complex approach combines probabilistic and ensemble models and has shown promising results in improving the reliability and accuracy of predictions. We aim to help create more effective predictive engagement tools that educators and institutions can use to improve online learning experiences. We use the capabilities of machine learning to reduce more personal and effective educational methods in today’s digital landscape.
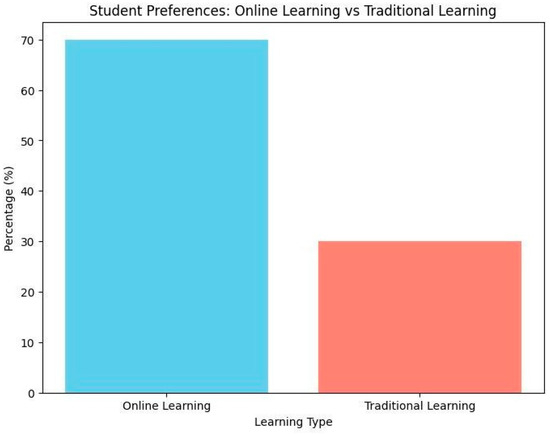
Figure 1.
Online leaning vs. traditional learning.
2. Literature Review
Now, we will dive into the existing research on student engagement prediction. To develop an effective predictive framework, we conducted an in-depth review of 19 studies, each contributing unique insights and methodologies. This section elaborates on the methodologies, findings, and limitations of these studies, highlighting how existing work has informed the foundation of this research. The anticipation of students’ enrollment in online classes is a crucial aspect of online student engagement enhancement research. The efforts in developing AI-enhanced behavioral engagement detection were propelled by utilizing Transformations-Digitalization magazine and automated involvement detection aimed at automating participation detection. The system recognizes various learning activities within cyberspace and employs a multi-class classification model to assess the engagement patterns and thereby make more fine-grained predictions. Engagement prediction and analytics with strategic frameworks for appreciating strong predictors for engagement spans are the main points identified. However, there are still some remaining concerns, such as a lack of session-oriented analysis, imprecise controlling, and binary classification means 0 and 1 of available APIs (Application Programming Interfaces). Solving these above problems is crucial for predicting student engagement in online learning [2]. We also studied an analysis of different methods that was proposed in previous studies for detecting student engagement, including teacher questionnaires, checklists and different case studies. Additionally, Decision Tree, SVM (Support Vector Machine), and ANN (Artificial Neural Network) algorithms were introduced for prediction performance and engagement assessment. These studies show that ML (Machine Learning) models like ANN are likely accurate, at 85% maximum, and Decision Tree also approaches a good score. Teachers’ checklists and other case studies also predict good accuracy. Also, the prediction system clearly warned teachers about the possibility of dropout, allowing them to intervene at the right time. The results obtained indicate the benefit of implementing a hybrid model of the participatory monitoring system that integrates the standard approach with machine learning transformations [3]. Our research extends into advanced machine learning techniques and statistical methods to perceive the way students show up for class. An analysis of engagement patterns was performed by utilizing supervised learning with the Random Forest algorithm, as well as unsupervised clustering, which operates with the Expectation-Maximization (EM) Algorithm. Spearman’s correlation coefficient was performed to analyze the correlations between engagement variables. The models managed to distinctively categorize different types of learning behavior with an overall accuracy of 84.10% and an RMSE of 12.35. To strengthen the results, outliers were eradicated from the analysis. Still, the fact that students logged data may lead to the loss of meaningful elements of engagement, and survey methods in most instances are biased. The evaluation of unconstrained learning systems and the generalizability of the conclusions to new contexts are also limited. Overcoming these limitations is an important step towards the improvement of engagement prediction techniques [4]. Another research paper shows that students are motivated to engage in self-directed online learning which positively impacts their academic performance and promotes self-efficacy. This study employed an Online Learning Readiness Scale survey within a framework using SEM (Structural Equation Modeling), Pearson correlation, linear regression analysis, and reliability analysis. The finding indicates that students’ readiness to embrace online self-directed learning was the biggest local e-learning predictor, and e-learning willingness was second. Tailoring and customization must be developed, as embodiment is limited by the type of students and one type of online course; this can invariably hinder the generalizability of the results [5]. This study uses multiple predictive models including Random Forest, Multilayer perceptron, Neural Network, and Gradient Boosting Machine to predict student performance. Random Forest achieved the lowest accuracy, while the Gradient Boosting Machine achieved the highest accuracy, of 0.086. This paper has some limitations, including potential overfitting and poor MLP (Multi Layer Perceptron) performance [6]. Another study uses Random Forest’s robustness through feature engineering on the DEEDS (Digital Electronics Education and Design Suite) dataset, achieving 94.4% accuracy, outperforming comparable studies. However, these models faced challenges regarding overfitting and dataset-specific constraints. This paper had much better accuracy than the existing one, which shows it is better than the previous results, but another paper achieved 96% accuracy or higher, making it a good one to present [6]. Going forward, CAT-Boost (Categorical Boosting) and XG-Boost (Extreme Gradient Boosting) were introduced, achieving over 92% accuracy and precision in engagement prediction. In this study, CAT-Boost and XG-Boost were used and the results had maximum 92% accuracy. These results demonstrated the effectiveness of ensemble techniques in handling categorical and numerical data, further emphasizing their adaptability to various data contexts [7]. In another research paper, behavioral and cognitive dimensions of engagement were also explored. One study analyzed the impact of self-directed learning and motivation on academic performance. Using surveys and structural equation modeling, it revealed that self-directed learning had the strongest correlation with performance, while internet self-efficacy was insignificant [8]. Another study expanded on this work by examining the emotional and cognitive engagement of students, using PLS-SEM (Partial Least Squares Structural Equation Modeling) to explain adjustments across dimensions like participation and skills. Basic motivation was a significant predictor, while extrinsic motivation had no effect, suggesting a need to foster internal drivers of engagement [9]. These studies provide valuable insights into the psychological aspects of engagement but are limited by small sample sizes and a lack of integration with dynamic learning data [8,9]. Multivariate analysis and natural language processing (NLP) are increasingly applied to entry prediction. One study used neural networks and NLP techniques to identify students at risk of dropping out, using textual content and speed as indicators of engagement. While this approach is useful for real-time monitoring, it suffers from language complexity and a lack of data [10]. Neural Turing Machines were employed for multi-modal feature extraction, incorporating eye gaze, facial expressions, and body pose to enhance engagement recognition. This innovative approach outperformed traditional models but faced challenges related to video feature redundancy and environmental noise [11]. These advancements highlight the potential of combining behavioral, linguistic, and physiological data for comprehensive engagement prediction [10,11]. Table 1 summarizes the methodologies employed in previous studies along with their reported accuracies.
Knowledge Gaps and Limitations in Existing Work
Across the reviewed studies, several recurring limitations were identified:
- Dataset Diversity: Many studies relied on specific datasets, limiting generalizability. For instance, one study used only the DEEDS dataset, while another focused on a single course [6,12].
- Overfitting Risks: Ensemble methods like Gradient Boosting faced overfitting challenges in some studies [5].
- Exclusion of Real-Time Data: Most studies used static datasets, with limited exploration of dynamic, session-level engagement [1,2].
- Sample Size Constraints: Several studies were limited by small participant groups, reducing the robustness of their findings [8,9].

Table 1.
Summary of methodologies and accuracy from previous studies.
Table 1.
Summary of methodologies and accuracy from previous studies.
| References | Methodologies | Accuracy |
|---|---|---|
| [1] | Supervised algorithms using Moodle logs | N/A |
| [2] | Decision Tree, SVM, ANN | ANN: 85% |
| [3] | Random Forest, Clustering | 84.10% |
| [5] | Gradient Boosting, Random Forest, Neural Network | Random Forest: 95% |
| [8] | Random Forest with feature engineering | 94.40% |
| [11] | CATBoost, XGBoost | CATBoost: 94.40% |
| [12] | J48, JRIP, Gradient Booster | J48: 88.52% |
3. Methodology
In this study, we deployed five machine learning models—Decision Tree, Random Forest, Gradient Booster, Naive Bayes, and KNN—to predict engagement levels in online courses. The flow of our work from starting point to finalized results is as in [11]. Here is a flow of the complete steps from start to end of dataset collection to the finalizing of the results. The overall research workflow is illustrated in Figure 2, which provides an overview of the proposed methodology.
3.1. Dataset Preparation
The dataset used in this study has a total of 9000 rows and their partition is 48% by 52%, which shows its balance and that it is ready to use in our study. The columns included Course Category, Time Spent on the Course, Number of Videos Watched, Number of Quizzes Taken, Quiz Score, Completion Rate, Device Type, and Course Completion. These features were designed to capture various aspects of student engagement, such as the frequency of course interactions, time spent on learning materials, quiz scores, and forum participation [12]. Data preprocessing played an important role in preparing the dataset for machine learning. The steps taken were as follows: Normalization: Normalization was applied to ensure all features were on a comparable scale. This process scaled the numerical data to a uniform range, typically between 0 and 1. Normalization is essential for models like KNN, which are sensitive to the magnitude of the features, and helps prevent certain features from dominating others based on their scale.
3.2. Model Selection
Below are the models selected for this research based on their accurate performance and stability for predicting engagement levels in online courses:
- Decision Tree: Decision trees are chosen as the primary example due to their simplicity and interpretability. They provide a clear, principled basis for decision making, making it easy to understand the factors that influence engagement. While they tend to be quite complex, they can serve as a useful starting point for comparison with more complex models.
- Random Forest: This clustering method aggregates multiple decision trees, which helps improve the overall model by reducing the bias and variability associated with individual decision trees. Random Forests are very useful when dealing with large datasets and are less likely to be added to a single decision tree. They are a strong candidate for this study because of their ability to handle data, including statistical data.
- Gradient Booster: This model was chosen due to its strong ability to capture complex relationships and non-linearities in the data. Gradient boosting works by adding decision trees to correct for errors made by previous decision trees. This iterative process improves the accuracy of the model, which is particularly useful for datasets with confounding factors, such as predicting student enrollment.
- Naive Bayes: Naive Bayes is a probability model that assumes independence between estimates and is simple and efficient for tasks involving categorical data. Despite its simplicity, Naive Bayes works well when independence assumptions are met. It was chosen to study how the program reflects participatory politics.
- KNN (K-Nearest Neighbors): Number of their nearest neighbors. Although KNN is intuitive and easy to implement, it is very sensitive to the size of the data, which can affect its performance if not implemented properly. It aims to examine how a simple non-parametric model performs in this context.

Figure 2.
Methodology workflow.
3.3. Evaluation Metrices
To evaluate the performance of the models, we used different measurement techniques. Using these metrics, we were able to assess the accuracy and robustness of each model, as well as their ability to predict the level of good integration. The following steps were used:
- Accuracy: The ratio of correctly predicted instances to all instances. This measure gives a global evaluation of how well the model is performing.
- Precision: The ratio of true positive predictions over all positive predictions. Precision is particularly crucial when the false positive cost is extremely high, like in the case of predicting a student is active when they are not.
- Recall: Number of true positive predictions out of all actual positives. Recall is desirable when the aim is to minimize false negatives, i.e., failing to find students at risk of disengagement.
- F1-Score: Harmonic mean of precision and recall, providing an equal weight to both precision and recall. This is helpful for imbalanced datasets, where class distribution may favor one class compared to another.
These evaluation metrics allowed us to compare the models’ performance comprehensively, ensuring that we not only considered the overall accuracy but also the trade-offs between false positives and false negatives.
4. Results
In our research, we used the below models and beat the previous once. Their results are mentioned, along with their name and accuracy. Our best results were with Decision Tree, Random Forest, and Gradient Booster. The results we obtained were much better than those in previous studies. Table 2 presents the results, highlighting the accuracy levels and corresponding strengths of the proposed approach.
Table 2.
Comparison of classification models based on accuracy and strengths.
4.1. Random Forest
Random Forest attained 96.11%. Random Forest performs well with high-dimensional datasets, benefiting from the combination of multiple decision trees, which helps it generalize better than individual decision trees. This model’s ability to combined results from many trees provides robustness and higher stability, making it a strong contender for engagement prediction tasks. Figure 3 illustrates the Random Forest process in RapidMiner. Figure 4 shows the confusion matrix of the Random Forest model, illustrating its classification performance.
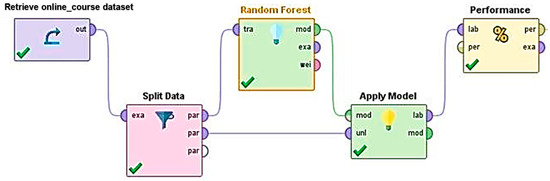
Figure 3.
Random Forest process in Rapid Miner as an Example.
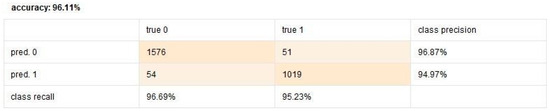
Figure 4.
Random Forest confusion matrix.
4.2. Decision Tree
This model achieved 96.07% accuracy, emphasizing its capability to handle categorical data effectively. The model’s performance indicates its suitability for engagement prediction tasks where clear, rule-based decisions are required. However, while decision trees excel at classification, their performance may degrade in cases of overfitting or high feature connection. Figure 5 illustrates the Decision Tree process in RapidMiner. Figure 6 shows the confusion matrix of the Decision Tree model, illustrating its classification performance.
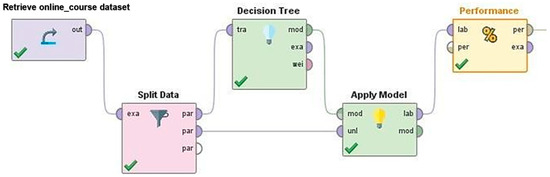
Figure 5.
Decision Tree process.
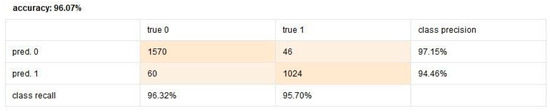
Figure 6.
Decision Tree confusion matrix.
4.3. Gradient Booster
This reached 95.78% accuracy, excelling in datasets with complex feature interdependencies. Gradient boosting methods iteratively correct errors made by previous trees, resulting in a strong predictive model. The high accuracy is indicative of the model’s capacity to capture intricate patterns in the data. However, it is more prone to overfitting compared to Random Forest, especially if hyperparameters are not carefully tuned. Figure 7 shows the confusion matrix of the Gradient Boosting model, illustrating its classification performance.
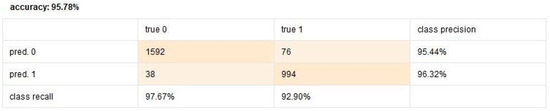
Figure 7.
Gradient Booster confusion matrix.
4.4. Naïve Bayes
This delivered 82% accuracy, with limitations in the modeling of non-independent features. Despite its simplicity, Naive Bayes performs well on datasets where features are largely independent. In this context, its assumptions about feature independence hinder its performance when dealing with complex relationships between features, such as those found in online engagement behaviors.
4.5. KNN (K-Nearest Neighbors)
This achieved 71% accuracy, hindered by sensitivity to high-dimensional data and feature scaling. KNN’s performance is highly dependent on the choice of distance metric and the scale of the features, which can result in reduced accuracy when dealing with a large number of features or poorly scaled data. While KNN is a simple and interpretable model, its performance lags behind more sophisticated models in this application. These results repeat the effectiveness of ensemble methods in engagement prediction, such as Random Forest for predicting engagement.
5. Conclusions
In this study, we started by examining the existing work on predicting course engagement with machine learning. More than 12 studies show different results according to their research; every paper provides different accuracy and results along with their methodologies. Our research showed 94% maximum accuracy, which is good for predicting student engagement in course learning. We have researched this idea and obtained a very balanced dataset which consists of 9000 rows and is balanced for deployment for the rapid checking of accuracies of different models. We also performed some crucial steps like data preprocessing and outlier removal. Our study deployed five models, including Random Forest, Decision Tree, KNN, Gradient Booster, and Naïve Bayes, and achieved 96% above maximum accuracy, which is better than the results of previous studies. Our results, methods, and accuracy are much better than previous ones. Our results and accuracy show better parameters, which makes this an optimal method.
Author Contributions
F.Z.A. conceived the study, designed the methodology, and supervised the overall research process. R.A. was responsible for data collection, preprocessing, and implementation of the machine learning models. I.S. contributed to the analysis, interpretation of results, and drafting of the manuscript. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data that support the findings of this study are available from the corresponding author upon reasonable request.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Torun, E.D. Online Distance Learning in Higher Education: E-Learning Readiness as a Predictor of Academic Achievement. Open Praxis 2020, 12, 191–208. [Google Scholar] [CrossRef]
- Naik, V.; Kamat, V. Predicting Engagement Using Machine Learning Techniques. In Proceedings of the International Conference on Computers in Education (ICCE 2018), Manila, Philippines, 26–30 November 2018. [Google Scholar]
- Orji, F.; Vassileva, J. Using Machine Learning to Explore the Relation Between Student Engagement and Student Performance. In Proceedings of the 24th International Conference Information Visualization, Melbourne, Australia, 7–11 September 2020. [Google Scholar]
- Soffer, T.; Cohen, A. Students’ Engagement Characteristics Predict Success and Completion of Online Courses. J. Comput. Assist. Learn. 2019, 35, 378–389. [Google Scholar] [CrossRef]
- Ayouni, S.; Hajjej, F.; Maddeh, M.; Al-Otaibi, S. A New ML-Based Approach to Enhance Student Engagement in the Online Environment. PLoS ONE 2021, 16, e0258788. [Google Scholar] [CrossRef] [PubMed]
- Alshabandar, R.; Hussain, A.; Keight, R.; Khan, W. Students Performance Prediction in Online Courses Using Machine Learning Algorithms. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020. [Google Scholar]
- Ben Brahim, G. Predicting Student Performance from Online Engagement Activities Using Novel Statistical Features. Arab. J. Sci. Eng. 2022, 47, 10225–10243. [Google Scholar] [CrossRef] [PubMed]
- Alruwais, N.; Zakariah, M. Student-Engagement Detection in Classroom Using Machine Learning Algorithm. Electronics 2023, 12, 731. [Google Scholar] [CrossRef]
- Vezne, R.; Yildiz Durak, H.; Atman Uslu, N. Online Learning in Higher Education: Examining the Predictors of Students’ Online Engagement. Educ. Inf. Technol. 2023, 28, 1865–1889. [Google Scholar] [CrossRef] [PubMed]
- Toti, D.; Capuano, N.; Campos, F.; Dantas, M.; Neves, F.; Caballé, S. Detection of Student Engagement in E-Learning Systems Based on Semantic Analysis and Machine Learning. In Advances on P2P, Parallel, Grid, Cloud and Internet Computing; Springer: Cham, Switzerland, 2021. [Google Scholar]
- Diwaker, C.; Tomar, P.; Solanki, A.; Nayyar, A.; Jhanjhi, N.Z.; Abdullah, A.; Supramaniam, M. A New Model for Predicting Component-Based Software Reliability Using Soft Computing. IEEE Access 2019, 7, 147191–147203. [Google Scholar] [CrossRef]
- Kok, S.H.; Abdullah, A.; Jhanjhi, N.Z.; Supramaniam, M. A review of intrusion detection system using machine learning approach. Int. J. Eng. Res. Technol. 2019, 12, 8–15. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).