
A Complete System for Automated Semantic–Geometric Mapping of Corrosion in Industrial Environments



Abstract
1. Introduction
- Portability: Inspectors should be able to easily carry and operate the data collection device in industrial assets during long periods.
- Accuracy: High precision imaging sensors for accurate 3D semantic mapping of corroded assets.
- Autonomy: Intelligent software that should be able to perform mapping, localization, and semantic localization and categorization of industrial assets from sensory data. However, the software may not strictly run online, on the data collection device, but instead offline in a more powerful computational device.
- Design of a portable, accurate, and autonomous system for detection corrosion based on the integration state-of-the-art technologies.
- Algorithmic design and full prototype implementation of the integrated system.
- Validation and performance evaluation of the automated system in relevant test environments.
2. Related Work
2.1. Positioning Systems
2.2. Technologies for Corrosion Identification
2.3. Camera and LiDAR Calibration
2.4. LiDAR-Based Localization and Mapping
2.4.1. LiDAR-Based SLAM Approaches
2.4.2. LiDAR-Based Localization Approaches
2.5. Image-Based Semantic Segmentation
Semantic–Geometric Segmentation in the Context of Corrosion Detection
3. Methodologies
3.1. Problem Formulation
- Perception and data collection system design: To support corrosion inspections at various environments, without the need for any external permanent fixtures, a portable platform for hosting sensors and computational resources is required. The platform should be lightweight, portable, and allow the recording of RGB and point cloud data streams in outdoor environments for prolonged periods of time. We envision a handheld sensor apparatus containing a camera and LiDAR and a backpack computer and power system. The handheld nature of the sensor apparatus should support capturing data in complex environments.
- Sensor calibration: With the purpose of projecting image-based data accurately to the LiDAR point cloud, we need to find the pose of the camera system, relative to the LiDAR, i.e., the extrinsic camera matrix parameters, encoding a transformation between the camera and the LiDAR. This way, one can accurately map RGB and semantic information to LiDAR point clouds in order to build detailed colored point clouds, representing the surrounding environment.
- 3D localization and mapping: The addition of automatic localization allows accurately solving where a given image has been taken from. Offshore assets can be geometrically complex and multiple stories tall, and images are also likely to be captured from varied poses. As such, the localization system must be able to operate in 3D, i.e., a detailed map of the environment is required for localization, and must be generated using a LiDAR and a camera system.
- Corrosion detection: The large amount of images collected from an inspection may contain numerous small spots of corrosion that can be missed during review, and some images may feature corrosion runoff or other visual blemishes that are not relevant on their own. Corrosion is also quite varied, depending on the environment and type of metal. A well-defined semantic segmentation system is needed for this task as to alleviate the time spent by expert reviewers.
3.2. Physical Setup of the Portable Corrosion Identification System
3.3. LiDAR–Camera Geometry
3.3.1. Intrinsic Camera Parameters
3.3.2. Extrinsic Camera Parameters
3.4. Camera and LiDAR Calibration
3.4.1. Camera Intrinsic Calibration

3.4.2. LiDAR–Camera Extrinsic Calibration
Reference Point Estimation
Registration Procedure
3.5. Image-Based Corrosion Identification
3.6. LiDAR-Based Localization and Mapping
3.6.1. Graph-Based LiDAR SLAM
3.6.2. Real-Time LiDAR-Based Localization
3.7. Semantic–Geometric Mapping
4. Experimental Validation and Performance Evaluation
4.1. Hardware Design and Sensor Selection
4.2. Indoor Laboratory Experimentation
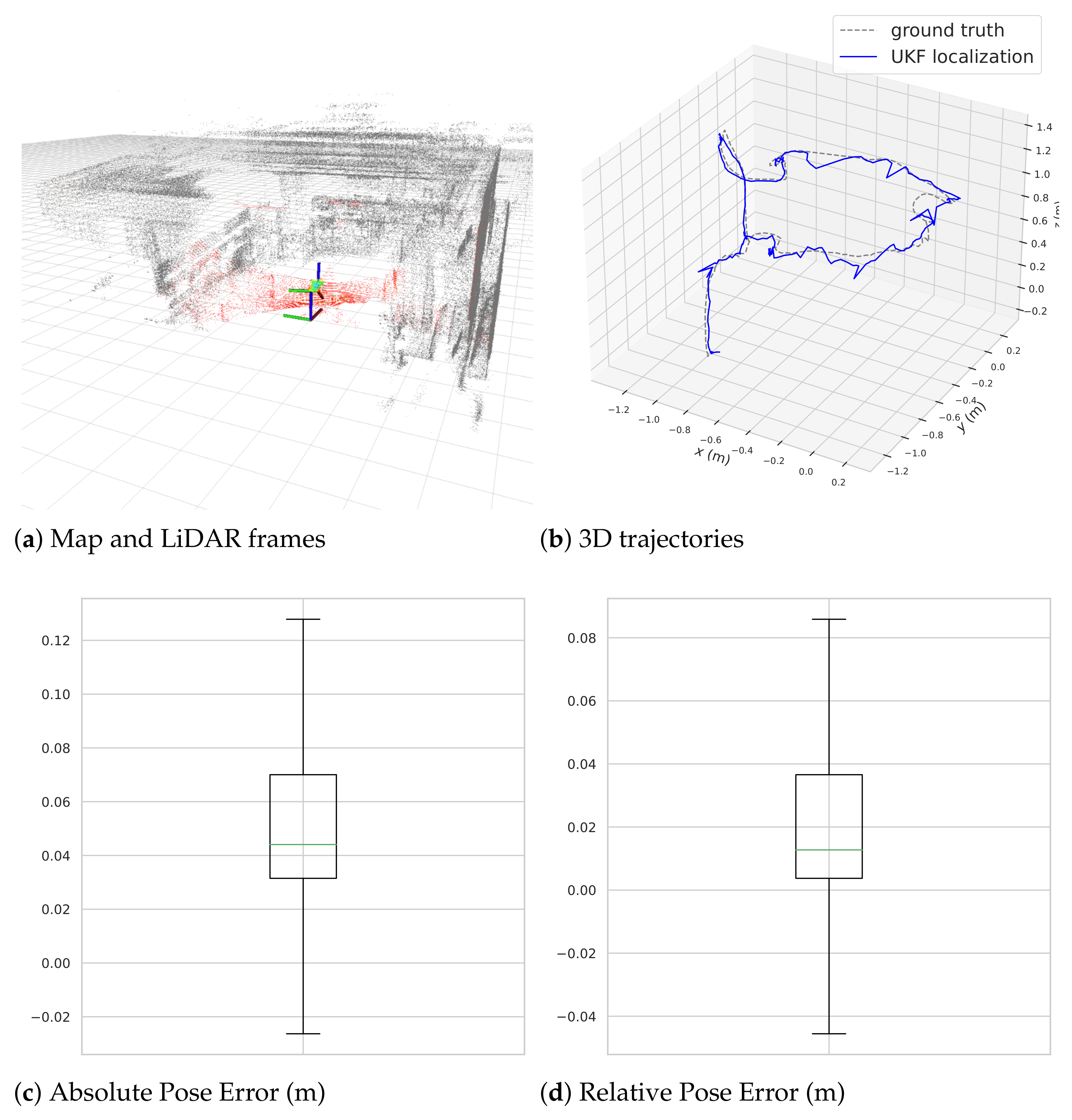
4.2.1. Localization and Mapping Performance
4.3. Semantic Segmentation in Outdoor Offshore Conditions
4.3.1. Evaluation Metrics
4.3.2. Quantitative and Qualitative Analysis
4.4. Operational Validation in an Industrial Manufacturing Scenario
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Koch, G.H.; Brongers, M.P.H.; Thompson, N.G.; Virmani, Y.P.; Payer, J.H.; CC Technologies, Inc. NACE International. Corrosion Cost and Preventive Strategies in the United States [Final Report]; Technical Report FHWA-RD-01-156, R315-01. Federal Highway Administration: Washington, DC, USA, 2002. [Google Scholar]
- Koch, G. 1—Cost of Corrosion. In Trends in Oil and Gas Corrosion Research and Technologies; El-Sherik, A.M., Ed.; Woodhead Publishing Series in Energy; Woodhead Publishing: Boston, MA, USA, 2017; pp. 3–30. [Google Scholar] [CrossRef]
- Revie, R.W. Corrosion and Corrosion Control: An Introduction to Corrosion Science and Engineering, 4th ed.; John Wiley & Sons: Hoboken, NJ, USA, 2008. [Google Scholar] [CrossRef]
- Liu, Y.; Hajj, M.; Bao, Y. Review of Robot-Based Damage Assessment for Offshore Wind Turbines. Renew. Sustain. Energy Rev. 2022, 158, 112187. [Google Scholar] [CrossRef]
- Schjørring, A.; Cretu-Sircu, A.L.; Rodriguez, I.; Cederholm, P.; Berardinelli, G.; Mogensen, P. Performance Evaluation of a UWB Positioning System Applied to Static and Mobile Use Cases in Industrial Scenarios. Electronics 2022, 11, 3294. [Google Scholar] [CrossRef]
- Crețu-Sîrcu, A.L.; Schiøler, H.; Cederholm, J.P.; Sîrcu, I.; Schjørring, A.; Larrad, I.R.; Berardinelli, G.; Madsen, O. Evaluation and Comparison of Ultrasonic and UWB Technology for Indoor Localization in an Industrial Environment. Sensors 2022, 22, 2927. [Google Scholar] [CrossRef]
- Nastac, D.I.; Lehan, E.S.; Iftimie, F.A.; Arsene, O.; Cramariuc, B. Automatic Data Acquisition with Robots for Indoor Fingerprinting. In Proceedings of the 2018 International Conference on Communications (COMM), Bucharest, Romania, 14–16 June 2018; pp. 321–326. [Google Scholar] [CrossRef]
- Fatihah, S.N.; Dewa, G.R.R.; Park, C.; Sohn, I. Self-Optimizing Bluetooth Low Energy Networks for Industrial IoT Applications. IEEE Commun. Lett. 2023, 27, 386–390. [Google Scholar] [CrossRef]
- Wang, F.; Yu, Y.; Yang, D.; Wang, L.; Xing, J. First Potential Demonstrations and Assessments of Monitoring Offshore Oil Rigs States Using GNSS Technologies. IEEE Trans. Instrum. Meas. 2022, 71, 1–15. [Google Scholar] [CrossRef]
- Specht, C.; Pawelski, J.; Smolarek, L.; Specht, M.; Dabrowski, P. Assessment of the Positioning Accuracy of DGPS and EGNOS Systems in the Bay of Gdansk using Maritime Dynamic Measurements. J. Navig. 2019, 72, 575–587. [Google Scholar] [CrossRef]
- Angelats, E.; Espín-López, P.F.; Navarro, J.A.; Parés, M.E. Performance Analysis of The IOPES Seamless Indoor–Outdoor Positioning Approach. Int. Arch. Photogramm. Remote. Sens. Spat. Inf. Sci. 2021, XLIII-B4-2021, 229–235. [Google Scholar] [CrossRef]
- Liu, L.; Tan, E.; Cai, Z.Q.; Zhen, Y.; Yin, X.J. An Integrated Coating Inspection System for Marine and Offshore Corrosion Management. In Proceedings of the 2018 15th International Conference on Control, Automation, Robotics and Vision (ICARCV), Singapore, 18–21 November 2018; pp. 1531–1536. [Google Scholar] [CrossRef]
- Ricardo Luhm Silva, O.C.J.; Rudek, M. A road map for planning-deploying machine vision artifacts in the context of industry 4.0. J. Ind. Prod. Eng. 2022, 39, 167–180. [Google Scholar] [CrossRef]
- Choi, J.; Son, M.G.; Lee, Y.Y.; Lee, K.H.; Park, J.P.; Yeo, C.H.; Park, J.; Choi, S.; Kim, W.D.; Kang, T.W.; et al. Position-based augmented reality platform for aiding construction and inspection of offshore plants. Vis. Comput. 2020, 36, 2039–2049. [Google Scholar] [CrossRef]
- Irmisch, P.; Baumbach, D.; Ernst, I. Robust Visual-Inertial Odometry in Dynamic Environments Using Semantic Segmentation for Feature Selection. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, V-2-2020, 435–442. [Google Scholar] [CrossRef]
- Wen, F.; Pray, J.; McSweeney, K.; Hai, G. Emerging Inspection Technologies-Enabling Remote Surveys/Inspections. In Proceedings of the OTC Offshore Technology Conference, Huston, TX, USA, 6–9 May 2019. [Google Scholar] [CrossRef]
- Roberge, P.R. Corrosion Inspection and Monitoring, 1st ed.; Wiley Series in Corrosion; John Wiley & Sons: Hoboken, NJ, USA, 2007. [Google Scholar]
- Kapoor, K.; Krishna, K.S.; Bakshu, S.A. On Parameters Affecting the Sensitivity of Ultrasonic Testing of Tubes: Experimental and Simulation. J. Nondestruct. Eval. 2016, 35, 56. [Google Scholar] [CrossRef]
- Sophian, A.; Tian, G.; Fan, M. Pulsed Eddy Current Non-destructive Testing and Evaluation: A Review. Chin. J. Mech. Eng. 2017, 30, 500–514. [Google Scholar] [CrossRef]
- Bortak, T.N. Guide to Protective Coatings Inspection and Maintenance; US Department of the Interior, Bureau of Reclamation: Washington, DC, USA, 2002; p. 118. [Google Scholar]
- Kelly, R.G.; Scully, J.R.; Shoesmith, D.; Buchheit, R.G. Electrochemical Techniques in Corrosion Science and Engineering; CRC Press: Boca Raton, FL, USA, 2002. [Google Scholar] [CrossRef]
- Doshvarpassand, S.; Wu, C.; Wang, X. An overview of corrosion defect characterization using active infrared thermography. Infrared Phys. Technol. 2019, 96, 366–389. [Google Scholar] [CrossRef]
- Choi, K.Y.; Kim, S. Morphological analysis and classification of types of surface corrosion damage by digital image processing. Corros. Sci. 2005, 47, 1–15. [Google Scholar] [CrossRef]
- Lovejoy, D. Magnetic Particle Inspection: A Practical Guide, 1st ed.; Springer Netherlands: Dordrecht, The Netherlands, 1993. [Google Scholar] [CrossRef]
- Zaki, A.; Chai, H.K.; Aggelis, D.G.; Alver, N. Non-Destructive Evaluation for Corrosion Monitoring in Concrete: A Review and Capability of Acoustic Emission Technique. Sensors 2015, 15, 19069. [Google Scholar] [CrossRef]
- Aharinejad, S.H.; Lametschwandtner, A. Microvascular Corrosion Casting in Scanning Electron Microscopy: Techniques and Applications; Springer Science & Business Media: Vienna, Austria, 1992. [Google Scholar] [CrossRef]
- Debeunne, C.; Vivet, D. A review of visual-LiDAR fusion based simultaneous localization and mapping. Sensors 2020, 20, 2068. [Google Scholar] [CrossRef]
- Zhang, Z. A flexible new technique for camera calibration. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1330–1334. [Google Scholar] [CrossRef]
- Rehder, J.; Nikolic, J.; Schneider, T.; Hinzmann, T.; Siegwart, R. Extending kalibr: Calibrating the extrinsics of multiple IMUs and of individual axes. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 4304–4311. [Google Scholar] [CrossRef]
- Mirzaei, F.M.; Kottas, D.G.; Roumeliotis, S.I. 3D LIDAR–Camera Intrinsic and Extrinsic Calibration: Identifiability and Analytical Least-Squares-Based Initialization. Int. J. Robot. Res. 2012, 31, 452–467. [Google Scholar] [CrossRef]
- Arshad, S.; Kim, G.W. Role of deep learning in loop closure detection for visual and lidar slam: A survey. Sensors 2021, 21, 1243. [Google Scholar] [CrossRef]
- Koide, K.; Miura, J.; Menegatti, E. A portable three-dimensional LIDAR-based system for long-term and wide-area people behavior measurement. Int. J. Adv. Robot. Syst. 2019, 16, 1729881419841532. [Google Scholar] [CrossRef]
- Thrun, S.; Montemerlo, M. The Graph SLAM Algorithm with Applications to Large-Scale Mapping of Urban Structures—Sebastian Thrun, Michael Montemerlo, 2006. Int. J. Robot. Res. 2006, 25, 403–429. [Google Scholar] [CrossRef]
- Xu, W.; Zhang, F. FAST-LIO: A Fast, Robust LiDAR-Inertial Odometry Package by Tightly-Coupled Iterated Kalman Filter. IEEE Robot. Autom. Lett. 2021, 6, 3317–3324. [Google Scholar] [CrossRef]
- Urrea, C.; Agramonte, R. Kalman filter: Historical overview and review of its use in robotics 60 years after its creation. J. Sens. 2021, 2021, 9674015. [Google Scholar] [CrossRef]
- Xu, W.; Cai, Y.; He, D.; Lin, J.; Zhang, F. FAST-LIO2: Fast Direct LiDAR-Inertial Odometry. IEEE Trans. Robot. 2022, 38, 2053–2073. [Google Scholar] [CrossRef]
- Akai, N.; Hirayama, T.; Murase, H. 3D Monte Carlo Localization with Efficient Distance Field Representation for Automated Driving in Dynamic Environments. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October 2020–13 November 2020; pp. 1859–1866. [Google Scholar] [CrossRef]
- Perez-Grau, F.J.; Caballero, F.; Viguria, A.; Ollero, A. Multi-sensor three-dimensional Monte Carlo localization for long-term aerial robot navigation. Int. J. Adv. Robot. Syst. 2017, 14, 1729881417732757. [Google Scholar] [CrossRef]
- Vizzo, I.; Guadagnino, T.; Mersch, B.; Wiesmann, L.; Behley, J.; Stachniss, C. KISS-ICP: In Defense of Point-to-Point ICP – Simple, Accurate, and Robust Registration If Done the Right Way. IEEE Robot. Autom. Lett. (RA-L) 2023, 8, 1029–1036. [Google Scholar] [CrossRef]
- Akai, N. Efficient Solution to 3D-LiDAR-based Monte Carlo Localization with Fusion of Measurement Model Optimization via Importance Sampling. arXiv 2023, arXiv:2303.00216. [Google Scholar] [CrossRef]
- de Figueiredo, R.P.; Bøgh, S. Vision-Based Corrosion Identification Using Data-Driven Semantic Segmentation Techniques. In Proceedings of the 2023 IEEE International Conference on Imaging Systems and Techniques (IST), Copenhagen, Denmark, 17–19 October 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Seo, H.; Badiei Khuzani, M.; Vasudevan, V.; Huang, C.; Ren, H.; Xiao, R.; Jia, X.; Xing, L. Machine learning techniques for biomedical image segmentation: An overview of technical aspects and introduction to state-of-art applications. Med. Phys. 2020, 47, e148–e167. [Google Scholar] [CrossRef]
- Tøttrup, D.; Skovgaard, S.L.; Sejersen, J.l.F.; Pimentel de Figueiredo, R. A Real-Time Method for Time-to-Collision Estimation from Aerial Images. J. Imaging 2022, 8, 62. [Google Scholar] [CrossRef]
- le Fevre Sejersen, J.; Pimentel De Figueiredo, R.; Kayacan, E. Safe Vessel Navigation Visually Aided by Autonomous Unmanned Aerial Vehicles in Congested Harbors and Waterways. In Proceedings of the 2021 IEEE 17th International Conference on Automation Science and Engineering (CASE), Lyon, France, 23–27 August 2021; pp. 1901–1907. [Google Scholar] [CrossRef]
- De Figueiredo, R.P.; le Fevre Sejersen, J.; Hansen, J.G.; Brandão, M.; Kayacan, E. Real-Time Volumetric-Semantic Exploration and Mapping: An Uncertainty-Aware Approach. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 9064–9070. [Google Scholar] [CrossRef]
- Pimentel de Figueiredo, R.; le Fevre Sejersen, J.; Hansen, J.; Brandão, M. Integrated design-sense-plan architecture for autonomous geometric-semantic mapping with UAVs. Front. Robot. AI 2023, 9, 911974. [Google Scholar] [CrossRef]
- Gruosso, M.; Capece, N.; Erra, U. Human Segmentation in Surveillance Video with Deep Learning. Multimed. Tools Appl. 2021, 80, 1175–1199. [Google Scholar] [CrossRef]
- Tao, H.; Zheng, Y.; Wang, Y.; Qiu, J.; Vladimir, S. Enhanced Feature Extraction YOLO Industrial Small Object Detection Algorithm based on Receptive-Field Attention and Multi-scale Features. Meas. Sci. Technol. 2024, 35, 105023. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the 13th European Conference, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar] [CrossRef]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar] [CrossRef]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.; et al. Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 6877–6886. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the 18th International Conference, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar] [CrossRef]
- Furgale, P.; Rehder, J.; Siegwart, R. Unified temporal and spatial calibration for multi-sensor systems. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013; pp. 1280–1286. [Google Scholar] [CrossRef]
- Nocedal, J.; Wright, S.J. Numerical Optimization, 2nd ed.; Springer Series in Operations Research and Financial Engineering; Springer: New York, NY, USA, 2006. [Google Scholar] [CrossRef]
- Beltran, J.; Guindel, C.; Escalera, A.D.L.; Garcia, F. Automatic Extrinsic Calibration Method for LiDAR and Camera Sensor Setups. IEEE Trans. Intell. Transp. Syst. 2022, 23, 17677–17689. [Google Scholar] [CrossRef]
- Garrido-Jurado, S.; Muñoz-Salinas, R.; Madrid-Cuevas, F.J.; Marín-Jiménez, M.J. Automatic generation and detection of highly reliable fiducial markers under occlusion. Pattern Recognit. 2014, 47, 2280–2292. [Google Scholar] [CrossRef]
- Levinson, J.; Thrun, S. Automatic Online Calibration of Cameras and Lasers. In Proceedings of the Robotics: Science and Systems, Berlin, Germany, 24–28 June 2013. [Google Scholar] [CrossRef]
- Kanopoulos, N.; Vasanthavada, N.; Baker, R. Design of an Image Edge Detection Filter Using the Sobel Operator. IEEE J. -Solid-State Circuits 1988, 23, 358–367. [Google Scholar] [CrossRef]
- Isa, S.M.; Shukor, S.A.; Rahim, N.; Maarof, I.; Yahya, Z.; Zakaria, A.; Abdullah, A.; Wong, R. Point cloud data segmentation using ransac and localization. Proc. IOP Conf. Ser. Mater. Sci. Eng. 2019, 705, 012004. [Google Scholar] [CrossRef]
- Nguyen, A.; Le, B. 3D point cloud segmentation: A survey. In Proceedings of the 2013 6th IEEE conference on robotics, automation and mechatronics (RAM), Manila, Philippines, 12–15 November 2013; pp. 225–230. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar] [CrossRef]
- Wan, E.A.; Van Der Merwe, R. The unscented Kalman filter. In Kalman Filtering and Neural Networks; Wiley: Hoboken, NJ, USA, 2001; pp. 221–280. [Google Scholar] [CrossRef]
- Magnusson, M.; Lilienthal, A.; Duckett, T. Scan registration for autonomous mining vehicles using 3D-NDT. J. Field Robot. 2007, 24, 803–827. [Google Scholar] [CrossRef]
- Kümmerle, R.; Grisetti, G.; Strasdat, H.; Konolige, K.; Burgard, W. G2o: A general framework for graph optimization. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 3607–3613. [Google Scholar] [CrossRef]
- Besl, P.; McKay, N.D. A method for registration of 3-D shapes. IEEE Trans. Pattern Anal. Mach. Intell. 1992, 14, 239–256. [Google Scholar] [CrossRef]
- Furtado, J.S.; Liu, H.H.; Lai, G.; Lacheray, H.; Desouza-Coelho, J. Comparative analysis of optitrack motion capture systems. In Proceedings of the Advances in Motion Sensing and Control for Robotic Applications: Selected Papers from the Symposium on Mechatronics, Robotics, and Control (SMRC’18)—CSME International Congress 2018, Toronto, CA, USA, 27–30 May 2018; pp. 15–31. [Google Scholar] [CrossRef]
- Kabsch, W. A solution for the best rotation to relate two sets of vectors. Acta Crystallogr. Sect. A Cryst. Phys. Diffr. Theor. Gen. Crystallogr. 1976, 32, 922–923. [Google Scholar] [CrossRef]
- Bedkowski, J.M.; Röhling, T. Online 3D LIDAR Monte Carlo localization with GPU acceleration. Ind. Robot. Int. J. 2017, 44, 442–456. [Google Scholar] [CrossRef]
- Segments.ai. 2D & 3D Data Labeling. 2022. Available online: https://segments.ai/ (accessed on 30 November 2022).
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Koonce, B.; Koonce, B. ResNet 34. In Convolutional Neural Networks with Swift for Tensorflow: Image Recognition and Dataset Categorization; Apress: Berkeley, CA, USA, 2021; pp. 51–61. [Google Scholar] [CrossRef]
- Bianchi, E.; Hebdon, M. Development of Extendable Open-Source Structural Inspection Datasets. J. Comput. Civ. Eng. 2022, 36, 04022039. [Google Scholar] [CrossRef]
- Rosas-Cervantes, V.; Lee, S.G. 3D localization of a mobile robot by using Monte Carlo algorithm and 2D features of 3D point cloud. Int. J. Control. Autom. Syst. 2020, 18, 2955–2965. [Google Scholar] [CrossRef]
- Grinvald, M.; Furrer, F.; Novkovic, T.; Chung, J.J.; Cadena, C.; Siegwart, R.; Nieto, J. Volumetric Instance-Aware Semantic Mapping and 3D Object Discovery. IEEE Robot. Autom. Lett. 2019, 4, 3037–3044. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Total Images in Dataset | |
|---|---|
| training | 8559 (80%) |
| validation | 2853 (10%) |
| testing | 2853 (10%) |
| Model | IoU Score | Precision | Recall | F-Score | Avg. Inference Time |
|---|---|---|---|---|---|
| UNET-resnet34 585256922 | 0.5852 | 0.7368 | 0.7065 | 0.6922 | 0.0445 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pimentel de Figueiredo, R.; Eriksen, S.N.; Rodriguez, I.; Bøgh, S. A Complete System for Automated Semantic–Geometric Mapping of Corrosion in Industrial Environments. Automation 2025, 6, 23. https://doi.org/10.3390/automation6020023
Pimentel de Figueiredo R, Eriksen SN, Rodriguez I, Bøgh S. A Complete System for Automated Semantic–Geometric Mapping of Corrosion in Industrial Environments. Automation. 2025; 6(2):23. https://doi.org/10.3390/automation6020023
Chicago/Turabian StylePimentel de Figueiredo, Rui, Stefan Nordborg Eriksen, Ignacio Rodriguez, and Simon Bøgh. 2025. "A Complete System for Automated Semantic–Geometric Mapping of Corrosion in Industrial Environments" Automation 6, no. 2: 23. https://doi.org/10.3390/automation6020023
APA StylePimentel de Figueiredo, R., Eriksen, S. N., Rodriguez, I., & Bøgh, S. (2025). A Complete System for Automated Semantic–Geometric Mapping of Corrosion in Industrial Environments. Automation, 6(2), 23. https://doi.org/10.3390/automation6020023