
A Large-Scale COVID-19 Twitter Chatter Dataset for Open Scientific Research—An International Collaboration

 ,
,  , , and
, , and 
Abstract
:1. Introduction
2. Materials and Methods
Data Availability and Usage Description
3. Results and Discussion
3.1. A Google–Wikipedia–Twitter Model as a Leading Indicator of the Numbers of Coronavirus Deaths
3.2. Analysis of Twitter Data Using Evolutionary Clustering during the COVID-19 Pandemic
3.3. Understanding the Public Discussion about the Centers for Disease Control and Prevention during the COVID-19 Pandemic Using Twitter Data: Text Mining Analysis Study
3.4. Public Risk Perception and Emotion on Twitter during the COVID-19 Pandemic
3.5. COVID-19 Twitter Monitor: Aggregating and Visualizing COVID-19-Related Trends in Social Media
3.6. Using Tweets to Understand How COVID-19-Related Health Beliefs Are Affected in the Age of Social Media: Twitter Data Analysis Study
3.7. Changes of Diurnal Rhythms of Social Media Activities during the COVID-19 Pandemic
3.8. Characterizing Public Emotions and Sentiments in COVID-19 Environment: A Case Study of India
3.9. Characterizing Drug Mentions in COVID-19 Twitter Chatter
3.10. Large-Scale, Language-Agnostic Discourse Classification of Tweets during COVID-19
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- World Health Organization WHO Characterizes COVID-19 as a Pandemic. Available online: https://www.who.int/emergencies/diseases/novel-coronavirus-2019/events-as-they-happen (accessed on 27 March 2020).
- Coronavirus Update (Live): 737,575 Cases and 34,998 Deaths from COVID-19 Virus Outbreak-Worldometer. Available online: https://www.worldometers.info/coronavirus/ (accessed on 30 March 2020).
- Bruns, A.; Liang, Y.E. Tools and Methods for Capturing Twitter Data during Natural Disasters. First Monday 2012, 17, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Zou, L.; Lam, N.S.N.; Cai, H.; Qiang, Y. Mining Twitter Data for Improved Understanding of Disaster Resilience. Ann. Assoc. Am. Geogr. 2018, 108, 1422–1441. [Google Scholar] [CrossRef]
- Earle, P. Earthquake Twitter. Nat. Geosci. 2010, 3, 221–222. [Google Scholar] [CrossRef]
- Gao, J.; Tian, Z.; Yang, X. Breakthrough: Chloroquine Phosphate Has Shown Apparent Efficacy in Treatment of COVID-19 Associated Pneumonia in Clinical Studies. Biosci. Trends 2020, 14, 72–73. [Google Scholar] [CrossRef] [Green Version]
- Xu, Z.; Shi, L.; Wang, Y.; Zhang, J.; Huang, L.; Zhang, C.; Liu, S.; Zhao, P.; Liu, H.; Zhu, L.; et al. Pathological Findings of COVID-19 Associated with Acute Respiratory Distress Syndrome. Lancet Respir. Med. 2020, 8, 420–422. [Google Scholar] [CrossRef]
- Zhou, F.; Yu, T.; Du, R.; Fan, G.; Liu, Y.; Liu, Z.; Xiang, J.; Wang, Y.; Song, B.; Gu, X.; et al. Clinical Course and Risk Factors for Mortality of Adult Inpatients with COVID-19 in Wuhan, China: A Retrospective Cohort Study. Lancet 2020, 395, 1054–1062. [Google Scholar] [CrossRef]
- Tekumalla, R.; Banda, J.M. Characterizing drug mentions in COVID-19 Twitter Chatter. In Proceedings of the 1st Workshop on NLP for COVID-19 (Part 2) at EMNLP 2020, London, UK, 20 November 2020. [Google Scholar]
- Warren, E. Strengthening Research through Data Sharing. N. Engl. J. Med. 2016, 375, 401–403. [Google Scholar] [CrossRef]
- Saez-Rodriguez, J.; Costello, J.C.; Friend, S.H.; Kellen, M.R.; Mangravite, L.; Meyer, P.; Norman, T.; Stolovitzky, G. Crowdsourcing Biomedical Research: Leveraging Communities as Innovation Engines. Nat. Rev. Genet. 2016, 17, 470–486. [Google Scholar] [CrossRef] [PubMed]
- Emmert-Streib, F.; Dehmer, M.; Yli-Harja, O. Against Dataism and for Data Sharing of Big Biomedical and Clinical Data with Research Parasites. Front. Genet. 2016, 7, 154. [Google Scholar] [CrossRef] [Green Version]
- Greene, C.S.; Garmire, L.X.; Gilbert, J.A.; Ritchie, M.D.; Hunter, L.E. Celebrating Parasites. Nat. Genet. 2017, 49, 483–484. [Google Scholar] [CrossRef] [Green Version]
- Banda, J.M.; Tekumalla, R. A Twitter Dataset of 40+ Million Tweets Related to COVID-19. Available online: https://doi.org/10.5281/zenodo.3723940 (accessed on 21 July 2021).
- Banda, J.M.; Tekumalla, R. Covid-19 Twitter Dataset and Pre-Processing Scripts. Available online: https://github.com/thepanacealab/covid19_twitter (accessed on 27 March 2021).
- Banda, J.M.; Tekumalla, R.; Wang, G.; Yu, J.; Liu, T.; Ding, Y.; Artemova, K.; Tutubalina, E.; Chowell, G. A Large-Scale COVID-19 Twitter Chatter Dataset for Open Scientific Research-an International Collaboration. arXiv 2020, arXiv:2004.03688. [Google Scholar]
- Wilkinson, M.D.; Dumontier, M.; Aalbersberg, I.J.J.; Appleton, G.; Axton, M.; Baak, A.; Blomberg, N.; Boiten, J.-W.; da Silva Santos, L.B.; Bourne, P.E.; et al. The FAIR Guiding Principles for Scientific Data Management and Stewardship. Sci. Data 2016, 3, 160018. [Google Scholar] [CrossRef] [Green Version]
- Banda, J.M.; Tekumalla, R.; Wang, G.; Yu, J.; Liu, T.; Ding, Y.; Artemova, K.; Tutubalina, E.; Chowell, G. A Twitter Dataset of 383+ Million Tweets Related to COVID-19. Available online: https://doi.org/10.5281/zenodo.3884334 (accessed on 21 July 2021).
- Tekumalla, R.; Banda, J.M. Social Media Mining Toolkit (SMMT). Genom. Inform. 2020, 18, e16. [Google Scholar] [CrossRef]
- Twarc [Computer Software]. Available online: https://github.com/DocNow/twarc (accessed on 21 July 2021).
- Banda, J.M.; Tekumalla, R.; Chowell, G. A Twitter Dataset of 70+ Million Tweets Related to COVID-19 2020. Available online: https://doi.org/10.5281/zenodo.3732460 (accessed on 21 July 2021).
- Tweepy [Computer Software]. Available online: https://www.tweepy.org/ (accessed on 21 July 2021).
- Tekumalla, R.; Asl, J.R.; Banda, J.M. Mining Archive. Org’s Twitter Stream Grab for Pharmacovigilance Research Gold. In Proceedings of the International AAAI Conference on Web and Social Media, Atlanta, GA, USA, 8–11 June 2020; Volume 14, pp. 909–917. [Google Scholar]
- spaCy-Industrial-Strength Natural Language Processing in Python [Computer Software]. Available online: https://spacy.io/ (accessed on 21 July 2021).
- Sullivan, K.J.; Burden, M.; Keniston, A.; Banda, J.M.; Hunter, L.E. Characterization of Anonymous Physician Perspectives on COVID-19 Using Social Media Data. Pac. Symp. Biocomput. 2021, 26, 95–106. [Google Scholar] [CrossRef]
- Tariq, A.; Banda, J.M.; Skums, P.; Dahal, S.; Castillo-Garsow, C.; Espinoza, B.; Brizuela, N.G.; Saenz, R.A.; Kirpich, A.; Luo, R.; et al. Transmission Dynamics and Forecasts of the COVID-19 Pandemic in Mexico, March 20–November 11, 2020. medRxiv 2021. [Google Scholar] [CrossRef]
- O’Leary, D.E.; Storey, V.C. A Google–Wikipedia–twitter Model as a Leading Indicator of the Numbers of Coronavirus Deaths. Intell. Syst. Account. Finance Manag. 2020, 27, 151–158. [Google Scholar] [CrossRef]
- Arpaci, I.; Alshehabi, S.; Al-Emran, M.; Khasawneh, M.; Mahariq, I.; Abdeljawad, T.; Hassanien, A.E. Analysis of Twitter Data Using Evolutionary Clustering during the COVID-19 Pandemic. Comput. Mater. Contin. 2020, 65, 193–204. [Google Scholar] [CrossRef]
- Lyu, J.C.; Luli, G.K. Understanding the Public Discussion about the Centers for Disease Control and Prevention during the COVID-19 Pandemic Using Twitter Data: Text Mining Analysis Study. J. Med. Internet Res. 2021, 23, e25108. [Google Scholar] [CrossRef] [PubMed]
- Slovic, P. If I look at the mass I will never act: Psychic numbing and genocide. In Emotions and Risky Technologies; Springer: Berlin/Heidelberg, Germany, 2010; pp. 37–59. [Google Scholar]
- Dyer, J.; Kolic, B. Public Risk Perception and Emotion on Twitter during the Covid-19 Pandemic. Appl. Netw. Sci. 2020, 5, 99. [Google Scholar] [CrossRef] [PubMed]
- Cornelius, J.; Ellendorff, T.; Furrer, L.; Rinaldi, F. COVID-19 Twitter Monitor: Aggregating and Visualizing COVID-19 Related Trends in Social Media. In Proceedings of the Fifth Social Media Mining for Health Applications Workshop & Shared Task (Online), Barcelona, Spain, 12 December 2020; pp. 1–10. [Google Scholar]
- Luo, Y. Using Tweets to Understand How COVID-19—Related Health Beliefs Are Affected in the Age of Social Media: Twitter Data Analysis Study. J. Med. Internet Res. 2021, 23, e26302. [Google Scholar]
- Zhou, L. Changes of Diurnal Rhythms of Social Media Activities During the COVID-19 Pandemic. Int. J. Sci. Basic Appl. Res. 2020, 53, 97–104. [Google Scholar]
- Das, S.; Dutta, A. Characterizing Public Emotions and Sentiments in COVID-19 Environment: A Case Study of India. J. Hum. Behav. Soc. Environ. 2021, 31, 154–167. [Google Scholar] [CrossRef]
- Barkur, G.; Vibha, G.B.K. Sentiment Analysis of Nationwide Lockdown due to COVID 19 Outbreak: Evidence from India. Asian J. Psychiatr. 2020, 51, 102089. [Google Scholar] [CrossRef] [PubMed]
- Gencoglu, O. Large-Scale, Language-Agnostic Discourse Classification of Tweets during COVID-19. Mach. Learn. Knowl. Extr. 2020, 2, 603–616. [Google Scholar] [CrossRef]
- Hussain, A.; Tahir, A.; Hussain, Z.; Sheikh, Z.; Gogate, M.; Dashtipour, K.; Ali, A.; Sheikh, A. Artificial Intelligence-Enabled Analysis of UK and US Public Attitudes on Facebook and Twitter towards COVID-19 Vaccinations. J. Med. Internet Res. 2021. [Google Scholar] [CrossRef] [PubMed]
- Balech, S.; Benavent, C.; Calciu, M.; Monnot, J. The Covid-19 Crisis: An NLP Exploration of the French Twitter Feed (February-May 2020). Int. Conferr. Hum. Comput. Interact. 2021, 308–321. [Google Scholar] [CrossRef]
- Mukherjee, R.; Poddar, S.; Naik, A.; Dasgupta, S. How Have We Reacted To The COVID-19 Pandemic? Analyzing Changing Indian Emotions through the Lens of Twitter. arXiv 2020, arXiv:2008.09035. [Google Scholar]
- Kaur, S.; Kaul, P.; Zadeh, P.M. Study the Impact of COVID-19 on Twitter Users with Respect to Social Isolation. In Proceedings of the 2020 Seventh International Conference on Social Networks Analysis, Management and Security (SNAMS), Paris, France, 14–16 December 2020; pp. 1–6. [Google Scholar]
- Cotfas, L.-A.; Delcea, C.; Roxin, I.; Ioanăş, C.; Gherai, D.S.; Tajariol, F. The Longest Month: Analyzing COVID-19 Vaccination Opinions Dynamics from Tweets in the Month Following the First Vaccine Announcement. IEEE Access 2021, 9, 33203–33223. [Google Scholar] [CrossRef]
- Banda, J.M.; Singh, G.V.; Alser, O.; Prieto-Alhambra, D. Long-Term Patient-Reported Symptoms of COVID-19: An Analysis of Social Media Data. bioRxiv 2020. [Google Scholar] [CrossRef]
- Banda, J.M.; Adderley, N.; Ahmed, W.-U.-R.; AlGhoul, H.; Alser, O.; Alser, M.; Areia, C.; Cogenur, M.; Fišter, K.; Gombar, S.; et al. Characterization of Long-Term Patient-Reported Symptoms of COVID-19: An Analysis of Social Media Data. medRxiv 2021. [Google Scholar] [CrossRef]
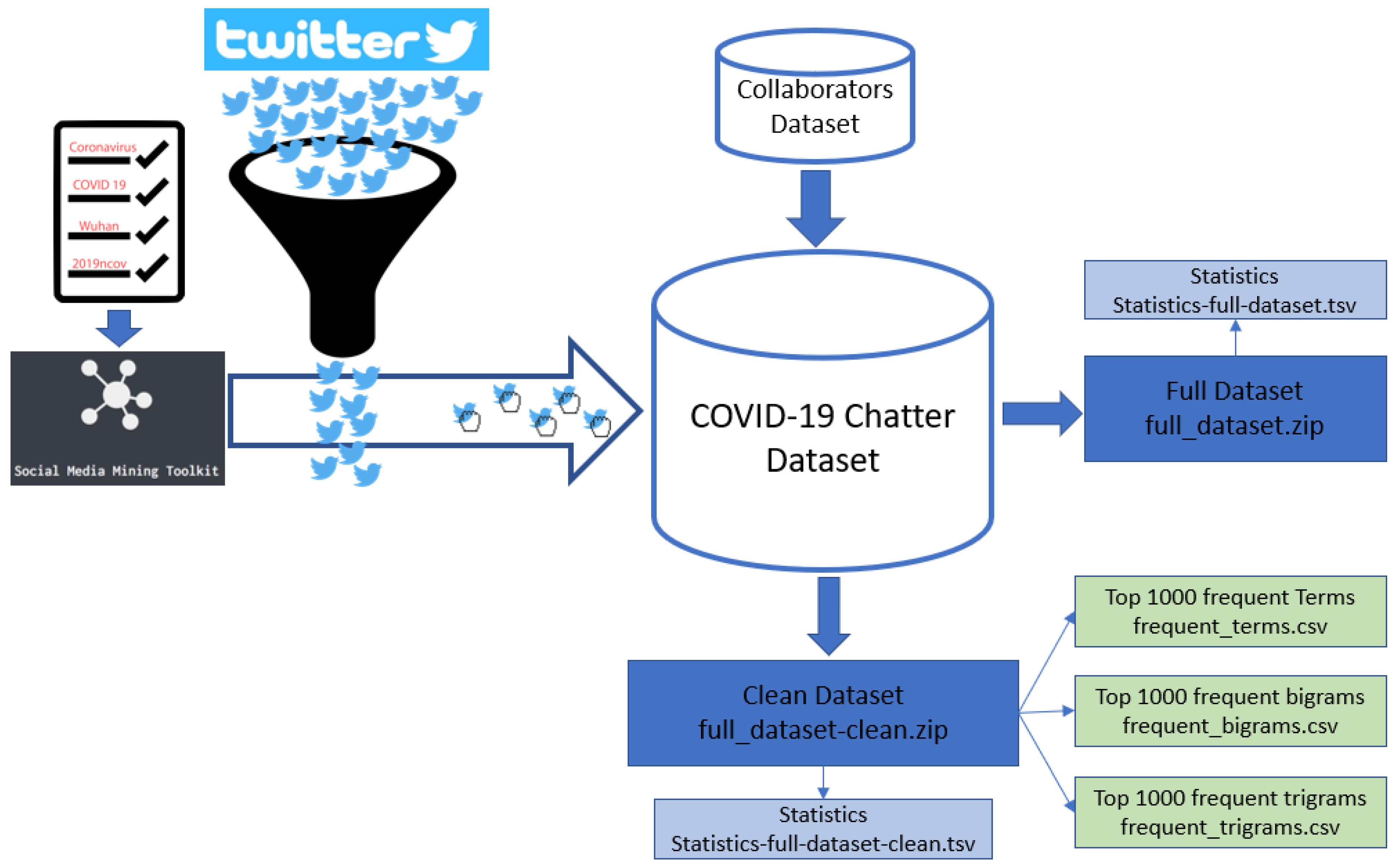

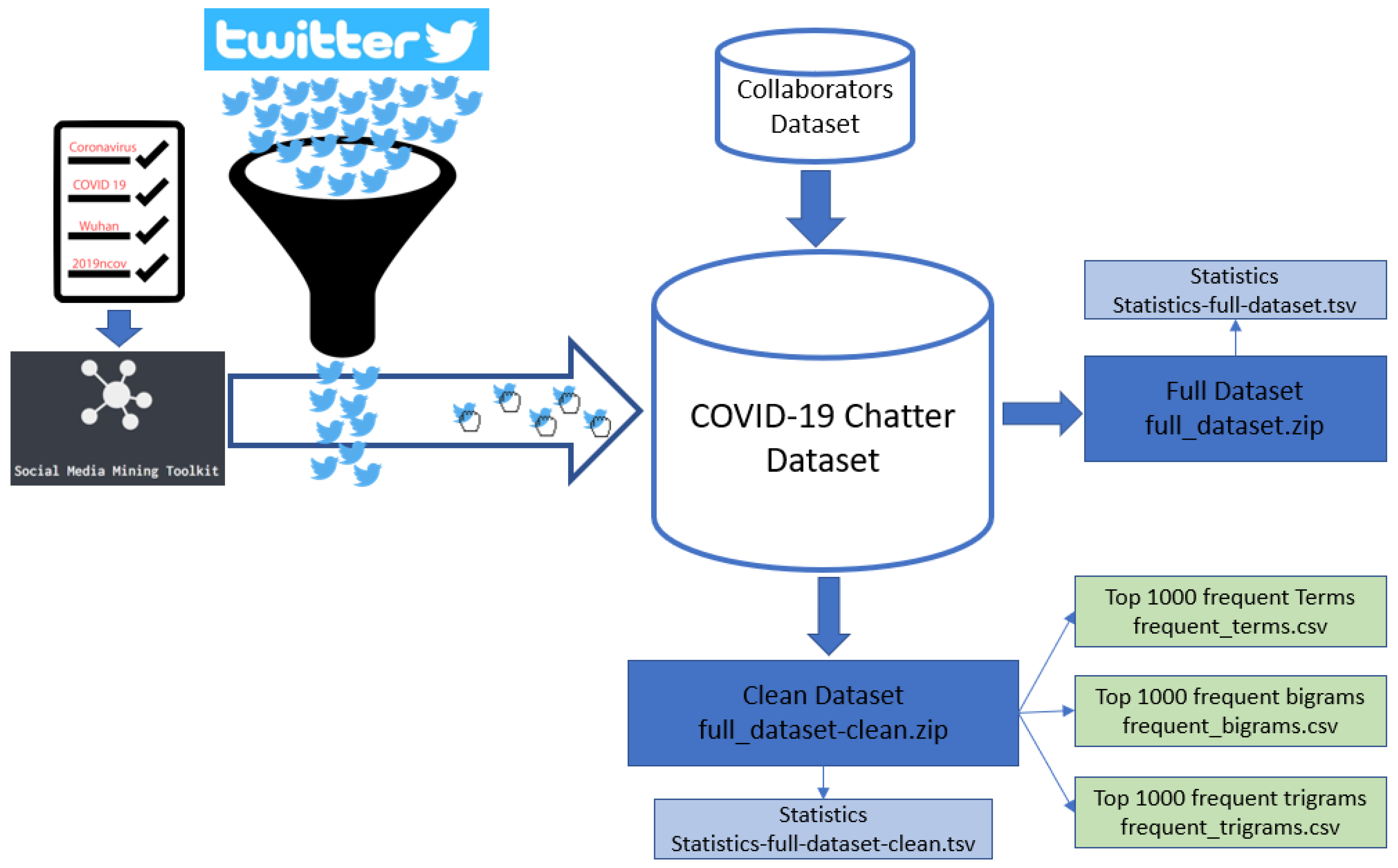{kind=link}
| Full Dataset | Clean Dataset | |||
|---|---|---|---|---|
| Month/Year | 2020 | 2021 | 2020 | 2021 |
| January | 6,737,966 | 52,655,429 | 1,329,483 | 14,379,452 |
| February | 27,666,656 | 32,718,733 | 5,886,751 | 9,479,306 |
| March | 111,006,589 | 38,992,458 | 21,612,183 | 10,685,354 |
| April | 128,048,263 | 46,816,335 | 31,661,550 | 10,864,230 |
| May | 120,186,704 | 39,077,398 | 31,361,965 | 9,298,310 |
| June | 92,566,134 | 22,961,987 | 23,410,940 | 6,326,726 |
| July | 97,185,376 | 23,595,378 | ||
| August | 73,931,454 | 18,614,572 | ||
| September | 61,120,895 | 15,513,125 | ||
| October | 71,836,689 | 18,522,752 | ||
| November | 47,631,306 | 16,155,884 | ||
| December | 51,738,825 | 16,366,051 | ||
| File Name | Description |
|---|---|
| full_dataset.tsv.gz | A zipped, tab separated file which contains all the tweet IDs in the format—Tweet ID TAB Date TAB Time TAB language TAB country_code |
| full_dataset-clean.tsv.gz | A zipped, tab separated file which does not contain any retweet IDs in the format—Tweet ID TAB Date Tab Time |
| statistics-full_dataset-clean.tsv | A tab separated file which contains counts of total tweets each day for the clean dataset in the format—Date TAB Total No of Tweet IDs |
| statistics-full_dataset.tsv | A tab separated file which contains counts of total tweets each day for full dataset in the format—Date TAB Total No of Tweet IDs |
| frequent_terms.csv | A comma separated file which contains the counts of the top 1000 frequent terms in the following format—term, Total count |
| frequent_bigrams.csv | A comma separated file which contains counts of top 1000 bigrams in the format—gram, Total count |
| frequent_trigrams.csv | A comma separated file which contains counts of top 1000 trigrams in the format—gram, Total count |
| emoji.zip | A zipped collection of dated files which contain the top emojis, both in text and unicode character versions, and their frequencies per day for all clean tweets |
| hashtag.zip | A zipped collection of dated files which contain the top hashtags and their frequencies per day for all clean tweets |
| mentions.zip | A zipped collection of dated files which contain the top mentions (@) and their frequencies per day for all clean tweets |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Banda, J.M.; Tekumalla, R.; Wang, G.; Yu, J.; Liu, T.; Ding, Y.; Artemova, E.; Tutubalina, E.; Chowell, G. A Large-Scale COVID-19 Twitter Chatter Dataset for Open Scientific Research—An International Collaboration. Epidemiologia 2021, 2, 315-324. https://doi.org/10.3390/epidemiologia2030024
Banda JM, Tekumalla R, Wang G, Yu J, Liu T, Ding Y, Artemova E, Tutubalina E, Chowell G. A Large-Scale COVID-19 Twitter Chatter Dataset for Open Scientific Research—An International Collaboration. Epidemiologia. 2021; 2(3):315-324. https://doi.org/10.3390/epidemiologia2030024
Chicago/Turabian StyleBanda, Juan M., Ramya Tekumalla, Guanyu Wang, Jingyuan Yu, Tuo Liu, Yuning Ding, Ekaterina Artemova, Elena Tutubalina, and Gerardo Chowell. 2021. "A Large-Scale COVID-19 Twitter Chatter Dataset for Open Scientific Research—An International Collaboration" Epidemiologia 2, no. 3: 315-324. https://doi.org/10.3390/epidemiologia2030024
APA StyleBanda, J. M., Tekumalla, R., Wang, G., Yu, J., Liu, T., Ding, Y., Artemova, E., Tutubalina, E., & Chowell, G. (2021). A Large-Scale COVID-19 Twitter Chatter Dataset for Open Scientific Research—An International Collaboration. Epidemiologia, 2(3), 315-324. https://doi.org/10.3390/epidemiologia2030024