
Quantum-Enhanced Attention Neural Networks for PM2.5 Concentration Prediction

Abstract
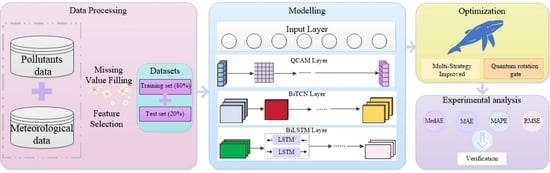
1. Introduction
- To address challenges such as slow convergence, local optima, and premature convergence in the Whale Optimization Algorithm (WOA), this paper presents an enhanced version, the Quantum Multi-strategy Enhanced Whale Optimization Algorithm (QMEWOA), integrated with quantum computing.
- Considering that unidirectional Temporal Convolutional Networks (TCNs) may miss valuable backward feature information, bidirectional Temporal Convolutional Networks (BiTCNs) are employed for more comprehensive feature extraction.
- Drawing inspiration from quantum state mapping to capture higher-order feature information, this paper enhances the Causal Attention Mechanism (CAM) and introduces a Quantum Causal Attention Mechanism (QCAM).
2. Materials and Methods
2.1. Research Area and Data
2.1.1. Data Preprocessing
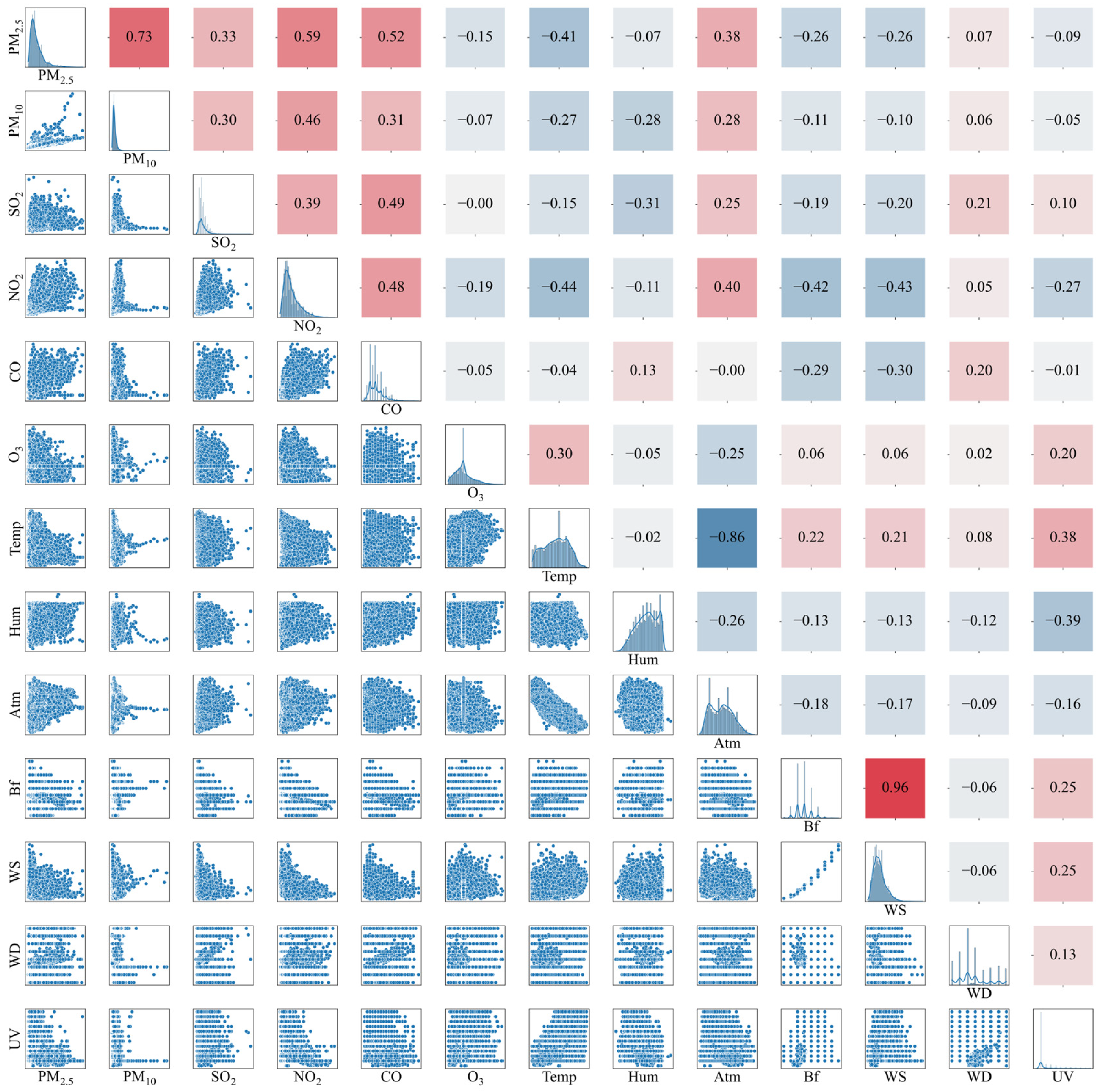
2.1.2. Correlation Analysis
2.2. Feature Selection
2.3. Model Evaluation Metrics
2.4. BiTCN
2.5. BiLSTM
2.6. QMEWOA
2.6.1. Traditional WOA
2.6.2. Multi-Strategy Enhanced WOA Integrated with Quantum Computing
- (1)
- Bernoulli chaotic mapping: Chaotic mapping generates sequences with greater ergodicity and randomness than regular random sequences, fostering a more diverse population [40]. Effective population initialization accelerates convergence and enhances the algorithm’s performance. Common chaotic mappings for population initialization include Tent, Cubic, and Bernoulli chaotic mappings. Of these, Bernoulli chaotic mapping yields a more uniform population distribution, improving diversity to some extent [41]. This paper thus adopts Bernoulli chaotic mapping to enhance population initialization, increase diversity, and improve WOA’s local search capabilities. The equation for Bernoulli chaotic mapping is
- (2)
- Improved nonlinear convergence factor and time-varying weight: In WOA, the convergence factor decreases linearly from 2 to 0, but this linear decay update mechanism restricts the individual search capacity, preventing the full manifestation of WOA’s search mechanism. To better balance the global and local search mechanisms, this paper improves a by proposing a nonlinear decay strategy, with its mathematical expression given in Equation (8).
- (3)
- Dual-strategy improvement in the bubble net hunting phase: In the later iterations of traditional WOA, the whale individuals are more concentrated, which makes the algorithm prone to getting stuck in local optima, resulting in stagnation or premature convergence. The inertia factor in Particle Swarm Optimization (PSO) helps guide a population’s individuals toward optimization. This paper combines the PSO inertia factor with the Levy flight mechanism and mutation differential operator to create dual-strategy improvement in the shrinking encirclement phase. Levy flight, proposed by Mantegna and Topics [42], is a random walk mechanism based on the Levy distribution. It effectively improves the algorithm’s ability to avoid local optima and enhances its global search capability. In this study, the step size for the Levy flight is set to 1000 for the simulation experiments, with the results displayed in Figure 5.
- (4)
- The sparrow follower position update method integrated with quantum particle swarm for solution generation: The position update rule for sparrow followers is that, when their fitness is low, they move to other areas to forage; otherwise, they forage near the optimal individual. The search units converge either by teleporting to the neighborhood of the optimal solution or by moving closer to the origin. However, this method lacks local search capability, making it susceptible to local optima. The Quantum Particle Swarm Optimization (QPSO) algorithm, introduced by Sun, et al. [43], simulates the uncertainty of quantum superposition states. This enables the algorithm to cover the entire search space and enhance global search capability through an adaptive potential field. Therefore, this paper combines QPSO-generated solutions with the follower update method to propose a follower position update strategy that integrates quantum computing. The position update expression after applying this strategy is shown below.
- (5)
- Quantum rotation gate update strategy: The quantum rotation gate is a crucial operation for population updating in Quantum Genetic Algorithms (QGAs), allowing the search algorithm to move closer to the optimal solution [44]. The goal of the quantum rotation gate is to converge the quantum bit probability amplitude of each quantum state gene position in the chromosome of the genetic algorithm to 0 or 1 [45]. In this paper, the quantum rotation gate is used to update the positions of individual whales. The quantum position of the k-th whale is represented by Equation (19), and the quantum rotation gate expression for the i-th whale corresponding to the j-th quantum rotation angle is shown in Equation (20).
2.6.3. QMEWOA Algorithm Steps
| Algorithm 1: QMEWOA |
| Input: Population size pop, dimension dim, lower bound lb, upper bound ub, maximum iteration MaxIter, fitness function fun |
| Output: Best fitness value GbestScore, best solution GbestPosition, convergence curve Curve |
| 1: Initialize whale population X within bounds [lb, ub] 2: Evaluate fitness of each whale using fun() 3: Sort the population X based on fitness 4: Set GbestScore ← best fitness, GbestPosition ← corresponding whale 5: for t ← 1 to MaxIter do 6: Set Leader ← best whale in population 7: Compute parameters: a ← (1.26 * arcsin(1 − t/MaxIter)) ^ exp(2.86 * t/MaxIter) a2 ← −1 + t * (−1/MaxIter) vc ← 2 * exp((1 − t/MaxIter − 1))^6 * rand() − exp((1 − t/MaxIter − 1))^6 Update inertia weight w based on vc and current iteration t 8: for i ← 1 to pop do 9: for j ← 1 to dim do 10: Generate random numbers r1, r2, p 11: Compute coefficients A, C, b, l 12: if p < 0.5 then 13: if |A| ≥ 1 then 14: Select random whale X_rand 15: Compute distance D_X_rand and update X[i,j] using Lévy flight with weight w 16: else 17: Compute distance D_Leader 18: Update X[i,:] using cosine–sine adaptive strategy with weight w 19: else 20: Select random whale X[Rindex] 21: Compute distance2Leader and Lambda 22: Update X[i,j] based on WOA prey behavior with weight w 23: end for 24: Update joiners via LJDUpdate 25: Apply boundary control on X 26: Evaluate fitness of updated X 27: Perform quantum rotation crossover with GbestPosition 28: Sort population and update Gbest if improved 29: for i ← 1 to pop do 30: Apply DE-inspired update strategy on X[i] with parameters fhai, wmega 31: Perform boundary control and evaluate fTemp 32: if fTemp < GbestScore then 33: Update GbestScore and GbestPosition 34: end for 35: Apply Gaussian-Cauchy mutation on GbestPosition 36: if mutated fitness < GbestScore then 37: Update GbestScore and GbestPosition 38: Record Curve[t] ← GbestScore 39: Print iteration info 40: end for 41: return GbestScore, GbestPosition, Curve |
2.7. QCAM
2.7.1. QSM
2.7.2. CAM Integrated with QSM
2.7.3. QCAM Algorithm Steps
| Algorithm 2: QCAM |
| Input: Input tensor inputs ∈ ℝ^(B × L × D) |
| Output: Attention-enhanced feature representation |
| 1: Initialize two Conv1D layers with 64 filters and kernel size 1 (Conv1, Conv2) 2: function QSM_Mapping(attention_scores) 3: Set constants: a ← 1.0, m ← 1.0, ℏ ← 1.0 4: Define sequence length n ← [1, 2,..., L] 5: Compute energy levels En ← (n2 * π2 * ℏ2)/(2ma2) 6: Compute spatial grid x ← linspace(0, a, L), time t ← 1.0 7: for each n_i in n do 8: Compute ψn(x, t) ← √(2/a) * sin(n_i * π * x/a) * cos(En * t/ℏ) 9: end for 10: Aggregate ψ ← ∑ ψn(x, t) 11: Compute probability density ψ2 ← |ψ|2 12: Tile ψ2 across batch dimension 13: return ψ2 14: end function 15: function CALL(inputs) 16: Compute FFT of inputs: fft ← FFT(inputs) 17: Extract frequency features: freq_features ← concat(Re(fft), Im(fft)) 18: Compute average pooled features: avg_pool ← mean(freq_features, axis = 1) 19: Compute max pooled features: max_pool ← max(freq_features, axis = 1) 20: avg_out ← Conv2(Conv1(avg_pool)) 21: max_out ← Conv2(Conv1(max_pool)) 22: Compute channel attention: channel_attn ← avg_out + max_out 23: Compute raw attention scores: scores ← channel_attn · channel_attnᵀ 24: Apply QSM mapping: qsm_scores ← QSM_Mapping(scores) 25: Create lower triangular mask M ∈ ℝ^(L × L) 26: Apply causal masking: masked_scores ← qsm_scores ⊙ M + (1 − M) * −∞ 27: Normalize attention weights: α ← softmax(masked_scores, axis = −1) 28: Compute weighted output: output ← α · freq_features 29: return output 30: end function |
2.8. Modeling Process
- (1)
- Missing values in the air quality and meteorological time series datasets are first filled. Then, feature variables are selected using correlation coefficients and RFECV to reduce model complexity.
- (2)
- The dataset is split into training and testing sets with an 8:2 ratio. The input data is first assigned attention weights through QCAM, then feature extraction is performed by BiTCN, and finally, predictions are made using BiLSTM.
- (3)
- QMEWOA is employed to optimize the model’s hyperparameters. Initially, the whale population size, iteration count, and other algorithm parameters are set. QMEWOA iteratively updates the fitness values, ultimately identifying the optimal hyperparameters. These optimal hyperparameters are then applied to the QCAM-BiTCN-BiLSTM model to obtain the locally optimal model using the best features.
- (4)
- Finally, the performance of the proposed model is compared with other models to validate its superiority.
3. Experiments and Analysis
3.1. Experimental Environment
3.2. Comparative Analysis of Optimization Algorithm Performance
3.3. Optimization Parameter Experimental Analysis
3.4. Hyperparameter Settings
3.5. Experimental Results Analysis
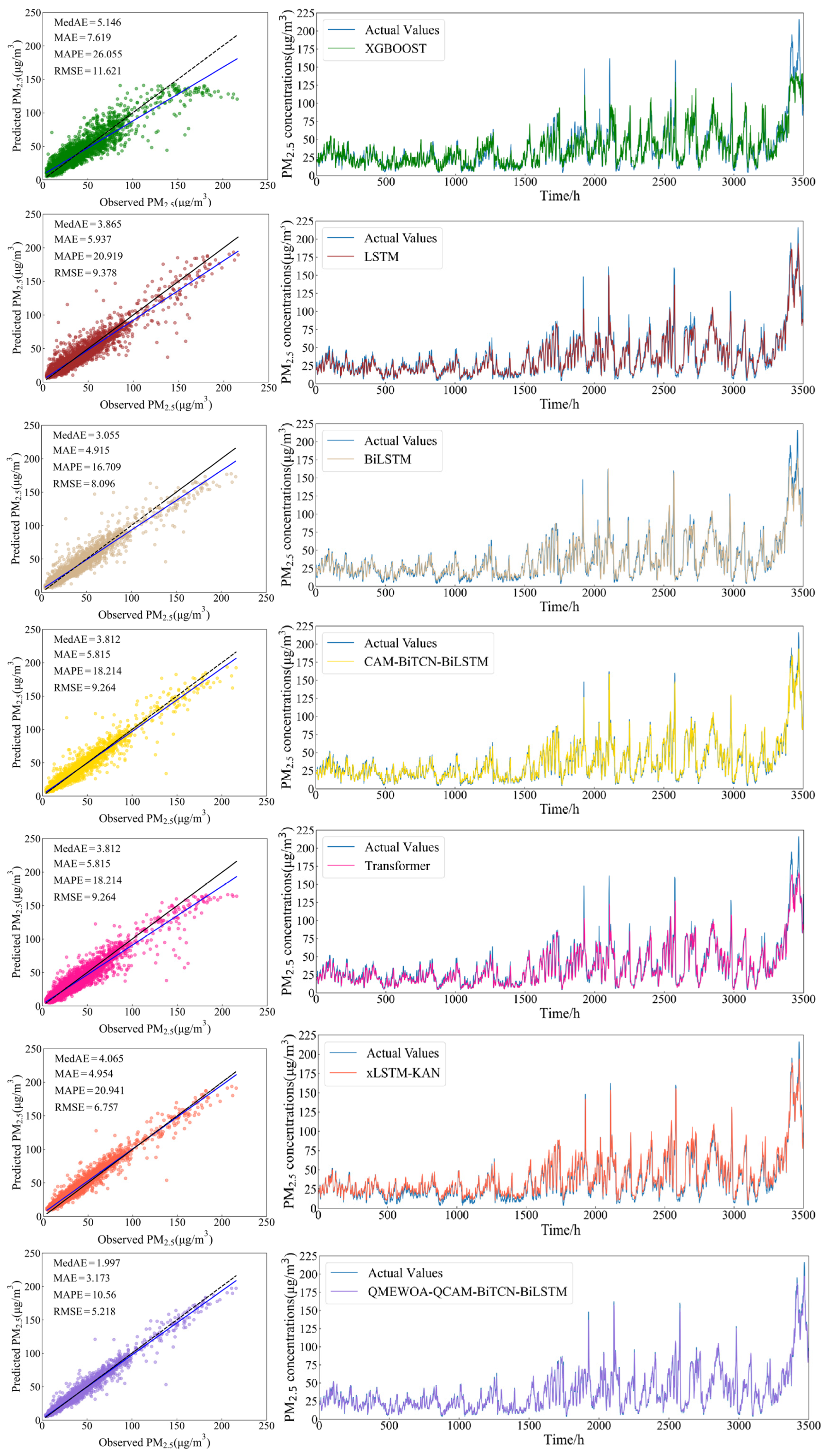
3.5.1. Comparison Experiment
3.5.2. Ablation Experiment
3.5.3. Five-Dimensional Evaluation of Practical Utility
3.5.4. Generalization Experiment
4. Future Research Trends
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zeng, T.; Xu, L.; Liu, Y.; Liu, R.; Luo, Y.; Xi, Y. A hybrid optimization prediction model for PM2.5 based on VMD and deep learning. Atmos. Pollut. Res. 2024, 15, 102152. [Google Scholar] [CrossRef]
- Yu, Q.; Yuan, H.-W.; Liu, Z.-L.; Xu, G.-M. Spatial weighting EMD-LSTM based approach for short-term PM2.5 prediction research. Atmos. Pollut. Res. 2024, 15, 102256. [Google Scholar] [CrossRef]
- Kaur, M.; Singh, D.; Jabarulla, M.Y.; Kumar, V.; Kang, J.; Lee, H.-N. Computational deep air quality prediction techniques: A systematic review. Artif. Intell. Rev. 2023, 56 (Suppl. 2), 2053–2098. [Google Scholar] [CrossRef]
- Woody, M.; Wong, H.-W.; West, J.; Arunachalam, S. Multiscale predictions of aviation-attributable PM2.5 for U.S. airports modeled using CMAQ with plume-in-grid and an aircraft-specific 1-D emission model. Atmos. Environ. 2016, 147, 384–394. [Google Scholar] [CrossRef]
- Mao, X.; Shen, T.; Feng, X. Prediction of hourly ground-level PM2.5 concentrations 3 days in advance using neural networks with satellite data in eastern China. Atmos. Pollut. Res. 2017, 8, 1005–1015. [Google Scholar] [CrossRef]
- MacIntosh, D.L.; Stewart, J.H.; Myatt, T.A.; Sabato, J.E.; Flowers, G.C.; Brown, K.W.; Hlinka, D.J.; Sullivan, D.A. Use of CALPUFF for exposure assessment in a near-field, complex terrain setting. Atmos. Environ. 2010, 44, 262–270. [Google Scholar] [CrossRef]
- Righi, S.; Lucialli, P.; Pollini, E. Statistical and diagnostic evaluation of the ADMS-Urban model compared with an urban air quality monitoring network. Atmos. Environ. 2009, 43, 3850–3857. [Google Scholar] [CrossRef]
- Kumar, A.; Patil, R.S.; Dikshit, A.K.; Kumar, R. Application of AERMOD for short-term air quality prediction with forecasted meteorology using WRF model. Clean Technol. Environ. Policy 2017, 19, 1955–1965. [Google Scholar] [CrossRef]
- Soni, M.; Verma, S.; Mishra, M.K.; Mall, R.; Payra, S. Estimation of particulate matter pollution using WRF-Chem during dust storm event over India. Urban Clim. 2022, 44, 16. [Google Scholar] [CrossRef]
- Gao, J.; Tian, H.; Cheng, K.; Lu, L.; Zheng, M.; Wang, S.; Hao, J.; Wang, K.; Hua, S.; Zhu, C. The variation of chemical characteristics of PM2.5 and PM10 and formation causes during two haze pollution events in urban Beijing, China. Atmos. Environ. 2015, 107, 1–8. [Google Scholar] [CrossRef]
- Chemel, C.; Fisher, B.; Kong, X.; Francis, X.; Sokhi, R.; Good, N.; Collins, W.; Folberth, G. Application of chemical transport model CMAQ to policy decisions regarding PM2.5 in the UK. Atmos. Environ. 2014, 82, 410–417. [Google Scholar] [CrossRef]
- Nopmongcol, U.; Koo, B.; Tai, E.; Jung, J.; Piyachaturawat, P.; Emery, C.; Yarwood, G.; Pirovano, G.; Mitsakou, C.; Kallos, G. Modeling Europe with CAMx for the Air Quality Model Evaluation International Initiative (AQMEII). Atmos. Environ. 2012, 53, 177–185. [Google Scholar] [CrossRef]
- Jiang, P.; Dong, Q.; Li, P. A novel hybrid strategy for PM2.5 concentration analysis and prediction. J. Environ. Manag. 2017, 196, 443–457. [Google Scholar] [CrossRef] [PubMed]
- Liu, H.; Jin, K.; Duan, Z. Air PM2.5 concentration multi-step forecasting using a new hybrid modeling method: Comparing cases for four cities in China. Atmos. Pollut. Res. 2019, 10, 1588–1600. [Google Scholar] [CrossRef]
- Zhang, B.; Zhang, H.; Zhao, G.; Lian, J. Constructing a PM2.5 concentration prediction model by combining auto-encoder with Bi-LSTM neural networks. Environ. Model. Softw. 2020, 124, 104600. [Google Scholar] [CrossRef]
- Yafouz, A.; AlDahoul, N.; Birima, A.H.; Ahmed, A.N.; Sherif, M.; Sefelnasr, A.; Allawi, M.F.; Elshafie, A. Comprehensive comparison of various machine learning algorithms for short-term ozone concentration prediction. Alex. Eng. J. 2022, 61, 4607–4622. [Google Scholar] [CrossRef]
- Duan, M.; Sun, Y.; Zhang, B.; Chen, C.; Tan, T.; Zhu, Y. PM2.5 Concentration Prediction in Six Major Chinese Urban Agglomerations: A Comparative Study of Various Machine Learning Methods Based on Meteorological Data. Atmosphere 2023, 14, 903. [Google Scholar] [CrossRef]
- Gong, H.; Guo, J.; Mu, Y.; Guo, Y.; Hu, T.; Li, S.; Luo, T.; Sun, Y. Atmospheric PM2.5 Prediction Model Based on Principal Component Analysis and SSA-SVM. Sustainability 2024, 16, 832. [Google Scholar] [CrossRef]
- Sun, W.; Sun, J. Daily PM2.5 concentration prediction based on principal component analysis and LSSVM optimized by cuckoo search algorithm. J. Environ. Manag. 2017, 188, 144–152. [Google Scholar] [CrossRef] [PubMed]
- Liu, H.; Chen, C. Prediction of outdoor PM2.5 concentrations based on a three-stage hybrid neural network model. Atmos. Pollut. Res. 2020, 11, 469–481. [Google Scholar] [CrossRef]
- Aman, N.; Panyametheekul, S.; Pawarmart, I.; Sudhibrabha, S. A Visibility-Based Historical PM2.5 Estimation for Four Decades (1981–2022) Using Machine Learning in Thailand: Trends, Meteorological Normalization, and Influencing Factors Using SHAP Analysis. Aerosol Air Qual. Res. 2025, 25, 4. [Google Scholar] [CrossRef]
- Cáceres-Tello, J.; Galán-Hernández, J.J. Mathematical Evaluation of Classical and Quantum Predictive Models Applied to PM2.5 Forecasting in Urban Environments. Mathematics 2025, 13, 1979. [Google Scholar] [CrossRef]
- Ma, J.; Cheng, J.C.P.; Lin, C.; Tan, Y.; Zhang, J. Improving air quality prediction accuracy at larger temporal resolutions using deep learning and transfer learning techniques. Atmos. Environ. 2019, 214, 116885. [Google Scholar] [CrossRef]
- Xia, S.; Zhang, R.; Zhang, L.; Wang, T.; Wang, W. Multi-dimensional distribution prediction of PM2.5 concentration in urban residential areas based on CNN. Build. Environ. 2025, 267, 112167. [Google Scholar] [CrossRef]
- Zhang, L.; Na, J.; Zhu, J.; Shi, Z.; Zou, C.; Yang, L. Spatiotemporal causal convolutional network for forecasting hourly PM2.5 concentrations in Beijing, China. Comput. Geosci. 2021, 155, 104869. [Google Scholar] [CrossRef]
- He, J.; Li, X.; Chen, Z.; Mai, W.; Zhang, C.; Wang, X.; Huang, M. A hybrid CLSTM-GPR model for forecasting particulate matter (PM2.5). Atmos. Pollut. Res. 2023, 14, 13. [Google Scholar] [CrossRef]
- Ma, J.; Li, X.; Chen, Z.; Mai, W.; Zhang, C.; Wang, X.; Huang, M. A Lag-FLSTM deep learning network based on Bayesian Optimization for multi-sequential-variant PM2.5 prediction. Sustain. Cities Soc. 2020, 60, 102237. [Google Scholar] [CrossRef]
- Luo, J.; Gong, Y. Air pollutant prediction based on ARIMA-WOA-LSTM model. Atmos. Pollut. Res. 2023, 14, 101761. [Google Scholar] [CrossRef]
- Bai, X.S.; Zhang, N.; Cao, X.; Chen, W. Prediction of PM2.5 concentration based on a CNN-LSTM neural network algorithm. Peerj 2024, 12, 23. [Google Scholar] [CrossRef] [PubMed]
- Ren, Y.; Wang, S.; Xia, B. Deep learning coupled model based on TCN-LSTM for particulate matter concentration prediction. Atmos. Pollut. Res. 2023, 14, 12. [Google Scholar] [CrossRef]
- Wang, H.Q.; Zhang, L.F.; Wu, R. MSAFormer: A Transformer-Based Model for PM2.5 Prediction Leveraging Sparse Autoencoding of Multi-Site Meteorological Features in Urban Areas. Atmosphere 2023, 14, 1294. [Google Scholar] [CrossRef]
- Pan, K.; Lu, J.; Li, J.; Xu, Z. A Hybrid Autoformer Network for Air Pollution Forecasting Based on External Factor Optimization. Atmosphere 2023, 14, 869. [Google Scholar] [CrossRef]
- Elkharadly, M.; Amin, K.; Abo-Seida, O.; Ibrahim, M. Bayesian optimization enhanced FKNN model for Parkinson’s diagnosis. Biomed. Signal Process. Control 2025, 100, 16. [Google Scholar] [CrossRef]
- Yang, H.; Wang, W.; Li, G. Multi-factor PM2.5 concentration optimization prediction model based on decomposition and integration. Urban Clim. 2024, 55, 101916. [Google Scholar] [CrossRef]
- Ni, S.; Jia, P.; Xu, Y.; Zeng, L.; Li, X.; Xu, M. Prediction of CO concentration in different conditions based on Gaussian-TCN. Sens. Actuators B Chem. 2023, 376, 133010. [Google Scholar] [CrossRef]
- Wei, X.; Wang, Z. TCN-attention-HAR: Human activity recognition based on attention mechanism time convolutional network. Sci. Rep. 2024, 14, 14. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Qin, S.J. Applying and dissecting LSTM neural networks and regularized learning for dynamic inferential modeling. Comput. Chem. Eng. 2023, 175, 13. [Google Scholar] [CrossRef]
- Song, B.; Liu, Y.; Fang, J.; Liu, W.; Zhong, M.; Liu, X. An optimized CNN-BiLSTM network for bearing fault diagnosis under multiple working conditions with limited training samples. Neurocomputing 2024, 574, 127284. [Google Scholar] [CrossRef]
- Mirjalili, S.; Lewis, A. The Whale Optimization Algorithm. Adv. Eng. Softw. 2016, 95, 51–67. [Google Scholar] [CrossRef]
- Li, M.; Xu, G.; Lai, Q.; Chen, J. A chaotic strategy-based quadratic Opposition-Based Learning adaptive variable-speed whale optimization algorithm. Math. Comput. Simul. 2022, 193, 71–99. [Google Scholar] [CrossRef]
- Xiao, W.-S.; Li, G.-X.; Liu, C.; Tan, L.-P. A novel chaotic and neighborhood search-based artificial bee colony algorithm for solving optimization problems. Sci. Rep. 2023, 13, 20496. [Google Scholar] [CrossRef] [PubMed]
- Mantegna, R.N. Fast, accurate algorithm for numerical simulation of Lévy stable stochastic processes. Phys. Rev. E 1994, 49, 4677. [Google Scholar] [CrossRef] [PubMed]
- Sun, J.; Xu, W.; Feng, B. A global search strategy of quantum-behaved particle swarm optimization. In Proceedings of the IEEE Conference on Cybernetics and Intelligent Systems, Singapore, 1–3 December 2004. [Google Scholar]
- Lyu, X.; Hu, Z.; Zhou, H.; Wang, Q. Application of improved MCKD method based on QGA in planetary gear compound fault diagnosis. Measurement 2019, 139, 236–248. [Google Scholar] [CrossRef]
- Xue, A.; Yang, W.; Yuan, X.; Yu, B.; Pan, C. Estimating state of health of lithium-ion batteries based on generalized regression neural network and quantum genetic algorithm. Appl. Soft Comput. 2022, 130, 109688. [Google Scholar] [CrossRef]
- Fan, J.; Yang, J.; Zhang, X.; Yao, Y. Real-time single-channel speech enhancement based on causal attention mechanism. Appl. Acoust. 2022, 201, 109084. [Google Scholar] [CrossRef]
- Zhang, J.T.; Cheng, P.; Li, Z.; Wu, H.; An, W.; Zhou, J. QCA-Net: Quantum-based Channel Attention for Deep Neural Networks. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Broadbeach, Australia, 18–23 June 2023. [Google Scholar]
- Zhang, J.; Zhou, J.; Wang, H.; Lei, Y.; Cheng, P.; Li, Z.; Wu, H.; Yu, K.; An, W. QEA-Net: Quantum-Effects-based Attention Networks. In Proceedings of the 6th Chinese Conference on Pattern Recognition and Computer Vision (PRCV), Xiamen, China, 13–15 October 2023; Springer: Berlin/Heidelberg, Germany, 2023. [Google Scholar]
- Abbal, K.; El-Amrani, M.; Aoun, O.; Benadada, Y. Adaptive Particle Swarm Optimization with Landscape Learning for Global Optimization and Feature Selection. Modelling 2025, 6, 9. [Google Scholar] [CrossRef]
- Xie, X.; Yang, Y.; Zhou, H. Multi-Strategy Hybrid Whale Optimization Algorithm Improvement. Appl. Sci. 2025, 15, 2224. [Google Scholar] [CrossRef]
- Gan, R.; Huang, T.; Shao, J.; Wang, F. Music Genre Classification Based on VMD-IWOA-XGBOOST. Mathematics 2024, 12, 1549. [Google Scholar] [CrossRef]
- Li, N.; Xu, W.; Zeng, Q.; Ren, Y.; Ma, W.; Tan, K. A hybrid WOA-CNN-BiLSTM framework with enhanced accuracy for low-voltage shunt capacitor remaining life prediction in power systems. Energy 2025, 326, 136183. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number | Variable Name | Unit |
|---|---|---|
| 1 | PM2.5 | μg/m3 |
| 2 | PM10 | μg/m3 |
| 3 | Sulfur dioxide (SO2) | μg/m3 |
| 4 | Nitrogen dioxide (NO2) | μg/m3 |
| 5 | Carbon monoxide (CO) | μg/m3 |
| 6 | Ozone (O3) | μg/m3 |
| 7 | Temperature (Temp) | °C |
| 8 | Humidity (Hum) | / |
| 9 | Atmospheric pressure (Atm) | Pa |
| 10 | Beaufort scale (Bf) | / |
| 11 | Wind speed (WS) | m/s |
| 12 | Wind direction (WD) | / |
| 13 | Ultraviolet (UV) | W/m |
| 14 | Visibility (Vis) | m |
| Selected Variables | Correlation Coefficient |
|---|---|
| PM10 | 0.73 |
| NO2 | 0.59 |
| CO | 0.52 |
| Vis | −0.48 |
| Temp | −0.41 |
| Atm | 0.38 |
| Function Expression | Dimension | Range | Optimum |
|---|---|---|---|
| 30 | [−100, 100] | 0 | |
| 30 | [−100, 100] | 0 | |
| 30 | [−100, 100] | 0 | |
| 100 | [−100, 100] | 0 | |
| 30 | [−30, 30] | 0 | |
| 30 | [−100, 100] | 0 | |
| 30 | [−32, 32] | 0 | |
| 30 | [−5.12, 5.12] | 0 | |
| 30 | [−600, 600] | 0 | |
| 2 | [−65, 65] | 1 |
| Algorithms | Metric | F1 | F2 | F3 | F4 | F5 | F6 | F7 | F8 | F9 | F10 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| QMEWOA | Best | 0 | 5.33 × 10−216 | 0 | 3.192 × 10−264 | 6.546 × 10−7 | 1.553 × 10−10 | 4.440 × 10−16 | 0 | 0 | 0.998 |
| Avg | 0 | 8.40 × 10−127 | 9.101 × 10−296 | 4.642 × 10−132 | 16.100 | 0.135 | 4.440 × 10−16 | 0 | 0 | 1.946 | |
| Std | 0 | 4.14 × 10−126 | 0 | 3.249 × 10−131 | 14.231 | 0.938 | 0 | 0 | 0 | 2.429 | |
| WOA | Best | 2.047 × 10−24 | 7.117 × 10−16 | 2.873 × 10−6 | 1.636 × 10−6 | 26.284 | 0.529 | 3.00 × 10−6 | 0 | 0 | 0.998 |
| Avg | 1.191 × 10−20 | 2.219 × 10−14 | 0.005 | 0.000 | 27.672 | 1.584 | 3.410 × 10−15 | 4.662 × 10−17 | 0 | 1.528 | |
| Std | 6.362 × 10−20 | 4.265 × 10−14 | 0.016 | 0.000 | 0.685 | 0.587 | 1.349 × 10−14 | 2.674 × 10−16 | 0 | 0.734 | |
| IWOA | Best | 3.307 × 10−47 | 5.915 × 10−28 | 1.164 × 10−17 | 6.409 × 10−14 | 26.228 | 1.418 | 4.440 × 10−16 | 0 | 0 | 0.998 |
| Avg | 2.245 × 10−37 | 1.828 × 10−24 | 5.828 × 10−12 | 1.086 × 10−10 | 27.806 | 2.932 | 4.423 × 10−15 | 0 | 0 | 3.716 | |
| Std | 1.089 × 10−36 | 4.234 × 10−24 | 2.135 × 10−11 | 2.416 × 10−10 | 0.755 | 0.566 | 1.355 × 10−15 | 0 | 0 | 3.044 | |
| GWO | Best | 1.668 × 10−29 | 1.702 × 10−17 | 1.009 × 10−8 | 8.542 × 10−8 | 26.025 | 5.365 × 10−5 | 7.505 × 10−14 | 5.684 × 10−14 | 0 | 0.99 |
| Avg | 1.401 × 10−27 | 1.119 × 10−16 | 8.846 × 10−6 | 7.305 × 10−7 | 27.326 | 0.767 | 1.058 × 10−13 | 2.338 | 0.004 | 3.801 | |
| Std | 1.737 × 10−27 | 1.514 × 10−16 | 2.050 × 10−5 | 8.489 × 10−7 | 0.716 | 0.367 | 1.871 × 10−14 | 3.293 | 0.110 | 3.785 | |
| PSO | Best | 229.904 | 289.187 | 3383.222 | 18.858 | 11,577.624 | 211.511 | 5.933 | 79.564 | 1.387 | 0.998 |
| Avg | 1430.455 | 692.692 | 13,778.357 | 31.1195 | 397,781.152 | 1883.327 | 11.965 | 126.838 | 15.388 | 2.164 | |
| Std | 1011.679 | 179.456 | 6226.064 | 5.590 | 489,303.742 | 2021.789 | 2.739 | 25.149 | 10.493 | 1.727 | |
| DBO | Best | 2.957 × 10−58 | 1.367 × 10−30 | 1.145 × 10−54 | 2.854 × 10−27 | 26.873 | 0.025 | 4.440 × 10−16 | 0 | 0 | 0.998 |
| Avg | 4.197 × 10−26 | 14.801 | 16,049.159 | 1.689 × 10−24 | 64.023 | 0.117 | 1.653 | 18.511 | 0.000 | 1.629 | |
| Std | 2.867 × 10−25 | 18.892 | 15,446.437 | 5.491 × 10−24 | 189.241 | 0.115 | 4.479 | 24.379 | 0.001 | 1.584 |
| Models | Neuron | Batch Size | Epoch | Learning Rate | Dropout Rate | Leaf Node | Maximum Depth | Embed Dim | Seed |
|---|---|---|---|---|---|---|---|---|---|
| XGBOOST | / | / | / | / | / | 100 | 100 | / | 3407 |
| LSTM | 512 | 512 | 50 | 0.0003 | 0.2 | / | / | / | 3407 |
| BiLSTM | 512 | 512 | 50 | 0.0003 | 0.2 | / | / | / | 3407 |
| Transformer | 512 | 512 | 50 | 0.0003 | 0.2 | / | / | 512 | 3407 |
| CAM-BiTCN-BiLSTM | 512 | 512 | 50 | 0.0003 | 0.2 | / | / | / | 3407 |
| xLSTM-KAN | 512 | 512 | 50 | 0.0003 | 0.2 | / | / | 512 | 3407 |
| QMEWOA-QCAM-BiTCN-BiLSTM | [10–512] | [1–512] | [10–50] | 0.0003 | 0.2 | / | / | / | 3407 |
| Models | MedAE | MAE | MAPE/% | RMSE |
|---|---|---|---|---|
| XGBOOST | 5.146 | 7.619 | 26.055 | 11.621 |
| LSTM | 3.865 | 5.937 | 20.919 | 9.378 |
| BiLSTM | 3.055 | 4.915 | 16.709 | 8.096 |
| Transformer | 3.812 | 5.815 | 18.214 | 9.264 |
| CAM-BiTCN-BiLSTM | 2.733 | 4.410 | 14.829 | 7.344 |
| xLSTM-KAN | 4.065 | 4.954 | 20.941 | 6.757 |
| QMEWOA-QCAM-BiTCN-BiLSTM | 1.997 | 3.173 | 10.560 | 5.218 |
| Comparison Methods | QMEWOA-QCAM-BiTCN-BiLSTM |
|---|---|
| XGBOOST | −16.602 *** |
| LSTM | −8.785 *** |
| BiLSTM | −17.745 *** |
| Transformer | −9.009 *** |
| CAM-BiTCN-BiLSTM | −8.581 *** |
| xLSTM-KAN | −21.182 *** |
| Model Description | Model Name | MedAE | MAE | MAPE/% | RMSE |
|---|---|---|---|---|---|
| Remove QMEWOA | QCAM-BiTCN-BiLSTM | 3.109 | 4.239 | 14.334 | 6.479 |
| Remove QSM | CAM-BiTCN-BiLSTM | 2.733 | 4.410 | 14.829 | 7.344 |
| Remove CAM | BiTCN-BiLSTM | 3.098 | 4.779 | 15.858 | 7.637 |
| Remove BiTCN | BiLSTM | 3.055 | 4.860 | 16.709 | 7.990 |
| Proposed Model | QMEWOA-QCAM-BiTCN-BiLSTM | 1.997 | 3.173 | 10.560 | 5.218 |
| Models | MedAE | MAE | MAPE/% | RMSE |
|---|---|---|---|---|
| XGBOOST | 10.710 | 18.929 | 45.165 | 31.310 |
| LSTM | 16.440 | 22.611 | 75.176 | 31.398 |
| BiLSTM | 13.233 | 19.871 | 54.124 | 29.522 |
| Transformer | 15.990 | 18.254 | 88.87 | 25.690 |
| CAM-BiTCN-BiLSTM | 9.669 | 16.570 | 54.390 | 25.900 |
| xLSTM-KAN | 13.717 | 18.823 | 61.107 | 27.204 |
| QMEWOA-QCAM-BiTCN-BiLSTM | 5.439 | 10.134 | 26.535 | 18.738 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, T.; Jiang, Y.; Gan, R.; Wang, F. Quantum-Enhanced Attention Neural Networks for PM2.5 Concentration Prediction. Modelling 2025, 6, 69. https://doi.org/10.3390/modelling6030069
Huang T, Jiang Y, Gan R, Wang F. Quantum-Enhanced Attention Neural Networks for PM2.5 Concentration Prediction. Modelling. 2025; 6(3):69. https://doi.org/10.3390/modelling6030069
Chicago/Turabian StyleHuang, Tichen, Yuyan Jiang, Rumeijiang Gan, and Fuyu Wang. 2025. "Quantum-Enhanced Attention Neural Networks for PM2.5 Concentration Prediction" Modelling 6, no. 3: 69. https://doi.org/10.3390/modelling6030069
APA StyleHuang, T., Jiang, Y., Gan, R., & Wang, F. (2025). Quantum-Enhanced Attention Neural Networks for PM2.5 Concentration Prediction. Modelling, 6(3), 69. https://doi.org/10.3390/modelling6030069