
A Multi-Head Attention-Based Transformer Model for Predicting Causes in Aviation Incidents





Abstract
1. Introduction
- A generative model based on a multi-head attention transformer is trained and evaluated to generate the probable cause of an aviation incident based on the raw textual analysis of event narratives preceding, during, or following an accident. Given that the training dataset comprises both long and short input narratives, the model effectively processes diverse input lengths, thereby expediting the investigation process and enhancing air transport safety.
- Many aviation incident datasets have instances with analysis narratives but no corresponding entries of the probable cause. Consequently, a significant number of instances are removed during data preprocessing, thereby reducing the volume of training data that could otherwise improve model learning. This data reduction negatively impacts the model’s ability to generalize to new instances. By using the model trained in this work, the missing probable cause entries can be inferred from the available analysis narratives, ultimately enhancing model performance and improving generalization to unseen data.
2. Related Work
3. Proposed Approach
3.1. Dataset
3.2. Data Pre-Processing
3.3. The Transformer
- is the projection dimension of keys, K.
- T transposes K to allow matrix multiplication.
- represents a learnable weight matrix that is used to project the concatenated outputs of all attention heads into the desired output dimension.
- is the dimension of the input and output embeddings through the transformer model.
3.4. Experimental Setup
3.5. Performance Metrics
3.5.1. Bilingual Evaluation Understudy (BLEU)
- Brevity Penalty, calculated using Equation (4);
- order i n-gram precision’s weight;
- n-gram’s modified precision score of order i;
- maximum n-gram order to consider.
- length of predicted cause
- average length of reference cause.
3.5.2. Recall Oriented Understudy for Gisting Evaluation (ROUGE)
- is the number of n-grams from the target probable cause matching with the predicated probable cause.
- is the count of n-grams in predicted probable cause.
- is the count of n-grams in actual probable cause.
3.5.3. Latent Semantic Analysis (LSA)
3.5.4. BERTScore
4. Results
4.1. Model Performance Based on the BERTScore
4.2. Model Performance Based on the BLEU Score
4.3. Model Performance Based on the LSA Similarity Score
4.4. Model Performance Based on the ROUGE Scores
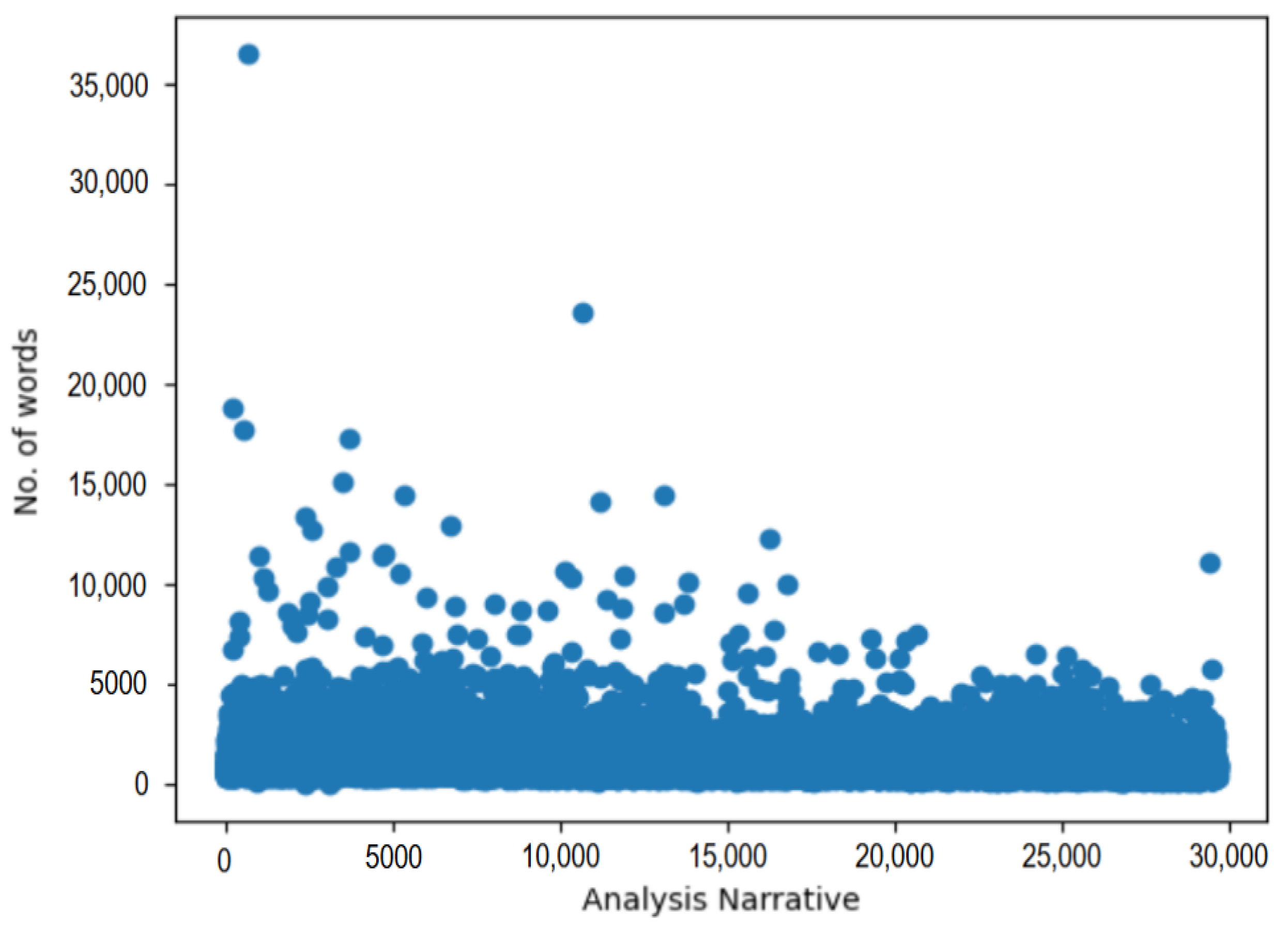
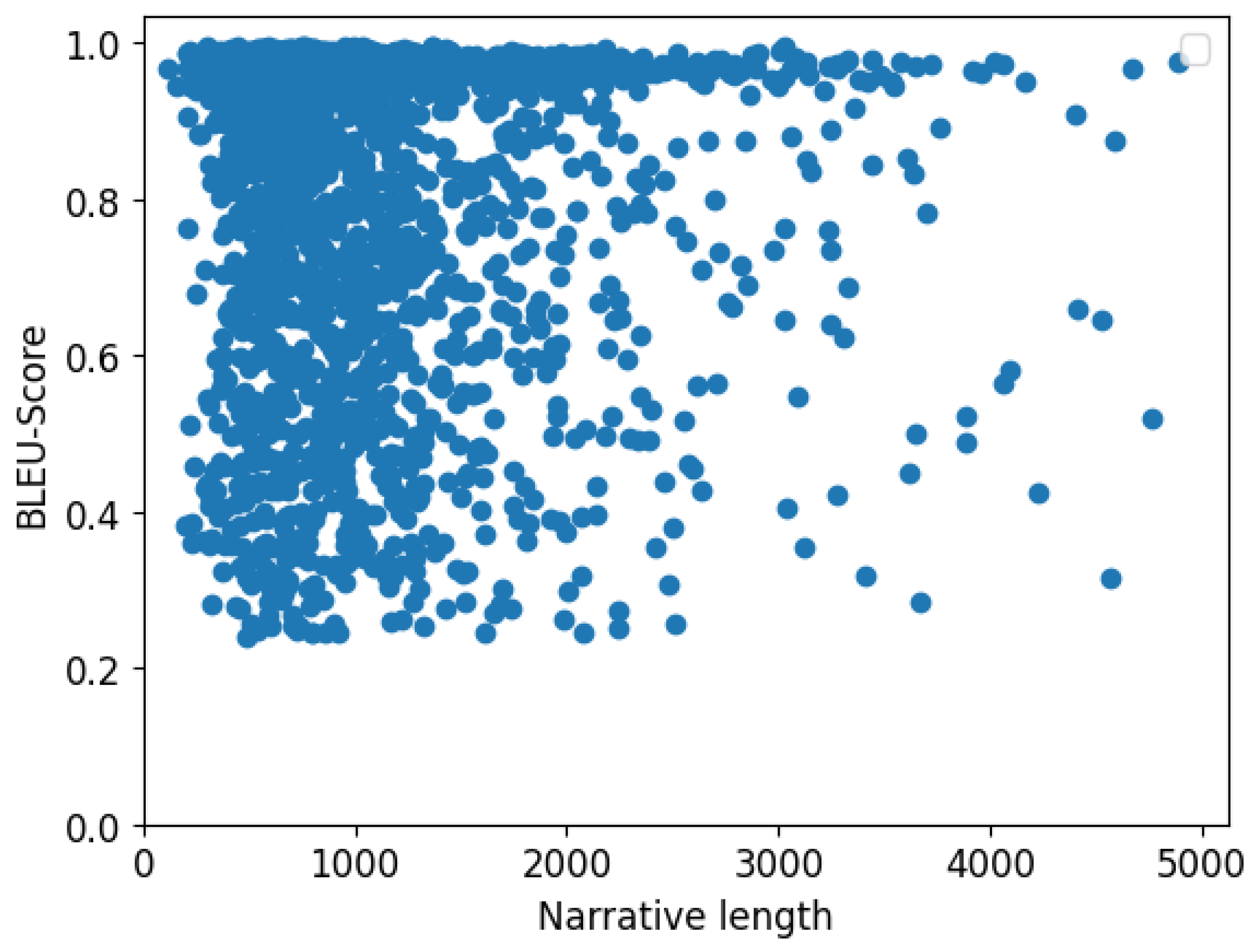
4.5. analysisNarrative Length vs. BLEU/LSA Scores
5. Discussion
“The mechanic’s improper maintenance of the main transmission aft pinion nut and belt drive system, which resulted in the uncoupling of the tail rotor driveshaft and the subsequent loss of helicopter control.”
“The failure of the main rotor drive belts due to a loss of belt tension on the main rotor drive system as a result of maintenance personnel’s failure to properly secure the nut and the helicopters main rotor drive belts.”
Limitations
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Vidović, A.; Franjić, A.; Štimac, I.; Ban, M.O. The importance of flight recorders in the aircraft accident investigation. Transp. Res. Procedia 2022, 64, 183–190. [Google Scholar] [CrossRef]
- Wild, G. Airbus A32x Versus Boeing 737 Safety Occurrences. IEEE Aerosp. Electron. Syst. Mag. 2023, 38, 4–12. [Google Scholar] [CrossRef]
- Johnson, C. A Handbook of Incident and Accident Reporting; Glasgow University Press: Glasgow, UK, 2003; Volume 115. [Google Scholar]
- Dong, T.; Yang, Q.; Ebadi, N.; Luo, X.R.; Rad, P. Identifying incident causal factors to improve aviation transportation safety: Proposing a deep learning approach. J. Adv. Transp. 2021, 2021, 5540046. [Google Scholar] [CrossRef]
- Levin, A.; Suhartono, H. Pilot Who Hitched a Ride Saved Lion Air 737 Day Before Deadly Crash. Bloomberg 2019, 19, 2019. [Google Scholar]
- Dahal, S. Letting go and saying goodbye: A Nepalese family’s decision, in the Ethiopian Airline crash ET-302. Forensic Sci. Res. 2022, 7, 383–384. [Google Scholar] [CrossRef] [PubMed]
- Nanyonga, A.; Wasswa, H.; Turhan, U.; Joiner, K.; Wild, G. Exploring Aviation Incident Narratives Using Topic Modeling and Clustering Techniques. In Proceedings of the 2024 IEEE Region 10 Symposium (TENSYMP), New Delhi, India, 27–29 September 2024; pp. 1–6. [Google Scholar]
- Ahmad, F.; de la Chica, S.; Butcher, K.; Sumner, T.; Martin, J.H. Towards automatic conceptual personalization tools. In Proceedings of the 7th ACM/IEEE-CS Joint Conference on Digital Libraries, Vancouver, BC, Canada, 18–23 June 2007; pp. 452–461. [Google Scholar]
- Jelodar, H.; Wang, Y.; Yuan, C.; Feng, X.; Jiang, X.; Li, Y.; Zhao, L. Latent Dirichlet allocation (LDA) and topic modeling: Models, applications, a survey. Multimed. Tools Appl. 2019, 78, 15169–15211. [Google Scholar] [CrossRef]
- Kuhn, K.D. Using structural topic modeling to identify latent topics and trends in aviation incident reports. Transp. Res. Part C Emerg. Technol. 2018, 87, 105–122. [Google Scholar] [CrossRef]
- Li, Z.; Zhang, H.; Wang, S.; Huang, F.; Li, Z.; Zhou, J. Exploit latent Dirichlet allocation for collaborative filtering. Front. Comput. Sci. 2018, 12, 571–581. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Nanyonga, A.; Wasswa, H.; Wild, G. Phase of flight classification in aviation safety using lstm, gru, and bilstm: A case study with asn dataset. In Proceedings of the 2023 International Conference on High Performance Big Data and Intelligent Systems (HDIS), Macau, China, 6–8 December 2023; pp. 24–28. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog. 2019, 1, 9. [Google Scholar]
- Jiao, X.; Yin, Y.; Shang, L.; Jiang, X.; Chen, X.; Li, L.; Wang, F.; Liu, Q. Tinybert: Distilling bert for natural language understanding. arXiv 2019, arXiv:1909.10351. [Google Scholar]
- Nanyonga, A.; Wasswa, H.; Wild, G. Aviation Safety Enhancement via NLP & Deep Learning: Classifying Flight Phases in ATSB Safety Reports. In Proceedings of the 2023 Global Conference on Information Technologies and Communications (GCITC), Bangalore, India, 1–3 December 2023; pp. 1–5. [Google Scholar]
- Liu, X.; Duh, K.; Gao, J. Stochastic answer networks for natural language inference. arXiv 2018, arXiv:1804.07888. [Google Scholar]
- Nanyonga, A.; Wasswa, H.; Wild, G. Comparative Study of Deep Learning Architectures for Textual Damage Level Classification. In Proceedings of the 2024 11th International Conference on Signal Processing and Integrated Networks (SPIN), Noida, India, 21–22 March 2024; pp. 421–426. [Google Scholar]
- Ainslie, J.; Ontanon, S.; Alberti, C.; Cvicek, V.; Fisher, Z.; Pham, P.; Ravula, A.; Sanghai, S.; Wang, Q.; Yang, L. ETC: Encoding long and structured inputs in transformers. arXiv 2020, arXiv:2004.08483. [Google Scholar]
- Zaheer, M.; Guruganesh, G.; Dubey, K.A.; Ainslie, J.; Alberti, C.; Ontanon, S.; Pham, P.; Ravula, A.; Wang, Q.; Yang, L.; et al. Big bird: Transformers for longer sequences. Adv. Neural Inf. Process. Syst. 2020, 33, 17283–17297. [Google Scholar]
- Katharopoulos, A.; Vyas, A.; Pappas, N.; Fleuret, F. Transformers are rnns: Fast autoregressive transformers with linear attention. In Proceedings of the International Conference on Machine Learning, PMLR, Vienna, Austria, 12–18 July 2020; pp. 5156–5165. [Google Scholar]
- Beltagy, I.; Peters, M.E.; Cohan, A. Longformer: The long-document transformer. arXiv 2020, arXiv:2004.05150. [Google Scholar]
- Burnett, R.A.; Si, D. Prediction of injuries and fatalities in aviation accidents through machine learning. In Proceedings of the International Conference on Compute and Data Analysis, Lakeland, FL, USA, 19–23 May 2017; pp. 60–68. [Google Scholar]
- Nanyonga, A.; Wasswa, H.; Turhan, U.; Molloy, O.; Wild, G. Sequential Classification of Aviation Safety Occurrences with Natural Language Processing. In Proceedings of the AIAA AVIATION 2023 Forum, San Diego, CA, USA, 12–16 June 2023; p. 4325. [Google Scholar]
- Nanyonga, A.; Joiner, K.; Turhan, U.; Wild, G. Applications of natural language processing in aviation safety: A review and qualitative analysis. In Proceedings of the AIAA SCITECH 2025 Forum, Orlando, FL, USA, 6–10 January 2025; p. 2153. [Google Scholar]
- Zhang, X.; Mahadevan, S. Ensemble machine learning models for aviation incident risk prediction. Decis. Support Syst. 2019, 116, 48–63. [Google Scholar]
- Zhang, X.; Mahadevan, S. Bayesian network modeling of accident investigation reports for aviation safety assessment. Reliab. Eng. Syst. Saf. 2021, 209, 107371. [Google Scholar]
- Valdés, R.M.A.; Comendador, V.F.G.; Sanz, L.P.; Sanz, A.R. Prediction of aircraft safety incidents using Bayesian inference and hierarchical structures. Saf. Sci. 2018, 104, 216–230. [Google Scholar]
- Nanyonga, A.; Wasswa, H.; Molloy, O.; Turhan, U.; Wild, G. Natural language processing and deep learning models to classify phase of flight in aviation safety occurrences. In Proceedings of the 2023 IEEE Region 10 Symposium (TENSYMP), Canberra, Australia, 6–8 September 2023; pp. 1–6. [Google Scholar]
- Nanyonga, A.; Wasswa, H.; Wild, G. Topic Modeling Analysis of Aviation Accident Reports: A Comparative Study between LDA and NMF Models. In Proceedings of the 2023 3rd International Conference on Smart Generation Computing, Communication and Networking (SMART GENCON), Bangalore, India, 29–31 December 2023; pp. 1–2. [Google Scholar]
- de Vries, V. Classification of aviation safety reports using machine learning. In Proceedings of the 2020 International Conference on Artificial Intelligence and Data Analytics for Air Transportation (AIDA-AT), Singapore, 3–4 February 2020; pp. 1–6. [Google Scholar]
- Buselli, I.; Oneto, L.; Dambra, C.; Gallego, C.V.; Martínez, M.G.; Smoker, A.; Martino, P.R. Natural Language Processing and Data-Driven Methods for Aviation Safety and Resilience: From Extant Knowledge to Potential Precursors. Open Research Europe. 2021. Available online: https://www.sesarju.eu/sites/default/files/documents/sid/2021/papers/SIDs_2021_paper_50.pdf (accessed on 24 March 2025).
- Tanguy, L.; Tulechki, N.; Urieli, A.; Hermann, E.; Raynal, C. Natural language processing for aviation safety reports: From classification to interactive analysis. Comput. Ind. 2016, 78, 80–95. [Google Scholar]
- Nanyonga, A.; Wasswa, H.; Joiner, K.; Turhan, U.; Wild, G. Explainable Supervised Learning Models for Aviation Predictions in Australia. Aerospace 2025, 12, 223. [Google Scholar] [CrossRef]
- Perboli, G.; Gajetti, M.; Fedorov, S.; Giudice, S.L. Natural Language Processing for the identification of Human factors in aviation accidents causes: An application to the SHEL methodology. Expert Syst. Appl. 2021, 186, 115694. [Google Scholar]
- Shen, N.; Gao, K.; Niu, T.; Li, Q.; Peng, R. Aero-Engine Life Prediction Based on ARIMA and LSTM with Multi-head Attention Mechanism. In Analytics Modeling in Reliability and Machine Learning and Its Applications; Springer: Berlin/Heidelberg, Germany, 2025; pp. 77–90. [Google Scholar]
- Li, Z.; Luo, S.; Liu, H.; Tang, C.; Miao, J. TTSNet: Transformer–Temporal Convolutional Network–Self-Attention with Feature Fusion for Prediction of Remaining Useful Life of Aircraft Engines. Sensors 2025, 25, 432. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Tang, Z.; Wei, J. Multi-Layer Perceptron Model Integrating Multi-Head Attention and Gating Mechanism for Global Navigation Satellite System Positioning Error Estimation. Remote Sens. 2025, 17, 301. [Google Scholar] [CrossRef]
- Cai, H.; Shao, X.; Zhou, P.; Li, H. Multi-Label Classification of Complaint Texts: Civil Aviation Service Quality Case Study. Electronics 2025, 14, 434. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Wang, Q.; Li, B.; Xiao, T.; Zhu, J.; Li, C.; Wong, D.F.; Chao, L.S. Learning deep transformer models for machine translation. arXiv 2019, arXiv:1906.01787. [Google Scholar]
- Yao, S.; Wan, X. Multimodal transformer for multimodal machine translation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 4346–4350. [Google Scholar]
- Raganato, A.; Tiedemann, J. An analysis of encoder representations in transformer-based machine translation. In Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, Brussels, Belgium, 1 November 2018; pp. 287–297. [Google Scholar]
- Khandelwal, U.; Clark, K.; Jurafsky, D.; Kaiser, L. Sample efficient text summarization using a single pre-trained transformer. arXiv 2019, arXiv:1905.08836. [Google Scholar]
- Liu, Y.; Lapata, M. Text summarization with pretrained encoders. arXiv 2019, arXiv:1908.08345. [Google Scholar]
- Sheang, K.C.; Saggion, H. Controllable sentence simplification with a unified text-to-text transfer transformer. In Proceedings of the 14th International Conference on Natural Language Generation (INLG), Aberdeen, UK, 20–24 September 2021; ACL (Association for Computational Linguistics): Aberdeen, UK, 2021. [Google Scholar]
- Alissa, S.; Wald, M. Text simplification using transformer and BERT. Comput. Mater. Contin. 2023, 75, 3479–3495. [Google Scholar]
- Alikaniotis, D.; Raheja, V. The unreasonable effectiveness of transformer language models in grammatical error correction. arXiv 2019, arXiv:1906.01733. [Google Scholar]
- Hossain, N.; Bijoy, M.H.; Islam, S.; Shatabda, S. Panini: A transformer-based grammatical error correction method for Bangla. Neural Comput. Appl. 2024, 36, 3463–3477. [Google Scholar]
- Shao, T.; Guo, Y.; Chen, H.; Hao, Z. Transformer-based neural network for answer selection in question answering. IEEE Access 2019, 7, 26146–26156. [Google Scholar]
- Cordonnier, J.B.; Loukas, A.; Jaggi, M. Multi-head attention: Collaborate instead of concatenate. arXiv 2020, arXiv:2006.16362. [Google Scholar]
- Zhang, X.; Shen, Y.; Huang, Z.; Zhou, J.; Rong, W.; Xiong, Z. Mixture of attention heads: Selecting attention heads per token. arXiv 2022, arXiv:2210.05144. [Google Scholar]
- Michel, P.; Levy, O.; Neubig, G. Are sixteen heads really better than one? In Proceedings of the 33rd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Liu, B.; Zheng, Q.; Wei, H.; Zhao, J.; Yu, H.; Zhou, Y.; Chao, F.; Ji, R. Deep hybrid transformer network for robust modulation classification in wireless communications. Knowl.-Based Syst. 2024, 300, 112191. [Google Scholar]
- Kedia, A.; Zaidi, M.A.; Khyalia, S.; Jung, J.; Goka, H.; Lee, H. Transformers get stable: An end-to-end signal propagation theory for language models. arXiv 2024, arXiv:2403.09635. [Google Scholar]
- Muraina, I. Ideal dataset splitting ratios in machine learning algorithms: General concerns for data scientists and data analysts. In Proceedings of the 7th International Mardin Artuklu Scientific Research Conference, Mardin, Turkey, 10–12 December 2021; pp. 496–504. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Park, C.; Yang, Y.; Lee, C.; Lim, H. Comparison of the evaluation metrics for neural grammatical error correction with overcorrection. IEEE Access 2020, 8, 106264–106272. [Google Scholar] [CrossRef]
- Min, J.H.; Jung, S.J.; Jung, S.H.; Yang, S.; Cho, J.S.; Kim, S.H. Grammatical error correction models for Korean language via pre-trained denoising. Quant. Bio-Sci. 2020, 39, 17–24. [Google Scholar]
- Yadav, A.K.; Singh, A.; Dhiman, M.; Vineet; Kaundal, R.; Verma, A.; Yadav, D. Extractive text summarization using deep learning approach. Int. J. Inf. Technol. 2022, 14, 2407–2415. [Google Scholar]
- Manojkumar, V.; Mathi, S.; Gao, X.Z. An experimental investigation on unsupervised text summarization for customer reviews. Procedia Comput. Sci. 2023, 218, 1692–1701. [Google Scholar]
- Van den Bercken, L.; Sips, R.J.; Lofi, C. Evaluating neural text simplification in the medical domain. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 3286–3292. [Google Scholar]
- Lin, C.Y. Rouge: A package for automatic evaluation of summaries. In Proceedings of the Text Summarization Branches Out, Barcelona, Spain, 25–26 July 2004; pp. 74–81. [Google Scholar]
- Kryściński, W.; Paulus, R.; Xiong, C.; Socher, R. Improving abstraction in text summarization. arXiv 2018, arXiv:1808.07913. [Google Scholar]
- Jain, M.; Saha, S.; Bhattacharyya, P.; Chinnadurai, G.; Vatsa, M.K. Natural Answer Generation: From Factoid Answer to Full-length Answer using Grammar Correction. arXiv 2021, arXiv:2112.03849. [Google Scholar]
- Ng, J.P.; Abrecht, V. Better summarization evaluation with word embeddings for ROUGE. arXiv 2015, arXiv:1508.06034. [Google Scholar]
- Dorr, B.; Monz, C.; Schwartz, R.; Zajic, D. A methodology for extrinsic evaluation of text summarization: Does ROUGE correlate? In Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, Ann Arbor, MI, USA, 29 June 2005; pp. 1–8. [Google Scholar]
- Barbella, M.; Tortora, G. Rouge Metric Evaluation for Text Summarization Techniques. 2022. Available online: https://ssrn.com/abstract=4120317 (accessed on 26 May 2022).
- Huang, J.; Jiang, Y. A DAE-based Approach for Improving the Grammaticality of Summaries. In Proceedings of the 2021 International Conference on Computers and Automation (CompAuto), Paris, France, 7–9 September 2021; pp. 50–53. [Google Scholar]
- Banerjee, S.; Kumar, N.; Madhavan, C.V. Text Simplification for Enhanced Readability. In Proceedings of the KDIR/KMIS, Vilamoura, Portugal, 19–22 September 2013; pp. 202–207. [Google Scholar]
- Zaman, F.; Shardlow, M.; Hassan, S.U.; Aljohani, N.R.; Nawaz, R. HTSS: A novel hybrid text summarisation and simplification architecture. Inf. Process. Manag. 2020, 57, 102351. [Google Scholar]
- Phatak, A.; Savage, D.W.; Ohle, R.; Smith, J.; Mago, V. Medical text simplification using reinforcement learning (teslea): Deep learning–based text simplification approach. JMIR Med. Inform. 2022, 10, e38095. [Google Scholar]
- Landauer, T.K.; Foltz, P.W.; Laham, D. An introduction to latent semantic analysis. Discourse Process. 1998, 25, 259–284. [Google Scholar]
- Landauer, T.K.; Dumais, S.T. A solution to Plato’s problem: The latent semantic analysis theory of acquisition, induction, and representation of knowledge. Psychol. Rev. 1997, 104, 211–240. [Google Scholar] [CrossRef]
- Steinberger, J.; Jezek, K. Using latent semantic analysis in text summarization and summary evaluation. Proc. ISIM 2004, 4, 8. [Google Scholar]
- Ozsoy, M.G.; Alpaslan, F.N.; Cicekli, I. Text summarization using latent semantic analysis. J. Inf. Sci. 2011, 37, 405–417. [Google Scholar]
- Gong, Y.; Liu, X. Generic text summarization using relevance measure and latent semantic analysis. In Proceedings of the 24th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, New Orleans, LA, USA, 9–13 September 2001; pp. 19–25. [Google Scholar]
- Hao, S.; Xu, Y.; Ke, D.; Su, K.; Peng, H. SCESS: A WFSA-based automated simplified chinese essay scoring system with incremental latent semantic analysis. Nat. Lang. Eng. 2016, 22, 291–319. [Google Scholar] [CrossRef]
- Vajjala, S.; Meurers, D. Readability assessment for text simplification: From analysing documents to identifying sentential simplifications. ITL-Int. J. Appl. Linguist. 2014, 165, 194–222. [Google Scholar]
- Salton, G.; Buckley, C. Term-weighting approaches in automatic text retrieval. Inf. Process. Manag. 1988, 24, 513–523. [Google Scholar] [CrossRef]
- Zhang, T.; Kishore, V.; Wu, F.; Weinberger, K.Q.; Artzi, Y. Bertscore: Evaluating text generation with bert. arXiv 2019, arXiv:1904.09675. [Google Scholar]
- Cer, D.; Yang, Y.; Kong, S.Y.; Hua, N.; Limtiaco, N.; John, R.S.; Constant, N.; Guajardo-Cespedes, M.; Yuan, S.; Tar, C.; et al. Universal sentence encoder for English. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Brussels, Belgium, 4 November 2018; pp. 169–174. [Google Scholar]
- Nanyonga, A.; Wild, G. Impact of Dataset Size & Data Source on Aviation Safety Incident Prediction Models with Natural Language Processing. In Proceedings of the 2023 Global Conference on Information Technologies and Communications (GCITC), Bengaluru, India, 14–16 December 2023; pp. 1–7. [Google Scholar]
- Darveau, K.; Hannon, D.; Foster, C. A comparison of rule-based and machine learning models for classification of human factors aviation safety event reports. In Proceedings of the Human Factors and Ergonomics Society Annual Meeting, Online, 5–9 October 2020; SAGE Publications Sage: Los Angeles, CA, USA, 2020; Volume 64, pp. 129–133. [Google Scholar]
- Zhao, X.; Yan, H.; Liu, Y. Hierarchical Multilabel Classification for Fine-Level Event Extraction from Aviation Accident Reports. INFORMS J. Data Sci. 2024, 4, 1–99. [Google Scholar] [CrossRef]
- Xiong, S.H.; Wei, X.H.; Chen, Z.S.; Zhang, H.; Pedrycz, W.; Skibniewski, M.J. Identifying causes of aviation safety events using wW2V-tCNN with data augmentation. Int. J. Gen. Syst. 2025, 1–30. [Google Scholar] [CrossRef]
- Hou, Z.; Wang, H.; Yue, Y.; Xiong, M.; Che, C. A novel method for cause portrait of aviation unsafe events based on hierarchical multi-task convolutional neural network. Expert Syst. Appl. 2025, 270, 126466. [Google Scholar] [CrossRef]
- Ni, X.; Wang, H.; Chen, L.; Lin, R. Classification of aviation incident causes using LGBM with improved cross-validation. J. Syst. Eng. Electron. 2024, 35, 396–405. [Google Scholar] [CrossRef]
- Xiong, M.; Hou, Z.; Wang, H.; Che, C.; Luo, R. An aviation accidents prediction method based on MTCNN and Bayesian optimization. Knowl. Inf. Syst. 2024, 66, 6079–6100. [Google Scholar] [CrossRef]
- Liu, H.; Hu, M.; Yang, L. A new risk level identification model for aviation safety. Eng. Appl. Artif. Intell. 2024, 136, 108901. [Google Scholar] [CrossRef]
- Aizawa, A. An information-theoretic perspective of tf–idf measures. Inf. Process. Manag. 2003, 39, 45–65. [Google Scholar] [CrossRef]
- Xiong, M.; Wang, H.; Wong, Y.D.; Hou, Z. Enhancing aviation safety and mitigating accidents: A study on aviation safety hazard identification. Adv. Eng. Inform. 2024, 62, 102732. [Google Scholar] [CrossRef]
- Katragadda, S.R.; Tanikonda, A.; Pandey, B.K.; Peddinti, S.R. Machine Learning-Enhanced Root Cause Analysis for Rapid Incident Management in High-Complexity Systems. J. Sci. Technol. 2022, 3, 325–345. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metric | Precision | Recall | F-Measure | |||
|---|---|---|---|---|---|---|
| Mean | Stddev | Mean | Stddev | Mean | Stddev | |
| rouge-1 | 0.666 | 0.217 | 0.610 | 0.211 | 0.618 | 0.192 |
| rouge-2 | 0.488 | 0.264 | 0.448 | 0.257 | 0.452 | 0.248 |
| rouge-L | 0.602 | 0.241 | 0.553 | 0.235 | 0.560 | 0.220 |
| Weight Vector | BLEU Score |
|---|---|
| 0.459 | |
| 0.732 | |
| 0.969 |
| Authors | NTSB Dataset | NLP | Transformer-Based Approach | BERT Score | ROUGE Score | BLEU Score | LSA Similarity |
|---|---|---|---|---|---|---|---|
| Nanyonga et al. [83] | Y | Y | N | N | N | N | N |
| Darveau et al. [84] | N | Y | N | N | N | N | N |
| Zhao et al. [85] | Y | Y | N | N | N | N | N |
| Xiong et al. [86] | N | Y | N | N | N | N | N |
| Hou et al. [87] | N | N | N | N | N | N | N |
| Ni et al. [88] | N | N | N | N | N | N | N |
| Xiong et al. [89] | Y | N | N | N | N | N | N |
| Liu et al. [90] | Y | N | N | N | N | N | N |
| Akiko Aizawa [91] | N | N | N | N | N | N | N |
| Xiong et al. [92] | N | N | N | N | N | N | N |
| Perboli et al. [35] | N | Y | N | N | N | N | N |
| Katragadda et al. [93] | N | Y | N | N | N | N | N |
| Dong et al. [4] | N | Y | N | N | N | N | N |
| Our study | Y | Y | Y | Y | Y | Y | Y |
| Observed “probableCause” | Predicted “probableCause” |
|---|---|
| The pilot’s inadequate compensation for the crosswind condition and failure to maintain directional control of the aircraft on landing. | The pilot’s failure to maintain directional control during landing. |
| The incapacitation of the pilot during high-altitude cruise flight for undetermined reasons. | The pilot’s intentional flight into terrain as a result of his impairment due to alcohol consumption. |
| The pilot’s failure to monitor the balloon’s altitude, which resulted in the balloon impacting an airport rotating beacon tower. | The pilot’s failure to maintain clearance from a powerline during landing. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nanyonga, A.; Wasswa, H.; Joiner, K.; Turhan, U.; Wild, G. A Multi-Head Attention-Based Transformer Model for Predicting Causes in Aviation Incidents. Modelling 2025, 6, 27. https://doi.org/10.3390/modelling6020027
Nanyonga A, Wasswa H, Joiner K, Turhan U, Wild G. A Multi-Head Attention-Based Transformer Model for Predicting Causes in Aviation Incidents. Modelling. 2025; 6(2):27. https://doi.org/10.3390/modelling6020027
Chicago/Turabian StyleNanyonga, Aziida, Hassan Wasswa, Keith Joiner, Ugur Turhan, and Graham Wild. 2025. "A Multi-Head Attention-Based Transformer Model for Predicting Causes in Aviation Incidents" Modelling 6, no. 2: 27. https://doi.org/10.3390/modelling6020027
APA StyleNanyonga, A., Wasswa, H., Joiner, K., Turhan, U., & Wild, G. (2025). A Multi-Head Attention-Based Transformer Model for Predicting Causes in Aviation Incidents. Modelling, 6(2), 27. https://doi.org/10.3390/modelling6020027