
Intent Identification by Semantically Analyzing the Search Query

 , , , and
, , , and
Abstract
1. Introduction
- We introduce spatial and temporal parsing, phrase detection, and semantic similarity recognition for semantic analysis and recognition to identify the intent of the user’s search query.
- We propose a probability-aware gated mechanism with a pre-trained RoBERTa model, which enhances the proposed system’s ability to discern nuanced intents through effective attention mechanisms.
- We incorporate adaptive training with Gensim to support continuous learning and refinement and ensure adaptability to evolving language patterns over time.
- Extensive experimental analyses on benchmark datasets demonstrate the superior performance of our proposed system compared to state-of-the-art systems.
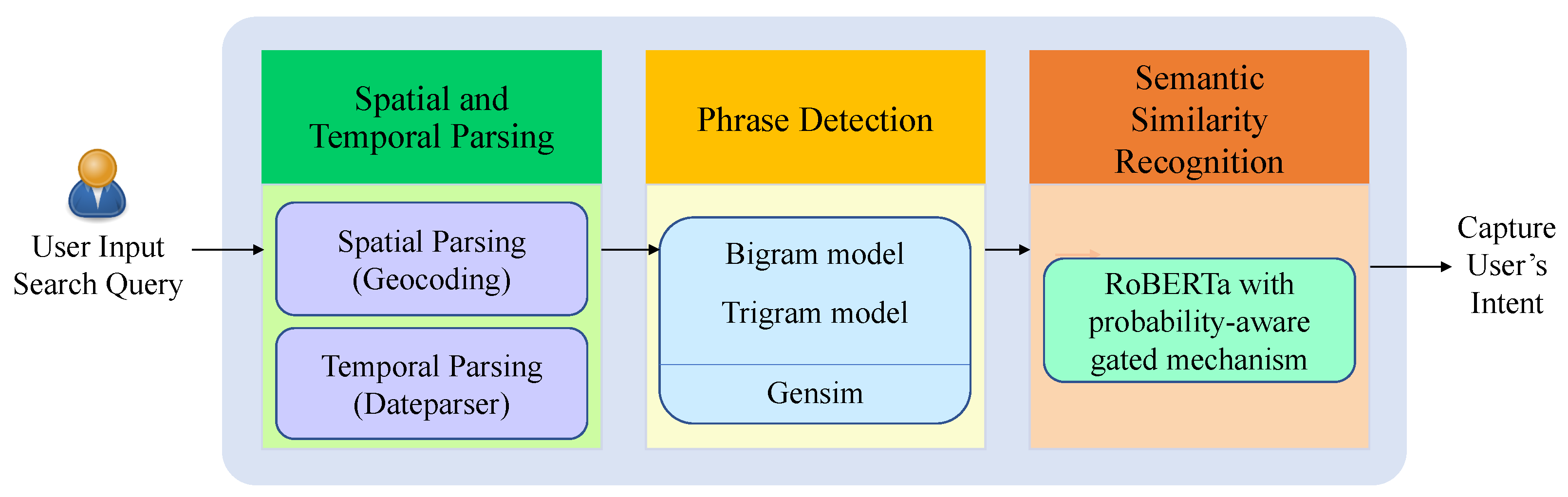
2. Materials and Methods
2.1. Spatial and Temporal Parsing
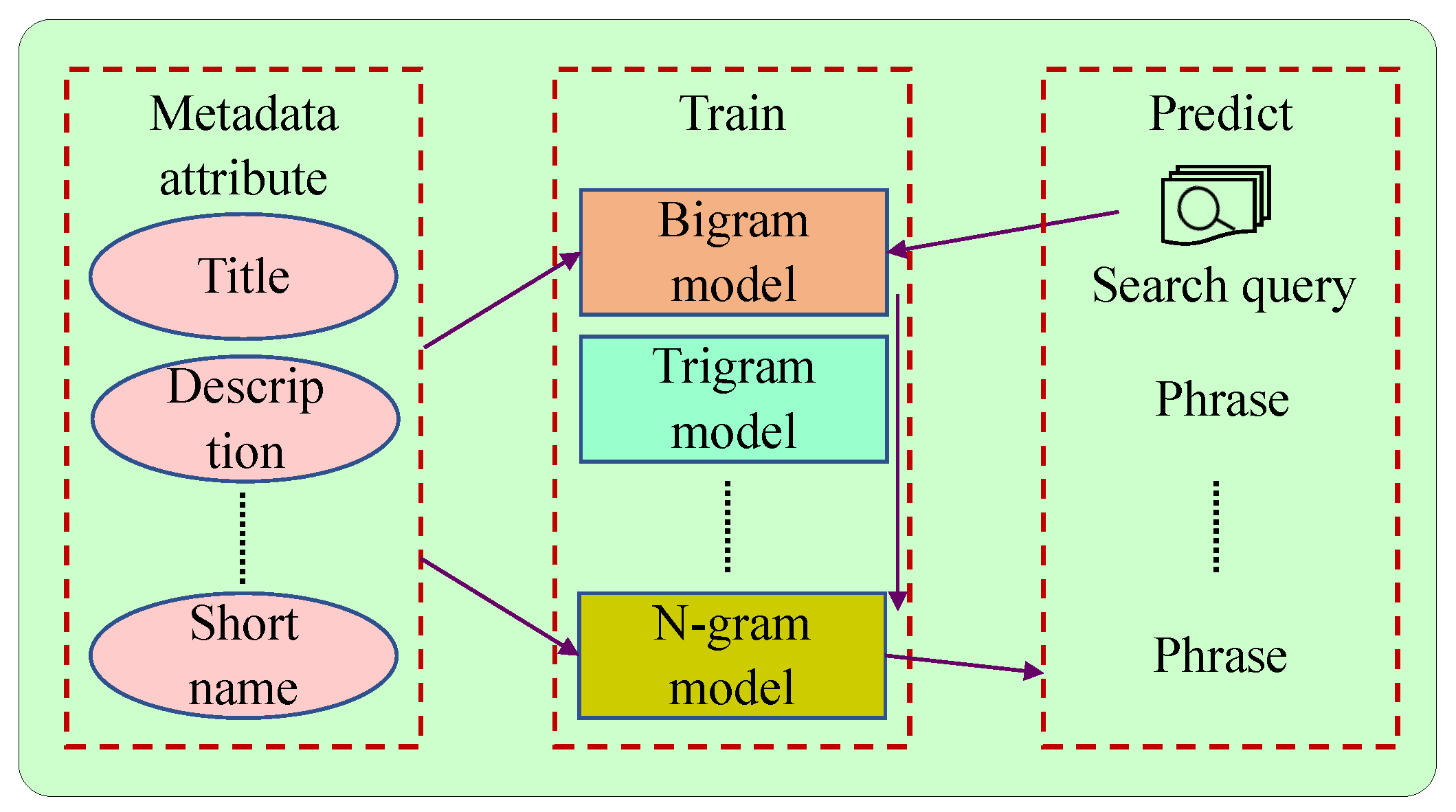
2.2. Phrase Detection
2.3. Semantic Similarity Recognition
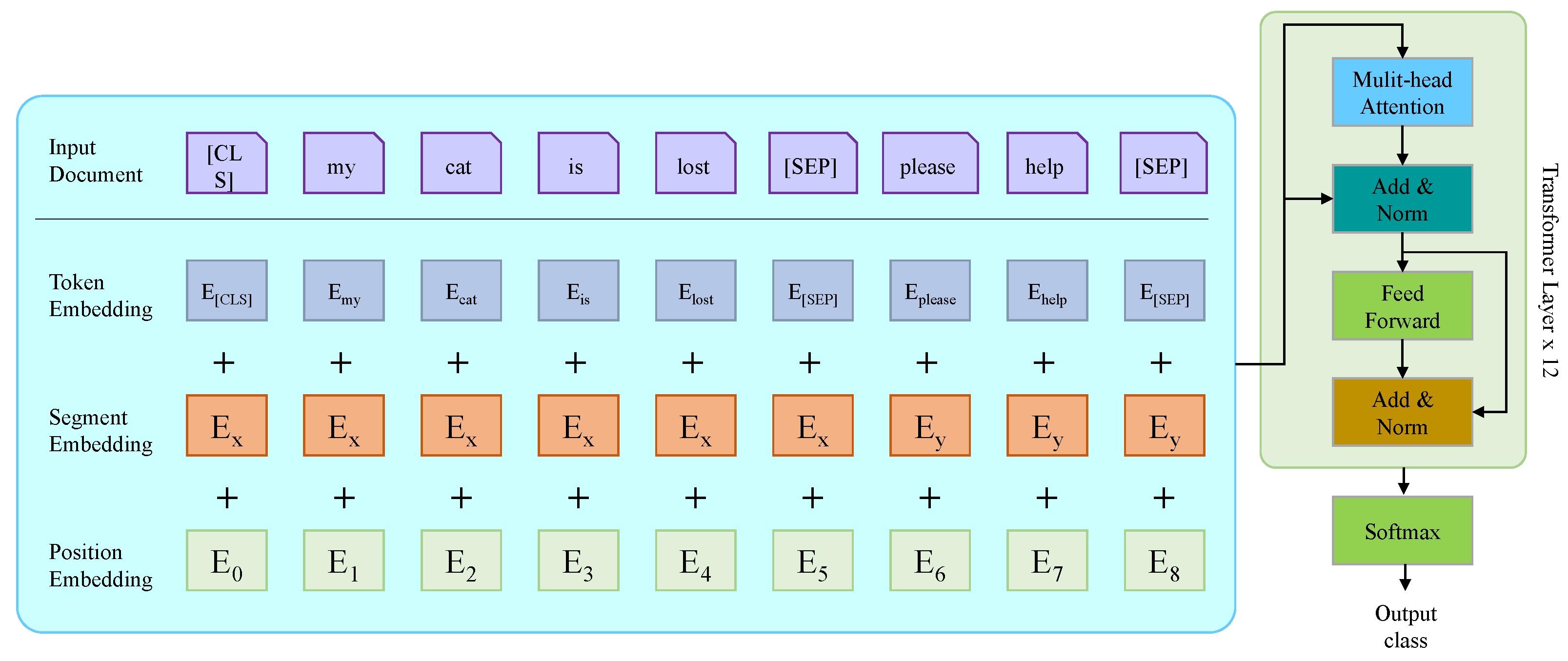
2.3.1. RoBERTa
2.3.2. Probability-Aware Gated Mechanism for RoBERTa Embeddings Refinement
Gating Function
Gated Semantic Embeddings
Intent Classification with Gated Embeddings
Training Objective
Model Training
Inference
| Algorithm 1 RoBERTa with Probability-Aware Gated Mechanism for Intent Identification | |
| Input: User query Q, RoBERTa model parameters , Gating mechanism parameters | |
| Output: Predicted intent label | |
| 1: | Load pre-trained RoBERTa model with parameters |
| 2: | Initialize gating mechanism parameters |
| 3: | Freeze parameters of the RoBERTa model during fine-tuning |
| 4: | procedure Fine-tuneModel |
| 5: | for each epoch do |
| 6: | for each batch B in training data do |
| 7: | Compute RoBERTa embeddings: |
| 8: | Compute gating probabilities: |
| 9: | Compute gated embeddings: |
| 10: | Compute intent logits: |
| 11: | Compute intent probabilities: |
| 12: | Compute intent classification loss: |
| 13: | Compute gating loss: |
| 14: | Compute overall loss: |
| 15: | Update parameters using backpropagation and SGD |
| 16: | end for |
| 17: | end for |
| 18: | end procedure |
3. Results and Discussion
3.1. Dataset
3.2. Baselines
- CAPSULE-NLU: The CAPSULE-NLU model, which was suggested by Zhang et al. [37], makes use of a neural network that is built on capsules and a method that uses dynamic routing-by-agreement to identify hierarchical links between words, intent, and slots.
- SF-ID Network: The SF-ID network, which was first proposed by E et al. [38], is intended to represent two-way relationships between intent detection and slot filling. It has two modes, ID-First and SF-First, with different starting orders.
- Stack-Propagation: Qin et al. [39] use Stack-Propagation to tackle intent detection problems by classifying intent at the token level. Intent information can be used to guide slot-filling operations in the Stack-Propagation architecture.
- Graph LSTM: Graph LSTM is introduced by Zhang et al. [40] to improve upon Slot Labeling Units (SLU) and circumvent the drawbacks of recurrent neural networks (RNNs).
- BERT-Joint: The BERT-Joint method was developed by Chen et al. [41] with the aim of improving performance in the joint tasks of intent detection and slot filling by utilizing BERT’s contextual awareness.
- Joint Sequence: Chen et al. [42] has proposed a novel model for multi-intent NLU called SelfDistillation Joint NLU (SDJN).
- Capsule Neural Network: Abro et al. [43] introduces the WFST-BERT model, which integrates weighted finite-state transducer (WFST) into the fine-tuning of a BERT-like architecture to mitigate the requirement for large quantities of supervised data.
- GE-BERT: Li et al. [44] addresses the challenge of query understanding by proposing GE-BERT, a novel graph-enhanced pre-training framework that leverages both query content and the query graph to capture semantic information and users’ search behavioral information, demonstrating its effectiveness through extensive experiments on offline and online tasks.
- Joint BiLSTM-CRF: Rizou et al. [45] focuses on developing an efficient multilingual conversational agent for university students, supporting both Greek and English, using a joint BiLSTM-CRF model for intent extraction and named entity recognition, achieving competitive performance in customer service tasks and introducing the UniWay dataset, demonstrating the effectiveness of a unified approach in handling multiple natural language understanding tasks in closed domains.
3.3. Experimental Setup
3.4. Experimental Analysis
3.4.1. Performance Metrics
F1-Score
Intent Accuracy
Precision
Recall
McNemar Test
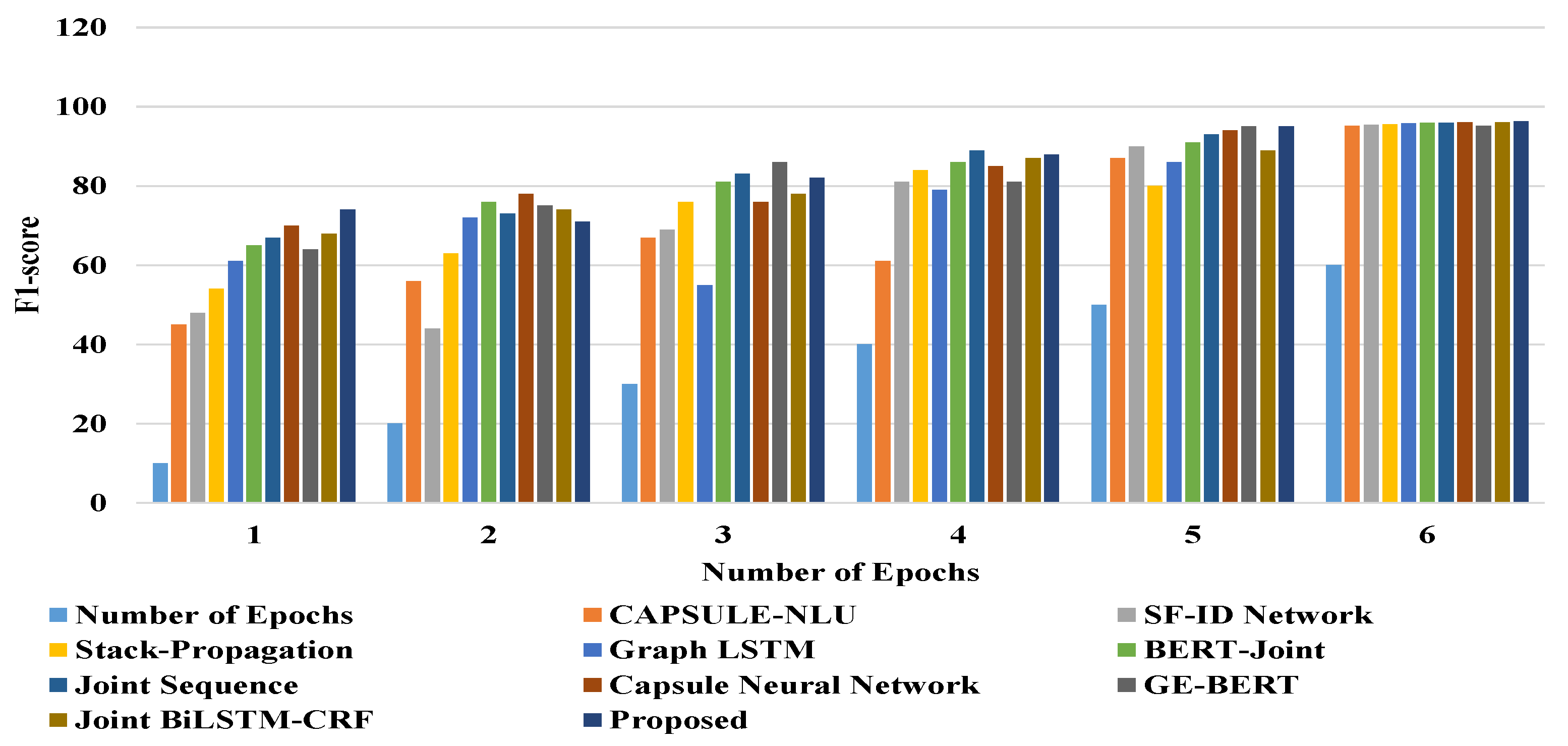
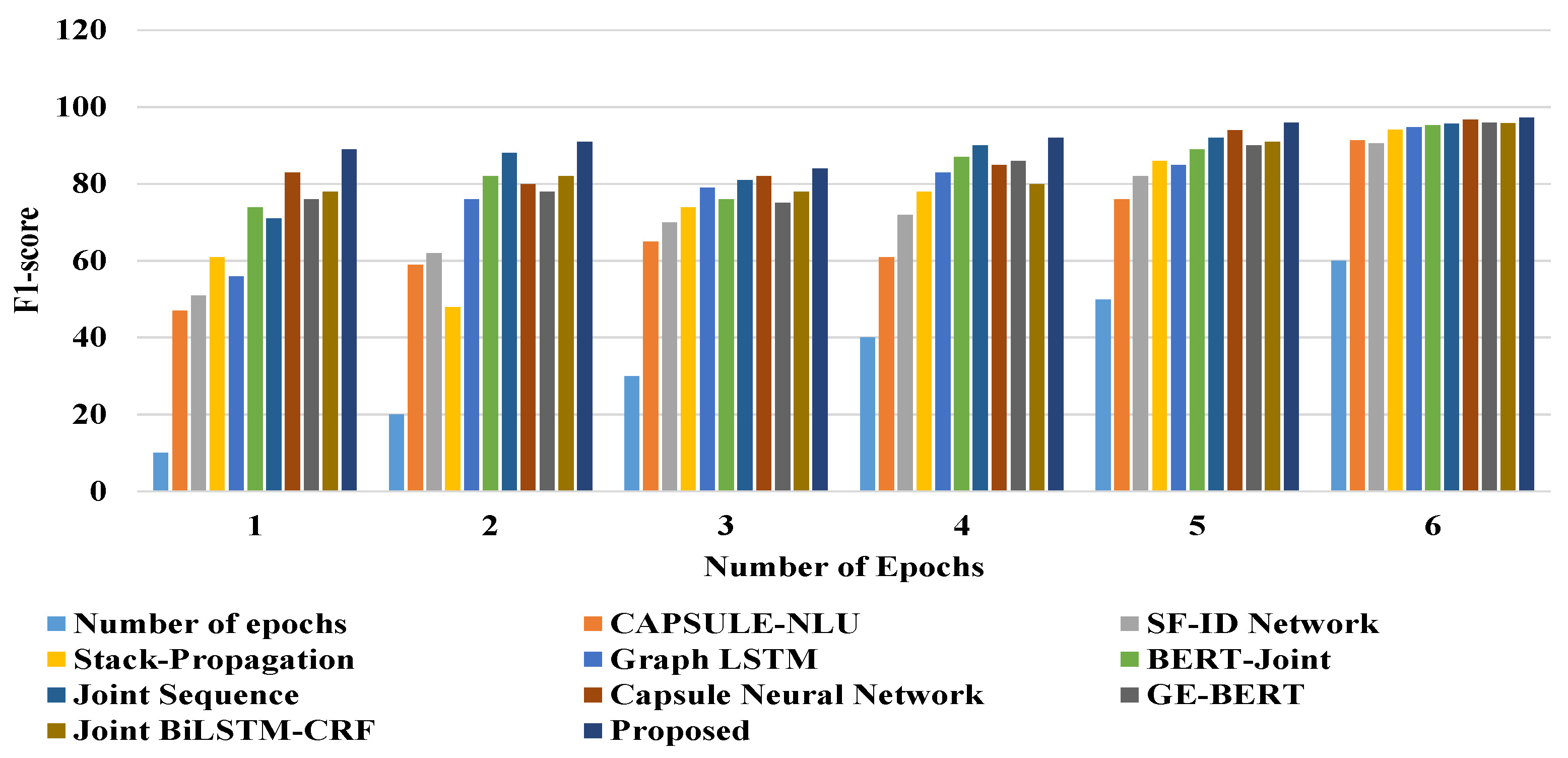
3.4.2. Experimental Results
- “Capsule Neural Network” correct: a = 97.61.
- “Capsule Neural Network” incorrect: b = 100 − a = 2.39.
- “Proposed” correct: c = 97.89.
- “Proposed” incorrect: d = 100 − c = 2.11.
3.4.3. Case Study
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Cheung, J.C.K.; Li, X. Sequence clustering and labeling for unsupervised query intent discovery. In Proceedings of the Fifth ACM International Conference on Web Search and Data Mining, Seattle, WA, USA, 8–12 February 2012; pp. 383–392. [Google Scholar]
- Hu, J.; Wang, G.; Lochovsky, F.; Sun, J.T.; Chen, Z. Understanding user’s query intent with Wikipedia. In Proceedings of the 18th International Conference on World Wide Web, Madrid, Spain, 20–24 April 2009; pp. 471–480. [Google Scholar]
- Shneiderman, B.; Byrd, D.; Croft, W.B. Clarifying Search: A User-Interface Framework for Text Searches. D-Lib Magazine. 1997. Available online: https://dl.acm.org/doi/abs/10.5555/865578 (accessed on 21 February 2024).
- Broder, A. A taxonomy of web search. In ACM Sigir Forum; ACM: New York, NY, USA, 2002; Volume 36, pp. 3–10. [Google Scholar]
- Cao, H.; Hu, D.H.; Shen, D.; Jiang, D.; Sun, J.T.; Chen, E.; Yang, Q. Context-aware query classification. In Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Boston, MA, USA, 19–23 July 2009; pp. 3–10. [Google Scholar]
- Beeferman, D.; Berger, A. Agglomerative clustering of a search engine query log. In Proceedings of the Sixth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Boston, MA, USA, 20–23 August 2000; pp. 407–416. [Google Scholar]
- Hong, Y.; Vaidya, J.; Lu, H.; Liu, W.M. Accurate and efficient query clustering via top ranked search results. Web Intell. 2016, 14, 119–138. [Google Scholar] [CrossRef]
- Wen, J.R.; Nie, J.Y.; Zhang, H.J. Query clustering using user logs. ACM Trans. Inf. Syst. 2002, 20, 59–81. [Google Scholar]
- Soto, A.J.; Przybyła, P.; Ananiadou, S. Thalia: Semantic search engine for biomedical abstracts. Bioinformatics 2019, 35, 1799–1801. [Google Scholar] [CrossRef] [PubMed]
- Kostakos, P. Strings and things: A semantic search engine for news quotes using named entity recognition. In Proceedings of the 2020 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), The Hague, The Netherlands, 7–10 December 2020; pp. 835–839. [Google Scholar]
- Ayazbayev, D.; Bogdanchikov, A.; Orynbekova, K.; Varlamis, I. Defining Semantically Close Words of Kazakh Language with Distributed System Apache Spark. Big Data Cogn. Comput. 2023, 7, 160. [Google Scholar] [CrossRef]
- Bouarroudj, W.; Boufaida, Z.; Bellatreche, L. Named entity disambiguation in short texts over knowledge graphs. Knowl. Inf. Syst. 2022, 64, 325–351. [Google Scholar] [CrossRef] [PubMed]
- Cowan, B.; Zethelius, S.; Luk, B.; Baras, T.; Ukarde, P.; Zhang, D. Named entity recognition in travel-related search queries. Proc. Aaai Conf. Artif. Intell. 2015, 29, 3935–3941. [Google Scholar] [CrossRef]
- Bernhard, S. GEOCODE3: Stata Module to Retrieve Coordinates or Addresses from Google Geocoding API Version 3. 2013. Available online: http://fmwww.bc.edu/repec/bocode/o/opencagegeo.pdf (accessed on 15 January 2024).
- DateParser. Dateparser—Python Parser for Human Readable Dates. 2020. Available online: https://dateparser.readthedocs.io/en/latest/ (accessed on 1 December 2023).
- PO.DAAC. PO.DAAC Web Portal Search Help Page. 2020. Available online: https://podaac.jpl.nasa.gov/DatasetSearchHelp (accessed on 1 December 2023).
- GeoNetwork. Portal Configuration. 2020. Available online: https://geonetwork-opensource.org/manuals/trunk/eng/users/administrator-guide/configuring-the-catalog/portal-configuration.html?highlight=search20syntax (accessed on 1 December 2023).
- Brown, B.F. Class-based n-gram models of natural language. Comput. Linguist. 1992, 18, 467–480. [Google Scholar]
- Clarkson, P.; Rosenfeld, R. Statistical language modeling using the CMU-Cambridge toolkit. In Proceedings of the Fifth European Conference on Speech Communication and Technology, Rhodes, Greece, 22–25 September 1997; pp. 22–25. [Google Scholar]
- Rehurek, R.; Sojka, P. Gensim–Python Framework for Vector Space Modelling; NLP Centre, Faculty of Informatics, Masaryk University: Brno, Czech Republic, 2011; Volume 3. [Google Scholar]
- Hollerit, B.; Kroll, M.; Strohmaier, M. Towards linking buyers and sellers: Detecting commercial intent on twitter. In Proceedings of the 22nd International Conference on World Wide Web; ACM: New York, NY, USA, 2013; pp. 629–632. [Google Scholar]
- Pandey, R.; Purohit, H.; Stabile, B.; Grant, A. Distributional semantics approach to detect intent in twitter conversations on sexual assaults. In Proceedings of the 2018 IEEE/WIC/ACM International Conference on Web Intelligence (WI), Santiago, Chile, 3–6 December 2018; pp. 270–277. [Google Scholar]
- Wang, J.; Cong, G.; Zhao, W.X.; Li, X. Mining user intents in twitter: A semi-supervised approach to inferring intent categories for tweets. In Proceedings of theTwenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; pp. 318–324. [Google Scholar]
- Peters, M.; Neumann, M.; Zettlemoyer, L.; Yih, W.-T. Dissecting contextual word embeddings: Architecture and representation. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing; Association for Computational Linguistics: Brussels, Belgium, 2018; pp. 1499–1509. [Google Scholar]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching word vectors with subword information. Trans. Assoc. Comput. Linguist. 2017, 5, 135–146. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the 26th International Conference on Neural Information Processing Systems; Curran Associates Inc.: Dutchess County, NY, USA, 2013; Volume 2, pp. 3111–3119. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Wang, A.; Pruksachatkun, Y.; Nangia, N.; Singh, A.; Michael, J.; Hill, F.; Levy, O.; Bowman, S. SuperGLUE: A stickier benchmark for general-purpose language understanding systems. Adv. Neural Inf. Process. Syst. 2019, 32, 3266–3280. [Google Scholar]
- Wang, A.; Singh, A.; Michael, J.; Hill, F.; Levy, O.; Bowman, S. GLUE: A multi-task benchmark and analysis platform for natural language understanding. In Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP; Association for Computational Linguistics: Brussels, Belgium, 2018; pp. 353–355. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. NAACLHLT 2019, 1, 2. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Briskilal, J.; Subalalitha, C.N. An ensemble model for classifying idioms and literal texts using BERT and RoBERTa. Inf. Process. Manag. 2022, 59, 102756. [Google Scholar] [CrossRef]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Chaudhari, S.; Mithal, V.; Polatkan, G.; Ramanath, R. An attentive survey of attention models. Acm Trans. Intell. Syst. Technol. (TIST) 2021, 12, 1–32. [Google Scholar] [CrossRef]
- Hemphill, C.T.; Godfrey, J.J.; Doddington, G.R. The ATIS spoken language systems pilot corpus. Hum. Lang. Technol. Conf. 1990, 1990, 24–27. [Google Scholar]
- Coucke, A. Snips voice platform: An embedded spoken language understanding system for private-by-design voice interfaces. arXiv 2018, arXiv:1805.10190. [Google Scholar]
- Zhang, C.; Li, Y.; Du, N.; Fan, W.; Yu, P.S. Joint slot filling and intent detection via capsule neural networks. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 5259–5267. [Google Scholar]
- Niu, P.; Chen, Z.; Song, M. A novel bi-directional interrelated model for joint intent detection and slot filling. Assoc. Comput. Linguist. 2019, 5467–5471. [Google Scholar] [CrossRef]
- Qin, L.; Che, W.; Li, Y.; Wen, H.; Liu, T. A stack-propagation framework with token-level intent detection for spoken language understanding. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP): System Demonstrations, Hong Kong, China, 3–7 November 2019; pp. 2078–2087. [Google Scholar]
- Zhang, L.; Ma, D.; Zhang, X.; Yan, X.; Wang, H. Graph LSTM with context-gated mechanism for spoken language understanding. AAAI Conf. Artif. Intell. 2020, 34, 9539–9546. [Google Scholar] [CrossRef]
- Chen, Q.; Zhuo, Z.; Wang, W. BERT for joint intent classification and slot filling. arXiv 2019, arXiv:1902.10909. [Google Scholar]
- Chen, L.; Zhou, P.; Zou, Y. Joint multiple intent detection and slot filling via self-distillation. In Proceedings of the ICASSP 2022–2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 7612–7616. [Google Scholar]
- Abro, W.A.; Qi, G.; Aamir, M.; Ali, Z. Joint intent detection and slot filling using weighted finite state transducer and BERT. Appl. Intell. 2022, 52, 17356–17370. [Google Scholar] [CrossRef]
- Li, J.; Zeng, W.; Cheng, S.; Ma, Y.; Tang, J.; Wang, S.; Yin, D. Graph enhanced BERT for query understanding. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, Taipei, Taiwan, 23–27 July 2023; pp. 3315–3319. [Google Scholar]
- Rizou, S.; Theofilatos, A.; Paflioti, A.; Pissari, E.; Varlamis, I.; Sarigiannidis, G.; Chatzisavvas, K.C. Efficient intent classification and entity recognition for university administrative services employing deep learning models. Intell. Syst. Appl. 2023, 19, 200247. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | ATIS | SNIPS |
|---|---|---|
| Train-Sentences | 4778 | 13,084 |
| Dev-Sentences | 500 | 700 |
| Test-Sentences | 893 | 700 |
| Intent | 21 | 7 |
| Slot | 126 | 72 |
| Vocabulary | 722 | 11,241 |
| Dataset | F1-Score | Intent Accuracy | Precision | Recall |
|---|---|---|---|---|
| ATIS | 0.9632 | 0.9789 | 0.8815 | 0.9561 |
| SNIPS | 0.9729 | 0.9886 | 0.9314 | 0.9438 |
| Model | ATIS | |||
|---|---|---|---|---|
| Intent Accuracy | F1-Score | Precision | Recall | |
| CAPSULE-NLU | 95.10 | 95.25 | 83.40 | 85.15 |
| SF-ID Network | 96.51 | 95.45 | 84.95 | 85.32 |
| Stack-Propagation | 96.85 | 95.62 | 85.10 | 88.01 |
| Graph LSTM | 97.01 | 95.86 | 85.96 | 88.91 |
| BERT-Joint | 97.45 | 95.91 | 86.20 | 91.18 |
| Joint Sequence | 97.52 | 95.98 | 86.89 | 93.26 |
| Capsule Neural Network | 97.61 | 96.05 | 87.65 | 93.86 |
| GE-BERT | 97.32 | 95.88 | 87.25 | 93.01 |
| Joint BiLSTM-CRF | 97.58 | 96.12 | 87.38 | 93.55 |
| Proposed | 97.89 * | 96.32 * | 88.15 * | 95.61 * |
| Model | SNIPS | |||
|---|---|---|---|---|
| Intent Accuracy | F1-Score | Precision | Recall | |
| CAPSULE-NLU | 97.02 | 91.37 | 80.46 | 87.09 |
| SF-ID Network | 97.12 | 90.50 | 78.14 | 87.67 |
| Stack-Propagation | 97.36 | 94.18 | 83.62 | 88.34 |
| Graph LSTM | 97.68 | 94.73 | 85.92 | 88.62 |
| BERT-Joint | 98.96 * | 95.26 | 88.19 | 89.03 |
| Joint Sequence | 98.04 | 95.63 | 90.03 | 89.97 |
| Capsule Neural Network | 98.31 | 96.71 | 91.71 | 91.75 |
| GE-BERT | 98.54 | 96.88 | 91.35 | 91.12 |
| Joint BiLSTM-CRF | 98.24 | 96.52 | 91.64 | 91.39 |
| Proposed | 98.86 | 97.29 * | 93.14 * | 94.38 * |
| Model | ATIS | |||
|---|---|---|---|---|
| Intent Accuracy | F1-Score | Precision | Recall | |
| RoBERTa + GRU | 97.21 | 95.13 | 87.52 | 94.30 |
| RoBERTa + LSTM | 97.34 | 95.64 | 87.68 | 94.89 |
| Stack-Propagation + RoBERTa | 97.67 | 96.04 | 88.03 | 95.23 |
| BERT-Joint + CRF | 96.98 | 95.47 | 87.57 | 94.51 |
| Proposed | 97.89 * | 96.32 * | 88.15 * | 95.61 * |
| Model | SNIPS | |||
|---|---|---|---|---|
| Intent Accuracy | F1-Score | Precision | Recall | |
| RoBERTa + GRU | 97.31 | 96.53 | 92.05 | 93.65 |
| RoBERTa + LSTM | 97.65 | 96.81 | 92.37 | 93.71 |
| Stack-Propagation + RoBERTa | 98.91 * | 96.97 | 92.94 | 94.12 |
| BERT-Joint + CRF | 97.55 | 96.46 | 92.59 | 93.58 |
| Proposed | 98.86 | 97.29 * | 93.14 * | 94.38 * |
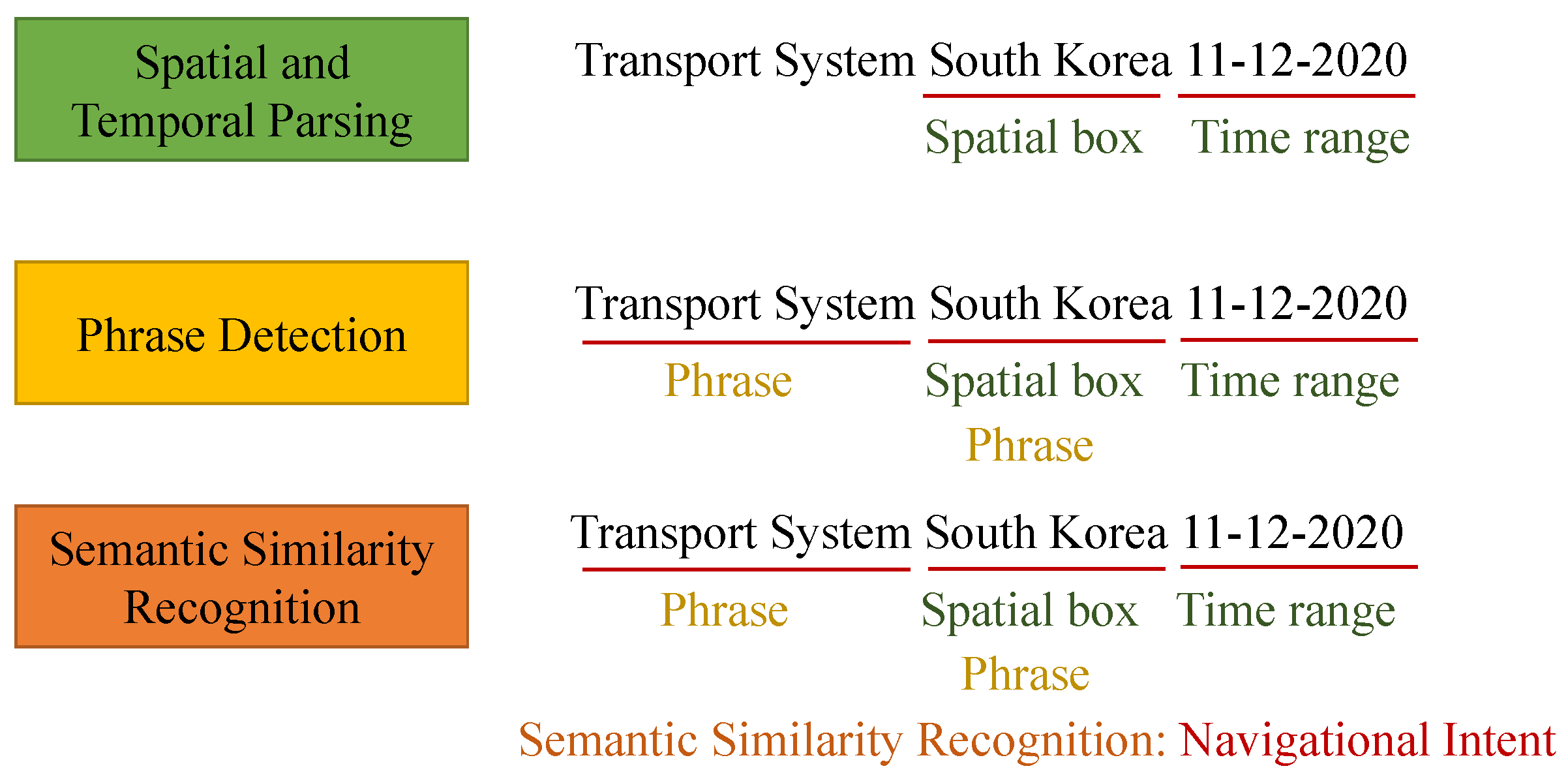
| Query No. | Query | Spatial and Temporal Parsing | Phrase Detection | Semantic Similarity Recognition (Intent) |
|---|---|---|---|---|
| 1 | Transport system South Korea 11 December 2020 | Spatial Parsing: 35.9078° N, 127.7669° E Temporal Parsing: 11 December 2020 | Phrases: Transport System, South Korea | Informational |
| 2 | Weather forecast my location | Spatial Parsing: 27.2046° N, 77.4977° E Temporal Parsing: 27 December 2020 21:26:21 | Phrases: my location | Navigational |
| 3 | UK vehicle licenses | Spatial Parsing: 55.3781° N, 3.4360° W | Phrases: vehicle licenses | Informational |
| 4 | Interest rate KEB HANA Bank | Spatial Parsing: 37°35′11.7″ N, 127°1′55.1″ E | Phrases: Interest rate, KEB HANA Bank | Transactional |
| 5 | Set living room temparture 23 degree celcius | Spatial Parsing: 25.62° N, 88.63° W Temporal Parsing: 7 January 2024 10:14:15 | Phrases: living room, degree celcius | SetTemparature |
| 6 | Get name location airports Dhaka | Spatial Parsing: 22.24° N, 91.81° E | Phrase: airports Dhaka | Navigational |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sultana, T.; Mandal, A.K.; Saha, H.; Sultan, M.N.; Hossain, M.D. Intent Identification by Semantically Analyzing the Search Query. Modelling 2024, 5, 292-314. https://doi.org/10.3390/modelling5010016
Sultana T, Mandal AK, Saha H, Sultan MN, Hossain MD. Intent Identification by Semantically Analyzing the Search Query. Modelling. 2024; 5(1):292-314. https://doi.org/10.3390/modelling5010016
Chicago/Turabian StyleSultana, Tangina, Ashis Kumar Mandal, Hasi Saha, Md. Nahid Sultan, and Md. Delowar Hossain. 2024. "Intent Identification by Semantically Analyzing the Search Query" Modelling 5, no. 1: 292-314. https://doi.org/10.3390/modelling5010016
APA StyleSultana, T., Mandal, A. K., Saha, H., Sultan, M. N., & Hossain, M. D. (2024). Intent Identification by Semantically Analyzing the Search Query. Modelling, 5(1), 292-314. https://doi.org/10.3390/modelling5010016