Application of Artificial Intelligence Algorithms to Estimate the Success Rate in Medically Assisted Procreation


 ,
, 

Abstract
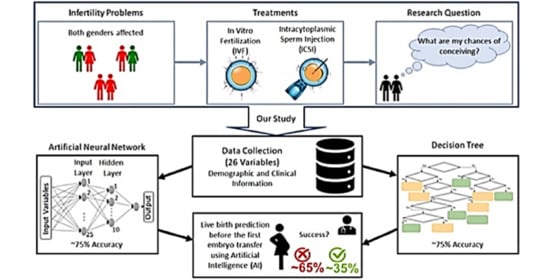
1. Introduction
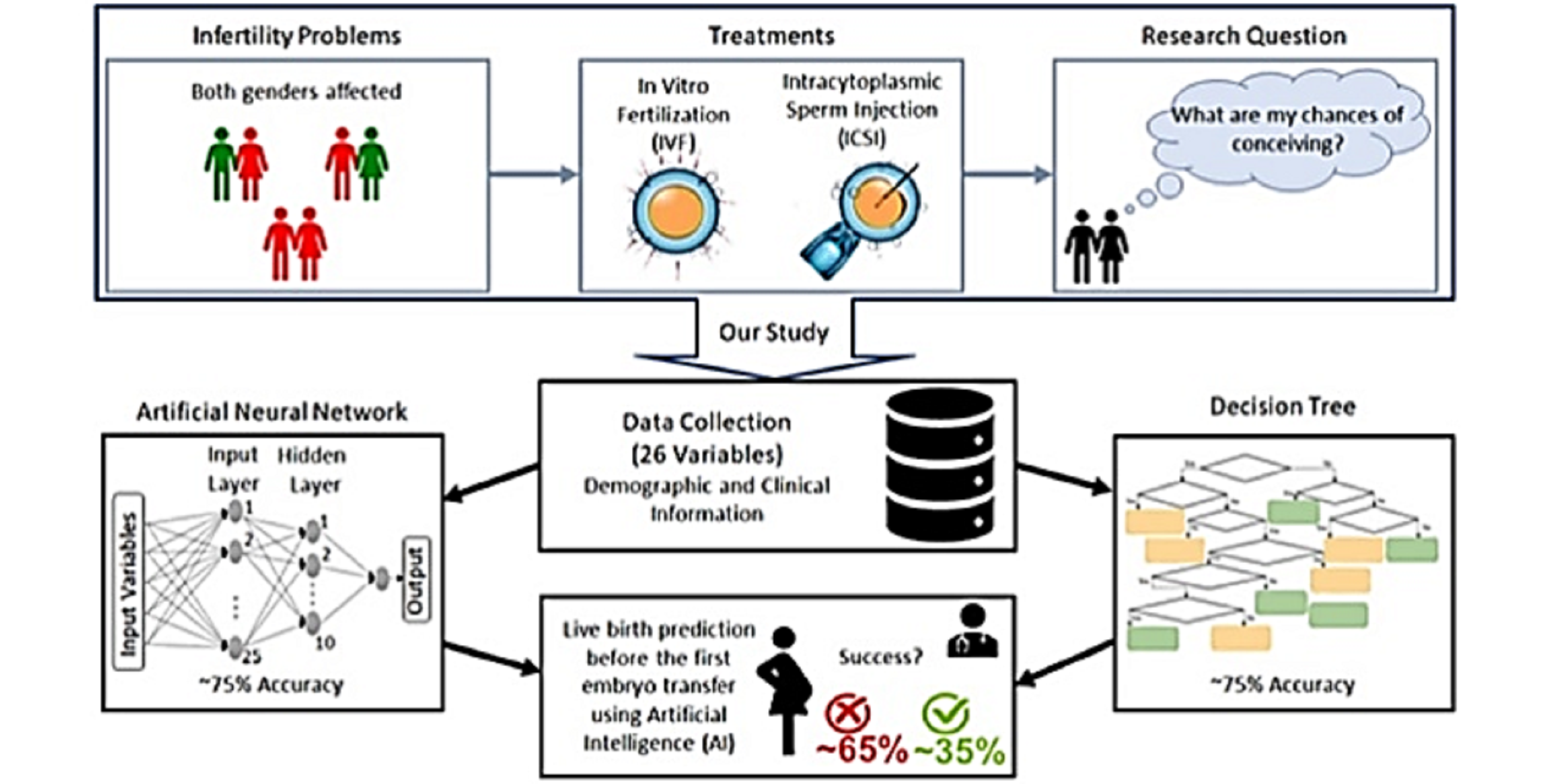
2. Materials and Methods
2.1. Data
2.2. IVF/ICSI Procedures
2.3. Statistical Analysis
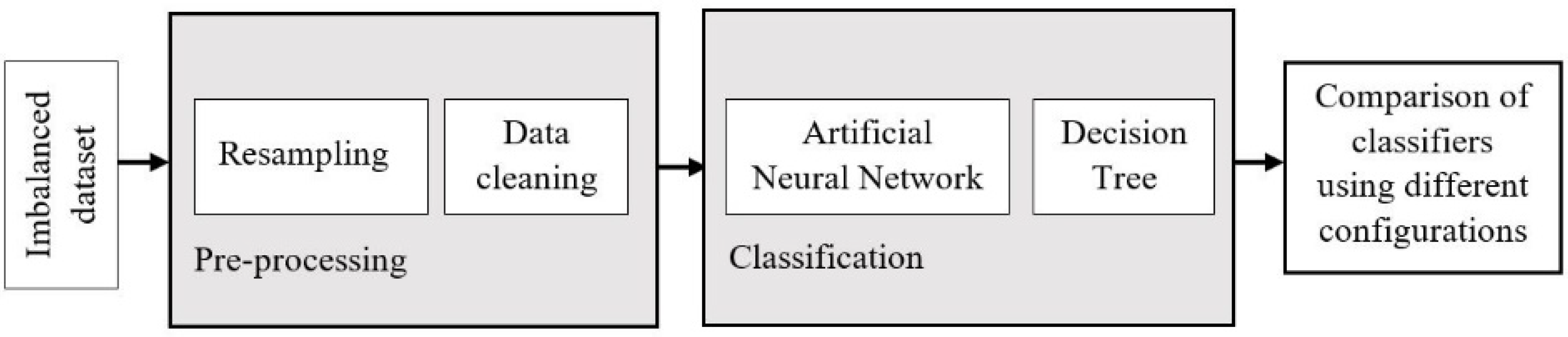
2.4. Predictive Model Analysis
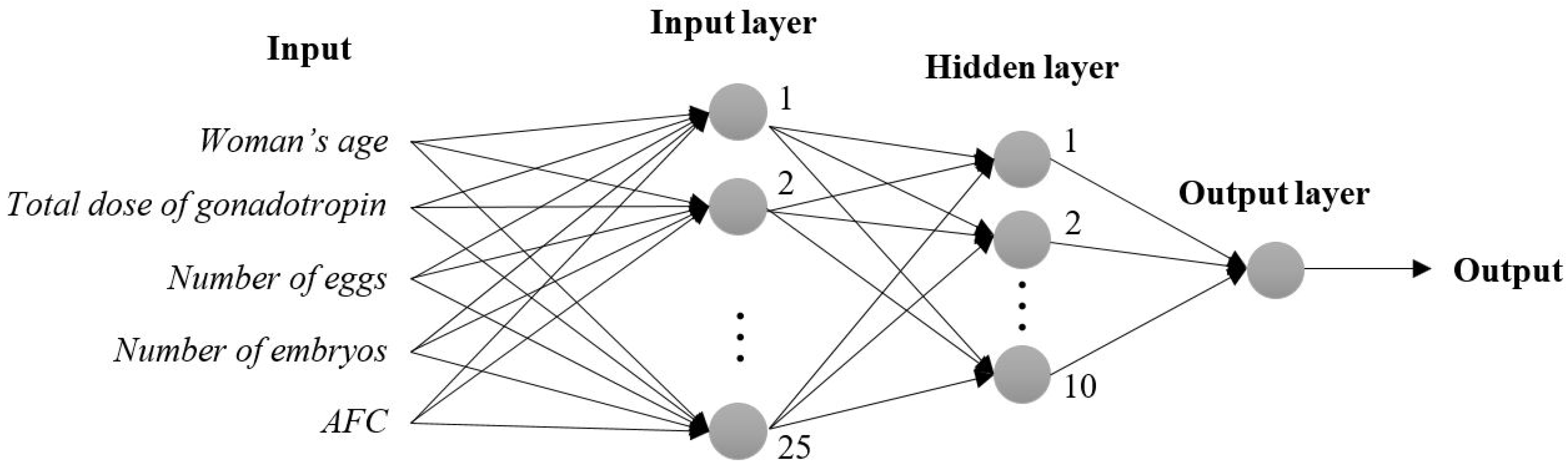
2.4.1. Artificial Neural Network.
2.4.2. Decision Tree
2.4.3. Model Evaluation
3. Results
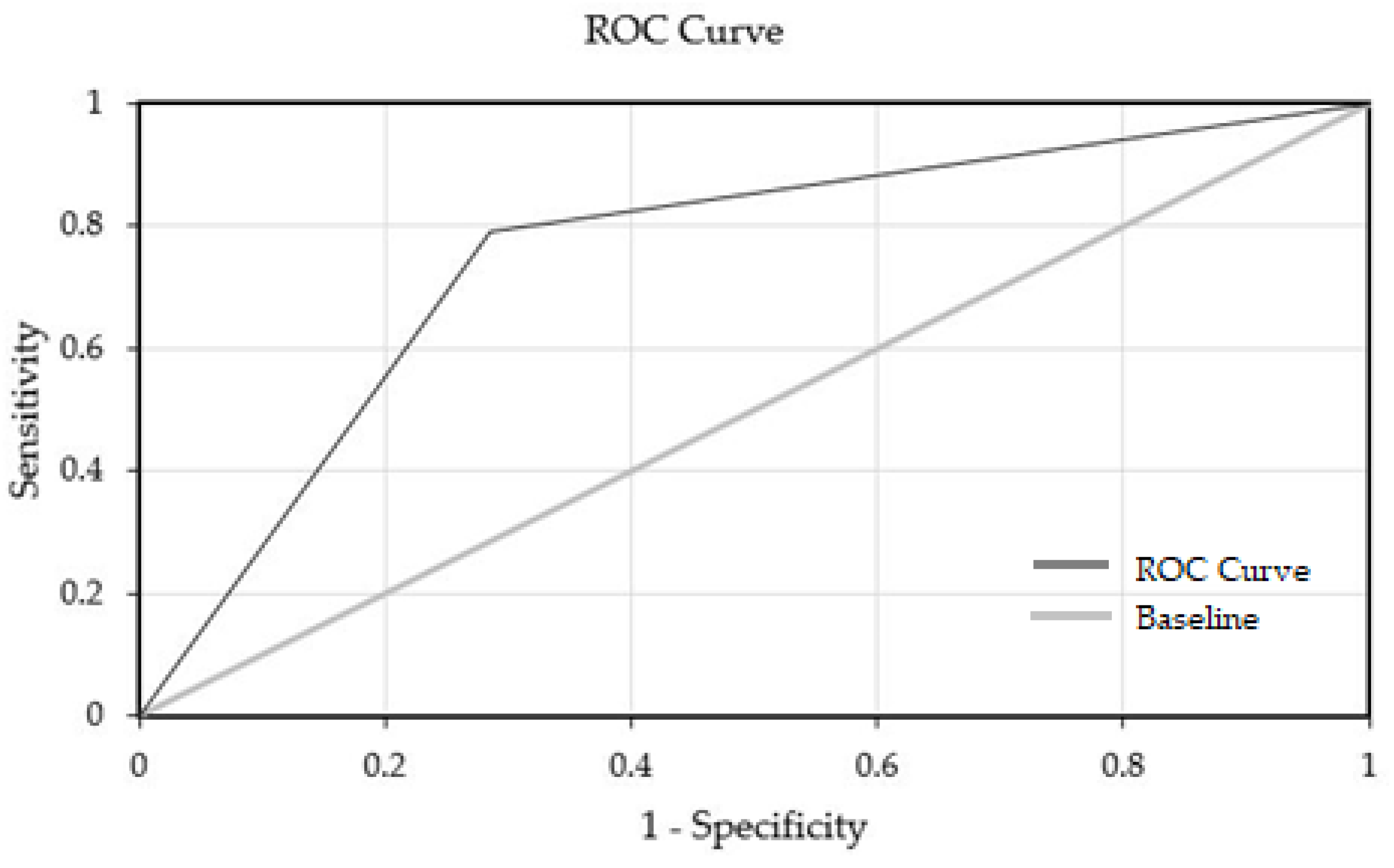
3.1. Artificial Neural Network
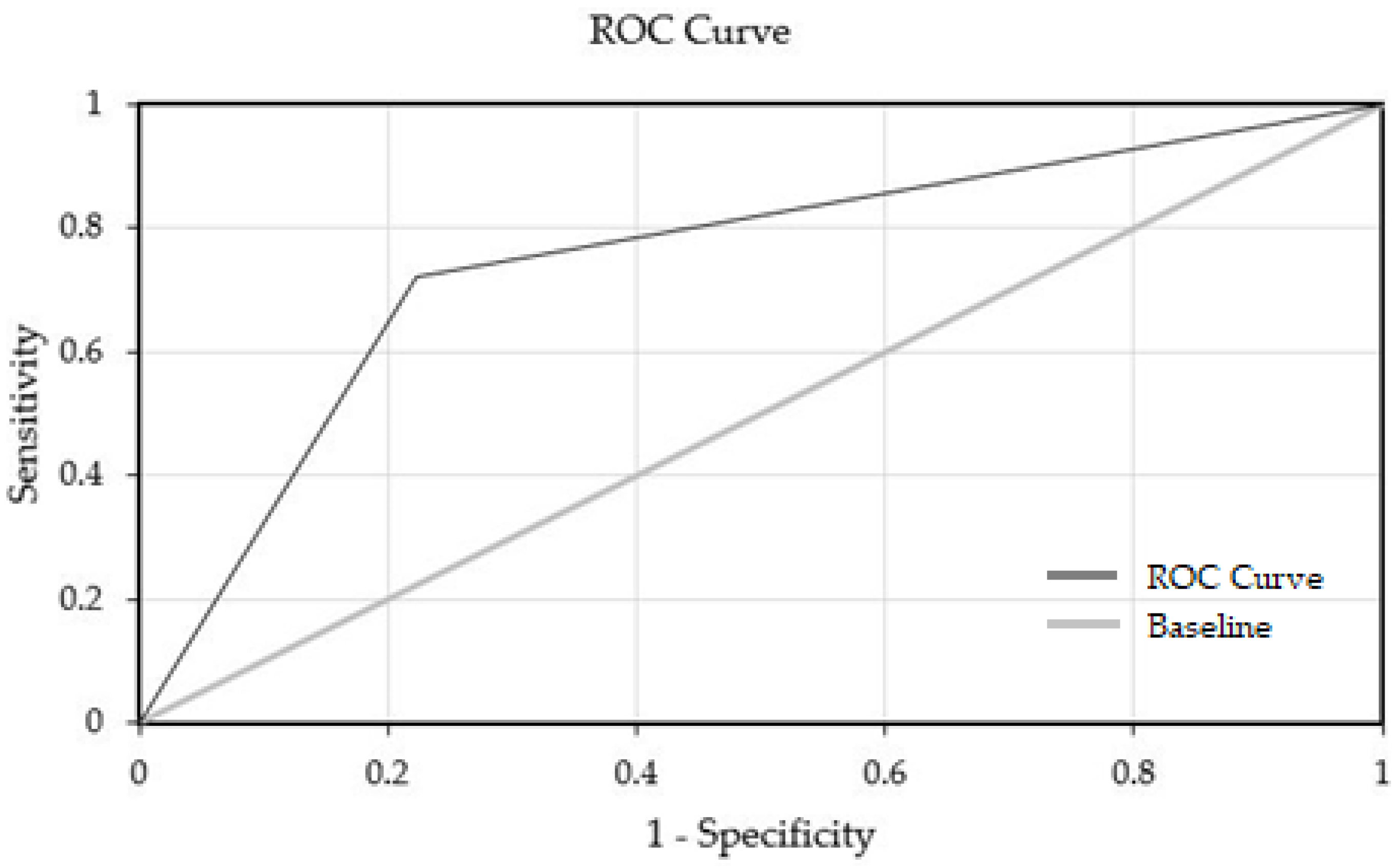
3.2. Decision Tree
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Data Availability
References
- Gurunath, S.; Pandian, Z.; Anderson, R.A.; Bhattacharya, S. Defining infertility—A systematic review of prevalence studies. Hum. Reprod. Update 2011, 17, 575–588. [Google Scholar] [CrossRef] [PubMed]
- Donarelli, Z.; Lo Coco, G.; Gullo, S.; Marino, A.; Volpes, A.; Salerno, A.; Allegra, A. Infertility-related stress, anxiety and ovarian stimulation: Can couples be reassured about the effects of psychological factors on biological responses to assisted reproductive technology? Reprod. Biomed. Soc. Online 2016, 3, 16–23. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Boivin, J.; Bunting, L.; Collins, J.A.; Nygren, K.G. International estimates of infertility prevalence and treatment-seeking: Potential need and demand for infertility medical care. Hum. Reprod. 2007, 22, 1506–1512. [Google Scholar] [CrossRef] [PubMed]
- Katz, D.J.; Teloken, P.; Shoshany, O. Male infertility—The other side of the equation. Aust. Fam. Physician 2017, 46, 641–646. [Google Scholar] [PubMed]
- Cao, X.-W.; Lin, K.; Li, C.-Y.; Yuan, C.-W. A review of WHO Laboratory Manual for the Examination and Processing of Human Semen (5th edition). Zhonghua Nan Ke Xue 2011, 17, 1059–1063. [Google Scholar]
- Templeton, A.; Morris, J.K.; Parslow, W. Factors that affect outcome of in-vitro fertilisation treatment. Lancet 1996, 348, 1402–1406. [Google Scholar] [CrossRef]
- Andrade, L.G. Inteligência Artificial e Medicina: Haverá Lugar para o Factor Humano? Rev. Port. Farmacoter. 2018, 10, 53–55. [Google Scholar] [CrossRef]
- Bhardwaj, A.; Tiwari, A. Breast cancer diagnosis using Genetically Optimized Neural Network model. Expert Syst. Appl. 2015, 42, 4611–4620. [Google Scholar] [CrossRef]
- Spelt, L.; Nilsson, J.; Andersson, R.; Andersson, B. Artificial neural networks—A method for prediction of survival following liver resection for colorectal cancer metastases. Eur. J. Surg. Oncol. 2013, 39, 648–654. [Google Scholar] [CrossRef]
- Ansari, D.; Nilsson, J.; Andersson, R.; Regnér, S.; Tingstedt, B.; Andersson, B. Artificial neural networks predict survival from pancreatic cancer after radical surgery. Am. J. Surg. 2013, 205, 1–7. [Google Scholar] [CrossRef]
- Patel, V.L.; Shortliffe, E.H.; Stefanelli, M.; Szolovits, P.; Berthold, M.R.; Bellazzi, R.; Abu-Hanna, A. The coming of age of artificial intelligence in medicine. Artif. Intell. Med. 2009, 46, 5–17. [Google Scholar] [CrossRef] [PubMed]
- Ghavami, P.; Kapur, K. Artificial neural network-enabled prognostics for patient health management. In Proceedings of the IEEE Conference on Prognostics and Health Management, Denver, CO, USA, 12–21 June 2012; pp. 1–8. [Google Scholar] [CrossRef]
- Massaro, A.; Maritati, V.; Giannone, D.; Convertini, D.; Galiano, A. LSTM DSS Automatism and Dataset Optimization for Diabetes Prediction. Appl. Sci. 2019, 9, 3532. [Google Scholar] [CrossRef]
- Kaji, D.A.; Zech, J.R.; Kim, J.S.; Cho, S.K.; Dangayach, N.S.; Costa, A.B.; Oermann, E.K. An attention based deep learning model of clinical events in the intensive care unit. PLoS ONE 2019, 14, e0211057. [Google Scholar] [CrossRef] [PubMed]
- Pham, T.; Tran, T.; Phung, D.; Venkatesh, S. Predicting healthcare trajectories from medical records: A deep learning approach. J. Biomed. Inform. 2017, 69, 218–229. [Google Scholar] [CrossRef]
- Lobo, L.C. Inteligência Artificial e Medicina. Rev. Bras. Educ. Med. 2017, 41, 185–193. [Google Scholar] [CrossRef]
- Siristatidis, C.; Vogiatzi, P.; Pouliakis, A.; Trivella, M.; Papantoniou, N.; Bettocchi, S. Predicting IVF Outcome: A Proposed Web-based System Using Artificial Intelligence. In Vivo 2016, 30, 507–512. [Google Scholar]
- Kaufmann, S.J.; Eastaugh, J.L.; Snowden, S.; Smye, S.W.; Sharma, V. The application of neural networks in predicting the outcome of in- vitro fertilization. Hum. Reprod. 1997, 12, 1454–1457. [Google Scholar] [CrossRef]
- Morales, D.A.; Bengoetxea, E.; Larrañaga, P.; García, M.; Franco, Y.; Fresnada, M.; Merino, M. Bayesian classification for the selection of in vitro human embryos using morphological and clinical data. Comput. Methods Programs Biomed. 2008, 90, 104–116. [Google Scholar] [CrossRef]
- Nelson, S.M.; Lawlor, D.A. Predicting live birth, preterm delivery, and low birth weight in infants born from in vitro fertilisation: A prospective study of 144,018 treatment cycles. PLoS Med. 2011, 8, e1000386. [Google Scholar] [CrossRef]
- Steuerwald, N.M.; Bermúdez, M.G.; Wells, D.; Munné, S.; Cohen, J. Maternal age-related differential global expression profiles observed in human oocytes. Reprod. Biomed. Online 2007, 14, 700–708. [Google Scholar] [CrossRef]
- La Marca, A.; Nelson, S.M.; Sighinolfi, G.; Manno, M.; Baraldi, E.; Roli, L.; Xella, S.; Marsella, T.; Tagliasacchi, D.; D’Amico, R.; et al. Anti-Müllerian hormone-based prediction model for a live birth in assisted reproduction. Reprod. Biomed. Online 2011, 22, 341–349. [Google Scholar] [CrossRef] [PubMed]
- Hajshafiha, M.; Ghareaghaji, R.; Salemi, S.; Sadegh-Asadi, N.; Sadeghi-Bazargani, H. Association of body mass index with some fertility markers among male partners of infertile couples. Int. J. Gen. Med. 2013, 6, 447–451. [Google Scholar] [CrossRef] [PubMed]
- Qiu, J.; Li, P.; Dong, M.; Xin, X.; Tan, J. Personalized prediction of live birth prior to the first in vitro fertilization treatment: A machine learning method. J. Transl. Med. 2019, 17, 317. [Google Scholar] [CrossRef] [PubMed]
- Dhillon, R.K.; Smith, P.P.; Malhas, R.; Harb, H.M.; Gallos, I.D.; Dowell, K.; Fishel, S.; Deeks, J.J.; Coomarasamy, A. Investigating the effect of ethnicity on IVF outcome. Reprod. Biomed. Online 2015, 31, 356–363. [Google Scholar] [CrossRef] [PubMed]
- Dhillon, R.K.; McLernon, D.J.; Smith, P.P.; Fishel, S.; Dowell, K.; Deeks, J.J.; Bhattacharya, S.; Coomarasamy, A. Predicting the chance of live birth for women undergoing IVF: A novel pretreatment counselling tool. Hum. Reprod. 2016, 31, 84–92. [Google Scholar] [CrossRef] [PubMed]
- Goryński, K.; Safian, I.; Gradzki, W.; Marszall, M.P.; Krysiński, J.; Goryński, S.; Bitner, A.; Romaszko, J.; Buciński, A. Artificial neural networks approach to early lung cancer detection. Open Med. 2014, 9, 632–641. [Google Scholar] [CrossRef]
- Batista, G.E.A.P.A.; Prati, R.C.; Monard, M.C. A study of the behavior of several methods for balancing machine learning training data. ACM SIGKDD Explor. Newsl. 2004, 6, 20–29. [Google Scholar] [CrossRef]
- Badura, A.; Marzec-Wróblewska, U.; Kamiński, P.; Łakota, P.; Ludwikowski, G.; Szymański, M.; Wasilow, K.; Lorenc, A.; Buciński, A. Prediction of semen quality using artificial neural network. J. Appl. Biomed. 2019, 17, 167–174. [Google Scholar] [CrossRef]
- Tabachnick, B.G.; Fidell, L.S. Using Multivariate Statistics, 6th ed.; Pearson Education, Inc.: Upper Saddle River, NJ, USA, 2013; pp. 1–983. [Google Scholar]
- Yang, P.; Liu, W.; Zhou, B.B.; Chawla, S.; Zomaya, A.Y. Ensemble-Based Wrapper Methods for Feature Selection and Class Imbalance Learning. Lect. Notes Comput. Sci. 2013, 7818, 544–555. [Google Scholar] [CrossRef]
- Kotsiantis, S.B. Decision trees: A recent overview. Artif. Intell. Rev. 2013, 39, 261–283. [Google Scholar] [CrossRef]
- Gordon, A.D.; Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees. Biometrics 1984, 40, 874. [Google Scholar] [CrossRef]
- Han, J.; Kamber, M.; Pei, J. Data Mining Concepts and Techniques, 3rd ed.; Elsevier Inc.: Waltham, MA, USA, 2012; pp. 1–632. [Google Scholar]
- Timofeev, R. Classification and Regression Trees (CART) Theory and Applications. Master’s Thesis, Humboldt University, Berlin, Germany, 20 December 2004. [Google Scholar]
- Kingsford, C.; Salzberg, S.L. What are decision trees? Nat. Biotechnol. 2008, 26, 1011–1013. [Google Scholar] [CrossRef] [PubMed]
- Garcia, S.C. O Uso da Árvore de Decisão na Descoberta de Conhecimento na Área da Saúde. Master’s Thesis, Universidade Federal do Rio Grande do Sul, Porto Alegre, Brazil, 2003. [Google Scholar]
- Yan-ya, S.O.N.G.; Ying, L.U. Decision tree methods: Applications for classification and prediction. Shanghai Arch. Psychiatry 2015, 27, 130–135. [Google Scholar] [CrossRef]
- Milewski, R.; Jamiołkowski, J.; Anna, J.M.; Domitrz, J.; Szamatowicz, J.; Wołczyński, S. Prognosis of the IVF ICSI/ET Procedure Efficiency With the Use of Artificial Neural Networks among Patients of the Department of Reproduction and Gynecological Endocrinology. Ginekol. Pol. 2009, 80, 900–906. [Google Scholar]
- Durairaj, M.; Thamilselvan, P. Applications of Artificial Neural Network for IVF Data Analysis and Prediction. J. Eng. Comput. Appl. Sci. 2013, 2, 11–15. [Google Scholar]
- Hafiz, P.; Nematollahi, M.; Boostani, R.; Jahromi, B.N. Predicting Implantation Outcome of In Vitro Fertilization and Intracytoplasmic Sperm Injection Using Data Mining Techniques. Int. J. Fertil. Steril. 2017, 11, 184–190. [Google Scholar] [CrossRef]
- Leijdekkers, J.A.; Eijkemans, M.J.C.; van Tilborg, T.C.; Oudshoorn, S.C.; McLernon, D.J.; Bhattacharya, S.; Mol, B.W.J.; Broekmans, F.J.M.; Torrance, H.L.; OPTIMIST Group. Predicting the cumulative chance of live birth over multiple complete cycles of in vitro fertilization: An external validation study. Hum. Reprod. 2018, 33, 1684–1695. [Google Scholar] [CrossRef]
- Negassa, A.; Monrad, E.S.; Bang, J.Y.; Srinivas, V.S. Tree-structured risk stratification of in-hospital mortality after percutaneous coronary intervention for acute myocardial infarction: A report from the New York State percutaneous coronary intervention database. Am. Heart J. 2007, 154, 322–329. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Judmaier, G.; Meyersbach, P.; Weiss, G.; Wachter, H.; Reibnegger, G. The role of neopterin in assessing disease activity in Crohn’s disease: Classification and regression trees. Am. J. Gastroenterol. 1993, 88, 706–711. [Google Scholar]
- Mello, F.C.Q.; Bastos, L.G.V.; Soares, S.L.M.; Rezende, V.M.C.; Conde, M.B.; Chaisson, R.E.; Kritski, A.L.; Ruffino-Neto, A.; Werneck, G.L. Predicting smear negative pulmonary tuberculosis with classification trees and logistic regression: A cross-sectional study. BMC Public Health 2006, 6, 43. [Google Scholar] [CrossRef] [PubMed]
- Pouliakis, A.; Karakitsou, E.; Chrelias, C.; Pappas, A.; Panayiotides, I.; Valasoulis, G.; Kyrgiou, M.; Paraskevaidis, E.; Karakitsos, P. The Application of Classification and Regression Trees for the Triage of Women for Referral to Colposcopy and the Estimation of Risk for Cervical Intraepithelial Neoplasia: A Study Based on 1625 Cases with Incomplete Data from Molecular Tests. Biomed Res. Int. 2015, 2015, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Takahashi, O.; Cook, E.F.; Nakamura, T.; Saito, J.; Ikawa, F.; Fukui, T. Risk stratification for in-hospital mortality in spontaneous intracerebral haemorrhage: A Classification and Regression Tree Analysis. QJM 2006, 99, 743–750. [Google Scholar] [CrossRef] [PubMed]
- McKenzie, D.P.; McGorry, P.D.; Wallace, C.S.; Low, L.H.; Copolov, D.L.; Singh, B.S. Constructing a minimal diagnostic decision tree. Methods Inf. Med. 1993, 32, 161–166. [Google Scholar] [PubMed]
- Milewska, A.J.; Jankowska, D.; Cwalina, U.; Citko, D.; Wiesak, T.; Acacio, B.; Milewski, R. Prediction of Infertility Treatment Outcomes Using Classification Tree. Stud. Log. Gramm. Rhetor. 2016, 47, 7–19. [Google Scholar] [CrossRef]
- Ghaeini, M.K.; Amin-Naseri, M.R.; Aghahoseini, M. Prediction of Clinical Pregnancy Occurrence after ICSI using Decision Tree and Support Vector Machine Methods. J. Obstet. Gynecol. Cancer Res. 2018, 3, 12–18. [Google Scholar] [CrossRef]
- McLernon, D.J.; Steyerberg, E.W.; te Velde, E.R.; Lee, A.J.; Bhattacharya, S. Predicting the chances of a live birth after one or more complete cycles of in vitro fertilisation: Population based study of linked cycle data from 113 873 women. BMJ 2016, 355, i5735. [Google Scholar] [CrossRef] [PubMed]
- Veiga, B.E.; Ferreira, F.; Metello, J.L.; Fonseca, J.M. Predicting the Chances of Live Birth for Couples Undergoing In Vitro Treatments Using Decision Trees. In Proceedings of the HEALTHINFO 2019: The Fourth International Conference on Informatics and Assistive Technologies for Health-Care, Medical Support and Well Being, Valencia, Spain, 24–28 November 2019; pp. 14–19. [Google Scholar]
- Hinkle, D.E.; Wiersma, W.; Jurs, S.G. Applied Statistics for the Behavioral Sciences, 5th ed.; Houghton Mifflin: Boston, MA, USA, 2003; pp. 1–756. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Continuous Attribute | All Couples (n = 1193) | Couples with Live Birth (n = 387) | Couples without Live Birth (n = 806) | t-Test p-Value |
|---|---|---|---|---|
| Duration of Infertility (months) | 58.72 29.60 | 56.40 29.24 | 59.83 29.71 | 0.060 |
| Woman’s age (years) | 34.34 3.66 | 33.36 3.72 | 34.81 3.54 | <0.000 |
| Woman’s weight (kg) | 64.68 12.54 | 64.26 12.15 | 64.88 12.72 | 0.416 |
| Woman’s height (cm) | 162.97 6.12 | 163.51 6.05 | 162.71 6.13 | 0.034 |
| Woman’s BMI (kg/m2) | 24.35 4.51 | 24.01 4.16 | 24.51 4.66 | 0.060 |
| Man’s age (years) | 36.58 5.21 | 35.93 4.90 | 36.89 5.33 | <0.000 |
| Man’s weight (kg) | 81.71 13.61 | 81.32 13.99 | 81.89 13.42 | 0.503 |
| Man’s height (cm) | 176.15 ± 6.78 | 176.57 ± 6.92 | 175.95 ± 6.70 | 0.144 |
| Man’s BMI (kg/m2) | 26.29 ± 3.85 | 26.03 ± 3.84 | 26.42 ± 3.85 | 0.099 |
| AMH level (ng/mL) | 3.22 ± 3.43 | 3.98 ± 3.59 | 2.86 ± 3.29 | <0.000 |
| AFC | 14.60 ± 9.44 | 17.19 ± 9.37 | 13.35 ± 9.22 | <0.000 |
| Number of attempts in the center | 1.25 ± 0.67 | 1.28 ± 0.53 | 1.24 ± 0.73 | 0.203 |
| Total dose of gonadotropin (IU) | 2478 956 | 2218 846 | 2603 981 | <0.000 |
| Days of stimulation | 10.38 2.25 | 10.36 2.03 | 9.35 2.35 | 0.789 |
| Average daily dose of gonadotropin (IU/day) | 236.4 73.1 | 213.1 66.8 | 247.6 73.4 | <0.000 |
| Number of eggs | 9.61 7.17 | 13.07 7.73 | 7.95 6.23 | <0.000 |
| Number of mature eggs | 7.79 6.15 | 10.96 6.68 | 6.27 5.24 | <0.000 |
| Number of embryos | 5.42 4.75 | 8.12 5.24 | 4.12 3.88 | <0.000 |
| Categorical Attribute | All Couples (n = 1193) | Couples with Live Birth (n = 387) | Couples without Live Birth (n = 806) | χ2 Statistic p-Value | |
|---|---|---|---|---|---|
| n (%) | n (%) | n (%) | |||
| Woman’s Smoking Status | Previous | 196 (16.4) | 66 (17.1) | 130 (16.1) | 0.421 |
| Never | 676 (56.7) | 209 (54.0) | 467 (57.9) | ||
| Present | 321 (26.9) | 112 (28.9) | 209 (25.9) | ||
| Man’s smoking status | Previous | 211 (17.7) | 66 (17.1) | 145 (18.0) | 0.681 |
| Never | 571 (47.9) | 181 (46.8) | 390 (48.4) | ||
| Present | 411 (34.5) | 140 (36.2) | 271 (33.6) | ||
| Woman’s ethnicity | Asian | 9 (0.8) | 2 (0.5) | 7 (0.9) | 0.560 |
| Caucasian | 1071 (89.8) | 346 (89.4) | 725 (90.0) | ||
| Gipsy | 15 (1.3) | 7 (1.8) | 8 (1.0) | ||
| Indian | 8 (0.7) | 3 (0.8) | 5 (0.6) | ||
| Mixture | 43 (3.6) | 17 (4.4) | 26 (3.2) | ||
| African | 47 (3.9) | 12 (3.1) | 35 (4.3) | ||
| Man’s ethnicity | Asian | 6 (0.5) | 1 (0.3) | 5 (0.6) | 0.088 |
| Caucasian | 1101 (92.3) | 347 (89.7) | 754 (93.5) | ||
| Gipsy | 16 (1.3) | 8 (2.1) | 8 (1.0) | ||
| Indian | 10 (0.8) | 4 (1.0) | 6 (0.7) | ||
| Mixture | 26 (2.2) | 14 (3.6) | 12 (1.5) | ||
| African | 34 (2.8) | 13 (3.4) | 21 (2.6) | ||
| Cause of infertility | Endometriosis | 120 (10.1) | 32 (8.3) | 88 (10.9) | 0.315 |
| Male factor | 368 (30.8) | 134 (34.6) | 234 (29.0) | ||
| Both male and female factor | 112 (9.4) | 29 (7.5) | 83 (10.3) | ||
| Unexplained infertility | 275 (23.1) | 89 (23.0) | 186 (23.1) | ||
| Multiple female factors | 39 (3.3) | 9 (2.3) | 30 (3.7) | ||
| Other | 8 (0.7) | 2 (0.5) | 6 (0.7) | ||
| Cause of infertility | Ovulatory factor | 93 (7.8) | 32 (8.3) | 61 (7.6) | 0.315 |
| Tubal factor | 175 (14.7) | 60 (15.5) | 115 (14.3) | ||
| Uterine factor | 3 (0.3) | 0 (0.0) | 3 (0.4) | ||
| Woman’s with previous children | Yes | 122 (10.2) | 36 (9.3) | 86 (10.7) | 0.032 |
| No | 1071 (89.8) | 351 (90.7) | 720 (89.3) | ||
| Man’s with previous children | Yes | 137 (11.5) | 47 (12.1) | 90 (11.2) | 0.620 |
| No | 1056 (88.5) | 340 (87.9) | 716 (88.8) | ||
| Nature of treatment | IVF | 629 (52.7) | 208 (53.7) | 421 (52.2) | <0.000 |
| ICSI | 542 (45.4) | 164 (42.4) | 378 (46.9) | ||
| Mixed IVF/ICSI | 22 (1.8) | 15 (3.9) | 7 (0.9) | ||
| Continuous Attribute | Coefficient r | p-Value | Continuous Attribute | Coefficient r | p-Value |
|---|---|---|---|---|---|
| Duration of infertility | −0.047 | 0.120 | Total dose of gonadotropin | −0.183 | <0.000 |
| Woman’s age | −0.184 | <0.000 | Days of stimulation | −0.006 | 0.848 |
| Woman’s weight | −0.017 | 0.570 | Average daily dose of gonadotropin | −0.217 | <0.000 |
| Woman’s height | 0.067 | 0.026 | Number of attempts in the center | 0.037 | 0.211 |
| Woman’s BMI | −0.047 | 0.114 | Number of eggs | 0.347 | <0.000 |
| Man’s age | −0.090 | 0.003 | Number of mature eggs | 0.370 | <0.000 |
| Man’s weight | −0.023 | 0.441 | Number of embryos | 0.401 | <0.000 |
| Man’s height | 0.037 | 0.217 | AMH level | 0.156 | <0.000 |
| Man’s BMI | −0.048 | 0.109 | AFC | 0.198 | <0.000 |
| Variable | Relative Importance (%) |
|---|---|
| Number of embryos | 100.00 |
| Woman’s age | 13.26 |
| Total dose of gonadotropin | 1.07 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Brás de Guimarães, B.; Martins, L.; Metello, J.L.; Ferreira, F.L.; Ferreira, P.; Fonseca, J.M. Application of Artificial Intelligence Algorithms to Estimate the Success Rate in Medically Assisted Procreation. Reprod. Med. 2020, 1, 181-194. https://doi.org/10.3390/reprodmed1030014
Brás de Guimarães B, Martins L, Metello JL, Ferreira FL, Ferreira P, Fonseca JM. Application of Artificial Intelligence Algorithms to Estimate the Success Rate in Medically Assisted Procreation. Reproductive Medicine. 2020; 1(3):181-194. https://doi.org/10.3390/reprodmed1030014
Chicago/Turabian StyleBrás de Guimarães, Beatriz, Leonardo Martins, José Luís Metello, Fernando Luís Ferreira, Pedro Ferreira, and José Manuel Fonseca. 2020. "Application of Artificial Intelligence Algorithms to Estimate the Success Rate in Medically Assisted Procreation" Reproductive Medicine 1, no. 3: 181-194. https://doi.org/10.3390/reprodmed1030014
APA StyleBrás de Guimarães, B., Martins, L., Metello, J. L., Ferreira, F. L., Ferreira, P., & Fonseca, J. M. (2020). Application of Artificial Intelligence Algorithms to Estimate the Success Rate in Medically Assisted Procreation. Reproductive Medicine, 1(3), 181-194. https://doi.org/10.3390/reprodmed1030014