1. Introduction
Deep learning has revolutionized various fields, including computer vision, speech recognition, and natural language processing, by leveraging artificial neural networks (ANNs) with deep architectures [
1,
2,
3,
4,
5,
6,
7]. Among these, convolutional neural networks (CNNs) have become a fundamental tool for image and video analysis due to their ability to automatically extract hierarchical features such as edges, textures, and patterns [
8,
9,
10,
11,
12]. CNNs achieve this by applying convolutional operations using kernels of different sizes, followed by pooling, nonlinear activation functions, and successive convolutional layers. These operations enable CNNs to recognize complex patterns in large datasets, making them highly effective for classification and object detection tasks. However, despite their superior performance, CNNs demand extensive computational resources, especially as the depth of the network and the size of the input images increase.
The computational complexity of CNNs is largely attributed to convolution operations, which scale with both image resolution and kernel size. For an image with n × n pixels convolved with a k × k kernel, the number of computations is proportional to n
2 × k
2, leading to substantial processing requirements. This challenge becomes more pronounced when dealing with real-time applications, where high latency and power consumption pose significant limitations. Although graphics processing units (GPUs) have been widely used to accelerate CNN inference through parallel processing, they suffer from inefficiencies such as high energy consumption and memory bandwidth constraints [
13,
14,
15]. Furthermore, deploying CNNs on large-scale systems often requires multiple GPUs, which introduces additional communication overhead and synchronization delays [
16,
17]. These limitations highlight the necessity for alternative hardware architectures that can offer improved computational efficiency, reduced power consumption, and real-time processing capabilities, paving the way for innovations in specialized AI hardware and optical computing solutions.
To address the challenges of CNNs, researchers are increasingly exploring the feasibility of optical convolutional neural networks (OCNNs). Traditionally, OCNNs have been implemented using the 4f correlator system [
18,
19,
20,
21,
22], which leverages Fourier optics for convolution operations [
23]. While this approach offers certain advantages, it also has inherent limitations that hinder its practicality in optical neural networks. One major drawback is the limited scalability of input images due to the finite space–bandwidth product (SBP) of the lens used for Fourier transformation [
18]. This issue is further exacerbated by geometric aberrations, which degrade the optical system’s resolution as image size increases.
Another significant limitation is the latency introduced by spatial light modulators (SLMs), which are essential for generating coherent optical inputs. Most SLMs operate at relatively low speeds, typically in the kilohertz range [
24,
25], significantly reducing the potential parallelism of optical computing. This becomes particularly problematic in multilayer optical neural networks, where the output of one layer serves as the input for the next. The need to update SLM pixels at each layer transition introduces additional delays, ultimately reducing throughput. Furthermore, reconfiguring convolution kernels in a 4f system is computationally intensive, as the kernel representation is based on its Fourier transform. This additional computational requirement further slows real-time processing, making the 4f correlator system less suitable for scalable and efficient optical deep learning applications.
To solve these problems, we first proposed a scalable optical convolutional neural network (SOCNN) [
26] based on free-space optics utilizing a lens array and an SLM. Later, we improved the original design by replacing the SLM with a smart-pixel light modulator (SPLM) [
27,
28,
29]. This improved architecture is referred to as the smart-pixel-based optical convolutional neural network (SPOCNN) [
29]. The introduction of the SPLM resolves several issues related to the slow switching speed and limited cascading capability of the SLM. Additionally, the fast refresh rate and memory capabilities of the SPLM enable the development of other architectures, such as the smart-pixel-based bidirectional optical convolutional neural network (SPBOCNN) and the two-mirror-like SPBOCNN (TML-SPBOCNN) [
29]. These two derived architectures are highly effective in making the SPOCNN scalable in both transverse and longitudinal directions across layers. The enhanced scalability makes the SPOCNN more adaptable, allowing it to handle large input array sizes and an arbitrary number of convolution layers based on software, without the need for expanded hardware resources.
In the previous study [
29], the SPOCNN architecture was proposed only conceptually, with its performance analyzed through rough estimations. Consequently, many researchers may have questioned the feasibility of the SPOCNN design. Additionally, scaling analysis indicated that the kernel size was primarily limited by geometric aberrations. While this limitation can theoretically be overcome by implementing clustering methods [
30] or software-based scaling with smart-pixel memory [
29], these approaches introduce additional hardware requirements or processing delays. Therefore, it is crucial to evaluate the performance and scaling limits of concrete SPOCNN designs before implementing specialized scaling techniques.
In this study, we verified the optical design of the SPOCNN using optical design software. We presented design examples with various kernel sizes, employing three-element lenses optimized through the software. Performance is evaluated by analyzing spot size and encircled energy diagrams to estimate alignment tolerance, minimize cross-talk between channels, and assess the overall scalability of the SPOCNN. From an engineering development perspective, this paper represents the preliminary or detailed design phase that follows the initial conceptual design. These specifications provide a foundation for subsequent manufacturing, testing, and system verification.
2. Materials and Methods
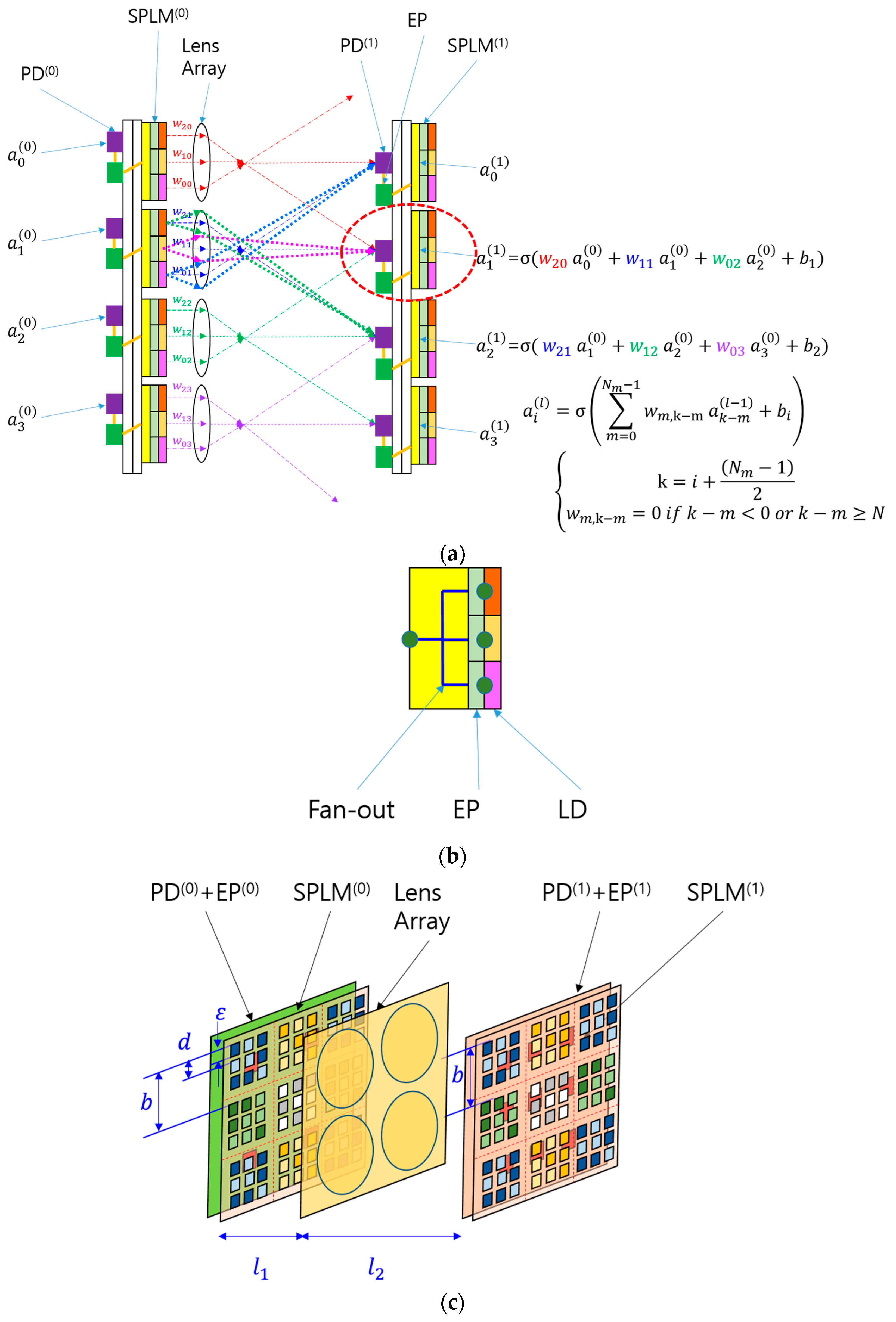
Before presenting the optical designs of SPOCNNs, it is useful to first explain the fundamental concepts of the architecture. This allows for a more effective comparison between the performance estimations from previous studies and those obtained through simulations using concrete optical designs. The schematic in
Figure 1a illustrates an SPOCNN comprising SPLMs, lenses, and photodetectors (PDs), along with mathematical formulas representing convolution.
The input signal originates from PD
(0) in the zeroth layer and is sent to the electronic processor (EP) in the same layer, which is connected to SPLM
(0) on the substrate. The internal structure of the SPLM is depicted in
Figure 1b, where the electrical fan-out distributes the input signal across multiple pixels. Within the SPLM, EPs amplify the input signal according to the weight values stored in memory and then transmit the processed signal to the light-emitting diode (LED) within the same pixel. Each set of weight values controlled by an SPLM subarray corresponds to a kernel or filter in the SPOCNN.
The LED in the SPLM emits light, which then passes through a lens that refracts the beams based on their relative positions to the optical axis. The varying ray angles allow the transmission of signals from a single input node to multiple PDs in the first layer. PD(1) collects the light from multiple SPLMs, performing convolution calculations. The computed results are then sent to the EP connected to the PD, where additional operations such as bias addition and activation functions (e.g., sigmoid function) are applied. The final output is then forwarded to SPLM(1) in the first layer.
Because the pixels in SPLM
(0) are optically conjugated to PD
(1) via the lens, the image of an SPLM pixel is sharply projected onto the PD
(1) plane. The thick dotted lines (green, magenta, and blue) in
Figure 1a represent the marginal rays of the projection lens, demonstrating the conjugation relationship. In contrast, the other thin lines, known as chief rays, indicate the relative positions of the pixel images.
Although
Figure 1a illustrates a one-dimensional array of SPLMs, lenses, and PDs, this structure can be readily extended to a two-dimensional array, as shown in
Figure 1c. The example in
Figure 1c depicts a 3 × 3 kernel array. The lens magnification is determined by the kernel array size [
26,
29]. Suppose the pixel size and pitch are denoted by
ε and
d, respectively, as shown in
Figure 1c. The pitch of the kernel subarray, represented as
b, is equal to both the pitch of the detectors in the first layer and the lens diameter. For an M × M kernel array, the kernel subarray size is given by M
d, satisfying
b = M
d. Since the detector pitch corresponds to the magnified image of the pixel pitch, the relationship
b = M’
d holds, where M’ is the lens magnification which is
. Therefore, the lens magnification M’ is equivalent to the kernel size M.
As mentioned in the introduction, SPOCNN does not have a limitation on input array size, unlike the 4f correlator system. However, it does have a scaling limit for the kernel array size, primarily due to the geometric aberration of the lens [
26,
29]. Consequently, the scaling limit of the kernel array depends on the lens design and its imaging performance. The previous scaling analysis was based on the assumption that the lens has an f/# of 2 and an angular aberration of approximately 3 mrad.
Before discussing the scaling properties of SPOCNN, it is useful to review how the scaling analysis was conducted in previous research [
26,
29]. The analysis began with a 5 × 5 kernel array, examining the lens’s spot size under specific constraints as the kernel size increased. If the image size of a pixel exceeded the detector pitch or the remaining alignment tolerance became too small for practical implementation, it was considered the limiting factor for the kernel array size.
A similar approach can be applied to analyzing the scaling limit of the SPOCNN kernel, despite the differences in optical setups between SPOCNN and SOCNN. SPOCNN utilizes a single projection lens, whereas SOCNN consists of both a condenser lens and a projection lens, comprising a three-lens system. However, the scaling limits are assumed to be similar, as the projection lens primarily determines the scaling characteristics. The only distinction is that the projection lens in SPOCNN consists of a single lens group, whereas in SOCNN, it comprises two lens groups forming a relay lens system.
Suppose SPOCNN has a 5 × 5 kernel array with a square pixel of 10 μm and a period of 40 μm. The side length of the square kernel subarray is 200 μm, which corresponds to the lens diameter and the detector pitch in the first substrate. According to the notations in
Figure 1c,
ε,
d, and
b are 10, 40, and 200 μm, respectively. As mentioned earlier, the lens magnification M is equal to the row size of the kernel array, which is 5. Consequently, the geometric image size of a pixel is 50 μm, corresponding to a 25% duty cycle of the detector pitch, as it accounts for 25% of the pixel pitch in the SPLM plane. Here, the image size and image spread are expressed in terms of the duty cycle relative to either the detector pitch or the SPLM pixel pitch, since these two pitches are related by the magnification factor of the projection lens, and the duty cycle remains the same in both planes.
To estimate the geometric aberration spread, we must determine the distance l2 between the lens and the detector plane. Given that the lens has an f/# of 2, the focal length is 0.4 mm, as dictated by the given diameter b. Using the lens formula and magnification, l2 is calculated to be 2.4 mm. Assuming the lens has an angular aberration of 3 mrad, the image spread due to geometric aberration is 7.2 μm, which accounts for 3.6% of the detector pitch. In this context, the image spread is initially estimated as the product of the angular aberration and l2. Subsequently, it refers to the root mean square (RMS) spot diameter obtained from simulation.
Regarding diffraction spread, the diameter of the Airy disk is given by . For a wavelength of 850 nm, this results in 20.4 μm, accounting for 10.2% of the detector pitch. Therefore, the total image spread sums up to 39% of the detector pitch. The remaining duty cycle of the detector pitch can serve as an alignment tolerance in either the detector plane or the SPLM pixel plane. Since pixel plane alignment is more critical, it must be managed with greater precision. The alignment tolerance in the pixel plane is 61% of the pixel pitch, approximately 24 μm, which can be readily achieved using modern optomechanical techniques. This alignment tolerance can be allocated as a margin for various alignment factors, including detector and lens positioning, tilt, and other fabrication and assembly processes.
If the kernel array size is scaled up by a factor of α, it expands to a 5α × 5α array. With fixed values of ε and d, b increases by a factor of α. As the lens diameter increases by a scale factor, the focal length must also increase proportionally to maintain the same f/#. Since the subarray row size equals the magnification, the magnification also scales up by α times. The maximum image height increases by α2 times, as both the maximum object height and magnification increase by α times. Additionally, l1 and l2 grow by approximately α and α2 times, respectively.
To determine the critical factor in the scaling limitation, we analyzed the effects of scaling on geometric image size, geometric aberration, and diffraction spread. When the kernel array is scaled up by a factor of α, the geometric image size of a pixel increases proportionally due to the increase in magnification. However, the duty cycle of the pixel image in the detector pitch remains constant since the detector pitch also scales by α. In terms of geometric aberration, the image spread due to aberration increases by α2 because l2 increases α2 times, while the angular aberration remains approximately constant. Consequently, the duty cycle of image spread due to aberration increases by α within the detector pitch, making geometric aberration a more significant factor as the kernel size scales up.
Similarly, diffraction spread also increases by α, following the relation
, where λ is the wavelength. Since the lens aperture increases by α and
l2 increases by α
2, the duty cycle of diffraction spread in the detector pitch remains unchanged with scale-up. Thus, while diffraction effects remain constant, geometric aberration becomes the primary limiting factor in scaling. If the minimum alignment tolerance is set to a duty cycle of 13%, the remaining duty cycle available for geometric aberration is 48%. Given that the aberration of a 5 × 5 kernel array occupies 3.6% of the duty cycle, the maximum feasible scale-up factor is approximately 13.3, leading to a kernel array of about 66 × 66, as noted in previous studies [
26,
29]. The minimum alignment tolerance in the SPLM plane corresponds to approximately 5 μm, which can be achieved using modern optical packaging techniques.
This estimation of the scaling limit is based on approximations and several assumptions. Therefore, a more precise assessment would require simulations using optical design software applied to specific lens designs.
3. Results
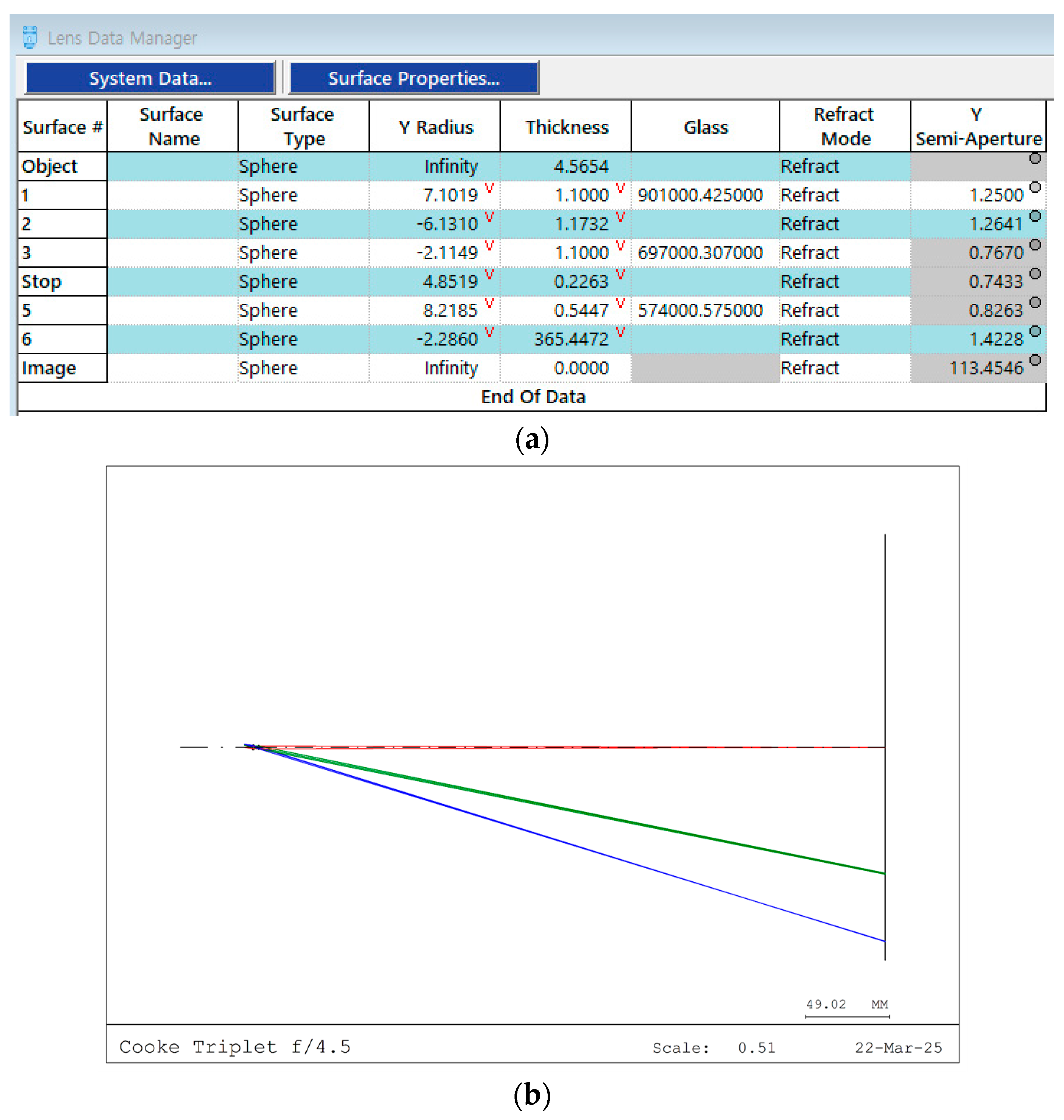
A design example of SPOCNN is presented in
Figure 2. The optical design was performed using CodeV (Ver. 2023.03). The initial design was based on US Patent 2,298,090 [
31], retrieved through the patent lens search feature in CodeV. This initial design consisted of a three-lens system with an infinite conjugate configuration. However, since SPOCNN operates as a finite conjugate system with a limited object distance, the lens arrangement was flipped and scaled to accommodate the maximum object height. The initial kernel array size was set to 61, as a larger array size closely approximates the infinite conjugate system of the original design. This similarity required fewer modifications during the optimization process when transitioning from an infinite to a finite conjugate system. The array size of 61 was chosen instead of 66—the scaling limit identified in the preliminary analysis—because 61 is an odd number that is close to both a multiple of ten and the scaling limit. Using an odd-sized array ensures symmetry around the central pixel.
The maximum object height is determined by the kernel array size and pixel pitch. Given that the pixel size and pitch are set to 10 μm and 40 μm, respectively, the side length of the kernel array measures 2.44 mm, which also defines the maximum lens diameter. The object heights were set at 0.0 mm, 1.24 mm, and 1.86 mm. Notably, the third field value of 1.86 mm slightly exceeds 1.72 mm, which represents the distance from the center to the corner of the kernel subarray. The effective focal length and entrance pupil diameter were set to 6.2 mm and 2.48 mm, respectively, yielding an f/# of 2.5. The design utilizes a wavelength of 850 nm.
The lens parameters were further optimized to minimize spot size while meeting target specifications, such as effective focal length and magnification. The final optimized lens data are shown in
Figure 2a, with the lens structure and its magnified view depicted in
Figure 2b and
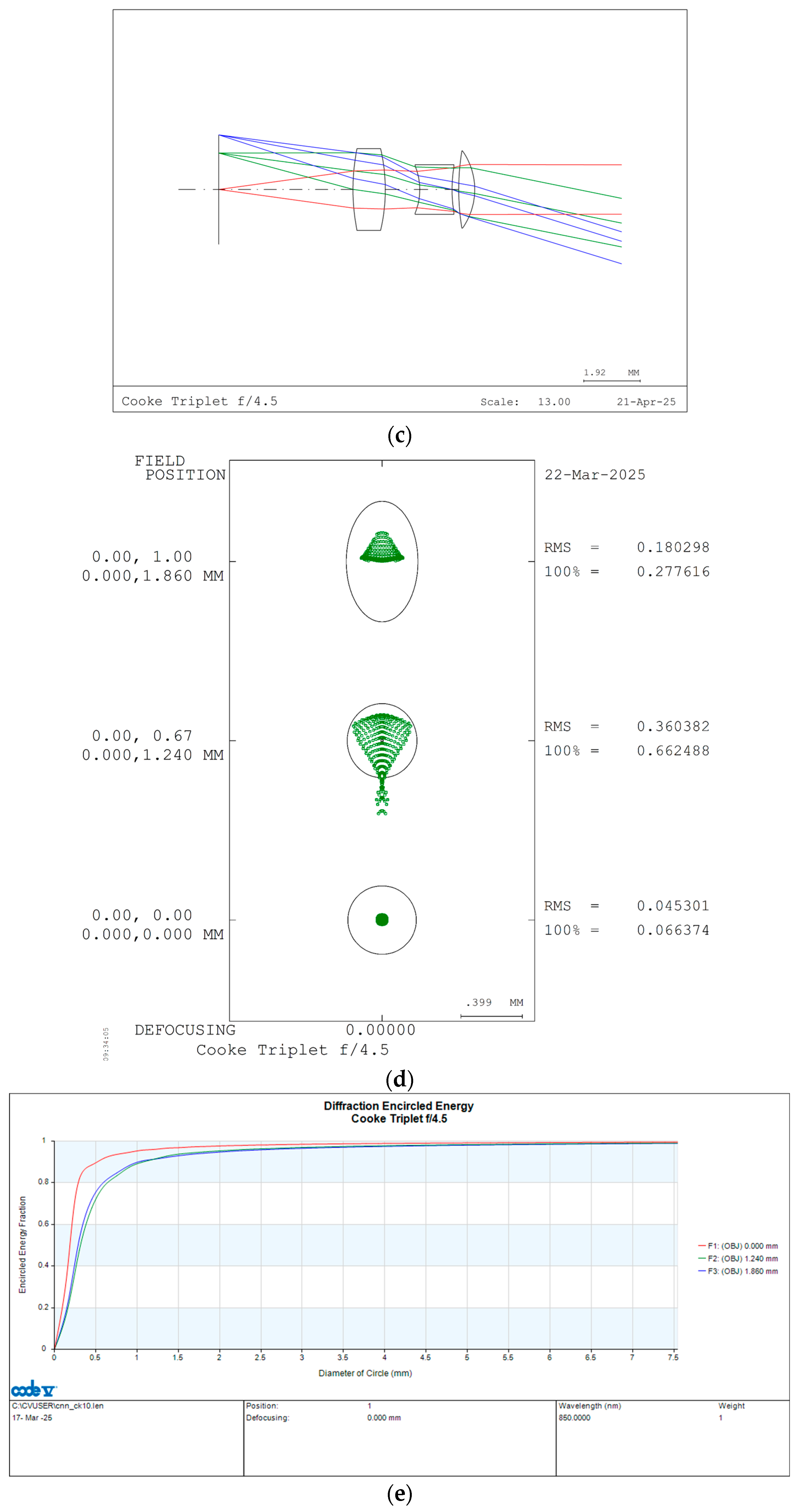
Figure 2c, respectively. The corresponding spot diagram and encircled energy diagram are displayed in
Figure 2d,e. As seen in the second field of
Figure 2d, the largest RMS spot diameter is 360 μm. Given that the distance from the last lens surface to the image plane is 365 mm, the resulting angular aberration is approximately 1 mrad. The encircled energy diameter, incorporating both geometric aberration and diffraction effects, is 647 μm, as shown in
Figure 2e. Within this diameter, 80% of the total energy is contained. The lens parameters and corresponding simulation results are available in the
Supplementary Materials.
In this design, the encircled energy diameter accounts for 26% of the detector pitch, which measures 2.48 mm. Considering that the geometric image of a pixel occupies 25% of the detector pitch, the remaining duty cycle is 49%, which can be utilized for alignment tolerance. This 49% duty cycle corresponds to 19.6 μm in the pixel plane, ensuring ease of alignment.
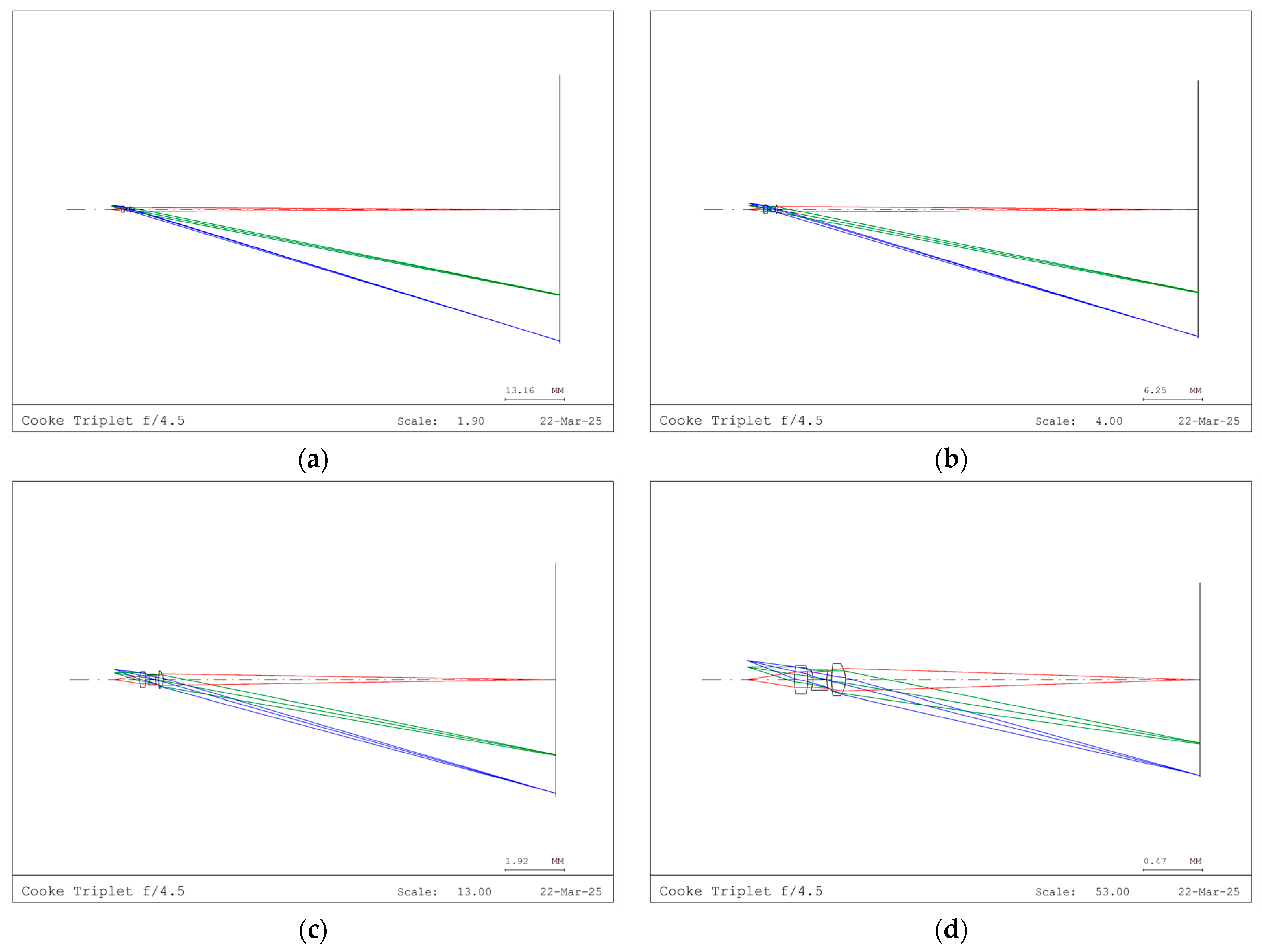
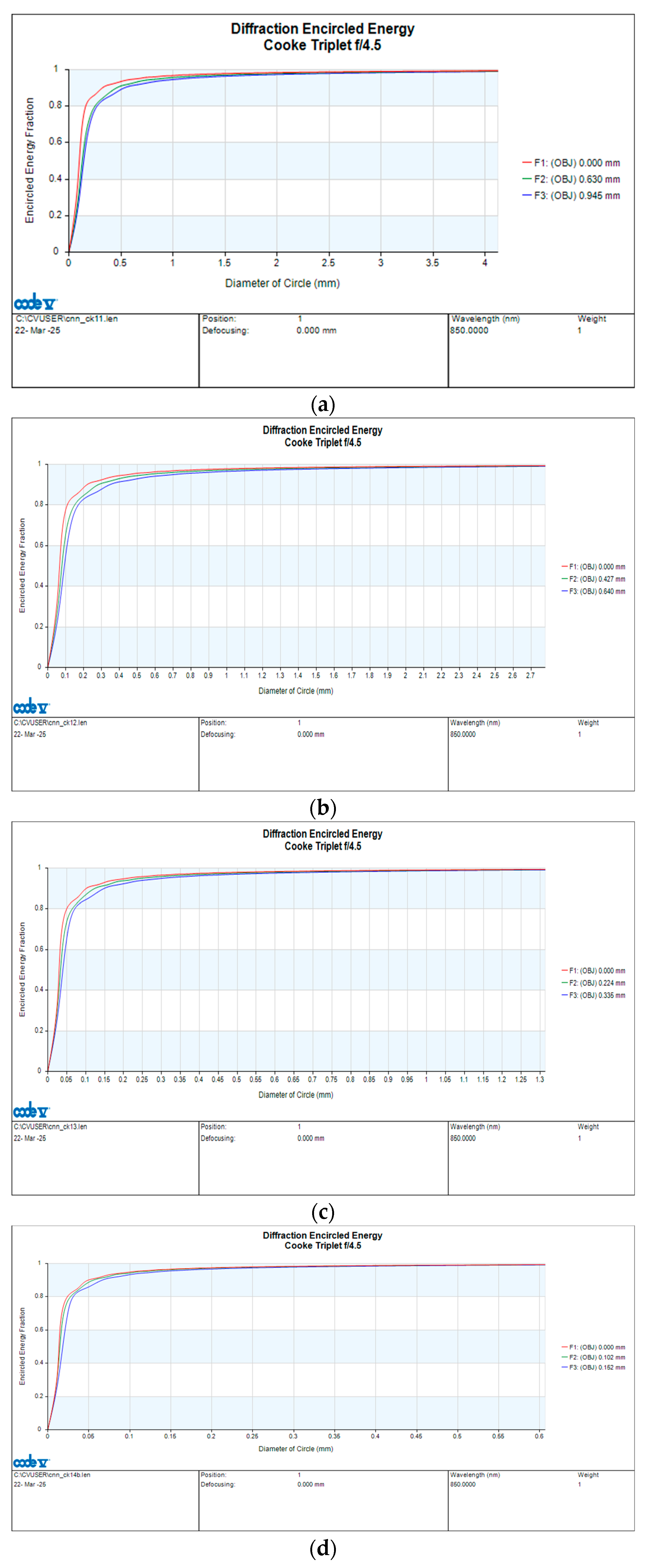
To demonstrate different kernel array sizes, we first scaled down and then reoptimized the lens parameters with reduced magnification constraints. The tested array sizes, or magnifications, included 31, 21, 11, and 5. The simulation results are presented as lens views, spot diagrams, and encircled energy diagrams, as shown in
Figure 3,
Figure 4 and
Figure 5, respectively. As the magnification decreases, the image distance decreases proportionally to the square of the scale-down factor, as illustrated in
Figure 3.
As shown in
Figure 4, the maximum RMS spot sizes occur in the second field rather than at the third field point. The resulting spot sizes are 94 μm, 45 μm, 16 μm, and 4 μm for magnifications (M) of 31, 21, 11, and 5, respectively. The spot size decreases approximately in proportion to the square of the scale-down factor, as predicted by the scaling analysis in the previous section. This result indicates that the angular aberration remains around 1 mrad, even after the reoptimization of the lens parameters.
As shown in
Figure 5, the encircled energy fractions are plotted as a function of diameter for various kernel sizes. As the kernel size decreases, the encircled energy diameter also decreases. Since the encircled energy diameter is determined by both aberration and diffraction, the final image size is the sum of this encircled energy diameter and the geometric image size. Therefore, this diameter can be used to assess the alignment tolerance for different kernel sizes.
4. Discussion
The simulation results for various kernel sizes are summarized in
Table 1. The encircled energy diameters were obtained from the software’s text output and can be converted into the duty cycle within the detector pitch using the detector pitch value. This duty cycle, along with the duty cycle of the geometric image size (25%), can be used to determine the remaining duty cycle available for alignment tolerance. Since the duty cycle within the detector pitch is equivalent to that within the pixel pitch, it can be converted into the alignment tolerance in the pixel plane, measured in micrometers, as shown in
Table 1.
For a kernel size of 31, the RMS spot diameter is 94 μm, accounting for 7.6% of the detector pitch. If the contribution of the RMS spot size is subtracted from the duty cycle of the encircled energy diameter (22%), the remaining duty cycle of 14% can be attributed to diffraction effects. The portion of aberration decreases approximately in proportion to the square of the scale-down factor. For a kernel size of 5, the RMS spot diameter is 4 μm, accounting for 2% of the detector pitch. Thus, the duty cycle attributed to diffraction remains approximately 14%, the same as that for a kernel size of 31. Although the diffraction duty cycle obtained from the simulation differs slightly from the 10% expected from the scaling analysis in the previous section, it remains consistent as the kernel size decreases.
The last column of
Table 1 shows the alignment tolerance in the pixel plane. Although it decreases as the kernel size increases, it does not reach the critical level of difficulty for the array size of 61 × 61. In the scaling analysis of the previous section, a kernel size of 66 has an alignment tolerance of only 5 μm, which is considered the limit of practical alignment. It may be ascribed to the different assumption of the angular aberration of the three-element lens. The angular aberrations of the designs in the simulation are usually about 1 mrad, which is 3 times smaller than that assumed in the preliminary scaling analysis. If an angular aberration of 1 mrad had been assumed instead of 3 mrad, the image spread caused by geometric aberration would have accounted for 14.6% of the detector pitch, rather than 43.8%, for the array size of 61 × 61. Given that the image spreads due to geometric image size and diffraction are 25% and 10.2% of the detector pitch, respectively, the remaining alignment tolerance would be 50.2%. This indicates that the 61 × 61 array size remains well below the scaling limit, as does the 66 × 66 array.
Therefore, the actual optical designs confirm that an array size of 61 × 61 is feasible for the SPOCNN architecture with a reasonable alignment tolerance. They also validate that the previous scaling analysis is generally accurate in predicting the trends of image spread caused by geometric aberration and diffraction as the kernel array size increases.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}