
Biased by Design? Evaluating Bias and Behavioral Diversity in LLM Annotation of Real-World and Synthetic Hotel Reviews



Abstract
1. Introduction
2. Literature Review
2.1. Biases in AI Systems
Types of Biases in AI Systems
2.2. Human vs. AI Annotator Biases

{kind=link}
{kind=link}
{kind=link}
| Study | Domain | Source | Mode | Task | Annotators | Key Findings |
|---|---|---|---|---|---|---|
| Giorgi et al. [12] | Hate speech/Social media posts | Real | Batch | Hate speech labeling (not hate/maybe/hate) | Humans: crowdworkers; LLMs: Llama3, Phi3, Solar, Starling | Humans show biases (age, religion, gender identity); LLMs exhibit fewer annotator-like biases but still misreport by simulated persona (e.g., underreported by Christian/straight, overreport by gay/bisexual personas). |
| Felkner et al. [11] | Fairness/Survey responses | Real & Synthetic | N/A | Bias benchmark construction (Jewish Community Survey) | Humans: Jewish Community Survey; LLMs: ChatGPT-3.5 | All LMs showed significant antisemitic bias (avg. 69% vs. ideal 50%), higher on Jewish women/mothers and Israel/Palestine topics. LLM-extracted predicates often hallucinated, and were repetitive and poorly aligned with human annotations. |
| Nasution & Onan [21] | Multilingual/Tweets | Real | Batch | Topic classification, sentiment analysis, emotion classification | Humans: native speakers, crowdworkers; LLMs: ChatGPT-4, BERT, RoBERTa, T5 | Humans outperform LLMs on topic and emotion (higher precision/recall); LLMs competitive on sentiment (i.e., ChatGPT-4, BERTurk); both struggle with fear/neutral; ChatGPT-4 shows promise for low-resource languages. |
| Wang et al. [43] | Gen. NLP/Sentence pairs, social media posts | Real | N/A | NLI, stance detection, hate speech detection | Humans, verifier models, LLMs | Verifier-assisted human reannotation improves accuracy (+7–8%) over LLM-only; LLM explanations help when correct but mislead otherwise; increases cognitive load without improving perceived trust. |
| Zendel et al. [41] | Info. retrieval/TREC topics | Real | Batch & Manual | Cognitive complexity classification (Remember/Understand/Analyze) | Humans: expert-annotated benchmark; LLMs: ChatGPT-3.5/4 | ChatGPT-4 stable and matches human quality; 3.5 less consistent and sensitive to batch order. Batch mode reduces time/cost without significant loss of quality. ChatGPT-4 effective as additional annotator. |
| Aldeen et al. [42] | Multi-task/Web, social media posts | Real | Batch | 10 classification tasks: sentiment, emotion, spam, sarcasm, topic, etc. | Humans: benchmark datasets; LLMs: ChatGPT-3.5/4 | ChatGPT performs better on formal tasks (e.g., banking, websites); weaker on informal/casual tasks (sarcasm, emotion); still competitive on some informal tasks with explicit cues (e.g., Amazon reviews, Twitter topics). |
| Mohta et al. [20] | Multimodal/Image-text, text pairs | Real | N/A | Movie genre, hate speech, NLI, binary internal tasks | Humans: crowdworkers; LLMs: Llama2, Vicuna-v1.5 | Humans outperform LLMs; fine-tuned Vicuna better than base Llama; images improve response rates but not accuracy. |
| Current Study | Hospitality/Hotel booking reviews | Real & Synthetic | Batch & Manual | Sentiment, aspect, topic classification | Humans: domain expert; LLMs: ChatGPT-3.5/4 | LLMs showed high internal agreement; moderate with human on sentiment (real); low on aspects and synthetic data; manual mode improved agreement, revealing mode- and data-driven biases. |
2.3. Large Language Models and Synthetic Data
3. Materials and Methods
3.1. Real Review Data
3.2. Real Review Data Annotation
3.3. Synthetic Review Data Generation
3.4. Synthetic Review Data Annotation
4. Results
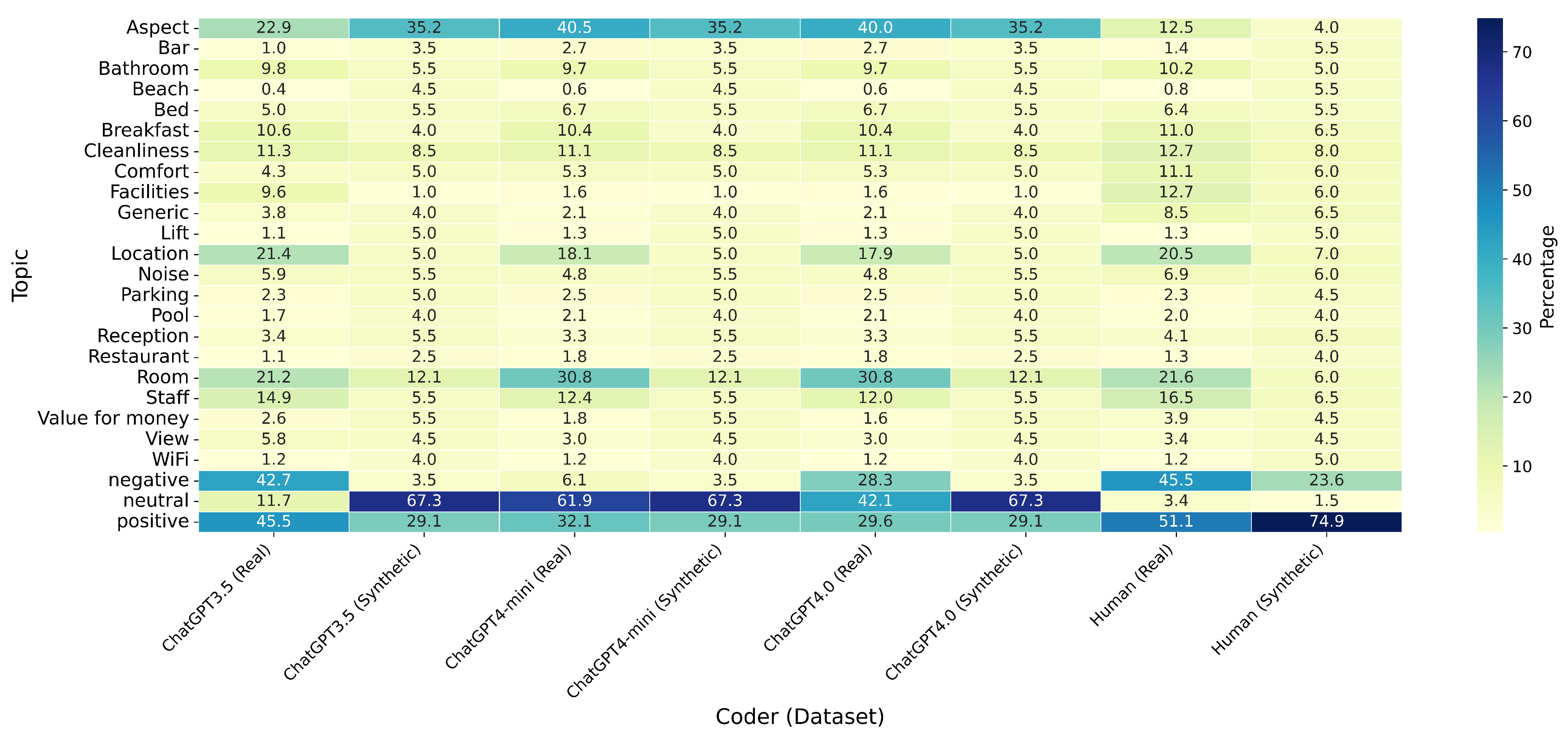
4.1. Descriptive Statistics
4.2. Hypothesis Testing
5. Discussion
5.1. Theoretical Contribution
5.2. Methodological Contribution
5.3. Practical Contribution
5.4. Limitations and Future Research
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| Abbreviation | Definition |
| AI | Artificial Intelligence |
| LLM | Large Language Model |
| HRAST | Hotel Reviews: Aspects, Sentiments, and Topics |
| CSV | Comma-Separated Values |
| AUC | Area Under the ROC Curve |
| ROC | Receiver Operating Characteristic |
| GPT | Generative Pre-trained Transformer |
| SE | Standard Error |
| SD | Standard Deviation |
| M | Mean |
| p | p-value (probability value) |
Appendix A
Appendix A.1. Annotation Protocol and Prompt Design for LLM-Based Labeling
- The breakfast was poor but the staff was very helpful
- The breakfast was decent and the room was quiet
- The breakfast was rich but quite expensive
- Room
- Location
- Staff
- Cleanliness
- Comfort
- Facilities/Amenities
- Breakfast
- Bathroom/Shower (toilet)
- Bed
- Noise
- Value for money
- Generic (design, architecture, building, atmosphere, etc.)
- View (Balcony)
- Parking
- Bar
- Pool
- Restaurant (dinner)
- Reception (check-in, check-out, etc.)
- Lift
- Wi-Fi
- Beach
- None
- Room
- Location
- Staff
- Cleanliness
- Comfort
- Facilities/Amenities
- Breakfast
- Bathroom/Shower (toilet)
- Bed
- Noise
- Value for money
- Generic (design, architecture, building, atmosphere, etc.)
- View (Balcony)
- Parking
- Bar
- Pool
- Restaurant (dinner)
- Reception (check-in, check-out, etc.)
- Lift
- Wi-Fi
- Beach
- None
Appendix A.2. Prompt Design for Synthetic Hotel Review Generation Using LLMs
- Be concise and natural, reflecting typical guest feedback
- Contain no more than 30 words
- Be written in the style of real booking reviews
- Include 500 positive and 500 negative sentences
- Room
- Location
- Staff
- Cleanliness
- Comfort
- Facilities/Amenities
- Breakfast
- Bathroom/Shower (toilet)
- Bed
- Noise
- Value for money
- Generic (design, architecture, building, atmosphere, etc.)
- View (Balcony)
- Parking
- Bar
- Pool
- Restaurant (dinner)
- Reception (check-in, check-out, etc.)
- Lift
- Wi-Fi
- Beach
- Combine positive and negative sentiments about the same topic, or
- Refer to multiple topics within the same sentence.
- The breakfast was poor but the staff was very helpful.
- The breakfast was decent and the room was quiet.
- The breakfast was rich but quite expensive.
- Format: CSV
- Each row should contain a single sentence only
- Do not include headers or additional text
References
- Milwood, P.A.; Hartman-Caverly, S.; Roehl, W.S. A scoping study of ethics in artificial intelligence research in tourism and hospitality. In ENTER22 e-Tourism Conference; Springer: Berlin/Heidelberg, Germany, 2023; pp. 243–254. [Google Scholar]
- Wang, P.Q. Personalizing guest experience with generative AI in the hotel industry: There’s more to it than meets a Kiwi’s eye. Curr. Issues Tour. 2024, 28, 527–544. [Google Scholar] [CrossRef]
- Wüst, K.; Bremser, K. Artificial Intelligence in Tourism Through Chatbot Support in the Booking Process—An Experimental Investigation. Tour. Hosp. 2025, 6, 36. [Google Scholar] [CrossRef]
- Kouros, T.; Theodosiou, Z.; Themistocleous, C. Machine Learning Bias: Genealogy, Expression and Prevention; CABI Books: Bognor Regis, UK, 2025; pp. 113–126. [Google Scholar] [CrossRef]
- Akter, S.; McCarthy, G.; Sajib, S.; Michael, K.; Dwivedi, Y.K.; D’Ambra, J.; Shen, K.N. Algorithmic bias in data-driven innovation in the age of AI. Int. J. Inf. Manag. 2021, 60, 102387. [Google Scholar] [CrossRef]
- Kordzadeh, N.; Ghasemaghaei, M. Algorithmic bias: Review, synthesis, and future research directions. Eur. J. Inf. Syst. 2021, 31, 388–409. [Google Scholar] [CrossRef]
- Chen, Y.; Clayton, E.W.; Novak, L.L.; Anders, S.; Malin, B. Human-Centered Design to Address Biases in Artificial Intelligence. J. Med. Internet Res. 2023, 25, e43251. [Google Scholar] [CrossRef]
- Haliburton, L.; Ghebremedhin, S.; Welsch, R.; Schmidt, A.; Mayer, S. Investigating labeler bias in face annotation for machine learning. In HHAI 2024: Hybrid Human AI Systems for the Social Good; IOS Press: Amsterdam, The Netherlands, 2024; pp. 145–161. [Google Scholar]
- Parmar, M.; Mishra, S.; Geva, M.; Baral, C. Don’t blame the annotator: Bias already starts in the annotation instructions. arXiv 2022, arXiv:2205.00415. [Google Scholar]
- Das, A.; Zhang, Z.; Hasan, N.; Sarkar, S.; Jamshidi, F.; Bhattacharya, T.; Rahgouy, M.; Raychawdhary, N.; Feng, D.; Jain, V. Investigating annotator bias in large language models for hate speech detection. In Proceedings of the Neurips Safe Generative AI Workshop 2024, Vancouver, BC, Canada, 15 December 2024. [Google Scholar]
- Felkner, V.K.; Thompson, J.A.; May, J. Gpt is not an annotator: The necessity of human annotation in fairness benchmark construction. arXiv 2024, arXiv:2405.15760. [Google Scholar]
- Giorgi, T.; Cima, L.; Fagni, T.; Avvenuti, M.; Cresci, S. Human and LLM biases in hate speech annotations: A socio-demographic analysis of annotators and targets. In Proceedings of the International AAAI Conference on Web and Social Media, Copenhagen, Denmark, 23–26 June 2025; pp. 653–670. [Google Scholar]
- Gonzales, A.; Guruswamy, G.; Smith, S.R. Synthetic data in health care: A narrative review. PLoS Digit. Health 2023, 2, e0000082. [Google Scholar] [CrossRef]
- Kozinets, R.V.; Gretzel, U. Commentary: Artificial Intelligence: The Marketer’s Dilemma. J. Mark. 2020, 85, 156–159. [Google Scholar] [CrossRef]
- Li, Z.; Zhu, H.; Lu, Z.; Yin, M. Synthetic data generation with large language models for text classification: Potential and limitations. arXiv 2023, arXiv:2310.07849. [Google Scholar]
- Nikolenko, S.I. Synthetic Data for Deep Learning; Springer: Berlin/Heidelberg, Germany, 2021; Volume 174. [Google Scholar]
- Guo, X.; Chen, Y. Generative ai for synthetic data generation: Methods, challenges and the future. arXiv 2024, arXiv:2403.04190. [Google Scholar]
- Andreou, C.; Tsapatsoulis, N.; Anastasopoulou, V. A Dataset of Hotel Reviews for Aspect-Based Sentiment Analysis and Topic Modeling. In Proceedings of the 2023 18th International Workshop on Semantic and Social Media Adaptation & Personalization (SMAP) 18th International Workshop on Semantic and Social Media Adaptation & Personalization (SMAP 2023), Limassol, Cyprus, 25–26 September 2023. [Google Scholar] [CrossRef]
- Herrera-Poyatos, D.; Peláez-González, C.; Zuheros, C.; Herrera-Poyatos, A.; Tejedor, V.; Herrera, F.; Montes, R. An overview of model uncertainty and variability in LLM-based sentiment analysis. Challenges, mitigation strategies and the role of explainability. arXiv 2025, arXiv:2504.04462. [Google Scholar]
- Mohta, J.; Ak, K.; Xu, Y.; Shen, M. Are large language models good annotators? In Proceedings of the NeurIPS 2023 Workshops, New Orleans, LA, USA, 16 December 2023; pp. 38–48. [Google Scholar]
- Nasution, A.H.; Onan, A. Chatgpt label: Comparing the quality of human-generated and llm-generated annotations in low-resource language nlp tasks. IEEE Access 2024, 12, 71876–71900. [Google Scholar] [CrossRef]
- Kar, A.K.; Choudhary, S.K.; Singh, V.K. How can artificial intelligence impact sustainability: A systematic literature review. J. Clean. Prod. 2022, 376, 134120. [Google Scholar] [CrossRef]
- Bacalhau, L.M.; Pereira, M.C.; Neves, J. A bibliometric analysis of AI bias in marketing: Field evolution and future research agenda. J. Mark. Anal. 2025, 13, 308–327. [Google Scholar] [CrossRef]
- Roselli, D.; Matthews, J.; Talagala, N. Managing Bias in AI. In Proceedings of the WWW’19: Companion Proceedings of the 2019 World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019. [Google Scholar] [CrossRef]
- Varsha, P.S. How can we manage biases in artificial intelligence systems—A systematic literature review. Int. J. Inf. Manag. Data Insights 2023, 3, 100165. [Google Scholar] [CrossRef]
- Oxford English Dictionary. Bias, n., sense 3.c. Available online: https://doi.org/10.1093/OED/4832698884 (accessed on 27 June 2025).
- Smith, J.; Noble, H. Bias in research. Evid. Based Nurs. 2014, 17, 100–101. [Google Scholar] [CrossRef] [PubMed]
- Delgado-Rodriguez, M.; Llorca, J. Bias. J. Epidemiol. Community Health 2004, 58, 635–641. [Google Scholar] [CrossRef]
- Nazer, L.H.; Zatarah, R.; Waldrip, S.; Ke, J.X.C.; Moukheiber, M.; Khanna, A.K.; Hicklen, R.S.; Moukheiber, L.; Moukheiber, D.; Ma, H.; et al. Bias in artificial intelligence algorithms and recommendations for mitigation. PLoS Digit. Health 2023, 2, e0000278. [Google Scholar] [CrossRef]
- Spennemann, D.H. Who Is to Blame for the Bias in Visualizations, ChatGPT or DALL-E? AI 2025, 6, 92. [Google Scholar] [CrossRef]
- Gupta, O.; Marrone, S.; Gargiulo, F.; Jaiswal, R.; Marassi, L. Understanding Social Biases in Large Language Models. AI 2025, 6, 106. [Google Scholar] [CrossRef]
- Gautam, S.; Srinath, M. Blind spots and biases: Exploring the role of annotator cognitive biases in NLP. arXiv 2024, arXiv:2404.19071. [Google Scholar]
- Pandey, R.; Castillo, C.; Purohit, H. Modeling human annotation errors to design bias-aware systems for social stream processing. In Proceedings of the 2019 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, Vancouver, BC, Canada, 27–30 August 2019; pp. 374–377. [Google Scholar]
- Reason, J. Human error: Models and management. BMJ 2000, 320, 768–770. [Google Scholar] [CrossRef]
- Reason, J. Human Error; Cambridge University Press: Cambridge, UK, 1990. [Google Scholar]
- Ntalianis, K.; Tsapatsoulis, N.; Doulamis, A.; Matsatsinis, N. Automatic annotation of image databases based on implicit crowdsourcing, visual concept modeling and evolution. Multimed. Tools Appl. 2014, 69, 397–421. [Google Scholar] [CrossRef]
- Giannoulakis, S.; Tsapatsoulis, N. Filtering Instagram Hashtags Through Crowdtagging and the HITS Algorithm. IEEE Trans. Comput. Soc. Syst. 2019, 6, 592–603. [Google Scholar] [CrossRef]
- Geva, M.; Goldberg, Y.; Berant, J. Are we modeling the task or the annotator? An investigation of annotator bias in natural language understanding datasets. arXiv 2019, arXiv:1908.07898. [Google Scholar]
- Kuwatly, H.; Wich, M.; Groh, G. Identifying and measuring annotator bias based on annotators’ demographic characteristics. In Proceedings of the Fourth Workshop on Online Abuse and Harms; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 184–190. [Google Scholar]
- Siriborvornratanakul, T. From Human Annotators to AI: The Transition and the Role of Synthetic Data in AI Development. In Proceedings of the International Conference on Human-Computer Interaction, Gothenburg, Sweden, 22–27 June 2025; pp. 379–390. [Google Scholar]
- Zendel, O.; Culpepper, J.S.; Scholer, F.; Thomas, P. Enhancing human annotation: Leveraging large language models and efficient batch processing. In Proceedings of the 2024 Conference on Human Information Interaction and Retrieval, Sheffield, UK, 10–14 March 2024; pp. 340–345. [Google Scholar]
- Aldeen, M.; Luo, J.; Lian, A.; Zheng, V.; Hong, A.; Yetukuri, P.; Cheng, L. Chatgpt vs. human annotators: A comprehensive analysis of chatgpt for text annotation. In Proceedings of the 2023 International Conference on Machine Learning and Applications (ICMLA), Jacksonville, FL, USA, 15–17 December 2023; pp. 602–609. [Google Scholar]
- Wang, X.; Kim, H.; Rahman, S.; Mitra, K.; Miao, Z. Human-llm collaborative annotation through effective verification of llm labels. In Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 11–16 May 2024; pp. 1–21. [Google Scholar]
- Ferrara, E. Fairness and Bias in Artificial Intelligence: A Brief Survey of Sources, Impacts, and Mitigation Strategies. Sci 2023, 6, 3. [Google Scholar] [CrossRef]
- Djouvas, C.; Charalampous, A.; Christodoulou, C.J.; Tsapatsoulis, N. LLMs are not for everything: A Dataset and Comparative Study on Argument Strength Classification. In Proceedings of the 28th Pan-Hellenic Conference on Progress in Computing and Informatics, Athens, Greece, 13–15 December 2024; pp. 437–443. [Google Scholar]
- Chan, Y.C.; Pu, G.; Shanker, A.; Suresh, P.; Jenks, P.; Heyer, J.; Denton, S. Balancing cost and effectiveness of synthetic data generation strategies for llms. arXiv 2024, arXiv:2409.19759. [Google Scholar]
- Muñoz-Ortiz, A.; Gómez-Rodríguez, C.; Vilares, D. Contrasting linguistic patterns in human and LLM-generated news text. Artif. Intell. Rev. 2024, 57, 265. [Google Scholar] [CrossRef]
- Yadav, R.K.; Jiao, L.; Granmo, O.C.; Goodwin, M. Human-level interpretable learning for aspect-based sentiment analysis. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2021; Volume 35, pp. 14203–14212. [Google Scholar]
- Jia, S.; Chi, O.H.; Chi, C.G. Unpacking the impact of AI vs. human-generated review summary on hotel booking intentions. Int. J. Hosp. Manag. 2025, 126, 104030. [Google Scholar] [CrossRef]
- Sparks, B.A.; Browning, V. The impact of online reviews on hotel booking intentions and perception of trust. Tour. Manag. 2011, 32, 1310–1323. [Google Scholar] [CrossRef]
- O’Connor, C.; Joffe, H. Intercoder Reliability in Qualitative Research: Debates and Practical Guidelines. Int. J. Qual. Methods 2020, 19, 1609406919899220. [Google Scholar] [CrossRef]
- Gisev, N.; Bell, J.S.; Chen, T.F. Interrater agreement and interrater reliability: Key concepts, approaches, and applications. Res. Soc. Adm. Pharm. 2013, 9, 330–338. [Google Scholar] [CrossRef] [PubMed]
- Landis, J.R.; Koch, G.G. The Measurement of Observer Agreement for Categorical Data. Biometrics 1977, 33, 159–174. [Google Scholar] [CrossRef] [PubMed]
- Huo, F.Y.; Johnson, N.F. Capturing AI’s Attention: Physics of Repetition, Hallucination, Bias and Beyond. arXiv 2025, arXiv:2504.04600. [Google Scholar]
- Arora, K.; Asri, L.E.; Bahuleyan, H.; Cheung, J.C.K. Why exposure bias matters: An imitation learning perspective of error accumulation in language generation. arXiv 2022, arXiv:2204.01171. [Google Scholar]
- Li, L.; Sleem, L.; Gentile, N.; Nichil, G.; State, R. Exploring the Impact of Temperature on Large Language Models: Hot or Cold? arXiv 2025, arXiv:2506.07295. [Google Scholar]
- Peeperkorn, M.; Kouwenhoven, T.; Brown, D.; Jordanous, A. Is temperature the creativity parameter of large language models? arXiv 2024, arXiv:2405.00492. [Google Scholar]
- Nishu, K.; Mehta, S.; Abnar, S.; Farajtabar, M.; Horton, M.; Najibi, M.; Nabi, M.; Cho, M.; Naik, D. From Dense to Dynamic: Token-Difficulty Driven MoEfication of Pre-Trained LLMs. arXiv 2025, arXiv:2502.12325. [Google Scholar]
- Behera, A.P.; Champati, J.P.; Morabito, R.; Tarkoma, S.; Gross, J. Towards Efficient Multi-LLM Inference: Characterization and Analysis of LLM Routing and Hierarchical Techniques. arXiv 2025, arXiv:2506.06579. [Google Scholar]
- Macdonald, S.; Birdi, B. The concept of neutrality: A new approach. J. Doc. 2019, 76, 333–353. [Google Scholar] [CrossRef]
- Donohue, G.A.; Tichenor, P.J.; Olien, C.N. Gatekeeping: Mass media systems and information control. Curr. Perspect. Mass Commun. Res. 1972, 1, 41–70. [Google Scholar]
- Pryzant, R.; Martinez, R.D.; Dass, N.; Kurohashi, S.; Jurafsky, D.; Yang, D. Automatically neutralizing subjective bias in text. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 480–489. [Google Scholar]
- Snow, R.; O’connor, B.; Jurafsky, D.; Ng, A.Y. Cheap and fast–but is it good? evaluating non-expert annotations for natural language tasks. In Proceedings of the 2008 Conference on Empirical Methods in Natural Language Processing, Honolulu, HI, USA, 25–27 October 2008; pp. 254–263. [Google Scholar]
- Nowak, S.; Rüger, S. How reliable are annotations via crowdsourcing: A study about inter-annotator agreement for multi-label image annotation. In Proceedings of the International Conference on Multimedia Information Retrieval, Philadelphia, PA, USA, 29–31 March 2010; pp. 557–566. [Google Scholar]
- Wardhani, N.W.S.; Rochayani, M.Y.; Iriany, A.; Sulistyono, A.D.; Lestantyo, P. Cross-validation metrics for evaluating classification performance on imbalanced data. In Proceedings of the 2019 International Conference on Computer, Control, Informatics and Its Applications (IC3INA), Tangerang, Indonesia, 23–24 October 2019; pp. 14–18. [Google Scholar]
- Rasool, A.; Shahzad, M.I.; Aslam, H.; Chan, V.; Arshad, M.A. Emotion-aware embedding fusion in large language models (Flan-T5, Llama 2, DeepSeek-R1, and ChatGPT 4) for intelligent response generation. AI 2025, 6, 56. [Google Scholar] [CrossRef]
- Thormundsson, B.S.R.T. Artificial Intelligence Tools Popularity in the United States as of September 2024, by Brand. 2024. Available online: https://www.statista.com/forecasts/1480449/ai-tools-popularity-share-usa-adults (accessed on 15 July 2025).

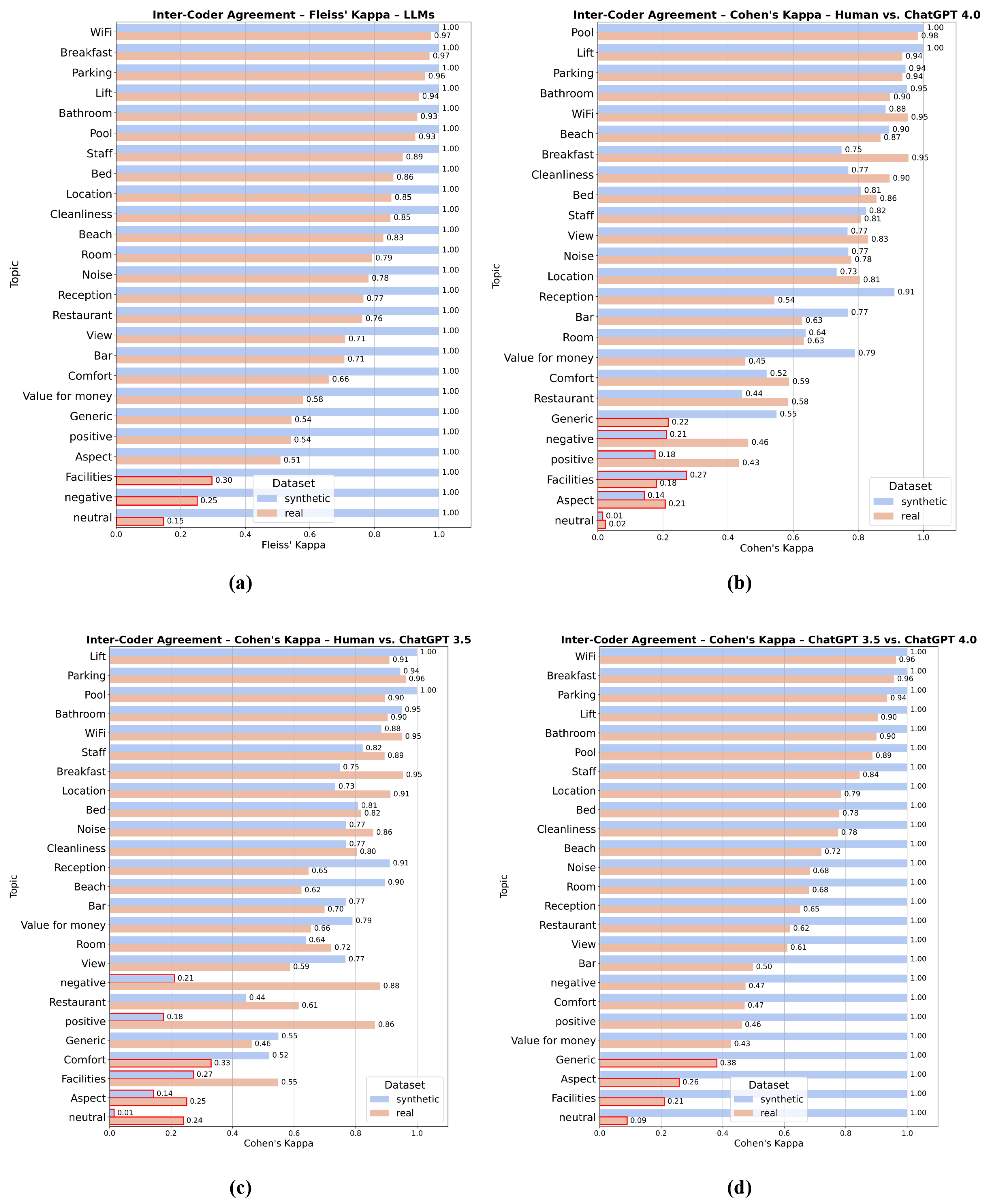
| Variable | Cohen’s | Asympt. SE | Approx. T | Approx. Sig. |
|---|---|---|---|---|
| Neutral | 0.109 | 0.004 | 27.49 | <0.001 |
| Negative | 0.201 | 0.004 | 48.75 | <0.001 |
| Aspect | 0.244 | 0.007 | 46.73 | <0.001 |
| Facilities | 0.270 | 0.011 | 54.55 | <0.001 |
| Generic | 0.381 | 0.017 | 6.69 | <0.001 |
| Comfort | 0.423 | 0.014 | 64.43 | <0.001 |
| Bar | 0.498 | 0.021 | 84.94 | <0.001 |
| Positive | 0.535 | 0.006 | 82.44 | <0.001 |
| View | 0.610 | 0.013 | 97.89 | <0.001 |
| Restaurant | 0.619 | 0.022 | 96.55 | <0.001 |
| Reception | 0.667 | 0.014 | 101.46 | <0.001 |
| Value For Money | 0.672 | 0.015 | 102.45 | <0.001 |
| Room | 0.681 | 0.005 | 106.75 | <0.001 |
| Noise | 0.683 | 0.011 | 104.38 | <0.001 |
| Beach | 0.721 | 0.033 | 113.11 | <0.001 |
| Cleanliness | 0.775 | 0.007 | 117.87 | <0.001 |
| Bed | 0.795 | 0.009 | 123.00 | <0.001 |
| Location | 0.802 | 0.005 | 122.23 | <0.001 |
| Staff | 0.827 | 0.005 | 125.76 | <0.001 |
| Pool | 0.887 | 0.011 | 135.52 | <0.001 |
| Bathroom | 0.900 | 0.005 | 136.87 | <0.001 |
| Lift | 0.904 | 0.013 | 137.80 | <0.001 |
| Parking | 0.945 | 0.007 | 143.65 | <0.001 |
| Breakfast | 0.958 | 0.003 | 145.69 | <0.001 |
| WiFi | 0.963 | 0.008 | 146.34 | <0.001 |
| Dataset | Example | Human | ChatGPT-3.5 (1-1) | ChatGPT-3.5 (Batch) | ChatGPT-4 | ChatGPT-4-mini | Agr. |
|---|---|---|---|---|---|---|---|
| real | Air conditioning worked well. | positive | positive | neutral | neutral | neutral | no |
| facilities | facilities | none | none | none | |||
| no | no | no | no | no | |||
| real | Basic restaurant with limited choice. | negative | negative | neutral | neutral | neutral | no |
| restaurant | restaurant | restaurant | restaurant | restaurant | |||
| no | no | no | no | no | |||
| real | No fresh air and AC didn’t work the first night. | negative | negative | neutral | negative | neutral | no |
| room, facilities | room | room, facilities | room | room | |||
| no | yes | yes | yes | yes | |||
| real | At breakfast I was asked for €6 for juice. | negative | negative | neutral | neutral | neutral | no |
| breakfast, value for money | breakfast, value for money | breakfast | breakfast | breakfast | |||
| no | yes | no | no | no | |||
| real | Very poor noise cancellation. | negative | negative | negative | negative | negative | yes |
| noise | noise | noise | noise | noise | |||
| no | no | no | no | no | |||
| real | Lack of physical and relational contact. | negative | neutral | neutral | neutral | neutral | no |
| staff | staff | none | none | none | |||
| no | no | no | yes | yes | |||
| synthetic | Slept like a baby on that bed. | positive | N/A | neutral | neutral | neutral | no |
| bed | N/A | bed | bed | bed | |||
| no | N/A | no | no | no | |||
| synthetic | Beautifully designed interior and exterior. | positive | N/A | neutral | neutral | neutral | no |
| generic | N/A | generic | generic | generic | |||
| no | N/A | yes | yes | yes | |||
| synthetic | Great spot near all attractions. | positive | N/A | positive | positive | positive | no |
| location | N/A | none | none | none | |||
| no | N/A | no | no | no | |||
| synthetic | Reception staff were disorganized. | negative | N/A | neutral | neutral | neutral | no |
| staff, reception | N/A | staff, reception | staff, reception | staff, reception | |||
| no | N/A | no | no | no | |||
| synthetic | Location was inconvenient. | negative | N/A | neutral | neutral | neutral | no |
| location | N/A | location | location | location | |||
| no | N/A | no | no | no | |||
| synthetic | Affordable without compromising quality. | positive | N/A | positive | positive | positive | yes |
| value for money | N/A | value for money | value for money | value for money | |||
| no | N/A | no | no | no |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Voutsa, M.C.; Tsapatsoulis, N.; Djouvas, C. Biased by Design? Evaluating Bias and Behavioral Diversity in LLM Annotation of Real-World and Synthetic Hotel Reviews. AI 2025, 6, 178. https://doi.org/10.3390/ai6080178
Voutsa MC, Tsapatsoulis N, Djouvas C. Biased by Design? Evaluating Bias and Behavioral Diversity in LLM Annotation of Real-World and Synthetic Hotel Reviews. AI. 2025; 6(8):178. https://doi.org/10.3390/ai6080178
Chicago/Turabian StyleVoutsa, Maria C., Nicolas Tsapatsoulis, and Constantinos Djouvas. 2025. "Biased by Design? Evaluating Bias and Behavioral Diversity in LLM Annotation of Real-World and Synthetic Hotel Reviews" AI 6, no. 8: 178. https://doi.org/10.3390/ai6080178
APA StyleVoutsa, M. C., Tsapatsoulis, N., & Djouvas, C. (2025). Biased by Design? Evaluating Bias and Behavioral Diversity in LLM Annotation of Real-World and Synthetic Hotel Reviews. AI, 6(8), 178. https://doi.org/10.3390/ai6080178