1. Introduction
The Panel Assignment Problem (PAP) is a subclass of the General Assignment Problem (GAP), which involves the allocation of tasks (e.g., reviews) to reviewers while satisfying multiple constraints [
1,
2]. The PAP is a combinatorial optimization problem commonly found in peer review systems, workforce allocation, and decision-making tasks [
3,
4]. The primary objectives of solutions to the PAP include fairness, workload balance, expertise maximization, and conflict avoidance. The PAP is a combinatorial optimization challenge categorized as NP-hard (nondeterministic polynomial time), meaning that in computational complexity theory, finding a solution may not always be feasible within polynomial time. Such NP-hard problems are widespread in operations research and manufacturing industries, where they arise in various operational and strategic decision-making scenarios. Developing and implementing effective solution approaches, including optimization algorithms, heuristic strategies, and Artificial Intelligence (AI)-based techniques, can provide substantial advantages. By utilizing the methods proposed in this study, industries can enhance operational efficiency and sustain competitiveness in an increasingly dynamic environment. Several optimization and heuristic techniques have been proposed to solve the PAP, and these include the following: (1) Greedy algorithms [
5]—which make locally optimal choices at each step but may not guarantee global optimality, (2) Optimization-based Integer Linear Programming (ILP) [
6]—which provides globally optimal solutions but can be computationally expensive at larger-scale problem sizes, (3) Constraint Programming (CP) [
7]—which handles complex constraints efficiently but can be slow for large problems, (4) Heuristic methods [
8]—which are computationally efficient but may not yield optimal results (e.g., simulated annealing), (5) Bipartite matching [
9] (Hungarian algorithm)—which can offer an optimal assignment in polynomial time, (6) Branch and Bound [
10]—which guarantees an optimal solution but is slow for large-scale problems, (7) Genetic algorithms [
3,
11,
12]—which are search-based optimization techniques inspired by natural selection that can explore a large parametric space but can be slow to converge, and (8) Hybrid approaches [
4,
8,
13]—which combine the different techniques listed above to leverage their different strengths.
1.1. Related Work and Motivation
Natural Language Processing (NLP) and its subset Large Language Modeling (LLM) [
2,
14,
15,
16] present an alternative paradigm to optimization and Heuristic-based approaches by leveraging data-driven capabilities to enhance efficiency, scalability, and flexibility in solving the PAP. Since panel assignments often depend on document similarity, reviewer expertise, and content matching, NLP techniques can be highly effective in automating this process [
17,
18,
19,
20,
21,
22,
23,
24,
25]. One of the primary challenges in the PAP is determining the relevance between a document and a reviewer’s expertise. In traditional methods, this is usually determined by obtaining a preferences matrix from each reviewer, who are tasked with determining their interest in reviewing each proposal/document [
26]. These are called rankings, which are denoted by integer values of 0 s, 1 s, 2 s, and 3 s, where 0 s indicate a conflict of interest (COI) and a reviewer cannot be assigned a proposal; 1 s, 2 s, and 3 s indicate high preference, medium preference, and low preference, respectively [
26]. A different scale may also be used (e.g., 0 to 10), which will not change the logic and methodology.
However, obtaining rankings/preferences from reviewers can introduce bias and compliance issues, potentially compromising the fairness and efficiency of the panel assignment process. One major concern is the subjectivity and bias in self-reported numbers of rankings/preferences. Reviewers may intentionally or unintentionally inflate or deflate their preferences based on personal biases, unofficial collaborations, or other motivations. This can lead to preference misrepresentation, where certain reviewers favor specific proposals while avoiding others, even when they may be well-suited for an objective evaluation. Another challenge is inconsistent and incomplete ranking/preference submissions, where reviewers may fail to provide submissions on time, leaving assignment coordinators with missing or incomplete data. In such cases, the absence of preference scores can lead to suboptimal assignments. Furthermore, time constraints and high workload demands may lead some reviewers to submit arbitrary or rushed preferences, further reducing the reliability of user-preference-based assignments. Given these challenges, automated similarity-based matching using NLP and Large Language Models (LLMs) offers a promising alternative by reducing dependence on subjective rankings, potentially resulting in a more objective, scalable, and consistent panel assignment process. NLP-based document similarity methods can entail approaches such as TF-IDF (term frequency-inverse document frequency) and cosine similarity, which are traditional methods that measure lexical similarity but may struggle with synonyms and the contextual meaning. Other NLP-based methods include word embeddings (e.g., Word2Vec, GloVe, FastText), which can capture semantic relationships between words, offering more nuanced similarity comparisons. Transformer-based models (e.g., BERT, RoBERTa, GPT) are also part of the NLP suite of methods, and these can provide deep contextual embeddings that enable highly accurate semantic similarity detection [
27,
28,
29,
30,
31,
32,
33].
1.2. Research Objectives
In this study, we present a novel approach to the PAP by levering NLP-based document similarity and AI-driven decision making to augment the optimization-based Panel Assignment Problem. Panel assignments in organizations such as the U.S. National Science Foundation (NSF) and other proposal review agencies require careful alignment between reviewer expertise and proposal content whilst also adhering to multiple constraints such as the workload balance, conflict of interest (COI), fairness, and minimization of bias. The complexity of the PAP is further increased when additional reviewer roles, such as the lead reviewer (who introduces the proposal) and scribe reviewer (who takes notes and writes up the summary) must be assigned optimally within a panel, aside from the ordinary reviewer role. This is because the workload for a lead or scribe is higher than an ordinary reviewer. Ensuring that assignments are optimal and feasible also presents a significant computational challenge especially for large-scale problem sizes. We propose an alternative approach to solving the multi-level PAP using NLP-based similarity detection in combination with integer programming (optimization) rather than relying on manually provided preference rankings. We then evaluate how well NLP techniques can automatically determine reviewer–proposal relevance while maintaining fairness and reducing biases.
2. Methods
This section outlines the methodology used for NLP-based similarity detection and optimization for automating optimal panel assignments. The process involves multiple stages such as document processing, text extraction, preprocessing, embedding generation, tokenization, similarity computation, optimization, and assignment visualization.
2.1. Text Extraction and Preprocessing
To accurately match proposals with reviewers, the first step is extracting meaningful textural data from uploaded documents. Since the documents are typically in PDF format, we employ two primary text-extraction techniques. For regular text extraction, the PyMuPDF library (version 1.26.3) is used to extract text from the PDFs directly. PyMuPDF is a high-performance Python library (version 3.11.7) for data extraction, analysis, conversion, and manipulation of PDF files. PyMuPDF provides a robust framework for reading, processing, and manipulating PDFs while preserving their original structure and formatting. This method is effective for digitally created PDFs where text is embedded in a machine-readable format. If successful, the extracted text is passed to the preprocessing step.
If direct extraction fails (e.g., due to scanned documents or image-based content), we use optical character recognition (OCR) to extract text from the documents. The document pages are first converted into images with enhanced contrast to improve text recognition. The OCR engine extracts text from each page, ensuring that even non-machine-readable PDFs are processed. The extracted text is then structured into a format suitable for NLP-based similarity analysis. To perform the OCR, we use EasyOCR which is a Python-based OCR module. EasyOCR is optimized for speed, while maintaining high accuracy, making it more suitable for real-time document processing. The library automatically enhances contrast and sharpness, improving text recognition without extensive pre-processing. To determine when to switch from regular text extraction to OCR-based text extraction, we compute the stopword ratio of the document. Stopwords are commonly used words in a language (e.g., ‘the’, ‘is’, ‘and’, ‘of’, ‘in’, ‘at’) that typically carry minimal or no meaning in text analysis. These words are frequently filtered out in NLP tasks to improve computationally efficiency and focus more on informative terms. The stopword ratio can be defined as the number of stopwords in the extracted text to the total number of words in the extracted text. A higher stopword ratio indicates that the extracted text is natural and complete, as stopwords are expected to be present in well-formed sentences. A very low stopword ratio suggests incomplete or faulty extraction, missing words, fragmented text and/or garbled characters, which indicate that the regular text extraction was erroneous. In this study, we use a threshold stopword ratio of 0.05 to denote that if the stopword ratio is less than 0.05, the code will switch from regular text extraction to OCR-based extraction. It is important to first attempt regular text extraction as OCR-based text extraction is computationally more expensive. Aside from stopword removal, the extracted text also undergoes additional preprocessing steps to enhance accuracy. These include whitespace and formatting normalization where line breaks and redundant spaces are eliminated to create a clean text representation.
2.2. Text Similarity Computation
To determine the relevance of proposals to reviewers, we compute similarity scores using two different NLP-based methods. In the first method, a pre-trained deep learning model from SentenceTransformers called ‘all-mpnet-base-v2’ is utilized [
34]. Each pre-processed document (proposal or reviewer profile) is converted into a numerical vector (embedding), and the vector captures the semantic meaning of the text. Cosine similarity is computed between the embeddings of the proposals and reviewers to determine relevance. Unlike traditional keyword-based methods, transformers understand context and meaning. They can detect subtle similarities between documents even when different words are used to express similar ideas. The cosine similarity score ranges from −1 to 1. A score of 1 indicates perfect similarity, meaning the texts are identical in meaning, while a score of 0 indicates no similarity, suggesting the texts are completely unrelated. A score of −1 indicates complete dissimilarity, where the texts are maximally opposite in meaning. Since research proposals and reviewer profiles typically belong to related academic domains, we expect the similarity scores to generally be positive or at the most, weakly negative. Higher similarity values are expected when comparing proposals and reviewers within the same field, while lower scores are anticipated when comparing across different disciplines.
The ‘all-mpnet-base-v2’ model is a pre-trained sentence-embedding model developed as part of the SentenceTransformers library. It is based on MPNet (Masked and Permuted Pre-training for Language Understanding), a state-of-the-art transformer architecture introduced by Microsoft. MPNet combines the strengths of BERT (Bidirectional Encoder Representations from Transformers) and XLNet (eXtreme Learning Net), making it highly effective for capturing contextual semantics, syntactic dependencies, and long-range relationships in textual data. While the ‘all-mpnet-base-v2’ model does not generate text like full-scale LLMs, it still processes and understands natural language in a deep, contextual way. Given its transformer-based architecture, large-scale pre-training, and ability to encode rich semantic representations, it can be considered a mini LLM specialized for text similarity and retrieval tasks rather than open-ended text generation.
Transformer-based models, such as SentenceTransformer’s ‘all-mpnet-base-v2’, impose strict token length limitations, typically capping input sequences at 512 tokens due to hardware constraints and model architecture. This poses a significant challenge when processing long documents, as exceeding the token limit can lead to truncation and the loss of important semantic information. Given that research proposals and reviewer profiles often contain thousands of tokens, processing them in a single pass is infeasible. Furthermore, truncating the document to fit the token limit may not be a sound strategy as often key information is often distributed across different sections of the document. To address the token limit, we implement a chunking strategy that ensures complete document representation while maintaining the model’s efficiency and accuracy. The document is first tokenized using the same tokenizer employed by the ‘all-mpnet-base-v2’ model. It is then split into sequential 512-token chunks, ensuring that each segment remains within the model’s processing limits. Each of the 512-token chunks is individually passed through the transformer model, generating an embedding vector for that specific portion of the text. The final document embedding is then computed as the mean of all the chunk embeddings, which helps to smooth out variability between chunks and ensures a stable document representation. After the cosine similarity scores are computed, the similarity scores are converted to rankings for the purpose of standardization for the subsequent panel assignment optimization and the conversion can be determined as follows:
This ensures that a higher similarity score results in a lower numerical rank (better match) and ensures that rankings are bounded between 1 (highest preference) and 3 (lowest preference). Conflicts of interest will be assigned as 0s. The final output is a rankings matrix, where each proposal is ranked against every reviewer determined by the similarity analysis as opposed to obtaining manually obtaining preferences from reviewers.
For this study, we use journal publications (which are publicly available through a valid license if subscription-based or freely available if open-access) as a replacement for proposals since proposal documents are proprietary. Journal publications are a valid replacement as they share contextual similarity with a proposal and have a similar length and similar amount of domain-specific information that can be used for similarity analysis. For reviewer profile documents (to compare against the journal publications), we use (1) Google Scholar profiles of faculty and (2) CVs of faculty, both of which are considered publicly available documents and contain sufficient technical information to be accurately analyzed against the journal publications for similarity matching and analysis.
2.3. Google Scholar Title Extraction
A google scholar profile provides a comprehensive summary of a researcher’s academic contribution, citation metrics, and research impact. When printed as a PDF, the profile typically contains the following key information such as the full name, affiliation, research areas, total citations, H-index, i10-index, citation trends, title of each paper, author names, journal/conference name, publication year, keywords, and profile URLs. These elements make the google scholar profile valuable for reviewer selection, but some of the information contained may be unnecessary and may skew the similarity analysis. As a result, we developed a method to accurately extract only the research publication titles from the Google Scholar profiles. This was performed by leveraging PyMUPDF to detect and retrieve blue-colored text elements. Since Google Scholar consistently formats publication titles in blue, identifying and extracting these elements provides a reliable method for title retrieval.
Each text span in a PDF document is associated with an RGB (red–green–blue) color value. To detect blue text, we ensured that the blue component was greater than both the red and green components. Consecutive blue text spans were merged to capture complete titles, even when they spanned multiple lines, to ensure accurate title extraction. Since only blue-colored text is considered, we avoid capturing irrelevant sections such as author names, affiliations, or citation counts.
2.4. CV Publication Title Extraction
A researcher’s Curriculum Vitae (CV) provides a detailed overview of their academic background, professional experience and research contributions. It is typically structured into several key sections containing personal information, education, professional affiliations, research interests, publications, grants and funding, awards and honors, teaching experience, mentorship and supervision, etc. The length of a CV can also range from 1 to over 50 pages. Like the journal paper title extraction of the Google Scholar document, here, we also develop a methodology to extract journal paper titles from the CV to eliminate redundant information from the CV that may skew the similarity results when a CV is used for similarity analysis.
The first step is to parse text from the CV PDF document using PyMuPDF, whereby structured output is generated, maintaining line breaks and spacing to preserve document integrity. The extraction method also ensures compatibility with both single-column and multi-column CV formats. CVs often contain headers, footers, and marginal content that do not contribute to the extraction of research publications. To address this, we set margin thresholds to exclude text near the top and bottom of each page, preventing the inclusion of headers/footers. Page numbers and institutional affiliations, commonly found in these regions, are automatically discarded. The first page of a CV typically contains an introductory section, and since publication lists typically appear after this introductory content, we employed a character-based truncation strategy whereby the first 400 characters of the extracted text were skipped to avoid capturing general information, and this approach ensures that only relevant publication entries, which are formatted as numbered lists or bulleted items, are retained. After processing all pages, the extracted text is concatenated into a single structured string, with page breaks preserved to maintain content organization.
Subsequently, a LLaMA-3-8B-8192 model through the Groq API was used to focus on journal paper title extraction from the CV document. The LLaMA-3-8B-8192 model is a cutting-edge, large-scale language model from Meta’s LLaMA 3 series, optimized for high-performance natural language processing (NLP) tasks [
35]. The model features 8 billion parameters and supports an extended context length of 8192 tokens, making it well-suited for processing long documents such as CVs, research papers, and proposal reviews. The Groq API is a cloud-based AI inference service designed to provide ultra-low latency and high throughput for large language models (LLMs) [
36]. It enables seamless deployment and the execution of models like LLaMA-3-8B-8192, making it ideal for NLP tasks that require real-time or high-speed processing [
37,
38].
A specialized prompt was created to provide the model with examples of correctly extracted journal/research publications. Example-driven few-shot prompting enhanced the model’s ability to generalize across different layouts, and the prompt explicitly guided the model to focus on numbered/bulleted publication lists whilst ignoring other sections of the CV. LLMs have character input constraints, limiting the length of text that they can process in a single pass. Hence, we implemented an iterative segmentation strategy whereby the text was split into 13,000-character segments and each segment was processed separately while maintaining contextual continuity, and the results are merged into a structured output array to ensure completeness. We also specify a rigid output format within the prompt, enabling the development of a robust parsing function where extracted titles are systematically added to an array, which can then be used for post-processing similarity analysis.
2.5. Optimization
To assign reviewers to proposals (or journal papers as used in this study), we employ an Optimization-based Integer Linear Programming (ILP) approach to minimize the total preference score across assignments that is based on the authors’ prior work [
39] and related works [
18,
40]. Hence, only the pertinent details are reported here, and for complete details, please refer to
Appendix A. The preference score is determined by a ranking matrix, where each entry represents a reviewer’s suitability for a given proposal. However, now, the rankings matrix is not based on reviewer preferences that are obtained from reviewer input but rather from a document similarity analysis (
Section 2.1,
Section 2.2,
Section 2.3 and
Section 2.4), whereby a similarity score is computed by comparing a ‘proposal’ with a reviewer document. In this study, we will use a journal paper as the ‘proposal’ (henceforth denoted as ‘proposal’) and either a Google Scholar profile document or a CV as the reviewer document. Higher similarity scores are hypothesized to result in the optimization, prioritizing the matches in order of lead, scribe, and ordinary reviewer, while lower similarity scores will tend to result in unassigned matches. Conflicts between a ‘proposal’ and a reviewer document will be entered
a priori so that the match is excluded from the optimization. For the optimization, the similarity scores are scaled to a range of 1 to 3 to ensure that they are consistent with the traditional method of obtaining preferences (1 to 3) from reviewers. Here, a similarity score of 1 is scaled to a ranking of 0 and a similarity score of 0 is scaled to a ranking of 3 with an inverse linear rule applied for in-between similarity scores. It is possible that when two documents are divergent in semantic similarity, they can result in negative similarity scores, which will result in the rankings becoming greater than 3. This does not pose any problem for the optimization as it will just treat scores of greater than 3 as less preferred in terms of matching.
The optimization problem consists of the objective function (fval), which can be represented as follows:
where
n = number of proposals, m = number of reviewers, and R is the rankings matrix, where R
ij represents the ranking or preference of assigning reviewer j to proposal i, and X is the assignment matrix, where X
ij = 1 if reviewer j is assigned to proposal i and X
ij = 0 otherwise. The constraints can be represented as follows, whereby each proposal is (1) assigned the required number of reviews, (2) reviewers are assigned with minimum and maximum workload limits, and (3) conflicts of interest (COI) are avoided by ensuring reviewers are not assigned proposals where their ranking is 0.
The lead and scribe assignment problems follow the same optimization-based approach whereby the lead assignments are assigned based on their workload and preference scores, using a round-robin approach for balanced distribution. The optimization is performed using PULP/CPLEX. PULP (Python Utility for Linear Programming) is an open-source library for formulating and solving Integer Linear Programming (ILP) and Mixed-Integer Linear Programming (MILP) problems in Python. CPLEX is a commercial solver available in Python that handles ILP and it uses a combination of simplex methods, barrier methods, Branch-and-Bound, and branch-and-cut. The optimization method also incorporates the case of where the lead and scribe reviewer are the same and where the lead and scribe reviewer are different.
2.6. Implementation and Deployment
The complete procedure is implemented as an interactive web application using Streamlit (an open-source Python framework to deliver interactive data applications). This allows users to upload proposal-based documents (journal publications) and reviewer portfolio documents (google scholar profiles or CVs) as PDFs. To ascertain if a document is a Google Scholar profile, the highest text line on the first page was examined to confirm if the phrase ‘Google Scholar’ was present. The system then processes the documents and generates similarity scores and corresponding rankings. Subsequently, the rankings matrix is then used to perform the panel assignment either via optimization.
3. Results and Discussion
All results were computed using Python. The Python version used was Python 3.10.4 with key libraries such as NumPy, pandas, scikit-learn, and data preprocessing tasks, along with PuLP for the optimization in Python. The simulations were performed on a 12th Gen Intel(R) Core(TM) i7-1255U CPU @ 1.70 GHz, 16 GB RAM, Windows 11 64-bit operating system.
3.1. Document Similarity
We first compared the general text extraction method for Google Scholar (GS) and CV documents and compared results with the specialized text extraction method for the same documents (
Section 2.3 and
Section 2.4). Results showed that there was no discernible difference in the similarity score between the two approaches. This can be attributed to the robustness of the sentence transformer mode (allmpnet-base-v2), which effectively captures overall semantic similarity, even in the presence of non-technical or less relevant text. These models are designed to focus on the core meaning of the content, making them resilient to extraneous information such as author names, affiliations, or formatting inconsistencies. Given the negligible impact of specialized extraction and the added computational overhead that it introduced, we opted to proceed with the general text extraction method.
We then conducted a series of tests to evaluate the robustness of our NLP-based document similarity method using the general method. We created a controlled environment where the ‘proposal’ documents used were the journal papers of the corresponding reviewer. This means that in the similarity matrix S, where Si,j represents the similarity score between proposal i and proposal j, the diagonal elements Si,i correspond to the similarity score between a reviewer’s own papers and their professional profile documents. Since each ‘proposal’ is authored by the corresponding reviewer (who is one of the authors of the ‘proposal’), we expect these diagonal elements Si,i for i = 1, 2, …, N to exhibit significantly higher similarity scores compared to the off-diagonal elements where . This experimental design enables us to validate our method and its ability to detect semantic relationships accurately. The diagonal elements represent the self-similarity scores, and the off-diagonal elements represent the dissimilarity scores
For a comprehensive analysis, we consider 40 researchers from two distinct disciplines: Chemical and Biochemical Engineering (20 researchers) and Philosophy (20 researchers). To ensure a balanced evaluation, we analyze 10 ‘proposals’ from each of the 40 researchers. We structure our evaluation into three cases:
Case 1: Examines similarity by comparing proposals and reviewer documents within the Chemical Engineering discipline, with reviewer information derived from (1) Google Scholar profiles and (2) CVs.
Case 2: Examines similarity within the Philosophy discipline, using reviewer information from (1) Google Scholar profiles and (2) CVs.
Case 3: Assesses both similarity and dissimilarity by pairing a mix of ‘proposals’ from Chemical Engineering and Philosophy with reviewer documents (Google Scholar profiles and CVs) from the respective disciplines.
This structured evaluation allows us to test the robustness of our method across distinct subject areas and data sources.
3.1.1. Average Similarity Results
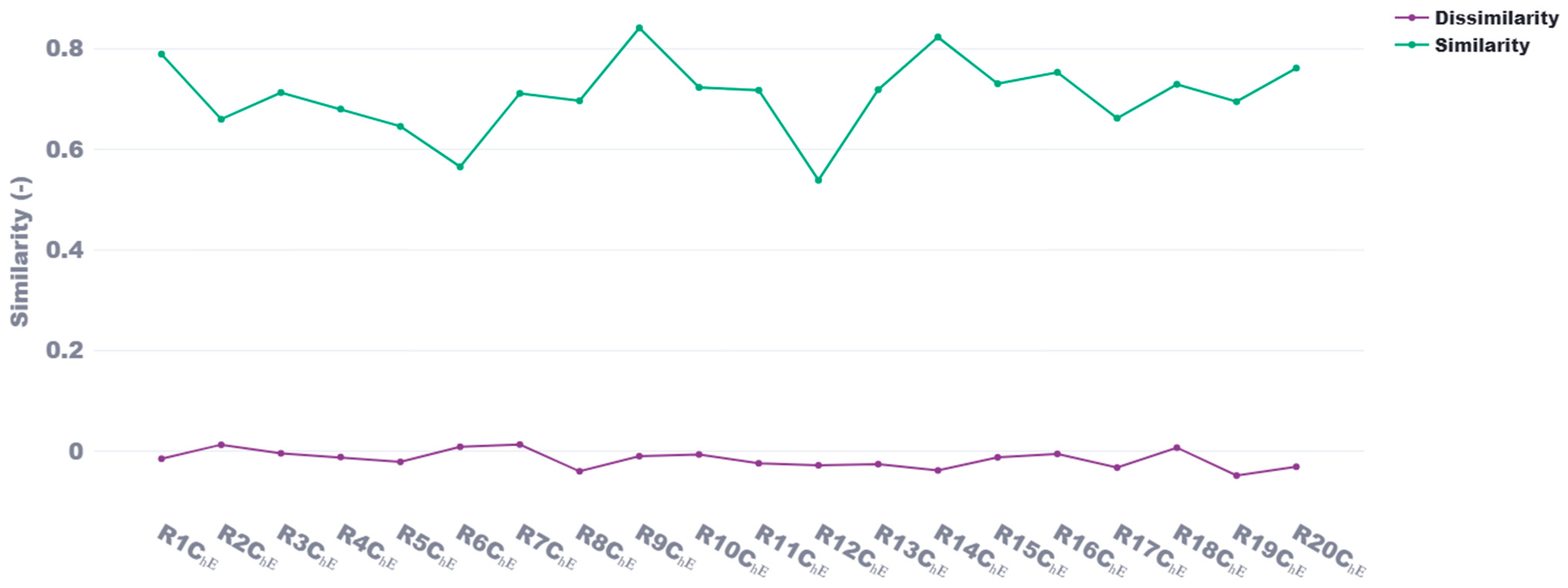
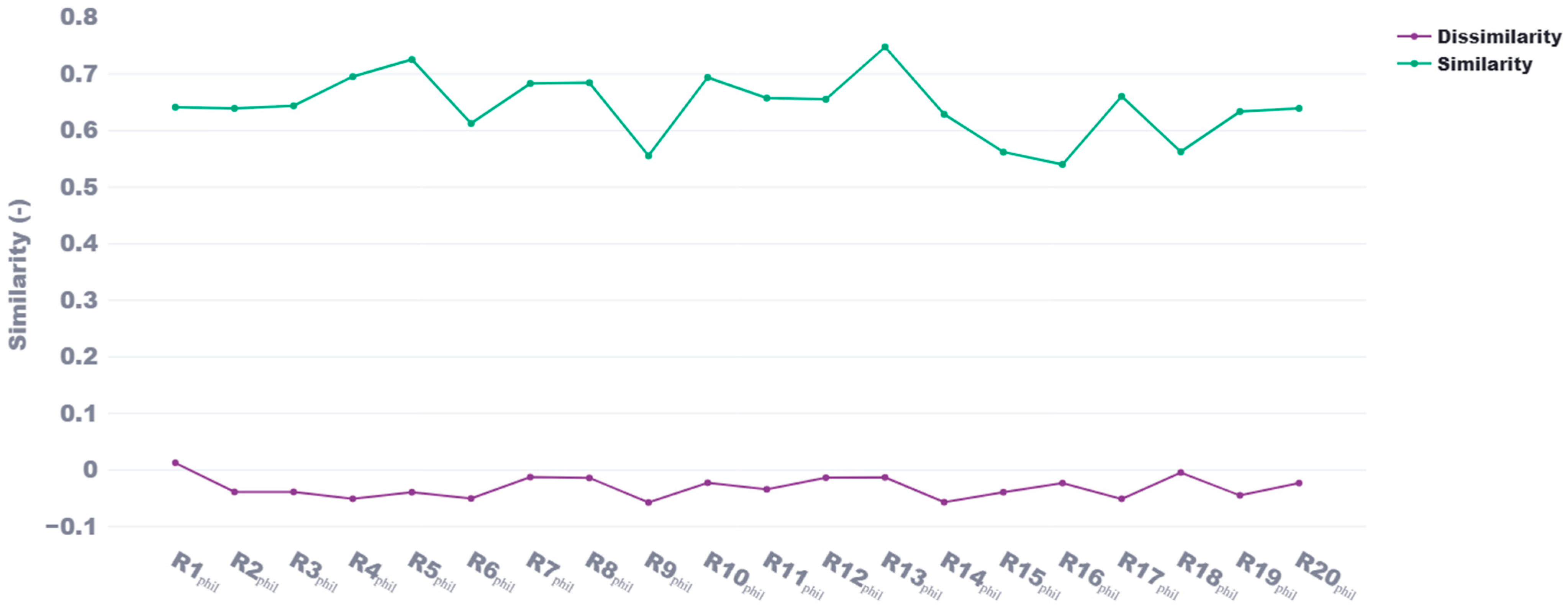
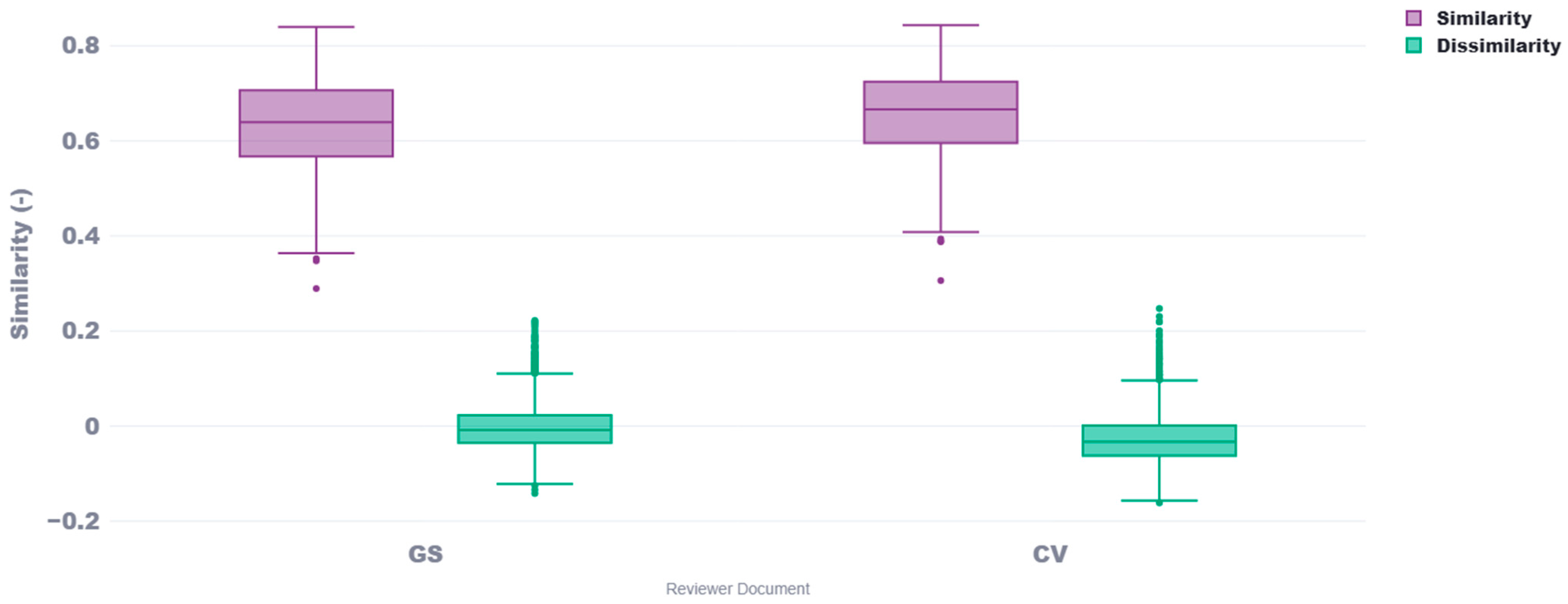
The average self-similarity score across the Philosophy and Chemical Engineering departments is 0.655 when using reviewer data from Google Scholar profiles and 0.672 when using data from CVs. This difference is expected, as Google Scholar profiles primarily include published works and citation data, which may not fully capture the breadth of a researcher’s contributions. In contrast, CVs provide a more comprehensive and structured overview, including unpublished research, professional activities, and detailed descriptions of academic work, leading to a slightly higher self-similarity score. Meanwhile, the average dissimilarity score is −0.01 for Google Scholar-based reviewer data and −0.02 for CV-based reviewer data. These near-zero values indicate that proposals paired with reviewers from different disciplines exhibit minimal to no semantic alignment. The slightly more negative dissimilarity scores from CV-based reviewer data suggest that the additional details captured in CVs may accentuate disciplinary differences more effectively than Google Scholar profiles, reinforcing the method’s ability to distinguish between unrelated fields. Ultimately, however, there is minimal difference between Google Scholar profiles and CVs, as both offer rich semantic information suitable for similarity analysis.
3.1.2. Similarity Results for Chemical Engineering ‘Proposals’ and Reviewers
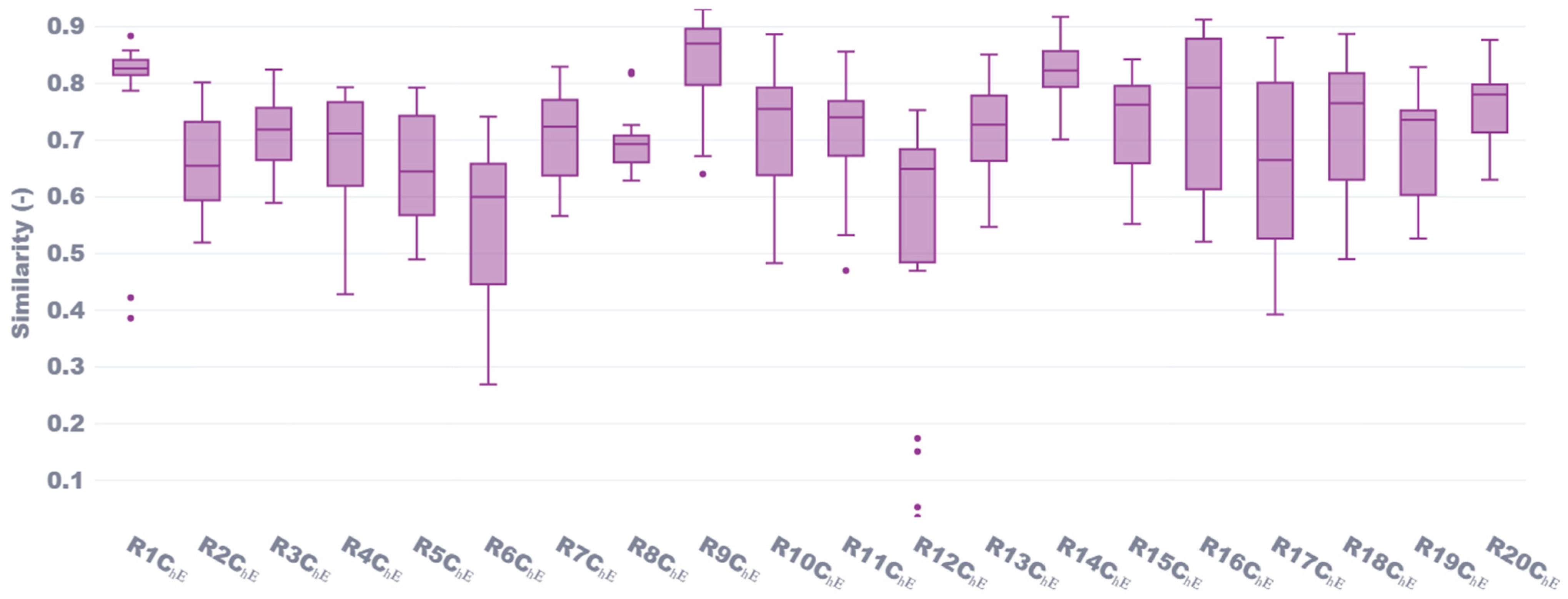
As shown in
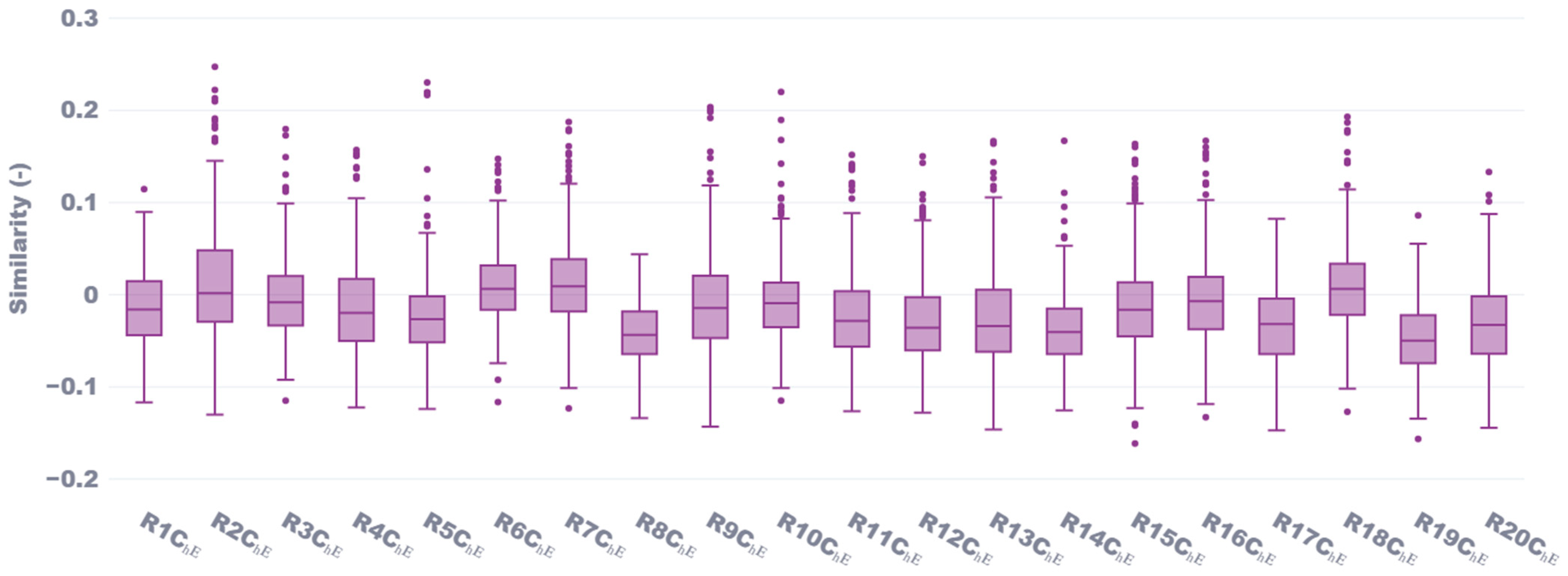
Figure 1, similarity scores for Chemical Engineering (ChE) reviewers (R) demonstrate strong self-similarity, with median values predominantly ranging between 0.65 and 0.85. Reviewer R9_ChE achieved the highest median similarity score of approximately 0.89, followed closely by reviewers R1_ChE, R14_ChE, and R16_ChE, with scores ranging from 0.82 to 0.85. Notably, R1_ChE had the highest lower fence with a score of 0.79, indicating a robust consistency in similarity across their proposals and reviewer profile documents. Additionally, R1_ChE exhibited the tightest distribution, with scores spanning from 0.78 to 0.86, further confirming their strong internal consistency. However, R12_ChE exhibited significant outliers at the lower end, with similarity scores of 0.05 and 0.15, suggesting that these two proposals were semantically distant from the reviewer’s expertise, despite an otherwise moderate median similarity score of 0.65. Conversely, R6_ChE had the lowest median score of 0.60, along with the second-lowest mean similarity score (averaged across both CV and Google Scholar methods) of 0.56 as seen in
Figure 2. In contrast, the highest average similarity scores were achieved by R9_ChE and R14_ChE, with averages of 0.84 and 0.82, respectively. From
Figure 3, we observed a high degree of consistency between the Google Scholar profiles and CVs as document sources. Both approaches yielded similar median similarity scores of 0.72, with comparable interquartile ranges. However, the CV-based approach demonstrated a slightly tighter distribution, suggesting a more consistent alignment of proposals to reviewer profiles when using CVs. This consistency validates our methodology of extracting relevant information from different document types, highlighting the flexibility in source documents while maintaining reliable similarity assessments.
3.1.3. Similarity Test Results for Philosophy ‘Proposals’ and Reviewers
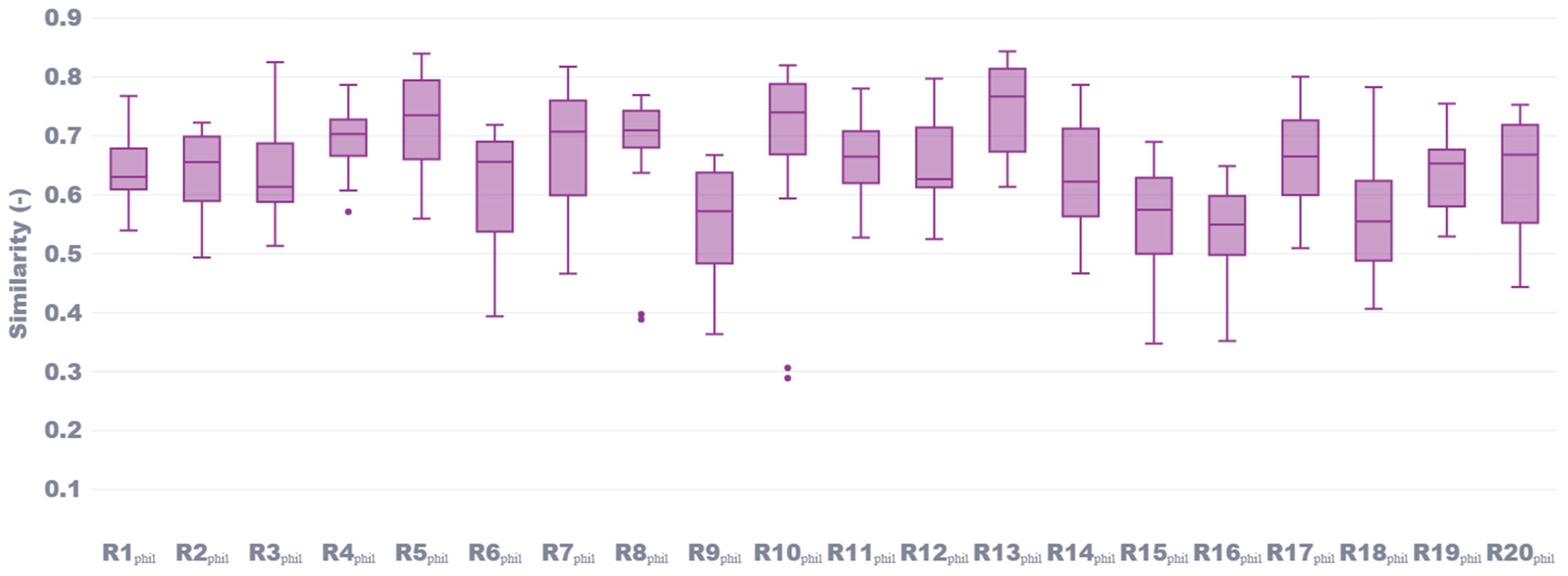
Building upon our evaluation of Chemical Engineering documents, we extended our analysis to the Philosophy discipline, maintaining the same controlled design where proposals consisted of research papers from the corresponding reviewers. This cross-disciplinary comparison allowed us to assess whether our NLP-based similarity method performs consistently across distinct academic fields, each with its own linguistic and semantic characteristics. As seen in
Figure 4, similarity scores for Philosophy reviewers (R1
Phil through R20
Phil) exhibited strong self-similarity, albeit with slightly different patterns than the Chemical Engineering test cases. The median values predominantly ranged between 0.55 and 0.75, with tighter distributions observed for most reviewers. Reviewer R13
Phil achieved the highest median similarity score of 0.76, followed closely by R10
Phil (0.74), R5
Phil (0.73), and R7
Phil (0.71). Compared to Chemical Engineering, the Philosophy reviewers exhibited fewer extreme outliers. The most notable outlier was R10
Phil, with an isolated point at approximately 0.30, suggesting that this reviewer’s document may have had less semantic alignment with the corresponding proposals. However, this point appeared to be an anomaly, as R10
Phil’s median score remained high at 0.74, indicating overall consistency in similarity scores. In
Figure 5, we observe that the anomaly in R10
Phil’s document significantly impacted the reviewer’s overall mean similarity score, which dropped to 0.55. The highest average similarity scores were achieved by R5
Phil (0.72) and R13
Phil (0.75), while R16
Phil and R9
Phil had the lowest scores at 0.54 and 0.55, respectively. Notably, the overall range of average similarity scores (0.54 to 0.75) was narrower than in the Chemical Engineering test cases, suggesting a more consistent alignment across Philosophy documents. From
Figure 6, we observed similar consistency between Google Scholar profiles and CVs as sources for Philosophy reviewers, with both document types yielding median similarity scores of approximately 0.65. The interquartile ranges for both sources were nearly identical, indicating that both sources provide equally reliable semantic information in the Philosophy domain. Although the median similarity scores in Philosophy were slightly lower than those for Chemical Engineering (0.65 versus 0.73), the distributions for Philosophy were tighter, suggesting more homogeneity within the discipline across both document types.
Overall, the consistently strong self-similarity scores in both disciplines validate the effectiveness of our approach across different academic domains. While Philosophy documents showed slightly lower absolute similarity values than Chemical Engineering, they exhibited greater consistency across reviewers. These results demonstrate that our transformer-based document similarity method successfully captures semantic relationships within related documents across distinct academic fields and writing styles.
3.1.4. Similarity Test Results for Mix of Chemical Engineering and Philosophy ‘Proposals’ and Corresponding Mix of Reviewers
To evaluate the effectiveness of our algorithm in distinguishing semantically unrelated documents, we conducted cross-disciplinary tests between Chemical Engineering and Philosophy. For these tests, we processed 200 proposal documents per reviewer, which provided a robust dataset to measure dissimilarity scores across disciplines. This cross-disciplinary analysis is particularly important for real-world panel assignment scenarios, where reviewers from one discipline should not be assigned proposals from unrelated fields.
When evaluating Chemical Engineering reviewers against Philosophy ‘proposals’, we consistently observed low similarity scores, confirming the model’s effectiveness in identifying dissimilar documents. As shown in
Figure 7, the median similarity scores for Chemical Engineering reviewers when paired with Philosophy proposals ranged from −0.14 to 0.08 using the Google Scholar method and from −0.21 to 0.067 when using CVs as the source for reviewers’ professional information. These scores signify minimal semantic overlap between the two disciplines. The highest average similarity score of 0.013 was exhibited by R7
ChE.
Figure 7 further highlights that R7
ChE demonstrated the highest median value of approximately 0.006, while R8
ChE, R14
ChE, and R19
ChE showed the lowest median scores, around −0.04. These consistently low values across all reviewers indicate that our similarity method effectively identifies cross-disciplinary mismatches. The interquartile ranges for these scores were narrow, typically spanning from −0.10 to 0.10, reflecting consistent dissimilarity between Chemical Engineering and Philosophy documents.
Similarly, when Philosophy reviewers were evaluated against Chemical Engineering ‘proposals’, the results showed a comparable pattern of significant dissimilarity. As illustrated in
Figure 8, the similarity scores for Philosophy reviewers using the Google Scholar method ranged between −0.12 and 0.11, while the CV-based approach yielded scores between −0.15 and 0.09. These ranges align with the expected outcome given the semantic differences between the two disciplines. Among the Philosophy reviewers, R18
Phil exhibited the highest average similarity score of −0.004, while R9
Phil had the lowest average score of −0.057.
Figure 8 shows that R1
Phil had the highest median similarity at approximately 0.005, while R14
Phil demonstrated the lowest median at about −0.06. The interquartile ranges for Philosophy reviewers were slightly wider than those observed for the Chemical Engineering reviewers, spanning from −0.08 to 0.05. This suggests marginally more variability in dissimilarity patterns within the Philosophy group.
The consistently negative or near-zero median similarity scores across both cross-disciplinary tests validate the method’s ability to accurately distinguish between semantically relevant and irrelevant document matches. This capability is particularly crucial for panel assignment tasks, where the algorithm must avoid assigning reviewers to proposals outside their domain of expertise.
3.2. Panel Assignment Optimization
We present three cases to demonstrate the results for the panel assignment optimization via NLP-based document similarity: Case 1: 10 ‘proposals’, which are represented by journal publications, and 10 ‘reviewers’, which are represented by reviewers’ Google Scholar profiles or CVs are considered, whereby the reviewer documents are from the Chemical Engineering discipline. Case 2: 10 ‘proposals’, which are represented by journal publications, and 10 ‘reviewers’, which are represented by reviewers’ Google Scholar profiles or CVs are considered, whereby the reviewer documents are from the Philosophy discipline. For each case, we consider the instance where the lead and scribe are the same and when they are different. The number of reviews per proposal is set at four for all cases. In each case, ‘proposal’ 1 to 10 represent the journal paper from that particular reviewer, 1 to 10. Hence, we expect the diagonal elements in the panel assignment matrix to have the highest similarity scores (and correspondingly, a lower rankings score) due the self-similarity of the ‘proposals’ to the reviewers, and as a result, the diagonal elements should be ideally assigned as “LS”, when lead/scribe are the same and “L” when the lead and scribe are different since the leads (L) are prioritized in the optimization formulation to be assigned their highest rates for ‘proposal’. Case 3 represents a scenario whereby half of the set (documents 1 to 5) are from Chemical Engineering and the other half (documents 6 to 10—Google Scholar profiles and CVs) are from Philosophy
3.2.1. Case 1: Chemical Engineering ‘Proposals’ and Related Google Scholar Profile and CV Documents
Results from
Table 1, where Chemical Engineering ‘proposals’ are compared with Chemical Engineering Google Scholar (GS) profiles, show that the similarity scores for the diagonal elements are significantly higher than the scores of the off-diagonal elements. The average self-similarity score for the diagonal elements is 0.78 and the average (dis)-similarity score for the off-diagonal elements is 0.39. The corresponding average rankings are 1.42 and 2.21, respectively. This confirms that the document similarity method can sufficiently capture the semantic similarity (or dis-similarity) between documents from the same reviewer and documents from different reviewers. Based on the rankings, panel assignment optimization was performed, and the results are illustrated in
Table 2. Here, it can be seen that each diagonal pairing (proposal—reviewer) was assigned as lead (L)/scribe (S) (when the lead and scribe are the same) or lead (when the lead and scribe are different) confirming that the optimizer was able to ensure that the proposal was assigned to the reviewer with the most related expertise, which is confirmed with the similarity scores and known a priori due to the self-similarity aspects in this assignment. R indicates reviewer.
Results from
Table 3 and
Table 4 (where now instead of GS documents, CVs are used) follow the same trends as drawn from the results in
Table 1 and
Table 2. Here, we note that when CVs are used, the average of the self-similarity scores for the diagonal elements increase from 0.78 to 0.79, and the average of the (dis)-similarity scores for the off-diagonal elements increase from 0.39 to 0.41. The negligible differences can be attributed to the difference in semantic information that is captured in a GS document versus a CV, but it is noted that both offer sufficient semantic context.
3.2.2. Case 2: Philosophy ‘Proposals’ and Corresponding Google Scholar Profile and CV Documents
Results from
Table 5, where Philosophy ‘proposals’ are compared with Chemical Engineering Google Scholar (GS) profiles, show that the similarity scores for the diagonal elements are significantly higher than the scores of the off-diagonal elements. The average self-similarity score for the diagonal elements is 0.67, and the average (dis)-similarity score for the off-diagonal elements is 0.41. The corresponding average rankings are 1.64 and 2.17, respectively. This confirms that the document similarity method can sufficiently capture the semantic similarity (or dis-similarity) between documents from the same reviewer and documents from different reviewers. Based on the rankings, the panel assignment optimization was performed, and results are illustrated in
Table 6. Here, it can be seen that each diagonal pairing (proposal—reviewer) was assigned as lead/scribe (when the lead and scribe are the same) or lead (when the lead and scribe are different) confirming that the optimizer was able to ensure that the proposal was assigned to the reviewer with the most related expertise, which is confirmed with the similarity scores and known a priori due to the self-similarity aspects in this assignment.
Results from
Table 7 and
Table 8 (where now instead of GS documents, CVs are used) follow the same trends as drawn from the results in
Table 1 and
Table 2. Here, we note that when CVs are used, the average of the self-similarity scores for the diagonal elements increase from 0.67 to 0.69, and the average of the (dis)-similarity scores for the off-diagonal elements increase from 0.41 to 0.43. The negligible differences can be attributed to the difference in semantic information that is captured in a GS document versus a CV, but it is noted that both offer sufficient semantic context even in a different discipline. It is also interesting to note that the difference between the self- and dis-similarity scores in the Philosophy discipline is less than that in the Chemical Engineering discipline, and this can be attributed to the reviewers in the Philosophy discipline having more diverse research areas compared to those in Chemical Engineering, for the sample set that was used in this study.
3.2.3. Case 3: Mix of Chemical Engineering and Philosophy ‘Proposals’ and Their Corresponding Google Scholar Profile and CV Documents
Here, we consider a case where half the set (1 to 5) is represented by Chemical Engineering documents and the other half is represented by Philosophy documents. Results from
Table 9 and
Table 10 show that the self-similarity score of the diagonal elements within each set is high, confirming the same trends as seen in the earlier cases. Similarly, we see the lower similarity scores reflected within each set for the off-diagonal elements, confirming the same trends seen earlier. Correspondingly, from
Table 11 and
Table 12, we can see that the optimized panel assignment is able to ensure that the diagonal pairings consist of the lead/scribe or lead assignments. As expected, the optimizer was able to ensure a clear separation of all assignments, whereby it seen that the review assignments are only made within each set due to the expectation that ‘proposals’ of that specific discipline should be reviewed by reviewers from that discipline. The same trends are seen whether GS or CV documents are used.
3.3. Implications of Research Results
The findings of this study have important implications for enhancing the efficiency, fairness, and scalability of panel assignment processes across diverse domains. By demonstrating that NLP-based similarity detection combined with optimization can reliably match reviewers to proposals without relying on subjective preferences, this research paves the way for more objective, bias-resistant assignment frameworks. The consistent performance across disciplines and document sources underscores the method’s adaptability in real-world scenarios, including large-scale peer review systems. Additionally, the ability to differentiate between semantically unrelated documents ensures discipline-aware assignments, reducing the risk of mismatches that compromise review quality. The success of automatic lead and scribe assignments further highlights the method’s practical value in managing complex role distributions within panels. Beyond academic peer review, these results can inform broader applications in workforce allocation, project-team formation, and other expert-task matching contexts where fairness, expertise alignment, and efficiency are critical. The proposed framework offers a scalable and data-driven alternative to traditional preference-based approaches.
4. Conclusions
This study demonstrates the effectiveness of an NLP-based document similarity approach in optimizing panel assignments by ensuring that proposals are matched with the most semantically relevant reviewers. The three cases examined provide clear evidence of the method’s robustness across different disciplines and document sources. For single-discipline cases (Cases 1 and 2), where proposals and reviewers belonged to the same field (Chemical Engineering or Philosophy), the self-similarity scores of diagonal elements were significantly higher than off-diagonal elements. This confirmed that the method accurately captured semantic alignment between reviewers and proposals. Additionally, the panel assignment optimizer successfully assigned lead/scribe roles to the most relevant reviewers, reinforcing the reliability of the similarity-based optimization approach. Minor variations in similarity scores between Google Scholar profiles and CVs were observed, with CVs offering slightly higher self-similarity scores due to their broader coverage of academic contributions. The cross-disciplinary analysis (Case 3) further validated the method’s capability to distinguish semantically unrelated documents. When Chemical Engineering reviewers were matched with Philosophy proposals (and vice versa), the similarity scores were consistently near zero or negative, highlighting minimal semantic overlap. Despite the interdisciplinary nature of some research areas, the algorithm effectively separated proposals and reviewers into their respective disciplines, preventing cross-disciplinary mismatches. Additionally, the study revealed that Philosophy reviewers exhibited slightly more variability in similarity scores compared to Chemical Engineering reviewers, possibly due to the broader thematic diversity within the Philosophy discipline. Nonetheless, the optimizer ensured that proposals were only assigned to reviewers within the same discipline, further demonstrating the method’s practical applicability in real-world panel assignment scenarios. Overall, these findings confirm that our NLP-based similarity approach, combined with panel assignment optimization, provides a robust, scalable, and discipline-aware framework for assigning reviewers to research proposals.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}