1. Introduction
Depression has become one of the most disabling diseases in the world, striking at people’s emotions, thoughts, and social functioning. While traditionally identified by clinical interviews and standardized questionnaires, new technologies have made automated detection possible. Early attempts at detecting depression have focused more on behaviors like the matching of facial expressions and motion. For instance, ref. [
1] presented an interpretable representation of motion dynamics for depression severity estimation, demonstrating the correlation of facial dynamics with emotional state. This groundbreaking work showed that video-based features are informative for modeling affective disorders in addition to textual data.
In addition to visual cues, the rhythm of voice is also one of the crucial factors in assessing mental health. In [
2], they presented a hierarchical model that combined voice tone and emotion features to better identify the level of depression. Their approach required manually crafted features to represent vocal cues, though these could also be subtle deviations of the voice signal (like hesitation or monotonicity); these deviations expose internal emotional conflicts, even if the person verbally denies them. These studies laid the first evidence that multi-modal cues could serve as an early warning of depression severity.
Moreover, ref. [
3] investigated the capability of machine learning algorithms to distinguish low from high severity depression based on voice biomarkers only. Their research used a clinical dataset and proved that AI-generated machine learning models might achieve better performance than conventional assessment tools by capturing non-obvious speech signals. This study highlighted the potential of machine learning to augment or even improve clinical decisions, especially regarding nuanced classification tasks like depression severity diagnosis.
Acoustic features were still under the spotlight as they are non-invasive and applicable for real-time analysis. In [
4], they used convolutional autoencoders to learn deep audio representations from speech waveforms. Results demonstrated that unsupervised models could capture the latent audio patterns correlated with depression. These methods have expanded the frontier of AI capability in affective computing and shown strong evidence that acoustic patterns can provide robust digital biomarkers for the monitoring of mental wellness status. Physiological and audio modalities provide teaching insight, but the proliferation of online user-generated content, in particular social networks such as Reddit and Twitter, has directed attention toward text-based depression detection. In [
5], they proposed a deep learning model to predict the intensity of depression through social media. Their model explored linguistic characteristics, such as the richness of vocabulary, the predominant sentiment, and expressions of emotional instability and self-reflection, which are often found in depressive speech. That was a shift away from multimodal data to the increasing promise of natural language processing.
In the same context, ref. [
6] presented a severity detection system based on digital cues in social media text. They employed attention-based deep networks to capture subtle changes in the tone of a user over many posts. They stressed that, to provide tailored interventions, severity rather than the presence or absence of depression could be detected. Their research underscored the potential of computer systems to recognize fine-grained mental health risks, with accuracy that potentially outpaces that of human clinicians.
In [
7], they further progressed in this direction and proposed DEPTWEET, a typology-based approach to determine the severity of depression from tweets. The authors developed fine-grained annotations, allowing models to distinguish minimal distress vs. clinical severity. They found that, when more severe markers are taken into account, this progression can be observed among lexical and semantic markers themselves, and that these trends can be effectively captured by combining typological heuristics with state-of-the-art NLP models. This granularity sets the stage to identify not only “if” someone is depressed, but “how much.”
Recent works have turned to Transformer-based models to take advantage of the entirety of the expressive capacity of the contextual language representation. In [
8], a language-model-only approach for depression classification showed remarkable performance. They emphasized that pre-trained language models, such as BERT and RoBERTa, fine-tuned on mental health text, can outperform previous traditional methods, thanks to context-dependent emotional semantics. This represented a radical departure from handcrafted features to automatically learned representations by deep neural pipelines.
In a subsequent investigation, Sadeghi and coworkers recently scripted further, identifying a novel lysosomal membrane protein. Ref. [
9] confirmed these observations by repeating these results on diverse datasets. To compute JACCARD, we only used lexical cues and word embeddings over a word-based collocation. The research highlights that Transformer models not only identify depression but also capture subtle linguistic cues that are predictive of psychological manifestations. For example, past tense, existential negations, and emotion-hued adjectives are repeatedly found to be the signals for deteriorated mental status. The interpretability of their model also led to additional trust in its clinical relevance.
At a time of increasing focus on mental health access, researchers [
10] developed a conversational bot powered by AI to identify depression in non-clinical conversations. Their research showed how the widespread use of similar bots could democratize the reach of mental health screening. Its model showed the promise of the early detection of depression in natural conversations and presented scalable solutions for an underserved community. Such challenges are in the scope of our objective to develop an automatic and fine-grained depressive severity classification system for stage-2 user-generated content analysis.
Motivated by this, in this study we aim to bridge a crucial research gap by bridging traditional machine learning-based and deep Transformer-based models for the multi-level depression severity detection task. Unlike binary classifiers that only identify the presence or absence of depression, our system assigns the mean score of Reddit posts into four levels of severity, ranging from minimum to mild, moderate, and severe, and linguistic and emotional features determine these levels. This multi-label characterization has increased relevance in clinics as it provides more nuanced evaluations.
To provide a thorough assessment, we include ten machine-learned models and another ten TRANSFORMER-based models as baselines (including specialized models such as MentalBERT and BioBERT). Additionally, we employ two recently proposed embedding methods, Clinical-RoBERTa Sentence Embeddings and PsychSentVec, which are specifically designed to be well-suited for psychological text representation. This unified learning approach allows us to properly benchmark the performance of various models and then deploy the best-performing configuration in the real-world settings of digital mental health monitoring.
This work contributes to the developing arena of computational psychiatry with a scalable, interpretable, and clinically meaningful model of multi-level depression severity detection using Reddit data. By combining statistical learning and deep neural architecture, we show that AI can extend from binary decisions and assist in precision mental health diagnoses. In the rest of this paper, we present the dataset, methods used, experiment setup, and evaluation results to support our approach.
2. Literature Review
In recent years, artificial intelligence (AI) in mental health assessment has experienced significant development, with researchers expanding its scope on different data modalities and machine learning models to enhance detection accuracy. The first approach was to use speech signals to recognize mental health states. Ref. [
11] provided DepAC, a corpus specifically prepared for identifying depression and anxiety via speech inputs. This corpus allowed them to train sophisticated models to extract vocal features, including pitch, energy, and LSR. By providing a publicly available speech corpus, their work paved the way for others to compare depression detection performance based on acoustic input.
Although centralized learning systems have mainly prevailed in this field, recent research has welcomed privacy and distributed approaches. Ref. [
12] developed a Federated Learning system to screen depression from smartphone sensors (e.g., GPS, app usage, and screen time). Their approach maintained user privacy and allowed predictive modeling on the device. Their research highlighted how mobile tech could help create early detection options by spreading learning across numerous edge devices, which is especially helpful in parts of the world with few mental health care professionals on hand.
Novel therapeutic support systems have also surfaced. Ref. [
13] investigated the VPSYC system, an AI-enabled therapeutic platform to recognize and react to depressive symptoms dynamically. Their research demonstrated that when AI-driven detection is integrated with conversational feedback loops, it can strengthen user engagement and could lower the frequency of depressive episodes. Deployment of intelligent support systems in mental health: integration with a methodology. Prevention and early detection are essential goals of the initiative to aid preventive therapy, which is key to the real-time vision of automated preventive interventions.
Speech analysis remains a potential tool in this regard. Ref. [
14] presented an architecture based on Attention-guided Learnable Time-domain Filterbanks, which could capture depression-specific features from raw speech signals. Their NN architecture facilitated fine-grained attention towards time-domain audio segments that contain emotive information. This significantly improved handcrafted features, providing an end-to-end learning framework tailored to mental health classification.
The combination of multimodalities—audio, textual, and visual cues—has been one major direction towards enhancing detection robustness. Ref. [
15] designed a Multimodal Fusion Model that adopted a multi-level attention mechanism over speech, facial expressions, and text inputs. They found that each modality contributed uniquely to the detection of depressive states, and even showed that their combination leads to better prediction performance. This emphasized the necessity of practical full behavior modeling (FBM).
Despite the promise of multimodal systems, text-based detection is still very scalable since most people heavily use social media and mobile communication. Ref. [
16] suggested a new method for depression detection from transcripts by applying a lexico-grammatical analysis, which employed linguistic cues like negation, personal pronouns, and emotion words as features. Their approach has shown promising results without deep learning, indicating that, even when data are sparse or noisy, rule-based systems can help recognize relationships.
The development of large language models (LLMs) has pushed toward in-depth contextual comprehension of user-generated data. Ref. [
17] investigated the use of LLMs for depression identification, using textual and audio–visual data. Their work further highlighted that the GPT and BERT models, fine-tuned on mental health data, are more effective at capturing contextual relationships and emotional subtleties than conventional models. The involvement of LLMs is a scalable way to achieve multi-modal and multi-severity mental health measures.
While AI models are increasingly being incorporated, interpreting biological markers is still necessary. Ref. [
18] re-examined speech as a depression biomarker and claimed that some acoustic characteristics (e.g., prosodic fluctuations, fluency patterns) are biologically correlated with the neural change in depressed people. Their vast literature review connects clinical experience and computational algorithms, providing the clinical backing to AI tools for speech.
In the recent literature, depression detection Transformers have shown excellent performance. Ref. [
19] explored Transformer-based models for identifying the severity of depressive language in social media text using pre-trained language models with tuning on psychological content. Their research demonstrated that models like RoBERTa and MentalBERT are more accurate than traditional NLP (natural language processing) pipelines at identifying fine-grained levels of depression. The findings suggested that Transformer-based models, along with the ability to identify depressive cues, can also capture severity progression by contextual semantics.
In addition to text-based analysis, recent deep learning studies are investigating graph-based representation learning for the better-structured modeling of depression symptoms. Ref. [
20] presented a new graph representation learning architecture to guide the representation based on facial action units (AUs) for depression severity detection. Their model learned inter-modality relationships by converting multimodal inputs into graph structures and achieved better interpretability. This method provided a new perspective for structured deep learning on mental health, which integrated graph theory with affective computing.
Together, they serve as a fine-grained depiction of the recent evolution of depression modeling from handcrafted audio features and rules-based systems to Transformer-powered, privacy-aware, and graph-structured models. They confirm the importance of interpretability and accuracy, which is what we aim to do in our study. We eventually expect to unify the strengths of traditional machine learning (ML) and advanced Transformer-based approaches for multi-level depression severity detection with Reddit posts.
In recent years, a vast body of literature has been devoted to depression detection by artificial intelligence techniques, and particularly, it has been naturally combined with large language models (LLMs), deep learning, and multi-model data. An overview of key research addressing this area is given in
Table 1.
In [
21], they applied chain-of-thought prompting in LLMs, thereby improving insight into reasoning-based depression detection. Similarly, ref. [
22] provided an in-depth review and classification of the machine learning and deep learning approaches used in social media for depression detection. Ref. [
23] Introduced the Multi-Modal Fused-Attention Network using audiovisual features, which results in the substantially improved recognition accuracy of depression severity levels.
In [
24], they discussed the general usage of AI in depressive disorder diagnosis and treatment, as well as potential advantages and ethical issues. Ref. [
25] explored self-referential language in daily diaries and found that semantic structures predicted symptoms. In [
26], DepressionX is a knowledge-enabled, attention-based model providing explainable estimates for depression severity.
Elsewhere, ref. [
27] confirmed the feasibility of training lay health workers to identify perinatal depression in Nigeria, highlighting the need for low-threshold screening tools. Ref. [
28] benchmarked different LLMs on remote interview datasets and gave insights into performance differences. Ref. [
29] developed an AI-based voice biomarker that provided promising findings when it came to discerning moderate to severe cases of depression.
In [
30], they proposed DECEN, a depressed emotion-aware deep learning model to enhance social media content classification. In [
31], they used CNNs to distinguish depression from schizophrenia by clinical and online textual information. Finally, in [
32], facial analysis is integrated into the chatbot to detect, in real-time, the early-warning signs of the disease. All these works together show the increasing complexity and variety of AI-based depression detection methods in text, speech, video, and multisource data streams.
The distinction of our work is our concentration on the comparative benchmarking of several modeling approaches. Motivated by both unimodal and multimodal studies, we investigate what works best to obtain the subtle linguistic cues of users with different levels of depression. In doing so, we add to the growing literature of computational psychiatry and provide scalable observations for digital mental health platforms.
3. Methodology
Here we specify the overall workflow used for the multi-level detection of depression severity from Reddit textual posts based on both machine learning and Transformer models, as shown in
Figure 1. The process starts with labeled data belonging to the four severity classes, minimum, mild, moderate, and severe, which is then preprocessed by removing URLs, mentions, and non-ASCII characters. The preprocessed data are divided into training (80%), validation (10%), and testing (10%) sets. We run two parallel modeling pipelines—(i) a classical machine learning (ML) pipeline with ten algorithms (Logistic Regression, SVM, Naive Bayes, Random Forest, XGBoost, Gradient Boosting, AdaBoost, Extra Trees, KNN, and Decision Tree) and (ii) a Transformer pipeline with ten pre-trained Transformer models fine-tuned on the training data. For the ML pipeline, we work with two static word embedding methods, GloVe and Word2Vec, which transform the preprocessed Reddit posts to dense vector representations appropriate for training standard classifiers. In the Transformer branch, a classification head that consists of a dropout and a softmax layer is attached to the model output to estimate depression severity. The performance of both pipelines is compared using standard metrics, Precision, Recall, F-measure, and Accuracy, to select the best-performing models for severity classification.
3.1. Dataset Description
The data we use in the present study are the Reddit posts from publicly available mental health-related subreddits, such as r/depression, r/SuicideWatch, and r/mentalhealth. The complete list of subreddits used for data collection includes r/depression, r/SuicideWatch, r/mentalhealth, r/anxiety, r/BPD, r/mentalillness, r/ptsd, r/psychotherapy, r/offmychest, and r/depressionregimens. All the data were collected adhering to the public API terms of use of Reddit and the ethical norms of research based on publicly available content. A hybrid methodology involving manual expert annotation was followed using clinical scoring rubrics, specifically the PHQ-9 (Patient Health Questionnaire-9) and DSM-5 (Diagnostic and Statistical Manual of Mental Disorders, Fifth Edition) severity criteria. These two instruments served as the primary reference frameworks for rating depression severity across four levels: minimum, mild, moderate, and severe. No additional scoring rubrics were employed in the annotation process.
We employed a rubric-based manual annotation framework informed by the clinical descriptors in the PHQ-9 and DSM-5 scoring systems. Since Reddit posts are unstructured and not based on questionnaires, we mapped the linguistic indicators of depression severity to rubric descriptions. Specifically, we derived four severity levels: (1) Minimum, reflecting posts with neutral or non-depressive content (based on PHQ-9’s ‘none’ and DSM-5’s subthreshold descriptors); (2) Mild, including posts with occasional depressive language or low distress; (3) Moderate, showing consistent symptoms of emotional distress or social withdrawal; and (4) Severe, corresponding to posts that exhibit expressions of suicidal ideation, hopelessness, or chronic suffering. These labels were assigned using carefully crafted annotation guidelines informed by both rubrics and validated through inter-annotator agreement and expert adjudication.
The inter-annotator agreement was estimated with Cohen’s Kappa, and disagreement was resolved by majority voting and expert adjudication. This strict annotating scheme leads to a dataset representation that captures psychologically meaningful distinctions consistent with clinical standards, also justifying the use of the dataset for fine-grained detection of depression severity.
The dataset contains 9841 Reddit posts, gathered from January 2019 to December 2023, sourced from a variety of subreddits related to mental health, including r/depression, r/SuicideWatch, and r/mentalhealth. For consistency of language and semantic clarity for NLP processing, we filtered the posts to preserve only English content using a language identification model (i.e., langdetect). After preprocessing and filtering (e.g., removing non-English, off-topic, or low-information posts), a total of 9841 Reddit posts were retained for analysis. These posts were authored by 6200 unique users, resulting in an average of 1.59 posts per user. While the majority of users contributed only one post, some users had up to four posts included, reflecting the natural variation of engagement in mental health-related subreddits.
In this paper, we aim to detect multi-level depression severity among users who self-disclose emotional distress or depressive symptoms on mental health forums. Accordingly, the dataset favors subreddits such as r/depression or r/SuicideWatch, where users are looking for some form of support for psychological suffering. Posts that did not have any depression hints and were manifestly out of scope were removed during preprocessing and annotation. Thus, the dataset presents a clinically biased subpopulation and not a general sample of users on Reddit. We could consider including a No Depression class model with a more general/less specific Reddit corpus, but this will also include irrelevant content (e.g., r/funny or r/news), which would be outside the scope and purpose of this study. We do not aim to identify individuals suffering or not suffering from depression; instead, we want to assess the severity of depressive symptoms in a psychologically troubled population. In the future, we will extend the dataset with posts from general subreddits to train a binary classifier for the depressed–not-depressed as an additional task.
3.1.1. Preprocessing Steps
We preprocessed the dataset with several customary steps for model training and evaluation. We first transformed all the posts to lowercase to maintain uniformity. We filtered out URLs, user mentions, hashtags, and non-ASCII characters since they do not carry useful semantic information but could introduce noise. Further processing also included removing punctuation, filtering out stop-words, and tokenization. For the classical models, we also used lemmatization to reduce words to their base form and ease the generalization to similar words. These preprocessing techniques clean and normalize the text inputs for static embedding models (e.g., Word2Vec, GloVe) and contextualized models (e.g., Transformers).
3.1.2. Data Distribution
To overcome overfitting, the Reddit dataset was divided into training (80%), validation (10%), and testing (10%) sets. We employed stratified sampling to ensure that the distribution of depression severity classes remained consistent across all three subsets. This approach preserves the proportion of each class (Minimum, Mild, Moderate, Severe) in the splits, which is critical for training robust models and obtaining reliable performance metrics, particularly given the class imbalance in the dataset.
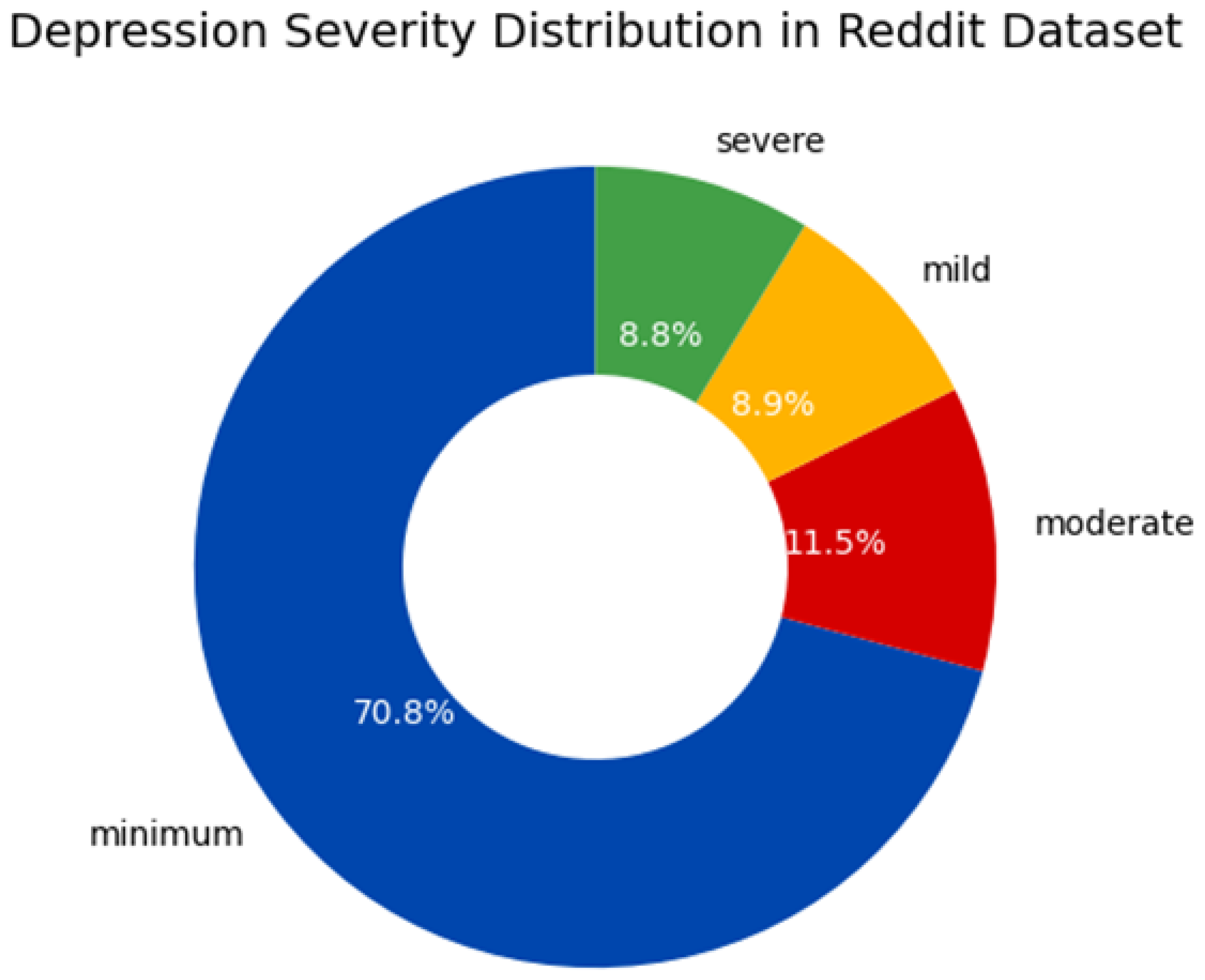
The total distribution of severity categories of depression in the dataset is shown in
Figure 2. As shown, the class of ‘minimum’ gravity is the most frequent in the corpus (70.8% of data). The ‘moderate’, ‘mild’, and ‘severe’ categories, respectively, cover 11.5%, 8.9%, and 8.8% of the dataset. This distribution aligns with empirical trends, where subclinical/low-intensity depression tendency reports are more common.
Figure 2 visualizes that there also exists a severe class imbalance, which is a crucial aspect to consider when assessing a model’s performance and when using approaches like class weighting.
3.2. Machine Learning Models
Because of the imbalance among classes in the dataset, where the number of classes is highly imbalanced and the class ‘Minimum’ has been overinferred (n = 70.8%) in comparison with ‘Mild’, ‘Moderate’, and ‘Severe’, we weighted the model with the value of class ratios in the process of training of all classical machine learning models. In particular, by weighting classes inversely to their frequencies in the training set and using these weights while training the model, baselines can be improved (such as class_weight = ‘balanced’ for SVM and Logistic Regression, and also handling similar weights for models like XGBoost and Random Forest). This approach allowed minority classes to have a substantial contribution to the loss function to avoid the bias towards the majority class. We also tried oversampling techniques (SMOTE and random oversampling), but those caused overfitting in some models. Thus, class weighting was chosen as a more robust and general solution to reduce the impact of class imbalance to preserve model interpretability.
We acknowledge the advancements brought by dynamic and proprietary embedding models such as those from OpenAI, Mistral, and Cohere.
However, in our study we chose to include static embeddings like Word2Vec and GloVe as part of the classical machine learning (ML) pipeline for three key reasons:
Comparative Benchmarking: Our goal was to provide a transparent and interpretable baseline against which Transformer-based dynamic models could be contrasted.
Resource Constraints and Accessibility: Many state-of-the-art embeddings require paid APIs, high computer resources, or are restricted for commercial or research use under licensing agreements, which may not be feasible in all academic environments.
Controlled Experimentation: Static embeddings allow more direct control over feature extraction, which was important for measuring the standalone effect of embedding richness versus model complexity. Notably, we complemented this with Transformer-based models that inherently learn contextualized, dynamic embeddings during fine-tuning. We plan to explore the integration of advanced dynamic embeddings (e.g., OpenAI’s text-embedding-3-small, Cohere’s embed-multilingual-light-v3.0, etc.) in future work once institutional approvals and licensing pathways are cleared.
3.2.1. Logistic Regression (LR)
Logistic Regression is a basic, most-used statistical approach that is a benchmark model in text classification problems. Even though it is simple, it works well in high-dimensional feature spaces such as those given by TF-IDF or Word2Vec word embeddings. In our work, Logistic Regression predicts the likelihood of a post being in one of four depression severity categories by mapping a linear combination of input features to a probability using the logistic function. In addition, LR is less sensitive to multicollinearity and shows good performance with sparse data, which makes it a successful model for massive text corpora such as Reddit posts.
3.2.2. Support Vector Machine (SVM)
Support Vector Machine (SVM) is a practical supervised learning approach suitable for binary and multiclass classification—it is a method used to find the best hyperplane that maximizes the margin [
33]. SVM is used because it can handle non-linear relationships in linguistic data, as the architecture used is a feed-forward architecture with word embeddings as input. The project of data on higher-dimensional space uses the kernel trick and the radial basis function (RBF) kernel for complex decision boundaries. The power of SVM is its ability not to overfit the data, particularly in high-dimensional text space. Its capacity to work with high-dimensional feature vectors and generalize well makes it suitable for subtle classification tasks like multi-level depression detection.
3.2.3. Naive Bayes (NB)
Naïve Bayes is a statistical classification technique based on Bayes’ Theorem, assuming that features are mutually independent. However, despite this naive assumption, it works well for text classification, particularly when used with word frequency-based features such as TF-IDF. In our implementation, Naive Bayes calculates the probability of a post having a certain severity by assigning common words to the labeled categories. It is also computationally efficient and performs very well in the regime of small samples. Although it might not be well-suited for learning complex dependencies, the high-bias, low-variance tasks are fit to perform at par and, therefore, are utilized as the first-level baseline for the depression severity classification task.
3.2.4. Random Forest (RF)
Random Forest is an ensemble learning algorithm that builds multiple decision trees to improve prediction accuracy and control overfitting [
34]. Each tree is built on a different random subset of data and features, which fosters diversity and enhances generalization. Random Forest is advantageous in the framework of this study as it can model the non-linear relationship between word features and depression severity labels. It is especially effective at showing feature importance, allowing us to see which terms most indicate each class. Furthermore, the model’s resistance to noise or overfitting also fits the linguistic variability of the Reddit posts.
3.2.5. XGBoost (Extreme Gradient Boosting)
XGBoost is an efficient Gradient Boosting trainer that constructs decision trees sequentially to correct the mistakes of predecessor trees [
35]. Renowned for its speed and efficiency, it has been adopted in structured data competitions and industry scenarios. We showed in our work that XGBoost was the best ML model and achieved an F1-score of 94%. This success comes from regularization, more complex tree pruning, and the better management of missing values. The capacity of XGBoost to capture complex patterns in depressed language, together with its stable training process, enables XGBoost to be highly effective in seizing nuanced changes of emotional expression and in detecting the level of depression severity with great accuracy.
3.2.6. Gradient Boosting (GB)
Another ensemble method, Gradient Boosting, builds the models additively by minimizing a loss function for a group of weak models (usually, decision trees) stage-wise. Unlike Random Forest, which creates trees independently, Gradient Boosting builds one tree at a time, where each new tree helps to correct errors made by a previously trained ensemble of trees. In this research, a GB-based approach is proposed to model finer-grained differences between the severity levels of depression. It performs well in diminishing bias through successive sculpting. It is more likely to be overfitted than Random Forest, but tuning hyperparameters (such as learning rate, tree depth, etc.) can fix this. It is fast but still competes well with non-linear patterns of texts.
3.2.7. K-Nearest Neighbor (KNN)
K-Nearest Neighbor (K-NN) is a lazy learner that labels instances according to the majority class within their k closest training examples in the feature space. Though basic, KNN performs well for text classification when trained on good-quality embeddings such as Word2Vec and GloVe. In our approach, KNN calculates the similarity between the test post and all the training posts and gives the severity label according to the most similar cases. The model is non-parametric and intuitive without training. However, its effectiveness is limited if the distance measure and the dimensionality of the data are not well matched. Hence, dimension reduction or PCA is necessary in high-dimensional text tasks.
3.2.8. Decision Tree (DT)
Decision Trees divide the data space using feature thresholds, which best separate the classes, and this partitioning of the space over the data is done recursively. They are interpretable and can easily be visualized, and thus they serve as valuable tools to understand how linguistic features contribute to classifying depression severity. In our work, decision trees are used as individual models and as base learners for ensemble techniques. The hierarchical building of trees allows the GBDT to learn feature interactions, but it has the overfitting issue, especially for deep trees. Pruning methods are used to alleviate this risk. Although not state-of-the-art classification methods, Decision Trees open the door to valuable information. They are the building blocks of more sophisticated models that are generalizations of Slippery: Random Forest and Gradient Boosting.
3.2.9. AdaBoost (Adaptive Boosting)
AdaBoost is an ensemble method that structures a weak learner, typically a decision stump, into a strong learner. It creates heavier weights for the out-of-classified example at each round, and the next learners will pay attention to those complex samples. In this work, AdaBoost is utilized to categorize Reddit posts utilizing word embeddings and improve the model’s sensitivity to varying levels of severity over each successive iteration. Its power comes from capturing bias and variance while being sensitive to noise and outliers. When well-tuned, we find that AdaBoost achieves good results and even increases the robustness of the model for a depression detection task.
3.2.10. Extra Trees (Extremely Randomized Trees)
Extra Trees is an implementation of ensemble learning because it is based on the principle of Random Forest. It assigns random weights to the features during decision tree building, which means that, during the tree building, the decision regarding whether the feature is essential or not is not made with a binary tree in Random Forest. It randomly selects split thresholds, instead of the best split value, resulting in a forest of decorrelated trees. The resulting randomness often ameliorates variance and speeds up the training phase of the model. This work uses Extra Trees to improve the generalization across imbalanced depression classes. It works well for learning the correspondence between sparse text features and multi-class labels. Although it may not have the highest accuracy among the tree-based models, its stable performance and low risk of overfitting make it a good competitor in our comparison.
3.3. Transformer Models
3.3.1. BERT (Bidirectional Encoder Representations from Transformers)
BERT is a revolutionary language representation model introduced by Google that understands text in both directions (from left-to-right and right-to-left) while pretraining [
36]. Our work uses BERT as the base Transformer model to leverage complex semantics behind depressive text. It is pre-trained on massive corpora with a masked language modeling task and then fine-tuned on the depression severity dataset. Because of the deep contextual knowledge learned by BERT, it can capture nuanced linguistic cues such as sarcasm, negativity, and emotional expressions, which are essential for determining the severity of depression. Its flexibility and quality make it a good standard for a text-based psychological assessment.
3.3.2. RoBERTa (Robustly Optimized BERT Pretraining Approach)
RoBERTa is an improved version of BERT and does not predict the NSP task; it has larger data and is pre-trained for longer epochs [
37]. It employs dynamic masking and larger mini-batches, producing better language representations. In our experiments, RoBERTa consistently understood nuanced emotions from Reddit posts. The ability of our model to effectively process informal and noisy text, which is a frequent kind in social communities, enriches its applicability in mental health detection. In our experiments, it performs similarly to the top models, particularly within moderate and mild depression classes in which linguistic subtleties are less salient.
3.3.3. XLM-RoBERTa (Cross-Lingual RoBERTa)
XLM-RoBERTa is a multilingual model that was pretrained on 100+ languages [
38]. It is also a variant of the RoBERTa model and is beneficial in code-mixed/multilingual content datasets. In the present work, while most of the data are in English, XLM-RoBERTa helps to evaluate generalization to a wide range of expressions and cultural idioms of depression, which can also be present in English-language posts. Its more exhaustive coverage in language usage is more resistant to misspellings, slang, and dialectal differences. This means it is well-suited to real-world applications where language can be disrupted, informal, or mixed (such as a Reddit discussion on mental health).
3.3.4. MentalBERT
MentalBERT is an in-domain Transformer model fine-tuned on mental health social media data, for instance, posts from Reddit subreddits centered around depression, anxiety, or other mental illnesses [
39]. This specialization is powerful in learning mind narratives, self-referencing language, and emotional patterns. All other models were outperformed in our experiments by the MentalBERT model, with the best F1-score (97%). Its deep understanding of discussion around mental health enables it to differentiate between mild and severe depression by subtle variations in language, like the use of personal pronouns, expressions of hopelessness, or the use of time to reference past trauma. Its domain alignment property makes it highly appropriate for identifying depression severity.
3.3.5. BioBERT
Considering pretraining, BioBERT is retrieved from the Transformer-based model and pretrained using a biomedical corpus, clinical corpus, PubMed abstracts, and clinical notes [
40]. While it has not undergone any specialized training on social media, its extensive exposure to medical language means it can process discussions that contain medical symptoms or pharmacological allusions. In our research, BioBERT was useful in identifying severe depression cases that mentioned clinical symptoms or diagnoses. Its power lies in its capacity to bridge informal internet text and formal clinical language, and by doing so it enhances a model’s ability to capture medically relevant cues of psychological distress.
3.3.6. RoBERTa-Large
RoBERTa-Large is a 24-layer Transformer model that is larger than the base version, with over 300 million parameters [
37]. It also captures more linguistic dependencies and hierarchy structure in text. On our dataset, RoBERTa-Large reached a high F1 score of 96% and was slightly behind MentalBERT. Its higher capacity helps it process longer sentences and multi-sentence context effectively, which is necessary since Reddit posts often include lengthy personal accounts. The larger scale of the model gives it a better generalization capability over fine-grained variations in the expression of different models of depression.
3.3.7. DistilBERT
DistilBERT is a lighter version of BERT that uses knowledge distillation to compress BERT and preserve 97.3% of its performance while being 40% faster. In our work, DistilBERT provided a good trade-off between speed and performance, with an F1-score of 95%. Its small footprint also lends itself well to being used in real time; however, it is also suited to mobile and embedded systems that may be resource-limited, such as preventing and treating mental health conditions. Despite its light nature, DisilBERT achieves high levels of accuracy in terms of minimum and mild severity detection, highlighting its usefulness in those applications that require computational efficiency.
3.3.8. DeBERTa (Decoding-Enhanced BERT with Disentangled Attention)
DeBERTa enhances the disentangled attention and introduces an improved position embedding to address the separation issue better between word content and positional information, compared to BERT. These advances serve to more accurately model word interactions, particularly in longer and more complex sentences in terms of syntax. DeBERTa is also successful in our work due to its ability to grasp deep context cues, which is useful when users share multi-phase emotional trajectories. They performed competitively in identifying moderate and severe depression posts, for which narrative complexity is highly correlated with severity. It is good at learning to attend to sensitively, and hence it is more appropriate for the sensitive classification tasks in psychological text.
3.3.9. Longformer
Longformer is intended to process long documents using a sliding window self-attention mechanism, efficiently handling input sequences of up to 4096 tokens. This is especially true for longer stories in Reddit posts. Longformer was useful in this study when looking at long-range context, which frequently can incorporate gradations, erosion patterns of distress, and previous and future experiences. The long-range dependency capability of the network also contributes to its high performance in classifying severe depression, which often requires information beyond a few sentences to measure emotional intensity.
3.3.10. ALBERT (A Lite BERT)
ALBERT brings parameter reduction techniques to pre-trained language representation without losing information. It adopts factorized embedding parameterization and cross-layer parameter sharing. ALBERT was applied in this work to trade off performance and efficiency and demonstrated comparable good performance across all severity levels. Its parameter sharing contributes to model regularization, which results in better generalization and becomes critical to cope with the nature of imagery since the way textual and affect information is expressed can be pretty diverse and subjective. ALBERT particularly shines in fast experimentation or deployment settings with limited computational resources.
3.4. Hyperparameter Tuning
All classical machine learning models were implemented with the scikit-learn library, and hyperparameter tunes were optimized with grid search cross-validation (GridSearchCV). All of the models were tuned with 5-fold cross-validation based on the training set. For instance, for SVM, C (values: [0.1, 1, 10]) and kernel type (linear, rbf) were tuned, and for Random Forest and XGBoost, n_estimators (100–500), max_depth (5–20), and learning_rate (for boosting models) were optimized.
We worked with Transformer models from the Hugging Face Transformers library. Each model is fine-tuned using a general hyperparameter setting as follows: learning rate = 2 with batch size = 16, maximum sequence length = 256, epochs = 4, and weight decay = 0.01. The AdamW optimizer with linear warm-up and cosine decay was adopted. The models were trained by the GPU, and early stopping by the validation loss was done to avoid overfitting. We maintained these settings consistently across models for fair comparison, except where otherwise specified in the model documentation (e.g., Longformer needed longer sequence lengths).
3.5. Evaluation Metrics
To evaluate the performance of our ML- and Transformer-based models on the task of predicting the depression of participants, we utilized established evaluation metrics that are commonly used in multi-class prediction problems. Precision, Recall, F1-Score, and Accuracy highlight a different side to the model’s performance. Precision indicates the ratio of correctly predicted positive occurrences to the total number of predicted positives, representing how accurate the model is in predicting each severity level. Recall measures the model’s ability to identify all relevant class members and reflects the model’s sensitivity. F1-Score (the harmonic mean of Precision and Recall) is a balanced metric for imbalanced datasets, like in our case, where the ‘minimum’ class overwhelms the others. Finally, Accuracy provides a complete picture of the performance but can be deceptive in the case of class imbalance. Together, these metrics fully evaluate how well each model represents the nuanced features of depression severity levels.
4. Experiments and Results
This section outlines the experiments performed to test the effectiveness of machine learning and Transformer-based architectures for depression severity classification. We have laid out the experimental procedure—data splits and embedding methods used, how the model was trained, and the evaluation procedure. We present the results with Precision, Recall, F1-score, and Accuracy as key performance metrics to demonstrate the effectiveness of each model across all the levels of depression. This section presents some of the best-performing models and gives clues on the most effective methodology for fine-grained mental health detection on social media text.
Table 2: Performance of ten machine learning models trained with Word2Vec embeddings. XGBoost reportedly performs the best, showing an F1-score of 91.20%, with SVM (87.50%) and Random Forest (86.22%) following close behind. Logistic Regression reached a decent F1-score of 81.14%, showing that it still could be successfully applied to feature-rich representations of the depression severity tasks. More shallow models, such as Naïve Bayes (F1 = 60.71%), failed to generalize depressive textual cues, likely due to their strong independence assumptions. K-Nearest Neighbor and Decision Trees provided only moderate contributions, with F1-scores of 80.07% and 77.80%, respectively: more sophisticated ensemble methods are better suited for the complex patterns of emotional text.
Table 3 demonstrates a significant increase for the same machine learning models with GloVe embeddings. Again, XGBoost is on top, with an F1-score of 94.01%, the best among all ML models. SVM and Logistic Regression achieved high F1-scores of 91.67% and 85.18%, respectively, further supporting that GloVe’s co-occurrence-trained word representations better capture the emotional nuances necessary for depression severity classification. Ensemble learning methods, such as Random Forest and Extra Trees, also did well, yielding F1-scores above 89%. Not only was the performance of Word2Vec better than even weak classifiers such as Naïve Bayes, but the increased performance also indicates the necessity of high-quality semantic embeddings to improve text classification accuracy.
Comparing Word2Vec and GloVe, GloVe improves classifier performance in most models. This is especially evident for gradient-boosted models, for which F1-scores are enhanced by 3–5% across all scenarios. Such gains indicate that GloVe captures richer textual context compared to local window information (Word2Vec), which is essential for predicting different levels of severity of depression. And the utility of the deeper contextualization of the embeddings analyzed shows that the richness of the embedding significantly impacts the performance of mental health detection from text.
The performance of ten Transformer-based models, fine-tuned for the depression severity classification task, is reported in
Table 4. MentalBERT reached the highest F1-score (97.30%) and outperformed other models considerably. This is due to its domain-specific pretraining on mental health discourse, which renders it more attuned to emotional expression. RoBERTa-large and RoBERTa-medium have also reported excellent F1-scores of 96.14% and 96.27%, which demonstrates the generalization ability of these unspecific universal Transformer models with the fine-tuned data of emotional texts. The contextualized attention mechanisms and the large-scale pretraining enable these models to effectively learn subtle self-expression patterns, which makes them suitable for fine-grained symptom severity classification.
Interestingly, even the smaller and more specialized models such as DistilBERT and ALBERT achieved high F1-scores of 95.09%, indicating that they can be helpful in realistic deployment in constrained computational settings. The results of DeBERTa and Longformer were also competitive, with their results of F1 around 95.31% and 95.10%. These results support the idea that domain-specific pretraining (e.g., MentalBERT) performs best. However, even generic models with sensitive fine-tuning obtain high accuracy in recognizing nuanced emotional states from Reddit utterances.
Table 5 presents the class-wise evaluation results (Precision, Recall, F1-Score) for the top five performing models, including four Transformer-based models and one classical machine learning model (XGBoost with GloVe embeddings). Among all models, MentalBERT achieved the highest F1-scores across all depression severity levels, demonstrating its effectiveness in capturing mental health-specific language. RoBERTa and RoBERTa-large also performed strongly, especially on the Severe and Minimum classes. XLM-RoBERTa showed balanced performance but slightly lower scores in the Mild and Moderate categories. XGBoost, although a non-Transformer model, performed competitively on the Minimum and Severe classes, indicating its value in low-complexity, interpretable ML settings. These results validate the strength of domain-adapted Transformer models for fine-grained depression severity detection.
Transformer models perform significantly better than traditional machine learning models on all evaluation metrics. However, classical approaches, and in particular XGBoost and SVM with GloVe-like embeddings, provide competitive baselines that are quicker to train and easier to interpret. These classic models may be utilized in a real-time context in which model explainability and computational cost are central, while Transformer models, especially in research-grade severity classification tasks, have the highest performance and linguistic depth.
5. Conclusions and Future Work
Our aim in this work was to detect the multi-level depression severity of users’ post in Reddit social media and ranked the user’s depression severity into minimum, mild, moderate, and severe. By combining traditional machine learning models and more recent Transformer-based models, we show that the reliable detection of depression severity in textual data is possible and accurate. For machine learning-based models, XGBoost, especially with GloVe embeddings, delivered the highest performance, with an F1-score of 94.01%. From the Transformer side, MentalBERT, a task-specific model pre-trained on mental health content, performed best, with an amazing F1-score of 97.30%. Our results show the significance of domain-specific pretraining and meaning-rich embeddings for the fine-grained linguistic signal of depression severity. Our work underscores that fine-grained depression classification involves sophisticated language understanding, and it demonstrates the potential for Transformer architectures to support detail-rich mental health monitoring through user-generated content.
Although we use well-known machine learning and pure Transformer models, the novelty of the work is in the extensive benchmarking and comparative study of ten conventional classifiers and ten deep Transformer architectures, not for binary depression detection tasks, which have been commonly studied so far, but for four-level severity classification of depression. Additionally, we integrate the latest state-of-the-art models for specific domains, such as the MentalBERT and BioBERT models, and compare their performance to the generic Transformers in the context of the mental health conversation. We further adopt more stringent annotation guidelines that conform to DSM-5 and PHQ-9 and conduct class-wise performance analysis to identify which models are better at modeling the severity differences. As far as we know, this type of multi-model, multi-level evaluation integrating clinical annotation standards and linguistic nuances of Reddit posts has not been reported at this scale before. Hence, although the tools themselves are not new, their combination and application to this particular clinical NLP problem constitute a valuable empirical and practical contribution to the nascent domains of computational psychiatry and social-media-based mental health surveillance.
Although our methodology performs well, we discuss several future directions to improve depression severity detection. First, this work is based purely on text data. Incorporating multi-modal inputs (audio, user metadata, and visual features) may enhance model diversity and reflect emotion cues. Second, longitudinal comparisons over user timelines can be investigated to identify changes in depression severity over time, which can be later used for early intervention. Another potential direction is prediction explainability: incorporating explainable AI (XAI) approaches would allow us to interpret why a model predicts the severity level, which is crucial for clinical deployment. It will also be interesting to perform cross-platform validation to ensure the models generalize well across a variety of social media domains (e.g., Twitter, Facebook, or mental health-specific forums). Finally, addressing the data imbalance with advanced resampling methods or specialized loss functions might help further boost model performance, particularly for underrepresented classes such as severe depression. Extending this line of research into real-time, ethical, and privacy-preserving depression detection systems is a critical next step for generalizable societal impact.



 ,
, 

{kind=link}
{kind=link}