4.2. Parameters and Setup
For the FB15K-237 dataset, experiments were conducted using two different architectures: RoBERTa and BERT-LARGE. The RoBERTa-based model was trained on two A100 GPUs, while the BERT-LARGE-based model was trained on two RTX 3090 GPUs. Both RoBERTa and BERT-LARGE consist of 24 Transformer layers, with a hidden size of 1024 and 16 attention heads.
During the sample generation phase, we used a fixed random seed (seed = 530) to ensure consistency in negative sampling and data shuffling. This allowed us to minimize the impact of random variation across different runs and enhance the reproducibility of the training and evaluation process.
The hyperparameter settings for the pretraining phases are shown in
Table 2:
During the pretraining phase, a learning rate of 5 × 10−5, a batch size of 32, an epoch of 32 (WN18RR), and a maximum sequence length of 143 were employed. In the fine-tuning phase, a learning rate of 1 × 10−6, a batch size of 32, and an epoch of 5 were used.
The hyperparameter settings for the Fine-tuning Parameter Settings are shown in
Table 3 and
Table 4:
The following key parameters were used in our task configuration:
model type = sequence-classification: This setting indicates that each triplet is linearized into a natural language-like sentence and fed into a pre-trained language model for binary classification, determining whether the triplet is valid or not.
negative train corrupt mode = corrupt-one: In this negative sampling strategy, for each training sample, only either the head or the tail entityis replaced to generate a negative triplet, rather than corrupting both sides. This approach reduces redundancy and improves training efficiency.
entity relation type mode: This parameter controls whether entity and relation type information are included in the input:
- –
When set to 0, no type information is used. The model relies solely on the surface names of entities and relations for reasoning.
- –
When set to 1, explicit type prompts for entities and relations are included in the input sequence (e.g., via hard tokens or soft embeddings), enhancing semantic constraints and generalization ability.
To train the model to distinguish plausible from implausible links, This paper adopted a negative sampling strategy inspired by KGLM. In the context of knowledge graph completion, are artificially constructed triplets assumed to be false. By contrasting these with positive triplets, the model learns discriminative representations for link prediction.
Specifically, for each positive triplet , we generate a total of ten negative triplets by independently corrupting the head and tail entities five times each, following the corrupt-one setting. This strategy considers both the head and tail positions as candidates for replacement, enhancing the model’s ability to capture structural variation.
We construct five negative samples of the form by replacing the head entity and five samples of the form by replacing the tail entity. The corrupted entities and are sampled uniformly from the set of all entities in the knowledge graph, excluding any replacements that would result in known positive triplets. This aligns with the principle of filtered negative sampling. This procedure is consistent with the implementation described in the original KGLM paper.
When LP tasks are applied to downstream tasks, the accuracy of the Top-k predicted results needs to be evaluated. Therefore, LP tasks are assessed using three evaluation metrics: mean rank (MR), mean reciprocal rank (MRR), and Hits@N.
Mean Rank (MR) is defined as in Equation (
12):
where
is the rank of the positive triple among its corrupted versions, and
is the number of positive test triples.
represents the processed dataset for LP tasks. A lower value of MR indicates better model performance.
MRR, compared to MR, uses. instead of . Therefore, a higher value of MRR indicates better model performance.
Hit@N is defined as follows in Equation (
13):
where
is commonly reported. A higher value of Hit@N indicates better model performance.
4.3. Analysis
During the ablation study, experiments were conducted on the WN18RR dataset to evaluate the effectiveness of the BRA module in improving model performance. Additionally, the impact of varying Top-K values within the BRA module on the model’s performance was further examined. The corresponding experimental results are presented in the following tables.
The comparative experimental results of Top-K in BRA of the WN18RR dataset are shown in
Table 5.
All experiments use KGLMbert-large as the baseline model. KGLM-BRA (Top-K) denotes the results of KGLMbert-large with the BRA module under different Top-K settings.
Table 5 presents the impact of different Top-K feature retention settings within the Bidirectional Routing Attention (BRA) module on link-prediction performance. The experimental results demonstrate that the choice of Top-K plays a critical role in determining the model’s effectiveness.
When the number of retained features is small (e.g., ), model performance drops significantly—Hits@1 is only 0.05, MRR is 0.196, and MR increases to 235. This suggests that excessive filtering leads to the loss of critical relational information, weakening the model’s semantic understanding and prediction capability.
As Top-K increases to , the model exhibits substantial performance gains, with Hits@10 reaching 0.60 and MRR rising to 0.32. This suggests that retaining a sufficient number of relevant features enables the model to capture structural and relational patterns better, thereby enhancing prediction accuracy.
However, when Top-K is further increased to 10, the performance no longer improves and slightly degrades—Hits@1 drops from 0.192 to 0.184, MRR decreases from 0.324 to 0.320, and MR increases to 94.32. This decline may be attributed to the introduction of redundant or noisy features, which negatively affect the model’s generalization.
Overall, these results confirm that a proper balance must be maintained between information sufficiency and redundancy. A value of Top-K that is too small may cause information loss, while a value that is too large may introduce noise and harm performance.
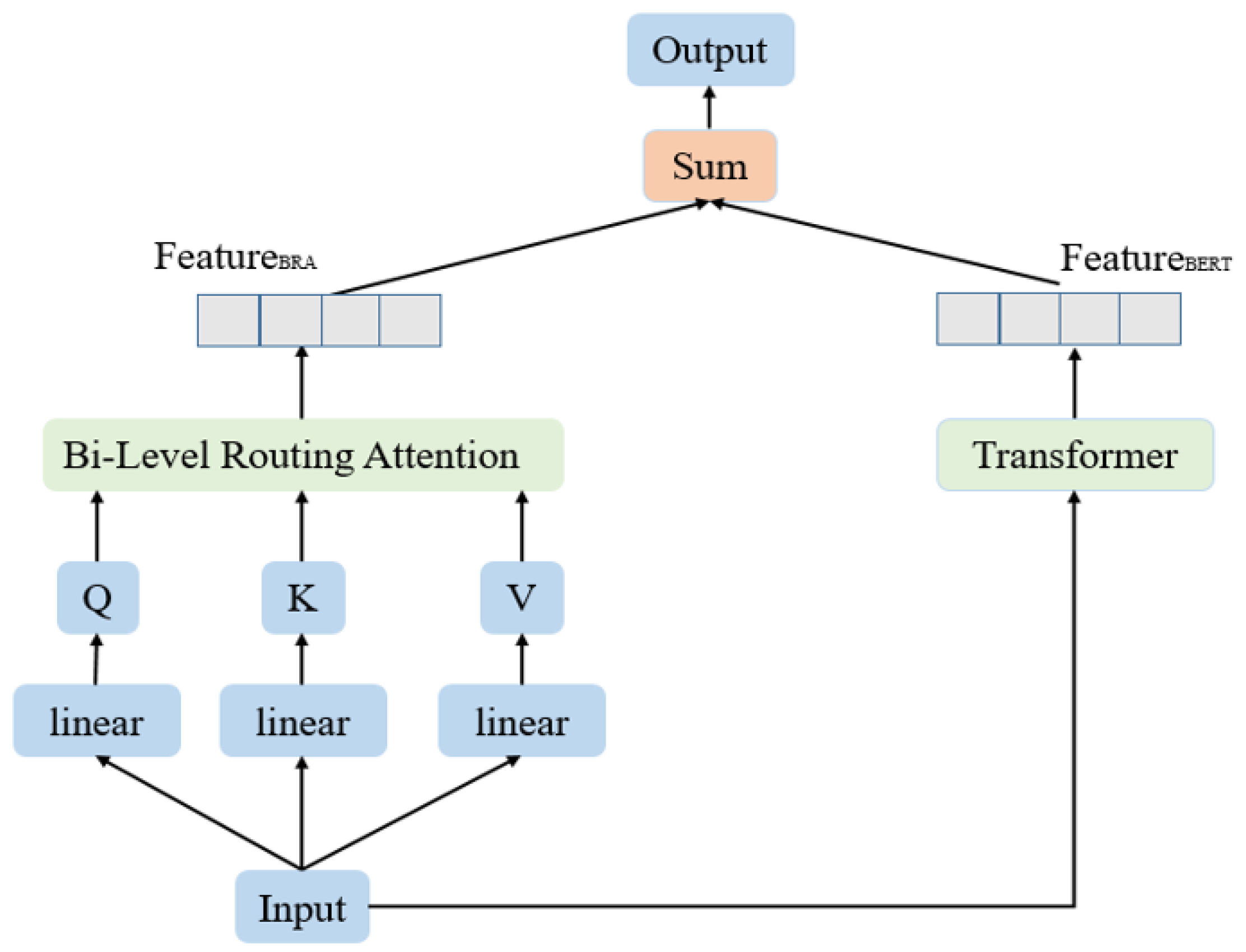
To further validate the effectiveness of the BRA module, an ablation study was conducted on the WN18RR dataset, using KGLM as the baseline model with BERT-LARGE as the encoder. In the experimental setup, the original BERT encoder was replaced with the proposed BRA-LP module while keeping all other hyperparameters unchanged.
The results show that incorporating BRA leads to overall improvements in MRR and MR, with particularly notable gains in Hits@10 and Hits@5. Although there is a slight decrease in Hits@1 and Hits@3, this suggests that BRA enhances the model’s ability to distinguish between positive and negative samples at a broader ranking level (Top-K), increasing the probability of correctly identifying the correct entity among the top candidates.
It is also worth noting that if Top-K is set too small, the model may overemphasize relational information while neglecting other contextual cues, which can negatively impact top-ranked predictions (e.g., Top-1 and Top-3). Therefore, careful tuning of the Top-K parameter is essential for maximizing the effectiveness of the BRA module.
This paper compares the parameters and computational costs between KGLM and KGLM-BRA on BERT-LARGE (WN18RR), as shown in
Table 6:
As shown in
Table 6, our proposed module is designed based on the Transformer architecture and incorporates dimensional expansion operations. As a result, under the condition of retaining the original hyperparameter settings, the model exhibits a noticeable increase in FLOPs—approximately three times higher than the baseline model. However, thanks to our structural simplification strategy (e.g., the removal of scaling and convolution operations), the module does not lead to a significant increase in training time, and the total number of model parameters increases by only about 1 million.
Although the FLOPs increase is substantial, the improvements in overall performance metrics (such as MRR and Hits@K) remain relatively modest. This phenomenon can be attributed to several factors. First, the pre-trained backbone models used in our study (e.g., BERT-large and RoBERTa) already exhibit strong baseline performance, making further improvements subject to diminishing returns. Second, the BRA module is primarily designed to enhance semantic representation and relation-modeling capabilities, aiming to improve global ranking metrics (e.g., Hits@10) rather than specifically optimizing Top-1 accuracy. Third, most mainstream evaluation metrics focus on final prediction outputs and may not fully capture the potential benefits brought by attention structure refinements in intermediate layers.
To further verify the generalization and adaptability of the BRA module, we conducted comparative experiments on the FB15K-237 dataset using two different backbone models: KGLM_BERT-LARGE and KGLM_RoBERTa. The corresponding results are presented in
Table 7 below. In future work, we plan to explore structural optimization techniques such as low-rank approximation, sparse attention, and dynamic routing mechanisms, aiming to reduce computational complexity while maintaining performance, thereby enhancing the method’s deployability and cost-effectiveness in real-world applications.
As shown in
Table 7, our proposed method achieves consistent performance improvements on both the FB15K-237 and WN18RR datasets. Specifically, the KGLM-BRA model outperforms the baseline KGLM in terms of overall ranking metrics such as Hits@10 and MRR across different encoder backbones. For instance, on FB15K-237, the BRA-enhanced model improves Hits@10 from 0.33 to 0.35 with BERT-large, and from 0.441 to 0.449 with RoBERTa, while also reducing the Mean Rank (MR), indicating better global ranking capability.
Although the improvements in Hits@1 and Hits@3 are marginal or slightly decreased in some cases, this is expected due to the already strong performance of the underlying PLMs and the inherent design of the BRA module, which focuses on enhancing global semantic representation rather than optimizing for exact Top-1 accuracy.
With the continued development of large-scale language models, we argue that returning a semantically plausible Top-K candidate list—rather than a single best prediction—provides more flexibility for real-world professional applications. This allows downstream modules or domain experts to perform further reasoning, validation, or filtering, which is often more aligned with practical decision-making workflows.
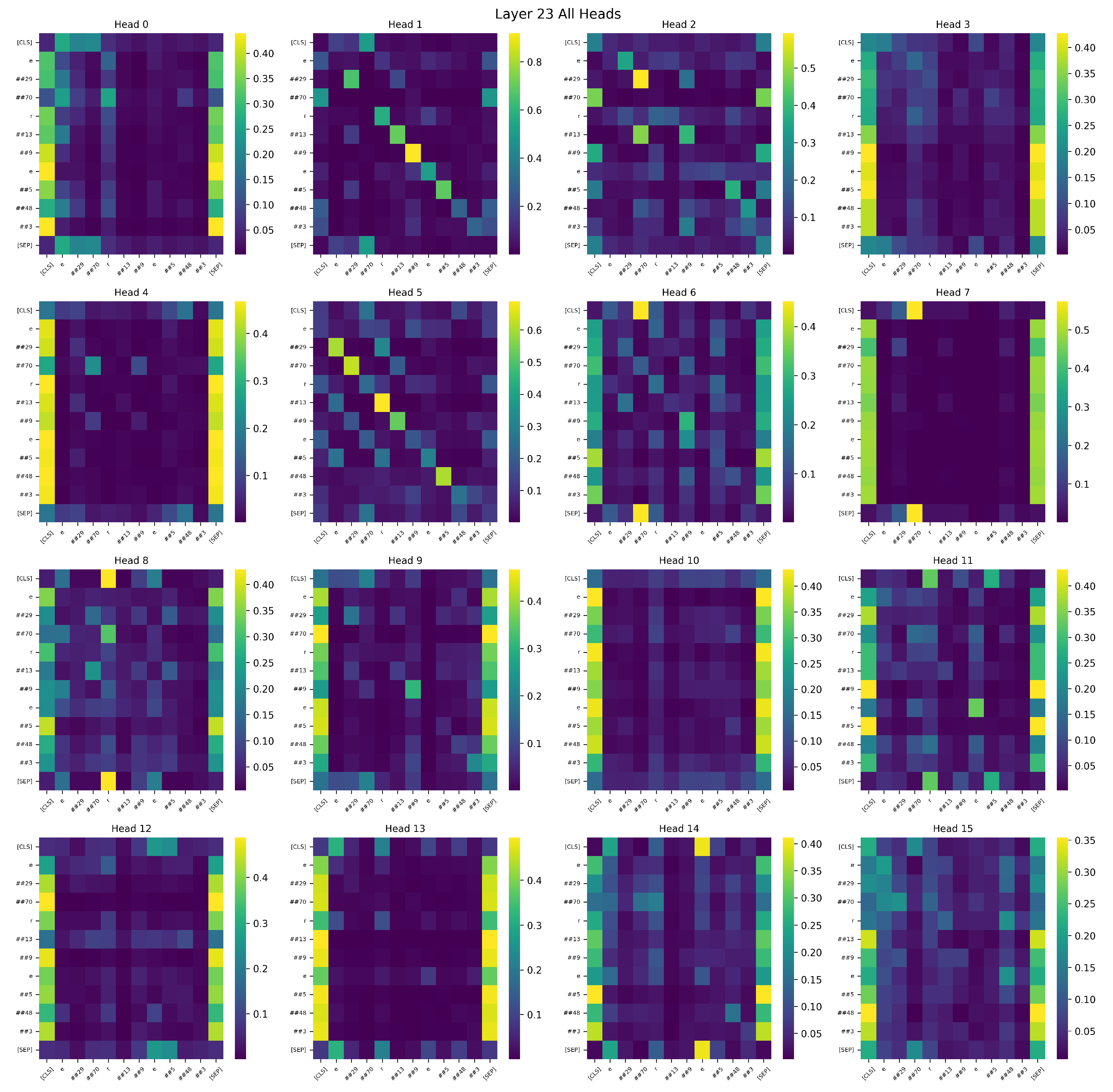
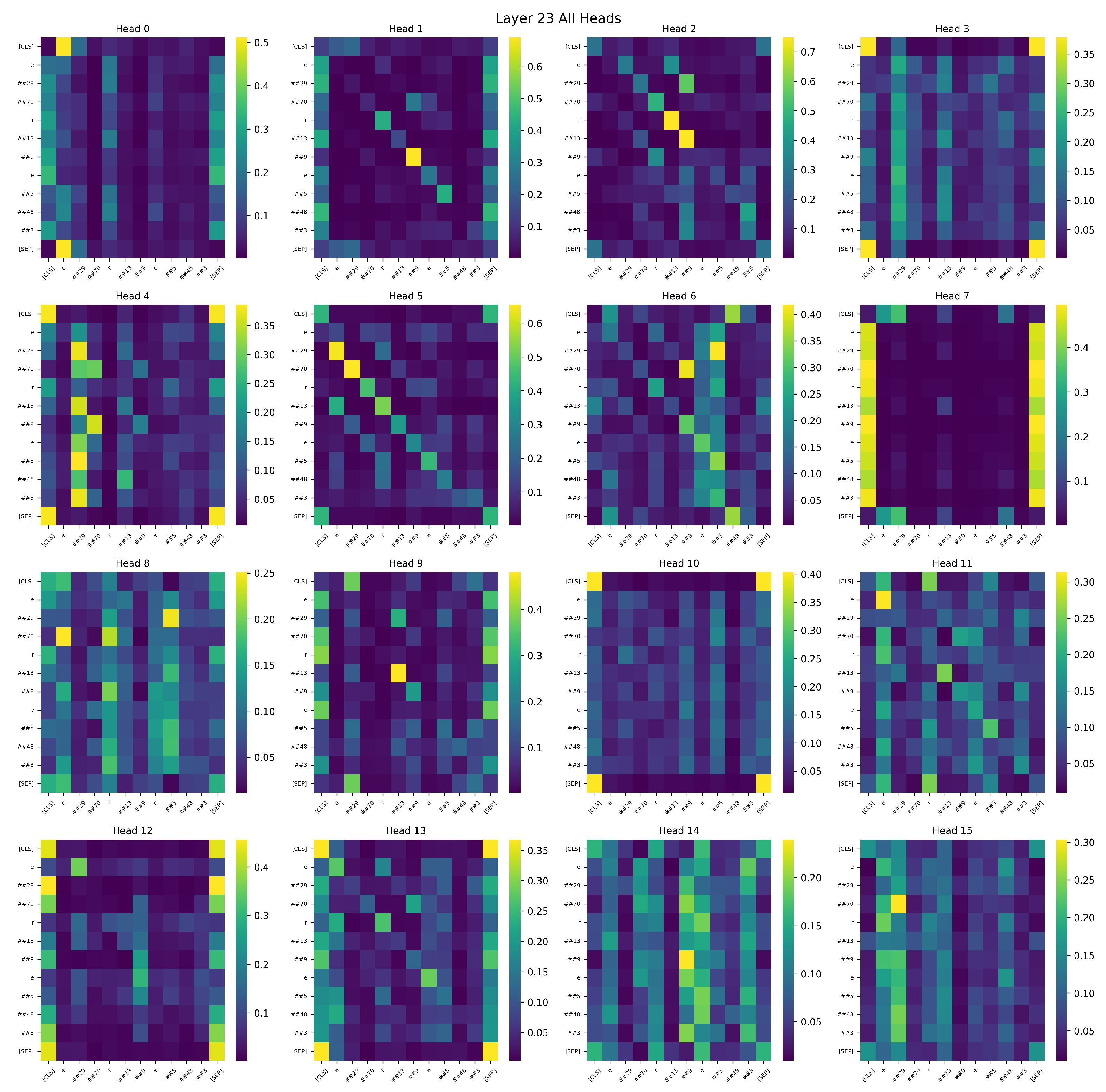
In multi-head attention architectures such as BERT-Large, each attention head is designed to capture distinct types of token-level dependencies, including syntactic, semantic, and positional relationships. During training, attention heads that are more aligned with task-specific objectives—such as modeling entity–relation or relation–tail interactions in link prediction—tend to receive stronger gradient updates. This leads to progressively sharper and more discriminative attention patterns. As illustrated in
Figure 6 and
Figure 7, which visualizes the attention maps of Layer 23 for sample, the BRA-enhanced model demonstrates that several attention heads consistently focus on semantically critical tokens, highlighting the model’s ability to align with predictive features in an interpretable manner.
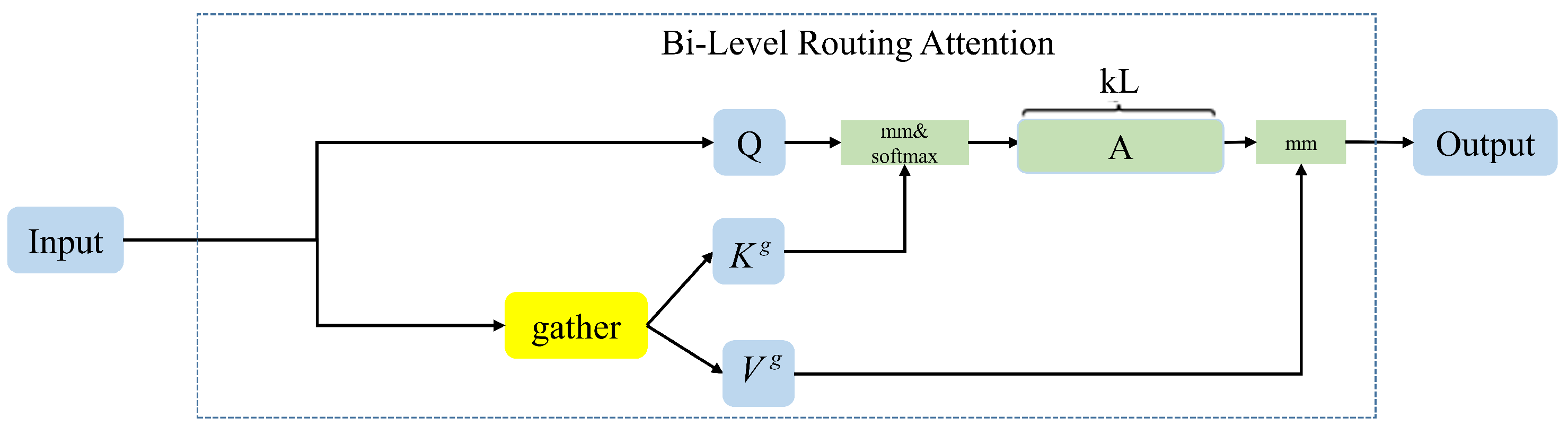
Furthermore, the proposed BRA module enhances this mechanism by introducing a semantic-aware reordering of feature importance. By encouraging the model to prioritize highly relevant regions early in training, BRA accelerates convergence and strengthens the model’s ability to capture fine-grained relational semantics. As a lightweight and modular enhancement, BRA requires no additional parameters or architectural modifications, yet effectively guides the standard attention mechanism toward semantically meaningful substructures.
The BRA-based model exhibits more structured and diverse attention behaviors in deeper layers. Multiple attention heads (e.g., Head 1, 2, 5, 6) form highly focused paths over task-relevant tokens, while the functional differentiation among heads becomes more pronounced. These results suggest that BRA substantially enhances the model’s semantic representation capacity, interpretability, and downstream reasoning performance.
To verify the stability of the experimental results, we conducted multiple independent runs during the fine-tuning stage using different random seeds. The experiments were carried out on the FB15k-237 dataset with RoBERTa as the baseline model. The performance metrics of each run are presented in
Table 8 below, showing that the model maintains relatively consistent performance across different random initializations. This confirms the robustness and reproducibility of the proposed method.
To verify the stability of the model under different random initializations, we supplemented the original experiment (seed = 530) with two additional runs using seeds 42 and 3407. As shown in
Table 8, the model exhibits consistent performance across different seeds, with small standard deviations in key metrics (e.g., MRR: 0.280 ± 0.009, Hits@10: 0.442 ± 0.042), indicating the robustness of the proposed method.
We compare the performance of KGLM-BRA against recent state-of-the-art methods on the WN18RR dataset and FB15K-237 as shown in
Table 9 and
Table 10:
As shown in
Table 9 and
Table 10, our approach exhibits notable advantages compared to recent methods. GCN-based models such as CompGCN and SimKGC generally outperform in Hits@1 and Hits@3 metrics, while PLM-based approaches like KGLM and StAR demonstrate strengths in Hits@10 and Mean Rank (MR), highlighting their superior global ranking capabilities.
Although the overall precision of KGLM-BRA may not yet surpass all state-of-the-art models—particularly in Hits@1 and MRR—it presents a promising direction for enhancing PLM-based architectures in the link-prediction domain. Rather than introducing entirely new model structures, our method focuses on lightweight, modular improvements specifically designed for BERT and RoBERTa backbones. This is achieved without altering the original hyperparameter settings or significantly increasing model size—the parameter count grows by only about one million.
While the computational cost (FLOPs) increases due to token-level routing operations, the training pipeline remains largely unchanged. This allows for improved semantic modeling with minimal additional overhead. Overall, the proposed method provides a practical and extensible solution for improving PLM-based link-prediction systems under constrained parameter budgets, offering a favorable trade-off between efficiency and accuracy.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}